
One-Stage Small Object Detection Using Super-Resolved Feature Map for Edge Devices

Abstract
:1. Introduction
- It introduces the integration of the FTT, originally designed for use in two-stage detectors, into a one-stage detector. This integration serves to improve the detection performance of small objects.
- It proposes an SR module that leverages three distinct input feature maps and synthesizes information twice, generating a super-resolved feature map tailored to the small-sized specific detection head. This approach enhances performance while upholding computational efficiency compared to the FTT module.
- It suggests a simplified version of the SR module that achieves similar performance as the FTT module while concurrently halving computing resources, making it similar to the vanilla one-stage detector.
- It shows that the proposed approach can be efficiently embedded into an edge device with an NPU for real-time processing.
2. Related Works
3. Proposed Method
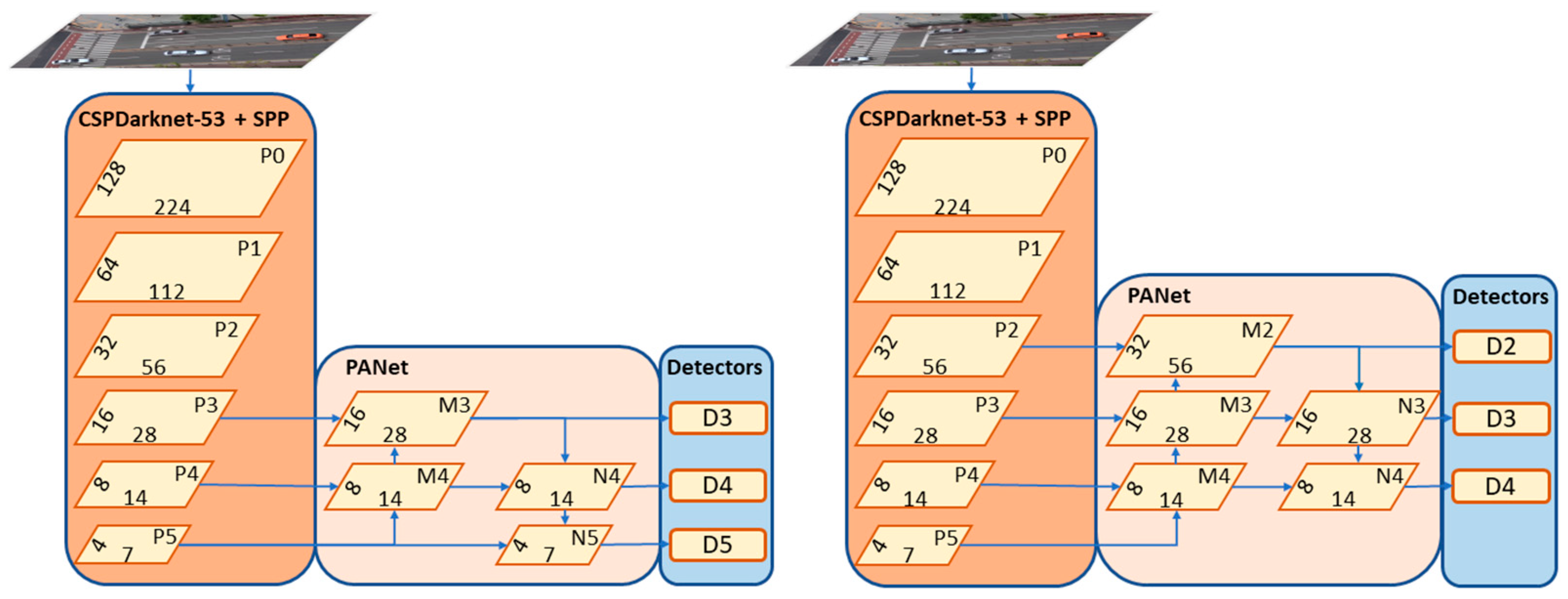
3.1. FTT Module in One-Stage Detector
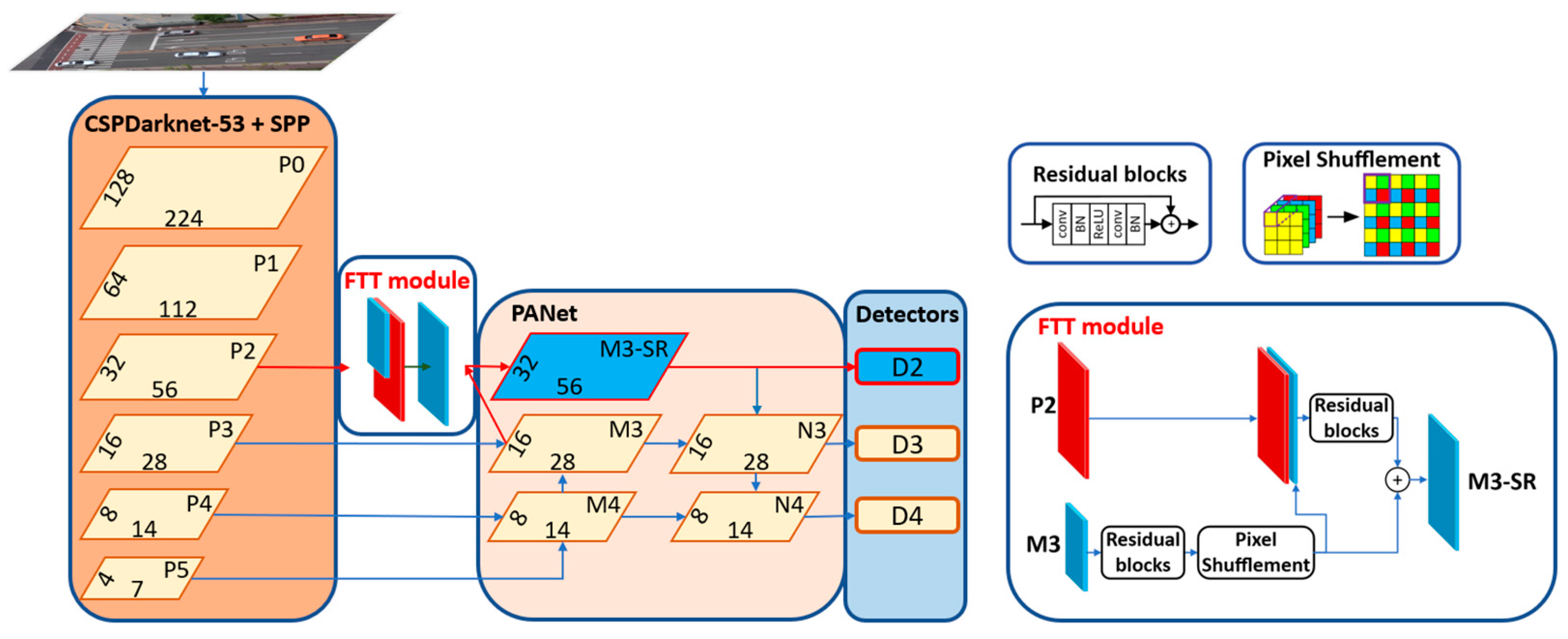
3.2. Proposed SR Module (SRm)
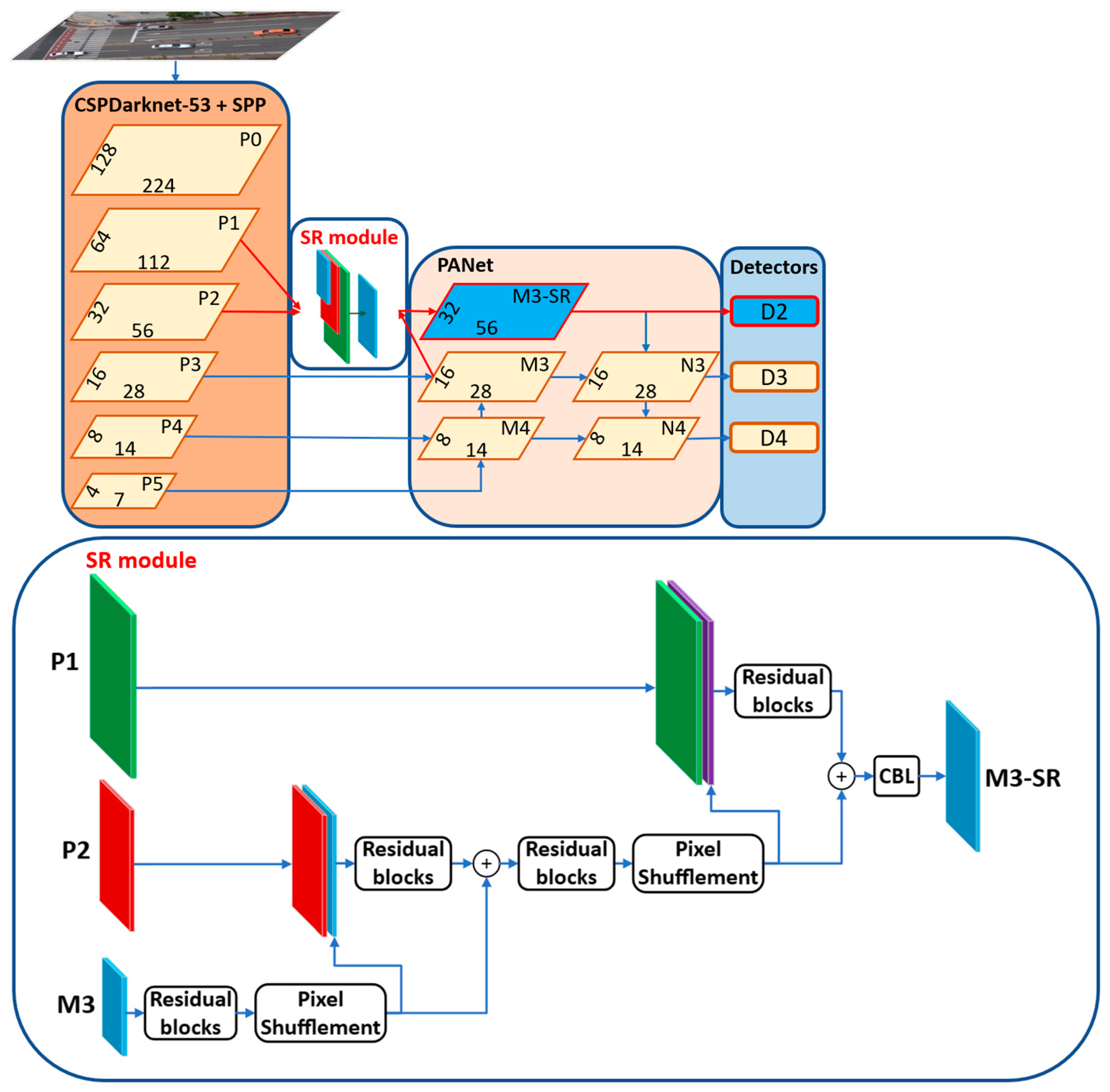
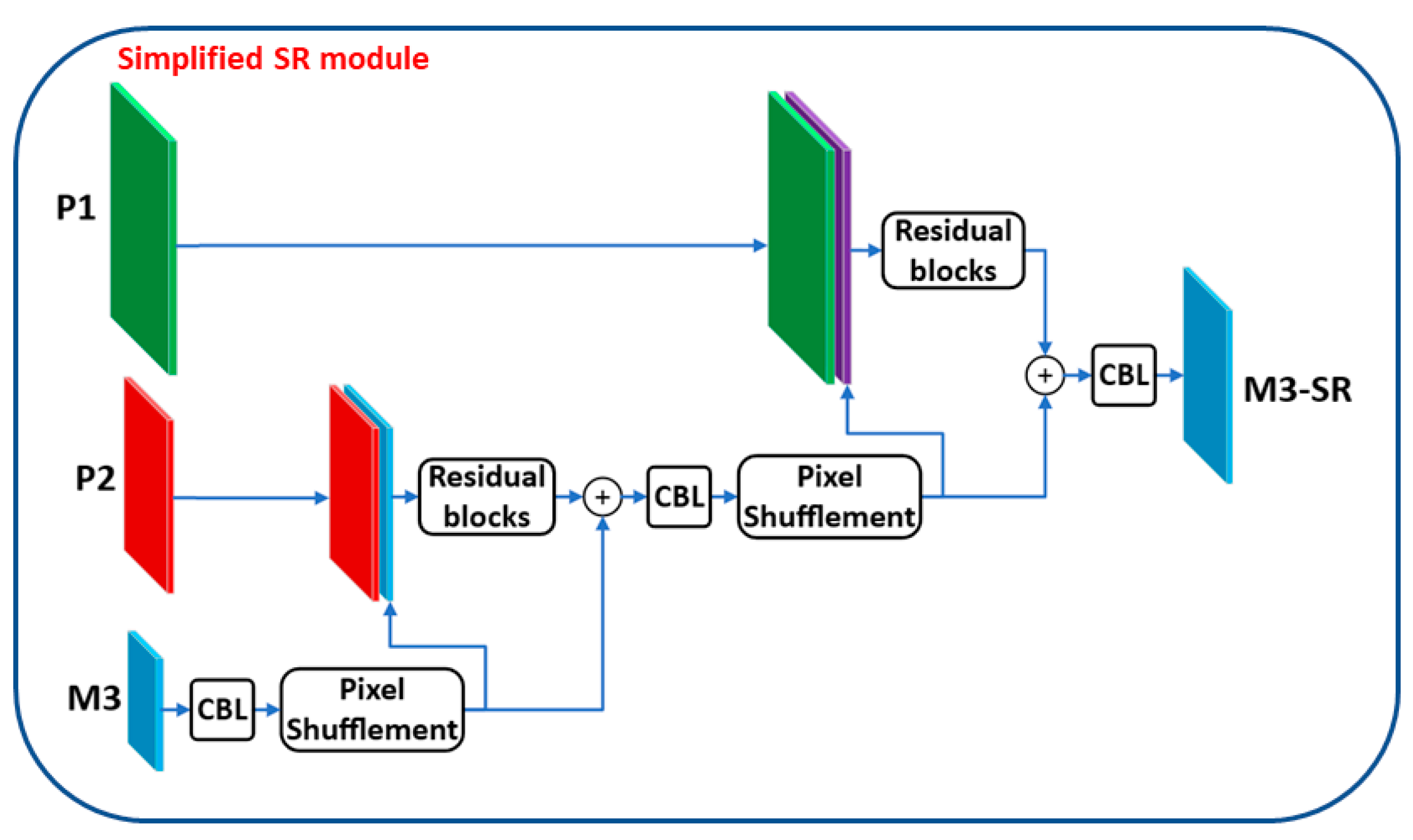
3.3. Simplification of SR Module (SSRm)
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Results and Comparisons
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE Inst. Electr. Electron. Eng. 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 28th Advances in Neural Information Processing Systems (NIPS’15), Montreal, QC, Canada, 7–10 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
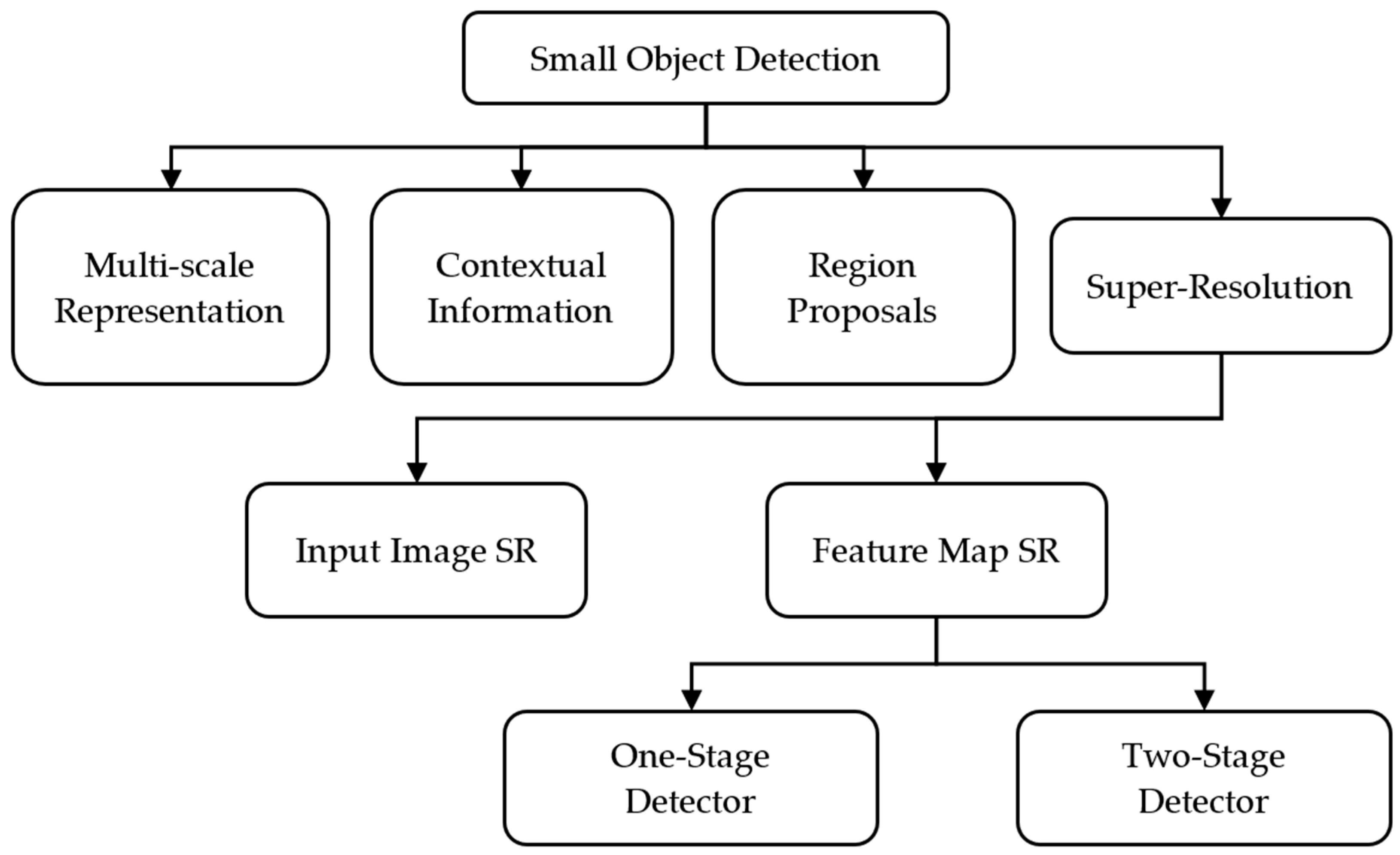
- Chen, G.; Wang, H.; Chen, K.; Li, Z.; Song, Z.; Liu, Y.; Chen, W.; Knoll, A. A Survey of the Four Pillars for Small Object Detection: Multiscale Representation, Contextual Information, Super-Resolution, and Region Proposal. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 936–953. [Google Scholar] [CrossRef]
- Tong, K.; Wu, Y. Deep learning-based detection from the perspective of small or tiny objects: A survey. Image Vis. Comput. 2022, 123, 104471. [Google Scholar] [CrossRef]
- Cheng, G.; Yuan, X.; Yao, X.; Yan, K.; Zeng, Q.; Xie, X.; Han, J. Towards Large-Scale Small Object Detection: Survey and Benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13467–13488. [Google Scholar] [CrossRef] [PubMed]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Task-Driven Super Resolution: Object Detection in Low-Resolution Images. In Proceedings of the Neural Information Processing: 28th International Conference (ICONIP 2021), Sanur, Indonesia, 8–12 December 2021; pp. 387–395. [Google Scholar]
- Pang, Y.; Cao, J.; Wang, J.; Han, J. JCS-Net: Joint Classification and Super-Resolution Network for Small-Scale Pedestrian Detection in Surveillance Images. IEEE Trans. Inf. Forensics Secur. 2019, 14, 3322–3331. [Google Scholar] [CrossRef]
- Wang, Z.-Z.; Xie, K.; Zhang, X.-Y.; Chen, H.-Q.; Wen, C.; He, J.-B. Small-Object Detection Based on YOLO and Dense Block via Image Super-Resolution. IEEE Access 2021, 9, 56416–56429. [Google Scholar] [CrossRef]
- Zhao, X.; Li, W.; Zhang, Y.; Feng, Z. Residual Super-Resolution Single Shot Network for Low-Resolution Object Detection. IEEE Access 2018, 6, 47780–47793. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 27th Advances in Neural Information Processing Systems (NIPS’14), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Mostofa, M.; Ferdous, S.N.; Riggan, B.S.; Nasrabadi, N.M. Joint-SRVDNet: Joint Super Resolution and Vehicle Detection Network. IEEE Access 2020, 8, 82306–82319. [Google Scholar] [CrossRef]
- Courtrai, L.; Pham, M.-T.; Lefèvre, S. Small Object Detection in Remote Sensing Images Based on Super-Resolution with Auxiliary Generative Adversarial Networks. Remote Sens. 2022, 12, 3152. [Google Scholar] [CrossRef]
- Jin, Y.; Zhang, Y.; Cen, Y.; Li, Y.; Mladenovic, V.; Voronin, V. Pedestrian detection with super-resolution reconstruction for low-quality image. Pattern Recognit. 2021, 115, 107846. [Google Scholar] [CrossRef]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 206–221. [Google Scholar]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. Finding Tiny Faces in the Wild with Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 21–30. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual Generative Adversarial Networks for Small Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1222–1230. [Google Scholar]
- Noh, J.; Bae, W.; Lee, W.; Seo, J.; Kim, G. Better to Follow, Follow to Be Better: Towards Precise Supervision of Feature Super-Resolution for Small Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9725–9734. [Google Scholar]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y.; Jiang, Y. Extended Feature Pyramid Network for Small Object Detection. IEEE Trans. Multimed. 2021, 24, 1968–1979. [Google Scholar] [CrossRef]
- Liu, Z.; Li, D.; Ge, S.S.; Tian, F. Small traffic sign detection from large image. Appl. Intell. 2019, 50, 1–13. [Google Scholar] [CrossRef]
- Cui, L.; Ma, R.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Xu, M. MDSSD: Multi-scale Deconvolutional Single Shot Detector for Small Objects. arXiv 2018, arXiv:1805.07009. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Chen, C.; Ling, Q. Adaptive Convolution for Object Detection. IEEE Trans. Multimed. 2019, 21, 3205–3217. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the 29th Advances in Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Wilms, C.; Frintrop, S. AttentionMask: Attentive, Efficient Object Proposal Generation Focusing on Small Objects. In Proceedings of the Computer Vision—ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers. Springer International Publishing: Cham, Switzerland, 2019; pp. 678–694. [Google Scholar]
- Chen, Z.; Wu, K.; Li, Y.; Wang, M.; Li, W. SSD-MSN: An Improved Multi-Scale Object Detection Network Based on SSD. IEEE Access 2019, 7, 80622–80632. [Google Scholar] [CrossRef]
- Hu, P.; Ramanan, D. Finding Tiny Faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 951–959. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Min, K.; Lee, G.-H.; Lee, S.-W. Attentional feature pyramid network for small object detection. Neural Netw. 2022, 155, 439–450. [Google Scholar] [CrossRef]
- Bosquet, B.; Mucientes, M.; Brea, V.M. STDnet: Exploiting high resolution feature maps for small object detection. Eng. Appl. Artif. Intell. 2020, 91, 103615. [Google Scholar] [CrossRef]
- YOLOv4. Available online: https://docs.nvidia.com/tao/tao-toolkit/text/object_detection/yolo_v4.html (accessed on 6 March 2023).
- Getting Started with YOLO V4. Available online: https://www.mathworks.com/help/vision/ug/getting-started-with-yolo-v4.html (accessed on 6 March 2023).
- Choi, K.; Wi, S.M.; Jung, H.G.; Suhr, J.K. Simplification of Deep Neural Network-Based Object Detector for Real-Time Edge Computing. Sensors 2023, 23, 3777. [Google Scholar] [CrossRef] [PubMed]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, J.; Yang, W.; Guo, H.; Zhang, R.; Xia, G.-S. Tiny Object Detection in Aerial Images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3791–3798. [Google Scholar]
- YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 2 January 2024).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Self-Built | VisDrone2019 | |
|---|---|---|---|
| Number of images | Training set | 21,494 | 6471 |
| Test set | 3229 | 1610 | |
| Test set | Inference resolution (pixels) | ||
| Total objects | 15,794 | 75,102 | |
| Very tiny objects | 9086 (57.53%) | 36,161 (48.15%) | |
| Tiny objects | 4054 (25.67%) | 20,321 (27.06%) | |
| Small objects | 2209 (13.99%) | 9386 (12.50%) | |
| Model | Metrics | |||||||
|---|---|---|---|---|---|---|---|---|
| AP50 | AP | AP50VT | APVT | AP50T | APT | AP50S | APS | |
| Vanilla YOLOv4 | 67.71 | 38.62 | 48.18 | 19.36 | 88.59 | 52.78 | 94.41 | 70.05 |
| YOLOv8-L | 67.34 | 41.84 | 45.98 | 19.71 | 88.75 | 54.16 | 96.88 | 76.16 |
| SRGAN + YOLOv4 | 79.17 | 48.05 | 69.20 | 33.14 | 93.35 | 61.71 | 96.56 | 75.53 |
| YOLOv4-HR | 72.66 | 41.52 | 60.25 | 25.76 | 89.08 | 55.16 | 92.96 | 68.26 |
| YOLOv4-FTT | 77.31 | 44.15 | 66.51 | 28.43 | 92.37 | 57.28 | 93.78 | 71.37 |
| YOLOv4-SRm | 79.09 | 47.42 | 69.75 | 32.60 | 92.14 | 60.20 | 95.46 | 72.06 |
| YOLOv4-SSRm | 77.20 | 44.03 | 65.86 | 28.76 | 91.84 | 56.43 | 96.60 | 71.69 |
| Model | Metrics | |||||||
|---|---|---|---|---|---|---|---|---|
| AP50 | AP | AP50VT | APVT | AP50T | APT | AP50S | APS | |
| Vanilla YOLOv4 | 15.98 | 7.23 | 3.14 | 0.95 | 17.77 | 6.56 | 34.46 | 15.15 |
| YOLOv8-L | 19.08 | 9.59 | 4.36 | 1.28 | 22.22 | 10.01 | 42.11 | 20.51 |
| SRGAN + YOLOv4 | 26.79 | 13.28 | 8.97 | 3.04 | 32.88 | 14.68 | 48.48 | 25.56 |
| YOLOv4-HR | 21.02 | 9.66 | 5.86 | 1.77 | 25.20 | 9.80 | 40.52 | 19.38 |
| YOLOv4-FTT | 22.78 | 11.02 | 7.19 | 2.42 | 29.19 | 12.15 | 43.06 | 21.64 |
| YOLOv4-SRm | 24.86 | 12.28 | 8.87 | 3.04 | 30.65 | 13.46 | 43.53 | 23.15 |
| YOLOv4-SSRm | 22.27 | 10.98 | 7.60 | 2.48 | 27.31 | 11.57 | 39.66 | 21.13 |
| Model | Params | Weight | Self-Built Dataset | VisDrone2019 Dataset | ||||
|---|---|---|---|---|---|---|---|---|
| FLOPs | IT | FPS | FLOPs | IT | FPS | |||
| Vanilla YOLOv4 | 64.4 | 244 | 9.99 | 8.80 | 114 | 48.16 | 10.38 | 96 |
| YOLOv8-L | 43.6 | 165 | 11.56 | 9.43 | 106 | 55.78 | 10.05 | 99 |
| SRGAN + YOLOv4 | 65.8 | 249 | 118.76 | 12.61 | 79 | 572.60 | 17.03 | 59 |
| YOLOv4-HR | 48.3 | 183 | 10.75 | 8.95 | 112 | 51.82 | 10.83 | 92 |
| YOLOv4-FTT | 55.0 | 208 | 20.29 | 9.16 | 109 | 97.83 | 11.14 | 90 |
| YOLOv4-SRm | 49.3 | 187 | 19.47 | 9.10 | 110 | 93.88 | 10.97 | 91 |
| YOLOv4-SSRm | 45.1 | 171 | 10.22 | 8.66 | 115 | 49.25 | 10.60 | 94 |
| Model | Inference Time (ms) | FPS |
|---|---|---|
| Vanilla YOLOv4 | 31.17 | 32 |
| YOLOv8-L | 29.90 | 33 |
| YOLOv4-HR | 29.40 | 34 |
| YOLOv4-FTT | 40.02 | 25 |
| YOLOv4-SRm | 40.79 | 25 |
| YOLOv4-SSRm | 27.51 | 36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huynh, X.N.; Jung, G.B.; Suhr, J.K. One-Stage Small Object Detection Using Super-Resolved Feature Map for Edge Devices. Electronics 2024, 13, 409. https://doi.org/10.3390/electronics13020409
Huynh XN, Jung GB, Suhr JK. One-Stage Small Object Detection Using Super-Resolved Feature Map for Edge Devices. Electronics. 2024; 13(2):409. https://doi.org/10.3390/electronics13020409
Chicago/Turabian StyleHuynh, Xuan Nghia, Gu Beom Jung, and Jae Kyu Suhr. 2024. "One-Stage Small Object Detection Using Super-Resolved Feature Map for Edge Devices" Electronics 13, no. 2: 409. https://doi.org/10.3390/electronics13020409