


Cyber-Physical System Security Based on Human Activity Recognition through IoT Cloud Computing
 , , , and
, , , and
Abstract
:1. Introduction
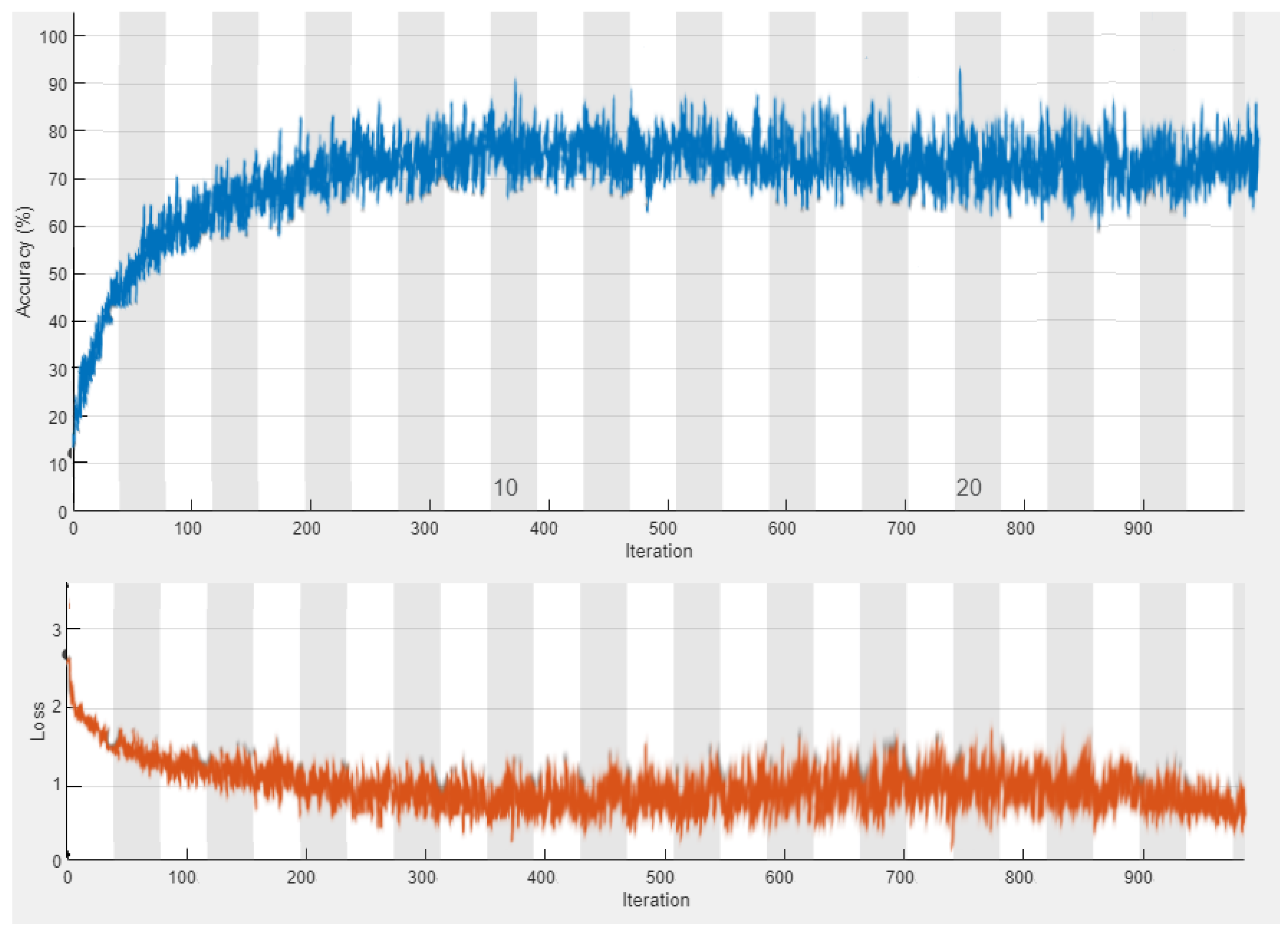
- Development and training of a GoogleNet–BiLSTM hybrid network to classify designated human activities from video with an average accuracy of 73.15%.
- Creative design of the cyber-physical security system using IoT and cloud computing to ensure the cyber-physical security of the proposed security system.
- Formulation of the novel HAR-CPS algorithm to use the GoogleNet–BiLSTM hybrid network to ensure security.
- Application of Machine Vision at the Edge (Mez) to minimize the cloud resources for cost minimization.
2. Literature Review
3. Methodology
3.1. Dataset Selection
3.2. The Hybrid Network Architecture
3.2.1. Sequence Folding
3.2.2. Feature Extractor Network in Cloud
| Algorithm 1 Constructing Feature Vector. |
Input: GoogleNet, ; Frame, F Output: Feature Vector, ; Initiate: Allocate Virtual Machine, ; Start for do end for end |
3.2.3. GoogleNet–BiLSTM Hybridization
3.2.4. Training the Hybrid Network
3.2.5. HAR-CPS Algorithm
3.3. Latency and Cloud Resource Optimization Using Mez
| Algorithm 2 The HAR-CPS Algorithm |
Input: CCTV Video Stream, ; HLS Request, Initiate: Allocate Cloud Resource; Output: Alert, a; Start while do Accept HLS Request if then if then end if else end if end while end |
3.3.1. Latency vs. Quality Trade-Off
3.3.2. Cloud Resource Optimization
4. Results and Performance Evaluation
4.1. Performance of the GoogleNet–BiLSTM Hybrid Network
4.1.1. Performance Comparison
4.1.2. Resource Optimization Performance
5. Limitations and Future Scope
5.1. Limited Number of Actions
5.2. Camera–Subject Angle Sensitivity
5.3. Security of the HAR-CPS Device
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Duo, W.; Zhou, M.; Abusorrah, A. A survey of cyber attacks on cyber physical systems: Recent advances and challenges. IEEE/CAA J. Autom. Sin. 2022, 9, 784–800. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, Y. Performance based attack detection and security analysis for cyber-physical systems. Int. J. Robust Nonlinear Control 2023, 33, 3267–3284. [Google Scholar] [CrossRef]
- Hammoudeh, M.; Epiphaniou, G.; Pinto, P. Cyber-Physical Systems: Security Threats and Countermeasures. J. Sens. Actuator Netw. 2023, 12, 18. [Google Scholar] [CrossRef]
- De Pascale, D.; Sangiovanni, M.; Cascavilla, G.; Tamburri, D.A.; Van Den Heuvel, W.J. Securing Cyber-Physical Spaces with Hybrid Analytics: Vision and Reference Architecture. In Proceedings of the Computer Security: ESORICS 2022 International Workshops: CyberICPS 2022, SECPRE 2022, SPOSE 2022, CPS4CIP 2022, CDT & SECOMANE 2022, EIS 2022, and SecAssure 2022, Copenhagen, Denmark, 26–30 September 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 398–408. [Google Scholar]
- Jadhao, A.; Bagade, A.; Taware, G.; Bhonde, M. Effect of background color perception on attention span and short-term memory in normal students. Natl. J. Physiol. Pharm. Pharmacol. 2020, 10, 981–984. [Google Scholar] [CrossRef]
- Del Giudice, M.; Scuotto, V.; Orlando, B.; Mustilli, M. Toward the human–centered approach. A revised model of individual acceptance of AI. Hum. Resour. Manag. Rev. 2023, 33, 100856. [Google Scholar] [CrossRef]
- Faruqui, N.; Yousuf, M.A.; Whaiduzzaman, M.; Azad, A.; Barros, A.; Moni, M.A. LungNet: A hybrid deep-CNN model for lung cancer diagnosis using CT and wearable sensor-based medical IoT data. Comput. Biol. Med. 2021, 139, 104961. [Google Scholar] [CrossRef]
- Chakraborty, P.; Yousuf, M.A.; Zahidur Rahman, M.; Faruqui, N. How can a robot calculate the level of visual focus of human’s attention. In Proceedings of the International Joint Conference on Computational Intelligence: IJCCI 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 329–342. [Google Scholar]
- Trivedi, S.; Patel, N.; Faruqui, N. Bacterial Strain Classification using Convolutional Neural Network for Automatic Bacterial Disease Diagnosis. In Proceedings of the 2023 13th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 19–20 January 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 325–332. [Google Scholar]
- Trivedi, S.; Patel, N.; Faruqui, N. NDNN based U-Net: An Innovative 3D Brain Tumor Segmentation Method. In Proceedings of the 2022 IEEE 13th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, NY, USA, 26–29 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 538–546. [Google Scholar]
- Arman, M.S.; Hasan, M.M.; Sadia, F.; Shakir, A.K.; Sarker, K.; Himu, F.A. Detection and classification of road damage using R-CNN and faster R-CNN: A deep learning approach. In Proceedings of the Cyber Security and Computer Science: Second EAI International Conference, ICONCS 2020, Dhaka, Bangladesh, 15–16 February 2020; Proceedings 2. Springer: Berlin/Heidelberg, Germany, 2020; pp. 730–741. [Google Scholar]
- Ibrahim, Y.; Wang, H.; Adam, K. Analyzing the reliability of convolutional neural networks on gpus: Googlenet as a case study. In Proceedings of the 2020 International Conference on Computing and Information Technology (ICCIT-1441), Tabuk, Saudi Arabia, 9–10 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Wei, X.; Wu, J.; Ajayi, K.; Oyen, D. Visual descriptor extraction from patent figure captions: A case study of data efficiency between BiLSTM and transformer. In Proceedings of the 22nd ACM/IEEE Joint Conference on Digital Libraries, Cologne, Germany, 20–24 June 2022; pp. 1–5. [Google Scholar]
- Zhang, X.; Kim, T. A hybrid attention and time series network for enterprise sales forecasting under digital management and edge computing. J. Cloud Comput. 2023, 12, 1–21. [Google Scholar] [CrossRef]
- Yang, L.; Yu, X.; Zhang, S.; Long, H.; Zhang, H.; Xu, S.; Liao, Y. GoogLeNet based on residual network and attention mechanism identification of rice leaf diseases. Comput. Electron. Agric. 2023, 204, 107543. [Google Scholar] [CrossRef]
- Pflanzner, T.; Kertész, A. A taxonomy and survey of IoT cloud applications. EAI Endorsed Trans. Internet Things 2018, 3, Terjedelem-14. [Google Scholar] [CrossRef]
- Ray, A.; Kolekar, M.H.; Balasubramanian, R.; Hafiane, A. Transfer Learning Enhanced Vision-based Human Activity Recognition: A Decade-long Analysis. Int. J. Inf. Manag. Data Insights 2023, 3, 100142. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Nini, B.; Sabokrou, M.; Hadid, A. Vision-based human activity recognition: A survey. Multimed. Tools Appl. 2020, 79, 30509–30555. [Google Scholar] [CrossRef]
- Park, H.; Kim, N.; Lee, G.H.; Choi, J.K. MultiCNN-FilterLSTM: Resource-efficient sensor-based human activity recognition in IoT applications. Future Gener. Comput. Syst. 2023, 139, 196–209. [Google Scholar] [CrossRef]
- Kulsoom, F.; Narejo, S.; Mehmood, Z.; Chaudhry, H.N.; Bashir, A.K. A review of machine learning-based human activity recognition for diverse applications. Neural Comput. Appl. 2022, 34, 18289–18324. [Google Scholar] [CrossRef]
- Paula, L.P.O.; Faruqui, N.; Mahmud, I.; Whaiduzzaman, M.; Hawkinson, E.C.; Trivedi, S. A Novel Front Door Security (FDS) Algorithm using GoogleNet-BiLSTM Hybridization. IEEE Access 2023, 11, 19122–19134. [Google Scholar] [CrossRef]
- Kobara, K. Cyber physical security for industrial control systems and IoT. IEICE Trans. Inf. Syst. 2016, 99, 787–795. [Google Scholar] [CrossRef]
- Sarp, B.; Karalar, T. Real time smart door system for home security. Int. J. Sci. Res. Inf. Syst. Eng. 2015, 1, 121–123. [Google Scholar]
- Aldawira, C.R.; Putra, H.W.; Hanafiah, N.; Surjarwo, S.; Wibisurya, A. Door security system for home monitoring based on ESp32. Procedia Comput. Sci. 2019, 157, 673–682. [Google Scholar]
- Sanjay Satam, S.; El-Ocla, H. Home Security System Using Wireless Sensors Network. Wirel. Pers. Commun. 2022, 125, 1185–1201. [Google Scholar] [CrossRef]
- Banerjee, P.; Datta, P.; Pal, S.; Chakraborty, S.; Roy, A.; Poddar, S.; Dhali, S.; Ghosh, A. Home Security System Using RaspberryPi. In Advanced Energy and Control Systems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 167–176. [Google Scholar]
- Tao, J.; Wu, H.; Deng, S.; Qi, Z. Overview of Intelligent Home Security and Early Warning System based on Internet of Things Technology. Int. Core J. Eng. 2022, 8, 727–732. [Google Scholar]
- Kong, M.; Guo, Y.; Alkhazragi, O.; Sait, M.; Kang, C.H.; Ng, T.K.; Ooi, B.S. Real-time optical-wireless video surveillance system for high visual-fidelity underwater monitoring. IEEE Photonics J. 2022, 14, 7315609. [Google Scholar] [CrossRef]
- Wan, S.; Ding, S.; Chen, C. Edge computing enabled video segmentation for real-time traffic monitoring in internet of vehicles. Pattern Recognit. 2022, 121, 108146. [Google Scholar] [CrossRef]
- Ujikawa, H.; Okamoto, Y.; Sakai, Y.; Shimada, T.; Yoshida, T. Time distancing to avoid network microbursts from drones’ high-definition video streams. IEICE Commun. Express 2023, 12, 126–131. [Google Scholar] [CrossRef]
- Darwich, M.; Ismail, Y.; Darwich, T.; Bayoumi, M. Cost Minimization of Cloud Services for On-Demand Video Streaming. SN Comput. Sci. 2022, 3, 226. [Google Scholar] [CrossRef]
- George, A.; Ravindran, A.; Mendieta, M.; Tabkhi, H. Mez: An adaptive messaging system for latency-sensitive multi-camera machine vision at the iot edge. IEEE Access 2021, 9, 21457–21473. [Google Scholar] [CrossRef]
- Kong, Y.; Fu, Y. Human action recognition and prediction: A survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; Chiaberge, M. Action Transformer: A self-attention model for short-time pose-based human action recognition. Pattern Recognit. 2022, 124, 108487. [Google Scholar] [CrossRef]
- Qi, W.; Wang, N.; Su, H.; Aliverti, A. DCNN based human activity recognition framework with depth vision guiding. Neurocomputing 2022, 486, 261–271. [Google Scholar] [CrossRef]
- Hesse, N.; Baumgartner, S.; Gut, A.; Van Hedel, H.J. Concurrent Validity of a Custom Method for Markerless 3D Full-Body Motion Tracking of Children and Young Adults based on a Single RGB-D Camera. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 1943–1951. [Google Scholar] [CrossRef]
- Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; Carlos Niebles, J. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Sigurdsson, G.A.; Gupta, A.; Schmid, C.; Farhadi, A.; Alahari, K. Charades-ego: A large-scale dataset of paired third and first person videos. arXiv 2018, arXiv:1804.09626. [Google Scholar]
- Sharma, V.; Gupta, M.; Pandey, A.K.; Mishra, D.; Kumar, A. A Review of Deep Learning-based Human Activity Recognition on Benchmark Video Datasets. Appl. Artif. Intell. 2022, 36, 2093705. [Google Scholar] [CrossRef]
- Carreira, J.; Noland, E.; Hillier, C.; Zisserman, A. A short note on the kinetics-700 human action dataset. arXiv 2019, arXiv:1907.06987. [Google Scholar]
- Yoshikawa, Y.; Lin, J.; Takeuchi, A. Stair actions: A video dataset of everyday home actions. arXiv 2018, arXiv:1804.04326. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Kumar, V.; Tripathi, V.; Pant, B. Exploring the strengths of neural codes for video retrieval. In Machine Learning, Advances in Computing, Renewable Energy and Communication: Proceedings of MARC 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 519–531. [Google Scholar]
- Lydia, A.; Francis, S. Adagrad—An optimizer for stochastic gradient descent. Int. J. Inf. Comput. Sci. 2019, 6, 566–568. [Google Scholar]
- Turitsyn, S.K.; Schafer, T.; Mezentsev, V.K. Generalized root-mean-square momentum method to describe chirped return-to-zero signal propagation in dispersion-managed fiber links. IEEE Photonics Technol. Lett. 1999, 11, 203–205. [Google Scholar] [CrossRef]
- Newey, W.K. Adaptive estimation of regression models via moment restrictions. J. Econom. 1988, 38, 301–339. [Google Scholar] [CrossRef]
- Berlt, P.; Altinel, B.; Bornkessel, C.; Hein, M.A. Concept for Virtual Drive Testing on the Basis of Challenging V2X and LTE Link Scenarios. In Proceedings of the 2022 16th European Conference on Antennas and Propagation (EuCAP), Madrid, Spain, 27 March–1 April 2022; IEEE: PIscataway, NJ, USA, 2022; pp. 1–5. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: PIscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Riedmiller, M.; Lernen, A. Multi layer perceptron. In Machine Learning Lab Special Lecture; University of Freiburg: Breisgau, Germany, 2014; pp. 7–24. [Google Scholar]
- Bin, Y.; Yang, Y.; Shen, F.; Xu, X.; Shen, H.T. Bidirectional long-short term memory for video description. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; 2016; pp. 436–440. [Google Scholar]
- Hossen, R.; Whaiduzzaman, M.; Uddin, M.N.; Islam, M.J.; Faruqui, N.; Barros, A.; Sookhak, M.; Mahi, M.J.N. Bdps: An efficient spark-based big data processing scheme for cloud fog-iot orchestration. Information 2021, 12, 517. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Categories | Videos | Description |
|---|---|---|---|
| ActivityNet [37] | 200 | 21,313 | Activities conducted on a daily, social, and domestic basis, including games and workouts. |
| Charades [38] | 157 | 66,493 | Routine chores performed within the house, such as refilling glasses, folding towels, etc. |
| HMDB51 [39] | 51 | 5100 | Movement of the body and face, as well as contact with objects, are all included. |
| Kinetics-700 [40] | 700 | 530,336 | Interactions involving a single person as well as those involving many people. |
| STAIR Actions [41] | 100 | 109,478 | Frequent indoor activities in the house, workplace, bathroom, and kitchen, including item handling, etc. |
| UCF101 [42] | 101 | 13,320 | Interactions between humans and other objects, movements of the body that do not include other objects, and the utilization of various instruments. |
| Serial | Incident | Class |
|---|---|---|
| 1 | Trying to break the door by punching | Punch |
| 2 | Trying to kick open the door | Kick |
| 3 | Hitting on the doorknob to break it | Hit |
| 4 | Showing up in front of the door with a weapon | Weapon |
| 4 | Pushing the door to open it forcefully | Push |
| Knob | Role | Frame Size Reduction | Scope |
|---|---|---|---|
| 1 | Resolution Adjustment | 84% | Resolutions: 1312 × 736, 960 × 528, 640 × 352, and 480 × 256 |
| 2 | Colorspace Modification | 62% | Colorspaces: BGR, Grayscale, HSV, LAB, and LUV |
| 3 | Blurring | 46% | Kernel size: 5 × 5, 8 × 8, 10 × 10, and 15 × 15 |
| 4 | Artifact Removal | 98% | Countour-based approach |
| 5 | Frame Differincing | 40% | Linear frame difference-based method |
| Evaluation Metrics | Mathematical Expression | Role |
|---|---|---|
| Accuracy | Classification accuracy | |
| Sensitivity | Correct identification of actual positive cases | |
| Specificity | True negative rate | |
| False positive rate | Type I error | |
| False negative rate | Type II error |
| Activity | Accuracy | Sensitivity | Specificity | FPR | FNR |
|---|---|---|---|---|---|
| Hit | 73.10% | 70.0% | 62.2% | 30.0% | 37.8% |
| Kick | 76.78% | 61.3% | 80.3% | 38.7% | 19.7% |
| Punch | 71.47% | 80.0% | 75.3% | 20.0% | 24.7% |
| Push | 68.63% | 72.5% | 66.7% | 27.5% | 33.3% |
| Weapon | 75.79% | 73.8% | 76.60 % | 26.2% | 23.4% |
| Model Name | Frame Sequence | |||||||
|---|---|---|---|---|---|---|---|---|
| 30 s Clips | 60 s Clips | |||||||
| Accuracy | Precision | Recall | F-1 Score | Accuracy | Precision | Recall | F-1 Score | |
| BiLSTM | 70.45% | 68.41% | 65.41% | 62.40% | 72.45% | 69.74% | 68.41% | 58.41% |
| CNN | 63.47% | 65.71% | 63.91% | 60.84% | 65.44% | 69.71% | 62.48% | 57.94% |
| MLP | 65.71% | 62.78% | 65.46% | 61.75% | 66.78% | 65.17% | 65.17% | 55.17% |
| LSTM | 67.40% | 64.71% | 66.34% | 65.37% | 68.41% | 62.47% | 66.34% | 62.78% |
| Proposed Model | 74.17% | 72.85% | 67.46% | 66.74% | 74.79% | 73.01% | 68.70% | 67.41% |
| Without Mez | With Mez | |||||
|---|---|---|---|---|---|---|
| Time | CPU (%) | Memory (MB) | Disk (MB/s) | CPU (%) | B (MB) | Disk (MB/s) |
| 10 | 0.2 | 151 | 0.10 | 0.1 | 37 | 0.13 |
| 20 | 0.8 | 155 | 0.20 | 0.5 | 47 | 0.13 |
| 30 | 1.1 | 90 | 0.10 | 0.4 | 57 | 0.13 |
| 40 | 1.2 | 78 | 0.30 | 0.1 | 36 | 0.13 |
| 50 | 0.7 | 120 | 0.30 | 0.3 | 50 | 0.07 |
| 60 | 0.7 | 140 | 0.30 | 0.6 | 34 | 0.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Achar, S.; Faruqui, N.; Whaiduzzaman, M.; Awajan, A.; Alazab, M. Cyber-Physical System Security Based on Human Activity Recognition through IoT Cloud Computing. Electronics 2023, 12, 1892. https://doi.org/10.3390/electronics12081892
Achar S, Faruqui N, Whaiduzzaman M, Awajan A, Alazab M. Cyber-Physical System Security Based on Human Activity Recognition through IoT Cloud Computing. Electronics. 2023; 12(8):1892. https://doi.org/10.3390/electronics12081892
Chicago/Turabian StyleAchar, Sandesh, Nuruzzaman Faruqui, Md Whaiduzzaman, Albara Awajan, and Moutaz Alazab. 2023. "Cyber-Physical System Security Based on Human Activity Recognition through IoT Cloud Computing" Electronics 12, no. 8: 1892. https://doi.org/10.3390/electronics12081892