1. Introduction
Chemical raw materials play a pivotal role in people’s lives, industrial production and the development of science and technology. With the continuous improvement of China’s industrialization, the demand for chemical raw materials from all walks of life is increasing day by day. However, some chemical materials are explosive, corrosive, flammable, toxic and other characteristics, and once leakage occurs, it may cause a certain degree of harm to the human body and the surrounding environment [
1]. Therefore, it is vital to ensure the safety of hazardous chemicals. According to statistics from the China Federation of Logistics and Purchasing (CFLP), more than 1 billion metric tons of hazardous chemicals are transported by road in China every year, accounting for more than 60% of the total transport of hazardous chemicals, and this proportion is still rising [
2]. According to data from the State Administration of Safety Supervision and the fire service, 77% of accidents occur during transportation [
3]. The transport of hazardous chemicals has become one of the highest risks in the safety of hazardous chemicals. Therefore, in order to reduce casualties and property damage, it is imperative to supervise hazardous chemical vehicles in transit.
In recent years, deep learning and machine vision have developed rapidly, such as object detection and image segmentation [
4]. This provides the technical basis for the identification of hazardous material vehicles. The use of vehicle detection technology to identify important roads in the detection of dangerous chemical vehicles, from road management departments for the vehicle to real-time dynamic monitoring, can avoid or reduce the occurrence of traffic accidents, or in the event of dangerous chemical transport accidents, can provide timely and effective emergency rescue, as best as possible avoid secondary accidents, reduce casualties and limit property damage [
5].
At present, vehicle recognition technology can be divided into two categories according to the required hardware and software basis: one is the recognition method using physical parameters and the other is the recognition method using image processing technology [
6]. Vehicle recognition based on physical parameters has high requirements on hardware, and although the recognition accuracy of this method is high, its cost is great and the maintenance work on the hardware during its use is also difficult. Vehicle recognition based on image processing technology is the extraction of feature information (color, texture, size, shape, etc.) from vehicle images using certain methods where possible. Vehicle image recognition is a process of multiple operations on the vehicle image, by using a specific algorithm to convert the vehicle image into a feature vector representation, and the obtained feature information is differentiated by a classification algorithm [
7].
In recent years, vehicle detection has been the focus of many researchers and there has been a proliferation of research on vehicle detection. Bochkovskiy et al. proposed a new YOLO architecture. Firstly, the CSPDarknet (Cross Stage Partial Darknet) is used as the backbone network and the SPP (Spatial Pyramid Pooling) is used for feature fusion for the first time. Then, the PAN (path aggregation network) structure is used as the neck of the model to do a further fusion of feature maps. Glenn Jocher proposes a YOLOv5 network model based on it, using adaptive anchor frames, automatic learning based on the training set as well as LeakyReLU and Sigmoid as activation functions. The SPPF (Spatial Pyramid Pooling Fast) layer is proposed to replace the SPP layer first. The algorithm can achieve fast and accurate detection [
8]. Wang et al. proposed a new object detection algorithm. In this algorithm, the SPPCSPC (Spatial Pyramid Pooling Cross Stage Partial Conv) module is proposed for the first time and the original SPPF module is replaced by this module to achieve better feature fusion [
9]. Woo et al. proposed a convolutional block attention mechanism, and the classical network model such as ResNet using this module can make the network more focused on the object and exhibits remarkable effects in the field of object detection [
10]. Gevorgyan et al. proposed a new bounding box regression algorithm. This algorithm considers the direction of mismatch between the ground truth box and the prediction box and can effectively improve the accuracy of model inference [
11].
Djenouri et al. proposed an improved regional convolutional neural network, which first uses a SIFT extractor to remove noise (set of outlier images) and then builds an improved regional convolutional neural network to detect vehicles at different scales, achieving improvements in detection accuracy and proposing a new hyperparametric optimization model based on evolutionary computation that can be used to optimize the deep learning framework of parameters [
12]. Wang et al. proposed a new method for vehicle detection based on multi-sensor fusion. First, multiple sensors are combined to extract the target vehicle. Second, the potential area of the vehicle in the feature map is estimated according to the distribution of the target vehicle detected by the sensors, and predicting the region of interest (ROI) of the vehicle according to pixel regression. Finally, four new haar-like feature templates are developed to enhance the detection performance of vehicles [
13]. This method can remarkably enhance vehicle detection performance in severe weather.
In the process of vehicle detection, current detection algorithms face challenges such as large calculations and unsatisfactory detection accuracy. Dong et al. proposed an improved lightweight YOLOv5 method for vehicle detection. The method introduces the C3Ghost and Ghost modules in the YOLOv5 neck network and the convolutional attention module in the backbone network to improve the detection accuracy of the algorithm, and then further considers CIoU loss as the bounding box regression loss function to speed up the bounding box regression and improve the localization accuracy of the algorithm [
14]. The effectiveness and superiority of the method are demonstrated by example analysis and comparison. Li et al. propose a hierarchical joint CNN model. The method uses a Faster R-CNN to extract multiple feature maps for the vehicle image; then, a CNN is used to train multiple feature maps, and finally, multiple classifiers are used to achieve the fine recognition of vehicles [
15]. Mi et al. proposed a fusion algorithm of aggregated region classes and two-stage SVM classifiers for the detection of container trucks in ports. This method can display better truck detection performance than traditional methods [
16].
In order to rapidly detect moving vehicles in road transportation, Chen et al. propose an SSD-based vehicle detection algorithm. The method replaces the backbone network of SSD (single-shot multibox detector) with the MobileNet-v2 network to achieve a lightweight model, and introduces an attention mechanism in the model to enhance the model’s ability to extract vehicle features. Finally, a bottom-up feature fusion architecture is built based on a deconvolution module to enhance detection accuracy [
17]. Kang et al. proposed a remote sensing satellite video motion vehicle fast detection method with an automatic region of interest constraint. Firstly, the region of interest of the moving vehicle is rapidly and automatically acquired; then, the fast detection of moving vehicles in the region of interest is achieved based on an improved Gaussian background subtraction under the region of interest constraint [
18]. Zhang et al. proposed a detection algorithm based on sample adaptive segmentation. The method adopts different update strategies for different detection regions to achieve an adaptive update of background samples, and randomly penetrates the diffuse background points into the foreground region with a certain probability to update the background samples in its neighborhood, achieving the fast detection of vehicles in motion [
19]. Alsanad et al. proposed a real-time truck monitoring algorithm based on YOLOv2. Aiming at the shortage of traditional methods that only pay attention to the position of the class target to predict its probability in the class, this method considers the whole image area for strong target detection, which improves the effectiveness of truck detection [
20]. Zhang et al. proposed a non-maximum suppression method based on position priority to achieve the detection of mud trucks. This method designs a new bounding box matching algorithm to solve the problem of object loss when the IoU of two proposals is greater than a threshold and redefines the loss function to fit the improved method. Experiments prove the effectiveness of this method [
21].
The main source of image data for vehicle detection is traffic surveillance images [
22]. In recent years, vehicle detection algorithms have flourished, especially the YOLO family represented by the use of deep learning methods. However, these methods require manually labeling a large amount of data to train the network model [
23]. Currently, most of the datasets are labeled with vehicles captured during the daytime, while vehicle images at night are scarce [
24]. Li et al. proposed a domain adaptive (DA) method based on a Fast R-CNN. The method can increase the number of labeled nighttime vehicle images in the dataset by using the existing labeled daytime vehicle images to complement the unlabeled nighttime vehicle images, thus improving the detection capability of the model for nighttime vehicles [
25]. Chen et al. propose an information fusion-based algorithm for detecting vehicles driving at night, using millimeter wave radar and vision sensors to detect vehicles ahead at night in order to provide comprehensive and reliable information for night-time driving safety [
26]. Hua et al. proposed an improved YOLOv3 model algorithm based on dark channel defogging to address the problem of poor detection accuracy due to the serious influence of fog in the process of vehicle detection in foggy weather. First, the image is defogged by the dark channel algorithm to improve the clarity of the image, and then an attention mechanism is introduced to further the feature extraction of the feature map used for detection, which improves the algorithm’s ability to mine feature information [
27].
In this paper, an algorithm based on an improved YOLOv5 model is proposed for the detection of hazardous chemical vehicles. The main contributions include (1) integrating the attention module in the feature extraction network to enhance the quality of feature extraction for hazardous chemical vehicles by paying attention to spatial semantic information and channel semantic information; (2) replacing the spatial pyramid pooling layer (SPPF) in the backbone network by the Spatial Pyramid Pooling Cross Stage Partial Conv (SPPCSPC), which can enhance the fusion ability of the model under different size feature maps; (3) replacing the CIoU loss in the loss function by SIoU loss, which can effectively accelerate the speed of bounding box regression and increase the localization accuracy of the algorithm.
2. Methodology
The YOLOv5 algorithm makes predictions based on the whole image, giving all the detection results at once [
28]. YOLOv5 has four different sizes of network models, namely YOLOv5s, YOLOv5m, YOLOv5l and YOLOv5x. YOLOv5x has the largest model and thus has the highest detection accuracy. YOLOv5s has the smallest model, but it has the fastest detection speed. In this paper, YOLOv5s is chosen as the baseline model and improved to maximize detection accuracy while keeping the detection speed largely unchanged. This section details the architecture of the improved hazardous material vehicles detection model.
Specifically, the input images were first processed using Mosaic data enhancement, image scaling and adaptive initial anchor box calculation, and then the enhanced images were fed into the improved YOLOv5 network model for hazardous chemical vehicle detection. To further improve the semantic quality of the output of the feature from the feature extraction network, we replaced the original SPPF layer by the SPPCSPC in the backbone, and added attention modules to the backbone and neck of the network to focus on spatial features and channel features. The CIoU in the original bounding box loss is replaced with SIoU, effectively improving the inference accuracy.
2.1. Data Augmentation
To obtain a well-performing neural network model, a large amount of data is often required, but the task of acquiring new data is often time-consuming and labor-intensive [
29]. The use of data augmentation techniques can make full use of computers to generate data and increase the amount of data, for example by using scaling, panning, rotating, color transformations, etc. It is beneficial for data augmentation to increase the number of training samples and the ability to increase the generalization power of the model by adding suitable noisy data [
30].
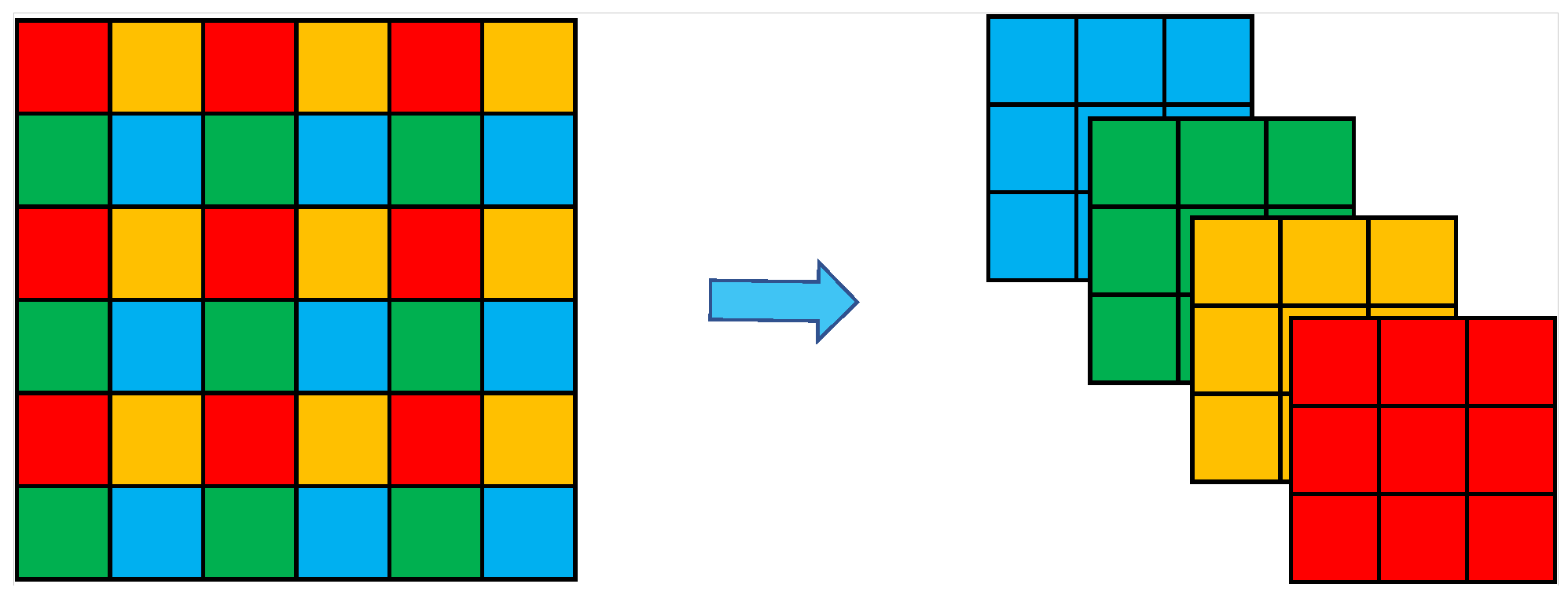
In order to obtain excellent detection results, data augmentation is also used in YOLOv5. YOLOv5 uses Mosaic data augmentation to increase the amount of data for small targets in the dataset and enrich the number of samples by randomly flipping, scaling and cropping four images into a new image. The Mosaic data enhancement effect is shown in
Figure 1.
2.2. Feature Extraction Backbone Network
YOLOv5 uses the CSP-Darknet53 network as the backbone of the model, which is mainly composed of modules such as Focus, Convolution block and C3 module. Specifically, the Focus module divides the feature data into four parts, each corresponding to two down samples, spliced in the channel dimension and then convolved to obtain a binary down-sampled feature map with no information loss, the structure of which is shown in
Figure 2. The convolution module is the basic convolution unit of YOLOv5, which performs two-dimensional convolution, batch normalization and activation operations on the feature map, in turn. The C3 module consists of several modules called bottleneck residual connections, in which the feature map passes through two convolution layers and then performs an additive operation with the original feature map. This structure accomplishes the migration of residual features without increasing the channel depth. The structure of the C3 module is shown in
Figure 3.
The attention mechanism allows the model to better focus on vehicle information features and suppress non-vehicle information features, enabling the model to extract more accurate semantic information about the vehicle [
31]. We add an attention module to the YOLOv5 backbone network to recalibrate the feature maps in order to enhance the feature representation capabilities. The attention module generates attentional feature map information in both channel and spatial dimensions, and then the feature map information is multiplied with the previous feature map for adaptive feature correction to produce the defined feature map. The architecture of the attention module is shown in
Figure 4.
Channel attention mechanism focuses on the feature relationships between channels in the feature map to generate the channel attention, and its module structure is shown in
Figure 5. Channel attention performs global maximum pooling and mean maximum pooling in the channel dimension of the feature map to aggregate the feature information in the spatial dimension, respectively. Finally, a channel attention feature map of
is obtained. This feature map is used as the input of the spatial attention module. The specific formula is formulated as follows:
After paying attention to the channel attention, the feature map is input into the spatial attention module, and its model structure is shown in
Figure 6. First, the global max-pooling and global avg-pooling based on the channel dimension are performed, and then both tensors are spliced in the channel dimension. The spliced tensor depth is reduced to 1 in the channel dimension by a convolution operation. Spatial attention features are generated after sigmoid activation, and finally the original feature map is fused with the spatial attention features to obtain the feature map focusing on spatial information. The specific formula is formulated as follows:
2.3. Neck
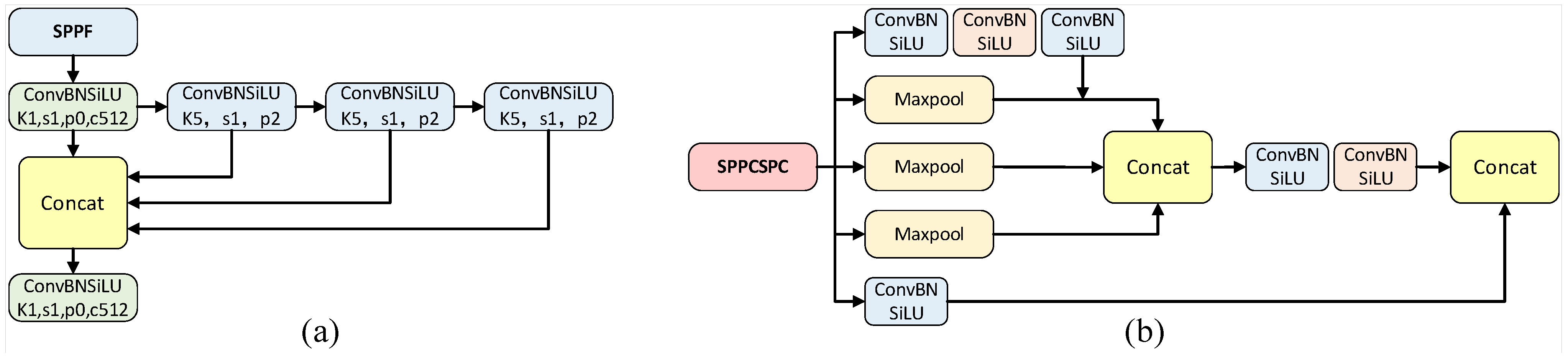
The neck of the YOLOv5 model consists mainly of Conv modules, C3 modules and SPP (Spatial Pyramidal Pooling), and uses a PANet (Path Aggregation Network) as the neck for feature aggregation. Specifically, the SPP (Spatial Pyramidal Pooling) performs max-pooling of different convolutional kernel sizes and integrates features. It can convert arbitrary-sized feature maps into fixed-sized features and effectively solve the problem of the repeated extraction of related features by convolutional neural networks. The structure of the SPPF (Feature Pyramid Pooling Fast) is shown in
Figure 7a.
To further improve the capability of network feature fusion, we replaced the SPPF of YOLOv5 by the SPPCSPC module to enhance the detection capability of the model for different scales. The structure of SPPCSPC is shown in
Figure 7b below.
In neural networks, the deeper the networks, the better the extraction of object feature information and the better the detection of the object by the model. However, the network model also makes the location information of the object blurred, and causes the loss of feature information for small objects as it continues to deepen. YOLOv5 adopts a PANet structure for the multi-scale fusion of features, which enables the bottom feature map to contain more semantic information of vehicles through top-down upsampling [
32]. The PAN structure achieves bottom-up subsampling through convolution. The PAN structure achieves bottom-up downsampling by convolution, so that the top-level feature map contains stronger information about the location of the vehicles. The specific process is shown in
Figure 8. Through the feature aggregation, the feature maps of different sizes contain richer semantic information and location information, thus ensuring the accuracy of the detection of different sizes of hazardous materials vehicles.
In order to enable the network to better learn the semantic information in the vehicle images, focusing on important information and suppressing useless information, we also introduced the attention mechanism into the neck structure of YOLOv5. The overall network structure we proposed is shown in
Figure 9.
2.4. Loss Function
The loss function of YOLOv5 consists of three components: the confidence loss
, the classes loss
and the position loss of the bounding box
. The network divides the feature map into several cells, and each cell corresponds to a vector
y = (
,
,
,
,
,
,
,
,
), where
,
is used to calculate the offset between the prediction box and the corresponding anchor box, and
,
are used to calculate the width and height of the prediction box.
is the probability that the cell contains the object to be detected, and
,
,
,
are the prediction values of the four classes corresponding to the hazardous material vehicles dataset. The loss function is calculated as follows:
The confidence loss
is formulated according to positive sample matching, including the object confidence score
in the prediction box and the intersection over union of the prediction box and the ground truth box. Both calculate the binary cross-entropy to obtain the final object confidence loss. The confidence loss
is defined as follows:
Classes loss is similar to confidence loss in that classes loss is calculated from the classes score of the prediction box and the one-hot value of the ground truth box classes. The classes loss
is defined as follows:
The CIoU loss is used in the position loss of the prediction box. That takes into account three geometric factors of the bounding box regression function: overlap area, centroid distance and aspect ratio. The position loss
is defined as follows:
where
is the centroid Euclidean distance between the bounding box and ground truth box,
is the diagonal distance between the bounding box,
v is a parameter measuring the consistency of the aspect ratio,
and
are the width and height of the ground truth box, respectively, and
and
are the width and height of the prediction box, respectively.
Considering the possible directional mismatch between the prediction box and the ground truth box, we introduce a new bounding box position loss, replacing the original CIoU loss with the SIoU loss. This loss takes into account the vector angle between regressions and redefines the penalty metric, effectively reducing the total degrees of freedom of the loss. The SIoU loss consists of four costs: angle, distance, shape and IoU, which is calculated as follows:
The angle cost is defined as follows:
Distance cost has been redefined based on the definition of angle cost:
Finally, the regression loss function for the position loss of bounding box is written as follows:
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}