
A Code Reviewer Recommendation Approach Based on Attentive Neighbor Embedding Propagation

Abstract
:1. Introduction
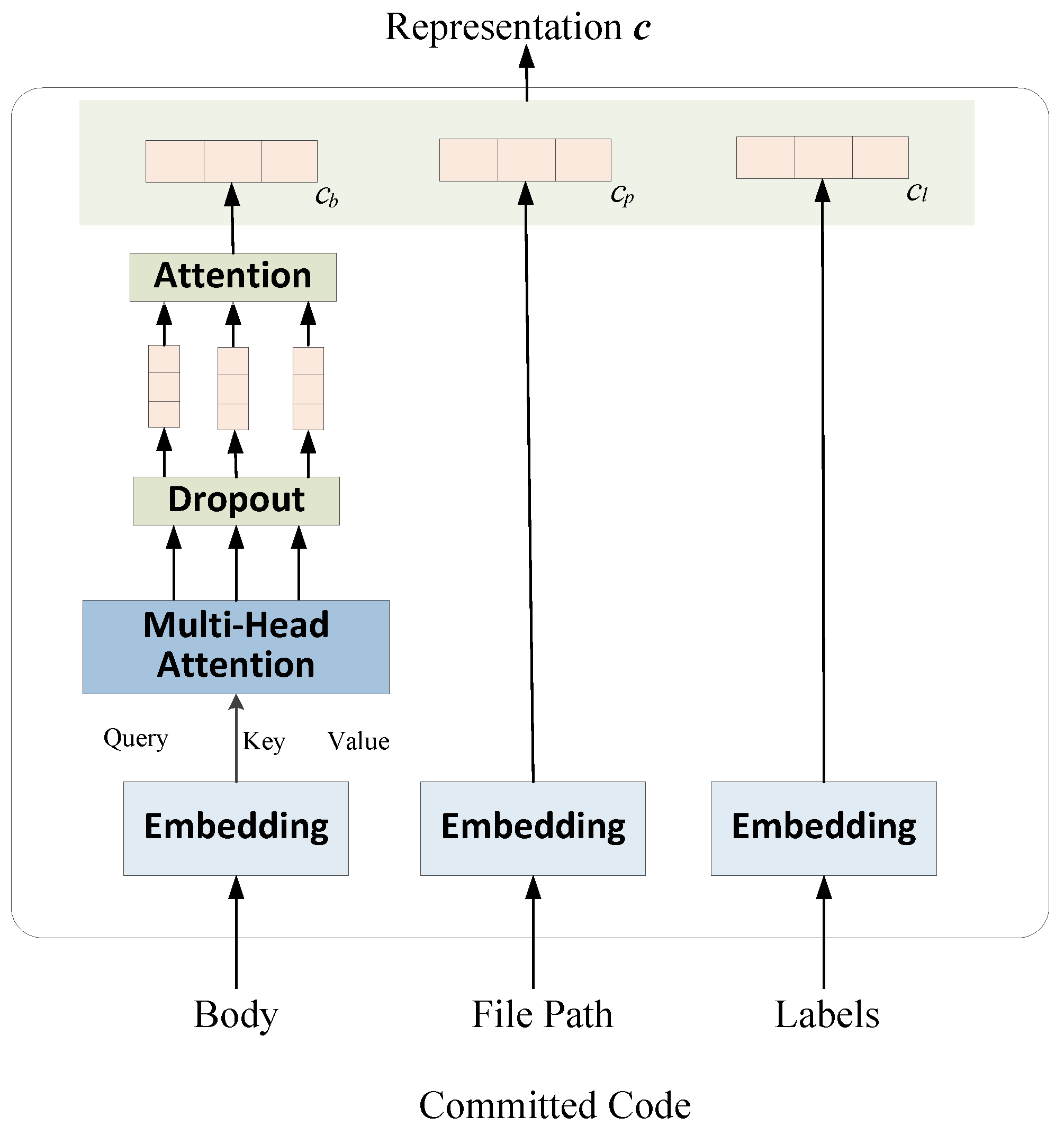
- First, we propose to leverage the transformer to learn the text semantics of the code body and then generate the code semantic representations. In particular, to distill more useful information, we utilize the multi-head attention mechanism to generate the weight of each word. Moreover, we also consider the file paths and label embeddings of code files, which contain important information such as business categories and technical categories.
- Second, to alleviate the data-sparsity problem and enhance the representations of the code and reviewers, we propose to explore the high-order embedding propagation and incorporate their neighbors’ representations based on graph attentive network. Moreover, to alleviate the noise problem, we leverage the attention mechanism, which calculates the weights of different nodes and propagation layers in the code-reviewer neighbor network.
- Third, to evaluate the effectiveness of ANEP, we conduct extensive experiments on four real-world datasets. The experimental results show that ANEP outperforms other state-of-the-art approaches effectively. To the best of our knowledge, ANEP is the first attempt at incorporating the text semantics of code into graph embedding learning and propagation to address the code reviewer recommendations.
2. Related Work
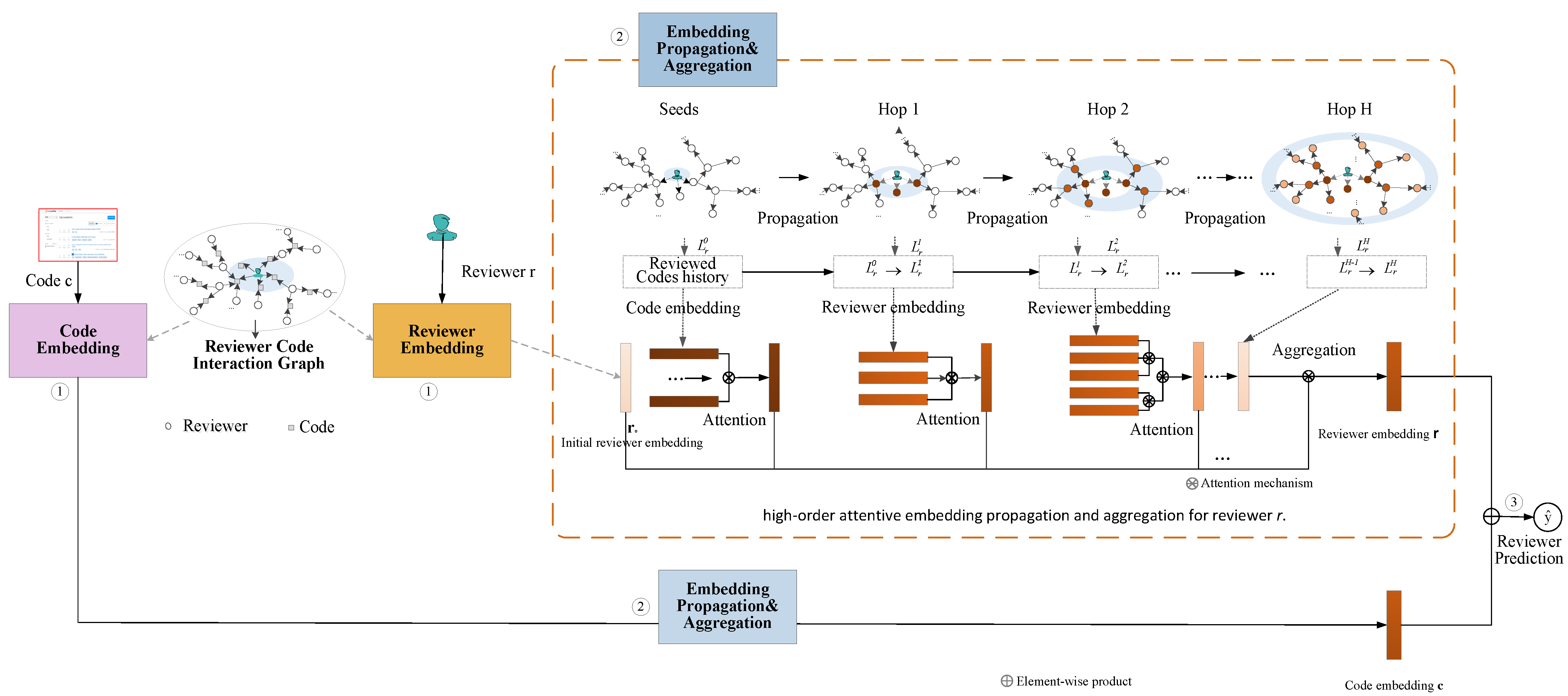
3. Methodology
3.1. Framework
3.2. Representations of Code and Reviewer
3.2.1. Code Embedding
3.2.2. Reviewer Embedding
3.3. High-Order Embedding Propagation
3.4. Code Reviewer Recommendation
4. Experiments
- RQ1: How does the proposed ANEP perform compared with the existing reviewer recommendation approaches?
- RQ2: How does the embedding propagation layer effect ANEP?
4.1. Datasets
4.2. Baseline Methods
- RevFinder [9]: This approach proposes to compute the similarity between code file paths that have been reviewed by the target code reviewer and the latest submitted code file paths. They consider that if a code reviewer has reviewed some code in a file path, the code located in similar paths is likely to be reviewed by the same reviewer.
- EARec [16]: This approach not only considers developer expertise, but also developer authority. They first construct a graph of the latest submitted code file and possible reviewers, and then calculate the text similarity of the latest submitted code file and social relations of reviewers to find suitable reviewers.
- MulTO [38]: This multi-objective approach proposes to not only evaluate reviewer expertise, but also consider estimating reviewer availability based on workload. They consider the review workload is also an influence important factor for a reviewer to decide if they will accept a review task.
4.3. Parameter Settings
4.4. Evaluation Metrics
4.5. Statistical Test Method
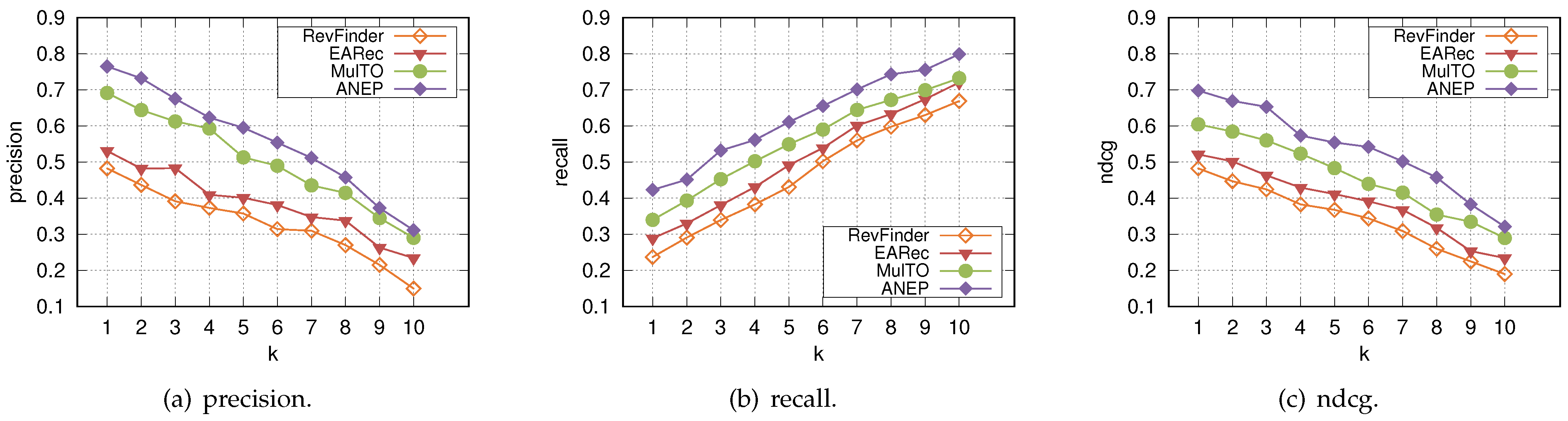
4.6. Performance Comparison (RQ1)
4.7. Effect of Embedding Propagation Layer Numbers (RQ2)
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tufan, R.; Pascarella, L.; Tufanoy, M.; Poshyvanykz, D.; Bavota, G. Towards Automating Code Review Activities. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), Madrid, Spain, 22–30 May 2021; pp. 163–174. [Google Scholar]
- Morales, R.; McIntosh, S.; Khomh, F. Do code review practices impact design quality? A case study of the qt, vtk, and itk projects. In Proceedings of the 2015 IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Montreal, QC, Canada, 2–6 March 2015; pp. 171–180. [Google Scholar]
- Bavota, G.; Russo, B. Four eyes are better than two: On the impact of code reviews on software quality. In Proceedings of the 2015 IEEE International Conference on Software Maintenance and Evolution (ICSME), Bremen, Germany, 29 September–1 October 2015; pp. 81–90. [Google Scholar]
- McIntosh, S.; Kamei, Y.; Adams, B.; Hassan, A.E. An empirical study of the impact of modern code review practices on software quality. Empir. Softw. Eng. 2016, 21, 2146–2189. [Google Scholar] [CrossRef]
- Thongtanunam, P.; McIntosh, S.; Hassan, A.E.; Iida, H. Investigating code review practices in defective files: An empirical study of the qt system. In Proceedings of the 2015 IEEE/ACM 12th Working Conference on Mining Software Repositories, Florence, Italy, 16–17 May 2015; pp. 168–179. [Google Scholar]
- Alami, A.; Cohn, M.L.; Wasowski, A. Why does code review work for open source software communities? In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 1073–1083. [Google Scholar]
- Çetin, H.A.; Doğan, E.; Tüzün, E. A review of code reviewer recommendation studies: Challenges and future directions. Sci. Comput. Program. 2021, 208, 102652. [Google Scholar] [CrossRef]
- MacLeod, L.; Greiler, M.; Storey, M.A.; Bird, C.; Czerwonka, J. Code reviewing in the trenches: Challenges and best practices. IEEE Softw. 2017, 35, 34–42. [Google Scholar] [CrossRef]
- Thongtanunam, P.; Tantithamthavorn, C.; Kula, R.G.; Yoshida, N.; Iida, H.; Matsumoto, K.I. Who should review my code? A file location-based code-reviewer recommendation approach for modern code review. In Proceedings of the 2015 IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Montreal, QC, Canada, 2–6 March 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 141–150. [Google Scholar]
- Bacchelli, A.; Bird, C. Expectations, outcomes, and challenges of modern code review. In Proceedings of the 2013 35th International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 2–6 March 2013; pp. 712–721. [Google Scholar]
- Kovalenko, V.; Tintarev, N.; Pasynkov, E.; Bird, C.; Bacchelli, A. Does reviewer recommendation help developers? IEEE Trans. Softw. Eng. 2018, 46, 710–731. [Google Scholar] [CrossRef]
- Rigby, P.C.; Bird, C. Convergent contemporary software peer review practices. In Proceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering, Saint Petersburg, Russia, 18–26 August 2013; pp. 202–212. [Google Scholar]
- Sadowski, C.; Söderberg, E.; Church, L.; Sipko, M.; Bacchelli, A. Modern code review: A case study at google. In Proceedings of the 40th International Conference on Software Engineering: Software Engineering in Practice, Gothenburg, Sweden, 27 May–3 June 2018; pp. 181–190. [Google Scholar]
- Xia, X.; Lo, D.; Wang, X.; Yang, X. Who should review this change? Putting text and file location analyses together for more accurate recommendations. In Proceedings of the 2015 IEEE International Conference on Software Maintenance and Evolution (ICSME), Bremen, Germany, 29 September–1 October 2015; pp. 261–270. [Google Scholar]
- Rahman, M.M.; Roy, C.K.; Collins, J.A. Correct: Code reviewer recommendation in github based on cross-project and technology experience. In Proceedings of the 38th International Conference on Software Engineering Companion, Austin, TX, USA, 14–22 May 2016; pp. 222–231. [Google Scholar]
- Ying, H.; Chen, L.; Liang, T.; Wu, J. Earec: Leveraging expertise and authority for pull-request reviewer recommendation in github. In Proceedings of the 2016 IEEE/ACM 3rd International Workshop on CrowdSourcing in Software Engineering (CSI-SE), Austin, TX, USA, 16 May 2016; pp. 29–35. [Google Scholar]
- Xie, X.; Yang, X.; Wang, B.; He, Q. DevRec: Multi-Relationship Embedded Software Developer Recommendation. IEEE Trans. Softw. Eng. (TSE) 2021, 48, 4357–4379. [Google Scholar] [CrossRef]
- Wang, Z.; Sun, H.; Fu, Y.; Ye, L. Recommending crowdsourced software developers in consideration of skill improvement. In Proceedings of the IEEE/ACM International Conference on Automated Software Engineering (ASE), Champaign, IL, USA, 30 October–3 November 2017; pp. 717–722. [Google Scholar]
- Bosu, A.; Greiler, M.; Bird, C. Characteristics of useful code reviews: An empirical study at microsoft. In Proceedings of the 2015 IEEE/ACM 12th Working Conference on Mining Software Repositories, Florence, Italy, 16–17 May 2015; pp. 146–156. [Google Scholar]
- Gousios, G.; Pinzger, M.; Deursen, A.v. An exploratory study of the pull-based software development model. In Proceedings of the IEEE/ACM 36th International Conference on Software Engineering (ICSE), Hyderabad, India, 31 May–7 June 2014; pp. 345–355. [Google Scholar]
- Hannebauer, C.; Patalas, M.; Stünkel, S.; Gruhn, V. Automatically recommending code reviewers based on their expertise: An empirical comparison. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering (ASE), Singapore, 3–7 September 2016; pp. 99–110. [Google Scholar]
- Amreen, S.; Karnauch, A.; Mockus, A. Developer Reputation Estimator (DRE). In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019; pp. 1082–1085. [Google Scholar]
- Kim, J.; Lee, E. Understanding review expertise of developers: A reviewer recommendation approach based on latent Dirichlet allocation. Symmetry 2018, 10, 114. [Google Scholar] [CrossRef]
- Asthana, S.; Kumar, R.; Bhagwan, R.; Bird, C.; Bansal, C.; Maddila, C.; Mehta, S.; Ashok, B. WhoDo: Automating reviewer suggestions at scale. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), Tallinn, Estonia, 26–30 August 2019; pp. 937–945. [Google Scholar]
- Yu, Y.; Wang, H.; Yin, G.; Wang, T. Reviewer recommendation for pull-requests in github: What can we learn from code review and bug assignment? Inf. Softw. Technol. 2016, 74, 204–218. [Google Scholar] [CrossRef]
- Xia, Z.; Sun, H.; Jiang, J.; Wang, X.; Liu, X. A hybrid approach to code reviewer recommendation with collaborative filtering. In Proceedings of the IEEE International Workshop on Software Mining (SoftwareMining), Champaign, IL, USA, 3 November 2017; pp. 24–31. [Google Scholar]
- Hirao, T.; McIntosh, S.; Ihara, A.; Matsumoto, K. The review linkage graph for code review analytics: A recovery approach and empirical study. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), Tallinn, Estonia, 26–30 August 2019; pp. 578–589. [Google Scholar]
- Mirsaeedi, E.; Rigby, P.C. Mitigating turnover with code review recommendation: Balancing expertise, workload, and knowledge distribution. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, Seoul, Republic of Korea, 5–11 October 2020; pp. 1183–1195. [Google Scholar]
- Zanjani, M.B.; Kagdi, H.; Bird, C. Automatically Recommending Peer Reviewers in Modern Code Review. IEEE Trans. Softw. Eng. (TSE) 2016, 42, 530–543. [Google Scholar] [CrossRef]
- Lipcak, J.; Rossi, B. A large-scale study on source code reviewer recommendation. In Proceedings of the 2018 44th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Prague, Czech Republic, 29–31 August 2018; pp. 378–387. [Google Scholar]
- Ge, S.; Wu, C.; Wu, F.; Qi, T.; Huang, Y. Graph enhanced representation learning for news recommendation. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2863–2869. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Wu, S.; Sun, F.; Zhang, W.; Xie, X.; Cui, B. Graph neural networks in recommender systems: A survey. ACM Comput. Surv. (CSUR) 2020, 55, 1–37. [Google Scholar] [CrossRef]
- Ouni, A.; Kula, R.G.; Inoue, K. Search-based peer reviewers recommendation in modern code review. In Proceedings of the 2016 IEEE International Conference on Software Maintenance and Evolution (ICSME), Raleigh, NC, USA, 2–7 October 2016; pp. 367–377. [Google Scholar]
- Ruangwan, S.; Thongtanunam, P.; Ihara, A.; Matsumoto, K. The impact of human factors on the participation decision of reviewers in modern code review. Empir. Softw. Eng. 2019, 24, 973–1016. [Google Scholar] [CrossRef]
- Hamasaki, K.; Kula, R.G.; Yoshida, N.; Cruz, A.C.; Fujiwara, K.; Iida, H. Who does what during a code review? Datasets of oss peer review repositories. In Proceedings of the 2013 10th Working Conference on Mining Software Repositories (MSR), San Francisco, CA, USA, 18–19 May 2013; pp. 49–52. [Google Scholar]
- Yang, X.; Kula, R.G.; Yoshida, N.; Iida, H. Mining the modern code review repositories: A dataset of people, process and product. In Proceedings of the 13th International Conference on Mining Software Repositories, Austin, TX, USA, 14–22 May 2016; pp. 460–463. [Google Scholar]
- Rebai, S.; Amich, A.; Molaei, S.; Kessentini, M.; Kazman, R. Multi-objective code reviewer recommendations: Balancing expertise, availability and collaborations. Autom. Softw. Eng. 2020, 27, 301–328. [Google Scholar] [CrossRef]
- Tantithamthavorn, C.; McIntosh, S.; Hassan, A.E.; Matsumoto, K. The impact of automated parameter optimization on defect prediction models. IEEE Trans. Softw. Eng. 2018, 45, 683–711. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Arcuri, A.; Briand, L. A practical guide for using statistical tests to assess randomized algorithms in software engineering. In Proceedings of the 2011 33rd International Conference on Software Engineering (ICSE), Honolulu, HI, USA, 21–28 May 2011; pp. 1–10. [Google Scholar]
- He, X.; Chen, T.; Kan, M.Y.; Chen, X. Trirank: Review-aware explainable recommendation by modeling aspects. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 1661–1670. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| r | reviewer |
| reviewer r’s 1-hop neighbor | |
| , | reviewer embedding propagation set |
| , | reviewer embedding |
| 1-hop neighbors of reviewer r | |
| 1-hop neighbors of reviewer | |
| information encoding function | |
| embedding propagated from to r | |
| embedding propagated from r’s H-hop neighbors | |
| refined representation of reviewer r from r’s 1-hop neighborhood | |
| refined representation of reviewer r from r’s H-hop neighborhood | |
| , | the trainable weight matrices |
| , | the trainable transformation matrices |
| the representations of r after H layer propagation | |
| the representations of the code c after H layer propagation | |
| initial representation of r | |
| initial representation of code c | |
| refined representation of code c from c’s H-hop neighbors | |
| reviewer’s preference towards the target code | |
| the representation of the i-th word with the k-th attention head | |
| the importance of the i-th and j-th words | |
| projection matrices | |
| attention weight of the i-th code body word | |
| , , | the representation of code body, path and label |
| attention weight of the i-th | |
| reviewer representation from code review history | |
| reviewer label representation | |
| the trainable parameters of attention weight |
| Evaluation Metrics | RevFinder | EARec | MulTO | ANEP | Imprv.↑ |
|---|---|---|---|---|---|
| precision | 0.3300 | 0.3872 | 0.5029 | 0.5598 | 10.17% |
| recall | 0.4642 | 0.5091 | 0.5576 | 0.62336 | 10.55% |
| ndcg | 0.3432 | 0.3892 | 0.4589 | 0.53539 | 14.27% |
| ANEP | Precision | Recall | ndcg | |||
|---|---|---|---|---|---|---|
| vs. | Mediam | p-Value(d) | Mediam | p-Value(d) | Mediam | p-Value(d) |
| RevFinder | 0.3359 | <0.05(L) | 0.4668 | <0.05(L) | 0.3659 | <0.05(L) |
| EARec | 0.3914 | <0.05(L) | 0.5153 | <0.05(L) | 0.4014 | <0.05(L) |
| MulTO | 0.5014 | <0.05(L) | 0.5699 | <0.05(L) | 0.4614 | <0.05(L) |
| ANEP | 0.5746 | - | 0.6333 | - | 0.5482 | - |
| Evaluation Method | ANEP-1 | ANEP-2 | ANEP-3 | ANEP-4 |
|---|---|---|---|---|
| precision | 0.4381 | 0.4965 | 0.5842 | 0.5882 |
| recall | 0.4423 | 0.5329 | 0.6421 | 0.6485 |
| ndcg | 0.4047 | 0.4768 | 0.5545 | 0.5378 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Deng, A.; Xie, Q.; Yue, G. A Code Reviewer Recommendation Approach Based on Attentive Neighbor Embedding Propagation. Electronics 2023, 12, 2113. https://doi.org/10.3390/electronics12092113
Liu J, Deng A, Xie Q, Yue G. A Code Reviewer Recommendation Approach Based on Attentive Neighbor Embedding Propagation. Electronics. 2023; 12(9):2113. https://doi.org/10.3390/electronics12092113
Chicago/Turabian StyleLiu, Jiahui, Ansheng Deng, Qiuju Xie, and Guanli Yue. 2023. "A Code Reviewer Recommendation Approach Based on Attentive Neighbor Embedding Propagation" Electronics 12, no. 9: 2113. https://doi.org/10.3390/electronics12092113