1. Introduction
The progress of semiconductor and computer technology has resulted in the development of highly integrated and complex integrated circuits, exhibiting exponential growth. To simulate these circuits, DC analysis based on modified nodal analysis (MNA) [
1] is essential for solving nonlinear algebraic equations. However, the convergence of the widely-used Newton–Raphson (NR) method [
2] and its variants [
3,
4] depends heavily on the diagonal dominance of the coefficient matrix and the appropriateness of the initial point. These factors are difficult to guarantee for analog circuits, often leading to convergence failure [
5]. As a result, researchers have investigated continuation algorithms to address the NR convergence problem, including Gmin stepping [
6], source stepping [
7], homotopy methods [
8,
9,
10], and PTA [
11]. However, Gmin and source-stepping methods may have inferior convergence when the solution curve is bifurcated, folded, or discontinuous; and the practical implementations of homotopy methods are highly dependent on device models. PTA has shown to be a promising alternative due to the good continuity of its solution curve and easy implementation.
PTA is used to convert a complex nonlinear algebraic system into an ordinary differential system, which can be solved with initial value problems by inserting pseudo-elements. Once the PTA solver has formed the ordinary differential system, it is solved iteratively through numerical integration using a time-step control technique to achieve a steady state. Since the efficiency of PTA is heavily influenced by its time-step control method, which determines the discrete time points that require resolution, including the resource-intensive NR iterations, it is crucial to optimize this aspect. Although some simplistic formula-based time-step control methods have been introduced in recent years to speed up PTA, such methods have not been adequate for large-scale nonlinear simulations. Therefore, a more effective time-step control approach is required.
The emergence of deep learning technologies has enabled the resolution of complex problems, such as computer vision [
12], cloud computing [
13], and natural language processing [
14], offering a promising avenue for researching time-step control methods. However, developing an efficient time-step control approach presents several challenges. Firstly, while different circuit types require different time-step requirements, conventional process variables in circuit solving can be utilized as features, along with expert knowledge, to identify the distinct time-step necessities. Secondly, since there is no precise definition for the optimal time step in PTA theory, a sampling strategy is necessary to determine the optimal time step. Thirdly, because PTA time-step control is temporal in nature, the proposed algorithm must be able to process timing information.
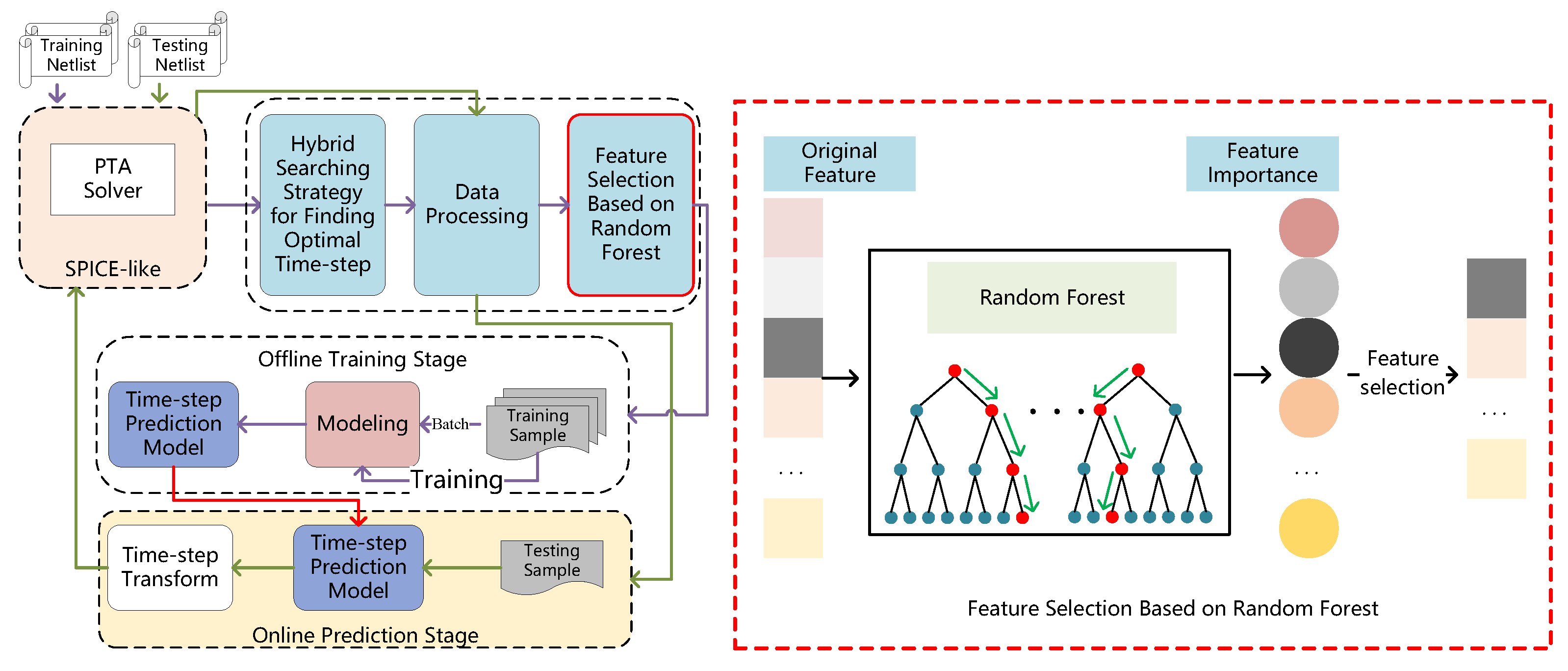
In this paper, we present a novel approach to time-step control by leveraging deep learning techniques to address Challenge 1. Our proposed method is illustrated in
Figure 1 and features a hybrid searching strategy with coarse and fine-grained steps to find the optimal time-step, thereby addressing Challenge 2. In addition, we utilized the LSTM model to effectively manage timing information and resolve Challenge 3. Our contributions are summarized as follows:
(1) We present a novel time-step control method that incorporates a deep learning framework for offline training and online prediction. Our methodology yields superior simulation efficiency and exhibits remarkable out-of-sample performance, surpassing extant approaches in terms of extrapolation accuracy.
(2) We propose a hybrid searching strategy for identifying the optimal time-step, addressing the key issue that cannot be theoretically defined. This approach also provides fine-grained labels for the training set.
(3) We incorporate the random forest model to evaluate feature importance during the feature-selection stage, leading to faster network training, improved simulation efficiency, and highly accurate predictions.
(4) We implemented our proposed approach in an out-of-the-box SPICE-like simulator and demonstrate its effectiveness with benchmark circuits. We achieved significant acceleration—the maximum speedup being 61.32 times on practical circuits.
3. Proposed Methods
3.1. Overview
The time-step control for the PTA method is not determined by accuracy considerations. Instead, the time-step is made as large as possible, which is consistent only with the convergence of the NR iteration [
20], and this time-step is defined as the optimal time step. In the actual simulation, if each PTA step can use the optimal time-step, the simulation efficiency can be greatly improved. According to the characteristics of the PTA time-step mentioned above, we first introduce a hybrid searching strategy for finding the optimal time step. Specifically, the hybrid search strategy consists of two parts: the coarse-grained process and the fine-grained process. The coarse-grained process is responsible for increasing the time step rapidly and without limitation under the precondition of NR convergence. The fine-grained process is triggered when NR does not converge and is responsible for reducing the time step, leading to NR non-convergence from large to small according to the set granularity, until a time step is found that can ensure NR convergence. In this case, the optimal time step is artificially defined—that is, the data labeling is completed. Furthermore, feature selection based on random forest is adopted to obtain fine features, which not only reduces the feature dimension through evaluating feature importance but also improves simulation efficiency with high accuracy of prediction and accelerates the network training.
Once optimal time steps and fine features are obtained, we utilize the key concepts of the proposed method—first, mapping time-step control for the regression-prediction problem. Then, the proposed method can fit the optimal time-step control function (
f) with the optimal time step (
h) and selected features (
) on the training set.
where
represents the parameters needed to learn by training. Furthermore, LSTM is employed to find parameters
on the training set, which makes model
have a closed actual optimal time-step control function
through batch gradient descent. Thus, the ordinary differential system reaches the steady state sufficiently quickly; that is, the number of NR iterations used to complete PTA is as small as possible.
Figure 4 shows the entire flow of the proposed method. Samples were collected during the PTA iteration for offline model training, and then the trained model was used for online prediction during the PTA iteration.
3.2. Hybrid Searching Strategy for Finding the Optimal Time Step
As mentioned previously, searching for the optimal time step is the first task to be solved. However, there is the issue that there is no precise definition of the optimal time step in PTA. Therefore, we introduce a hybrid searching strategy, as shown in
Figure 5, for finding the optimal time step to overcome above issue. In the traditional PTA iteration, when solving the NR iteration convergence of the nonlinear equation at each time point, the solution of this time point will be received and taken as the initial value to continue solving the problem at the next time point until PTA convergence. In our hybrid search strategy, when we start from a certain point in time to find the optimal time step of the next step, we first use the traditional method to predict the next time step and solve it. When the time point solution of the predicted time step is solved, NR iteration converges and we do not accept the solution of this time point. Instead, it goes back to the time point where the optimal time step is to be found, and a larger time step is given for solving. This process is repeated until the NR iteration does not converge. When the NR solutions do not converge, we believe that the optimal time step must be between the non-convergent time point and the previous convergent time point. However, if the time step of NR iteration convergence in the previous step is taken as the optimal time step directly, it is not accurate and not the real optimal time step. At this time, we further use the fine-grained time step to search between these two time points, and the time step obtained can at least ensure that the convergence time is longer than the previous time step. To ensure the efficiency of searching strategy, an adaptive granularity trick for a fine grained process is adopted, which can choose different granularities according to the order of magnitude of time step. In this way, we can find the optimal time step at each time point by mixing the aggressive coarse-grained growth strategy while looking for a larger time step with the finer fine-grained rollback strategy, and obtain a large number of samples with the optimal time-step label through mass sampling, which makes subsequent supervised learning based on deep learning possible.
Table 1 shows the speedup of several circuits simulated by using the introduced sampling strategy, which verifies that this sampling strategy can provide a fine dataset for implementing the optimal time-step control enhanced by deep learning.
3.3. Feature Selection Based on Random Forest
Feature selection decides the performance of the trained model. Reasonable feature selection not only reduces the computation of model training but also improves the accuracy of prediction. In addition, once feature selection is completed, we simulate all training netlists to get the total dataset.
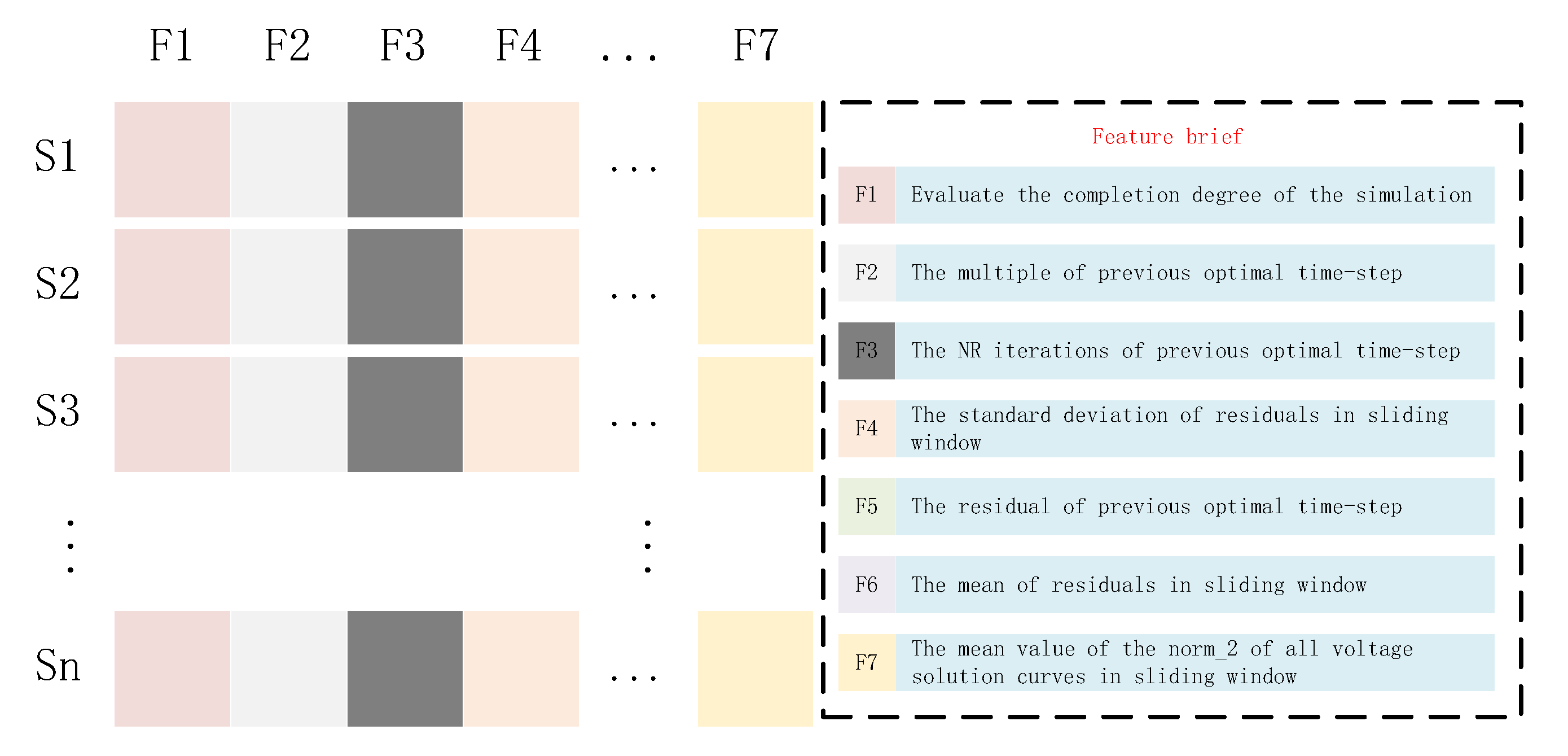
The time-step control in PTA is not limited to the circuit but depends on the change trends of the process variables in the simulation. Therefore, not only the features from the circuit itself, such as circuit type, but also the process variables in simulation, are selected as features. This enables our sample set not to be limited to a certain circuit type but can be sampled in the simulation process of all circuits in order to get as many samples as possible. Note that the features from five time points successively predict the sixth time step because too-few time points cannot describe the voltage fluctuation of nodes well, and in order to unify the inconsistent numbers of features caused by the different numbers of nodes in different circuits, we uniformly select the ten solution curves with the largest fluctuation for each circuit.
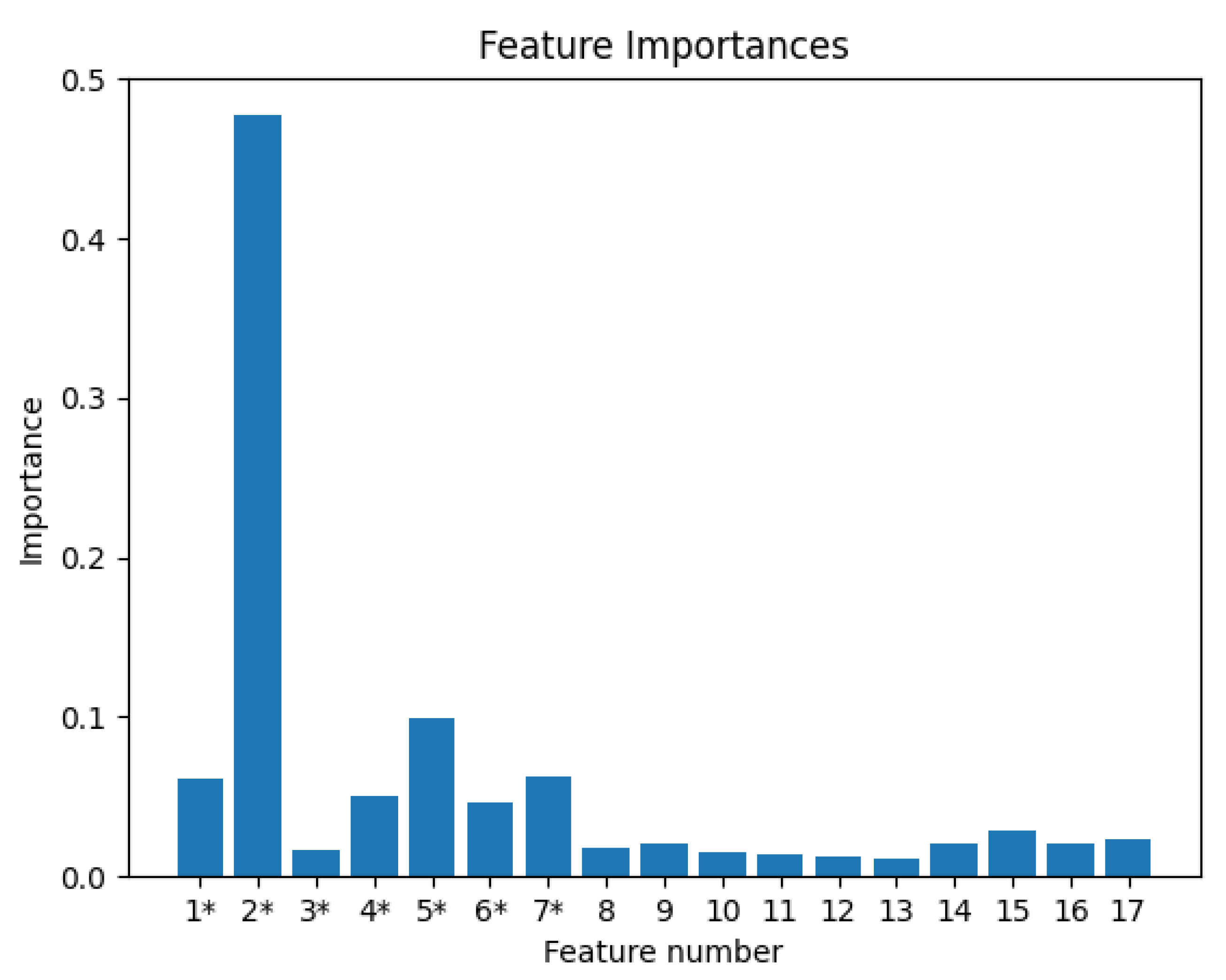
In our task, based on PTA theory and expert experience, we first select 17 features that are related to the time step (including step number; multiples of the time step; residuals of equations and NR iterations at the previous time point, and the standard deviation and mean of the residual; the 10 solution curves with the largest standard deviation; and the mean of the second-order norm of every solution curve along the row direction in a sliding window). Furthermore, random forest is employed to evaluate the importance of each feature. Each decision tree in a random forest is independent of the other. The information divergence is adopted to implement splitting of nodes in a decision tree, which shows the difference between the entropy of the set to be classified and the conditional entropy of the selected feature. Specifically, a random forest consists of many decision trees, which randomly select samples for training. The result of the random forest as a predictor (or classifier) is the mean value (mode) of each decision tree’s output. Therefore, it has great advantages over other traditional machine learning algorithms as follows: (1) It can handle higher-dimensional data without feature reduction. (2) Unbiased estimation is used for the generalization error, and the model has a strong generalization ability. (3) The training speed is fast, and it is easy to parallelize. It can be clearly seen that
Figure 6 shows a score of feature importance based on random forest to the 17 features mentioned earlier. Finally, the seven features with the higher scores, as shown in
Table 2, were selected as inputs to train the LSTM network. Although the number of NR iterations was slightly lower than the values of other features (proportionally), it was still chosen as the training feature, because the number of NR iterations is the only feature that can represent the degree of difficulty of solving the equations. Our training sets were composed of 720 samples from 30 circuits to analyze the correlation between each feature and the label, so as to obtain the importance of each feature in the time-step prediction task. In addition, these circuits included a variety of different types of circuits, such as MOS, BJT, oscillating circuits, and convergence difficulty circuits.
The detailed descriptions of the main features are given follows:
represents the difficulty of NR convergence at the previous optimal time-step. A smaller value for it means that NR converges more easily, and the next time step can be larger.
represents the distance of PTA convergence. When the value of the residual enters the PTA-convergence stage, a larger time step can also guarantee NR convergence.
represents the mean value of the of all voltage solution curves in the sliding window because there is a certain relationship between the fluctuation of voltage-solution curves and the time step. In general, the more dramatic the voltage fluctuation, the smaller the time-step.
3.4. Data Preprocessing
Individual data preprocessing for each feature. From the data structure in
Table 2, we can clearly know that different features have different data structures. However, the model requires input features with a uniform data structure (one-dimensional row vectors). Therefore, for residuals and voltages, we need to be unified. Firstly, for the voltage with a matrix structure, in order to preserve as much information as possible about the solution curve for all nodes
, the second order norm
, as shown in Equation (
9), is applied to the resulting voltage row vector at each time point in the sliding window. At this time, the matrix is changed to a vector with size
k of sliding window, and the mean value
is adopted to normalize a scalar.
Secondly, for residuals of one-dimensional column vector type in size
k of a sliding window, in order to describe the fluctuation of convergence distance of the current equations, the standard deviation
shown in Equation (
11) and mean value
shown in Equation (
10) are used to normalize the residuals and yield two scalars, respectively. After that, we can splice independent features based on column direction into a one-dimensional row vector as a training sample.
Whole data preprocessing for training set. After individual data processing, we spliced all the processed one-dimensional row vectors into a large matrix that is the training set, as shown in
Figure 7. As we all know, for the training set, the different value ranges and dimensions of each column feature will increase the training time and even lead to the non-convergence of the model. Therefore, for each column feature
x of the training set, the maximum and minimum normalization, as shown in Equation (
12), should be used to carry out numerical unification.
indicates the minimum value of the current column, and
indicates the maximum value of the current column.
It should be noted that the range of time steps may differ by dozens of orders of magnitude, which undoubtedly increases the difficulty of model learning. Therefore, in our work, in order to simplify the learning difficulty for the model, the time-step prediction task is converted to a prediction task based on the multiples of the previous time step.
3.5. LSTM-Enhanced Time-Step Control
Once all the data were ready to be sampled and processed, the deep learning model (LSTM) was employed to accomplish our task because of its ability to process timing information and avoid the gradient-disappearance problem in the recurrent neural network (RNN). PyTorch, a famous machine learning library, was adopted to implement LSTM. Firstly, we constructed a neural network structure with four hidden layers and a ReLU activation function, and each hidden layer contained 120 cells. In addition, batch size and learning rate were set to 32 and 0.0005, respectively. Adam and mean square error were utilized for the optimizer and loss function, respectively. Finally, Algorithm 1 was used for dealing with data and to train models. After training, the model for predicting time-step was obtained.
| Algorithm 1 LSTM-enhanced time-step control method for PTA. |
| Input: Training netlists |
| Output: Time-step predictor |
| 1: Hybrid Searching Strategy for Finding Optimal Time-Step |
| 2: Construct nonlinear equation by |
| 3: for PTA is not converge do |
| 4: Execute |
| 5: Find the maximum time-step that ensures NR convergence and mark as the optimal time-step |
| 6: end for |
| 7: Obtain optimal time-step set and features |
| 8: Feature Selection Based on Random Forest |
| 9: Select features , and ensure |
| 10: Data Preprocessing |
| 11: Execute |
| 12: Execute |
| 13: Modeling and Training |
| 14: Construct LSTM model with trainable parameters |
| 15: for i to n / do |
| 16: Loss (LSTM (, , )) |
| 17: Update |
| 18: Update |
| 19: end for |
| 20: |


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}