
Research and Optimization of a Lightweight Refined Mask-Wearing Detection Algorithm Based on an Attention Mechanism

Abstract
:1. Introduction
2. Related Principles
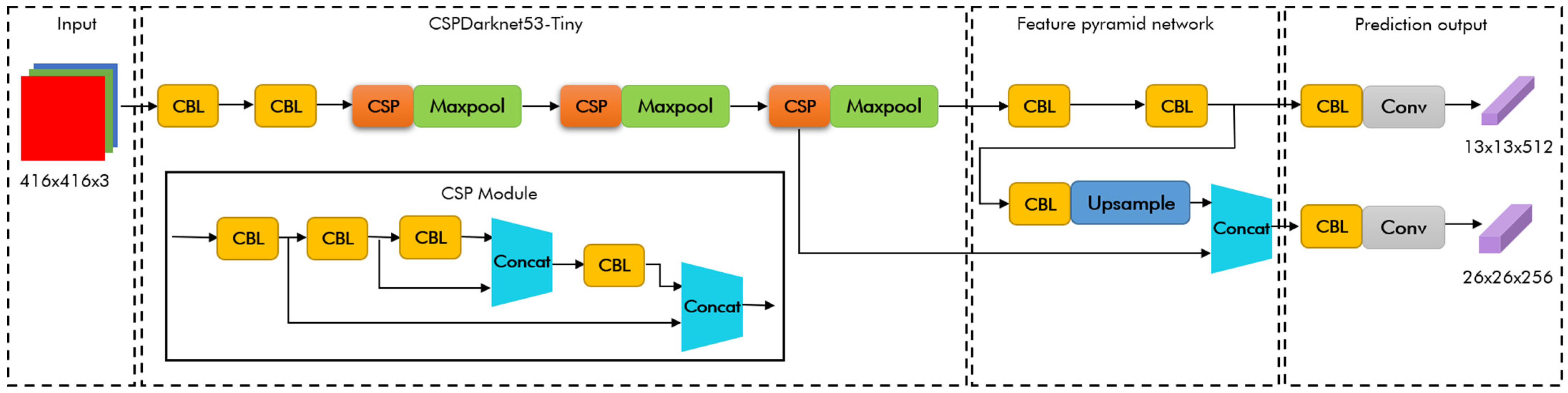
2.1. YOLOv4-Tiny Algorithm
2.2. CBAM Attention Module
2.3. Data Enhancement
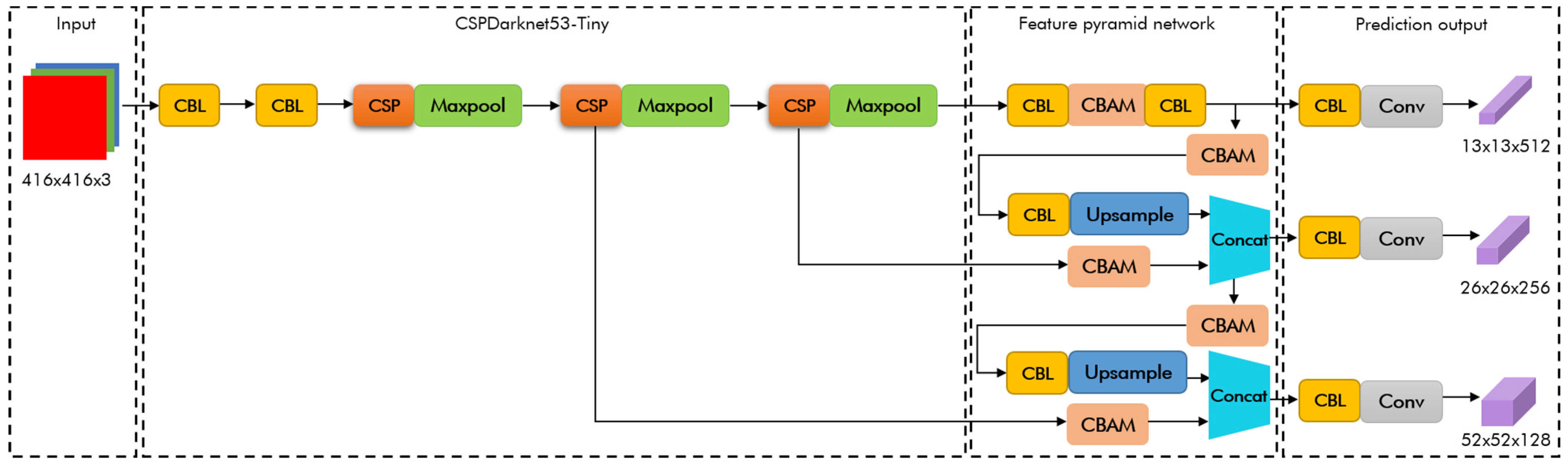
3. YOLOv4-Tiny Mask Detection Algorithm Optimization
3.1. Improving the Small-Target Detection Capability
3.2. Introducing the Attention Mechanism
3.3. Training Strategy Optimization
4. Experimental Results and Analysis
4.1. Datasets
4.2. Experimental Environment
4.3. Experimental Protocols
4.4. Analysis of the Experimental Results
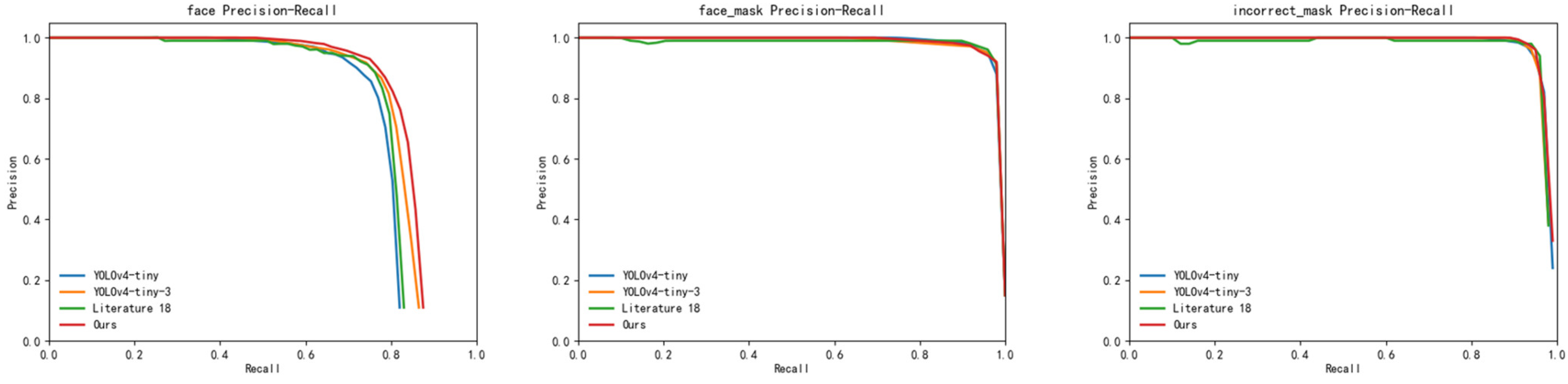
4.4.1. Comparison of P-R Curves
4.4.2. Comparison of Precision, Recall and AP Values
4.4.3. Comparison of Detection Speed
4.4.4. Comparison of Actual Scene Effects
4.4.5. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liang, M.; Gao, L.; Cheng, C.; Zhou, Q.; Uy, J.P.; Heiner, K.; Sun, C. Efficacy of face mask in preventing respiratory virus transmission: A systematic review and meta-analysis. Travel Med. Infect. Dis. 2020, 36, 101751. [Google Scholar] [CrossRef] [PubMed]
- Parente, C.; Montgomery, R.; Berry, L.; Mahida, N. Impact of universal mask wearing in reducing healthcare-associated respiratory virus infections in haematology patients. J. Hosp. Infect. 2022, 119, 192–193. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:02696. [Google Scholar]
- Wang, Z.; Wang, G.; Huang, B.; Xiong, Z.; Hong, Q.; Wu, H.; Yi, P.; Jiang, K.; Wang, N.; Pei, Y. Masked face recognition dataset and application. arXiv 2020, arXiv:09093. [Google Scholar]
- Cabani, A.; Hammoudi, K.; Benhabiles, H.; Melkemi, M. MaskedFace-Net–A dataset of correctly/incorrectly masked face images in the context of COVID-19. Smart Health 2021, 19, 100144. [Google Scholar] [CrossRef] [PubMed]
- Vrigkas, M.; Kourfalidou, E.A.; Plissiti, M.E.; Nikou, C. FaceMask: A New Image Dataset for the Automated Identification of People Wearing Masks in the Wild. Sensors 2022, 22, 896. [Google Scholar] [CrossRef] [PubMed]
- Niu, Z.; Qin, T.; Li, H.; Chen, J. Improved algorithm of RetinaFace for natural scene mask wear detection. Comput. Eng. Appl. 2020, 56, 1–7. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5203–5212. [Google Scholar]
- Wang, Y.; Ding, H.; Li, B.; Yang, Z.; Yang, J. Mask wearing detection algorithm based on improved YOLOv3 in complex scenes. Comput. Eng. 2020, 46, 12–22. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Wang, J.; Wang, B. Lightweight mask detection algorithm based on improved YOLOv4-tiny. Chin. J. Liq. Cryst. Disp. 2021, 1525–1534. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Kocacinar, B.; Tas, B.; Akbulut, F.P.; Catal, C.; Mishra, D. A Real-Time CNN-Based Lightweight Mobile Masked Face Recognition System. IEEE Access 2022, 10, 63496–63507. [Google Scholar] [CrossRef]
- Wei, M.; Zhou, T.; Ji, Z.; Zhang, X. Mask Wearing Detection in Complex Scenes Based on Mask-YOLO. J. Appl. Sci. 2022, 40, 93–104. [Google Scholar]
- Duan, X.; Chen, H.; Lou, H.; Bi, L.; Zhang, Y.; Liu, H. A more accurate mask detection algorithm based on Nao robot platform and YOLOv7. In Proceedings of the 2023 IEEE 3rd International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 19–31 January 2023; pp. 1295–1299. [Google Scholar]
- Endris, A.; Yang, S.; Zenebe, Y.A.; Gashaw, B.; Mohammed, J.; Bayisa, L.Y.; Abera, A.E. Efficient Face Mask Detection Method Using YOLOX: An Approach to Reduce Coronavirus Spread. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; pp. 568–573. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Bo, J.W.; Zhang, C.T. Lightweight mask wearing detection algorithm based on YOLOv3. Electron. Meas. Technol. 2021, 044, 105–110. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Zhang, L.P.; Li, Z.H.; Tang, Y.L. Light-YOLOv2 mask wearing detection method based on transfer learning. Electron. Meas. Technol. 2022, 45, 112–117. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/cvf Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. arXiv 2019, arXiv:08681. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the Icml, Atlanta, GA, USA, 16–21 June 2013; p. 3. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Parameters |
|---|---|
| Operating System | Windows 10 |
| CPU | Intel(R) Core(TM) i5-9400 CPU @ 2.90 GHz |
| GPU | GeForce RTX 1650 |
| RAM | 16 GB |
| CUDA | 10.0 |
| Keras | 2.1.5 |
| TensorFlow | 1.13.2 |
| Python | 3.6 |
| Models | Face (%) | face_mask (%) | incorrect_mask (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | AP | Precision | Recall | AP | Precision | Recall | AP | |
| YOLOv4 | 93.33 | 79.33 | 85.05 | 95.91 | 95.52 | 98.21 | 96.79 | 95.37 | 97.96 |
| YOLOv4-tiny | 86.21 | 74.23 | 77.64 | 94.97 | 94.84 | 98.01 | 96.72 | 93.26 | 97.27 |
| YOLOv4-tiny-3 | 92.30 | 72.25 | 80.93 | 95.35 | 94.57 | 98.10 | 97.35 | 92.63 | 96.87 |
| Literature 18 | 87.49 | 76.30 | 78.65 | 95.18 | 96.47 | 97.83 | 95.54 | 94.74 | 96.62 |
| Ours | 93.18 | 75.68 | 83.01 | 96.16 | 95.12 | 98.51 | 96.51 | 93.26 | 97.64 |
| Model | mAP (%) | FPS (Frame·s−1) | Parameters (M) |
|---|---|---|---|
| YOLOv4 | 93.74 | 11.29 | 64.0 |
| YOLOv4-tiny | 90.97 | 78.43 | 5.9 |
| YOLOv4-tiny-3 | 91.97 | 73.26 | 6.1 |
| Literature 18 | 91.04 | 67.20 | 9.18 |
| Ours | 93.05 | 70.22 | 6.2 |
| ID | Predictive Feature Layer | CBAM | Focal Loss | Mosaic | mAP (%) |
|---|---|---|---|---|---|
| 1 | √ | × | × | × | 91.25 |
| 2 | × | √ | × | × | 91.57 |
| 3 | √ | × | √ | √ | 91.97 |
| 4 | × | √ | √ | √ | 92.42 |
| 5 | √ | √ | √ | √ | 93.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, X.; Tong, Y.; Mei, F.; Wu, Z. Research and Optimization of a Lightweight Refined Mask-Wearing Detection Algorithm Based on an Attention Mechanism. Electronics 2023, 12, 1911. https://doi.org/10.3390/electronics12081911
Shi X, Tong Y, Mei F, Wu Z. Research and Optimization of a Lightweight Refined Mask-Wearing Detection Algorithm Based on an Attention Mechanism. Electronics. 2023; 12(8):1911. https://doi.org/10.3390/electronics12081911
Chicago/Turabian StyleShi, Xiangbo, Yala Tong, Fei Mei, and Zhongjian Wu. 2023. "Research and Optimization of a Lightweight Refined Mask-Wearing Detection Algorithm Based on an Attention Mechanism" Electronics 12, no. 8: 1911. https://doi.org/10.3390/electronics12081911