
A Review of the Evaluation System for Curriculum Learning
Abstract
:1. Introduction
- (1)
- Explains the research history of curriculum learning, summarizes its variants and optimization results, and also defines the curriculum learning method.
- (2)
- Classifies and summarizes curriculum learning research for the three major application levels of data, tasks, and models.
- (3)
- Offers a comprehensive summary of the methods of the curriculum learning evaluation system, including the difficulty evaluator (evaluating sample difficulty), the training scheduler (establishing scheduling rules based on sample difficulty), and the loss evaluator (evaluating model performance). Provides theoretical support for the application of curriculum learning to various tasks in the field of machine learning.
2. Basic Theory of Curriculum Learning
2.1. Curriculum Learning Proposal and Development
2.2. Basic Theory
2.3. Method Definition of Curriculum Learning
| Algorithm 1: Curriculum Learning Framework |
| Input: Dataset ; Training set ; Difficulty Measurer ; List ; Training Scheduler ; Loss Scheduler ; Model |
| Output: the optimal model |
| 1: |
| 2: |
| 3: |
| 4: |
| 5: |
| 6: |
| 7: |
| 8: |
| 9: |
| 10: |
3. Difficulty Evaluator
3.1. Heuristic Difficulty Evaluator
3.1.1. Computer Vision
3.1.2. Natural Language Processing
3.1.3. Speech Processing
3.2. Non-Heuristic Difficulty Evaluator
3.2.1. Human Annotation
3.2.2. Self-Scoring
3.2.3. Transfer Learning
3.2.4. Algorithm-Driven
3.2.5. Others
4. Training Scheduler
4.1. Focus on Adjusting the Time of the Sample
4.1.1. Static Scheduling
- (1)
- Speed function control. The velocity function directly controls the sampling speed of the model for simple samples through a monotonic nondecreasing function [135], indicating that the proportion of simple samples sampled increases gradually during model learning, with a large slope indicating a fast model learning speed and a small slope indicating a slow model learning speed. In addition, some of the methods that use the model ability function to control the rate of joining samples also use static scheduling by comparing the estimated ability of the model with the sample difficulty scores, and when the difficulty of a sample is less than or equal to the estimated ability, then that sample is included in the training subset for that period; otherwise, it is not included. Since its function involves only the initial sample proportion, the maximum number of iterations, and the current number of iterations [3] factors, the variation of the model capacity is predefined. This type of function control scheduling method, because the speed is predefined, cannot correspond to faster data addition when the model’s capability is rapidly improving and may lead to model performance degradation when the corresponding model is improving slowly and data is added too fast. The design of this type of function includes the following:
- (2)
- Fixed epochs length. The training model is divided into M stages by adding new samples after a predetermined number of iterations, and the iteration steps of each stage are determined by the initial sample proportion [90], the maximum number of iterations [91], etc. Three scheduling functions—fixed exponential pacing, varied exponential pacing, and single-step pacing—were proposed in the study [90], where the size of the number of iterations per phase is fixed for fixed exponential scheduling and single-step scheduling, and the size of the number of iterations per phase varies for varying exponential scheduling. Figure 7 shows the visualization of the static training scheduler.
4.1.2. Dynamic Scheduling
- (1)
- Based on model convergence. When the model has converged in the previous phase or when the model’s performance has not improved in a certain period, it indicates that the model has learned sufficiently from the previous training set and a new training set should be added to improve the model’s performance. This adjustment strategy is divided into three stages, and in the first stage, only simple and easy-to-learn samples are used for training, allowing the model to learn the underlying knowledge structure of the data from a large number of simple samples and laying the foundation for subsequent learning of more difficult samples, which are mainly low signal-to-noise ratio samples [86], local samples [137], frontal views [138], images containing medium bounding boxes [139], etc. The second stage adds relatively difficult samples for learning, which have mostly noisy labels [93], complex expression and cross-domain samples [20], global samples [137], etc., from which the model can learn more discriminative and meaningful features to improve the model’s performance. After the first two stages of learning, the model has sufficient underlying knowledge, and adding difficult samples in the third stage can effectively improve the generalization ability of the model, which is usually unrelated to the attribute classification labels of images, noisy images, etc. For example, Chen et al. [140] used simple images collected by search engines in the first phase of CNN model training for initializing the network and discovering the structure of similarity relationships in the data, and when the model in the first phase converged, difficult images collected on social platforms were used to fine-tune the original network.
- (2)
- Based on model capability. Based on the relevant parameters used to estimate the potential capability of the model, samples matching the current model capability are selected as the training set for this round of training. When the difficulty of a sample is less than or equal to the ability of the model evaluated in the current training period, the sample will be included in the current training set; otherwise, it will not be included. Section 3.1.1 contains studies related to the static evaluation of model capabilities, with the difference that in this section the model capabilities are evaluated through an adaptive approach rather than a predefined model to calculate model capabilities, with relevant parameters including the norm [143], the degree of loss reduction [25], and the degree of model improvement [27]. For example, Zhou et al. [113] used the Monte Carlo dropout method to approximate the variance of the network probabilistic distribution given by the Bayesian network as the capability of the model. In particular, Lalor et al. proposed [97] the use of Item Response Theory (IRT) for estimating the ability of deep learning models. Item Response Theory (IRT) is a mathematical model used to analyze performance or questionnaire data by testing a large number of subjects and collecting the graded subject responses that are used to estimate the underlying characteristics of the data. The ability to estimate the model by maximizing the likelihood of a given response pattern and sample difficulty in the research of Lalor et al. is similar to the model being validated against a test set. Table 3 summarizes the two types of model capability estimation methods.
4.2. Focus on Adjusting the Weight of the Sample
4.2.1. Direct Weighting
4.2.2. Threshold Weighting

4.3. Focus on Adjusting the Proportion of the Sample
4.3.1. Threshold
4.3.2. Fragment
| Algorithm 2: Mixed Algorithm |
| Input: Dataset ; Training set ; List ; Model |
| Output: the optimal model |
| 1: |
| 2: |
| 3: |
| 4: |
| 5: |
| 6: |
| 7: |
| 8: |
| 9: |
| Algorithm 3: Single Algorithm |
| Input: Dataset ; Training set ; List ; Model |
| Output: the optimal model |
| 1: |
| 2: |
| 3: |
| 4: |
| 5: |
| 6: |
| 7: |
5. Loss Evaluator
6. Discussion
7. Machine Learning Concepts Similar to Curriculum Learning
8. Case Study
9. Summary and Prospects
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Kumar, M.P.; Turki, H.; Preston, D.; Koller, D. Learning specific-class segmentation from diverse data. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1800–1807. [Google Scholar]
- Platanios, E.A.; Stretcu, O.; Neubig, G.; Poczos, B.; Mitchell, T.M. Competence-based curriculum learning for neural machine translation. arXiv 2019, arXiv:1903.09848, 2019. [Google Scholar]
- Manela, B.; Biess, A. Curriculum learning with hindsight experience replay for sequential object manipulation tasks. Neural Netw. 2022, 145, 260–270. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Lu, T.; Cai, Y.; Wang, S. Manipulation skill learning on multi-step complex task based on explicit and implicit curriculum learning. Sci. China Inf. Sci. 2022, 65, 114201. [Google Scholar] [CrossRef]
- Zhao, R.; Chen, X.; Chen, Z.; Li, S. Diagnosing glaucoma on imbalanced data with self-ensemble dual-curriculum learning. Med. Image Anal. 2022, 75, 102295. [Google Scholar] [CrossRef]
- Li, J.; Yang, B.; Yu, T. Distributed deep reinforcement learning-based coordination performance optimization method for proton exchange membrane fuel cell system. Sustain. Energy Technol. Assess. 2022, 50, 101814. [Google Scholar] [CrossRef]
- Li, J.; Geng, J.; Yu, T. Grid-area coordinated load frequency control strategy using large-scale multi-agent deep reinforcement learning. Energy Rep. 2022, 8, 255–274. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, X.; Fan, M.; Huang, J.; Yang, S.; Zhu, W. Curriculum meta-learning for next POI recommendation. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event Singapore, 14–18 August 2021; pp. 2692–2702. [Google Scholar]
- Liu, Z.; Cao, W.; Gao, Z.; Bian, J.; Chen, H.; Chang, Y.; Liu, T.-Y. Self-paced ensemble for highly imbalanced massive data classification. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 841–852. [Google Scholar]
- Sarafianos, N.; Giannakopoulos, T.; Nikou, C.; Kakadiaris, I.A. Curriculum learning of visual attribute clusters for multi-task classification. Pattern Recognit. 2018, 80, 94–108. [Google Scholar] [CrossRef] [Green Version]
- Xu, B.; Zhang, L.; Mao, Z.; Wang, Q.; Xie, H.; Zhang, Y. Curriculum learning for natural language understanding. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6095–6104. [Google Scholar]
- Skinner, B.F. The Behavior of Organisms: An Experimental Analysis; BF Skinner Foundation: Cambridge, MA, USA, 1938. [Google Scholar]
- Krueger, K.A.; Dayan, P. Flexible shaping: How learning in small steps helps. Cognition 2009, 110, 380–394. [Google Scholar] [CrossRef]
- Selfridge, O.G.; Sutton, R.S.; Barto, A.G. Training and Tracking in Robotics. Ijcai 1985, 670–672. [Google Scholar]
- Elman, J.L. Learning and development in neural networks: The importance of starting small. Cognition 1993, 48, 71–99. [Google Scholar] [CrossRef]
- Allgower, E.L.; Georg, K. Numerical Continuation Methods: An Introduction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Kumar, M.; Packer, B.; Koller, D. Self-paced learning for latent variable models. In Proceedings of the 24th Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010. [Google Scholar]
- Spitkovsky, V.I.; Alshawi, H.; Jurafsky, D. From baby steps to leapfrog: How “less is more” in unsupervised dependency parsing. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 751–759. [Google Scholar]
- Jiang, L.; Meng, D.; Yu, S.I.; Lan, Z.; Shan, S.; Hauptmann, A. Self-paced learning with diversity. Adv. Neural Inf. Process. Syst. 2014, 27, 2078–2086. [Google Scholar]
- Jiang, L.; Meng, D.; Zhao, Q.; Shan, S.; Hauptmann, A.G. Self-paced curriculum learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Li, H.; Gong, M.; Meng, D.; Miao, Q. Multi-objective self-paced learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, Y.; Gan, W.; Yang, J.; Wu, W.; Yan, J. Dynamic curriculum learning for imbalanced data classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5017–5026. [Google Scholar]
- Zhao, R.; Chen, X.; Chen, Z.; Li, S. EGDCL: An adaptive curriculum learning framework for unbiased glaucoma diagnosis. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 190–205. [Google Scholar]
- Gan, Z.; Xu, H.; Zan, H. Self-supervised curriculum learning for spelling error correction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 3487–3494. [Google Scholar]
- Dai, Y.; Li, H.; Li, Y.; Sun, J.; Huang, F.; Si, L.; Zhu, X. Preview, attend and review: Schema-aware curriculum learning for multi-domain dialog state tracking. arXiv 2021, arXiv:2106.00291. [Google Scholar]
- Li, S.; Yang, B.; Zou, Y. Adaptive curriculum learning for video captioning. IEEE Access 2022, 10, 31751–31759. [Google Scholar] [CrossRef]
- Matiisen, T.; Oliver, A.; Cohen, T.; Schulman, J. Teacher–student curriculum learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3732–3740. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kesgin, H.T.; Amasyali, M.F. Cyclical Curriculum Learning. arXiv 2022, arXiv:2202.05531. [Google Scholar]
- Yang, Z.Y.; Xia, L.Y.; Zhang, H.; Liang, Y. MSPL: Multimodal self-paced learning for multi-omics feature selection and data integration. IEEE Access 2019, 7, 170513–170524. [Google Scholar] [CrossRef]
- Zhang, D.; Meng, D.; Han, J. Co-saliency detection via a self-paced multiple-instance learning framework. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 865–878. [Google Scholar] [CrossRef]
- Shen, L.; Feng, Y. CDL: Curriculum dual learning for emotion-controllable response generation. arXiv 2020, arXiv:2005.00329. [Google Scholar]
- Zhang, W.; Geng, S.; Fu, Z.; Zheng, L.; Jiang, C.; Hong, S. MetaVA: Curriculum Meta-learning and Pre-fine-tuning of Deep Neural Networks for Detecting Ventricular Arrhythmias based on ECGs. arXiv 2022, arXiv:2202.12450. [Google Scholar]
- Morerio, P.; Cavazza, J.; Volpi, R.; Vidal, R.; Murino, V. Curriculum dropout. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3544–3552. [Google Scholar]
- Dong, Q.; Gong, S.; Zhu, X. Multi-task curriculum transfer deep learning of clothing attributes. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Sanat Rosa, CA, USA, 24–31 March 2017; pp. 520–529. [Google Scholar]
- Tang, Y.P.; Huang, S.J. Self-paced active learning: Query the right thing at the right time. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; Volume 33, pp. 5117–5124. [Google Scholar]
- Ge, Y.; Zhu, F.; Chen, D.; Zhao, R. Self-paced contrastive learning with hybrid memory for domain adaptive object re-id. Adv. Neural Inf. Process. Syst. 2020, 33, 11309–11321. [Google Scholar]
- Pi, T.; Li, X.; Zhang, Z.; Wu, F.; Xiao, J.; Zhuang, Y. Self-paced boost learning for classification. In Proceedings of the 25th International Joint Conference on Artificial Intelligence IJCAI-16, New York, NY, USA, 9–13 July 2016; pp. 1932–1938. [Google Scholar]
- Liu, F.; Tian, Y.; Chen, Y.; Liu, Y. ACPL: Anti-curriculum pseudo-labelling for semi-supervised medical image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 20697–20706. [Google Scholar]
- Cascante-Bonilla, P.; Tan, F.; Qi, Y.; Ordonez, V. Curriculum labeling: Revisiting pseudo-labeling for semi-supervised learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 6912–6920. [Google Scholar]
- Zhang, B.; Wang, Y.; Hou, W.; Wang, J.; Okumura, M.; Shinozaki, T. Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling. Adv. Neural Inf. Process. Syst. 2021, 34, 18408–18419. [Google Scholar]
- Shu, Y.; Cao, Z.; Long, M.; Wang, J. Transferable curriculum for weakly-supervised domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; Volume 33, pp. 4951–4958. [Google Scholar]
- Ma, F.; Meng, D.; Xie, Q.; Li, Z.; Dong, X. Self-paced co-training. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 2275–2284. [Google Scholar]
- Zhan, R.; Liu, X.; Wong, D.F.; Chao, L.S. Meta-curriculum learning for domain adaptation in neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2021; Volume 35, pp. 14310–14318. [Google Scholar]
- Cirik, V.; Hovy, E.; Morency, L.P. Visualizing and understanding curriculum learning for long short-term memory networks. arXiv 2016, arXiv:1611.06204. [Google Scholar]
- Pentina, A.; Sharmanska, V.; Lampert, C.H. Curriculum learning of multiple tasks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5492–5500. [Google Scholar]
- De Buysscher, D.; Pollack, T.; Van Kampen, E.J. Safe Curriculum Learning for Linear Systems with Parametric Unknowns in Primary Flight Control. In Proceedings of the AIAA SCITECH 2022 Forum, San Diego, CA, USA, 3–7 January 2022. [Google Scholar]
- Mao, J.; Gan, C.; Kohli, P.; Tenenbaum, J.B.; Wu, J. The neuro-symbolic concept learner: Interpreting scenes, words, and sentences from natural supervision. arXiv 2019, arXiv:1904.12584. [Google Scholar]
- Ma, H.; Dong, D.; Ding, S.X.; Chen, C. Curriculum-based deep reinforcement learning for quantum control. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Zhang, Y.; David, P.; Foroosh, H.; Gong, B. A curriculum domain adaptation approach to the semantic segmentation of urban scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1823–1841. [Google Scholar] [CrossRef] [Green Version]
- Sarafianos, N.; Giannakopoulos, T.; Nikou, C.; Kakadiaris, I.A. Curriculum learning for multi-task classification of visual attributes. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2608–2615. [Google Scholar]
- Fu, P.; Zhang, D.; Yin, F.; Tang, H. The multi-mode operation decision of cleaning robot based on curriculum learning strategy and feedback network. Neural Comput. Appl. 2022, 34, 9955–9966. [Google Scholar] [CrossRef]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Ayyubi, H.A.; Yao, Y.; Divakaran, A. Progressive Growing of Neural ODEs. arXiv 2020, arXiv:2003.03695. [Google Scholar]
- Sinha, S.; Garg, A.; Larochelle, H. Curriculum by smoothing. Adv. Neural Inf. Process. Syst. 2020, 33, 21653–21664. [Google Scholar]
- Kurmi, V.K.; Bajaj, V.; Subramanian, V.K.; Namboodiri, V.P. Curriculum based dropout discriminator for domain adaptation. arXiv 2019, arXiv:1907.10628. [Google Scholar]
- Sharma, R.; Barratt, S.; Ermon, S.; Pande, V. Improved training with curriculum gans. arXiv 2018, arXiv:1807.09295. [Google Scholar]
- Doan, T.; Monteiro, J.; Albuquerque, I.; Mazoure, B.; Durand, A.; Pineau, J.; Hjelm, R.D. On-line adaptative curriculum learning for gans. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; Volume 33, pp. 3470–3477. [Google Scholar]
- Lee, Y.J.; Grauman, K. Learning the easy things first: Self-paced visual category discovery. In Proceedings of the CVPR 2011, Washington, DC, USA, 20–25 June 2011; pp. 1721–1728. [Google Scholar]
- Zhang, D.; Han, J.; Zhao, L.; Meng, D. Leveraging prior-knowledge for weakly supervised object detection under a collaborative self-paced curriculum learning framework. Int. J. Comput. Vis. 2019, 127, 363–380. [Google Scholar] [CrossRef]
- Oksuz, I.; Ruijsink, B.; Puyol-Antón, E.; Clough, J.R.; Cruz, G.; Bustin, A.; Prieto, C.; Botnar, R.; Rueckert, D.; Schnabel, J.A.; et al. Automatic CNN-based detection of cardiac MR motion artefacts using k-space data augmentation and curriculum learning. Med. Image Anal. 2019, 55, 136–147. [Google Scholar] [CrossRef]
- Pan, Y.; Li, Z.; Zhang, L.; Tang, J. Causal Inference with Knowledge Distilling and Curriculum Learning for Unbiased VQA. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 67. [Google Scholar] [CrossRef]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3867–3876. [Google Scholar]
- Wang, Y.; Perazzi, F.; McWilliams, B.; Sorkine-Hornung, A.; Sorkine-Hornung, O.; Schroers, C. A fully progressive approach to single-image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 864–873. [Google Scholar]
- Tudor Ionescu, R.; Alexe, B.; Leordeanu, M.; Popescu, M.; Papadopoulos, D.P.; Ferrari, V. How hard can it be? Estimating the difficulty of visual search in an image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2157–2166. [Google Scholar]
- Wei, Y.; Liang, X.; Chen, Y.; Shen, X.; Cheng, M.-M.; Feng, J.; Zhao, Y.; Yan, S. Stc: A simple to complex framework for weakly-supervised semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2314–2320. [Google Scholar] [CrossRef] [Green Version]
- Gui, L.; Baltrušaitis, T.; Morency, L.P. Curriculum learning for facial expression recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 505–511. [Google Scholar]
- Zhu, J.; Li, D.; Han, T.; Tian, L.; Shan, Y. Progressface: Scale-aware progressive learning for face detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part 6; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 344–360. [Google Scholar]
- Gao, R.; Grauman, K. On-demand learning for deep image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1086–1095. [Google Scholar]
- Tang, Y.; Wang, X.; Harrison, A.P.; Lu, L.; Xiao, J.; Summers, R.M. Attention-guided curriculum learning for weakly supervised classification and localization of thoracic diseases on chest radiographs. In Proceedings of the Machine Learning in Medical Imaging: 9th International Workshop, MLMI 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 16 September 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 249–258. [Google Scholar]
- Jesson, A.; Guizard, N.; Ghalehjegh, S.H.; Goblot, D.; Soudan, F.; Chapados, N. CASED: Curriculum adaptive sampling for extreme data imbalance. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017; Part III. Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 639–646. [Google Scholar]
- Zhang, Y.; David, P.; Gong, B. Curriculum domain adaptation for semantic segmentation of urban scenes. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2020–2030. [Google Scholar]
- Rajeswar, S.; Subramanian, S.; Dutil, F.; Pal, C.; Courville, A. Adversarial generation of natural language. arXiv 2017, arXiv:1705.10929. [Google Scholar]
- Yu, Y.; Zhang, W.; Hasan, K.; Yu, M.; Xiang, B.; Zhou, B. End-to-end answer chunk extraction and ranking for reading comprehension. arXiv 2016, arXiv:1610.09996. [Google Scholar]
- Tay, Y.; Wang, S.; Tuan, L.A.; Fu, J.; Phan, M.C.; Yuan, X.; Rao, J.; Hui, S.C.; Zhang, A. Simple and effective curriculum pointer-generator networks for reading comprehension over long narratives. arXiv 2019, arXiv:1905.10847. [Google Scholar]
- Kocmi, T.; Bojar, O. Curriculum learning and minibatch bucketing in neural machine translation. arXiv 2017, arXiv:1707.09533. [Google Scholar]
- Tsvetkov, Y.; Faruqui, M.; Ling, W.; MacWhinney, B.; Dyer, C. Learning the curriculum with bayesian optimization for task-specific word representation learning. arXiv 2016, arXiv:1605.03852. [Google Scholar]
- Press, O.; Bar, A.; Bogin, B.; Berant, J.; Wolf, L. Language generation with recurrent generative adversarial networks without pre-training. arXiv 2017, arXiv:1706.01399. [Google Scholar]
- Liu, F.; Ge, S.; Wu, X. Competence-based multimodal curriculum learning for medical report generation. arXiv 2022, arXiv:2206.14579. [Google Scholar]
- Ruiter, D.; van Genabith, J.; España-Bonet, C. Self-induced curriculum learning in self-supervised neural machine translation. arXiv 2020, arXiv:2004.03151. [Google Scholar]
- Wang, W.; Tian, Y.; Ngiam, J.; Yang, Y.; Caswell, I.; Parekh, Z. Learning a multi-domain curriculum for neural machine translation. arXiv 2019, arXiv:1908.10940. [Google Scholar]
- Lu, Y.; Lin, H.; Xu, J.; Han, X.; Tang, J.; Li, A.; Sun, L.; Liao, M.; Chen, S. Text2event: Controllable sequence-to-structure generation for end-to-end event extraction. arXiv 2021, arXiv:2106.09232. [Google Scholar]
- Wang, C.; Wu, Y.; Liu, S.; Zhou, M.; Yang, Z. Curriculum pre-training for end-to-end speech translation. arXiv 2020, arXiv:2004.10093. [Google Scholar]
- Ranjan, S.; Hansen, J.H.L. Curriculum learning based approaches for noise robust speaker recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 26, 197–210. [Google Scholar] [CrossRef]
- Ng, D.; Chen, Y.; Tian, B.; Fu, Q.; Chng, E.S. Convmixer: Feature interactive convolution with curriculum learning for small footprint and noisy far-field keyword spotting. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 3603–3607. [Google Scholar]
- Braun, S.; Neil, D.; Liu, S.C. A curriculum learning method for improved noise robustness in automatic speech recognition. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 548–552. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in English and mandarin. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 173–182. [Google Scholar]
- Takahashi, N.; Singh, M.K.; Mitsufuji, Y. Source Mixing and Separation Robust Audio Steganography. arXiv 2021, arXiv:2110.05054. [Google Scholar]
- Zhang, X.; Kumar, G.; Khayrallah, H.; Murray, K.; Gwinnup, J.; Martindale, M.J.; McNamee, P.; Duh, K.; Carpuat, M. An empirical exploration of curriculum learning for neural machine translation. arXiv 2018, arXiv:1811.00739. [Google Scholar]
- Hacohen, G.; Weinshall, D. On the power of curriculum learning in training deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Vancouver, BC, Canada, 13 October 2019; pp. 2535–2544. [Google Scholar]
- Penha, G.; Hauff, C. Curriculum learning strategies for ir: An empirical study on conversation response ranking. In Proceedings of the Advances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–17 April 2020; Part I. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 699–713. [Google Scholar]
- Weinshall, D.; Cohen, G.; Amir, D. Curriculum learning by transfer learning: Theory and experiments with deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 14–16 November 2018; pp. 5238–5246. [Google Scholar]
- Guo, S.; Huang, W.; Zhang, H.; Zhuang, C.; Dong, D.; Scott, M.R.; Huang, D. Curriculumnet: Weakly supervised learning from large-scale web images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 135–150. [Google Scholar]
- Liu, X.; Zhou, F.; Shen, D.; Wang, S. Deep convolutional neural networks with curriculum learning for facial expression recognition. In Proceedings of the 2019 Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 5925–5932. [Google Scholar]
- Wei, J.; Suriawinata, A.; Ren, B.; Liu, X.; Lisovsky, M.; Vaickus, L.; Brown, C.; Baker, M.; Nasir-Moin, M.; Tomita, N.; et al. Learn like a pathologist: Curriculum learning by annotator agreement for histopathology image classification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 2473–2483. [Google Scholar]
- Jiménez-Sánchez, A.; Mateus, D.; Kirchhoff, S.; Kirchhoff, C.; Biberthaler, P.; Navab, N.; Ballester, M.A.G.; Piella, G. Curriculum learning for improved femur fracture classification: Scheduling data with prior knowledge and uncertainty. Med. Image Anal. 2022, 75, 102273. [Google Scholar] [CrossRef]
- Lalor, J.P.; Yu, H. Dynamic data selection for curriculum learning via ability estimation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; Volume 545. [Google Scholar]
- Zhao, M.; Wu, H.; Niu, D.; Wang, X. Reinforced curriculum learning on pre-trained neural machine translation models. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9652–9659. [Google Scholar]
- Qu, M.; Tang, J.; Han, J. Curriculum learning for heterogeneous star network embedding via deep reinforcement learning. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 468–476. [Google Scholar]
- Narvekar, S.; Peng, B.; Leonetti, M.; Sinapov, J.; Taylor, M.E.; Stone, P. Curriculum learning for reinforcement learning domains: A framework and survey. J. Mach. Learn. Res. 2020, 21, 7382–7431. [Google Scholar]
- Gupta, K.; Mukherjee, D.; Najjaran, H. Extending the capabilities of reinforcement learning through curriculum: A review of methods and applications. SN Comput. Sci. 2022, 3, 28. [Google Scholar] [CrossRef]
- Kumar, G.; Foster, G.; Cherry, C.; Krikun, M. Reinforcement learning based curriculum optimization for neural machine translation. arXiv 2019, arXiv:1903.00041. [Google Scholar]
- Sachan, M.; Xing, E. Self-training for jointly learning to ask and answer questions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Long Papers); Association for Computational Linguistics: New Orleans, LA, USA, 2018; Volume 1, pp. 629–640. [Google Scholar]
- Xiang, L.; Ding, G.; Han, J. Learning from multiple experts: Self-paced knowledge distillation for long-tailed classification. In Computer Vision, Proceedings of the ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part V 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 247–263. [Google Scholar]
- Zhao, Q.; Meng, D.; Jiang, L.; Xie, Q.; Xu, Z.; Hauptmann, A. Self-paced learning for matrix factorization. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Spitkovsky, V.I.; Alshawi, H.; Jurafsky, D. Baby Steps: How “Less is More” in Unsupervised Dependency Parsing; Association for Computational Linguistics: Los Angeles, CA, USA, 2009. [Google Scholar]
- Zhou, T.; Wang, S.; Bilmes, J. Curriculum learning by dynamic instance hardness. Adv. Neural Inf. Process. Syst. 2020, 33, 8602–8613. [Google Scholar]
- Durand, T.; Mehrasa, N.; Mori, G. Learning a deep convnet for multi-label classification with partial labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 647–657. [Google Scholar]
- Kesgin, H.T.; Amasyali, M.F. Development and Comparison of Scoring Functions in Curriculum Learning. In Proceedings of the 2022 2nd International Conference on Computing and Machine Intelligence (ICMI), Istanbul, Turkey, 15–16 July 2022; pp. 1–6. [Google Scholar]
- Zhang, X.; Shapiro, P.; Kumar, G.; McNamee, P.; Carpuat, M.; Duh, K. Curriculum learning for domain adaptation in neural machine translation. arXiv 2019, arXiv:1905.05816. [Google Scholar]
- Guo, M.; Haque, A.; Huang, D.A.; Yeung, S.; Fei-Fei, L. Dynamic task prioritization for multitask learning. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 270–287. [Google Scholar]
- Fan, Y.; He, R.; Liang, J.; Hu, B. Self-paced learning: An implicit regularization perspective. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 6–9 February 2017; Volume 31. [Google Scholar]
- Zhou, Y.; Yang, B.; Wong, D.F.; Wan, Y.; Chao, L.S. Uncertainty-aware curriculum learning for neural machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6934–6944. [Google Scholar]
- Dou, Z.Y.; Anastasopoulos, A.; Neubig, G. Dynamic data selection and weighting for iterative back-translation. arXiv 2020, arXiv:2004.03672. [Google Scholar]
- Wang, W.; Caswell, I.; Chelba, C. Dynamically composing domain-data selection with clean-data selection by “co-curricular learning” for neural machine translation. arXiv 2019, arXiv:1906.01130. [Google Scholar]
- Mousavi, H.; Imani, M.; Ghassemian, H. Deep curriculum learning for polsar image classification. In Proceedings of the 2022 International Conference on Machine Vision and Image Processing (MVIP), Ahvaz, Iran, 23–24 February 2022; pp. 1–5. [Google Scholar]
- Zhou, T.; Wang, S.; Bilmes, J. Robust curriculum learning: From clean label detection to noisy label self-correction. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Guo, J.; Tan, X.; Xu, L.; Qin, T.; Chen, E.; Liu, T.-Y. Fine-tuning by curriculum learning for non-autoregressive neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7839–7846. [Google Scholar]
- Xia, Z.; Zhou, Y.; Yan, F.Y.; Jiang, J. Automatic Curriculum Generation for Learning Adaptation in Networking. arXiv 2022, arXiv:2202.05940. [Google Scholar]
- Maicas, G.; Bradley, A.P.; Nascimento, J.C.; Reid, I.; Carneiro, G. Training medical image analysis systems like radiologists. In Medical Image Computing and Computer Assisted Intervention, Proceedings of the MICCAI 2018: 21st International Conference, Granada, Spain, 16–20 September 2018, Proceedings, Part I; Springer International Publishing: Cham, Switzerland, 2018; pp. 546–554. [Google Scholar]
- Jin, X.; Peng, B.; Wu, Y.; Liu, Y.; Liu, J.; Liang, D.; Yan, J.; Hu, X. Knowledge distillation via route constrained optimization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1345–1354. [Google Scholar]
- Liu, J.; Chen, Y.; Liu, H.; Zhang, H.; Zhang, Y. From Less to More: Progressive Generalized Zero-Shot Detection with Curriculum Learning. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19016–19029. [Google Scholar] [CrossRef]
- Huang, Y.; Du, J. Self-attention enhanced CNNs and collaborative curriculum learning for distantly supervised relation extraction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 389–398. [Google Scholar]
- Soviany, P.; Ardei, C.; Ionescu, R.T.; Leordeanu, M. Image difficulty curriculum for generative adversarial networks (CuGAN). In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 3463–3472. [Google Scholar]
- Shelke, O.; Meisheri, H.; Khadilkar, H. Identifying efficient curricula for reinforcement learning in complex environments with a fixed computational budget. In Proceedings of the 5th Joint International Conference on Data Science & Management of Data (9th ACM IKDD CODS and 27th COMAD), Bangalore, India, 8–10 January 2022; pp. 81–89. [Google Scholar]
- Pang, Z.-J.; Liu, R.-Z.; Meng, Z.-Y.; Zhang, Y.; Yu, Y.; Lu, T. On reinforcement learning for full-length game of starcraft. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 26 January 2019; Volume 33, pp. 4691–4698. [Google Scholar]
- Wu, Y.; Tian, Y. Training agent for first-person shooter game with actor-critic curriculum learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhang, X.; Eseye, A.T.; Knueven, B.; Liu, W.; Reynolds, M.; Jones, W. Curriculum-based Reinforcement Learning for Distribution System Critical Load Restoration. IEEE Trans. Power Syst. 2022; early access. [Google Scholar] [CrossRef]
- Choi, J.; Jeong, M.; Kim, T.; Kim, C. Pseudo-labeling curriculum for unsupervised domain adaptation. arXiv 2019, arXiv:1908.00262. [Google Scholar]
- Liu, Z.; Manh, V.; Yang, X.; Huang, X.; Lekadir, K.; Campello, V.; Ravikumar, N.; Frangi, A.F.; Ni, D. Style curriculum learning for robust medical image segmentation. In Medical Image Computing and Computer Assisted Intervention, Proceedings of the MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021, Proceedings, Part I 24; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 451–460. [Google Scholar]
- Graves, A.; Bellemare, M.G.; Menick, J.; Munos, R.; Kavukcuoglu, K. Automated curriculum learning for neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 1311–1320. [Google Scholar]
- Huang, Y.; Wang, Y.; Tai, Y.; Liu, X.; Shen, P.; Li, S.; Li, J.; Huang, F. Curricularface: Adaptive curriculum learning loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5901–5910. [Google Scholar]
- Ghasedi, K.; Wang, X.; Deng, C.; Huang, H. Balanced self-paced learning for generative adversarial clustering network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4391–4400. [Google Scholar]
- Luo, B.; Feng, Y.; Wang, Z.; Zhu, Z.; Huang, S.; Yan, R.; Zhao, D. Learning with noise: Enhance distantly supervised relation extraction with dynamic transition matrix. arXiv 2017, arXiv:1705.03995. [Google Scholar]
- Wu, X.; Dyer, E.; Neyshabur, B. When do curricula work? arXiv 2020, arXiv:2012.03107. [Google Scholar]
- Jiménez-Sánchez, A.; Mateus, D.; Kirchhoff, S.; Kirchhoff, C.; Biberthaler, P.; Navab, N.; Ballester, M.A.G.; Piella, G. Medical-based deep curriculum learning for improved fracture classification. In Medical Image Computing and Computer Assisted Intervention. Proceedings of the MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019, Proceedings, Part VI 22; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 694–702. [Google Scholar]
- Haarburger, C.; Baumgartner, M.; Truhn, D.; Broeckmann, M.; Schneider, H.; Schrading, S.; Kuhl, C.; Merhof, D. Multi scale curriculum CNN for context-aware breast MRI malignancy classification. In Medical Image Computing and Computer Assisted Intervention, Proceedings of the MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019, Proceedings, Part IV 22; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 495–503. [Google Scholar]
- Chung, J.S.; Zisserman, A.P. Lip reading in profile. In Proceedings of the BMVC 2017, London, UK, 4–7 September 2017. [Google Scholar]
- Liu, Y.; Shi, M.; Zhao, Q.; Wang, X. Point in, box out: Beyond counting persons in crowds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6469–6478. [Google Scholar]
- Chen, X.; Gupta, A. Webly supervised learning of convolutional networks. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 1431–1439. [Google Scholar]
- Boroumand, M.; Chen, M.; Fridrich, J. Deep residual network for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1181–1193. [Google Scholar] [CrossRef]
- Ye, J.; Ni, J.; Yi, Y. Deep learning hierarchical representations for image steganalysis. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2545–2557. [Google Scholar] [CrossRef]
- Liu, X.; Lai, H.; Wong, D.F.; Chao, L.S. Norm-based curriculum learning for neural machine translation. arXiv 2020, arXiv:2006.02014. [Google Scholar]
- Agrawal, S.; Carpuat, M. An Imitation Learning Curriculum for Text Editing with Non-Autoregressive Models. arXiv 2022, arXiv:2203.09486. [Google Scholar]
- Liu, C.; He, S.; Liu, K.; Zhao, J. Curriculum Learning for Natural Answer Generation. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 4223–4229. [Google Scholar]
- Jiang, L.; Zhou, Z.; Leung, T.; Fei-Fei, L. Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2304–2313. [Google Scholar]
- Luo, J.; Kitamura, G.; Doganay, E.; Arefan, D.; Wu, S. Medical knowledge-guided deep curriculum learning for elbow fracture diagnosis from x-ray images. In Proceedings of the Medical Imaging 2021: Computer-Aided Diagnosis, Online, 15–19 February 2021; Volume 11597, pp. 247–252. [Google Scholar]
- Luo, J.; Kitamura, G.; Arefan, D.; Doganay, E.; Panigrahy, A.; Wu, S. Knowledge-guided multiview deep curriculum learning for elbow fracture classification. In Machine Learning in Medical Imaging, Proceedings of the 12th International Workshop, MLMI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, 27 September 2021, Proceedings 12; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 555–564. [Google Scholar]
- Gao, H.; Huang, H. Self-paced network embedding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1406–1415. [Google Scholar]
- Xu, W.; Liu, W.; Chi, H.; Qiu, S.; Jin, Y. Self-paced learning with privileged information. Neurocomputing 2019, 362, 147–155. [Google Scholar] [CrossRef]
- Jiang, L.; Meng, D.; Mitamura, T.; Hauptmann, A.G. Easy samples first: Self-paced reranking for zero-example multimedia search. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 547–556. [Google Scholar]
- Li, C.; Yan, J.; Wei, F.; Dong, W.; Liu, Q.; Zha, H. Self-paced multi-task learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Gong, M.; Li, H.; Meng, D.; Miao, Q.; Liu, J. Decomposition-based evolutionary multiobjective optimization to self-paced learning. IEEE Trans. Evol. Comput. 2018, 23, 288–302. [Google Scholar] [CrossRef]
- Han, L.; Zhang, D.; Huang, D.; Chang, X.; Ren, J.; Luo, S.; Han, J. Self-paced Mixture of Regressions. In Proceedings of the IJCAI 2017, Melbourne, Australia, 19–25 August 2017; pp. 1816–1822. [Google Scholar]
- Li, C.; Wei, F.; Yan, J.; Zhang, X.; Liu, Q.; Zha, H. A self-paced regularization framework for multilabel learning. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 2660–2666. [Google Scholar] [CrossRef] [Green Version]
- Zhou, D.; He, J.; Yang, H.; Fan, W. Sparc: Self-paced network representation for few-shot rare category characterization. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2807–2816. [Google Scholar]
- Wang, C.; Jin, S.; Guan, Y.; Liu, W.; Qian, C.; Luo, P.; Ouyang, W. Pseudo-labeled auto-curriculum learning for semi-supervised keypoint localization. arXiv 2022, arXiv:2201.08613. [Google Scholar]
- Florensa, C.; Held, D.; Wulfmeier, M.; Zhang, M.; Abbeel, P. Reverse curriculum generation for reinforcement learning. In Proceedings of the Conference on Robot Learning, PMLR, Seoul, Republic of Korea, 15–17 November 2017; pp. 482–495. [Google Scholar]
- Havaei, M.; Guizard, N.; Chapados, N.; Bengio, Y. Hemis: Hetero-modal image segmentation. In Medical Image Computing and Computer-Assisted Intervention, Proceedings of the MICCAI 2016: 19th International Conference, Athens, Greece, 17–21 October 2016, Proceedings, Part II 19; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 469–477. [Google Scholar]
- Zhang, D.; Kim, J.; Crego, J.; Senellart, J. Boosting neural machine translation. arXiv 2016, arXiv:1612.06138. [Google Scholar]
- Lyu, Y.; Tsang, I.W. Curriculum loss: Robust learning and generalization against label corruption. arXiv 2019, arXiv:1905.10045. [Google Scholar]
- Wu, L.; Tian, F.; Xia, Y.; Fan, Y.; Qin, T.; Lai, J.; Liu, T.-Y. Learning to teach with dynamic loss functions. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2018; Volume 31. [Google Scholar]
- Li, X.; Wen, L.; Deng, Y.; Feng, F.; Hu, X.; Wang, L.; Fan, Z. Graph neural network with curriculum learning for imbalanced node classification. arXiv 2022, arXiv:2202.02529. [Google Scholar]
- Yao, X.; Feng, X.; Han, J.; Cheng, G.; Li, K. Automatic weakly supervised object detection from high spatial resolution remote sensing images via dynamic curriculum learning. IEEE Trans. Geosci. Remote Sens. 2020, 59, 675–685. [Google Scholar] [CrossRef]
- Saxena, S.; Tuzel, O.; DeCoste, D. Data parameters: A new family of parameters for learning a differentiable curriculum. In Proceedings of the 33nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2019; Volume 32. [Google Scholar]
- Korbar, B.; Tran, D.; Torresani, L. Cooperative learning of audio and video models from self-supervised synchronization. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2018; Volume 31. [Google Scholar]
- Wang, X.; Chen, Y.; Zhu, W. A survey on curriculum learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4555–4576. [Google Scholar] [CrossRef]
- Soviany, P.; Ionescu, R.T.; Rota, P.; Sebe, N. Curriculum learning: A survey. Int. J. Comput. Vis. 2022, 130, 1526–1565. [Google Scholar] [CrossRef]
- Chang, H.S.; Learned-Miller, E.; McCallum, A. Active bias: Training more accurate neural networks by emphasizing high variance samples. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Amiri, H. Neural self-training through spaced repetition. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 21–31. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
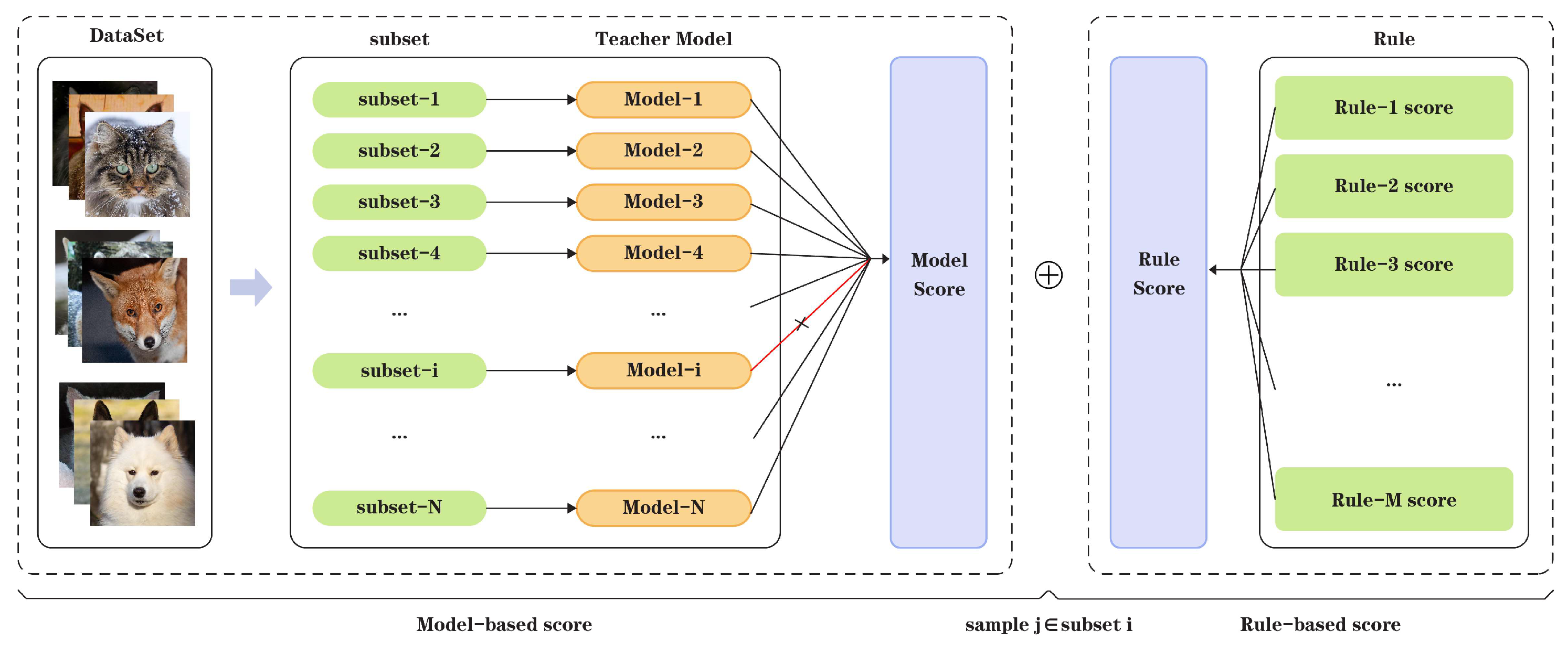{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
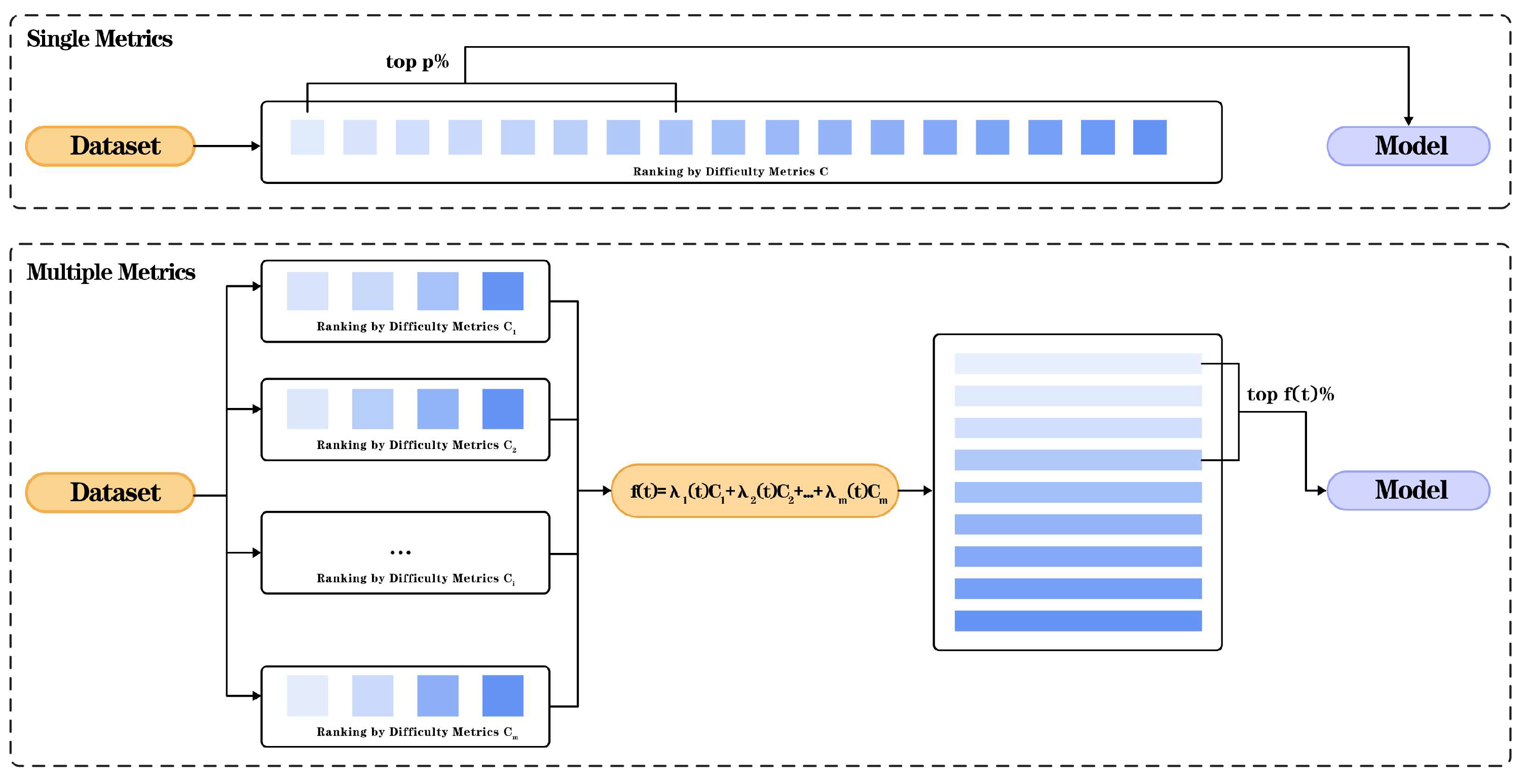{kind=link}
{kind=link}








| Method | Characteristic | Ref. | |
|---|---|---|---|
| Self-Scoring | Using the model to output scores | [26,32] [89,90] [17,18] | |
| Transfer Learning | Using external models to guide knowledge transfer | [90,91,92] [35,46] | |
| Algorithm Driven | Grouping of data by algorithm | [93,94] [11] [89] | |
| Human Annotation | Leverage expert knowledge with high manual workload | [95,96,97] | |
| Others | Reinforced Learning | Take a series of actions to maximize the cumulative rewards | [98,99,100,101,102] |
| Direct Calculation | Direct calculation of certain types of features for sorting | [23,79] [103,104] | |
| Method | Advantages | Disadvantages | Ref. | |
|---|---|---|---|---|
| Dynamic | Model Convergence | Matching with model learning progress | - | [93,94] |
| Model Competence | Relate model capabilities to sampling and rationalize the selection of samples that the epochs model can learn | - | [113] | |
| Static | Function | No manual adjustment during training | The speed of adding samples does not match the speed of lifting the model | [3,23] [91] |
| Fixed epochs | Difficult to accurately estimate the step length | [90,91] |
| Method | Ref. | |
|---|---|---|
| Dynamic | Maximizing the likelihood of the data given the response patterns and the sample difficulties to obtain the ability estimate. | [97] |
| Use the Monte Carlo Dropout to approximate Bayesian inference, which places a probabilistic distribution over the model parameters on constant input and output data (variance result). | [113] | |
| function (the parameters include loss reduction/improvement of the model). | [25,27] | |
| Root function (the parameters include norm/initial value/task-independent hyperparameter). | [143] | |
| Static | Linear/root function (the parameters include the maximum epochs/initial value). | [3,144] |
| Evaluator | Methods | Select Preferences |
|---|---|---|
| Difficulty evaluator | Heuristic | Multidimensional heuristic difficulty evaluators outperform single scales, and this type of evaluator is more suitable for tasks that rely on expert knowledge, such as in the medical domain. |
| Non-heuristic | More suitable for most scenarios that are unfamiliar with datasets and do not depend on specific datasets and tasks. | |
| Training scheduler | time | Root functions outperform other functions, and square root functions outperform the rest of the root functions. |
| Dynamic model capability evaluators outperform static. | ||
| weight | Dynamic thresholding outperforms thresholding with fixed parameters. | |
| proportion | Multiple metric thresholds are more comprehensive than single metric thresholds. | |
| Loss evaluator | Evaluating the model’s learning progress at each stage is better than not evaluating it. |
| Method | WebVision | Select Preferences | ||
|---|---|---|---|---|
| Top-1 | Top-5 | Top-5 | Top-1 | |
| Using the whole dataset | 30.16 | 12.43 | 36.00 | 16.20 |
| Only using the clean subset | 30.28 | 12.98 | 37.09 | 16.42 |
| Using the proposed curriculum learning strategy on: clean and noisy subsets | 28.44 | 11.38 | 35.66 | 15.24 |
| Using the proposed curriculum learning strategy on: clean, noisy, and highly noisy subsets | 27.91 | 10.82 | 35.24 | 15.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Zhang, T.; Zhang, C.; Liu, L.; Wang, L.; Liu, B. A Review of the Evaluation System for Curriculum Learning. Electronics 2023, 12, 1676. https://doi.org/10.3390/electronics12071676
Liu F, Zhang T, Zhang C, Liu L, Wang L, Liu B. A Review of the Evaluation System for Curriculum Learning. Electronics. 2023; 12(7):1676. https://doi.org/10.3390/electronics12071676
Chicago/Turabian StyleLiu, Fengchun, Tong Zhang, Chunying Zhang, Lu Liu, Liya Wang, and Bin Liu. 2023. "A Review of the Evaluation System for Curriculum Learning" Electronics 12, no. 7: 1676. https://doi.org/10.3390/electronics12071676