
Non-Rigid Point Cloud Matching Based on Invariant Structure for Face Deformation
Abstract
:1. Introduction
- We explore the properties of the texture space and normalize the global structure features of expressive faces based on added invariant topology, which decreases the magnitude of variations in face movements.
- We make a modification to the traditional SC feature to solve the problem of regional cross-mismatch and combine the modified SC and European distance features to improve the effectiveness of feature description.
- We built a photo dataset of real persons with face deformation. Experiments were carried out on real data with extreme expressions and a high percentage of outliers, demonstrating the capabilities of our method.
2. Method
2.1. Model Preprocessing
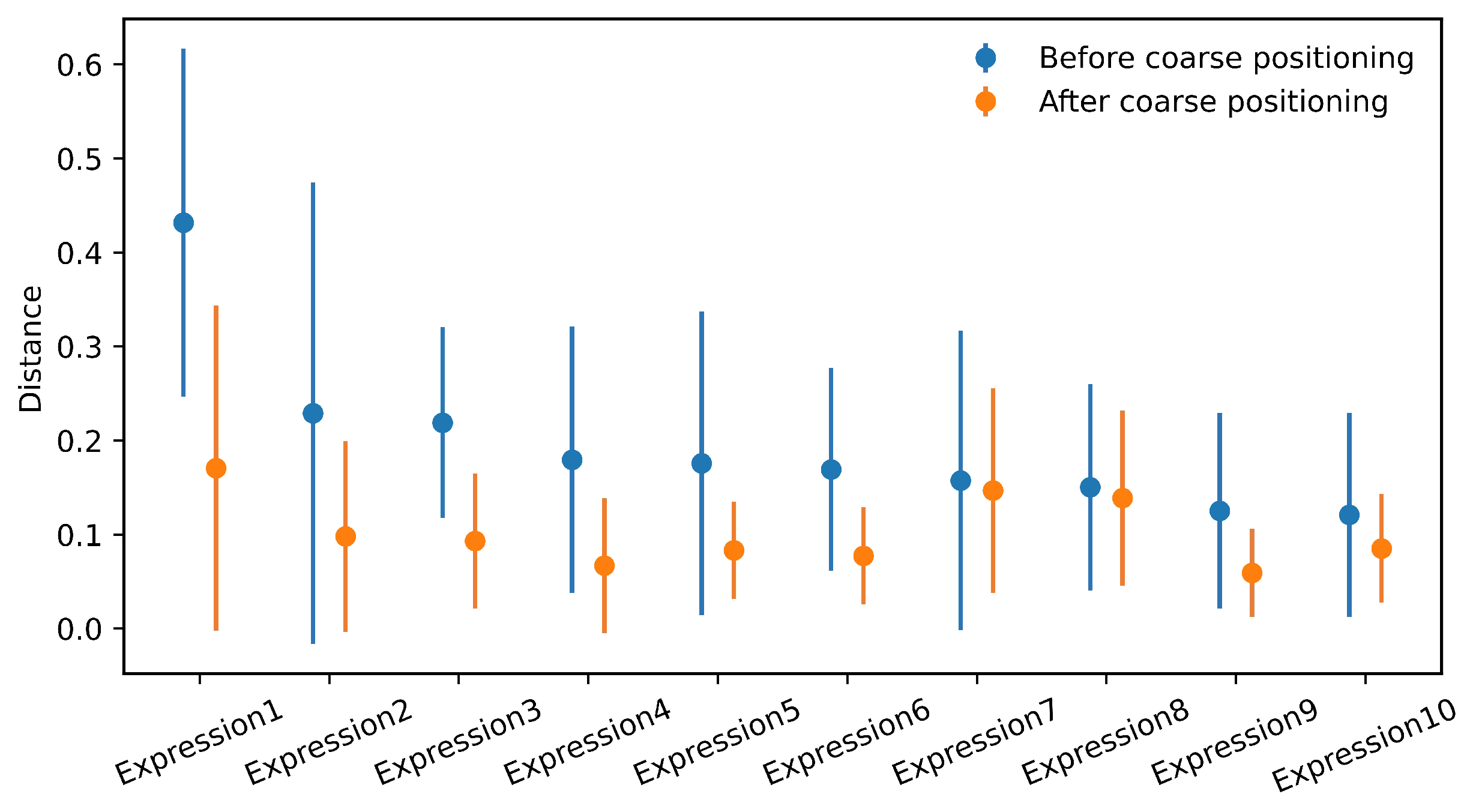
2.2. Coarse Positioning
2.3. Fine Matching
2.3.1. Shape Context Descriptor
2.3.2. Additional Correction
3. Experiments
3.1. Experimental Conditions
3.1.1. Datasets
3.1.2. Implementation Details
3.2. Experimental Results
3.2.1. Ablation Study
3.2.2. Comparison with Other Algorithms
3.2.3. Test of Anti-Interference
4. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fang, Z.; Cai, L.; Wang, G. MetaHuman Creator The starting point of the metaverse. In Proceedings of the 2021 International Symposium on Computer Technology and Information Science (ISCTIS), Guilin, China, 4–6 June 2021; pp. 154–157. [Google Scholar]
- Zhang, X.; Yang, D.; Yow, C.H.; Huang, L.; Wu, X.; Huang, X.; Guo, J.; Zhou, S.; Cai, Y. Metaverse for Cultural Heritages. Electronics 2022, 11, 3730. [Google Scholar] [CrossRef]
- Feng, Y.; Feng, H.; Black, M.J.; Bolkart, T. Learning an animatable detailed 3D face model from in-the-wild images. ACM Trans. Graph. 2021, 40, 1–13. [Google Scholar] [CrossRef]
- Riviere, J.; Gotardo, P.; Bradley, D.; Ghosh, A.; Beeler, T. Single-shot high-quality facial geometry and skin appearance capture. ACM Trans. Graph. 2020, 39, 1–12. [Google Scholar] [CrossRef]
- Fang, Z.; Cai, L.; Wang, G. Self-supervised monocular 3d face reconstruction by occlusion-aware multi-view geometry consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Berlin, Germany; pp. 53–70. [Google Scholar]
- Deng, Y.; Yang, J.; Xu, S.; Chen, D.; Jia, Y.; Tong, X. Accurate 3D Face Reconstruction With Weakly-Supervised Learning: From Single Image to Image Set. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Nagano, K.; Seo, J.; Xing, J.; Wei, L.; Li, Z.; Saito, S.; Agarwal, A.; Fursund, J.; Li, H.; Roberts, R.; et al. paGAN: Real-time avatars using dynamic textures. ACM Trans. Graph. 2018, 37, 1–12. [Google Scholar] [CrossRef]
- Yoon, J.S.; Shiratori, T.; Yu, S.I.; Park, H.S. Self-supervised adaptation of high-fidelity face models for monocular performance tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA; pp. 4601–4609. [Google Scholar]
- Zollhöfer, M.; Thies, J.; Garrido, P.; Bradley, D.; Beeler, T.; Pérez, P.; Stamminger, M.; Nießner, M.; Theobalt, C. State of the Art on Monocular 3D Face Reconstruction, Tracking, and Applications. Comput. Graph. Forum 2018, 37, 523–550. [Google Scholar] [CrossRef]
- Wu, F.; Bao, L.; Chen, Y.; Ling, Y.; Song, Y.; Li, S.; Ngan, K.N.; Liu, W. Mvf-net: Multi-view 3d face morphable model regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA; pp. 959–968. [Google Scholar]
- Gotardo, P.; Riviere, J.; Bradley, D.; Ghosh, A.; Beeler, T. Practical Dynamic Facial Appearance Modeling and Acquisition. ACM Trans. Graph. 2018, 37, 1–13. [Google Scholar] [CrossRef]
- Lombardi, S.; Simon, T.; Saragih, J.; Schwartz, G.; Lehrmann, A.; Sheikh, Y. Neural volumes: Learning dynamic renderable volumes from images. ACM Trans. Graph. 2019, 38, 1–14. [Google Scholar] [CrossRef]
- Dou, P.; Kakadiaris, I.A. Multi-view 3D face reconstruction with deep recurrent neural networks. Image Vis. Comput. 2018, 80, 80–91. [Google Scholar] [CrossRef]
- Liu, F.; Zhu, R.; Zeng, D.; Zhao, Q.; Liu, X. Disentangling features in 3D face shapes for joint face reconstruction and recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, NJ, 18–22 June 2018; IEEE: Piscataway, NJ, USA; pp. 5216–5225. [Google Scholar]
- Tewari, A.; Bernard, F.; Garrido, P.; Bharaj, G.; Elgharib, M.; Seidel, H.P.; Pérez, P.; Zollhofer, M.; Theobalt, C. Fml: Face model learning from videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA; pp. 10812–10822. [Google Scholar]
- Zhou, Y.; Deng, J.; Kotsia, I.; Zafeiriou, S. Dense 3d face decoding over 2500fps: Joint texture & shape convolutional mesh decoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA; pp. 1097–1106. [Google Scholar]
- Guo, J.; Zhu, X.; Yang, Y.; Yang, F.; Lei, Z.; Li, S.Z. Towards fast, accurate and stable 3d dense face alignment. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Berlin, Germany; pp. 152–168. [Google Scholar]
- Wood, E.; Baltrušaitis, T.; Hewitt, C.; Johnson, M.; Shen, J.; Milosavljević, N.; Wilde, D.; Garbin, S.; Sharp, T.; Stojiljković, I.; et al. 3d face reconstruction with dense landmarks. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Berlin, Germany; pp. 160–177. [Google Scholar]
- Egger, B.; Smith, W.A.; Tewari, A.; Wuhrer, S.; Zollhoefer, M.; Beeler, T.; Bernard, F.; Bolkart, T.; Kortylewski, A.; Romdhani, S.; et al. 3d morphable face models—Past, present, and future. ACM Trans. Graph. 2020, 39, 1–38. [Google Scholar] [CrossRef]
- Li, T.; Liu, S.; Bolkart, T.; Liu, J.; Li, H.; Zhao, Y. Topologically Consistent Multi-View Face Inference Using Volumetric Sampling. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA; pp. 3824–3834. [Google Scholar]
- Li, J.; Kuang, Z.; Zhao, Y.; He, M.; Bladin, K.; Li, H. Dynamic facial asset and rig generation from a single scan. ACM Trans. Graph. 2020, 39, 1–18. [Google Scholar] [CrossRef]
- Seol, Y.; Ma, W.C.; Lewis, J.P. Creating an actor-specific facial rig from performance capture. In Proceedings of the 2016 Symposium on Digital Production (DigiPro), Anaheim, CA, USA, 23 July 2016; ACM: New York, NY, USA; pp. 13–17. [Google Scholar]
- Taylor, J.; Bordeaux, L.; Cashman, T.; Corish, B.; Keskin, C.; Sharp, T.; Soto, E.; Sweeney, D.; Valentin, J.; Luff, B.; et al. Efficient and precise interactive hand tracking through joint, continuous optimization of pose and correspondences. ACM Trans. Graph. 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Chui, H.; Rangarajan, A. A new point matching algorithm for non-rigid registration. Comput. Vis. Image Underst. 2003, 89, 114–141. [Google Scholar] [CrossRef]
- Sheikhbahaee, Z.; Nakajima, R.; Erben, T.; Schneider, P.; Hildebrandt, H.; Becker, A. Photometric calibration of the COMBO-17 survey with the Softassign Procrustes Matching method. Mon. Not. R. Astron. Soc. 2017, 471, 3443–3455. [Google Scholar] [CrossRef]
- ElSayed, A.; Kongar, E.; Mahmood, A.; Sobh, T.; Boult, T. Neural Generative Models for 3D Faces with Application in 3D Texture Free Face Recognition. 2018. Available online: https://arxiv.org/pdf/1811.04358.pdf (accessed on 20 December 2022).
- Myronenko, A.; Song, X. Point set registration: Coherent point drift. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 2262–2275. [Google Scholar] [CrossRef] [PubMed]
- Yuille, A.L.; Grzywacz, N.M. A mathematical analysis of the motion coherence theory. Int. J. Comput. Vis. 1989, 3, 155–175. [Google Scholar] [CrossRef]
- Zheng, Y.; Doermann, D. Robust point matching for nonrigid shapes by preserving local neighborhood structures. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 643–649. [Google Scholar] [CrossRef]
- Jian, B.; Vemuri, B.C. Robust point set registration using gaussian mixture models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1633–1645. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Yuille, A.L. Non-rigid point set registration by preserving global and local structures. IEEE Trans. On Image Processing 2015, 25, 53–64. [Google Scholar]
- Belongie, S.; Malik, J.; Puzicha, J. Shape matching and object recognition using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef]
- Cheng, S.; Chen, X.; Qu, H. Rapid Real-Time Collision Detection for Large-Scale Complex Scene Based on Virtual Reality. In Proceedings of the 2021 International Conference on Applications and Techniques in Cyber Intelligence (ATCI), Fuyang, China, 19–21 June 2021; Abawajy, J., Xu, Z., Atiquzzaman, M., Zhang, X., Eds.; Springer: Cham, Switzerland; pp. 605–610. [Google Scholar]
- ElSayed, A.; Kongar, E.; Mahmood, A.; Sobh, T.; Boult, T. Attention Mesh: High-Fidelity Face Mesh Prediction in Real-Time. 2020. Available online: https://arxiv.org/pdf/2006.10962.pdf (accessed on 20 December 2022).
- Kartynnik, Y.; Ablavatski, A.; Grishchenko, I.; Grundmann, M. Real-Time Facial Surface Geometry from Monocular Video on Mobile GPUs. 2019. Available online: https://arxiv.org/pdf/1907.06724.pdf (accessed on 20 December 2022).
- Bazarevsky, V.; Kartynnik, Y.; Vakunov, A.; Raveendran, K.; Grundmann, M. Blazeface: Sub-Millisecond Neural Face Detection on Mobile GPUs, 2019. Available online: https://arxiv.org/pdf/1907.05047.pdf (accessed on 20 December 2022).
- Gabrovšek, B.; Novak, T.; Povh, J.; Rupnik Poklukar, D.; Žerovnik, J. Multiple Hungarian method for k-assignment problem. Mathematics 2020, 8, 2050. [Google Scholar] [CrossRef]
- Ghosh, A.; Fyffe, G.; Tunwattanapong, B.; Busch, J.; Yu, X.; Debevec, P. Multiview face capture using polarized spherical gradient illumination. In Proceedings of the 2011 SIGGRAPH Asia Conference, Hong Kong, China, 12–15 December 2011; ACM: New York, NY, USA; pp. 1–10. [Google Scholar]
- Ekman, P.E.; Friesen, W.V. Facial Action Coding System: A Technique for the Measurement of Facial Actions. Riv. Psichiatr. 1978, 47, 126–138. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy |
|---|---|
| SC | |
| SC-AC | |
| SC-UV | |
| SC-UV-AC |
| Method | Accuracy of Subject 1 | Accuracy of Subject 2 | Mean Accuracy |
|---|---|---|---|
| ICP | 84.60 | 86.76 | 85.68 |
| CPD | 92.84 | 97.24 | 95.04 |
| TPS-RPM | 95.52 | 96.12 | 95.82 |
| PR-GLS | 98.56 | 97.96 | 98.26 |
| SC+Munkres | 97.68 | 97.31 | 97.50 |
| SC-UV-AC+Munkres |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Weng, D.; Chen, J. Non-Rigid Point Cloud Matching Based on Invariant Structure for Face Deformation. Electronics 2023, 12, 828. https://doi.org/10.3390/electronics12040828
Li Y, Weng D, Chen J. Non-Rigid Point Cloud Matching Based on Invariant Structure for Face Deformation. Electronics. 2023; 12(4):828. https://doi.org/10.3390/electronics12040828
Chicago/Turabian StyleLi, Ying, Dongdong Weng, and Junyu Chen. 2023. "Non-Rigid Point Cloud Matching Based on Invariant Structure for Face Deformation" Electronics 12, no. 4: 828. https://doi.org/10.3390/electronics12040828