
Appraising Early Reliability of a Software Component Using Fuzzy Inference

 , , and
, , and
Abstract
:1. Introduction
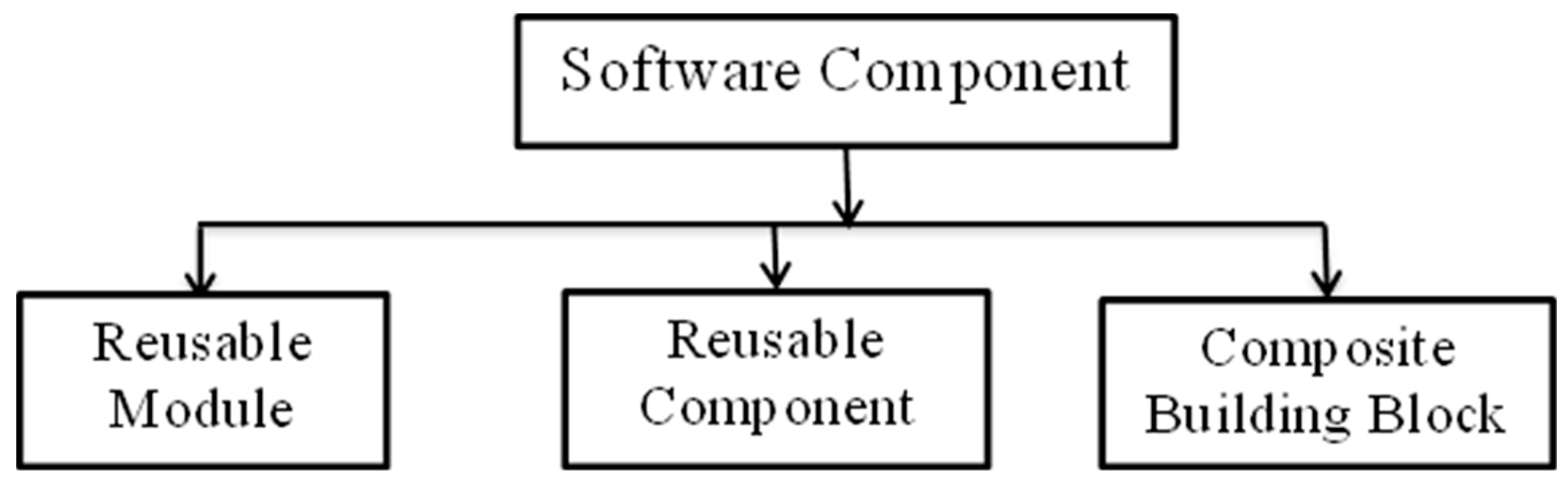
1.1. Software Component
- Reusable module: This is the traditional reusable concept, in which independent and realizable modules of the software encapsulate the functionality.
- Reusable component: This is an autonomous, exchangeable, deployable, and customized unit of software with specified interfaces. The third party can thereby reuse it according to application specifications and requirements.
- Composite building block: This emphasizes both component reuse and component composition to form a building block.
1.2. Research Flow
- Understand the existing software industry model and investigate any acceptable real-time changes that can enhance the performance of the model.
- Identify the influencing real-time factors and design the metric, or better recognize the prevailing industry-based metric, as it is showing results in real-time application.
- Determine the best technique for experimenting (i.e., Mamdani-Fuzzy inference system). Mamdani FIS depends on experts’ opinions. It is highly natural and produces good results.
- Experts’ based M-FIS: Design the rules by taking opinions from experts and domain-knowledge engineers. Fuzzify the inputs, i.e. map crisp input(s) into a fuzzy variable. Defuzzify the output by mapping the output to a crisp value.
- In the absence of experts, and given the industry’s profound demand for maximum automation, seek for some learning algorithm which can design a Mamdani FIS through data sets. (Fuzzy C-mean sunsupervised or self-learning.)
- Generate an inference system using Fuzzy C-means clustering, providing an input/output data set. Rules are auto generated through analysis of data behavior. The model is self-trained and predicts the reliability [10].
- Estimate the obtained results for both fuzzy inference systems and compare with the original to find the percentage of error.
2. Related Work
3. Fuzzy Logic
- Rules designed with domain knowledge and experts’ opinion yield significantly better result compared to statistical and regression models.
- When there is less or no domain knowledge, rules can also be designed using clustering techniques such as Fuzzy C-means, K-means, subtractive clustering, etc.
- This approach can apply without historical data, or even no data.
3.1. Fuzzy Inference System (FIS)
- Fuzzification: Input possessing a crisp scalar value in the universe of discourse is not deterministic and carries uncertainty and doubts. Therefore, crisp inputs transform into a fuzzy singleton with the help of different types of fuzzifiers (membership functions) in a domain.
- Rule Base: Experts and knowledge engineers design and develop the rules for inference. However:
- Inference: The inference evaluates rules using fuzzy sets of operations, and thus combine to achieve the final result.
- Defuzzification: This is the transformation of fuzzy outputs into an absolute crisp value. A crisp value is thereby obtained as the consequence of implication and aggregation. There are two types of fuzzy inference system:
- Sugeno-type fuzzy inference system: It works better with adaptive and optimization techniques, and control problems. It is highly computationally efficient, and is ideally suited for no dynamic linear systems [32].
3.2. Data Clustering
- Hard clustering: In this algorithm, each pattern lies exactly on one cluster, i.e. there are no overlapping groups and no probability calculation.
- Soft clustering: In this technique, each data point can belong to multiple clusters with some degree of membership. Soft clustering can be transformed into hard clustering by assigning each data point to the cluster having the highest membership.
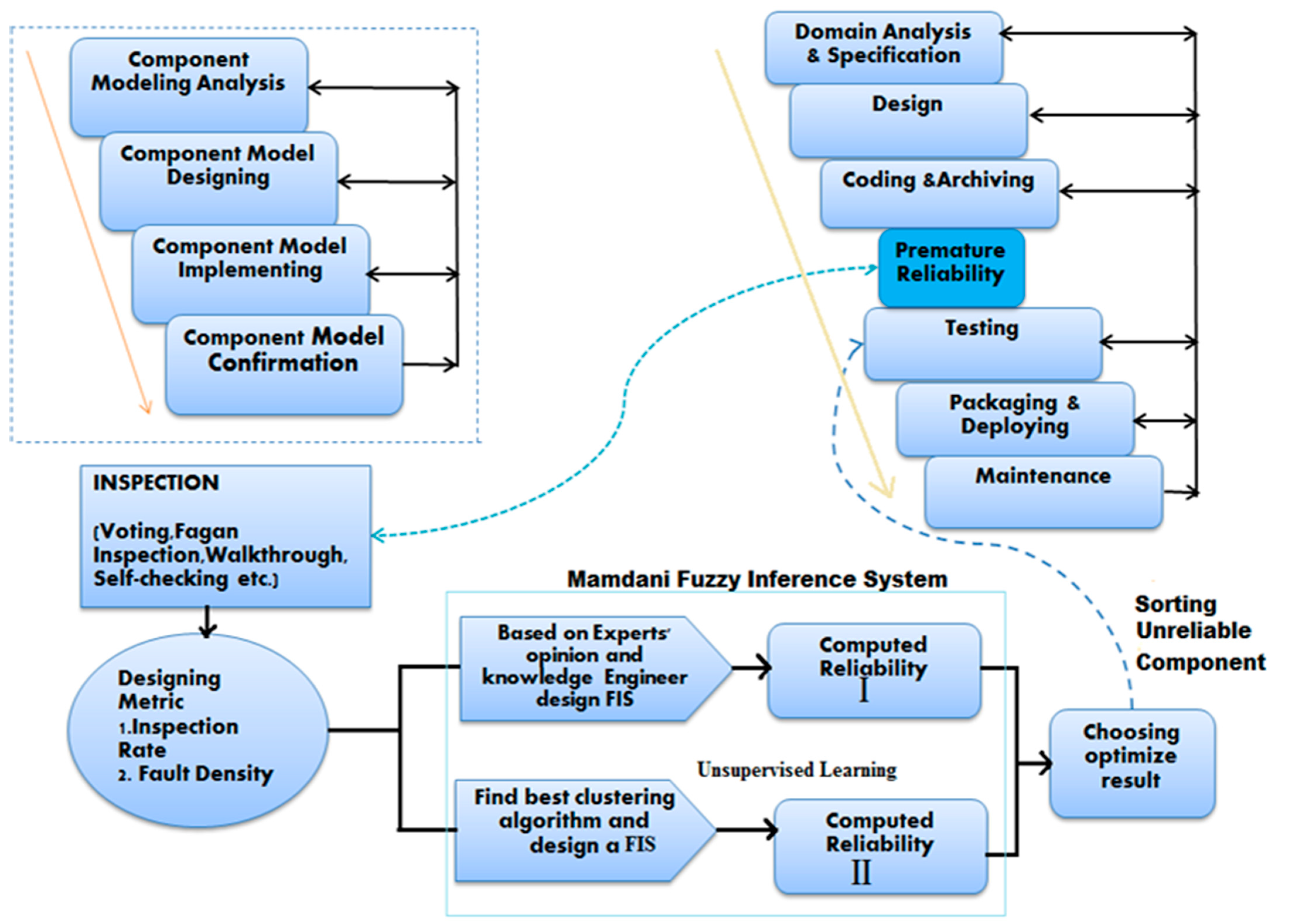
4. Proposed Model
4.1. Software Component Development Phases
- Domain analysis and specification: This is an envisioning phase, in which the development team defines the structure and objectives of solutions (including requirements, use case, technologies, interfaces, performance and operating environment).
- Design: This is a conceptual design phase that assigns functional logic in the architecture, and that realizes components via data-exchange mechanisms in interactions and via approaches in component packaging and deployment.
- Coding: This is the implementation phase, executed with specific technology and programming languages on a targeted operating environment.
- Testing: This is a validation phase for a software component, considering its specifications and design. It includes both black- and white-box testing, and provides all testing reports.
- Packaging and deployment: This phase ensures components’ customization, packaging, deployment approach, and tunes its configuration for a particular environment.
- Maintenance: This phase collects feedback and requests from users to enhance and upgrade it.
4.2. Designing Metric
- Inspection Rate: In the real inspection session, the inspectors study the program and search for mistakes. The inspection rate is calculated by dividing the number of source lines without comments that have been examined by the length of the inspection session. Inspection rate is not an entirely separate variable. It is influenced by the rate of defect identification, which is in turn influenced by the degree of planning and the frequency of errors in the code. It was determined that the inspection rate and the density of errors identified had an inverse correlation.
- Size of Code: It had been discovered that the primary factor affecting the planning and the inspection rate is the size of the code that had been inspected. In general, larger modules of code received relatively less research and underwent inspections more frequently. For bigger units of code, this led to a reduced density of identified mistakes. A reduced rate of inspection during the session and a high rate of preparatory work compared to the code size were two characteristics of the tiny to reasonably-sized coding units. As a consequence, these chunks of code usually had greater densities of identified mistakes.
4.3. Early Reliability Prediction
- Choose the most suitable defect-detection technique from industry practices such as voting, inspection, walkthrough, self-checking, and data-flow analysis. (Fagan inspection is costlier but shows better outcomes.)
- Inspection is a peer review of the early development phase by trained and experienced personnel, having a well-defined approach [37]. Obtaining an examination report provides inspection hours, the size of code, and a total number of found faults.
- Realize the metric inspection rate and fault density using Equations (2) and (3).
- Normalize the values for proper scaling between [0–1] by using min-max normalization.
- If experts are available with good domain knowledge, then design a Mamdani-FIS, else determine the suitable clustering technique and design a Mamdani fuzzy inference system using data sets. Personnel can judge both accuracy and differentiation.
- Select the optimized result, and on that basis reject the defect-prone component. Then move high-grade components to test beds for functionality and performance testing, and continue the following phases.
5. Case Study
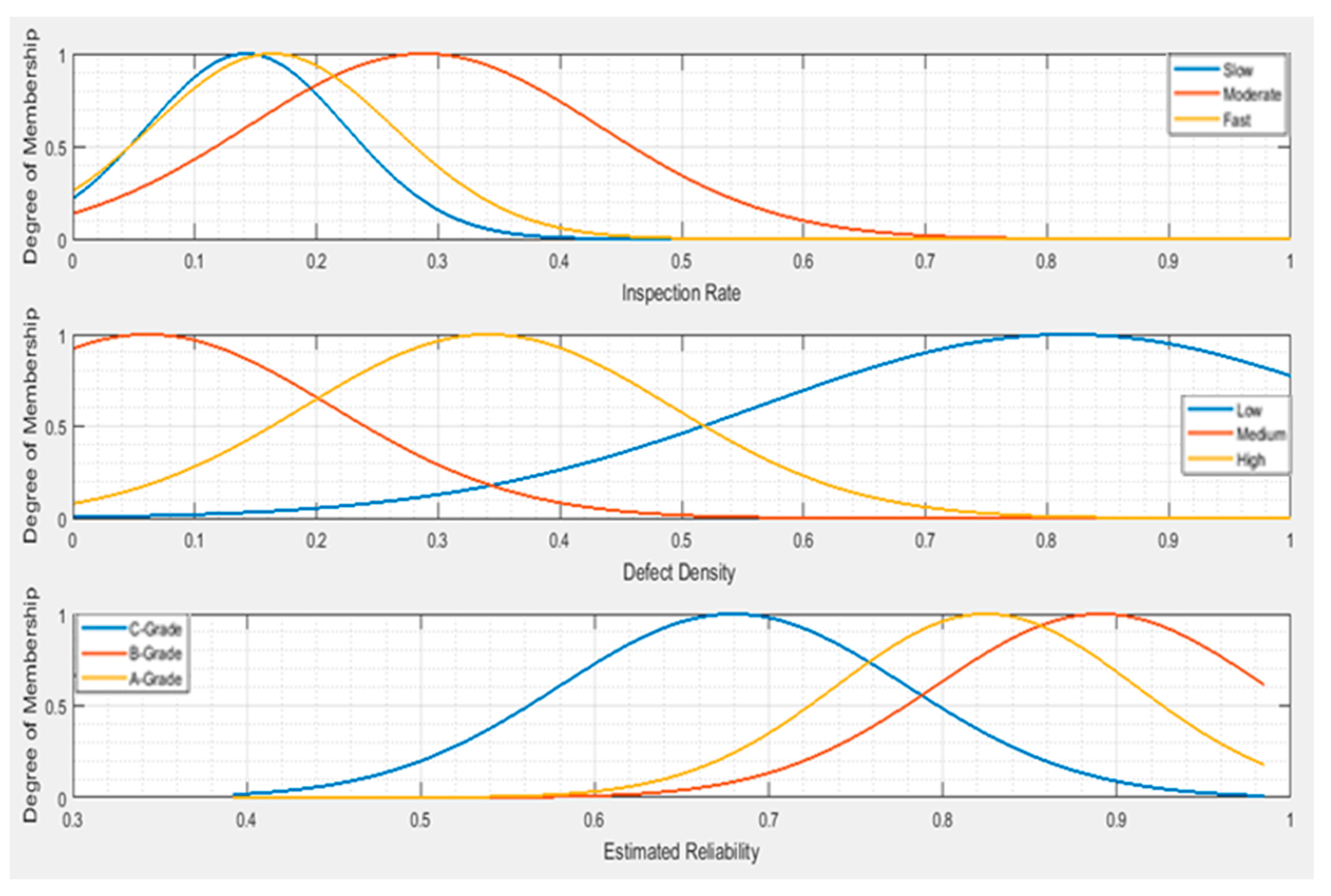
5.1. Experts’ Opinion Rule Base Mamdani-FIS
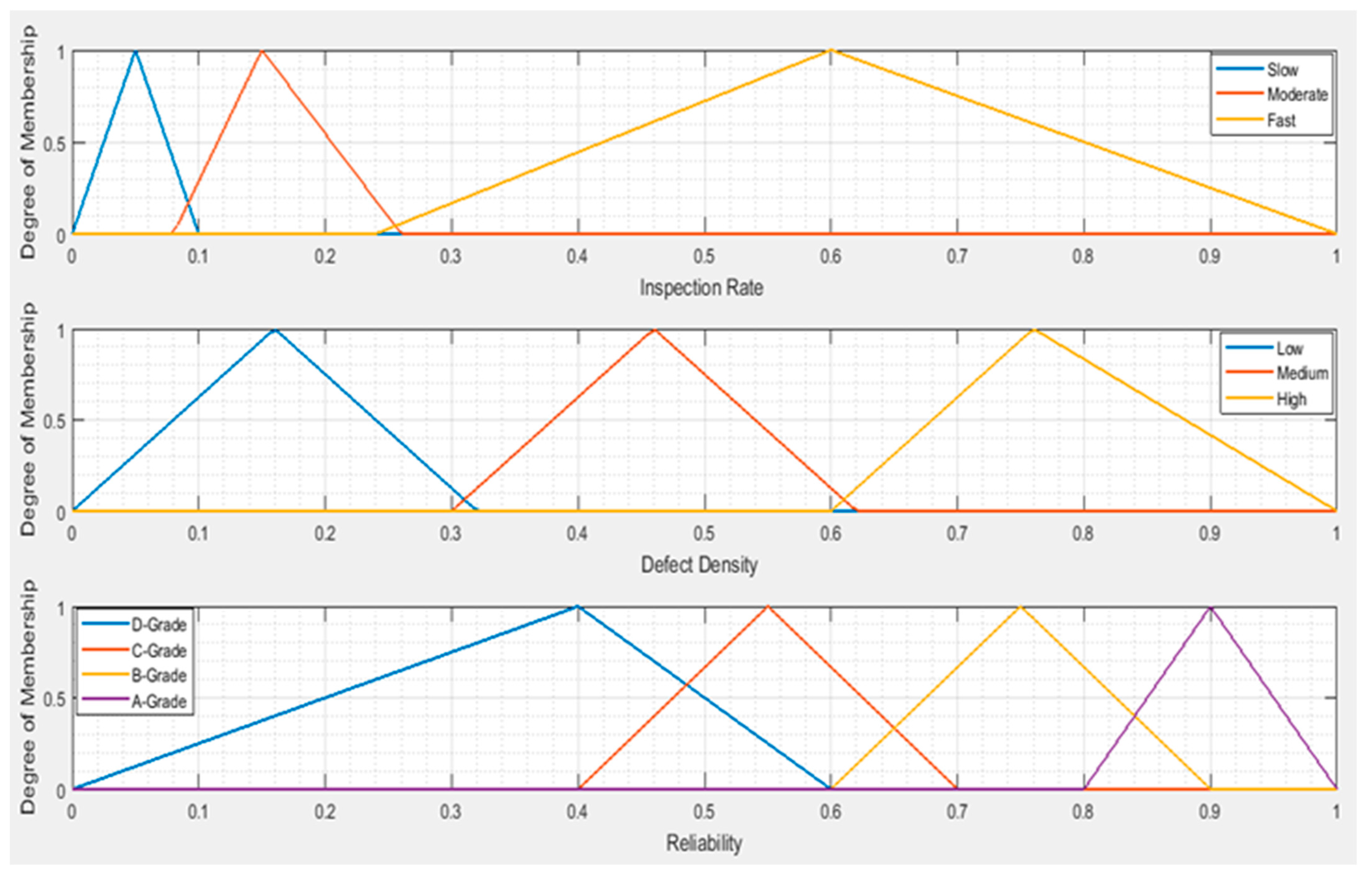
- If inspection rate is Fast and defect density is High, then the reliability index is grade-D.
- If inspection rate is Fast and defect density is Medium, then the reliability index is grade-C.
- If inspection rate is Fast and defect density is Low, then the reliability index is grade-B.
- If inspection rate is Moderate and defect density is High, then the reliability index is grade-C.
- If inspection rate is Moderate and defect density is Medium, then the reliability index is grade-B.
- If inspection rate is Moderate and defect density is Low, then the reliability index is grade-A.
- If inspection rate is Slow and defect density is High, then the reliability index is grade-C.
- If inspection rate is Slow and defect density is Medium, then the reliability index is grade-C.
- If inspection rate is Slow and defect density is Low, then the reliability index is grade-B.
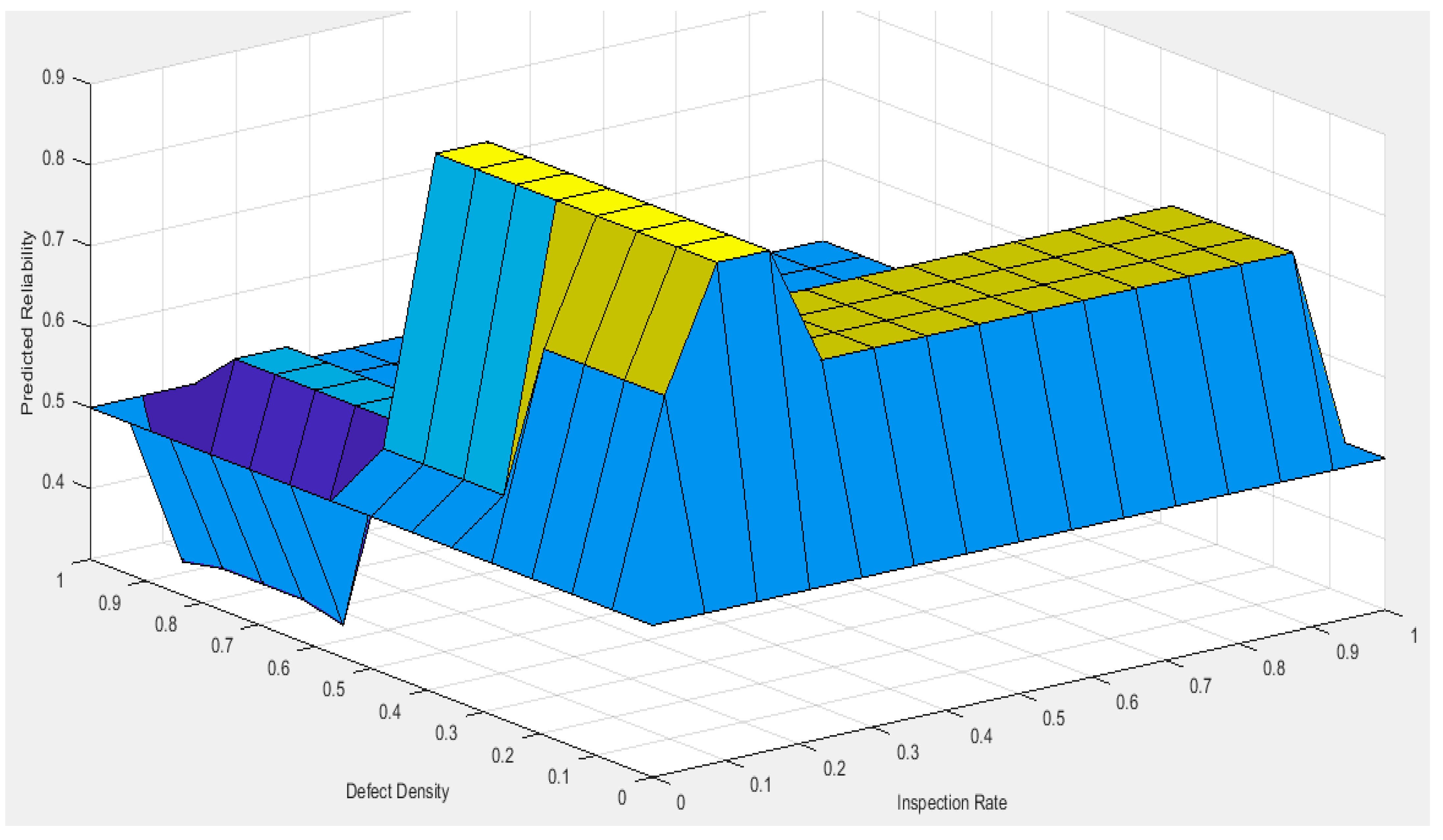
5.2. Evaluation of Model
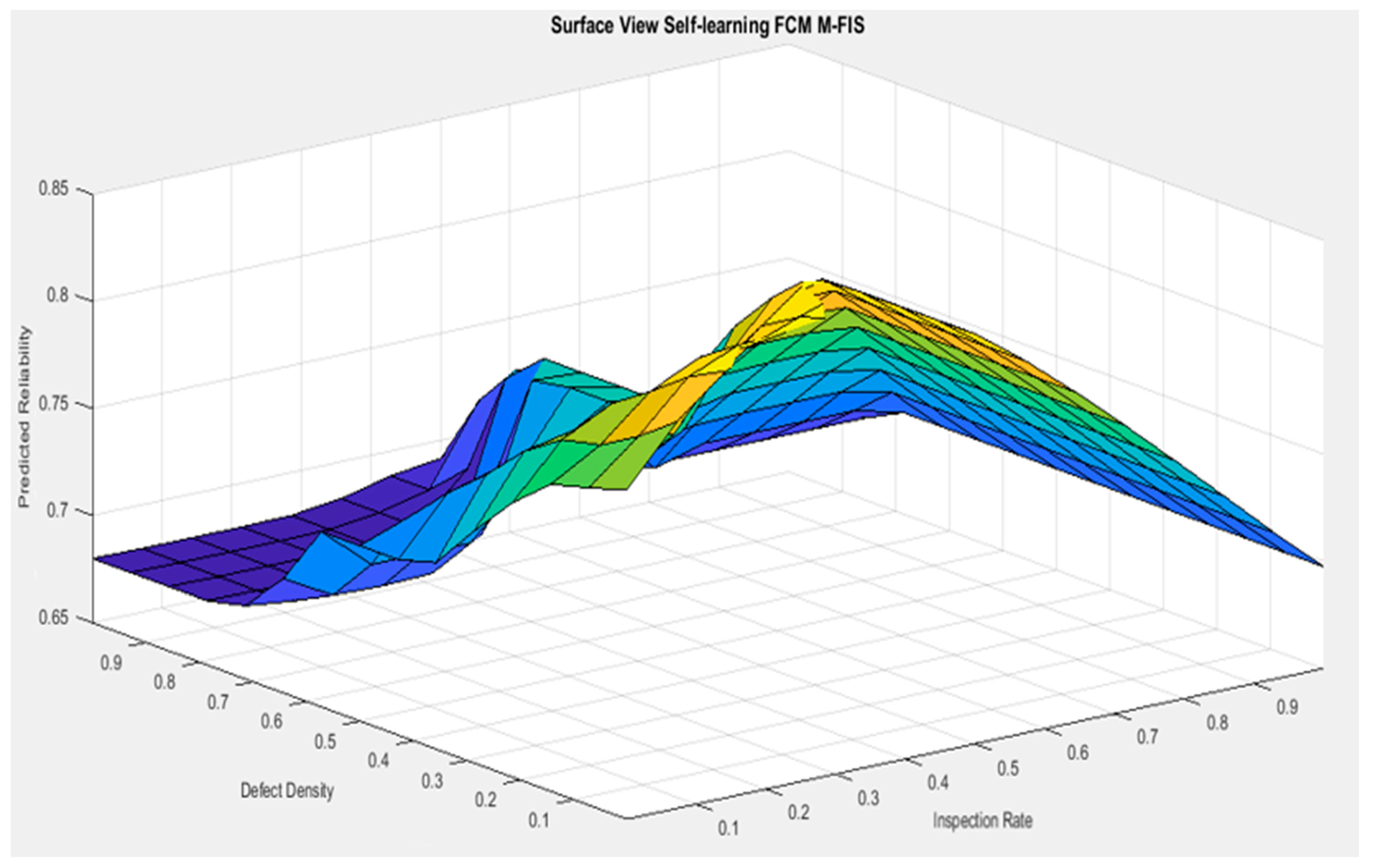
5.3. Self-Learning FCM Mamdani-FIS
5.4. Evaluation of the Model
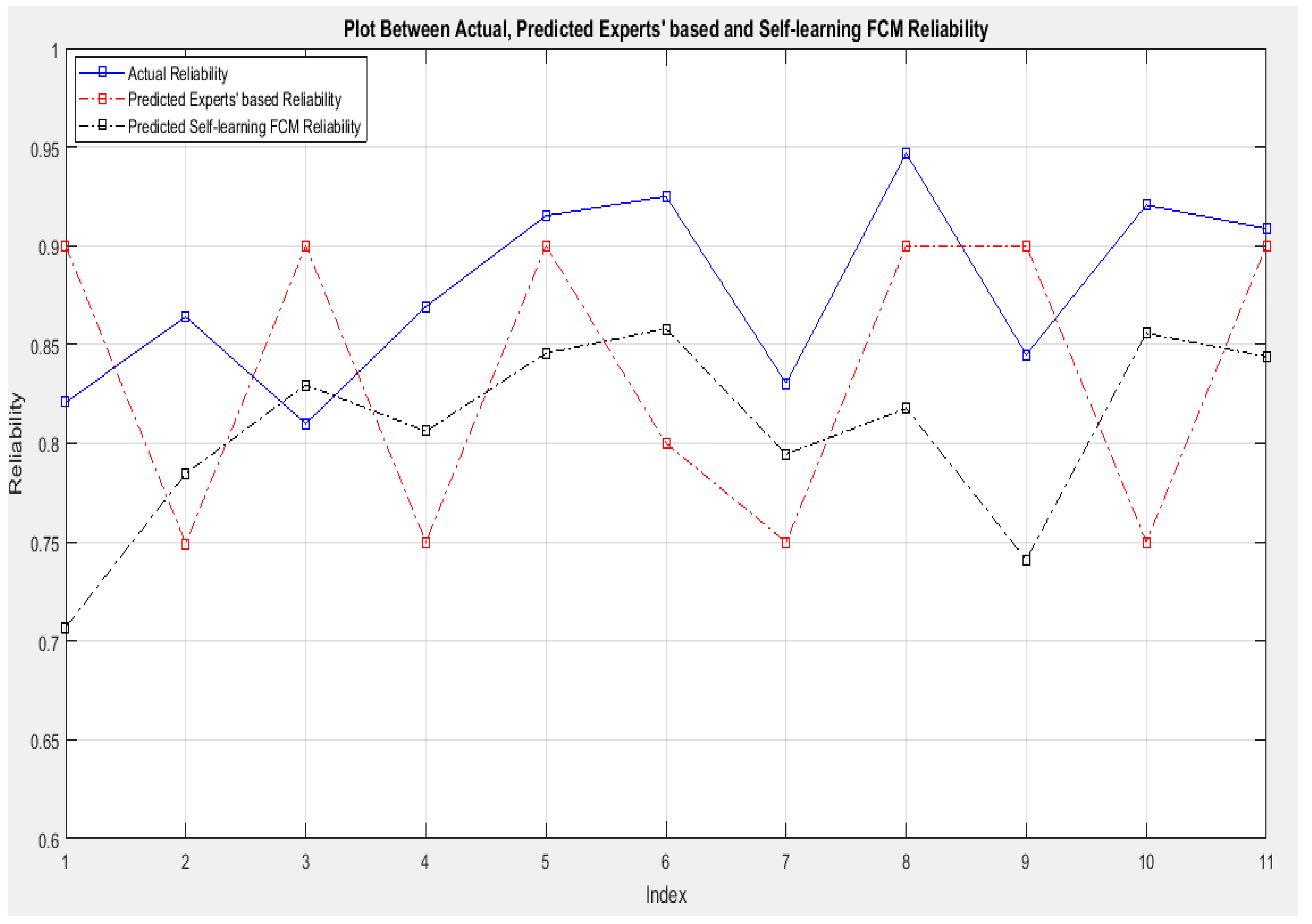
6. Results and Discussion
- Choose the variable that will be investigated.
- Assume values for each variable.
- Execute the simulation using the chosen series while maintaining the other variables at their default values.
- Determine the goal function for each property-evaluation metric.
- Determine the findings’ percentage difference and categories each variable correspondingly.
- Evaluate every variable’s relative importance.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Glinz, M. A glossary of requirements engineering terminology. Stand. Gloss. Certif. Prof. Requir. Eng. (CPRE) Stud. Exam 2011, 1, 56. [Google Scholar]
- Wang, G. Digital reframing: The design thinking of redesigning traditional products into innovative digital products. J. Prod. Innov. Manag. 2022, 39, 95–118. [Google Scholar] [CrossRef]
- Wang, R.; Xu, J.; Zhang, W.; Gao, J.; Li, Y.; Chen, F. Reliability analysis of complex electromechanical systems: State of the art, challenges, and prospects. Qual. Reliab. Eng. Int. 2022, 38, 3935–3969. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, M.; Chen, J. ELS algorithm for estimating open source software reliability with masked data considering both fault detection and correction processes. Commun. Stat.-Theory Methods 2022, 51, 6792–6817. [Google Scholar] [CrossRef]
- Parsons, S. Splithalf: Robust estimates of split half reliability. J. Open Source Softw. 2021, 6, 3041. [Google Scholar] [CrossRef]
- Gokhale, S.S.; Trivedi, K.S. Reliability prediction and sensitivity analysis based on software architecture. In Proceedings of the 13th International Symposium on Software Reliability Engineering, Annapolis, MD, USA, 12 November 2002. [Google Scholar]
- Wang, W.L.; Wu, Y.; Chen, M.H. An architecture-based software reliability model. In Proceedings of the 1999 Pacific Rim International Symposium on Dependable Computing, Hong Kong, China, 17 December 1999. [Google Scholar]
- Batra, S.; Sachdeva, S.; Bhalla, S. Entity Attribute Value Style Modeling Approach for Archetype Based Data. Information 2018, 9, 2. [Google Scholar] [CrossRef] [Green Version]
- Szyperski, C.; Bosch, J.; Weck, W. Component-oriented programming. In Proceedings of the European Conference on Object-Oriented Programming, Oslo, Norway, 1 January 2002; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Lin, C.T.; Prasad, M.; Chang, J.Y. Designing mamdani type fuzzy rule using a collaborative FCM scheme. In Proceedings of the 2013 International Conference on Fuzzy Theory and Its Applications (iFUZZY), Taipei, Taiwan, 6 December 2013. [Google Scholar]
- Tyagi, K.; Sharma, A. A rule-based approach for estimating the reliability of component-based systems. Adv. Eng. Softw. 2012, 54, 24–29. [Google Scholar] [CrossRef]
- Christenson, D.A.; Huang, S.T.; Lamperez, A.J. Statistical quality control applied to code inspections. IEEE J. Sel. Areas Commun. 1990, 8, 196–200. [Google Scholar] [CrossRef]
- So, S.S.; Cha, S.D.; Kwon, Y.R. Empirical evaluation of a fuzzy logic-based software quality prediction model. Fuzzy Sets Syst. 2002, 127, 199–208. [Google Scholar] [CrossRef]
- Seliya, N.; Khoshgoftaar, T.M. Software quality analysis of unlabeled program modules with semisupervised clustering. IEEE Trans. Syst. Man Cybern.-Part A Syst. Hum. 2007, 37, 201–211. [Google Scholar] [CrossRef]
- Littlewood, B.; Verrall, J.L. A Bayesian reliability growth model for computer software. J. R. Stat. Soc. Ser. C Appl. Stat. 1973, 22, 332–346. [Google Scholar] [CrossRef]
- Cheung, R.C. A user-oriented software reliability model. IEEE Trans. Softw. Eng. 1980, 2, 118–125. [Google Scholar] [CrossRef]
- Krishnamurthy, S.; Mathur, A.P. On the estimation of reliability of a software system using reliabilities of its components. In Proceedings of the Eighth International Symposium on Software Reliability Engineering, Albuquerque, NM, USA, 2–5 November 1997; pp. 146–155. [Google Scholar]
- Reussner, R.H.; Schmidt, H.W.; Poernomo, I.H. Reliability prediction for component-based software architectures. J. Syst. Softw. 2003, 66, 241–252. [Google Scholar] [CrossRef]
- Yacoub, S.; Cukic, B.; Ammar, H.H. A scenario-based reliability analysis approach for component-based software. IEEE Trans. Reliab. 2004, 53, 465–480. [Google Scholar] [CrossRef]
- Dong, W.; Ning, H.; Ming, Y. Reliability analysis of component-based software based on relationships of components. In Proceedings of the 2008 IEEE International Conference on Web Services, Beijing, China, 7–11 July 2008; pp. 814–815. [Google Scholar]
- Zhang, F.; Zhou, X.; Chen, J.; Dong, Y. A novel model for component-based software reliability analysis. In Proceedings of the 2008 11th IEEE High Assurance Systems Engineering Symposium, Nanjing, China, 3–5 December 2008; pp. 303–309. [Google Scholar]
- Fiondella, L.; Rajasekaran, S.; Gokhale, S.S. Efficient software reliability analysis with correlated component failures. IEEE Trans. Reliab. 2013, 62, 244–255. [Google Scholar] [CrossRef]
- Ali, A.; Jawawi, D.N.; Isa, M.A. Modeling and calculation of scenarios reliability in component-based software systems. In Proceedings of the 2014 8th Malaysian Software Engineering Conference (MySEC), Langkawi, Malaysia, 23–24 September 2014; pp. 160–165. [Google Scholar]
- Crnkovic, G.T.H.I.; Stafford, H.W.S.J.A.; Wallnau, C.S.K. Component-based software engineering. J. Syst. Softw. 2005, 74, 1–3. [Google Scholar] [CrossRef]
- Vale, T.; Crnkovic, I.; De Almeida, E.S.; Neto, P.A.D.M.S.; Cavalcanti, Y.C.; de Lemos Meira, S.R. Twenty-eight years of component-based software engineering. J. Syst. Softw. 2016, 111, 128–148. [Google Scholar] [CrossRef]
- Asikainen, T.; Männistö, T. Undulate: A framework for data-driven software engineering enabling soft computing. Inf. Softw. Technol. 2022, 152, 107039. [Google Scholar] [CrossRef]
- Memon, I.; Hasan, M.K.; Shaikh, R.A.; Nebhen, J.; Bakar, K.A.A.; Hossain, E.; Tunio, M.H. Energy-Efficient Fuzzy Management System for Internet of Things Connected Vehicular Ad Hoc Networks. Electronics 2021, 10, 1068. [Google Scholar] [CrossRef]
- Hazari, M.R.; Jahan, E.; Mannan, M.A.; Das, N. Transient Stability Enhancement of a Grid-Connected Large-Scale PV System Using Fuzzy Logic Controller. Electronics 2021, 10, 2437. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy logic= computing with words. IEEE Trans. Fuzzy Syst. 1996, 4, 103–111. [Google Scholar] [CrossRef] [Green Version]
- Mamdani, E.H.; Assilian, S. An experiment in linguistic synthesis with a fuzzy logic controller. Int. J. Man-Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Surendra, H.J.; Deka, P.C.; Rajakumara, H.N. Application of Mamdani model-based fuzzy inference system in water consumption estimation using time series. Soft. Comput. 2022, 26, 11839–11847. [Google Scholar] [CrossRef]
- Golosovskiy, M.S.; Bogomolov, A.V.; Balandov, M.E. Optimized Fuzzy Inference for Sugeno-Type Systems. Autom. Doc. Math. Linguist. 2022, 56, 237–244. [Google Scholar] [CrossRef]
- Batra, S.; Parashar, H.J.; Sachdeva, S.; Mehndiratta, P. Applying data mining techniques to standardized electronic health records for decision support. In Proceedings of the 2013 Sixth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2013; pp. 510–515. [Google Scholar]
- Gao, Y.; Wang, Z.; Xie, J.; Pan, J. A new robust fuzzy c-means clustering method based on adaptive elastic distance. Knowl. Based Syst. 2022, 237, 107769. [Google Scholar] [CrossRef]
- Kaushal, M.; Lohani, Q.M. Generalized intuitionistic fuzzy c-means clustering algorithm using an adaptive intuitionistic fuzzification technique. Granul. Comput. 2022, 7, 183–195. [Google Scholar] [CrossRef]
- Gradišnik, M.; Beranič, T.; Karakatič, S. Impact of Historical Software Metric Changes in Predicting Future Maintainability Trends in Open-Source Software Development. Appl. Sci. 2020, 10, 4624. [Google Scholar] [CrossRef]
- Idri, A.; Zakrani, A.; Abran, A. Functional equivalence between radial basis function neural networks and fuzzy analogy in software cost estimation. In Proceedings of the 2008 3rd International Conference on Information and Communication Technologies: From Theory to Applications, Damascus, Syria, 7 April 2008. [Google Scholar]
- Knight, J.C.; Leveson, N.G. An experimental evaluation of the assumption of independence in multiversion programming. IEEE Trans. Softw. Eng. 1986, 1, 96–109. [Google Scholar] [CrossRef]
- So, S.; Lim, Y.; Cha, S.D.; Kwon, Y.R. An empirical study on software error detection: Voting, instrumentation and fagan inspection. In Proceedings of the 1995 Asia Pacific Software Engineering Conference, Brisbane, QLD, Australia, 6–9 December 1995. [Google Scholar]
- So, S.S.; Cha, S.D.; Shimeall, T.J.; Kwon, Y.R. An empirical evaluation of six methods to detect faults in software. Softw. Test. Verif. Reliab. 2002, 12, 155–171. [Google Scholar] [CrossRef]
- Kaloop, M.R.; Bardhan, A.; Kardani, N.; Samui, P.; Hu, J.W.; Ramzy, A. Novel application of adaptive swarm intelligence techniques coupled with adaptive network-based fuzzy inference system in predicting photovoltaic power. Renew. Sustain. Energy Rev. 2021, 148, 111315. [Google Scholar] [CrossRef]
- Zhu, Z.; Jin, D.; Wu, Z.; Xu, W.; Yu, Y.; Guo, X.; Wang, X. Assessment of surface roughness in milling of beech using a response surface methodology and an adaptive network-based fuzzy inference system. Machines 2022, 10, 567. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Basis Type | Operational Scope | Mechanism | Validation | Advantage | Disadvantage |
|---|---|---|---|---|---|---|
| [15] | Prediction/Black-box | Legacy Software Systems | Statistics and probability distribution | Real-time experimental validation | Explains failure phenomena in different environments | Programmer’s quality and difficulty is tougher to analyze |
| [16] | State-based Architectural/White-box | COTS, Component-based systems | Probability theory, matrix, mathematics | Validated by Illustrative Examples | The operational quality of a system can be predicted. | Real-time implementation is missing |
| [17] | Path Based Architectural Model, White-box | COTS, Component-based systems | Mathematical derivations, degree of independence, algorithms | Experimental validation | Considers component dependency, sensitivity, operational profile, interface, scalability and sets a basis for future works | Determining the value of degree of independence (DOI) is not clear. |
| [18] | State-based Architectural/White-box | SOA, Component-based system, COTS | State transition, probability, statistics, mathematical approach | Real-time validation (e-commerce) both empirically and experimentally | It indicates those program modules which are rare in use during execution time and are more critical one. | For reliability prediction, it needs partial statistical usage profiles. |
| [19] | Path-based Architectural/White-box | COTS, Component-based systems | CDG, Probability theory | Two case study and empirical validation | They are suited for component and system reliability estimation | Algorithm is not considered as overall reliability |
| [20] | Path-based Architecture/White-box | Component-based complex system, SOA | Mathematical equations | Not validated | Scope of Markov model is extended for complicated relationships of components | Assumes reliability and transition probability are known. |
| [21] | Path-based Architectural/ White-box | COTS, Component-based systems | Enhanced composition of algorithm, CDG, probability | Case study and Scenarios | Considering transition matrix and component to get the best result | No real time validation |
| [11] | Architectural model/White-box | COTS, Component-based system | Fuzzy inference system. | Empirical and Experimental validation | Software simulation is simple and accurate. | Model does not consider the probability of component failure |
| [22] | State-based architectural model/ White-box | COTS, Component-based system | DTMC, mathematical calculation, probability distribution theory. | Validated through two experimental studies. | Also analyzes the sensitivity of components, application reliability, and correlation parameters. | Analytical expression for application reliability is not computed |
| [23] | Path-based Architecture/White-box | Component-based complex system, COTS | Universal Live Sequence Charts (uLSC), Mathematical Formulas | Validated on automated railcar system | It accounts computational costs and scalability issue | Synchronization of execution among scenarios is not considered |
| [24] | No specific listing | Component based Software Engineering | Automated Component based Software Engineering | Predicted properties and extra functional characteristics | Automate the process of component deployment | Structural changes have a large impact |
| [25] | Black Box | Component based Software Engineering (CBSE) Approach, Commercial off the Shelf (COTS) | Research questionnaire in the field of CBSE | Surveys and Reports | Increase Productivity, save cost and improve quality | Detailed analysis on specific topic |
| [26] | No specific listing | Data Driven Software Engineering | Introducing framework for data engineering | Software Processes | Continuous software Engineering Process | Validity dependent on context and responsibility |
| Component Name | Inspection Rate (Nor.) | Defect Density (Nor.) | Actual Reliability | Predicted Experts’ M-FIS | Predicted Self-Learning M-FIS | Predicted K-Means |
|---|---|---|---|---|---|---|
| Conflict 6-2 | 0.1136 | 0.5839 | 0.8208 | 0.9000 | 0.7071 | 0.6548 |
| Conflict5-1 | 0.0966 | 0.3226 | 0.8640 | 0.7492 | 0.7846 | 0.8564 |
| LIP12-1 | 0.1672 | 0.1556 | 0.8099 | 0.9000 | 0.8296 | 0.7465 |
| LIP3-2 | 0.6369 | 0.0010 | 0.8692 | 0.7500 | 0.8061 | 0.9547 |
| Conflict8-5 | 0.2036 | 0.0930 | 0.9152 | 0.9000 | 0.8456 | 0.7549 |
| LIP12-2 | 0.2430 | 0.0010 | 0.9250 | 0.8000 | 0.8580 | 0.9854 |
| Conflict2-1 | 0.3294 | 0.2749 | 0.8304 | 0.7500 | 0.7945 | 0.8947 |
| LIP3-3 | 0.2261 | 0.2036 | 0.9468 | 0.9000 | 0.8176 | 0.7458 |
| Conflict8-2 | 0.1442 | 0.4984 | 0.8448 | 0.9000 | 0.7411 | 0.6487 |
| LIP12-4 | 0.3861 | 0.0010 | 0.9206 | 0.7500 | 0.7907 | 0.9571 |
| LIP3-1 | 0.2013 | 0.1018 | 0.9087 | 0.9000 | 0.8439 | 0.7654 |
| Model | MAE | RMSE |
|---|---|---|
| Predicted Experts’ based M-FIS reliability | 0.0823 | 0.0946 |
| Predicted Self-learning M-FIS reliability | 0.0796 | 0.0867 |
| Predicted K-Means | 0.1077 | 0.1254 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goswami, P.; Noorwali, A.; Kumar, A.; Khan, M.Z.; Srivastava, P.; Batra, S. Appraising Early Reliability of a Software Component Using Fuzzy Inference. Electronics 2023, 12, 1137. https://doi.org/10.3390/electronics12051137
Goswami P, Noorwali A, Kumar A, Khan MZ, Srivastava P, Batra S. Appraising Early Reliability of a Software Component Using Fuzzy Inference. Electronics. 2023; 12(5):1137. https://doi.org/10.3390/electronics12051137
Chicago/Turabian StyleGoswami, Puneet, Abdulfattah Noorwali, Arvind Kumar, Mohammad Zubair Khan, Prakash Srivastava, and Shivani Batra. 2023. "Appraising Early Reliability of a Software Component Using Fuzzy Inference" Electronics 12, no. 5: 1137. https://doi.org/10.3390/electronics12051137