
Task Scheduling Based on Adaptive Priority Experience Replay on Cloud Platforms

Abstract
:1. Introduction
- (1)
- We propose an adaptive priority experience replay (APER) strategy, which can dynamically adjust the sampling strategy. This improves convergence speed and performance.
- (2)
- We adopt new optimization objectives and selection functions. The scheduling objective is unified with the sampling optimization objective. Additionally, the selection functions can avoid invalid scheduling actions.
- (3)
- We test APER on workflow scheduling datasets in different scenarios. Our results demonstrate that APER performs well on real-world datasets. The advantage becomes more significant using datasets with more diversity.
2. Related Work
2.1. Reinforce Learning
2.2. Prioritized Experience Replay
3. Method
3.1. Related Definitions
- (1)
- The node set, , represents different types of tasks in a DAG.
- (2)
- The edge set, , represents a directed edge from node to node , reflecting the dependencies between tasks and using an adjacency matrix, , representation, .
- (3)
- For any sequence, satisfies .
3.2. Important Components
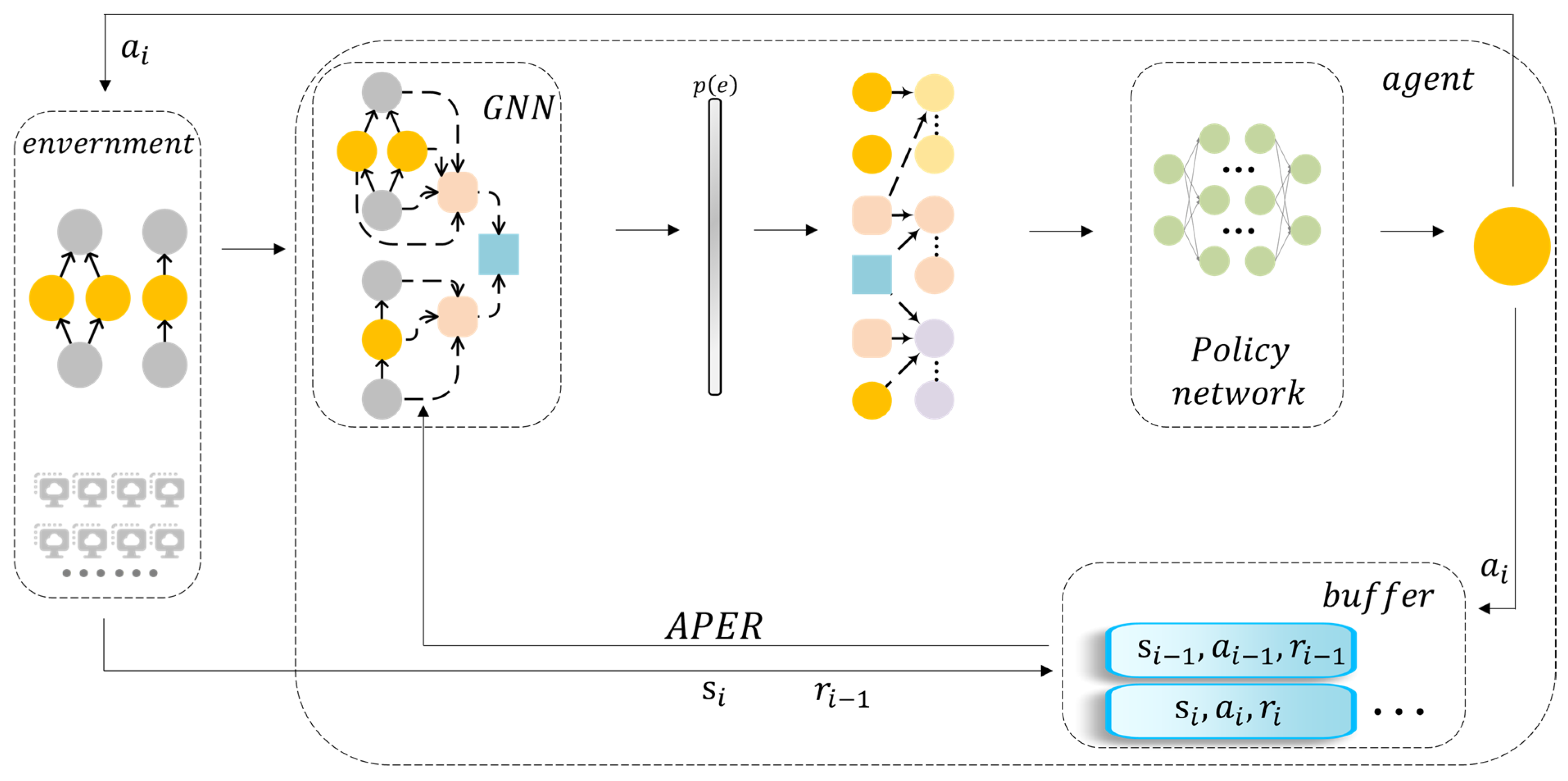
3.3. Model Structure
4. Implementation
4.1. Task Scheduling
4.2. Adaptive Priority Experience Replay
| Algorithm 1: Scheduler Decision Process |
| Input: State and Reward ; Output: Action ; Initialize the model parameter; For in : Initialize workflow data and environment parameter; While True do Select for each according to ; Execute actions, then observe and get the new state ; Store in replay buffer ; If workflow is None: End While End if Calculating as Equation (14) and as Equation (15); Selecting experiences form as Equation (16); For in selected samples: Select for each according to ; End for , update ; End for |
| Algorithm 2: The Sampling Process |
| Input: replay buffer and ; Output: selected samples; Get and replay buffer ; Sorted the replay buffer by ; Better sample num = (top samples); Poor sample num = (random selecting); Selected samples = Better sample + Poor sample; |
4.3. An Illustrative Example
5. Experiments
5.1. Experiment Settings
5.2. Use Different Datasets
5.3. Comparison of Different Algorithms
- (1)
- Decima with idle slots [20]. Based on Decima, the JCT can be reduced by delaying the running of some tasks for a period by intentionally inserting idle time slots for relatively large tasks.
- (2)
- GARLSched [68]. A reinforcement learning scheduling algorithm combined with generative adversarial networks. It uses an optimal policy in the expert database to guide agents to learn in large-scale dynamic scheduling problems while using a discriminator network based on task embedding to improve and stabilize the training process. This is an independent task scheduling algorithm.
- (3)
- Graphene [69]. A classic task heuristic scheduler based on DAGs and heterogeneous resources. It improves cluster performance by discovering potential parallelism in DAGs.
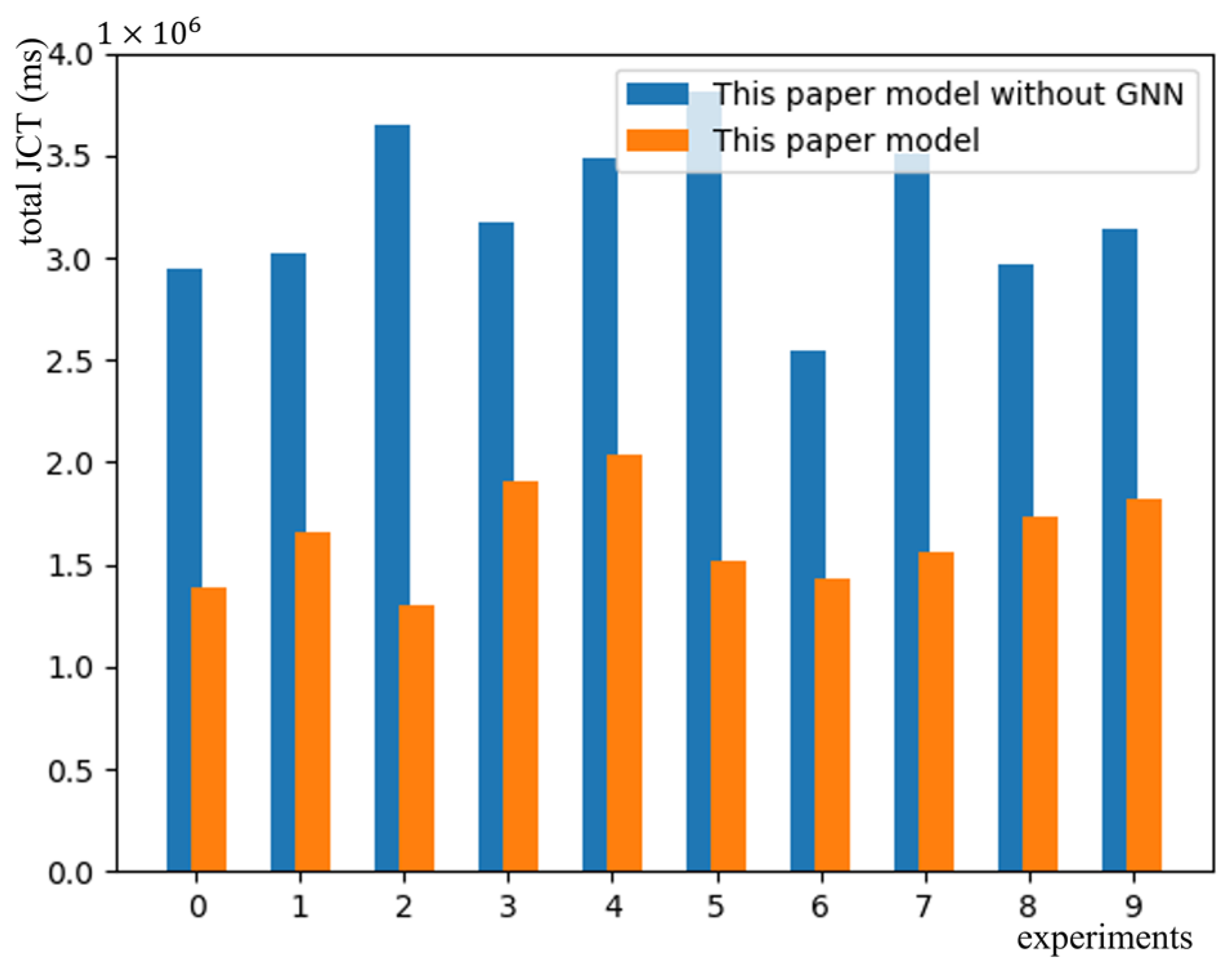
5.4. Ablation Experiment
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Grandl, R.; Ananthanarayanan, G.; Kandula, S.; Rao, S.; Akella, A. Multi-Resource Packing for Cluster Schedulers. SIGCOMM Comput. Commun. Rev. 2014, 44, 455–466. [Google Scholar] [CrossRef]
- Li, F.; Hu, B. DeepJS: Job Scheduling Based on Deep Reinforcement Learning in Cloud Data Center. In Proceedings of the 4th International Conference on Big Data and Computing, NewYork, NY, USA, 10–12 May 2019; pp. 48–53. [Google Scholar] [CrossRef]
- Sahu, D.P.; Singh, K.; Prakash, S. Maximizing Availability and Minimizing Markesan for Task Scheduling in Grid Computing Using NSGA II. In Proceedings of the Second International Conference on Computer and Communication Technologies, New Delhi, India, 24–26 July 2015; pp. 219–224. [Google Scholar] [CrossRef]
- Keshanchi, B.; Souri, A.; Navimipour, N.J. An improved genetic algorithm for task scheduling in the cloud environments using the priority queues: Formal verification, simulation, and statistical testing. J. Syst. Softw. 2017, 124, 1–21. [Google Scholar] [CrossRef]
- Chen, L.; Liu, S.H.; Li, B.C.; Li, B. Scheduling Jobs across Geo-Distributed Datacenters with Max-Min Fairness. IEEE Trans. Netw. Sci. Eng. 2019, 6, 488–500. [Google Scholar] [CrossRef]
- Al-Zoubi, H. Efficient Task Scheduling for Applications on Clouds. In Proceedings of the 2019 6th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2019 5th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), Paris, France, 21–23 June 2019; pp. 10–13. [Google Scholar] [CrossRef]
- Kumar, A.M.S.; Parthiban, K.; Shankar, S.S. An efficient task scheduling in a cloud computing environment using hybrid Genetic Algorithm—Particle Swarm Optimization (GA-PSO) algorithm. In Proceedings of the 2019 International Conference on Intelligent Sustainable Systems, Tokyo, Japan, 21–22 February 2019; pp. 29–34. [Google Scholar] [CrossRef]
- Faragardi, H.R.; Sedghpour, M.R.S.; Fazliahmadi, S.; Fahringer, T.; Rasouli, N. GRP-HEFT: A Budget-Constrained Resource Provisioning Scheme for Workflow Scheduling in IaaS Clouds. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1239–1254. [Google Scholar] [CrossRef]
- Kumar, K.R.P.; Kousalya, K. Amelioration of task scheduling in cloud computing using crow search algorithm. Neural Comput. Appl. 2020, 32, 5901–5907. [Google Scholar] [CrossRef]
- Mao, H.; Schwarzkopf, M.; Venkatakrishnan, S.B.; Meng, Z.; Alizadeh, M. Learning scheduling algorithms for data processing clusters. In Proceedings of the ACM Special Interest Group on Data Communication, Beijing, China, 19–23 August 2019; pp. 270–288. [Google Scholar] [CrossRef] [Green Version]
- Zade, M.H.; Mansouri, N.; Javidi, M.M. A two-stage scheduler based on New Caledonian Crow Learning Algorithm and reinforcement learning strategy for cloud environment. J. Netw. Comput. Appl. 2022, 202, 103–385. [Google Scholar] [CrossRef]
- Huang, B.; Xia, W.; Zhang, Y.; Zhang, J.; Zou, Q.; Yan, F.; Shen, L. A task assignment algorithm based on particle swarm optimization and simulated annealing in Ad-hoc mobile cloud. In Proceedings of the 9th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 11–13 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Wu, F.; Wu, Q.; Tan, Y.; Li, R.; Wang, W. PCP-B2: Partial critical path budget balanced scheduling algorithms for scientific workflow applications. Future Gener. Comput. Syst. 2016, 60, 22–34. [Google Scholar] [CrossRef]
- Zhou, X.M.; Zhang, G.X.; Sun, J.; Zhou, J.L.; Wei, T.Q.; Hu, S.Y. Minimizing cost and makespan for workflow scheduling in cloud using fuzzy dominance sort based HEFT. Future Gener. Comput. Syst. 2019, 93, 278–289. [Google Scholar] [CrossRef]
- Xing, L.; Zhang, M.; Li, H.; Gong, M.; Yang, J.; Wang, K. Local search driven periodic scheduling for workflows with random task runtime in clouds. Comput. Ind. Eng. 2022, 168, 14. [Google Scholar] [CrossRef]
- Peng, Z.P.; Cui, D.L.; Zuo, J.L.; Li, Q.R.; Xu, B.; Lin, W.W. Random task scheduling scheme based on reinforcement learning in cloud computing. Clust. Comput. J. Netw. Softw. Tools Appl. 2015, 18, 1595–1607. [Google Scholar] [CrossRef]
- Ran, L.; Shi, X.; Shang, M. SLAs-Aware Online Task Scheduling Based on Deep Reinforcement Learning Method in Cloud Environment. In Proceedings of the IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019; pp. 1518–1525. [Google Scholar] [CrossRef]
- Qin, Y.; Wang, H.; Yi, S.; Li, X.; Zhai, L. An Energy-Aware Scheduling Algorithm for Budget-Constrained Scientific Workflows Based on Multi-Objective Reinforcement Learning. J. Supercomput. 2020, 76, 455–480. [Google Scholar] [CrossRef]
- Wang, J.J.; Wang, L. A Cooperative Memetic Algorithm With Learning-Based Agent for Energy-Aware Distributed Hybrid Flow-Shop Scheduling. IEEE Trans. Evol. Comput. 2022, 26, 461–475. [Google Scholar] [CrossRef]
- Duan Yubin, W.J. Improving Learning-Based DAG Scheduling by Inserting Deliberate Idle Slots. IEEE Netw. Mag. Glob. Internetw. 2021, 35, 133–139. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; p. 342. [Google Scholar] [CrossRef]
- Yang, T.; Tang, H.; Bai, C.; Liu, J.; Hao, J.; Meng, Z.; Liu, P. Exploration in Deep Reinforcement Learning: A Comprehensive Survey. Inf. Fusion 2021, 85, 1–22. [Google Scholar] [CrossRef]
- Rjoub, G.; Bentahar, J.; Wahab, O.A.; Bataineh, A. Deep Smart Scheduling: A Deep Learning Approach for Automated Big Data Scheduling Over the Cloud. In Proceedings of the 2019 7th International Conference on Future Internet of Things and Cloud (FiCloud), Istanbul, Turkey, 26–28 August 2019; pp. 189–196. [Google Scholar] [CrossRef]
- Wei, Y.; Pan, L.; Liu, S.; Wu, L.; Meng, X. DRL-Scheduling: An Intelligent QoS-Aware Job Scheduling Framework for Applications in Clouds. IEEE Access 2018, 6, 55112–55125. [Google Scholar] [CrossRef]
- Yi, D.; Zhou, X.; Wen, Y.; Tan, R. Toward Efficient Compute-Intensive Job Allocation for Green Data Centers: A Deep Reinforcement Learning Approach. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 634–644. [Google Scholar] [CrossRef]
- Wang, L.; Huang, P.; Wang, K.; Zhang, G.; Zhang, L.; Aslam, N.; Yang, K. RL-Based User Association and Resource Allocation for Multi-UAV enabled MEC. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 741–746. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, H.; Wu, C.; Mao, S.; Ji, Y.; Bennis, M. Performance Optimization in Mobile-Edge Computing via Deep Reinforcement Learning. In Proceedings of the 2018 IEEE 88th Vehicular Technology Conference (VTC-Fall), Chicago, IL, USA, 27–30 August 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Cheng, F.; Huang, Y.; Tanpure, B.; Sawalani, P.; Cheng, L.; Liu, C. Cost-aware job scheduling for cloud instances using deep reinforcement learning. Clust. Comput. 2022, 25, 619–631. [Google Scholar] [CrossRef]
- Yan, J.; Huang, Y.; Gupta, A.; Liu, C.; Li, J.; Cheng, L. Energy-aware systems for real-time job scheduling in cloud data centers: A deep reinforcement learning approach. Comput. Electr. Eng. 2022, 99, 10. [Google Scholar] [CrossRef]
- Li, T.; Xu, Z.; Tang, J.; Wang, Y. Model-free control for distributed stream data processing using deep reinforcement learning. Proc. VLDB Endow. 2018, 11, 705–718. [Google Scholar] [CrossRef] [Green Version]
- Mao, H.; Alizadeh, M.; Menache, I.; Kandula, S. Resource Management with Deep Reinforcement Learning. In Proceedings of the 15th ACM Workshop on Hot Topics in Networks, Atlanta, GA, USA, 9–10 November 2016; pp. 50–56. [Google Scholar]
- Lee, H.; Lee, J.; Yeom, I.; Woo, H. Panda: Reinforcement Learning-Based Priority Assignment for Multi-Processor Real-Time Scheduling. IEEE Access 2020, 8, 185570–185583. [Google Scholar] [CrossRef]
- Di Zhang, D.D.; He, Y.; Bao, F.S.; Xie, B. RLScheduler: Learn to Schedule Batch Jobs Using Deep Reinforcement Learning. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020; pp. 1–15. [Google Scholar] [CrossRef]
- Liang, S.; Yang, Z.; Jin, F.; Chen, Y. Data centers job scheduling with deep reinforcement learning. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 24th Pacific-Asia Conference, PAKDD 2020, Singapore, 11–14 May 2020; pp. 906–917. [Google Scholar] [CrossRef]
- Liu, Q.; Shi, L.; Sun, L.; Li, J.; Ding, M.; Shu, F. Path Planning for UAV-Mounted Mobile Edge Computing with Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2020, 69, 5723–5728. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Weng, Q.; Wang, W.; Chen, C.; Li, B. Metis: Learning to Schedule Long-Running Applications in Shared Container Clusters at Scale. In Proceedings of the SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020; pp. 1–17. [Google Scholar] [CrossRef]
- Mitsis, G.; Tsiropoulou, E.E.; Papavassiliou, S. Price and Risk Awareness for Data Offloading Decision-Making in Edge Computing Systems. IEEE Syst. J. 2022, 16, 6546–6557. [Google Scholar] [CrossRef]
- Souri, A.; Zhao, Y.; Gao, M.; Mohammadian, A.; Shen, J.; Al-Masri, E. A Trust-Aware and Authentication-Based Collaborative Method for Resource Management of Cloud-Edge Computing in Social Internet of Things. IEEE Trans. Comput. Soc. Syst. 2023, 1–10. [Google Scholar] [CrossRef]
- Long, X.J.; Zhang, J.T.; Qi, X.; Xu, W.L.; Jin, T.G.; Zhou, K. A self-learning artificial bee colony algorithm based on reinforcement learning for a flexible job-shop scheduling problem. Concurr. Comput. Pract. Exp. 2022, 34, e6658. [Google Scholar] [CrossRef]
- Paliwal, A.S.; Gimeno, F.; Nair, V.; Li, Y.; Lubin, M.; Kohli, P.; Vinyals, O. Reinforced Genetic Algorithm Learning for Optimizing Computation Graphs. In Proceedings of the 2020 International Conference on Learning Representations, Addis Ababa, Ethiopia, 11 March 2020; pp. 1–24. [Google Scholar]
- Gao, Y.; Chen, L.; Li, B. Spotlight: Optimizing Device Placement for Training Deep Neural Networks. In Proceedings of the 35th International Conference on Machine Learning, Proceedings of Machine Learning Research, Stockholm, Sweden, 10–15 July 2018; pp. 1676–1684. [Google Scholar]
- Chen, X.; Tian, Y. Learning to perform local rewriting for combinatorial optimization. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates: New York, NY, USA; p. 564. [Google Scholar]
- Bao, Y.; Peng, Y.; Wu, C. Deep Learning-Based Job Placement in Distributed Machine Learning Clusters With Heterogeneous Workloads. IEEE/ACM Trans. Netw. 2022, 1–14. [Google Scholar] [CrossRef]
- Lee, H.; Cho, S.; Jang, Y.; Lee, J.; Woo, H. A Global DAG Task Scheduler Using Deep Reinforcement Learning and Graph Convolution Network. IEEE Access 2021, 9, 158548–158561. [Google Scholar] [CrossRef]
- Hu, Z.; Tu, J.; Li, B. Spear: Optimized Dependency-Aware Task Scheduling with Deep Reinforcement Learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 2037–2046. [Google Scholar] [CrossRef]
- Gao, Y.; Chen, L.; Li, B. Post: Device placement with cross-entropy minimization and proximal policy optimization. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 9993–10002. [Google Scholar]
- Mirhoseini, A.; Pham, H.; Le, Q.V.; Steiner, B.; Larsen, R.; Zhou, Y.; Kumar, N.; Norouzi, M.; Bengio, S.; Dean, J. Device placement optimization with reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning—Volume 70, Sydney, NSW, Australia, 6–11 August 2017; pp. 2430–2439. [Google Scholar]
- Zhu, J.; Li, Q.; Ying, S. SAAS parallel task scheduling based on cloud service flow load algorithm. Comput. Commun. 2022, 182, 170–183. [Google Scholar] [CrossRef]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar] [CrossRef]
- Zhang, C.; Song, W.; Cao, Z.; Zhang, J.; Tan, P.S.; Xu, C. Learning to Dispatch for Job Shop Scheduling via Deep Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 1621–1632. [Google Scholar]
- Sun, P.; Guo, Z.; Wang, J.; Li, J.; Lan, J.; Hu, Y. DeepWeave: Accelerating job completion time with deep reinforcement learning-based coflow scheduling. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020; p. 458. [Google Scholar]
- Grinsztajn, N.; Beaumont, O.; Jeannot, E.; Preux, P.; Soc, I.C. READYS: A Reinforcement Learning Based Strategy for Heterogeneous Dynamic Scheduling. In Proceedings of the IEEE International Conference on Cluster Computing (Cluster), Electr Network, Portland, OR, USA, 7–10 September 2021; pp. 70–81. [Google Scholar] [CrossRef]
- Wang, C.; Wu, Y.; Vuong, Q.; Ross, K. Striving for Simplicity and Performance in Off-Policy DRL: Output Normalization and Non-Uniform Sampling. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020; p. 11. [Google Scholar] [CrossRef]
- Atherton, L.A.; Dupret, D.; Mellor, J.R. Memory trace replay: The shaping of memory consolidation by neuromodulation. Trends Neurosci. 2015, 38, 560–570. [Google Scholar] [CrossRef] [Green Version]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. In Proceedings of the 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar] [CrossRef]
- Kumar, A.; Gupta, A.; Levine, S. DisCor: Corrective Feedback in Reinforcement Learning via Distribution Correction. In Proceedings of the Conference and Workshop on Neural Information Processing Systems, Virtual, 6–12 December 2020. [Google Scholar] [CrossRef]
- Liu, X.-H.; Xue, Z.; Pang, J.-C.; Jiang, S.; Xu, F.; Yu, Y. Regret Minimization Experience Replay in Off-Policy Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, Virtual, 6–14 December 2021; pp. 17604–17615. [Google Scholar] [CrossRef]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. Int. Conf. Mach. Learn. 2009, 139, 41–48. [Google Scholar] [CrossRef]
- Bondy, J.A.; Murty, U.S.R. Graph Theory with Applications. Soc. Ind. Appl. Math. 1976, 21, 429. [Google Scholar] [CrossRef]
- Lin, L.J. Self-Improving Reactive Agents Based on Reinforcement Learning, Planning and Teaching. Mach. Learn. 1992, 8, 293–321. [Google Scholar] [CrossRef]
- Chen, H.; Zhu, X.; Liu, G.; Pedrycz, W. Uncertainty-Aware Online Scheduling for Real-Time Workflows in Cloud Service Environment. IEEE Trans. Serv. Comput. 2021, 14, 1167–1178. [Google Scholar] [CrossRef]
- Gari, Y.; Monge, D.A.; Mateos, C. A Q-learning approach for the autoscaling of scientific workflows in the Cloud. Future Gener. Comput. Syst. Int. J. Escience 2022, 127, 168–180. [Google Scholar] [CrossRef]
- Hasselt, H.V.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar] [CrossRef]
- Wu, L.J.; Tian, F.; Xia, Y.; Fan, Y.; Qin, T.; Lai, J.H.; Liu, T.Y. Learning to Teach with Dynamic Loss Functions. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 3–8 December 2018; pp. 6467–6478. [Google Scholar] [CrossRef]
- TPC-H. The TPC-H Benchmarks. Available online: https://www.tpc.org/tpch/ (accessed on 10 April 2022).
- Guo, J.; Chang, Z.; Wang, S.; Ding, H.; Feng, Y.; Mao, L.; Bao, Y. Who limits the resource efficiency of my datacenter: An analysis of Alibaba datacenter traces. In Proceedings of the 2019 IEEE/ACM 27th International Symposium on Quality of Service (IWQoS), Phoenix, AZ, USA; 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Bharathi, S.; Chervenak, A.; Deelman, E.; Mehta, G.; Su, M.H.; Vahi, K. Characterization of scientific workflows. In Proceedings of the Third Workshop on Workflows in Support of Large-Scale Science, Austin, TX, USA, 17 November 2008; pp. 1–10. [Google Scholar] [CrossRef]
- Li, J.B.; Zhang, X.J.; Wei, J.; Ji, Z.Y.; Wei, Z. GARLSched: Generative adversarial deep reinforcement learning task scheduling optimization for large-scale high performance computing systems. Future Gener. Comput. Syst. Int. J. Escience 2022, 135, 259–269. [Google Scholar] [CrossRef]
- Grandl, R.; Kandula, S.; Rao, S.; Akella, A.; Kulkarni, J. Graphene: Packing and Dependency-Aware Scheduling for Data-Parallel Clusters. In Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation, Savannah, GA, USA; 2016; pp. 81–97. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| All nodes in a DAG | The feature of a node | ||
| The feature of a DAG | |||
| All edges in a DAG | The feature of global | ||
| , | th step reward | ||
| A | Discount factor | ||
| The set of DAGs | th step | ||
| -th DAG, | The filter for executability | ||
| n-th node in the m-th DAG | The sample rate | ||
| The actual finish time (metric: ms) | |||
| The actual start execution time (metric: ms) | Non-linear functions | ||
| The completion time (metric: ms) | The model parameters | ||
| The number of available executors | |||
| The state of executors; available is 1, else 0 | The policy entropy | ||
| The weight of the policy entropy | |||
| The average JCT of all DAGs (metric: ms) |
| Dataset | Amount | Sample Amount | Average Arrival Time | |
|---|---|---|---|---|
| Tpc-h | Twenty-two queries are generated under 7 data scales of 2 G, 5 G, 10 G, 20 G, 50 G, 80 G, and 100 G | 100 | 25 s | |
| alidata | Two million from real cluster running data | 1000 | 25 s | |
| Scientific workflows | Scientific Workflow | Number of Nodes | 20 | 50 s |
| CyberShake | 30, 50, 100, 1000 | |||
| Epigenomics | 24, 47, 100, 997 | |||
| Inspiral | 30, 50, 100, 1000 | |||
| Montage | 25, 50, 100, 1000 | |||
| Sipht | 29, 58, 97, 968 | |||
| Floodplain | 7 | |||
| HEFT | 10 | |||
| Mixed | 1000. 32% from Tpc-h, 64% from alidata, and 4% from scientific workflow | 1000 | 50 s | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Total | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| The proposed model | 1864.8 | 1560.6 | 1505.3 | 1556.0 | 1377.1 | 2014.3 | 1313.9 | 1768.3 | 1430.8 | 1724.6 | 16,115.7 | 1611.6 |
| Decima | 2854.5 | 7879.6 | 31,178.6 | 17,337.5 | 29,293.5 | 5221.1 | 3498.1 | 2281.9 | 7574.0 | 1748.7 | 108,867.4 | 10,886.7 |
| Relative advantage This model/Decima | 65.33% | 19.81% | 4.83% | 8.97% | 4.70% | 38.58% | 37.56% | 77.49% | 18.89% | 98.62% | 14.80% | 37.48% |
| Algorithm | Proposed Model | Decima | Decima with Idle Slots | GARLSched | Graphene |
|---|---|---|---|---|---|
| Average JCT on Tpc-h | 58.93 | 53.57 | / | / | 76.61 |
| Average JCT on alidata | 182.04 | 444.01 | 381.85 | 261.69 | 586.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Gao, W.; Shi, L.; Shang, Z.; Zhang, S. Task Scheduling Based on Adaptive Priority Experience Replay on Cloud Platforms. Electronics 2023, 12, 1358. https://doi.org/10.3390/electronics12061358
Li C, Gao W, Shi L, Shang Z, Zhang S. Task Scheduling Based on Adaptive Priority Experience Replay on Cloud Platforms. Electronics. 2023; 12(6):1358. https://doi.org/10.3390/electronics12061358
Chicago/Turabian StyleLi, Cuixia, Wenlong Gao, Li Shi, Zhiquan Shang, and Shuyan Zhang. 2023. "Task Scheduling Based on Adaptive Priority Experience Replay on Cloud Platforms" Electronics 12, no. 6: 1358. https://doi.org/10.3390/electronics12061358