

Stretching Deep Architectures: A Deep Learning Method without Back-Propagation Optimization

Abstract
:1. Introduction
2. Related Work
3. Stretching Deep Architecture
3.1. Feature Learning Models
- (1)
- PCA [24] is a linear dimensionality reduction algorithm. Assume that the data have zero mean. PCA uses the eigenvectors corresponding to the d largest eigenvalues of the data covariance matrix to form the projection matrix;
- (2)
- PPCA is a probabilistic variant of PCA from the perspective of Gaussian latent variable models [36]. It is often effective when there are missing values in the training data;
- (3)
- Sammon [37] is a nonlinear feature learning model. It performs dimensionality reduction while preserving the structure of inter-point distances in high-dimensional data space;
- (4)
- SNE [38] changes the idea of distance-invariant in MDS, mapping data from high-dimensional space to low-dimensional space while ensuring that the data distribution is not changed. SNE treats data distributions in both the high- and low-dimensional space as Gaussian;
- (5)
- MDS [39] linearly maps the high-dimensional data to a low-dimensional space, while retaining the pairwise distances between data points as much as possible;
- (6)
- LDA [25] seeks a linear projection that simultaneously minimizes the within-class scatter and maximizes the between-class scatter to separate the classes;
- (7)
- MFA is one special formulation of the graph embedding framework [40]. It utilizes an intrinsic graph to characterize the intraclass compactness, and another penalty graph to characterize the interclass separability.
3.2. Stretching
3.3. Stretching Deep Architectures
4. Experimental Results
4.1. Result on Texture Data Sets
4.1.1. Psychophysical Experiments
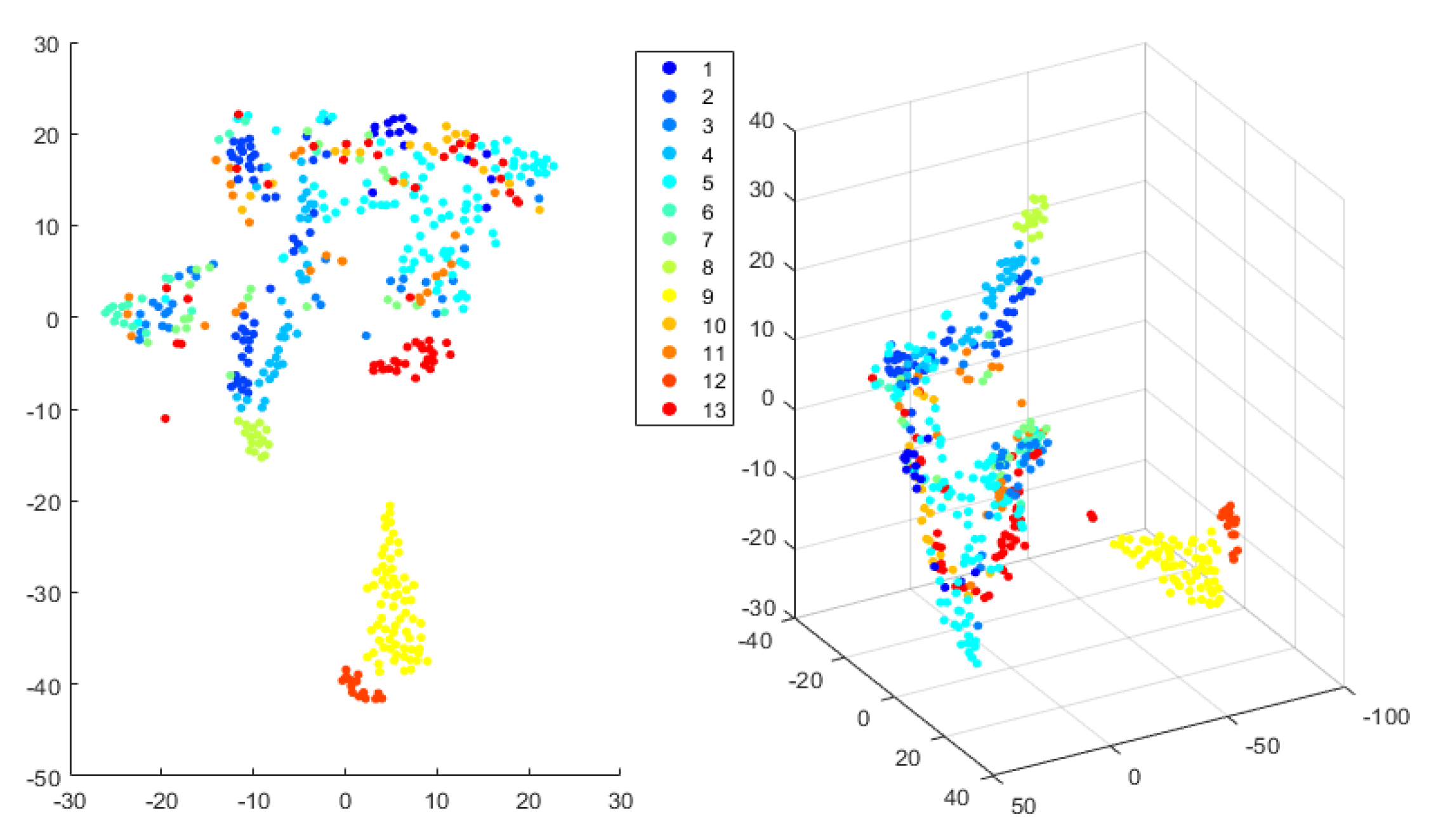
4.1.2. Visualization
4.1.3. Classification Results
4.2. Experimental Results on Handwritten Text Data Sets
4.2.1. Results on the USPS Data Set
4.2.2. Results on the Ibn Sina Data Set
4.2.3. Results on the Letter Data Set
4.3. Classification of the Cifar-10 Data Set
4.4. Improving the Effectiveness of CNNs
4.5. Evaluation of the Number of Feature Learning Layers
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, K.; Salman, A. Learning Speaker-Specific Characteristics with a Deep Neural Architecture. Neural Netw. IEEE Trans. 2011, 22, 1744–1756. [Google Scholar] [CrossRef]
- Stuhlsatz, A.; Lippel, J.; Zielke, T. Feature Extraction with Deep Neural Networks by a Generalized Discriminant Analysis. Neural Netw. Learn. Syst. IEEE Trans. 2012, 23, 596–608. [Google Scholar] [CrossRef]
- Yuan, M.; Tang, H.; Li, H. Real-Time Keypoint Recognition Using Restricted Boltzmann Machine. Neural Netw. Learn. Syst. IEEE Trans. 2014, 25, 2119–2126. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. Pattern Anal. Mach. Intell. IEEE Trans. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deerwester, S.; Dumais, S.; Landauer, T.; Furnas, G.; Harshman, R. Indexing by Latent Semantic Analysis. JASIS 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Landauer, T.; Foltz, P.; Laham, D. An Introduction to Latent Semantic Analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar] [CrossRef]
- Hinton, G.; Salakhutdinov, R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ainsworth, S. DeFT: A Conceptual Framework for Considering Learning with Multiple Representations. Learn. Instr. 2006, 16, 183–198. [Google Scholar] [CrossRef]
- Bengio, Y. Learning Deep Architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A. Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations. In Proceedings of the ICML, Montreal, QC, Canada, 14–18 June 2009; ACM: New York, NY, USA, 2009; pp. 609–616. [Google Scholar]
- Xiao, M.; Guo, Y. A Novel Two-Step Method for Cross Language Representation Learning. In Proceedings of the NIPS, Lake Tahoe, NY, USA, 5–10 December 2013; pp. 1259–1267. [Google Scholar]
- Huang, P.S.; He, X.; Gao, J.; Deng, L.; Acero, A.; Heck, L. Learning Deep Structured Semantic Models for Web Search Using Clickthrough Data. In Proceedings of the CIKM, San Francisco, CA, USA, 27 October–1 November 2013; ACM: New York, NY, USA, 2013; pp. 2333–2338. [Google Scholar]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. Learning Semantic Representations Using Convolutional Neural Networks for Web Search. In Proceedings of the WWW, Seoul, Republic of Korea, 7–11 April 2014; pp. 373–374. [Google Scholar]
- Oveis, A.H.; Giusti, E.; Ghio, S.; Martorella, M. A Survey on the Applications of Convolutional Neural Networks for Synthetic Aperture Radar: Recent Advances. IEEE Aerosp. Electron. Syst. Mag. 2022, 37, 18–42. [Google Scholar] [CrossRef]
- Landy, M.; Graham, N. Visual Perception of Texture. In Proceedings of the Visual Neurosciences; MIT Press: Cambridge, MA, USA, 2004; pp. 1106–1118. [Google Scholar]
- Heeger, D.; Bergen, J. Pyramid-based Texture Analysis/Synthesis. In Proceedings of the SIGGRAPH, Los Angeles, CA, USA, 6–11 August 1995; ACM: New York, NY, USA, 1995; pp. 229–238. [Google Scholar]
- Rao, A.; Lohse, G. Towards a Texture Naming System: Identifying Relevant Dimensions of Texture. Vis. Res. 1996, 36, 1649–1669. [Google Scholar]
- Wolfson, S.; Landy, M. Examining Edge- and Region-based Texture Mechanisms. Vis. Res. 1998, 38, 439–446. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gurnsey, R.; Fleet, D. Texture Space. Vis. Res. 2001, 41, 745–757. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingdom, F.; Hayes, A.; Field, D. Sensitivity to Contrast Histogram Differences in Synthetic Wavelet-Textures. Vis. Res. 2001, 41, 585–598. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Durgin, F. Texture Contrast Aftereffects Are Monocular, Texture Density Aftereffects Are Binocular. Vis. Res. 2001, 41, 2619–2630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, Y.; Zhong, G.; Liu, J.; Cai, X.; Dong, J. Visual Texture Perception with Feature Learning Models and Deep Architectures. In Pattern Recognition, Proceedings of the 6th Chinese Conference, CCPR 2014, Changsha, China, 17–19 November 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 401–410. [Google Scholar]
- Liu, J.; Dong, J.; Cai, X.; Q, L.; Chantler, M. Visual Perception of Procedural Textures: Identifying Perceptual Dimensions and Predicting Generation Models. PLoS ONE 2015, 10, e0130335. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jolliffe, I. Principal Component Analysis, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Fisher, R. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- van der Maaten, L.; Postma, E.; van den Herik, H. Dimensionality Reduction: A Comparative Review. J. Mach. Learn. Res. 2009, 10, 66–71. [Google Scholar]
- van der Maaten, L. An Introduction to Dimensionality Reduction Using Matlab. Report 2007, 1201, 62. [Google Scholar]
- Salakhutdinov, R.; Hinton, G. Deep Boltzmann Machines. In Proceedings of the AISTATS, Clearwater, FL, USA, 16–19 April 2009; pp. 448–455. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the NIPS, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Yin, F.; Wang, Q.F.; Zhang, X.Y.; Liu, C.L. ICDAR 2013 Chinese Handwriting Recognition Competition. In Proceedings of the ICDAR, Washington, DC, USA, 25–28 August 2013; pp. 1464–1470. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, L.N.; Zhong, G.; Gao, W.; Jiao, W.; Dong, J.; Shen, B.; Xia, D.; Xiang, W. Adaptive Gabor Convolutional Networks. Pattern Recognit. 2022, 124, 108495. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A Review on the Attention Mechanism of Deep Learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Tipping, M.; Bishop, C. Probabilistic Principal Component Analysis. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 1999, 61, 611–622. [Google Scholar] [CrossRef] [Green Version]
- Sammon, J. A Nonlinear Mapping for Data Structure Analysis. IEEE Trans. Comput. 1969, 18, 401–409. [Google Scholar] [CrossRef]
- Hinton, G.; Roweis, S. Stochastic Neighbor Embedding. In Proceedings of the NIPS, Vancouver, BC, Canada, 9–14 December 2002; Volume 2, pp. 833–840. [Google Scholar]
- Kruskal, J.; Wish, M. Multidimensional Scaling; Sage: New York, NY, USA, 1978; Volume 11. [Google Scholar]
- Yan, S.; Xu, D.; Zhang, B.; Zhang, H.J.; Yang, Q.; Lin, S. Graph Embedding and Extensions: A General Framework for Dimensionality Reduction. Pattern Anal. Mach. Intell. IEEE Trans. 2007, 29, 40–51. [Google Scholar] [CrossRef] [Green Version]
- Zhong, G.; Chherawala, Y.; Cheriet, M. An Empirical Evaluation of Supervised Dimensionality Reduction for Recognition. In Proceedings of the ICDAR, Washington, DC, USA, 25–28 August 2013; pp. 1315–1319. [Google Scholar]
- Pandey, G.; Dukkipati, A. Learning by Stretching Deep Networks. In Proceedings of the ICML, Beijing, China, 21–26 June 2014; pp. 1719–1727. [Google Scholar]
- Zheng, Y.; Cai, Y.; Zhong, G.; Chherawala, Y.; Shi, Y.; Dong, J. Stretching Deep Architectures for Text Recognition. In Proceedings of the ICDAR, Tunis, Tunisia, 23–26 August 2015; pp. 236–240. [Google Scholar]
- Ranzato, M.; Boureau, Y.; LeCun, Y. Sparse Feature Learning for Deep Belief Networks. In Proceedings of the NIPS, Vancouver, BC, Canada, 3–6 December 2007; pp. 1185–1192. [Google Scholar]
- Lee, H.; Pham, P.; Largman, Y.; Ng, A. Unsupervised Feature Learning for Audio Classification Using Convolutional Deep Belief Networks. In Proceedings of the NIPS, Vancouver, BC, Canada, 7–10 December 2009; pp. 1096–1104. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A Simple Deep Learning Baseline for Image Classification? Image Process. IEEE Trans. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [Green Version]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Julesz, B. Experiments in the visual perception of texture. Sci. Am. 1975, 232, 34–43. [Google Scholar] [CrossRef]
- Julesz, B. Textons, the elements of texture perception, and their interactions. Nature 1981, 290, 91–97. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.F.; Ren, C.X.; Dai, D.Q.; Huang, K.K. Kernel Embedding Multiorientation Local Pattern for Image Representation. IEEE Trans. Cybern. 2017, 48, 1124–1135. [Google Scholar] [CrossRef] [PubMed]
- Ji, L.; Ren, Y.; Liu, G.; Pu, X. Training-Based Gradient LBP Feature Models for Multiresolution Texture Classification. IEEE Trans. Cybern. 2017, 48, 2683–2696. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Liwicki, M.; Fernandez, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A Novel Connectionist System for Unconstrained Handwriting Recognition. Pattern Anal. Mach. Intell. IEEE Trans. 2009, 31, 855–868. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Schmidhuber, J. Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks. In Proceedings of the NIPS, Vancouver, BC, Canada, 7–10 December 2009; pp. 545–552. [Google Scholar]
- Graves, A. Generating Sequences with Recurrent Neural Networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Liu, C.L.; Yin, F.; Wang, D.H.; Wang, Q.F. Online and Offline Handwritten Chinese Character Recognition: Benchmarking on New Databases. Pattern Recognit. 2013, 46, 155–162. [Google Scholar] [CrossRef]
- Zeiler, M.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the ECCV, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Du, B.; Xiong, W.; Wu, J.; Zhang, L.; Zhang, L.; Tao, D. Stacked Convolutional Denoising Auto-Encoders for Feature Representation. IEEE Trans. Cybern. 2017, 47, 1017–1027. [Google Scholar] [CrossRef]
- Qiao, H.; Li, Y.; Li, F.; Xi, X.; Wu, W. Biologically Inspired Model for Visual Cognition Achieving Unsupervised Episodic and Semantic Feature Learning. IEEE Trans. Cybern. 2016, 46, 2335–2347. [Google Scholar] [CrossRef] [PubMed]
- Gama, J.; Brazdil, P. Cascade Generalization. Mach. Learn. 2000, 41, 315–343. [Google Scholar] [CrossRef]
- Zhao, H.; Ram, S. Constrained Cascade Generalization of Decision Trees. Knowl. Data Eng. IEEE Trans. 2004, 16, 727–739. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Robust Real-time Object Detection. Int. J. Comput. Vis. 2001, 4. [Google Scholar]
- Minguillón, J. On Cascading Small Decision Trees. Ph.D. Thesis, Universitat Autònoma de Barcelona, Barcelona, Spain, 2002. [Google Scholar]
- Pang, Y.; Cao, J.; Li, X. Cascade Learning by Optimally Partitioning. IEEE Trans. Cybern. 2017, 47, 4148–4161. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zha, H. Principal Manifolds and Nonlinear Dimensionality Reduction via Tangent Space Alignment. SIAM J. Sci. Comput. 2004, 26, 313–338. [Google Scholar] [CrossRef] [Green Version]
- Zhong, G.; Li, W.J.; Yeung, D.Y.; Hou, X.; Liu, C.L. Gaussian Process Latent Random Field. In Proceedings of the AAAI, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Zhong, G.; Liu, C.L. Error-Correcting Output Codes Based Ensemble Feature Extraction. Pattern Recognit. 2013, 46, 1091–1100. [Google Scholar] [CrossRef]
- Zhong, G.; Cheriet, M. Large Margin Low Rank Tensor Analysis. Neural Comput. 2014, 26, 761–780. [Google Scholar] [CrossRef] [Green Version]
- Cho, Y.; Saul, L. Large-Margin Classification in Infinite Neural Networks. Neural Comput. 2010, 22, 2678–2697. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Dong, J.; Qi, L.; Chantler, M. Identifying Perceptual Features of Procedural Textures. In Proceedings of the ECVP, Bremen, Germany, 25–29 August 2013. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Lin, S.W.; Ying, K.C.; Chen, S.C.; Lee, Z.J. Particle Swarm Optimization for Parameter Determination and Feature Selection of Support Vector Machines. Expert Syst. Appl. 2008, 35, 1817–1824. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
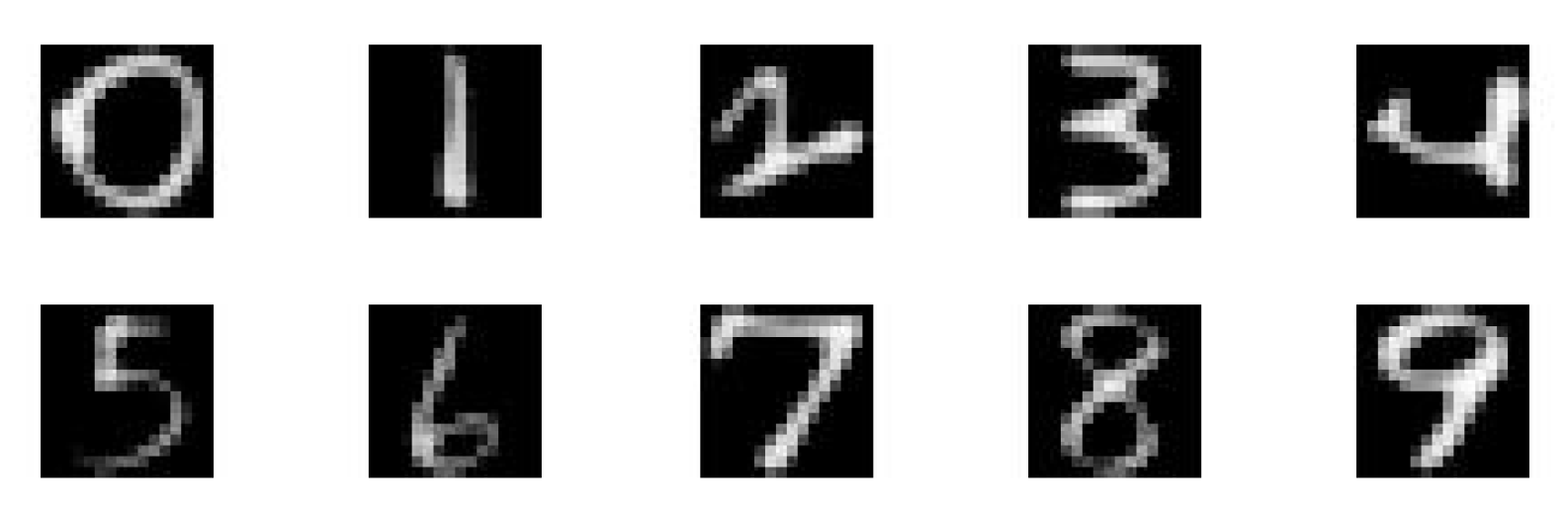{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Shallow | Deep | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ORIG | 0.5524 ±0.2302 | - - | - - | - - | - - | - - | - - | - - | - - |
| Autoencoder | - - | 0.3984 ±0.1116 | - - | - - | - - | - - | - - | - - | - - |
| LeNet | - - | 0.4214 ±0.1008 | - - | - - | - - | - - | - - | - - | - - |
| PCANet | - - | 0.4691 ±0.0854 | - - | - - | - - | - - | - - | - - | - - |
| PCA | 0.4388 ±0.2178 | 0.4215 ±0.2408 | 0.5578 ±0.0617 | 0.5640 ±0.0264 | 0.6217 ±0.0673 | 0.6266 ±0.0649 | 0.6168 ±0.0609 | 0.6109 ±0.0562 | 0.4228 ±0.0365 |
| PPCA | 0.3226 ±0.1947 | 0.3115 ±0.0623 | 0.3215 ±0.0980 | 0.3885 ±0.0620 | 0.3730 ±0.0445 | 0.3966 ±0.0531 | 0.4175 ±0.1144 | 0.3829 ±0.0491 | 0.2404 ±0.0507 |
| MDS | 0.4365 ±0.1742 | 0.5406 ±0.0995 | 0.5386 ±0.0567 | 0.5684 ±0.0562 | 0.5758 ±0.0524 | 0.5875 ±0.0683 | 0.5619 ±0.0513 | 0.5660 ±0.0478 | 0.3966 ±0.0516 |
| Sammon | 0.5023 ±0.1964 | 0.5658 ±0.0543 | 0.5300 ±0.0567 | 0.5783 ±0.0597 | 0.5700 ±0.0439 | 0.5922 ±0.0710 | 0.5989 ±0.0734 | 0.5931 ±0.0636 | 0.4321 ±0.0586 |
| SNE | 0.4192 ±0.2409 | 0.5289 ±0.1371 | 0.5199 ±0.0435 | 0.5547 ±0.0617 | 0.5529 ±0.0537 | 0.5610 ±0.0581 | 0.5718 ±0.0610 | 0.5693 ±0.0576 | 0.4106 ±0.0720 |
| MFA | 0.5552 ±0.0622 | 0.5593 ±0.0798 | 0.5601 ±0.0712 | 0.5621 ±0.0734 | 0.5738 ±0.0671 | 0.5496 ±0.0446 | 0.5422 ±0.0495 | 0.5335 ±0.0527 | 0.3984 ±0.0540 |
| Method | Shallow | Deep | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ORIG | 0.5524 ±0.2302 | - - | - - | - - | - - | - - | - - | - - | - - |
| Autoencoder | - - | 0.4392 ±0.0982 | - - | - - | - - | - - | - - | - - | - - |
| LeNet | - - | 0.4214 ±0.1008 | - - | - - | - - | - - | - - | - - | - - |
| PCANet | - - | 0.4691 ±0.0854 | - - | - - | - - | - - | - - | - - | - - |
| PCA | 0.3982 ±0.0906 | 0.3667 ±0.0795 | 0.4596 ±0.0529 | 0.4575 ±0.0695 | 0.4765 ±0.0812 | 0.4836 ±0.0712 | 0.4624 ±0.0309 | 0.4882 ±0.0523 | 0.3638 ±0.0254 |
| PPCA | 0.4649 ±0.0703 | 0.4679 ±0.0577 | 0.5095 ±0.0619 | 0.5115 ±0.0678 | 0.5212 ±0.0652 | 0.5266 ±0.0573 | 0.5046 ±0.0601 | 0.5092 ±0.0851 | 0.3988 ±0.0807 |
| MDS | 0.4628 ±0.0724 | 0.4797 ±0.0954 | 0.4921 ±0.0514 | 0.5035 ±0.0424 | 0.5342 ±0.0614 | 0.5028 ±0.0640 | 0.4963 ±0.0661 | 0.5243 ±0.0586 | 0.3806 ±0.0494 |
| Sammon | 0.4698 ±0.0653 | 0.4791 ±0.0774 | 0.5245 ±0.0713 | 0.5245 ±0.0639 | 0.5088 ±0.0617 | 0.5056 ±0.0609 | 0.5153 ±0.0562 | 0.5007 ±0.0619 | 0.3852 ±0.0374 |
| SNE | 0.5531 ±0.0904 | 0.4683 ±0.0489 | 0.5160 ±0.0568 | 0.5028 ±0.0452 | 0.5248 ±0.0677 | 0.5631 ±0.0521 | 0.5039 ±0.0647 | 0.4915 ±0.0579 | 0.3843 ±0.0333 |
| MFA | 0.4601 ±0.0475 | 0.4634 ±0.0475 | 0.4689 ±0.0352 | 0.4712 ±0.0431 | 0.4856 ±0.0372 | 0.5012 ±0.0234 | 0.4765 ±0.0528 | 0.4712 ±0.0327 | 0.3834 ±0.0413 |
| Method | Shallow | Deep | ||||||
|---|---|---|---|---|---|---|---|---|
| ORIG | 0.8366 | – | – | – | – | – | – | – |
| Autoencoder | – | 0.9402 | – | – | – | – | – | – |
| LeNet | – | 0.8032 | – | – | – | – | – | – |
| PCANet | – | 0.9477 | – | – | – | – | – | – |
| PCA | 0.9402 | 0.9427 | 0.9472 | 0.9492 | 0.9507 | 0.9517 | 0.8829 | 0.8615 |
| PPCA | 0.9342 | 0.9372 | 0.9367 | 0.9382 | 0.9372 | 0.9342 | 0.8789 | 0.8645 |
| Sammon | 0.9292 | 0.9302 | 0.9318 | 0.9342 | 0.9372 | 0.9397 | 0.8894 | 0.8794 |
| SNE | 0.9312 | 0.9367 | 0.9372 | 0.9382 | 0.9397 | 0.9422 | 0.8869 | 0.8749 |
| MDS | 0.9278 | 0.9292 | 0.9307 | 0.9352 | 0.9367 | 0.9387 | 0.8914 | 0.8824 |
| LDA(9D) | 0.9243 | 0.9268 | 0.9292 | 0.9342 | 0.9312 | 0.9302 | 0.8969 | 0.8879 |
| MFA | 0.9392 | 0.9432 | 0.9412 | 0.9442 | 0.9457 | 0.9497 | 0.8929 | 0.8857 |
| Method | Shallow | Deep | |||||
|---|---|---|---|---|---|---|---|
| ORIG | 0.9274 | – | – | – | – | – | – |
| Autoencoder | – | 0.9334 | – | – | – | – | – |
| LeNet | – | 0.8195 | – | – | – | – | – |
| PCANet | – | 0.8995 | – | – | – | – | – |
| PCA | 0.9056 | 0.9184 | 0.9258 | 0.9328 | 0.9453 | 0.9478 | 0.9002 |
| PPCA | 0.9232 | 0.9258 | 0.9274 | 0.9347 | 0.9363 | 0.9369 | 0.9011 |
| Sammon | 0.9110 | 0.9197 | 0.9235 | 0.9274 | 0.9315 | 0.9254 | 0.9082 |
| SNE | 0.9034 | 0.9168 | 0.9197 | 0.9235 | 0.9261 | 0.9242 | 0.9011 |
| MDS | 0.9200 | 0.9219 | 0.9286 | 0.9264 | 0.9267 | 0.9276 | 0.9058 |
| LDA | 0.9258 | 0.9274 | 0.9389 | 0.9395 | 0.9384 | 0.9389 | 0.9014 |
| MFA | 0.9263 | 0.9316 | 0.9359 | 0.9440 | 0.9466 | 0.9491 | 0.9107 |
| Method | Shallow | Deep | |||||
|---|---|---|---|---|---|---|---|
| ORIG | 0.8635 | – | – | – | – | – | – |
| Autoencoder | – | 0.8823 | – | – | – | – | – |
| LeNet | – | 0.6070 | – | – | – | – | – |
| PCANet | – | 0.5823 | – | – | – | – | – |
| PCA | 0.8565 | 0.8600 | 0.8613 | 0.8675 | 0.8713 | 0.8680 | 0.8613 |
| PPCA | 0.9610 | 0.9690 | 0.9703 | 0.9680 | 0.9430 | 0.9285 | 0.8988 |
| Sammon | 0.8233 | 0.8340 | 0.8388 | 0.8413 | 0.8345 | 0.8313 | 0.8255 |
| SNE | 0.7715 | 0.7750 | 0.7845 | 0.7893 | 0.8023 | 0.7895 | 0.7760 |
| MDS | 0.8673 | 0.8723 | 0.8750 | 0.8795 | 0.8770 | 0.8653 | 0.8620 |
| LDA | 0.9630 | 0.9688 | 0.9693 | 0.9720 | 0.9730 | 0.9713 | 0.9610 |
| MFA | 0.9670 | 0.9690 | 0.9713 | 0.9735 | 0.9758 | 0.9680 | 0.9520 |
| Method | Shallow | Deep | |||||
|---|---|---|---|---|---|---|---|
| ORIG | 0.3225 | – | – | – | – | – | – |
| Autoencoder | – | 0.3521 | – | – | – | – | – |
| LeNet | – | 0.3256 | – | – | – | – | – |
| PCANet | – | 0.2569 | – | – | – | – | – |
| PCA | 0.3379 | 0.3385 | 0.3398 | 0.3439 | 0.3489 | 0.3478 | 0.3358 |
| PPCA | 0.3385 | 0.3374 | 0.3385 | 0.3395 | 0.3402 | 0.3411 | 0.3388 |
| Sammon | 0.3278 | 0.3285 | 0.3312 | 0.3356 | 0.3389 | 0.3378 | 0.3314 |
| SNE | 0.3355 | 0.3387 | 0.3397 | 0.3425 | 0.3438 | 0.3441 | 0.3322 |
| MDS | 0.3311 | 0.3335 | 0.3356 | 0.3397 | 0.3415 | 0.3401 | 0.3325 |
| LDA | 0.3178 | 0.3211 | 0.3256 | 0.3298 | 0.3301 | 0.3341 | 0.3211 |
| MFA | 0.3401 | 0.3438 | 0.3479 | 0.3511 | 0.3546 | 0.3536 | 0.3359 |
| Method | Shallow | Deep | ||||||
|---|---|---|---|---|---|---|---|---|
| ORIG | 0.3218 | – | – | – | – | – | – | – |
| Autoencoder | – | 0.3448 | – | – | – | – | – | – |
| AlexNet | – | 0.3356 | – | – | – | – | – | – |
| LeNet | – | 0.3221 | – | – | – | – | – | – |
| PCANet | – | 0.2569 | – | – | – | – | – | – |
| PCA | 0.3378 | 0.3382 | 0.3398 | 0.3405 | 0.3451 | 0.3442 | 0.3435 | 0.3382 |
| PPCA | 0.3358 | 0.3389 | 0.3415 | 0.3426 | 0.3456 | 0.3458 | 0.3425 | 0.3378 |
| Sammon | 0.3314 | 0.3356 | 0.3389 | 0.3436 | 0.3441 | 0.3432 | 0.3402 | 0.3347 |
| SNE | 0.3312 | 0.3341 | 0.3375 | 0.3389 | 0.3401 | 0.3412 | 0.3385 | 0.3289 |
| MDS | 0.3345 | 0.3358 | 0.3425 | 0.3435 | 0.3432 | 0.3438 | 0.3389 | 0.3322 |
| LDA | 0.3341 | 0.3358 | 0.3372 | 0.3396 | 0.3411 | 0.3415 | 0.3401 | 0.3356 |
| MFA | 0.3402 | 0.3414 | 0.3456 | 0.3472 | 0.3488 | 0.3452 | 0.3402 | 0.3399 |
| Layer | Output Shape | Kernal Size |
|---|---|---|
| Conv_1 | (32, 32, 32) | (3 × 3) |
| Activation_1 (ReLU) | (32, 32, 32) | – |
| Max Pooling_1 | (16, 16, 32) | (2 × 2) |
| Conv_2 | (16, 16, 64) | (3 × 3) |
| Activation_2 (ReLU) | (16, 16, 64) | – |
| Max pooling_2 | (8, 8, 64) | (2 × 2) |
| Flatten_1 | (4096, 1) | – |
| Dense_1 | (512, 1) | – |
| Dense_2 | (256, 1) | – |
| Dense_3 (Softmax) | (10, 1) | – |
| Method | Deep | |||||
|---|---|---|---|---|---|---|
| Baseline CNN | 0.7158 | – | – | – | – | – |
| PCA | 0.7347 | 0.7348 | 0.7364 | 0.7345 | 0.7320 | 0.7205 |
| LDA | 0.7208 | 0.7241 | 0.7198 | 0.6098 | 0.6124 | 0.6972 |
| MDS | 0.7320 | 0.7340 | 0.7325 | 0.7321 | 0.7319 | 0.7193 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.-N.; Zheng, Y.; Wei, H.; Dong, J.; Zhong, G. Stretching Deep Architectures: A Deep Learning Method without Back-Propagation Optimization. Electronics 2023, 12, 1537. https://doi.org/10.3390/electronics12071537
Wang L-N, Zheng Y, Wei H, Dong J, Zhong G. Stretching Deep Architectures: A Deep Learning Method without Back-Propagation Optimization. Electronics. 2023; 12(7):1537. https://doi.org/10.3390/electronics12071537
Chicago/Turabian StyleWang, Li-Na, Yuchen Zheng, Hongxu Wei, Junyu Dong, and Guoqiang Zhong. 2023. "Stretching Deep Architectures: A Deep Learning Method without Back-Propagation Optimization" Electronics 12, no. 7: 1537. https://doi.org/10.3390/electronics12071537