1. Introduction
State Machine Replication (SMR) is a fundamental technique for providing available and consistent services in fault-tolerant distributed systems [
1]. Imagine a system where multiple replicas of a state machine are maintained across different processes. To implement SMR, all correct processes execute the same set of requests in the same order, leading to identical states across all correct processes in the system. SMR ensures that even if some processes fail, the system remains consistent and can process requests issued by clients. SMR is foundational in the design and implementation of fault-tolerant distributed systems.
At the core of SMR is a consensus protocol that reaches an agreement on requests [
2], even in the presence of failures such as crashed processes or network problems. Consensus protocols, also known as consensus algorithms, are the backbone of many modern distributed databases and other critical infrastructures, such as distributed file systems. Consensus serves as a middleware between applications and storage layers, thereby ensuring stable data management [
3,
4,
5,
6].
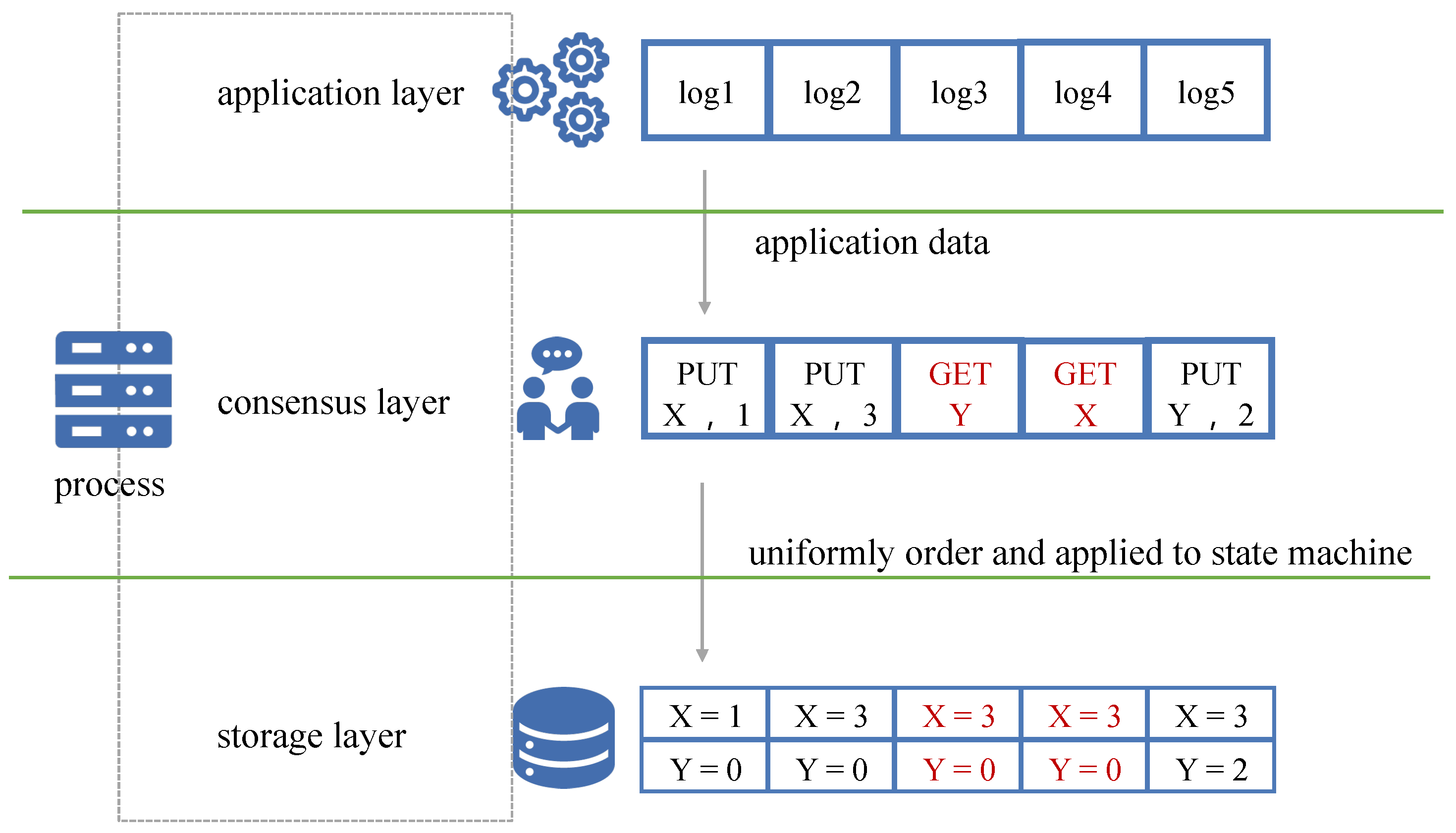
Figure 1 shows the role of consensus in distributed systems. Processes first receive application requests from clients and resort to a consensus protocol to locate each request in a shared log. After an order is determined, the logs are parsed into read and write operations on the underlying storage layer for persistent storage in databases.
Among existing consensus protocols, Paxos [
7,
8] and Raft [
9] are widely used in industry. Paxos relies on a leader to make a proposal and coordinate consensus, while other processes, usually called followers, negotiate and learn the proposal. This architecture provides foundational solutions to the consensus problem and inspires some of its variations [
10,
11,
12]. However, its complexity often makes it challenging to totally understand and implement in practical systems by system developers [
9,
13]. On the other hand, Raft, introduced by Ongaro and Ousterhout in 2014, is designed to be more understandable while retaining the desired properties, so it has been a popular alternative in recent years in terms of building consensus-based distributed storage services like Redis [
14], CockroachDB [
6], and etcd [
15]. Raft continues to reinforce the role of the stable leader, while during the implementation of Raft, there are still many details affecting data consistency that need to be paid attention to, such as handling split-brain conditions.
The above two consensus protocols, along with other protocols such as Viewstamped Replication [
16], are designed in the partially synchronous network model, which relies on the known timing bound of message transmission. In this model, the safety attribute called strong consistency holds irrespective of network conditions, while the liveness attribute hinges on a fixed period. In other words, these protocols guarantee that all the correct processes agree on the same order of commands. However, the protocols can always progress only in a partially synchronous network. The protocols proposed for the partially synchronous model are usually designed with a special role of a leader process [
9,
13]. Processes elect a sole leader entrusted with the helm of the consensus coordination. When the leader is considered failed, correct processes try to elect another process as the new leader, who then embarks on executing a fail-over protocol to retrieve the most recent state. Multi-leader [
17,
18] or leaderless [
12,
19] variants, which diverge from the above protocols, allow processes to take turns being the leader handling different consensus instances, or order requests with conflicting semantics through a coordinator. However, these variants are also bonded with the timing assumptions mentioned above and still need to accomplish fail-over protocols. In this case, system developers need to manually configure relevant variables to ensure the liveness of the system [
15].
In contrast, asynchronous protocols [
20,
21] do not need to hold elections to decide who owns the leadership, which means they are leaderless. The lack of crucial processes helps maintain liveness under asynchronous networks, simplifying the design and implementation of systems. For example, systems based on asynchronous consensus protocols run normally even when a minority of processes fail, allowing other recovery processes to join the consensus cluster without trivial recovery protocols. It should be noted that according to the FLP impossibility theorem [
22], it is impossible to design a deterministic algorithm that ensures consensus among all the correct processes in the presence of even a single failed process in asynchronous networks. Therefore, all the asynchronous consensus protocols need to import a randomization module, which means that under some circumstances, the termination of the consensus round is probabilistic rather than fixed. This may lead to an increase in the delay in completing the consensus on a specific request, which has made asynchronous consensus protocols be considered less efficient in the past few decades. Asynchronous consensus has already had mature applications in distributed system consensus under the Byzantine Fault Tolerance (BFT) model [
23,
24]. So, the asynchronous consensus in the Crash Fault Tolerance (CFT) model is worth exploring. However, in 2021, Rabia [
25] became the first asynchronous consensus protocol that entirely designs and implements SMR to be applied in the CFT model in the past few years.
If we look back at
Figure 1, we find that the execution of the read request does not change the state of the database storage. Therefore, the read request does not need to go through the consensus and run the state machine. The client can read directly from the processes, which can reduce the latency and resource consumption while running consensus instances, thereby achieving higher system throughput. In many systems, read operations vastly outnumber writes [
26]. The performance of read operations, as such, can impact the overall system performance. So, how to optimize read operations is a crucial topic, especially under read-heavy workloads.
However, it should be noted that although the read operation does not go through consensus, it is still necessary to ensure the linearizability [
27] of the read and write operations: Once a write operation is completed, each following read must see that state or some later state. In other words, every read must obtain the most recently updated value instead of the stale one.
Read optimization for leader-based consensus is divided into two types: read lease [
28,
29] and read quorum [
30,
31]. However, the read lease method is not suitable for all the leaderless consensus protocols, including asynchronous consensus, because the leader process is generally required to serve as the leaseholder. Similarly, the existing quorum read method cannot be directly applied to asynchronous consensus either because it cannot be ensured that each process can synchronously run the consensus instance in the same slot under asynchronous networks, which we discuss in detail in the
Section 3. So, the method designed for optimizing asynchronous consensus reads has yet to be discussed and proposed.
In the following sections, we first provide models of partially synchronous and asynchronous consensus protocols, then we carry out a brief introduction about the current read optimization methods for partial synchronous consensus, analyzing why they cannot be applied to the existing asynchronous consensus. Next, we introduce ACQR (Asynchronous Consensus Quorum Read), a read optimization mechanism for asynchronous consensus protocols like Rabia. It is a novel work to optimize read operations for asynchronous consensus. We implemented and evaluated ACQR to prove its performance compared with the original implementation of Rabia.
In summary, the highlights of this work include the following:
ACQR is the first proposed read optimization method for asynchronous consensus.
Read operations can be completed simply by reading from the quorum without any special role.
The implementation and evaluation of ACQR in Rabia, the state-of-the-art asynchronous consensus protocol. ACQR improves the throughput of Rabia by up to 1.7× and reduces the optimal latency by 40%.
2. Models
Firstly, we provide abstractions for the consensus problem. To provide fault-tolerant service to clients, processes are typically configured in a multi-machine set-up, presenting outwardly as a cluster. We consider a distributed system comprising a total of N processes. It is important to note that within this cluster, a maximum of f processes may experience failures, such as crash faults or hardware malfunctions. This redundancy is established to ensure consistent service delivery to clients, as each of the N processes in the cluster maintains identical data backups.
Suppose that the entire cluster has a fixed arrangement that satisfies
. To clarify, the precise formulation should be
, which stipulates the minimum number of processes required in a cluster to maintain a fault-tolerant consensus in the presence of
f possible process failures. This threshold is pivotal for the integrity of the consensus process. In real-world distributed system deployments,
N can indeed be any integer that satisfies this inequality. Conventionally,
N is chosen to be equal to
in order to facilitate the design of the protocol and reduce redundancy. Even if under the failure of
f processes, the consensus protocol can run effectively with the remaining
processes. Selecting a value of
N that exceeds
could lead to excess in resource allocation and operational costs. In practical process cluster configurations, especially those under Crash Fault Tolerance (CFT) model in cloud computing, it is common to use the configuration of five processes [
4] (accommodating for the failure of up to two processes). This strikes a balance between cost-effectiveness and reliability, preventing unnecessary overhead while implementing fault tolerance.
So, for the convenience of discussion, we assume
. In this case, any
will contain
processes. The concept of a quorum is integral to the consensus in distributed systems, representing the minimum number of processes that must concur to form a consensus. In Crash Fault Tolerant (CFT) models of consensus, the requisite quorum size is typically
, which, for
, equates to
. This threshold ensures that the agreement of
processes achieves a determined consensus, precluding the concurrent formation of a different consensus by any other quorum. Invoking the pigeonhole principle [
32], if a system were to have two distinct quorums within a cluster of
N processes, the sum of their sizes would less than
N, a contradiction with the fact that
. Consequently, any two quorums must overlap by at least one process, thereby ensuring that any decision endorsed by a quorum is indeed validated by an adequate number of processes.
It is noteworthy that all the issues we discuss are based on the CFT background, and the Byzantine fault will not happen. Communications between all the correct processes are reliable, meaning any message transmitted between them will eventually be delivered.
The client sends a request to the process cluster with a unique identification, it can be constructed with a client ID and timestamp. Consensus aims to allow each process to execute the client requests in the same order while satisfying the following properties:
- -
Safety: If two processes commit requests , at the same position, then and must be the same request.
- -
Liveness: Any request made by the correct client will eventually be delivered and executed by every correct process.
Based on satisfying the above model, partially synchronous and asynchronous consensus satisfies their time assumptions.
As shown in
Figure 2, there is often a stable leader in the partially synchronous consensus. Furthermore, other processes negotiate whether to accept the leader’s proposal. Because the upper limit of message transmission delay in this type of network is known, each process can find out in time whether the consensus messages of each round arrive within the specified time, thereby showing consistent behavior; in contrast, in the asynchronous consensus shown in
Figure 3, processes exchange proposals with each other on separate consensus instances. If the majority of agreement is received, the process will vote “1” representing approval; otherwise, a vote of 0 represents the opposition, and then it enters the randomized binary consensus stage, which is essentially the same as the random algorithm proposed by Ben-Or [
33], who states that if the process collects enough “1” votes, then it will determine the proposal as the result of the consensus instance. Otherwise, the process votes “?” if it cannot collect enough approved votes. If the process is still not sure in the next stage, then it will randomly vote “1” or “0” at the beginning of the next round through a global coin that randomly generates the same “0” or “1” value for all processes at the specific round. This algorithm’s special design is that if a process finally decides to output “1”, then other processes may not decide in the same round. However, as the number of subsequent consensus rounds increases, the final decision will be made the same. The probability of outputting “1” converges to 1. Therefore, advancing consensus under asynchronous consensus does not have a coordinated action. Nevertheless, it advances the consensus separately according to the type of votes received. At the same time, the design of the algorithm must be proved to ensure the safety of the consensus result.
4. Details of ACQR
In this section, we give the details of the read optimization method for asynchronous consensus protocols, termed ACQR (Asynchronous Consensus Quorum Reads). The assumption of the ACQR algorithm is that client interactions with the replicated key-value database are characterized by read and write requests targeting single keys. Furthermore, we assume that asynchronous consensus is committed and completed in sequential slot order.
4.1. Algorithm Description
The pseudocode for ACQR is shown in Algorithms 1 and 2. The client broadcasts a request, represented as , to a quorum and waits for responses from all the members of the quorum. Depending on whether the request pertains to a read or write operation on some value, we employ two distinct types, namely and . Each request encapsulates the specifics of the request, encompassing request type along with the information of a single key. c designates the client ID, which serves as a means for the processes to identify the original sender of the request. This facilitates the delivery of results to the designated client. In the context of Crash Fault Tolerance (CFT) model, where processes do not engage in deceitful behavior, the client ID is both unique and accurate.
The processes deal with both read and write requests. Each key has an associated and in each process, both initialized to 0. These arrays help trace the orders each key has been accessed. The is the highest sequence number, indicating the slot in which requests are committed in the consensus phase. When a write request is received from a client, the asynchronous consensus, such as Rabia, produces a consensus instance to process it, updating the sequence number for the key that the request accessed. Upon receiving a read request from a client, the process waits until the meets the . This ensures that the client’s read request receives the latest committed data. Once the sequences match, the committed sequence and result are returned to the client.
Upon receiving the responses, the client retrieves the result
associated with the maximum
. By fetching the result with the highest sequence number, the client ensures it receives the most recent committed data modification.
| Algorithm 1 Read Optimization in Asynchronous Consensus for client C. |
- 1:
broadcast to quorum and wait for all replies - 2:
return whose is the maximum one
|
| Algorithm 2 Read Optimization in Asynchronous Consensus for process . |
- Init:
- 1:
upon receiving write request from client - 2:
AsyncConsensus() - 3:
upon receiving read request from client - 4:
- 5:
wait until - 6:
send to c - 7:
upon is committed in consensus instance - 8:
- 9:
function AsyncConsensus() - 10:
return a consensus slot assigned to - 11:
end function
|
4.2. ACQR vs. Rabia
This subsection delineates the distinctions between ACQR and the previously proposed asynchronous consensus algorithm Rabia [
25]. As mentioned in
Section 1, by default, consensus algorithms like Rabia order all the read and write operations through the same (normal) path to ensure linearizability [
27], guaranteeing that read operations initiated after new writes do not return stale results. In Rabia, both read and write operations need to be handled by consensus, coordinating all the processes to reach a consistent order for client requests. However, this can be unnecessary; reads of one key and writes to another do not conflict, allowing processes to satisfy linearizability without a consistent order for such requests.
The superiority of ACQR lies in its ability to ascertain the state of a key without subjecting read operations to the consensus process. Nevertheless, to uphold linearizability, ACQR mandates that read operations be informed of the most recent write operation’s placement within the latest consensus slot. ACQR tailors the interaction of read operations with the Rabia consensus, bypassing the multi-process coordination, while conventional write operations still need to go through the consensus as Rabia’s standard procedure.
Furthermore, we also compare the theoretical round complexity of both algorithms in
Section 4.4, aiming to elucidate the theoretical improvement of our algorithm more clearly.
4.3. Discussion on Correctness
In this section, we provide a concise discussion on the correctness of the ACQR.
Lemma 1. If is a read request for a specific key k initiated at time , and is a concurrent write request for the same key, assume no other unfinished write requests existing at the same moment, and is a prior write request completed at time (where ) and no other writes completed between and , then is guaranteed to read the value of either or .
Proof. For a single process handling , there are two possible cases: First, the commit conditions for are satisfied, hence the local variable corresponds to the consensus slot of . Second, the process is terminating the consensus for , and the has not yet advanced to the slot of . In either case, a quorum has that has reached the slot number of , as the termination of consensus for needs participation by a majority of processes. Consequently, can at least ensure that the largest from the quorum will not be smaller than any write requests completed prior to . As for reading the value written by the concurrent request , it depends on whether the quorum read contain the process of reaching consensus for . If a majority of processes have begun the consensus for , since their will be greater than the slot number of , the processing of will wait and return the result of upon the completion of consensus.
To summarize, will read the value of the most recently completed write request or the concurrent write request , instead of the stale value. □
Lemma 2. If and are read requests for the same key k, with completed at and starting at (satisfying ), then will not read a value older than .
Proof. According to Lemma 1, if have read the value of the most recently completed write , then at that moment, the of a quorum of processes has reached the slot number of , ensuring that subsequent read requests reading from a quorum will at least obtain the equal to or greater than the slot number of , thereby preventing from reading an older write than . Alternatively, if reads a value from a concurrent write request , Lemma 1 indicates that the completion of must occur after ’s commit. In this case, the largest of a majority of processes is at least align with ’s slot number. In this scenario, and get different read results, with accessing a value from a more recently ongoing write operation . □
Combining these two lemmas, we can simply demonstrate that the design of ACQR satisfies the linearizability of read and write operations.
4.4. Performance Analysis
We analyze the complexity of Rabia and our proposed ACQR solution to illustrate that ACQR can achieve better performance than Rabia for read requests.
Table 1 illustrates the comparison of the number of rounds for the two methods. A simple analysis is as follows: In Rabia, when a client sends a read or write request to any process in the cluster, the process that receives the request will begin the asynchronous consensus stage. As described in the work of Rabia [
25], the expected number of rounds for randomized consensus is five. In addition to two additional rounds of communication between the client and the process cluster, Rabia’s expected termination round for processing read and write requests is 7, regardless of the type of request.
As for ACQR, in the best case, if all the requests are read operations, then there is no need for a regular consensus stage between processes, so only two rounds of request-response message exchange stage between processes and clients are required.
5. Evaluation
5.1. Implementation
We implement and evaluate ACQR protocol in Golang 1.13 using the open-source framework of Rabia [
25], so that we can compare the performance of the two methods with minimal change to the original implementation.
In the implementation of many modules, we do not need to modify Rabia’s code. For instance, in the communication module, the interactions between clients and processes are all facilitated through established TCP connections. Variables such as flag fields (e.g., request IDs), are defined within the protocol buffers (proto) file. Our modifications are twofold: Firstly, for read operations, clients establish TCP connections with a majority of the processes and broadcast their requests. Secondly, for write operations, we retain Rabia’s implementation, where the client initially broadcasts to the designated process, which then proposes the request, triggering the consensus stage.
5.2. Experimental Setup
We evaluate our ACQR prototype on AWS EC2 platform with Rabia and ACQR clients and processes deployed over t3.2xlarge instances with 8 vCPUs, 32 GB RAM, and 5 Gbps Network burst bandwidth, running Ubuntu 20.04.3 LTS. The workload generated for our benchmark is a simple key-value store implementation containing 1000 distinct objects. Each operation either updates (writes) or reads a 10-byte value. These two kinds of operations are generated with equal probability (i.e., 50% reads and 50% writes).
In the evaluations of Rabia, each client sends its requests to a designated process (the one located at the same LAN for the geo-replication test), which then proposes on the certain consensus instances. For ACQR, the clients send their requests to the fixed quorum of processes.
We conduct each test over 1 min and compute the median and 99%ile client-perceived latency (ms) experienced during that interval. We also compute the throughput (req/sec) during each experiment.
5.3. Latency
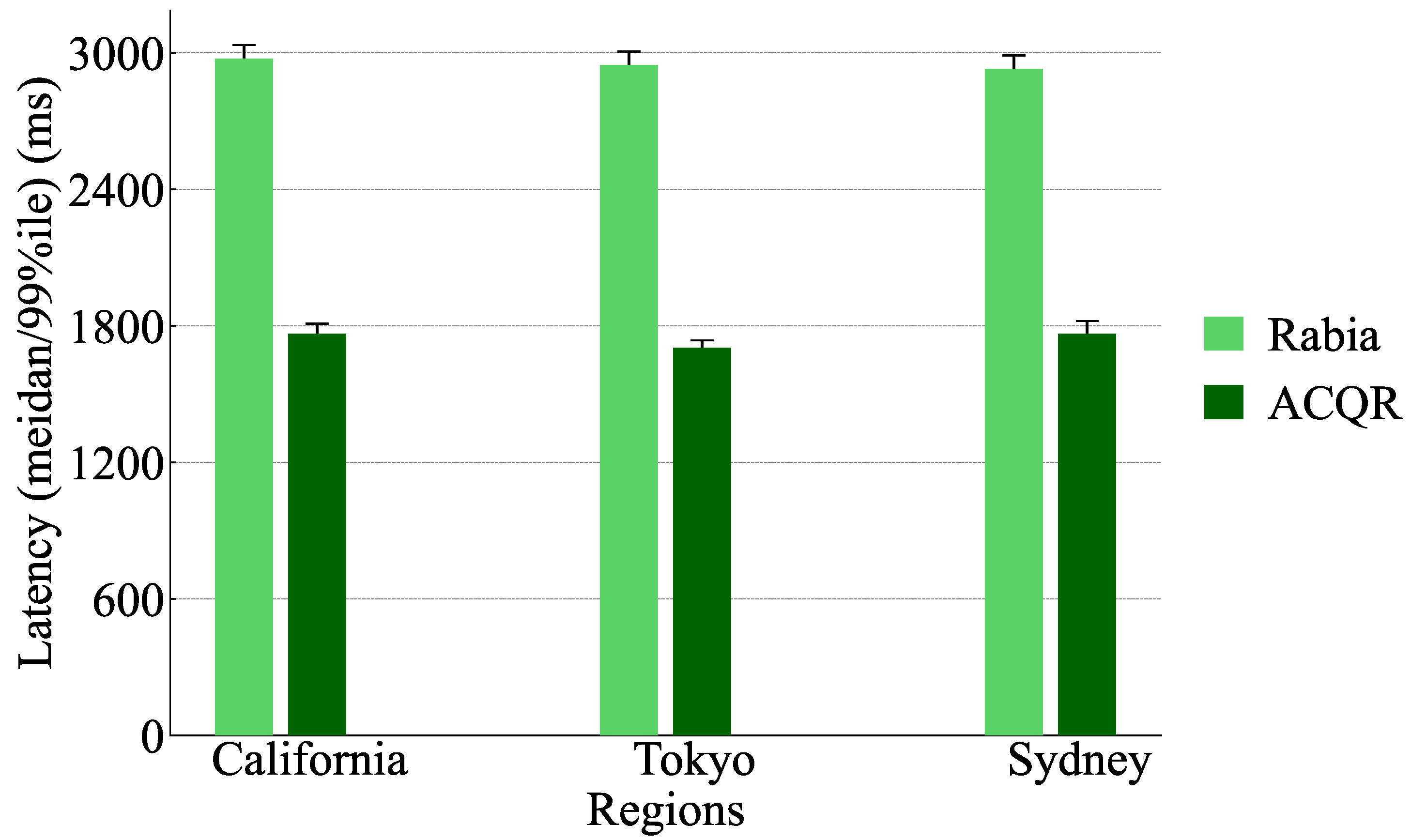
Initially, we assess both protocols in the context of wide-area replication. For a configuration of , the processes and clients are situated in California, Tokyo, and Sydney. Moreover, for the scenario, we incorporate locations in Virginia and Frankfurt. At each site, 10 clients are co-located with each process. Each client directs its requests to the process under the same LAN. We do not use pipelining mechanisms for wide-area network testing. We carry out closed-loop testing under the above-mentioned conditions.
As illustrated in
Figure 4 and
Figure 5, In both scenarios, read optimization can reduce the median latency to 60% of Rabia. Readers may notice that Rabia’s median latency has exceeded 1000 milliseconds, which is significantly high under wide-area network conditions. Here is a brief explanation: In Rabia, pipelining optimization is not enabled, meaning that at a certain time, only one request is processed at the same time, and the processing of other requests needs to wait for the consensus of the request to be completed. Under such conditions, since each write operation still needs to be encapsulated as a consensus instance, and the Rabia consensus within a wide-area network requires multiple rounds of communication, the latency to complete a write operation is about at the level of hundreds of milliseconds. Besides, the current write request also hinders the progress of subsequent write requests, as the server side can handle only one consensus instance at a time. Therefore, the calculation renders the median latency of Rabia in a wide-area network over 1000 milliseconds. Of course, it is also mentioned in the Rabia work that its design makes it more suitable for consensus within a single data center. Hence, such performance is understandable. What we primarily aim to reveal is that this kind of read optimization indeed significantly lowers the median latency within the wide-area network, and if the proportion of write operations continues decreasing, the performance improvement will become more noticeable.
5.4. Throughput
Next, we configure Rabia and ACQR to measure their peak throughput. We conduct two sets of experiments within a data center in Ohio, deploying configurations of three clients with three processes and five clients with five processes, respectively. For a fair comparison, we employ the same batching strategy for both protocols, that is, each client sends a batch of a fixed number of requests to the designated processes, and each process collects all the requests sent by clients until the batch is full or a timeout occurs, at which point the process proposes. We adopt variables that optimize Rabia’s performance: a client-side batch size of 1000 and a process-side size of 10. If the required batch size is unmet, the system utilizes a 2 ms timeout to batch the requests.
Figure 6 and
Figure 7 demonstrate the throughput and latency numbers by incrementing the number of concurrent closed-loop clients (3–650 for
, 5−1000 for
). It is evident that a substantial portion of read operations are expedited due to bypassing the consensus, resulting in overall lower latency and higher peak throughput for the system.
When , due to Rabia’s quadratic message complexity, Rabia’s throughput decreases, while ACQR, having a moderate proportion of read operations, is not severely impacted by the message complexity.
5.5. Varying Read–Write Ratio
We configure workloads with varying read–write ratios and deploy three clients and three processes within a data center in Ohio. For the peak throughput tests mentioned above, we examine the peak throughput of Rabia and the ACQR under these conditions by increasing the number of clients.
As shown in
Figure 8, we observe that as the proportion of read operations increased, the performance of ACQR improved, with a maximum enhancement of up to 1.75 times. We believe that the performance improvement will be more significant since, in a scenario of 100% read operations, a read can be completed in one Round Trip Time (1RTT) without going through any consensus instances. The potential reason might be that a client process needs to establish connections with multiple processes, thus consuming an amount of network resources. Additionally, upon reaching peak throughput, the CPU utilization on the process side exceeded 95%, indicating that the performance of the process side in handling network requests might be a limiting factor, preventing further elevation in the performance improvement.
5.6. Latency with High-Contention Workloads
To evaluate the impact of hot-spot data access on algorithm performance, an experimental setup with
is employed, entailing the deployment of three processes within a local area network in Ohio. Under equal read–write ratios, we vary the number of accessed keys, representing the objects of read–write operations. A smaller quantity of these keys indicates higher contention for hot-spot data. As
Figure 9 shows, Rabia’s performance is unaffected by hot-spot data contention. This is attributed to its design, where all the read–write accesses to hot-spot data undergo consensus to establish a consistent order before execution. In contrast, while ACQR optimizes read operations in high-contention scenarios, determining the order of read operations following write operations still necessitates execution of write operations, potentially prolonging waiting times. However, even in the worst-case scenario, ACQR outperforms Rabia. Moreover, in the settings of lower contention, ACQR consistently demonstrates superior performance.
6. Conclusions
We propose and implement a read optimization method, ACQR, for asynchronous consensus protocols. This method enhances the throughput and latency performance in both single-data and cross-data center scenarios. Through the evaluation, ACQR prove its ability to perform well under read-intensive workloads.
We also highlight the adaptability of ACQR under various workloads and scenarios, making it a universal solution when integrated with other asynchronous consensus-based protocols. Future work could focus on refining ACQR to explore its applicability in more diverse and demanding environments.
Additionally, the potential application of ACQR in real-world scenarios such as cloud computing and big data processing is promising. With the development of asynchronous consensus represented by Rabia, we hope that ACQR can be applied in the industry to improve the performance of asynchronous consensus.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}