

FM-STDNet: High-Speed Detector for Fast-Moving Small Targets Based on Deep First-Order Network Architecture

Abstract
:1. Introduction
2. Materials and Methods
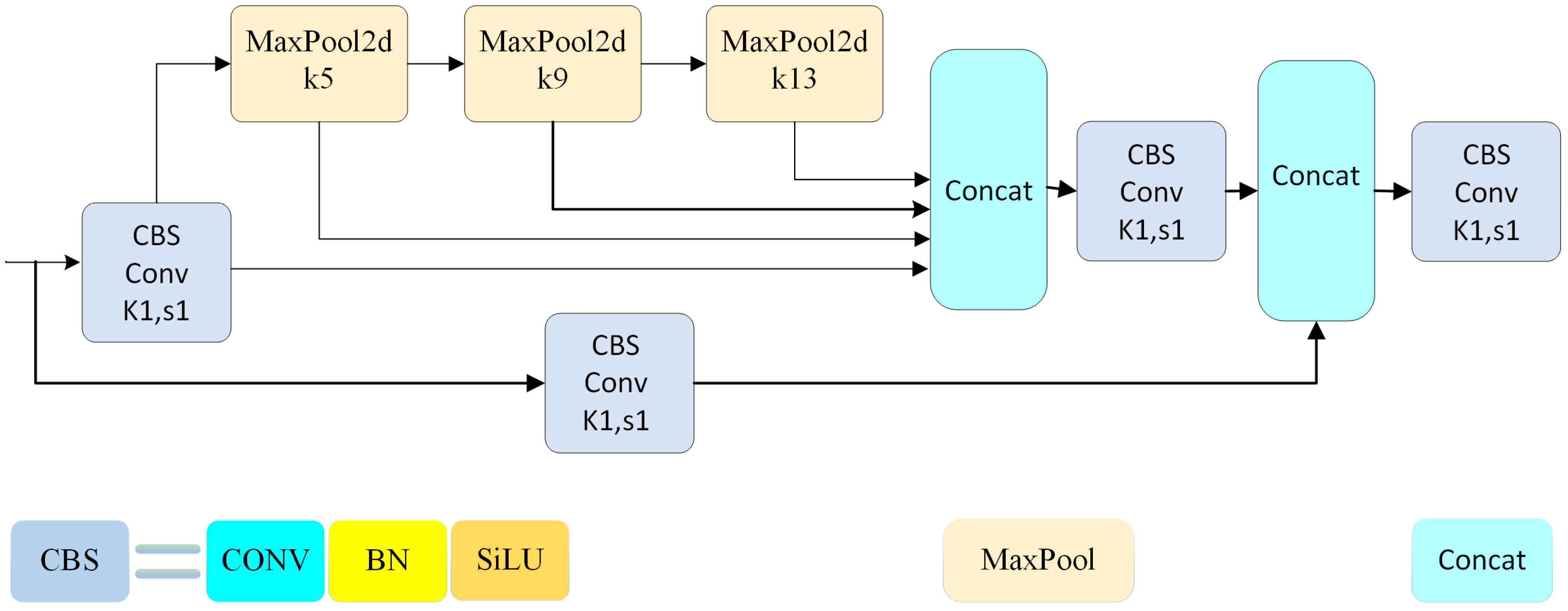
2.1. A Faster Spatial Pyramid Pooling Structure for the New Network SPPFCSP
2.2. A High-Speed Detection Head, RepHead, Based on Structural Re-Parameterization Construction
3. Evaluating the Performance of SPPFCSP and RepHead on a Benchmark Dataset
3.1. Data Set Introduction and Experimental Setup
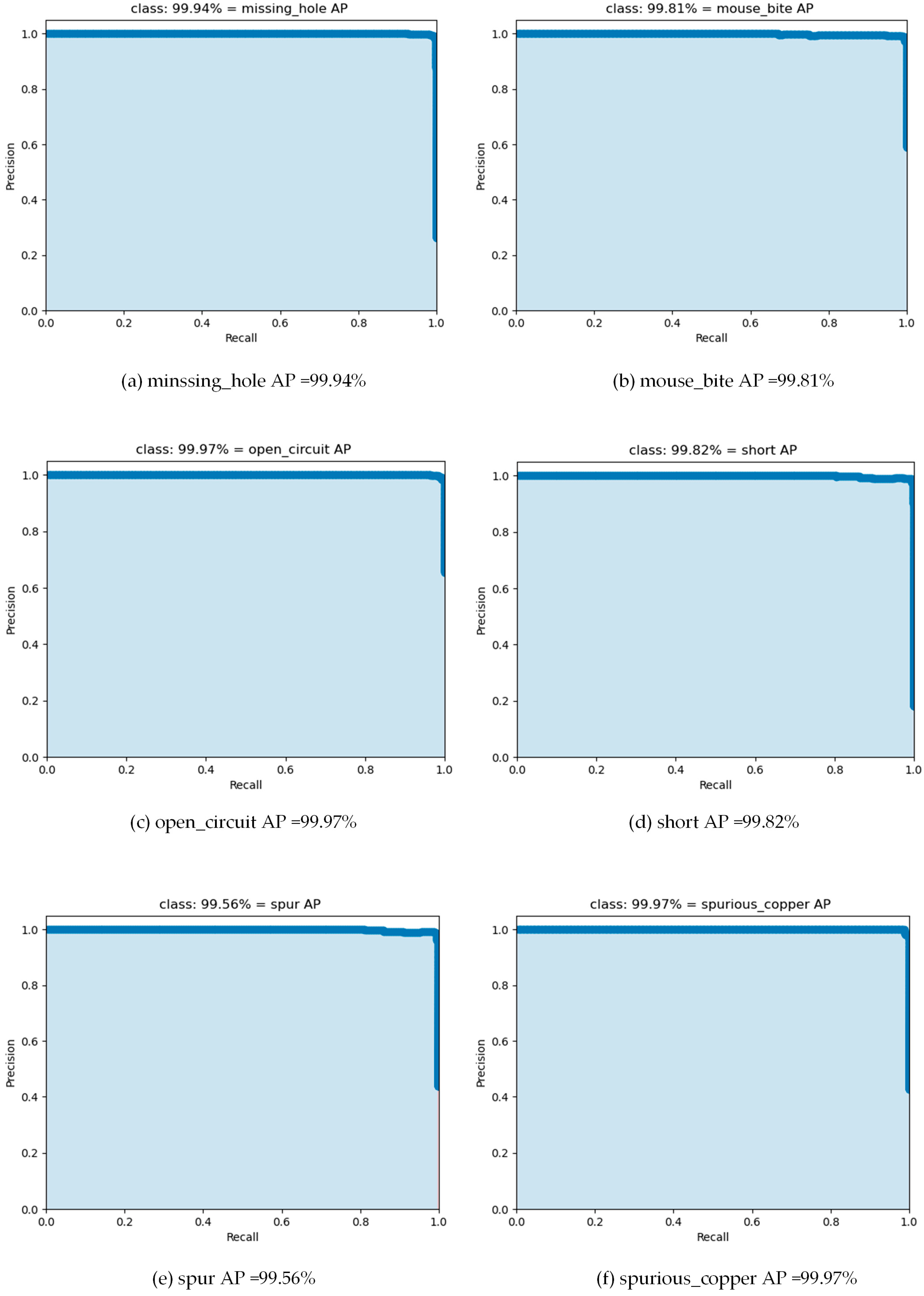
3.2. Evaluation Indicators and Roles
3.3. Ablation Experimental Results and Discussion
- (1)
- When the traditional SPP module is replaced with the SPPFCSP network, there is a 3.1% improvement in the average detection accuracy and 6 FPS in the computational speed, which indicates that SPPFCSP makes better feature fusion between local features and global features, and tandem different scale Maxpool layers give full play to the advantages of the SPPFCSP network structure for fusing different scale features while solving the CNN network’s problem of feature repetition extraction, reducing the model computation, improving the model operation speed, and increasing the detection accuracy.
- (2)
- The prediction part of the YOLOv5-s model is replaced by the prediction part structure of YOLOX-s, which contains four technical points Decoupled Head, Anchor Free, Label Assignment, and FocalLoss. The experimental results show that the YOLOX-s detection accuracy is 1.9% higher than YOLOv5-s, indicating that the Decoupled Head structure of the Anchor Free mode, together with the SimOTA label assignment strategy and the FocalLoss loss function, is more consistent with the feature expression of the YOLO detection framework, but the FLOPs increase, indicating that the YOLOX_Head model increases the model complexity and is not conducive to real-time detection of fast-moving objects.
- (3)
- Structural reparameterization of the YOLOX head part is constructed to obtain the Rep_Head module, and the experimental results show that mAP is improved by 0.1%, FLOPs are decreased by 12.5, and the FPS index is significantly improved by 27, indicating that structural reparameterization can maintain the detection accuracy of the original network while reducing the model complexity and improving the network operation speed. Compared with other methods that simply reduce the number of model parameters to reduce model complexity, the structural reparameterization in the prediction part of the construction does not compress the number of real model parameters, thus allowing the model to maintain the detection accuracy while significantly increasing the model computation speed.
4. Verification of FM-STDNet Network Detection on Fast-Moving Tiny Targets
4.1. FM-STDNet Network Framework Structure
4.2. FM-STDNet Evaluation Results and Discussion
4.2.1. Experimental Platform
4.2.2. Comparison of Detection Results between FM-STDNet and Other Five Excellent Models
4.2.3. Performance Evaluation of FM-STDNet
5. Conclusions and Limitation Statement
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting Tassels in RGB UAV Imagery with Improved YOLOv5 Based on Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Zeng, N.; Wu, P.; Wang, Z.; Li, H.; Liu, W.; Liu, X. A Small-Sized Object Detection Oriented Multi-Scale Feature Fusion Approach with Application to Defect Detection. IEEE Trans. Instrum. Meas. 2022, 71, 3997. [Google Scholar] [CrossRef]
- Sadykova, D.; Pernebayeva, D.; Bagheri, M.; James, A. IN-YOLO: Real-Time Detection of Outdoor High Voltage Insulators Using UAV Imaging. IEEE Trans. Power Deliv. 2020, 35, 1599–1601. [Google Scholar] [CrossRef]
- Gao, K.; Xiao, H.; Qu, L.; Wang, S. Optimal interception strategy of air defence missile system considering multiple targets and phases. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2022, 236, 138–147. [Google Scholar] [CrossRef]
- Haase, D.; Amthor, M. Rethinking Depthwise Separable Convolutions: How Intra-Kernel Correlations Lead to Improved MobileNets. IEEE Xplore 2020, 426, 14588–14597. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. IEEE GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Seattle, WA, USA, 14–19 June 2020; pp. 1577–1586. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. IEEE Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Ren, J.; He, Y.; Yu, G.; Li, G.Y. IEEE Joint Communication and Computation Resource Allocation for Cloud-Edge Collaborative System. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Marrakech, Morocco, 15–19 April 2019. [Google Scholar]
- Chadwick, D.W.; Fan, W.; Costantino, G.; de Lemos, R.; Di Cerbo, F.; Herwono, I.; Manea, M.; Mori, P.; Sajjad, A.; Wang, X.-S. A cloud-edge based data security architecture for sharing and analysing cyber threat information. Future Gener. Comput. Syst. Int. J. Escience 2020, 102, 710–722. [Google Scholar] [CrossRef]
- Xu, M.; Zhu, M.; Liu, Y.; Lin, F.X.; Liu, X. ACM DeepCache: Principled Cache for Mobile Deep Vision. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking (MobiCom), New Delhi, India, 29 October–2 November 2018; pp. 129–144. [Google Scholar]
- Pang, H.; Liu, J.; Fan, X.; Sun, L. Toward Smart and Cooperative Edge Caching for 5G Networks: A Deep Learning Based Approach. In Proceedings of the 26th IEEE/ACM International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018. [Google Scholar]
- Narayanan, A.; Verma, S.; Ramadan, E.; Babaie, P.; Zhang, Z.-L. Making Content Caching Policies ’Smart’ using the DEEPCACHE Framework. ACM SIGCOMM Comput. Commun. Rev. 2018, 48, 64–69. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, Y.; Wu, D.; Hu, M.; Zheng, X.; Chen, M.; Guo, S. Optimizing Video Caching at the Edge: A Hybrid Multi-Point Process Approach. Ieee Trans. Parallel Distrib. Syst. 2022, 33, 2597–2611. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. IEEE You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the 34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. Isprs J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Wei, L.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Cheng-Yang, F.; Berg, A.C. SSD Single Shot MultiBox Detector. Arxiv 2016, 2, 21–37. [Google Scholar] [CrossRef] [Green Version]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. IEEE CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q.; Soc, I.C. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Electr Network, New York, NY, USA, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Ji, W.; Pan, Y.; Xu, B.; Wang, J. A Real-Time Apple Targets Detection Method for Picking Robot Based on ShufflenetV2-YOLOX. Agriculture 2022, 12, 856. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Piscataway, NJ, USA, 19–25 June 2021; pp. 13728–13737. [Google Scholar]
- Daogang, P.; Ming, G.; Danhao, W.; Jie, H. Anomaly Identification of Critical Power Plant Facilities Based on YOLOX-CBAM. In Proceedings of the 2022 Power System and Green Energy Conference (PSGEC), Shanghai, China, 25–27 August 2022; pp. 649–653. [Google Scholar] [CrossRef]
- Dong, R.; Pan, X.; Li, F. DenseU-Net-Based Semantic Segmentation of Objects in Urban Remote Sensing Images. IEEE Access 2019, 7, 65347–65356. [Google Scholar] [CrossRef]
- Liang, S.; Wu, H.; Zhen, L.; Hua, Q.; Garg, S.; Kaddoum, G.; Hassan, M.M.; Yu, K. Edge YOLO: Real-Time Intelligent Object Detection System Based on Edge-Cloud Cooperation in Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25345–25360. [Google Scholar] [CrossRef]
- Ding, R.; Dai, L.; Li, G.; Liu, H. TDD-net: A tiny defect detection network for printed circuit boards. Caai Trans. Intell. Technol. 2019, 4, 110–116. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 2609. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set Item | Parameter |
|---|---|
| Iteration | 200 |
| Batch size | 16 |
| Initial learning rate | 0.1 |
| Min learning rate | 0.0001 |
| Optimizer | SGD |
| momentum | 0.937 |
| Weight decay | 5 × 10−4 |
| Learning rate decay type | COS |
| thread | 4 |
| Algorithm | mAP (%) | GFLOPs | Speed (bs = 1,fps) |
|---|---|---|---|
| YOLOv5-s | 36.7 | 17.1 | 85 |
| +SPPFCSP | 39.8 (+3.1↑) | 15.2 | 91 (+6↑) |
| YOLOX-s | 39.6 (+1.9↑) | 26.8 | 81 |
| +RepHead | 39.7 (+0.1↑) | 14.3 (−12.5↓) | 108 (+27↑) |
| Algorithm | mAP@0.50 (%) | Speed (bs = 1,fps) |
|---|---|---|
| SSD | 95.70 | 46 |
| Faster R-CNN | 91.74 | 37 |
| YOLOv3 | 97.50 | 45 |
| TDD-Net | 98.24 | 62 |
| YOLOX-s | 98.96 | 90 |
| FM-STDNet | 99.85 | 116 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Kong, D.; Liu, X.; Zhang, J.; Zhang, D. FM-STDNet: High-Speed Detector for Fast-Moving Small Targets Based on Deep First-Order Network Architecture. Electronics 2023, 12, 1829. https://doi.org/10.3390/electronics12081829
Hu X, Kong D, Liu X, Zhang J, Zhang D. FM-STDNet: High-Speed Detector for Fast-Moving Small Targets Based on Deep First-Order Network Architecture. Electronics. 2023; 12(8):1829. https://doi.org/10.3390/electronics12081829
Chicago/Turabian StyleHu, Xinyu, Defeng Kong, Xiyang Liu, Junwei Zhang, and Daode Zhang. 2023. "FM-STDNet: High-Speed Detector for Fast-Moving Small Targets Based on Deep First-Order Network Architecture" Electronics 12, no. 8: 1829. https://doi.org/10.3390/electronics12081829