
Efficient Lung Cancer Image Classification and Segmentation Algorithm Based on an Improved Swin Transformer


Abstract
:1. Introduction
2. Materials and Methods
2.1. Framework Description
2.1.1. Patch Embedding
2.1.2. Patch Merging
2.1.3. Mask
2.2. Algorithm Design
2.2.1. First and Second Stage
2.2.2. Self-Attention in Non-Overlapped Windows
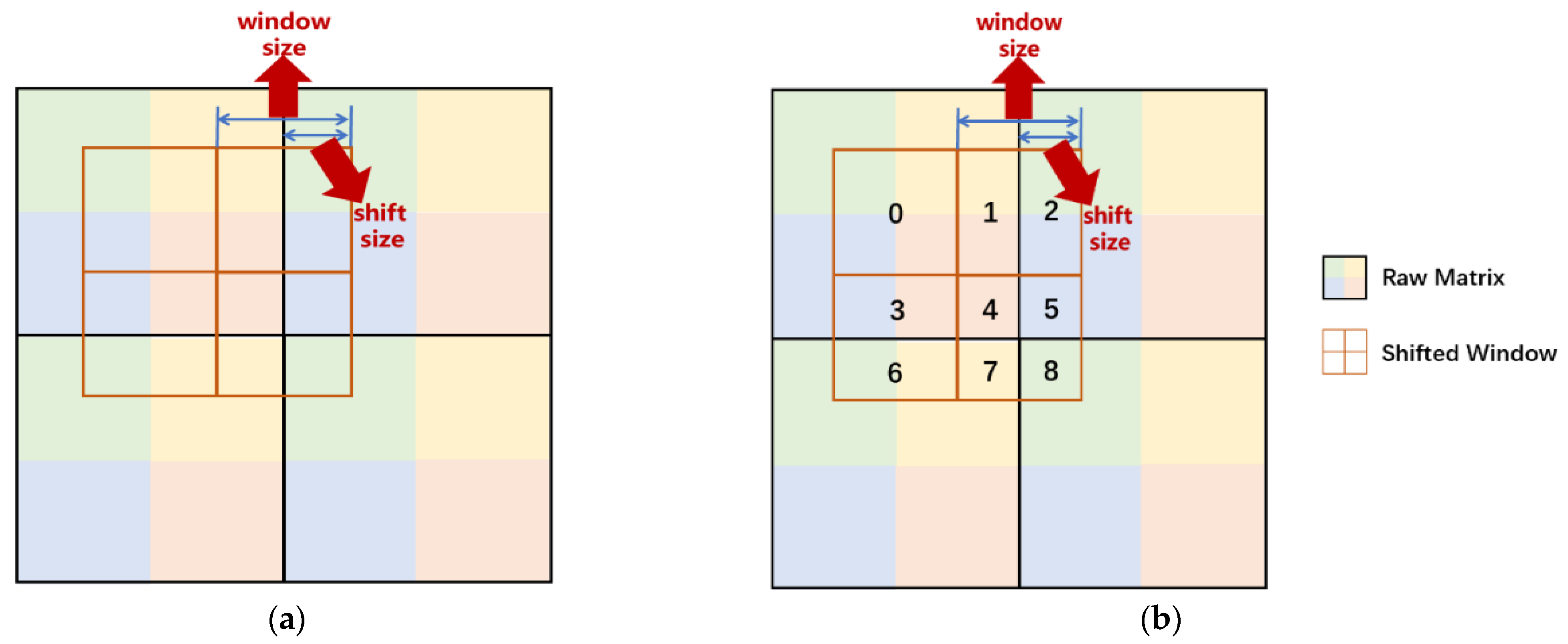
2.2.3. Shifted Window Partitioning in Successive Blocks
2.2.4. Multihead Self-Attention
2.2.5. Third Stage
2.3. Architecture Variants
- Swin-T: C = 96, layer numbers = {2, 2, 6, 2};
- Swin-S: C = 96, layer numbers = {2, 2, 18, 2};
- Swin-B: C = 128, layer numbers = {2, 2, 18, 2}.
2.4. Loss Function
3. Experiments
3.1. Datasets
3.1.1. Classification Dataset
3.1.2. Segmentation Dataset
3.2. Metric Evaluation
3.3. Experiment Result
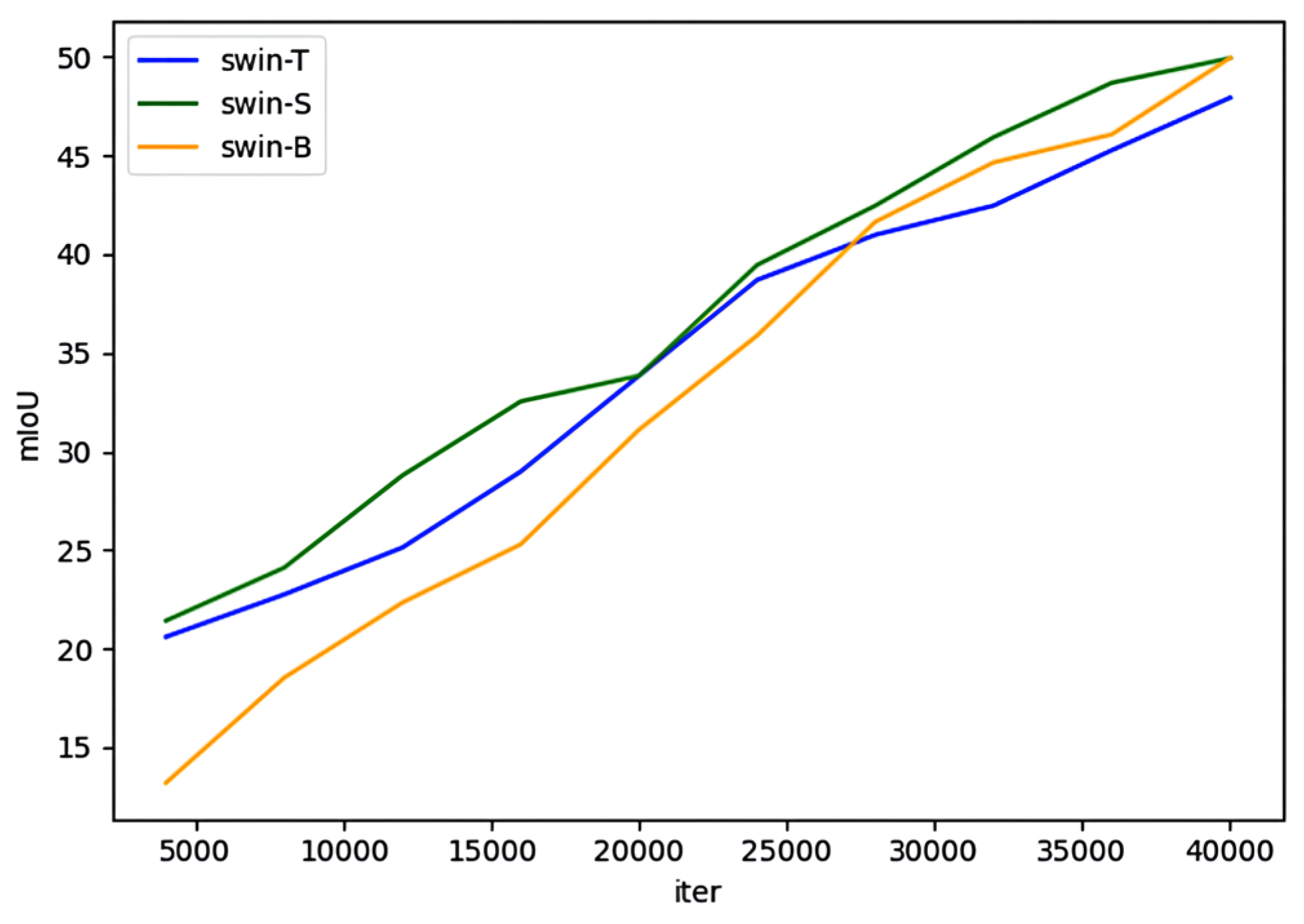
3.3.1. Classification
3.3.2. Segmentation
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hvidtfeldt, U.A.; Severi, G.; Andersen, Z.J.; Atkinson, R.; Bauwelinck, M.; Bellander, T.; Boutron-Ruault, M.-C.; Brandt, J.; Brunekreef, B.; Cesaroni, G.; et al. Long-term low-level ambient air pollution exposure and risk of lung cancer–A pooled analysis of 7 European cohorts. Environ. Int. 2021, 146, 106249. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Zhu, M.; Ji, M.; Fan, J.; Xie, J.; Wei, X.; Jiang, X.; Xu, J.; Chen, L.; Yin, R.; et al. Air pollution, genetic factors, and the risk of lung cancer: A prospective study in the UK Biobank. Am. J. Respir. Crit. Care Med. 2021, 204, 817–825. [Google Scholar] [CrossRef] [PubMed]
- Prabhakar, B.; Shende, P.; Augustine, S. Current trends and emerging diagnostic techniques for lung cancer. Biomed. Pharmacother. 2018, 106, 1586–1599. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Huang, S.; Chen, S.; Li, B.; Geng, T.; Li, A.; Jiang, W.; Wen, W.; Bi, J.; Liu, H.; et al. A length adaptive algorithm-hardware co-design of transformer on fpga through sparse attention and dynamic pipelining. In Proceedings of the 59th ACM/IEEE Design Automation Conference, San Antonio, Texas, USA, 16–19 May 2022; pp. 1135–1140. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Wei, X.; Saha, D. KNEW: Key Generation using NEural Networks from Wireless Channels. In Proceedings of the 2022 ACM Workshop on Wireless Security and Machine Learning, San Francisco, CA, USA, 10–14 July 2022; pp. 45–50. [Google Scholar]
- Kuan, K.; Ravaut, M.; Manek, G.; Chen, H.; Lin, J.; Nazir, B.; Chen, C.; Howe, T.C.; Zeng, Z.; Chandrasekhar, V. Deep learning for lung cancer detection: Tackling the kaggle data science bowl 2017 challenge. arXiv 2017, arXiv:1705.09435. [Google Scholar]
- Zou, Z.; Careem, M.; Dutta, A.; Thawdar, N. Joint Spatio-Temporal Precoding for Practical Non-Stationary Wireless Channels. IEEE Trans. Commun. 2023. [Google Scholar] [CrossRef]
- Zou, Z.; Careem, M.; Dutta, A.; Thawdar, N. Unified characterization and precoding for non-stationary channels. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 5140–5146. [Google Scholar]
- Shen, G.; Zeng, W.; Han, C.; Liu, P.; Zhang, Y. Determination of the average maintenance time of CNC machine tools based on type II failure correlation. Eksploatacja i Niezawodność 2017, 19. [Google Scholar] [CrossRef]
- Moradi, P.; Jamzad, M. Detecting lung cancer lesions in CT images using 3D convolutional neural networks. In Proceedings of the 2019 4th International Conference on Pattern Recognition and Image Analysis (IPRIA), Tehran, Iran, 6–7 March 2019; pp. 114–118. [Google Scholar]
- Shen, W.; Zhou, M.; Yang, F.; Yang, C.; Tian, J. Multi-scale convolutional neural networks for lung nodule classification. In International Conference on Information Processing in Medical Imaging; Springer: Cham, Switzerland, 2015; pp. 588–599. [Google Scholar]
- Xie, Y.; Xia, Y.; Zhang, J.; Song, Y.; Feng, D.; Fulham, M.; Cai, W. Knowledge-based collaborative deep learning for benign-malignant lung nodule classification on chest CT. IEEE Trans. Med. Imaging 2018, 38, 991–1004. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Gurevin, D.; Huang, S.; Geng, T.; Jiang, W.; Khan, O.; Ding, C. Towards Sparsification of Graph Neural Networks 2022 IEEE 40th International Conference on Computer Design (ICCD). In Proceedings of the 2022 IEEE 40th International Conference on Computer Design (ICCD), Olympic Valley, CA, USA, 23–26 October 2022; pp. 272–279. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Du, X.; Tang, S.; Lu, Z.; Wet, J.; Gai, K.; Hung, P.C.K. A Novel Data Placement Strategy for Data-Sharing Scientific Workflows in Heterogeneous Edge-Cloud Computing Environments. In Proceedings of the 2020 IEEE International Conference on Web Services (ICWS), Beijing, China, 19–23 October 2020; pp. 498–507. [Google Scholar]
- Fu, J.; Liu, J.; Wang, Y.; Li, Y.; Bao, Y.; Tang, J.; Lu, H. Adaptive context network for scene parsing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6748–6757. [Google Scholar]
- Zhou, J.; Xiong, W.; Tian, Q.; Qi, Y.; Liu, J.; Leow, W.K.; Han, T.; Venkatesh, S.K.; Wang, S. Semi-automatic segmentation of 3D liver tumors from CT scans using voxel classification and propagational learning. MICCAI Workshop 2008, 41, 43. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, M.; Gevaert, O.; Tang, Z.; Dong, D.; Liu, Z.; Jie, T. A multi-view deep convolutional neural networks for lung nodule segmentation. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Republic of Korea, 11–15 July 2017; pp. 1752–1755. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Zhang, Y.; Mu, L.; Shen, G.; Yu, Y.; Han, C. Fault diagnosis strategy of CNC machine tools based on cascading failure. J. Intell. Manuf. 2019, 30, 2193–2202. [Google Scholar] [CrossRef]
- Ning, X.; Tian, W.; He, F.; Bai, X.; Sun, L.; Li, W. Hyper-sausage coverage function neuron model and learning algorithm for image classification. Pattern Recognit. 2023, 136, 109216. [Google Scholar] [CrossRef]
- Cai, W.; Liu, D.; Ning, X.; Wang, C.; Xie, G. Voxel-based three-view hybrid parallel network for 3D object classification. Displays 2021, 69, 102076. [Google Scholar] [CrossRef]
- Chen, Z.; Silvestri, F.; Tolomei, G.; Wang, J.; Zhu, H.; Ahn, H. Explain the Explainer: Interpreting Model-Agnostic Counterfactual Explanations of a Deep Reinforcement Learning Agent. IEEE Trans. Artif. Intell. 2022. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, L.; Li, W.; Zhang, J.; Cai, W.; Cheng, C.; Ning, X. A joint bayesian framework based on partial least squares discriminant analysis for finger vein recognition. IEEE Sens. J. 2021, 22, 785–794. [Google Scholar] [CrossRef]
- Armato, S.G., III; McLennan, G.; Bidaut, L.; McNitt-Gray, M.F.; Meyer, C.R.; Reeves, A.P.; Zhao, B.; Aberle, D.R.; Henschke, C.I.; Hoffman, E.A.; et al. The lung image database consortium (LIDC) and image database resource initiative (IDRI): A completed reference database of lung nodules on CT scans. Med. Phys. 2011, 38, 915–931. [Google Scholar] [CrossRef] [Green Version]
- He, F.; Bai, K.; Zong, Y.; Zhou, Y.; Jing, Y.; Wu, G.; Wang, C. Makeup transfer: A review. IET Comput. Vis. 2022. [Google Scholar] [CrossRef]
- Simpson, A.L.; Antonelli, M.; Bakas, S.; Bilello, M.; Farahani, K.; Van Ginneken, B.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.; Menze, B.; et al. A large annotated medical image dataset for the development and evaluation of segmentation algorithms. arXiv 2019, arXiv:1902.09063. [Google Scholar]
- Wang, Y.; Du, X.; Lu, Z.; Duan, Q.; Wu, J. Improved LSTM-based Time-Series Anomaly Detection in Rail Transit Operation Environments. IEEE Trans. Ind. Inform. 2022, 18, 9027–9036. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Polyak, B.T.; Juditsky, A.B. Acceleration of stochastic approximation by averaging. SIAM J. Control. Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Contributors, M. Mmsegmentation, an Open Source Semantic Segmentation Toolbox. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 23 December 2022).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Segmentation | |
|---|---|---|
| Dataset type | LUNA16 | MSD |
| Train data | 20,565 | 22,009 |
| Validate data | 2571 | 1702 |
| Test data | 7076 | 1702 |
| Space usage | 18.6 MB | 5.48 GB |
| Method | Resolution | Top-1 Acc | Top-5 Acc | Max Acc | #Params | FLOPs |
|---|---|---|---|---|---|---|
| Swin-T [23] | 2242 | 82.26 | 82.26 | 82.3 | 28 M | 4.5 G |
| Swin-S [23] | 2242 | 19.76 | 19.76 | 19.8 | 50 M | 8.7 G |
| Swin-B [23] | 2242 | 17.736 | 17.736 | 17.7 | 88 M | 15.4 G |
| Swin-B [23] | 3842 | 50.0 | 50.0 | 50.0 | 88 M | 47.1 G |
| ViT-B/16 [36] | 3842 | 68.56 | 68.56 | 68.6 | 86 M | 55.4 G |
| ViT-L/16 [36] | 3842 | 69.43 | 69.43 | 69.4 | 307 M | 190.7 G |
| Method | Resolution | Top-1 Acc | Top-5 Acc | Max Acc | #Params | FLOPs |
|---|---|---|---|---|---|---|
| Swin-B Swin-B | 2242 3842 | 82.264 82.260 | 82.264 82.260 | 82.3 82.3 | 88 M 88 M | 15.4 G 47.1 G |
| ViT-B/16 [36] | 3842 | 79.731 | 79.731 | 79.7 | 86 M | 55.4 G |
| ViT-L/16 [36] | 3842 | 79.890 | 79.890 | 79.9 | 307 M | 190.7 G |
| Backbone | Method | #Parmas | FLOPs | mIoU | mAcc | aAcc |
|---|---|---|---|---|---|---|
| Swin-T [23] | UPerNet | 60 M | 945 G | 47.93 | 95.87 | 95.87 |
| Swin-S [23] | UPerNet | 81 M | 1038 G | 49.94 | 99.87 | 99.87 |
| Swin-B [23] | UPerNet | 121 M | 1188 G | 49.95 | 99.91 | 99.91 |
| ResNet-101 | UperNet | 86 M | 1029 G | 44.93 | 92.25 | 92.25 |
| DeiT-S [15] | UPerNet | 52 M | 1099 G | 44.12 | 90.75 | 90.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, R.; Pang, Y.; Li, W. Efficient Lung Cancer Image Classification and Segmentation Algorithm Based on an Improved Swin Transformer. Electronics 2023, 12, 1024. https://doi.org/10.3390/electronics12041024
Sun R, Pang Y, Li W. Efficient Lung Cancer Image Classification and Segmentation Algorithm Based on an Improved Swin Transformer. Electronics. 2023; 12(4):1024. https://doi.org/10.3390/electronics12041024
Chicago/Turabian StyleSun, Ruina, Yuexin Pang, and Wenfa Li. 2023. "Efficient Lung Cancer Image Classification and Segmentation Algorithm Based on an Improved Swin Transformer" Electronics 12, no. 4: 1024. https://doi.org/10.3390/electronics12041024