1. Introduction
Deep neural networks (DNN) are currently performing well in computer vision, particularly in the areas of semantic segmentation [
1,
2,
3], instance segmentation [
4], target detection [
5,
6,
7], image classification [
8,
9,
10], and other fields. However, the neural network is easily affected by the adversarial sample in the field of computer vision. Adding some interference to the original sample that is difficult for human eyes to detect will make the model output incorrect classification results. Due to the existence of adversarial samples, security issues in such fields as face recognition [
11,
12], artificial intelligence [
13,
14,
15], and driverless cars [
16,
17,
18], have to be paid attention to [
19,
20]. In addition, improving the transferability of adversarial samples is to find the weaknesses of the model and thus improve the robustness of the model. In order to better find the flaws in the model, this forces us to design adversarial samples with better attack performance.
In recent years, many methods for generating adversarial samples have been proposed, such as the fast gradient symbolic method [
21], iteration-based gradient symbolic method [
22], momentum-based iteration [
23], and accelerated gradient iteration method [
24]. They both showed good attack performance in white box settings. However, it has been demonstrated that the generated adversarial samples are somewhat transferable, which also suggests that adversarial samples made on the source model may be somewhat aggressive towards other models. Because of this transferability nature, an attacker can attack a target model without needing to know any specifics about it, which poses a number of security issues in real life.
The process of improving the transferability of adversarial samples is regarded as the process of improving model generalization [
24]. However, methods to improve model generalization usually use better optimization methods or data augmentation. At present, the proposed optimization methods are usually divided into two categories. One is to optimize before each iteration. For example, Lin et al. [
24] introduces the Nesterov acceleration gradient to jump out of the local optimal solution before each iteration, so as to obtain a better solution. Wang et al. [
25] achieves the same by additional accumulation of the average gradient of the data points sampled on the gradient direction of the previous iteration in order to stabilize the update direction and remove the poor local maximum. The other is to optimize in each iteration process. For example, Dong et al. [
23] optimizes by integrating the momentum term into the iterative process. Wang et al. [
26] used the gradient variance information of the previous iteration to optimize the current gradient information, so as to achieve the updating direction of the stable gradient.
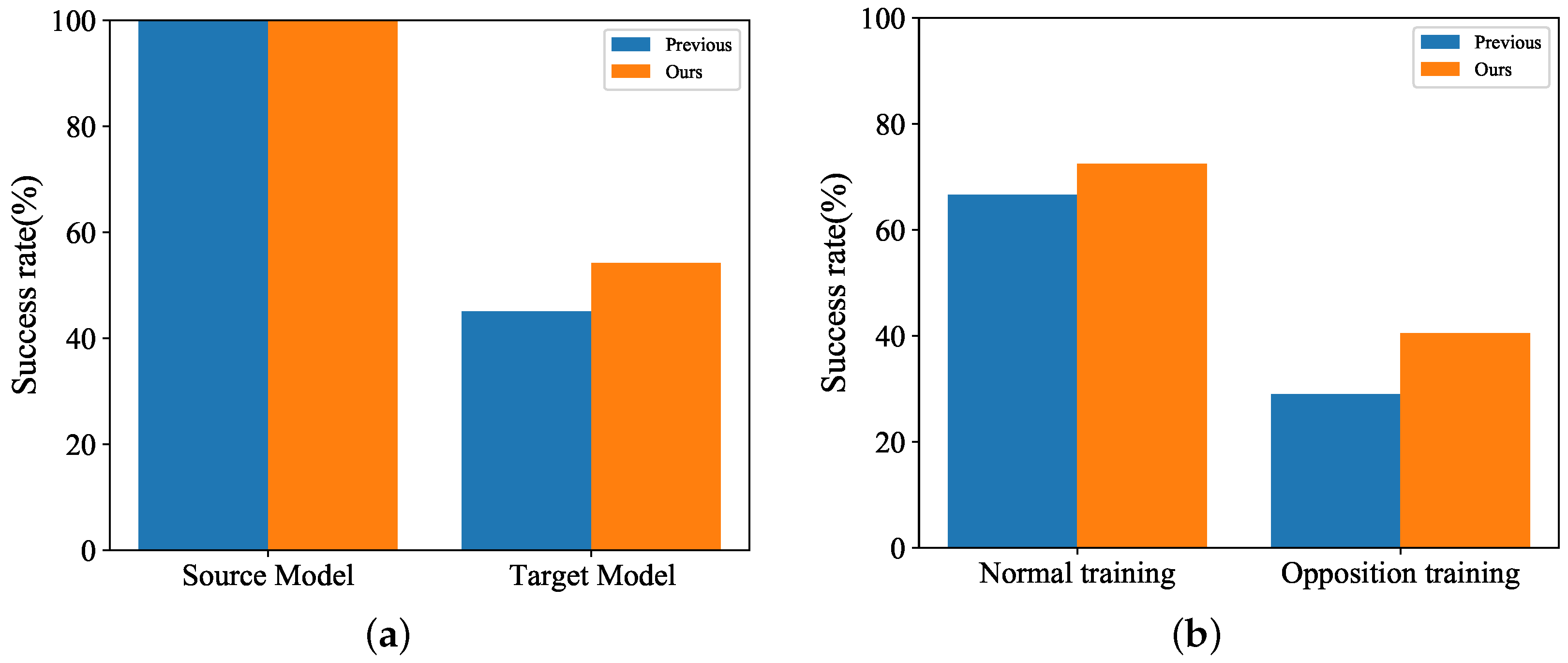
Specifically, these methods are optimized before and after iteration to improve transferability; however, there are still two deficiencies: Although the optimization method, before each iteration, can enhance the portability of opposing samples, this method is prone to overfitting the source model. The reason is that the gradient information added to the original sample each time contains the gradient information of the last iteration. On the one hand, although the gradient is optimized each time in the iterative process to enhance transferability, the adversarial samples produced by this method have weak attack performance against the adversarial training model. The reason is that the process of gradient optimization ignores many characteristic differences between the adversarial sample and the clean image learned by the adversarial training model. In particular, the uniform sampling approach in [
26] for finding the gradient variance information has high transferability for the normally trained model, but shows poor transferability for the adversarially trained model, as shown in
Figure 1. This has encouraged us to create a more effective method for discovering model flaws in order to increase transferability and address some of the issues that arise in the aforementioned two classes of approaches.
In this study, we propose a Dual-Sampling Variance Aggregation and Feature Heterogeneity Attacks (VMHI-FGSM), which reduces the overfitting of the adversarial samples to the source model by destroying the model-specific feature information, especially the black-box model with adversarial training, which has a better attack success rate.
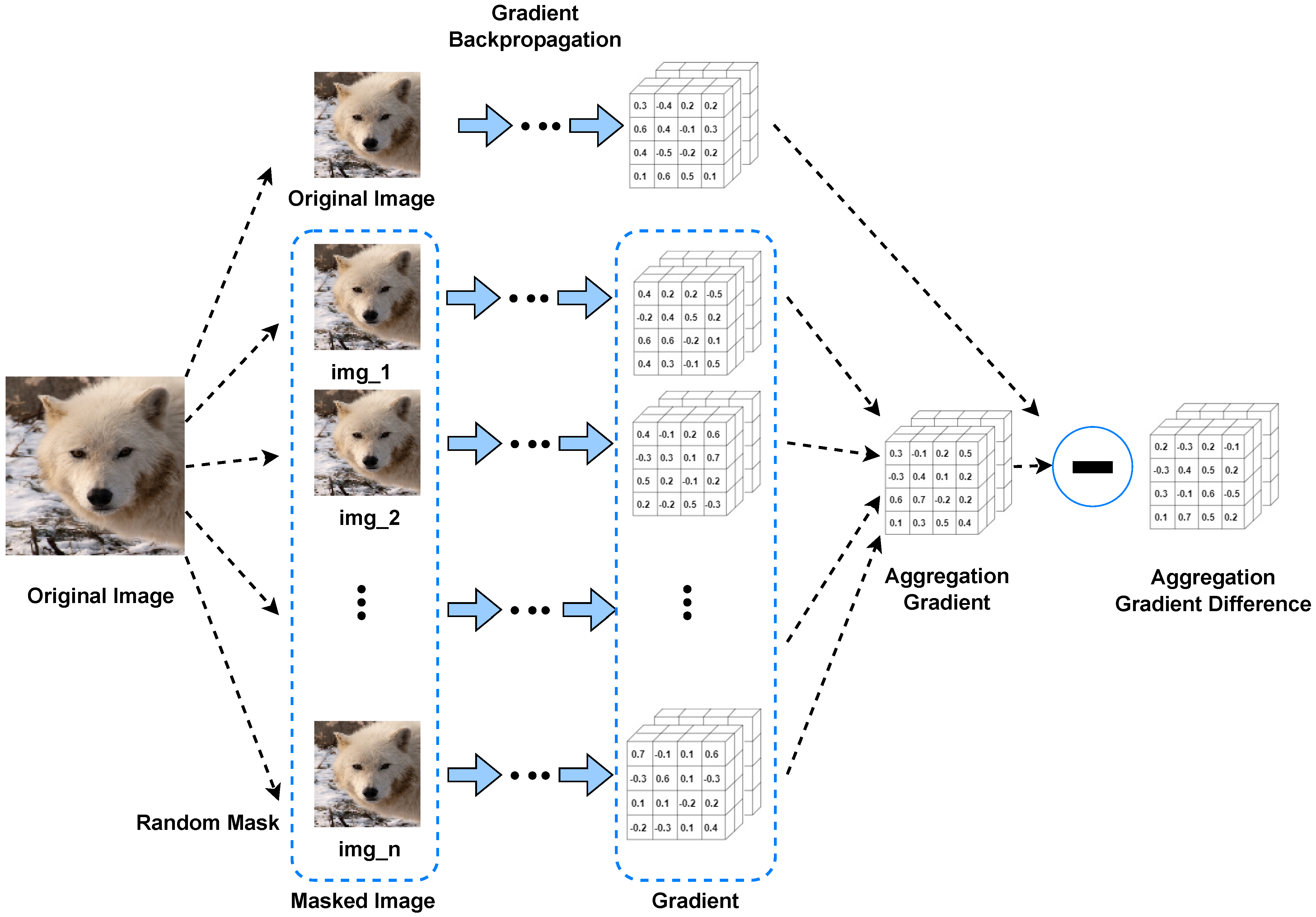
Our method is as follows: we add the aggregate gradient difference to the original image to make the original image achieve feature heterogeneity, so as to solve the overfitting of the source model by the adversarial samples. More specifically, the original image is preprocessed by randomly deleting pixels due to the specific differences between the image of the deleted pixel and the original image in the network; therefore, we add this difference to the original sample, which is usually called feature heterogeneity. Further, in order to enhance the black-box attack success rate of adversarial samples against the adversarial training model with high robustness, we aggregate the variance information obtained from uniform distribution and normal distribution sampling. More specifically, we average the gradient variance information obtained by the two sampling methods, which will effectively improve the attack success rate of adversarial samples on the more robust model. Additionally, the adversarial samples generated by our method perform better in the standard training model. Finally, our method has been improved through both the pre-iteration and iteration processes, and the experiment shows that it is superior in the context of a black box.
Our main contributions are summarized as follows:
The adversarial examples generated by the existing methods have weak generalization and low transferability, which is due to an overfitting to the source model. In order to direct the creation of more transferable adversarial examples, we introduce aggregated gradient differences.
At the same time, the adversarial samples produced by the current state-of-the-art methods show poor transferability to the adversarially trained classification model. On this basis, we introduce the dual-sampling variance aggregation method to further improve the transferability of the adversarial samples on the adversarially trained model.
Numerous tests on various classification models show that the adversarial examples produced by our suggested method have better transferability than cutting-edge adversarial attack techniques.
2. Related Work
Given a clean sample x as the input, f as the classifier, y as the true label of x, is the output after x is input to the model, which is the predicted label of x, and is the network parameter. We denote as the loss function of the classifier f, which generally defaults to the cross-entropy loss function. We define adversarial attack as finding an imperceptible adversarial example to mislead the model , and the adversarial example satisfies this constraint, where denotes the p-norm distance, and we keep p = ∞ in line with previous work.
2.1. Adversarial Attacks
Existing adversarial attacks can roughly be divided into two settings based on the threat of adversarial examples to the model: (a) In a white-box attack, the attacker has total access to all of the model’s hyperparameters, outputs, gradients, model architecture, etc. (b) In a black-box attack, the attacker only has access to the model’s output; all of the other parameters are unknown. The current white-box attack research has produced good attack performance, and while researching the white-box attack, it is discovered that the adversarial samples produced on one model exhibit good transferability between different models. The use of adversarial examples, also known as “black-box attacks”, can deceive both the source model and other models simultaneously. To address the low portability of current adversarial attack methods, several improved adversarial (gradient-based) attack methods have been put forth. Dong et al. [
23] suggested incorporating momentum into iterative gradient-based attacks from gradient optimization. To further improve the migrability, Lin et al. [
24] proposed the accelerated gradients of Nestorve from image optimization. According to Liu et al. [
24], the migrability can be increased even more by combining the aforementioned gradient-based optimization and image-based optimization techniques with integrated model attacks that target multiple models. Therefore, our method can be used in conjunction with both integrated model attacks to produce more migrable adversarial samples.
Additionally, according to some studies, applying different input transformations to the original image can enhance the transferability of adversarial examples even more. For example, DIM [
27] randomly crops and fills the input image within a certain range with a fixed probability, and inputs the processed image into the model to generate noise to enhance transferability. The translation-invariant [
28] uses a set of images to compute gradients. Dong et al. [
28] shift the image by a small amount to reduce the computation of gradients, and then they approximate the gradient by convolution the gradient of the unshifted image with the kernel matrix. Scale-invariant methods [
24] compute gradients by scaling the input image to a set of images by a factor of 1/
(
i denotes a hyperparameter) to enhance the mobility of the generated adversarial examples. Meanwhile, current work integrates input transformation-based attacks, ensemble model attacks, and gradient-based attack techniques to further enhance the transferability of adversarial examples. Our approach is a novel gradient-based assault that not only relies on gradients but also on picture features to produce more portable adversarial examples. It may be integrated with ensemble model attacks and input transformation-based approaches to increase portability.
2.2. Adversarial Defense
Finding the weaknesses in adversarial attacks is crucial for improving the robustness of deep learning models. However, one of the most effective methods to strengthen the model is adversarial training, which involves including adversarial samples in the training set. Numerous studies have demonstrated that this technique can successfully increase the model’s robustness [
29]. Ensemble adversarial training, which combines adversarial training with the ensemble model, is an alternative to applying it to a single model. The method has been shown to be resistant to adversarial samples with migration when the adversarial training is combined with the integrated model to create integrated adversarial training, which trains the adversarial samples produced by the integrated model alongside clean samples.
Based on the above methods to enhance robustness, recent studies have proposed some variants to enhance the robustness of the model. Xie et al. [
30] used random resizing and padding (R&P) at image input to mitigate the effect of adversarial perturbations. Liao et al. [
31] cleaned the images by using a trained high-level representation denoiser (HGD) on the images to enhance the recognition. Xu et al. [
21] proposed to detect adversarial samples by compressing the extracted features using bit-depth reduction (bit-Red). A JPEG-based defensive compression framework called feature distillation (FD) [
32] can successfully target adversarial samples. An end-to-end image compression model that can successfully fend off hostile samples is called ComDefend [
33]. Stochastic smoothing (RS) was used by Cohen et al. [
34] to train a trustworthy ImageNet classifier. An automatically derived supervised neural representation purifier (NRP) based model that can successfully purify adversarially perturbed images was created by Naseer et al. [
35].
4. Experiments
To validate the attack performance of our proposed V
MHI-FGSM attack method, we performed extensive experimental validation on the standard ImageNet2012 dataset [
38]. We set up the data, models, etc., needed for the experiments, and then our method was also compared with the baseline in the case of integration with several input transformations. Note that the attack success rates in this article are all the false-recognition rates of the model. Our method clearly outperforms the baseline attack success rate, as shown in
Table 1. Finally, we further investigated the discard probability P and the set number N of feature differences in gradient aggregation, as well as the hyperparameters
and N in orthogonal sampling.
4.1. Experimental Setup
Data. Similar to [
26], we randomly selected 1000 images of different categories from the ILSVRC2012 validation set, and we also make sure that all these 1000 images can be correctly classified by each model in this paper; randomly selected, these images are pre-resized to 299 × 299 × 3.
Model. Our model has four normally trained models Inception-v3(Inc-v3) [
39], Inception-v4(Inc-v4), Inception-Resnet-v2(IncRes-v2) [
40], Resnet-v2-101(Res-101) [
41], and four adversarially trained models, namely ens3-adv-Inception-v3(Inc-v3
), ens4-Inception-v3(Inc-v3
), ens-adv-Inception-ResNet-v2(IncRes-v2
), and adv-Inception-v3(Inc-v3
) [
42].
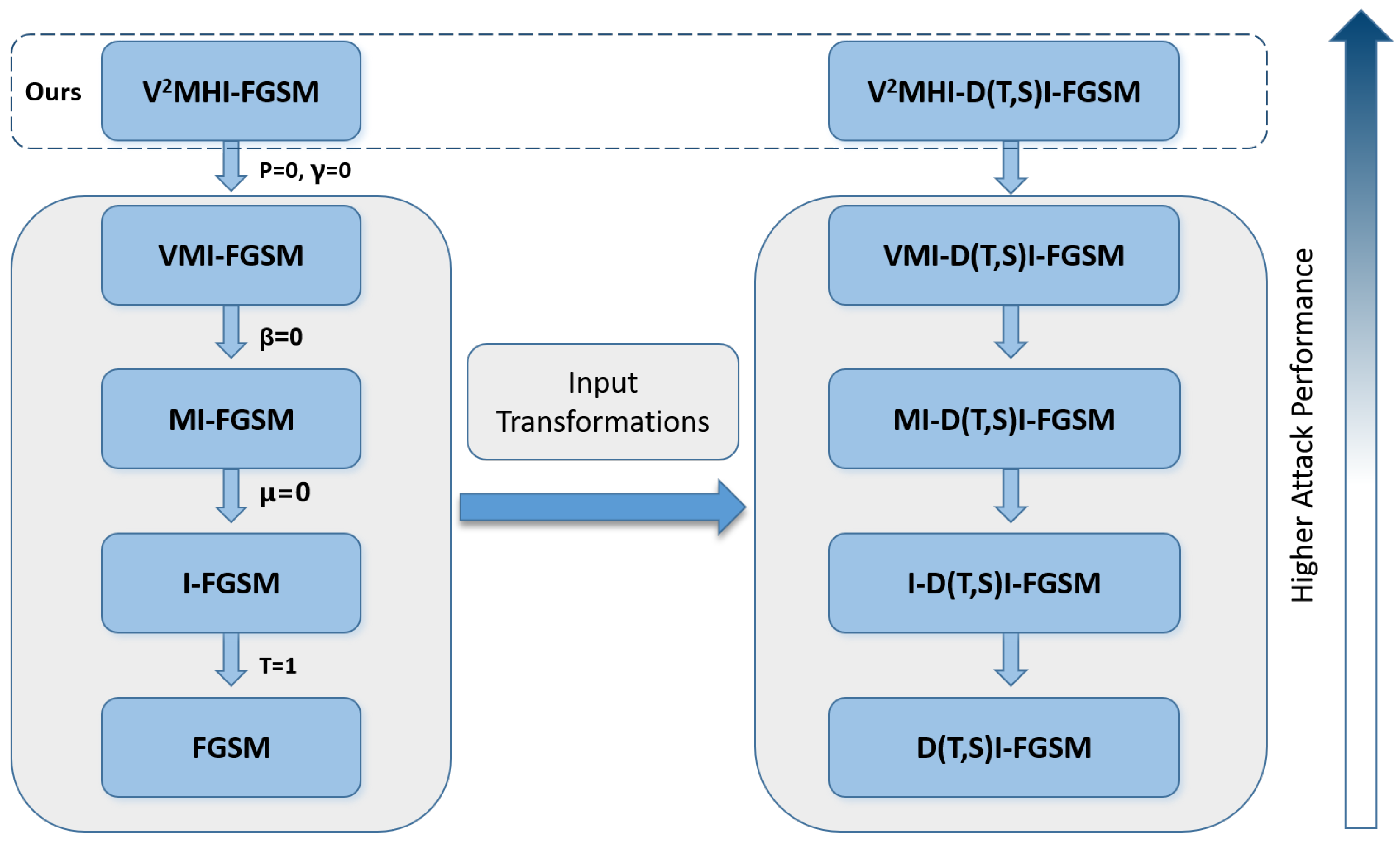
Baseline. Four gradient-based attack techniques—the MI-FGSM, NI-FGSM, VMI-FGSM, and VNI-FGSM—are compared to our approach. We also combined our method with various input transforms, namely DIM, TIM, SIM, and DTS (which represents the integration of the three of them), denoted as V
M(N)HI-DTS, V
MHI-FGSM-DIM, V
MHI-FGSM-TIM, and V
MHI-FGSM-SIM. Finally, our method was integrated into the attack method of the ensemble model [
24] to further demonstrate the effectiveness of our method.
Hyper-parameters. We are consistent with the parameter settings in [
26]: the maximum perturbation is
= 16, step size
= 1.6, the number of iterations T = 10,
= 3/2, N = 20 in uniform sampling. For the momentum term, we set the decay factor u=1 to the same as [
23,
24]. For DIM, the transformation probability is set to 0.5. For TIM, we use a Gaussian kernel with a kernel size of 7 × 7. For SIM, the number of scale replicas is 5 (i.e., i = 0, 1, 2, 3, 4). In our proposed method V
MHI-FGSM, the drop probability when attacking the normal training model is P = 0.2, the set in the aggregated gradient is N
= 10. For the parameter
in sampling the positive distribution, it is set to 3/2, the domain the number of samples within N
= 20.
4.2. Comparison with Gradient-Based Attacks
We first generate adversarial examples in the single-model setting and test its attack performance on both white-box and black-box, as shown in
Table 1. Next, we generate adversarial examples in the ensemble model setting and test their attack performance on the ensemble model, as shown in
Table 2. Finally, we randomly select five clean images and visualize the adversarial samples produced after four adversarial attacks, as shown in
Figure 5.
Attack a single model. We first produced adversarial samples using six adversarial attack methods on a single model, and the produced adversarial samples were attacked against the baseline methods in this paper; these adversarial attack methods include FGSM, I-FGSM, MI-FGSM, NI-FGSM, VMI-FGSM, and our proposed dual-sampling variance aggregation with feature heterogeneity attacks VMHI-FGSM and VMI-FGSM. All of the above attack algorithms produced adversarial samples on the Inc-v3 model, and the generated adversarial samples were tested on Inc-v3 and the remaining seven models, i.e., the misclassification rate of the adversarial samples on the corresponding models.
Our method shows the best block attack performance among the existing methods, as shown in
Table 1. Meanwhile, our method and the optimal method were compared with four different models as source models, respectively, as shown in
Table 3.
Attack ensemble model. Lin et al. [
24] showed that the adversarial samples produced by integrating logits from multiple models have better transferability. There are three types of ensemble methods for general models, namely ensemble in loss function, ensemble in prediction result, and ensemble in logits. In this paper, we fuse the logits output of the four models. In this section, our ensemble attack method averages the logit outputs of the models Inception-v3, Inception-v4, Inception-Resnet-v2, and Inception-v2-101; our approach also exhibits optimal attack performance, as shown in
Table 2.
4.3. Input Transformation Attack
To further enhance the migrability of the generated adversarial samples, we combine previous gradient-based attack techniques with three input transformations (e.g., DIM [
27], TIM [
28], and SIM [
24]). Additionally, we combine our suggested method with these three input transformations, as shown in
Table 4, and experimentally show that both our method and earlier adversarial attack methods perform at their best when doing so.
Combining these input transformations with the gradient-based attack algorithm, while integrating the combined results over multiple models, as shown in
Table 4, our approach also exhibits optimal performance.
As described in [
43], the combination of DIM, TIM, and SIM can be performed as DTS, which can further enhance the portability of the gradient-based attack algorithm. Further, we combined our method with DTS, as shown in
Table 4 and
Table 5, which shows optimal attack performance for the remaining four models of black-box attacks, especially on the adversarially trained models, indicating that our method generates better generalization of adversarial examples.
4.4. Ablation Experiment on Hyper-Parameters
To better show the performance of the double-sampling variance aggregation and feature heterogeneity attack methods, we conducted ablation experiments on variance parameters and N
in the double-sampled variance ensemble. The characteristic heterogeneous attacks in the heterogeneity attack aggregation number N
and discard probability P on the performance of the V
MHI-FGSM method, as well as the parameter settings of uniform sampling, are consistent with [
26]. We used Inc-v3 as a source model to make confrontation samples, and set the default settings
= 3/2, N
= 20, P = 0.2, and N
= 10.
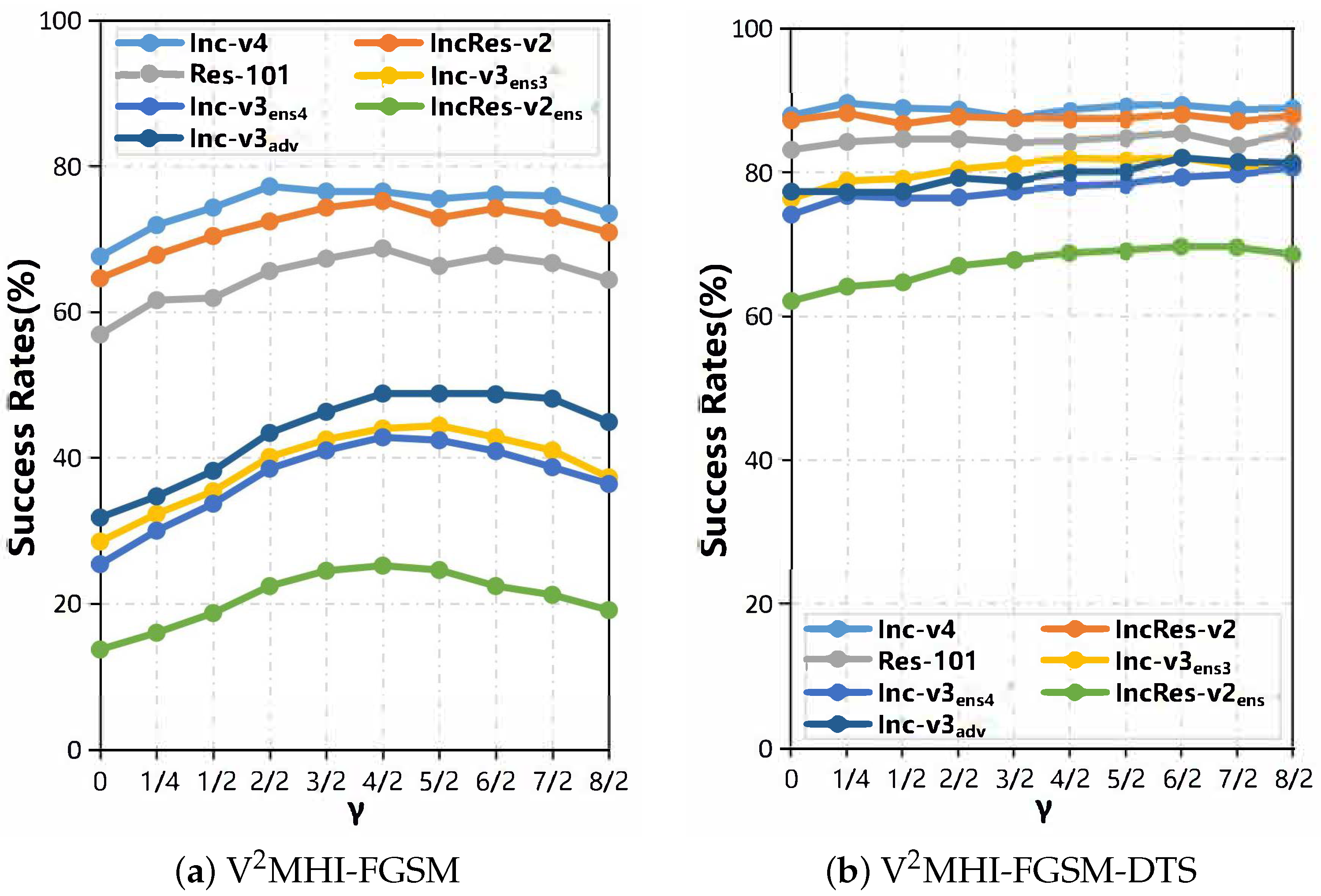
The variance parameter in normal distribution sampling. We studied the parameter
and determined the impact of the neighborhood size in the neighborhood distribution on the attack success rate of the black-box settings in
Figure 6. Fixed N
= 20. When
= 0, V
MI-FGSM degenerates to VMI-FGSM, and the lowest migration is achieved. When
= 1/5, although the samples are very small, our proposed two-sample variance aggregation attack can effectively improve the migration of adversarial samples. With the increase of
, when
= 4/2, the average success rate of the black-box attack of our method reaches its peak, especially for the transferability of the combination of training models. As a result, we choose
= 4/2.
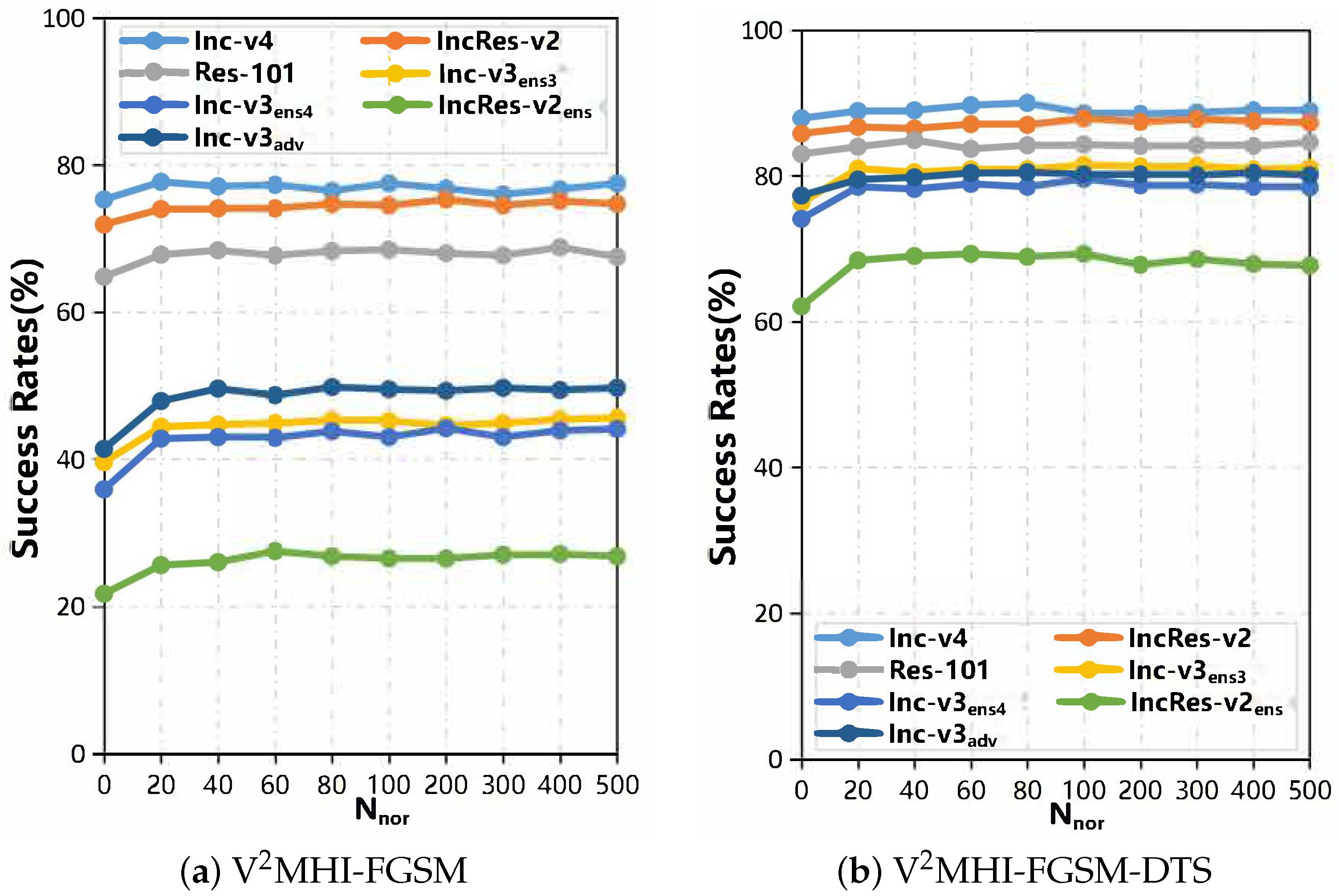
The number of samples in the field N. We analyzed the impact of the number of samples in the sample in a normal distribution (
fixed to 4/2). As shown in
Figure 7, when N
= 0, the V
MI-FGSM degenerates to VMI-FGSM, and the lowest migration is achieved. When N
= 20, the migration of the adversarial samples of our method production is significantly higher. When the N
continues to increase, the transferability can increase slowly. Because a large number of gradients need to be calculated at each iteration, the greater the value of N
, the greater the calculation overhead. In order to balance calculation overhead and migration, we set N
= 20 in the experiment.
In short, when N > 20, N has a small impact on migration, and parameter plays an important role in the impact success rate. In our experiments, the ultra-parameters and N in the dual sampling square polymerization method were set to 4/2 and 20, respectively.
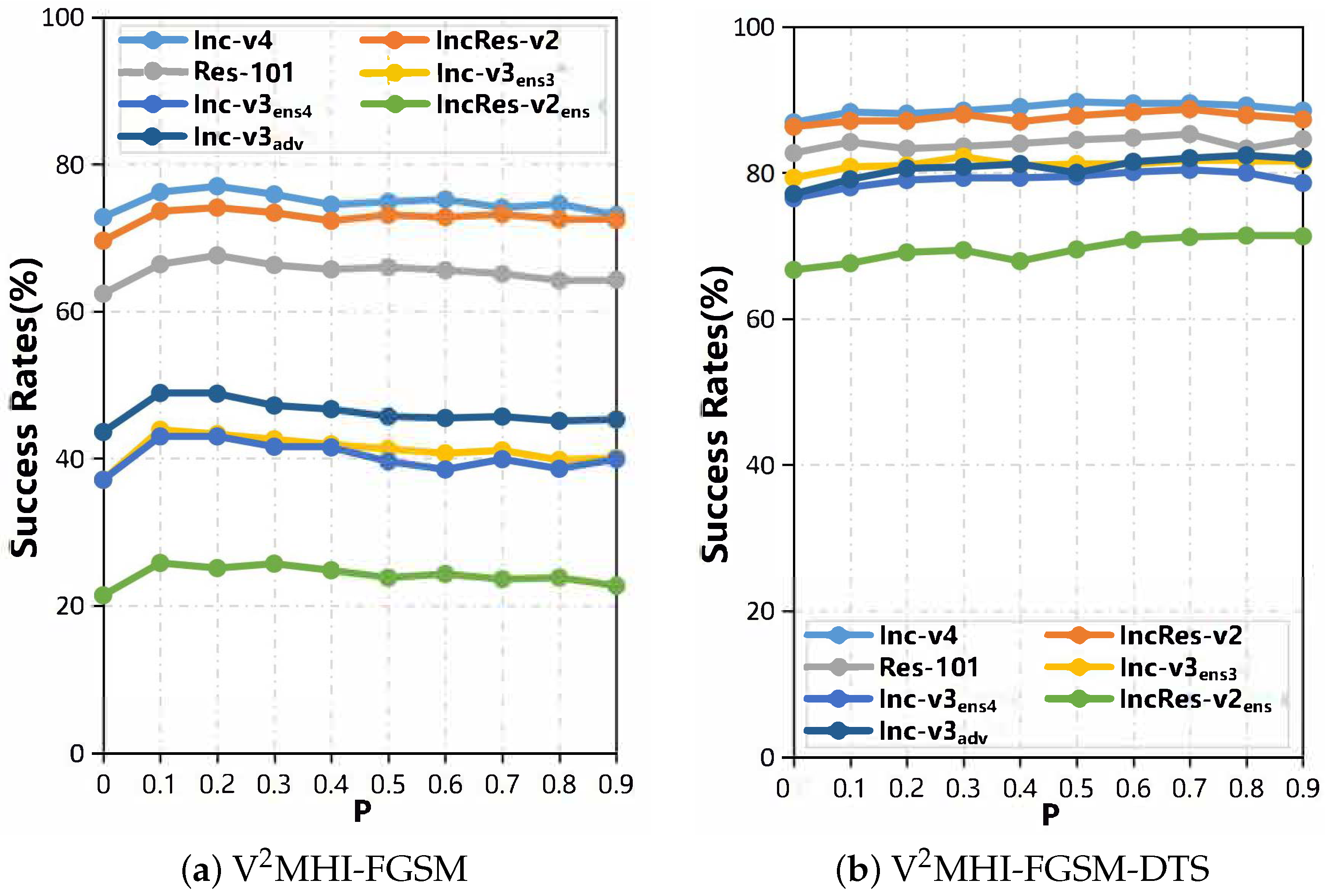
About the number of random deletions of image pixels. In
Figure 8, we studied the impact of discarding probability on the success rate of an attack under black-box settings. Among them, fixed N
= 10 increased the abandoned probability from 0 to 0.9, and the step length was 0.1. When P = 0, V
MHI-FGSM degenerates to V
MI-FGSM, and the lowest migration can be achieved. When P = 0.1, the probability of discarding is very small, but the success rate of the black-box attack has improved significantly. When P > 0.1, the success rate of the black-box attack gradually decreases with the increase of P; therefore, we discard the probability to 0.2, when the average success rate of a black-box attack is maximized.
The number of deleted pixel images N. Finally, we analyzed the effects of the aggregate N
on the attack success rate under the black-box settings (discard probability P = 0.2). As shown in
Figure 9, when N
= 0, V
MHI-FGSM degenerates to V
MI-FGSM, and the lowest migration is achieved. When N
= 1, although the number of aggregation is small, our method can significantly improve the transferability of the adversarial samples. With the increase of N
with the step length, the power of black-box attacks only increases in a small amount. Because the process of seeking gradient aggregation requires a lot of computing resources, we balance the success rate of black-box attacks and computing resources. We set up N
= 10.
In short, the discarding probability P plays a key role in migration, and when N > 10, N has a small impact. Therefore, in our experiments, we set P to 0.2, N = 10.
5. Conclusions
In this paper, we propose a dual-sample variance aggregation with a feature heterogeneity attack method to improve the transferability of the adversarial samples. Although based on the the previous method, our method has certain differences: our method starts from both pre-iteration and in-iteration perspectives, optimizing the image before the iteration and optimizing the gradient during the iteration, respectively. First, feature information with differences is added to the images, and then the gradients of the images are optimized by double-sampling variance aggregation to improve the transferability of the adversarial samples, as evaluated on the standard ImageNet dataset. Our method maintains similar success rates to the state-of-the-art methods in the white-box setting and significantly improves the transferability of the adversarial samples in the black-box setting.
Our state-of-the-art VMHI-FGSM attack method with three input transformations for integration achieves an average attack success rate of more than 83%, and our method with integrated models and three input transformations for combination achieves an average attack success rate of more than 97%, significantly improving the transferability of the adversarial samples. Additionally, on eight different models, our approach outperforms cutting-edge attack methods by an average of 8%. Our research demonstrates that the current defense models are technically flawed, necessitating an increase in the models’ robustness.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}