The algorithm model in this paper is mainly divided into three parts: embedding acquisition based on graph neural networks, the parameter sharing based on multi-task learning, and the selection of a loss-merging algorithm. This paper will explain these three parts respectively.
3.1. Embedded Acquisition Based on Graph Neural Networks
Predecessors mainly rely on CNN [
1] and RNN [
2] for embedding acquisition. These two embedding acquisitions have two limitations. On top of space, data in non-Euclidean spaces cannot be processed. Second, it can only aggregate information from first-order neighbors, but cannot aggregate information from higher-order neighbors. The birth of the graph neural network has proposed a brand-new idea to solve these two problems. Therefore, this model intends to use the graph neural network to obtain embedding. The reason is that this model is mainly through the interaction between users and products. relationship, without considering the information of the user and the product itself. It seems that this article operates on the graph, so it is a better choice to choose the graph neural network.
For the classic GCN [
37], the embedding of the node obtained by the single-layer GCN layer is expressed as (1):
where
represents the embedding obtained by the
l layer,
is the normalized adjacency matrix, where
A is the adjacency matrix,
D is the angle matrix,
,
I is the identity matrix.
is the parameter matrix of layer
l, and
is the activation function.
is the initialization embedding matrix.
The problem with this classic GCN model is that it only aggregates node information (user nodes aggregate user node information, and commodity nodes aggregate commodity node information. In fact, it is meaningless under the current assumptions of this article, because this article does not consider the relationship between users for the time being. The connection or the relationship between the items (but only considering the relationship between users and items) and the model does not take into account a variety of behaviors, so this paper needs to improve it to meet the ideal requirements.
For the first question, this article wants to achieve the representation of the user aggregated through the related products, and also establishes a relationship through the relationship between the user and the product; therefore, taking the user as an example, the original GCN representation becomes (2):
In the graph neural network, it is mainly divided into two theoretical systems, the graph domain and the frequency domain, where (1) is the frequency domain implementation method of GCN, and (2) is actually a variant of the GCN graph domain implementation method, where represents the neighbors of user, u, under various behaviors, and is a standardized item.
The representation of the commodity is shown in (3):
After completing the previous work, this paper introduces the attention mechanism of GAT into the work of this paper.
First of all, this article calculates the attention coefficient, first looking at the attention coefficient calculation method in GAT [
38].
For vertex u, the similarity coefficient between its neighbors,
and itself, was calculated, as indicated in (4):
This formula was interpreted as (4): First, a linear map with a shared parameter,
W, increases the dimension of the feature of the vertex. Of course, this is a common feature enhancement method; splicing, and finally,
a(⋅) maps the spliced high-dimensional features to a real number. This is the calculation method of the similarity coefficient in the classic GAT. With the correlation coefficient, the distance from the attention coefficient is normalized. Here, the normalization method similar to GAT is directly used, as shown in Formula (5):
After getting the attention coefficient, this article can improve Formula (2) to (6):
and improve Formula (3) to (7):
After the attention mechanism is improved, it does not depend on the structure of the graph, has no pressure on the inductive task, and realizes the assignment of different learning weights to different neighbors. In the future, it can continue to be optimized and improved to a multi-head attention mechanism. After completing the above work, the first part of the model of this paper is completed.
3.2. Parameter Sharing Based on Multi-Tasking Learning
This paper obtains the embedded representation of users and products, but does not introduce the parameter sharing of multi-task learning, which leads to the fact that the multiple behaviors in this paper as the embedded representation between is only an independent representation, so this paper needs to find a way to solve the problem of parameter sharing [
39]. Based on this idea, looking back at Formula (6), this paper finds that the parameter is actually
, so it considers setting this parameter as a parameter common to multiple behaviors, and then improves (6) to:
After the improved Formula (8), this paper finds that the parameters represent the behavior disappearance, so this paper introduces an embedded representation,
, for each behavior, and then improves Formula (8) to (9):
The
update method is as follows (10):
In fact, here gives different weights to different behaviors, which is the non-shared layer in multi-behavior learning.
So far, this paper has solved the problem of the shared layer, and also obtained the embedded representation of users, products, and relationships.
The representations obtained from different layers emphasize the information delivered from different hops. For example, the first layer enforces the smoothing of interacting users and items, the second layer smooths overlapping users (items) on interacting items (users), and the higher layers capture higher-order proximity, thus combining them further to get the final representation. The attention mechanism is still used here, and the attention coefficient is (11):
The superimposed users, items, and relationship embeddings are expressed as (12):
Finally, this paper obtains the predicted value, which represents the probability of interaction between user,
u, and product,
v, under k behaviors (13):
where
represents a diagonal matrix, of which the diagonal elements are equal
.
At this point, the first two modules of this model in the article are solved, and the subsequent third module is to solve the problem of loss.
3.3. Introduction to the Algorithm of Loss Merging
Taking the single
k-th behavior as an example for a batch of users,
B, and the entire product set,
V, the traditional weighted regression loss is:
It can be seen that the time complexity of calculating this loss is
, which is generally unaffordable in practice. However, based on previous research [
40], it can be optimized to
. The work of this paper is not focused on this, but on the summation of the subsequent multi-behavior losses. Optimizing model operations, such as reducing model time complexity and optimal resource allocation, can be done according to [
41,
42].
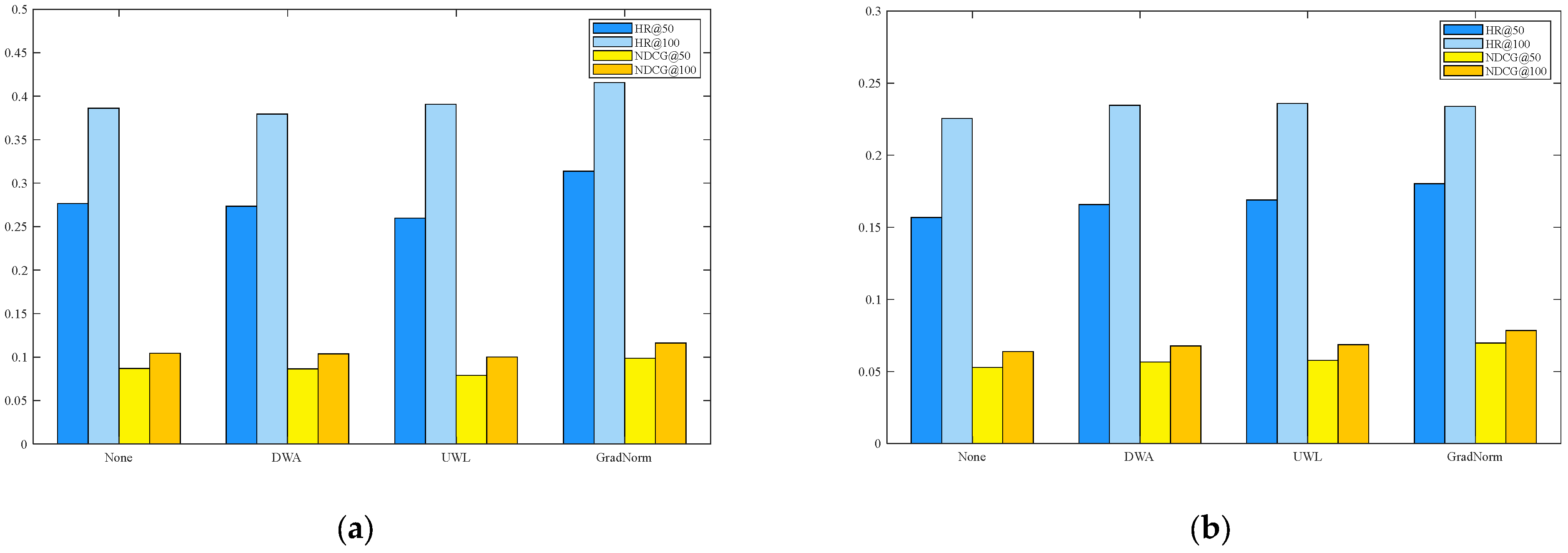
For the traditional summation method, the losses of multiple tasks are directly added to obtain the overall loss. However, there are two problems. One is that the magnitude of the loss of different tasks is different, and there may be a phenomenon that the task with a larger loss dominates. The other is that the learning speed of different tasks is different; some are slow, and some are fast. This paper discusses three commonly used loss optimization algorithms: gradient normalization (GradNorm) [
43], using uncertainty to weigh losses (UWL) [
44], and dynamic weight average (DWA) [
45], to conduct experiments to obtain an algorithm with better results in the current scenario. This is added to the model to improve the final effect of the model.
GradNorm proposes a new method which can automatically balance the different gradient levels of multitasks, improve the effect of multitask learning, and reduce overfitting.
The definition of total loss is still the weighted average of the loss of different tasks, as shown in (15):
GradNorm designed an additional loss to learn the weight,
, of different task losses, but it does not participate in the reverse gradient update of the parameters of the network layer. The purpose is that the gradients of different tasks can become the same magnitude through regularization, so that different tasks can be achieved. The train at a close speed is as follows:
Among them, t represents the number of training steps, W generally takes the weight of the last shared layer, where represents the regularization gradient of the i-th task; that is, the gradient of loss to , and then L2-norm. represents the mean of multiple regularized gradients.
indicates the relative learning speed of the
i-th task:
Among them,
represents the loss ratio of the
i-th task (step
t) and the initial loss ratio, which is used to represent the learning speed:
The core of UWL is , where is a learnable parameter, and the paper regards it as the uncertainty (uncertainty) of the corresponding task modeling. It can be seen that the consequence of the total loss on the tasks is a large loss and a small , because for this kind of task, will be very large and SGD will optimize it to a small size, This represents a task with a large loss, which means that its uncertainty (uncertainty) is also high. In order to prevent the model from “big steps” in the wrong direction, smaller gradients should be used to update w. On the contrary, for tasks with smaller losses, its uncertainty is also lower, and w is updated with larger gradients. At the same time, this can also avoid the problem of letting tasks with larger losses dominate.
The DWA method is relatively simple and direct. Unlike GradNorm, it does not need to calculate the gradient, but only needs the loss of the task. The formula is expressed as (19):
is the weight of the task; that is, the total loss is still the weighted average of the loss of all tasks: . is the loss ratio of the previous round, representing learning rates for different tasks. T plays a role in smoothing task weights, and the larger the T is, the more uniform the weight distribution of different tasks is. If T is large enough, then , and the weight of each task is equal. K means that the weighted sum of all tasks is K. Because in general, if there is no special treatment the weight of each task is equal to 1, all tasks will be K after weighting.
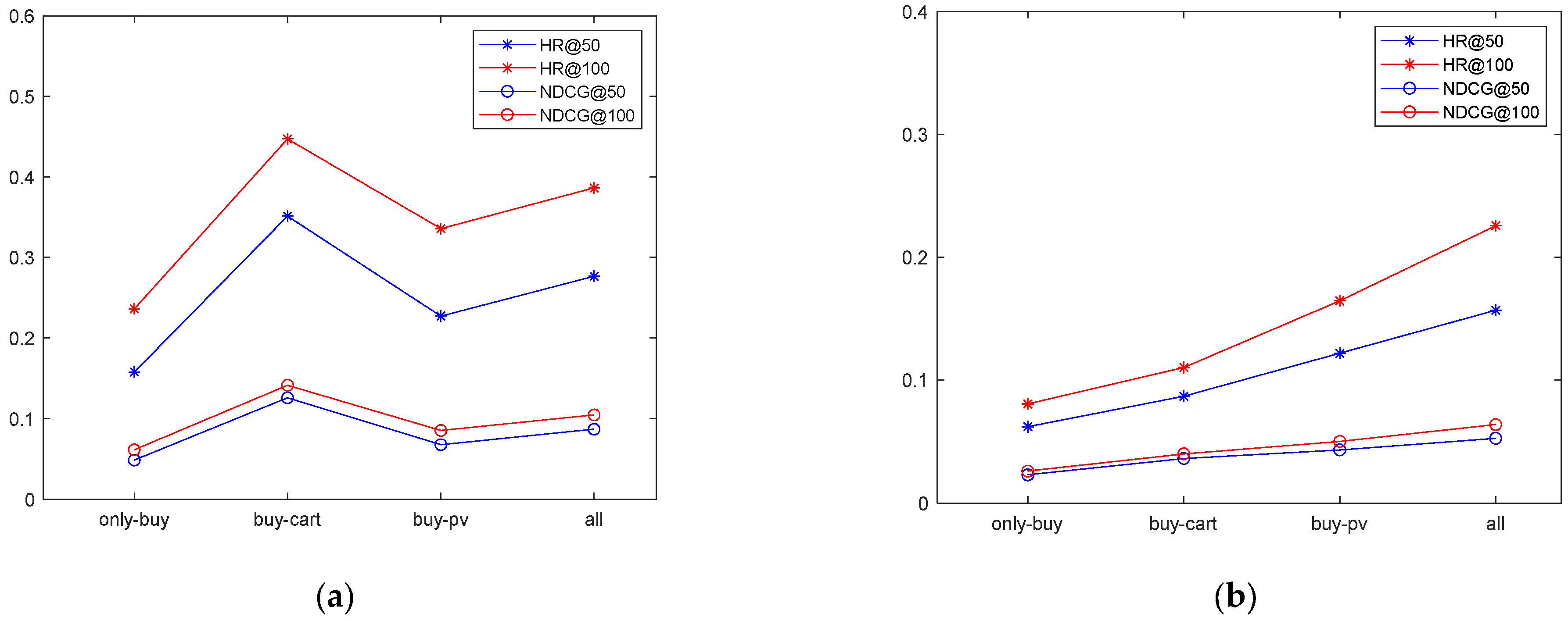
In terms of experimental indicators, this paper selects the hit rate (HR) and the normalized discounted cumulative gain (NDCG) as the experimental indicators of the experiment. These two indicators are commonly used in recommendation systems. Both HR and precision indicators are indicators for evaluating the accuracy of the model predictions. The HR indicator focuses more on whether the model can include user demand items in the recommendation list, while the precision indicator focuses more on how many of the samples predicted by the model as positive are truly positive. The main difference is in the calculation method and focus. In this study, the final test set used is the product that the user finally purchased. The model is to predict whether it is correctly recommended, so using the HR indicator is more appropriate. Recall and F-ratio indicators are similar to precision and will not be repeated. In addition to the accuracy of the recommendations, it is also necessary to consider whether the recommended items are closer to the front and whether they are placed in a more conspicuous position. Precision, recall, F-ratio, and other indicators cannot be represented, but the NDCG can be represented. NDCG is an evaluation indicator that emphasizes orderliness. Its focus is on whether the recommended items are placed in a conspicuous position for users and assigns higher scores to items that are closer to the front.
HR indicates the users’ things and whether the recommendation system has recommended it, emphasizing the accuracy of the prediction as per the formula shown in (20):
Among them, N represents the users’ access weight, which is the number of real clicks by the user. If the recommendation system recommends product i, hit(i) is 1, otherwise it is 0.
NDCG concerns with whether the found products are placed in a prominent position for users; that is, it emphasizes the order, as per the formula shown in (21):
Among them, N represents the total number of user visits, which is the number of real clicks by users. indicates the position where the item appears in the recommendation results; if it does not appear, then is infinite.







{kind=link}
{kind=link}
{kind=link}