
Research on Named Entity Recognition for Spoken Language Understanding Using Adversarial Transfer Learning


Abstract
:1. Introduction
- (1)
- For the first time, we applied transfer learning to the task of spoken language understanding. Aiming at the shortage of labeled training data for the task of NER in spoken language understanding, the source domain and target domain data are trained jointly, and shared features of different domains are extracted by sharing feature extractor. Building on the reference [9], we extend to two sharing modes: full sharing mode and private sharing mode.
- (2)
- Referring to the work [10], a NER method using adversarial transfer learning is proposed to solve the problem that unique features of the source domain in shared features have a negative impact on the target task. Therefore, an adversarial discriminator is added to the shared feature extractor. Two kinds of adversarial discriminators, OAD and GRAD, are investigated. We combine the two sharing modes to form a total of four combinations. The experimental results show that the method of adversarial transfer learning based on GRAD and private sharing mode can effectively improve the system performance of NER tasks in spoken language understanding.
2. Related Work
3. Method
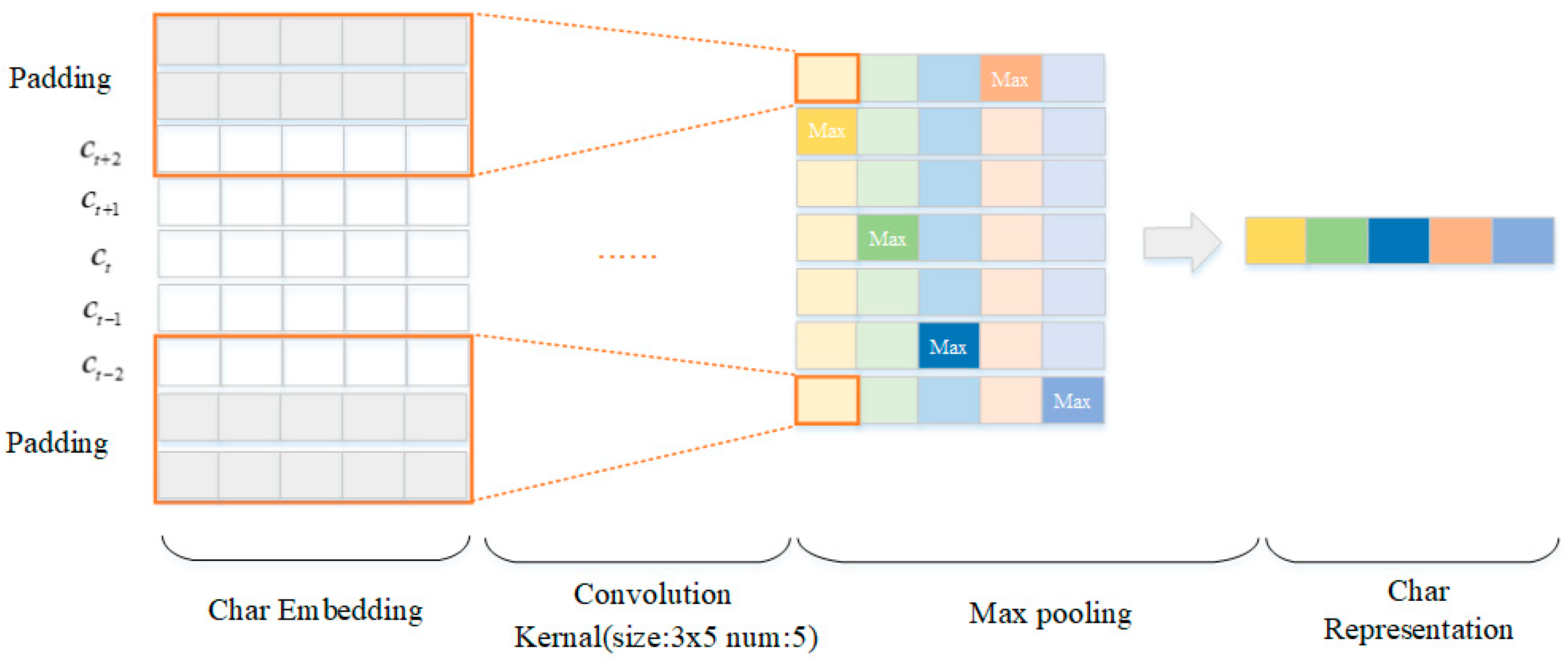
3.1. Embedding Layer
3.2. Word-Level Feature Extractor
3.3. Self-Attention
3.4. Adversarial Discriminator
3.4.1. Ordinary Adversarial Discriminator
3.4.2. Generalized Resource Adversarial Discriminator
3.5. Label Decoder
3.6. Training
4. Experiments
4.1. Data Set
4.2. Parameter Settings
4.3. Evaluation Metrics
4.4. Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tur, G.; De Mori, R. Spoken Language Understanding: Systems for Extracting Semantic Information from Speech; John Wiley & Sons Publishing: New York, NY, USA, 2011. [Google Scholar]
- Satoshi, S.; Nobata, C. Definition, Dictionaries and Tagger for Extended Named Entity Hierarchy. In Proceedings of the 4th International Conference on Language Resources and Evaluation, Lisbon, Portugal, 26–28 May 2004. [Google Scholar]
- Finkel, J.R.; Manning, C.D. Nested named entity recognition. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009. [Google Scholar]
- Singh, S.; Hillard, D.; Leggetter, C. Minimally-supervised extraction of entities from text advertisements. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Chiu, J.P.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar]
- Cao, P.; Chen, Y.; Liu, K.; Zhao, J.; Liu, S. Adversarial transfer learning for Chinese named entity recognition with self-attention mechanism. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Zhou, J.T.; Zhang, H.; Jin, D.; Zhu, H.; Fang, M.; Goh, R.S.M.; Kwok, K. Dual adversarial neural transfer for low-resource named entity recognition. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Eddy, S.R. Hidden markov models. Curr. Opin. Struct. Biol. 1996, 6, 361–365. [Google Scholar] [CrossRef]
- Berger, A.; Della Pietra, S.A.; Della Pietra, V.J. A maximum entropy approach to natural language processing. Comput. Linguist. 1996, 22, 39–71. [Google Scholar]
- Chen, P.H.; Lin, C.J.; Schölkopf, B. A tutorial on v-support vector machines. Appl. Stoch. Model. Bus. Ind. 2005, 21, 111–136. [Google Scholar] [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning, Williams College, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Habibi, M.; Weber, L.; Neves, M.; Wiegandt, D.L.; Leser, U. Deep learning with word embeddings improves biomedical named entity recognition. Bioinformatics 2017, 33, i37–i48. [Google Scholar]
- Wang, Q.; Zeng, L. Chinese symptom component recognition via bidirectional LSTM-CRF. In Proceedings of the 2018 Tenth International Conference on Advanced Computational Intelligence (ICACI), Xiamen, China, 29–31 March 2018. [Google Scholar]
- Zeng, Q.; Xiong, W.; Du, J.; Nie, B.; Guo, R. Electronic medical record named entity recognition combined with self-attention BILSTM-CRF. Comput. Appl. Softw. 2021, 38, 159–162. [Google Scholar]
- Ni, J.; Dinu, G.; Florian, R. Weakly supervised cross-lingual named entity recognition via effective annotation and representation projection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Ando, R.K.; Zhang, T. A framework for learning predictive structures from multiple tasks and unlabeled data. J. Mach. Learn. Res. 2005, 6, 1817–1853. [Google Scholar]
- Tommasi, T.; Caputo, B. The more you know, the less you learn: From knowledge transfer to one-shot learning of object categories. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009. [Google Scholar]
- Wang, Z.; Qu, Y.; Chen, L.; Shen, J.; Zhang, W.; Zhang, S.; Gao, Y.; Gu, G.; Chen, K.; Yu, Y. Label-aware double transfer learning for cross specialty medical named entity recognition. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Yang, Z.; Salakhutdinov, R.; Cohen, W.W. Transfer learning for sequence tagging with hierarchical recurrent networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Assoc. Comput. Mach. 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Lin, B.Y.; Xu, F.; Luo, Z. Multi-channel bilstm-crf model for emerging named entity recognition in social media. In Proceedings of the 3rd Workshop on Noisy User-Generated Text, Copenhagen, Denmark, 7 September 2017. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Xu, L.; Tong, Y.; Dong, Q.; Liao, Y.; Yu, C.; Tian, Y.; Liu, W.; Li, L.; Liu, C.; Zhang, X. CLUENER2020: Fine-grained Name Entity Recognition for Chinese. arXiv 2020, arXiv:2001.04351. [Google Scholar]
- Hou, L.; Li, Y.; Lin, M.; Li, C. Joint Recognition of Intent and Semantic Slot Filling Combining Multiple Constraints. J. Front. Comput. Sci. Technol. 2020, 14, 1545–1553. [Google Scholar]
- Hou, Y.; Che, W.; Lai, Y.; Zhou, Z.; Liu, Y.; Liu, H.; Liu, T. Few-shot slot tagging with collapsed dependency transfer and label-enhanced task-adaptive projection network. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sentences | Entities | Classes | Entity Types |
|---|---|---|---|---|
| CLUENER | 12,091 | 25,244 | 10 | Address, Book, Company, Game, Name, Government, Movie, Scene, Organization, Position |
| Flight Information | 5871 | 16,575 | 19 | Departure, Destination, Time, Airport Name, Fare Range, Airline, Flight Number, Seat Classes, etc. |
| Domain | Sentences | Entities | Classes | Entity Types |
|---|---|---|---|---|
| Cookbook | 438 | 450 | 4 | dishName, utensil, ingredient, keyword |
| Music | 189 | 195 | 3 | song, artist, category |
| News | 197 | 254 | 8 | datetime_time, datetime_date, category, country, province, city, area, keyword |
| Train | 171 | 366 | 8 | startLoc_province, startLoc_city, startLoc_area, endLoc_province, endLoc_city, endLoc_area, startDate_date, category |
| Source Domain | Model | SMP2020 | Cookbook | Music | News | Train |
|---|---|---|---|---|---|---|
| baseline | 86.75 | 83.87 | 74.29 | 88.46 | 87.50 | |
| CLUENER | MTL-P | 87.58 | 83.52 | 78.95 | 88.89 | 87.94 |
| MTL-F | 88.18 | 84.44 | 75.68 | 87.72 | 87.32 | |
| OAD-P | 87.96 | 87.64 | 81.08 | 90.57 | 89.04 | |
| OAD-F | 88.39 | 86.36 | 78.05 | 91.55 | 88.73 | |
| GRAD-P | 92.59 | 88.17 | 86.42 | 92.57 | 90.78 | |
| GRAD-F | 91.20 | 86.96 | 83.33 | 91.76 | 89.38 | |
| Flight Information | MTL-P | 88.72 | 85.39 | 73.17 | 89.29 | 88.73 |
| MTL-F | 87.76 | 84.09 | 73.68 | 90.91 | 88.59 | |
| OAD-P | 88.12 | 89.13 | 82.67 | 92.59 | 89.21 | |
| OAD-F | 88.27 | 89.89 | 82.93 | 90.20 | 89.51 | |
| GRAD-P | 92.99 | 91.40 | 87.18 | 92.86 | 90.14 | |
| GRAD-F | 90.22 | 88.89 | 84.21 | 92.31 | 92.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Li, M.; Li, Y.; Ge, F.; Qi, Y.; Lin, M. Research on Named Entity Recognition for Spoken Language Understanding Using Adversarial Transfer Learning. Electronics 2023, 12, 884. https://doi.org/10.3390/electronics12040884
Guo Y, Li M, Li Y, Ge F, Qi Y, Lin M. Research on Named Entity Recognition for Spoken Language Understanding Using Adversarial Transfer Learning. Electronics. 2023; 12(4):884. https://doi.org/10.3390/electronics12040884
Chicago/Turabian StyleGuo, Yao, Meng Li, Yanling Li, Fengpei Ge, Yaohui Qi, and Min Lin. 2023. "Research on Named Entity Recognition for Spoken Language Understanding Using Adversarial Transfer Learning" Electronics 12, no. 4: 884. https://doi.org/10.3390/electronics12040884