
Hybrid Classifiers for Spatio-Temporal Abnormal Behavior Detection, Tracking, and Recognition in Massive Hajj Crowds

 ,
,  , , and
, , and
Abstract
:1. Introduction
- We introduce a manually annotated and labeled large-scale crowd abnormal behaviors dataset for Hajj, HAJJv2;
- We propose two methods of hybrid CNN and RF classifiers to detect, track, and recognize spatio-temporal abnormal behaviors in small-scale and large-scale crowd videos;
- We evaluate the first proposed method on two common benchmark small-scale crowd video datasets, UMN and UCSD, against the currently published methods. Then, we evaluate the second proposed method on the HAJJv2 dataset and compare it with the previously existing method.
2. Related Work
- Small-scale crowds: Many recent studies have proposed and evaluated their methods on small-scale and common benchmark crowd public datasets, including UMN and UCSD [10,28,29,30,31,32,33].Piciarelli et al. [6] introduced a normal model by clustering the trajectories of moving objects for anomaly detection. Then, Mehran et al. [28] proposed to use an optical flows-based social force model to detect abnormal behaviors. A grid of particles was computed over the frames. Then, a bag of words method was applied to classify normal and abnormal behaviors.After Mehran et al. [28]’s work, Mahadevan et al. [29] applied learned mixtures of dynamic textures based on optical flow with salient location identification to detect abnormalities in the spatial domain. In the temporal domain, the learned mixtures of dynamic textures based on optical flow with negative log-likelihood were applied to detect abnormalities. Then, Cong et al. [32] applied a sparse reconstruction cost and a dictionary to measure normal and abnormal behaviors.After that, Zhang et al. [10] introduced a social attribute-aware force model. Using an online fusion algorithm, the social attribute-aware force maps are computed. Then, global abnormal events are detected with a bag-of-words representation and local abnormal events with an abnormal map.Later, Hasan et al. [30] learned semi-supervised spatio-temporal local hand-crafted features on a convolutional autoencoder to detect abnormal patterns. Histograms of oriented gradients and histograms of optical lows were used to extract the spatio-temporal features from raw video frames to feed the convolutional autoencoder for classification. Fradi et al. [13] applied local feature tracking to describe the movements of the crowd. They represented the crowd as an evolving graph. To analyze the crowd scene for an abnormal event, mid-level features are extracted from the graph.Colque et al. [7] used the histograms of magnitude, orientation, and entropy of the optical flow with the nearest neighbor search algorithm to detect the anomalies. In the training phase, they stored the histograms of each moving object as normal patterns. In the testing phase, they used the nearest neighbor search to find normal patterns to decide the abnormality.Coşar et al. [5] employed trajectory features and motion features. They used a bag-of-words representation to describe the actions. Then, they applied a clustering algorithm to perform abnormal detection in an unsupervised manner.Followed by [5,7,13,30], Tudor Ionescu et al. [31] used a sliding window technique to obtain partial video frames. The motions and appearance features were extracted from the frames and fed to a linear binary classifier to detect normality and abnormality in behaviors.Recently, Alafif et al. [33] applied a FlowNet and UNet framework to generate normal and abnormal optical flows to detect abnormalities. However, most current existing abnormal behavior detection methods are computationally expensive since they require modeling the appearance of the frames [29], particles advection [28], sliding windows [30,31], dictionaries [32], hand-crafted features extractors [30], and generating images [33]. In addition to the computational efficiency drawbacks, the effectiveness of their approach may decrease in large-scale crowds since they have many challenges, including partial and full occlusions, different scales, blurring, and a large number of abnormal behaviors.
- Large-scale crowds: Several research works studied abnormal behaviors on large-scale crowds [2,13,33,34,35,36,37,38,39,40,41,41].First, Solmaz et al. [34] introduced a linear approximation using a Jacobian matrix to identify large-scale crowd abnormal behaviors. An optical flow and particle advection were used. Then, Wang et al. [35] started to cluster crowd feature maps to analyze motion patterns. Followed by [35], Alqaysi and Sasi [36] applied motion history image and segmented optical flow to extracted features. Then, a histogram was used for the motion direction and magnitude to detect crowd abnormal behaviors.Later, Zou et al. [37] detected large-scale crowd motions and trajectories using tracklets association. Similar to [37], Bera et al. [2] computed abnormal behavior trajectories using Bayesian learning techniques. Then, Pennisi et al. [38] segmented the extracted features to detect crowd abnormal behaviors. In recent years, Fradi et al. [13] and Wu et al. [39] worked on analyzing large-scale crowd properties using visual feature descriptors. Then, Luo et al. [42] proposed a large-scale crowd motion framework for abnormal behavior detection. However, they focused on a crowd level rather than an individual level in their study. Finally, Miao et al. [40,41] leveraged unmanned aerial vehicles, airborne LiDAR, and computer vision technologies to continuously analyze individual abnormal behaviors in large-scale crowds.However, existing methods are only confined to detecting and analyzing large-scale crowds as a mass. To the best of our knowledge, no existing works have detected individuals’ abnormal behaviors in large-scale crowds, with the exception of the work presented in [33]. In comparison with the recent work in [33], the proposed methods do not require generating individual abnormal behavior images. Compared to the work in [33], the proposed method achieves better accuracy using the HAJJv1 dataset.
3. HAJJv2 Dataset
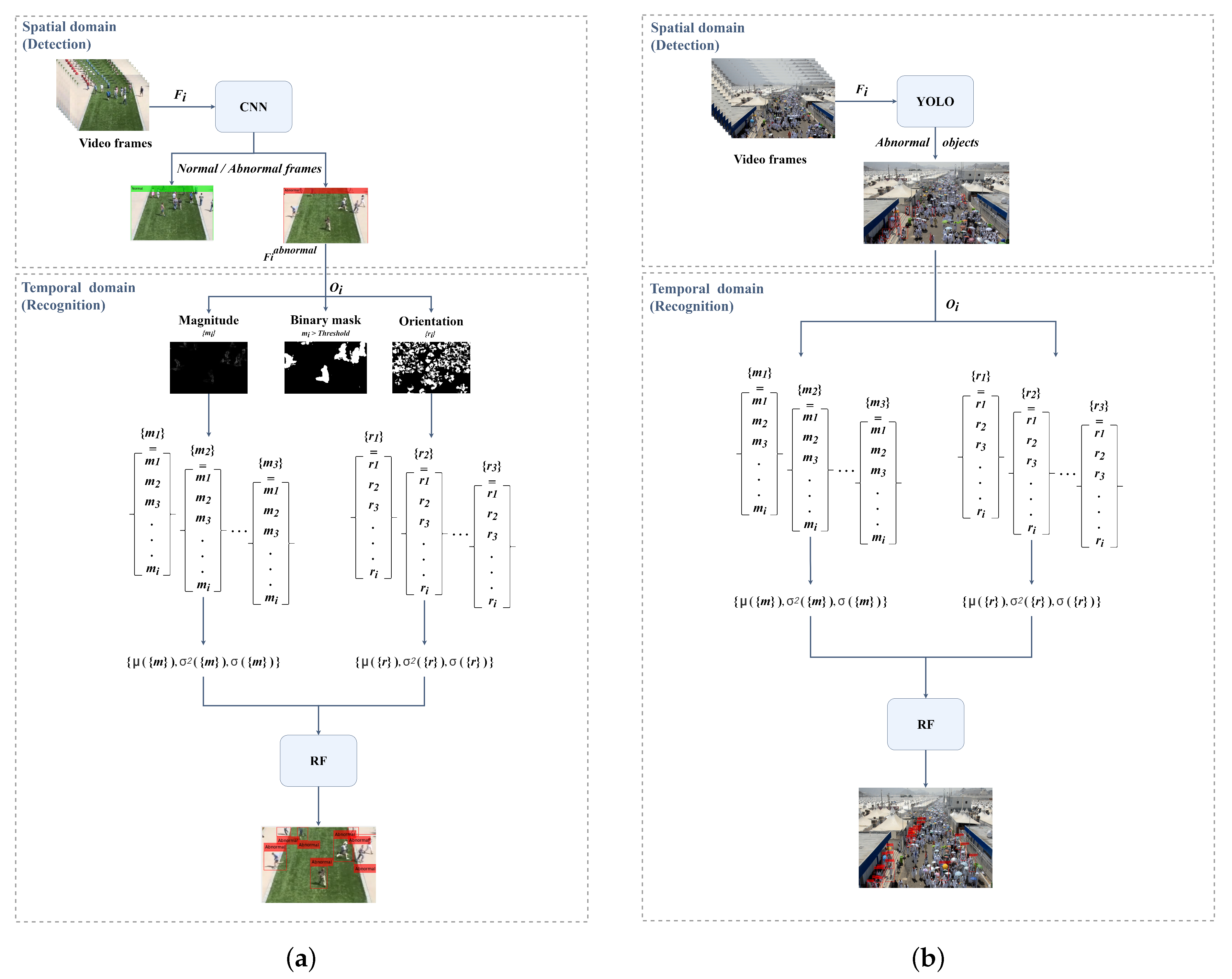
4. Proposed Methods
4.1. Individual Abnormal Behavior Detection, Tracking, and Recognition in Small-Scale Crowds
| Algorithm 1: A hybrid CNN and RF algorithm for spatio-temporal small-scale crowd abnormal behavior detection, tracking, and recognition in a video. |
 |
4.2. Individual Abnormal Behavior Detection and Recognition in Large-Scale Crowds
| Algorithm 2: A hybrid CNN and RF algorithm for spatio-temporal large-scale crowd abnormal behavior detection, tracking, and recognition in a video. |
 |
5. Experiments
5.1. Implementation
5.2. Datasets
- The University of Minnesota (UMN) dataset. The UMN dataset is a small-scale crowd dataset that contains three different unrealistic scenes. Two scenes were recorded outdoors, while one was recorded indoors. Each UMN scene starts with a normal activity followed by an abnormal behavior. Walking, for example, is considered a normal activity, while running is an abnormal one. The frame resolution in UMN scenes is 320 × 240 pixels. The abnormal frames contain a short description at the top of the frames. Thus, we apply a pre-processing technique on the frames to remove the pixels that contain these descriptions to avoid biases in training and testing the model in the experiment. Figure 4 illustrates an example of UMN’s frames. The training and testing splits are not explicitly specified. Moreover, the annotations are only available at the frame level. Due to these ambiguities, we use 70% of the frames for training and the rest for testing. To address the lack of pixel-level annotations, we consider all objects in the abnormal frames as abnormal individuals and all objects in the normal frames as normal individuals. The UMN scenes are evaluated separately since they have illumination and background variations.
- The University of California, San Diego (UCSD) dataset. The UCSD dataset is also a small-scale crowd dataset that consists of two subsets, namely Pedestrian 1 (Ped1) and Pedestrian 2 (Ped2). The dataset contains clips from independent static cameras viewing pedestrian walkways. It includes abnormal behaviors such as bicycles, cars, carts, skateboards, and wheelchairs as non-pedestrian objects. Ped1 contains 34 normal behavior videos and 16 abnormal behavior videos. Each video contains 200 frames with a resolution of 238 × 158 pixels. Ped2 contains 16 normal behavior videos and 12 abnormal behavior videos. The videos have different numbers of frames with a resolution of 360 × 240 pixels. Both temporal and spatial annotations are provided. Thus, the UCSD is appropriate for locating and tracking abnormal objects in small-scale crowds. In our experiment, we use both normal and abnormal videos for training and testing. Figure 5 illustrates some examples from Ped1 and Ped2 frames.
5.3. Experimental Settings and Hyperparameters
5.4. Effectiveness Evaluation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | UCSD Ped1 | UCSD Ped2 |
|---|---|---|
| MPPCA [51] | 59.0% | 69.3% |
| Social Force[SF] [28] | 67.5% | 55.6% |
| SF+MPPCA [29] | 68.8% | 61.3% |
| MDT [29] | 81.8% | 82.9% |
| Conv-AE [30] | 75.0% | 85.0% |
| Stacked RNN [52] | N/A | 92.2% |
| Unmasking [31] | 68.4% | 82.2% |
| Alafif et al. [33] | 82.81% | 95.7% |
| Ours | 88.87% | 98.55% |
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, Y.; Qin, L.; Ji, R.; Zhao, S.; Huang, Q.; Luo, J. Exploring coherent motion patterns via structured trajectory learning for crowd mood modeling. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 635–648. [Google Scholar] [CrossRef]
- Bera, A.; Kim, S.; Manocha, D. Realtime Anomaly Detection Using Trajectory-Level Crowd Behavior Learning. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 27–30 June 2016; pp. 1289–1296. [Google Scholar] [CrossRef]
- Zhou, S.; Shen, W.; Zeng, D.; Zhang, Z. Unusual event detection in crowded scenes by trajectory analysis. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 1300–1304. [Google Scholar] [CrossRef]
- Zhao, K.; Liu, B.; Li, W.; Yu, N.; Liu, Z. Anomaly Detection and Localization: A Novel Two-Phase Framework Based on Trajectory-Level Characteristics. In Proceedings of the 2018 IEEE International Conference on Multimedia Expo Workshops (ICMEW), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Coşar, S.; Donatiello, G.; Bogorny, V.; Garate, C.; Alvares, L.O.; Brémond, F. Toward abnormal trajectory and event detection in video surveillance. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 683–695. [Google Scholar] [CrossRef]
- Piciarelli, C.; Micheloni, C.; Foresti, G.L. Trajectory-based anomalous event detection. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1544–1554. [Google Scholar] [CrossRef]
- Colque, R.V.H.M.; Caetano, C.; de Andrade, M.T.L.; Schwartz, W.R. Histograms of optical flow orientation and magnitude and entropy to detect anomalous events in videos. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 673–682. [Google Scholar] [CrossRef]
- Cho, S.H.; Kang, H.B. Abnormal behavior detection using hybrid agents in crowded scenes. Pattern Recognit. Lett. 2014, 44, 64–70. [Google Scholar] [CrossRef]
- Qasim, T.; Bhatti, N. A hybrid swarm intelligence based approach for abnormal event detection in crowded environments. Pattern Recognit. Lett. 2019, 128, 220–225. [Google Scholar] [CrossRef]
- Zhang, Y.; Qin, L.; Ji, R.; Yao, H.; Huang, Q. Social attribute-aware force model: Exploiting richness of interaction for abnormal crowd detection. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 1231–1245. [Google Scholar] [CrossRef]
- Guo, H.; Wu, X.; Cai, S.; Li, N.; Cheng, J.; Chen, Y.L. Quaternion Discrete Cosine Transformation Signature Analysis in Crowd Scenes for Abnormal Event Detection. Neurocomputing 2016, 204, 106–115. [Google Scholar] [CrossRef]
- Yuan, Y.; Fang, J.; Wang, Q. Online Anomaly Detection in Crowd Scenes via Structure Analysis. IEEE Trans. Cybern. 2015, 45, 548–561. [Google Scholar] [CrossRef] [PubMed]
- Fradi, H.; Luvison, B.; Pham, Q.C. Crowd behavior analysis using local mid-level visual descriptors. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 589–602. [Google Scholar] [CrossRef]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A Simple Deep Learning Baseline for Image Classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sikdar, A.; Chowdhury, A.S. An adaptive training-less framework for anomaly detection in crowd scenes. Neurocomputing 2020, 415, 317–331. [Google Scholar] [CrossRef]
- Mehmood, A. Efficient Anomaly Detection in Crowd Videos Using Pre-Trained 2D Convolutional Neural Networks. IEEE Access 2021, 9, 138283–138295. [Google Scholar] [CrossRef]
- Bansod, S.D.; Nandedkar, A.V. Anomalous Event Detection and Localization Using Stacked Autoencoder. In Proceedings of the International Conference on Computer Vision and Image Processing, Jaipur, India, 27–29 September 2019; Springer: New York, NY, USA, 2019; pp. 117–129. [Google Scholar]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Klette, R. Deep-Cascade: Cascading 3D Deep Neural Networks for Fast Anomaly Detection and Localization in Crowded Scenes. IEEE Trans. Image Process. 2017, 26, 1992–2004. [Google Scholar] [CrossRef]
- Chaker, R.; Aghbari, Z.A.; Junejo, I.N. Social network model for crowd anomaly detection and localization. Pattern Recognit. 2017, 61, 266–281. [Google Scholar] [CrossRef]
- Zhou, S.; Shen, W.; Zeng, D.; Fang, M.; Wei, Y.; Zhang, Z. Spatial–temporal convolutional neural networks for anomaly detection and localization in crowded scenes. Signal Process. Image Commun. 2016, 47, 358–368. [Google Scholar] [CrossRef]
- Chen, C.Y.; Shao, Y. Crowd Escape Behavior Detection and Localization Based on Divergent Centers. IEEE Sens. J. 2015, 15, 2431–2439. [Google Scholar] [CrossRef]
- Bansod, S.D.; Nandedkar, A.V. Crowd anomaly detection and localization using histogram of magnitude and momentum. Vis. Comput. 2020, 36, 609–620. [Google Scholar] [CrossRef]
- Sikdar, A.; Chowdhury, A.S. Multi-level Threat Analysis in Anomalous Crowd Videos. In Proceedings of the International Conference on Computer Vision and Image Processing, Jaipur, India, 27–29 September 2019; Springer: New York, NY, USA, 2019; pp. 495–506. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Mehran, R.; Oyama, A.; Shah, M. Abnormal crowd behavior detection using social force model. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 935–942. [Google Scholar]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]
- Tudor Ionescu, R.; Smeureanu, S.; Alexe, B.; Popescu, M. Unmasking the abnormal events in video. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2895–2903. [Google Scholar]
- Cong, Y.; Yuan, J.; Liu, J. Sparse reconstruction cost for abnormal event detection. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 3449–3456. [Google Scholar]
- Alafif, T.; Alzahrani, B.; Cao, Y.; Alotaibi, R.; Barnawi, A.; Chen, M. Generative adversarial network based abnormal behavior detection in massive crowd videos: A Hajj case study. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 4077–4088. [Google Scholar] [CrossRef]
- Solmaz, B.; Moore, B.E.; Shah, M. Identifying behaviors in crowd scenes using stability analysis for dynamical systems. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2064–2070. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Zhao, X.; Wu, Z.; Liu, Y. Motion pattern analysis in crowded scenes based on hybrid generative-discriminative feature maps. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 2837–2841. [Google Scholar]
- Alqaysi, H.H.; Sasi, S. Detection of abnormal behavior in dynamic crowded gatherings. In Proceedings of the 2013 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 23–25 October 2013; pp. 1–6. [Google Scholar]
- Zou, Y.; Zhao, X.; Liu, Y. Detect coherent motions in crowd scenes based on tracklets association. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4456–4460. [Google Scholar]
- Pennisi, A.; Bloisi, D.D.; Iocchi, L. Online real-time crowd behavior detection in video sequences. Comput. Vis. Image Underst. 2016, 144, 166–176. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Yang, H.; Zheng, S.; Su, H.; Fan, Y.; Yang, M.H. Crowd behavior analysis via curl and divergence of motion trajectories. Int. J. Comput. Vis. 2017, 123, 499–519. [Google Scholar] [CrossRef]
- Miao, Y.; Yang, J.; Alzahrani, B.; Lv, G.; Alafif, T.; Barnawi, A.; Chen, M. Abnormal Behavior Learning Based on Edge Computing toward a Crowd Monitoring System. IEEE Netw. 2022, 36, 90–96. [Google Scholar] [CrossRef]
- Miao, Y.; Tang, Y.; Alzahrani, B.A.; Barnawi, A.; Alafif, T.; Hu, L. Airborne LiDAR assisted obstacle recognition and intrusion detection towards unmanned aerial vehicle: Architecture, modeling and evaluation. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4531–4540. [Google Scholar] [CrossRef]
- Luo, L.; Li, Y.; Yin, H.; Xie, S.; Hu, R.; Cai, W. Crowd-level Abnormal Behavior Detection via Multi-scale Motion Consistency Learning. arXiv 2022, arXiv:2212.00501. [Google Scholar]
- Of Minnesota, U. Unusual Crowd Activity Dataset of University of Minnesota. 2020. Available online: http://mha.cs.umn.edu/movies/crowdactivity-all.avi (accessed on 25 April 2020).
- Horn, B.K.; Schunck, B.G. Determining optical flow. In Artificial Intelligence; Elsevier: Amsterdam, The Netherlands, 1981; Volume 17, pp. 185–203. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Bishop, G.; Welch, G. An introduction to the kalman filter. Proc. Siggraph Course 2001, 8, 41. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Bottou, L. Stochastic gradient learning in neural networks. Proc. Neuro-Nımes 1991, 91, 12. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Kim, J.; Grauman, K. Observe locally, infer globally: A space-time MRF for detecting abnormal activities with incremental updates. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2921–2928. [Google Scholar]
- Luo, W.; Liu, W.; Gao, S. A revisit of sparse coding based anomaly detection in stacked rnn framework. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 341–349. [Google Scholar]
- Patel, N.; Mukherjee, S.; Ying, L. Erel-net: A remedy for industrial bottle defect detection. In Proceedings of the International Conference on Smart Multimedia, Toulon, France, 24–26 August 2018; Springer: New York, NY, USA, 2018; pp. 448–456. [Google Scholar]








| n | Classes | Training | Testing |
|---|---|---|---|
| 1 | Different Crowd Direction | 7152 | 6262 |
| 2 | Moving In Opposite | 36,577 | 18,802 |
| 3 | Moving Non Human Object | 4186 | 4146 |
| 4 | Running | 51 | 190 |
| 5 | Sitting | 100,633 | 83,644 |
| 6 | Sleeping | 2400 | 2618 |
| 7 | Standing | 19,773 | 14,107 |
| Total | 170,772 | 129,769 |
| Dataset | Abnormal Behaviors | Size | Crowd Scale | Reference |
|---|---|---|---|---|
| UMN | Escape | 24,240 KB | Small-scale | [43] |
| UCSD | Non-pedestrian movements | 1.74 GB | Small-scale | [33] |
| HAJJv1 | Standing, sitting, sleeping, running, moving in the opposite crowd direction, crossing or moving in different crowd direction, and non-pedestrian movements | 831 MB | Large-scale | [43] |
| HAJJv2 | Standing, sitting, sleeping, running, moving in the opposite crowd direction, crossing or moving in different crowd direction, and non-pedestrian movements | 831 MB | Large-scale | – |
| Dataset | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) | AUC (%) |
|---|---|---|---|---|---|
| UMN scene 1 | 97.93 | 98.31 | 99.15 | 98.73 | 99.73 |
| UMN scene 2 | 98.49 | 99.36 | 98.82 | 99.09 | 99.79 |
| UMN scene 3 | 98.07 | 99.46 | 98.41 | 98.93 | 99.77 |
| UCSD Ped1 | 75.72 | 64.72 | 89.31 | 75.05 | 88.87 |
| UCSD Ped2 | 94.14 | 96.29 | 92.11 | 94.15 | 98.55 |
| Dataset | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) | AUC (%) |
|---|---|---|---|---|---|
| UMN scene 1 | 88.85 | 99.34 | 87.35 | 92.96 | 97.00 |
| UMN scene 2 | 81.07 | 99.06 | 76.23 | 86.16 | 94.45 |
| UMN scene 3 | 93.33 | 99.40 | 93.32 | 96.26 | 97.38 |
| UCSD Ped1 | 99.49 | 99.60 | 99.88 | 99.74 | 97.66 |
| UCSD Ped2 | 99.62 | 99.76 | 99.86 | 99.81 | 97.43 |
| Method | UMN (%) |
|---|---|
| Optical flow [28] | 84.0 |
| SFM [28] | 96.0 |
| Sparse Reconstruction [32] | 97.0 |
| Alafif et al. [33] | 98.1 |
| Ours | 99.76 |
| Video No. | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) | AUC (%) |
|---|---|---|---|---|---|
| 10 (Arafat) | 60.73 | 62.01 | 55.95 | 58.83 | 90.38 |
| 12 (Tawaf) | 63.62 | 64.95 | 53.75 | 57.80 | 75.25 |
| 9 and 11 (Jamarat) | 96.83 | 33.47 | 33.02 | 33.24 | 61.19 |
| 2, 3, 5, 7, and 8 (Masaa) | 51.90 | 33.51 | 28.87 | 31.02 | 73.89 |
| Average | 68.27 | 48.49 | 42.90 | 45.22 | 75.18 |
| Track Assignment | IOU | |||||||
|---|---|---|---|---|---|---|---|---|
| Video No. | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) |
| 10 (Arafat) | 89.86 | 96.41 | 54.27 | 69.44 | 91.25 | 56.16 | 31.61 | 40.45 |
| 12 (Tawaf) | 96.66 | 98.84 | 2.92 | 5.67 | 96.87 | 4.65 | 0.14 | 0.27 |
| 9 and 11 (Jamarat) | 89.26 | 96.44 | 3.85 | 7.40 | 89.53 | 14.24 | 0.57 | 1.09 |
| 2, 3, 5, 7, and 8 (Masaa) | 91.30 | 78.19 | 50.93 | 61.69 | 93.23 | 51.66 | 33.65 | 40.75 |
| Average | 91.77 | 92.47 | 27.99 | 36.05 | 92.72 | 31.68 | 16.49 | 20.62 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1(%) | AUC (%) |
|---|---|---|---|---|---|
| Alafif et al. [33] | 65.10 | 61.48 | 80.30 | N/A | 79.63 |
| YOLOv2 (Ours) | 95.67 | 9.42 | 28.82 | 10.99 | N/A |
| RF (Ours) | 41.81 | 9.69 | 10.23 | 9.96 | 54.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alafif, T.; Hadi, A.; Allahyani, M.; Alzahrani, B.; Alhothali, A.; Alotaibi, R.; Barnawi, A. Hybrid Classifiers for Spatio-Temporal Abnormal Behavior Detection, Tracking, and Recognition in Massive Hajj Crowds. Electronics 2023, 12, 1165. https://doi.org/10.3390/electronics12051165
Alafif T, Hadi A, Allahyani M, Alzahrani B, Alhothali A, Alotaibi R, Barnawi A. Hybrid Classifiers for Spatio-Temporal Abnormal Behavior Detection, Tracking, and Recognition in Massive Hajj Crowds. Electronics. 2023; 12(5):1165. https://doi.org/10.3390/electronics12051165
Chicago/Turabian StyleAlafif, Tarik, Anas Hadi, Manal Allahyani, Bander Alzahrani, Areej Alhothali, Reem Alotaibi, and Ahmed Barnawi. 2023. "Hybrid Classifiers for Spatio-Temporal Abnormal Behavior Detection, Tracking, and Recognition in Massive Hajj Crowds" Electronics 12, no. 5: 1165. https://doi.org/10.3390/electronics12051165