
High-Performance QC-LDPC Code Co-Processing Approach and VLSI Architecture for Wi-Fi 6
Abstract
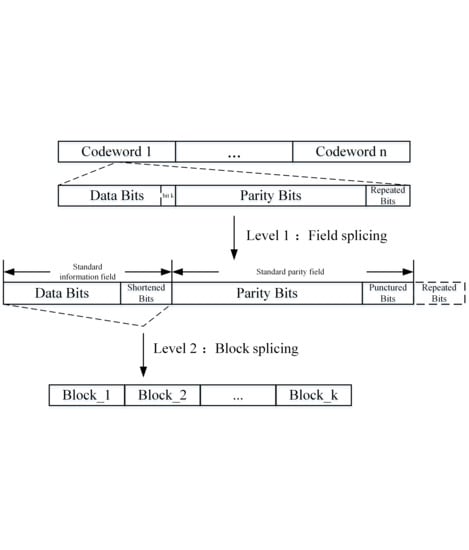
:
1. Introduction
2. Decoding Process and Parameters Calculation of the Decoder
2.1. Decoding Process
2.2. Co-Processing Parameter Calculation
2.2.1. Calculate the Real Number of Symbols NSYM and the Number of Available Bits Navbits
2.2.2. Compute the Number and Length of the Codewords
2.2.3. Calculate the SBs, PBs, and RBs
3. The Co-Processing Schemes and Architectures
3.1. The Strategy and Architecture of Pre-Processing
3.2. Post-Processing Strategy and Architecture
4. Implementation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- IEEE, 802.11-2016; Standard for Information Technology—Local and Metropolitan Area Networks—Specific Requirements—Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications. IEEE Standard Association: Piscataway, NJ, USA, 2016.
- IEEE, 802.11ax-2021; Standard for Information Technology—Telecommunications and Information Exchange between Systems Local and Metropolitan Area Networks—Specific Requirements Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications Amendment 1: Enhancements for High-Efficiency WLAN. IEEE Standard Association: Piscataway, NJ, USA, 2021; pp. 1–767.
- IEEE, 802.16-2004; Standard for Local and Metropolitan Area Networks—Part 16: Air Interface for Fixed Broadband Wireless Access Systems. IEEE Standard Association: Piscataway, NJ, USA, 2004.
- 3GPP TS 38.212 V16.1.0 (2020–03); 3rd Generation Partnership Project; Technical Specification Group Radio Access Network; NR. Multiplexing and channel coding (Release 16). ETSI: Sophia Antipolis, France, 2020.
- Suls, A.; Lefevre, Y.; Van Hecke, J.; Guenach, M.; Moeneclaey, M. Error Performance Prediction of Randomly Shortened and Punctured LDPC Codes. IEEE Commun. Lett. 2019, 23, 560–563. [Google Scholar] [CrossRef]
- Beermann, M.; Beermann, V.P. Joint optimization of multi-rate LDPC code ensembles for the AWGN channel based on shortening and puncturing. In Proceedings of the 2014 IEEE Wireless Communications and Networking Conference (WCNC), Istanbul, Turkey, 20 November 2014; pp. 200–205.
- Asvadi, R.; Banihashemi, A.H. A Rate-Compatible Puncturing Scheme for Finite-Length LDPC Codes. IEEE Commun. Lett. 2013, 17, 147–150. [Google Scholar] [CrossRef]
- Yongmin, J.; Chulho, C.; Jaeseok, K.; Yunho, J. 7.7 Gbps encoder design for IEEE 802.11n/ac QC-LDPC codes. In Proceedings of the 2012 International SoC Design Conference (ISOCC), Jeju Island, Replublic of Korea, 4–7 November 2012; pp. 215–218. [Google Scholar]
- Tsatsaragkos, I.; Paliouras, V. A Reconfigurable LDPC Decoder Optimized for 802.11n/ac Applications. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 182–195. [Google Scholar] [CrossRef]
- Roberts, M.K.; Jayabalan, R. An area efficient and high throughput multi-rate quasi-cyclic LDPC decoder for IEEE 802.11n applications. Microelectron. J. 2014, 45, 1489–1498. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Range of Navbits (bits) | NCW | LLDPC (bits) |
|---|---|---|
| . | 1 | 1296, if 648, otherwise |
| 1 | 1944, if 1296, otherwise | |
| 1 | 1944 | |
| 2 | 1944, if 1296, otherwise | |
| 1944 |
| Nss | BPSK | QPSK | 16QAM | 64QAM | 256QAM | 1024QAM |
|---|---|---|---|---|---|---|
| 1 | Q | Q | 2 × Q | 4 × Q | 6 × Q | 8 × Q |
| 2 | 2 × Q | 2 × Q | 4 × Q | 8 × Q | 12 × Q | 16 × Q |
| … | … | ... | ... | ... | ... | ... |
| 8 | 8 × Q | 8 × Q | 16 × Q | 32 × Q | 48 × Q | 64 × Q |
| Component | Area (mm2) | Complexity (kGE 1) | Percentage (%) |
|---|---|---|---|
| Block Stitching | 0.079 | 61.91 | 45.52 |
| Input Buffer | 0.046 | 35.73 | 26.28 |
| Output Buffer | 0.037 | 28.63 | 21.05 |
| Global Control | 0.005 | 4.01 | 2.95 |
| Preprocessor | 0.167 | 130.28 | 95.80 |
| Global Control2 | 0.001 | 1.01 | 0.74 |
| Input Buffer2 | 0.005 | 3.88 | 2.85 |
| Bit Width Converter | 0.002 | 1.32 | 0.97 |
| Postprocessor | 0.008 | 6.21 | 4.56 |
| Total | 0.175 | 136.49 | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Wu, B.; Zhou, X. High-Performance QC-LDPC Code Co-Processing Approach and VLSI Architecture for Wi-Fi 6. Electronics 2023, 12, 1210. https://doi.org/10.3390/electronics12051210
Wu Y, Wu B, Zhou X. High-Performance QC-LDPC Code Co-Processing Approach and VLSI Architecture for Wi-Fi 6. Electronics. 2023; 12(5):1210. https://doi.org/10.3390/electronics12051210
Chicago/Turabian StyleWu, Yujun, Bin Wu, and Xiaoping Zhou. 2023. "High-Performance QC-LDPC Code Co-Processing Approach and VLSI Architecture for Wi-Fi 6" Electronics 12, no. 5: 1210. https://doi.org/10.3390/electronics12051210