
Two-Dimensional Positioning with Machine Learning in Virtual and Real Environments


Abstract
:1. Introduction
2. Materials and Methods
2.1. Physical Implementation
- Maximum enclosure dimensions: H/W/W: 250/250/300 mm.
- Touch panel: 225 × 173 mm.
- Table angular adjustment accuracy: ±0.1 mm.
- Table tilting speed as axis minimum: 0.3 s/60 °C.
- At least 10 °C for angular rotation perpendicular to the X and Y axes.
- Application of low voltage system (<24 V).
- Position can be determined in every 0.05 s.
- Application of two servo motors for the angular rotation of the table.
- The connection between the ball and the table is continuous and non-slip.
- The ball is completely homogeneous and regular.
- Vibrations resulting from movement can be neglected.
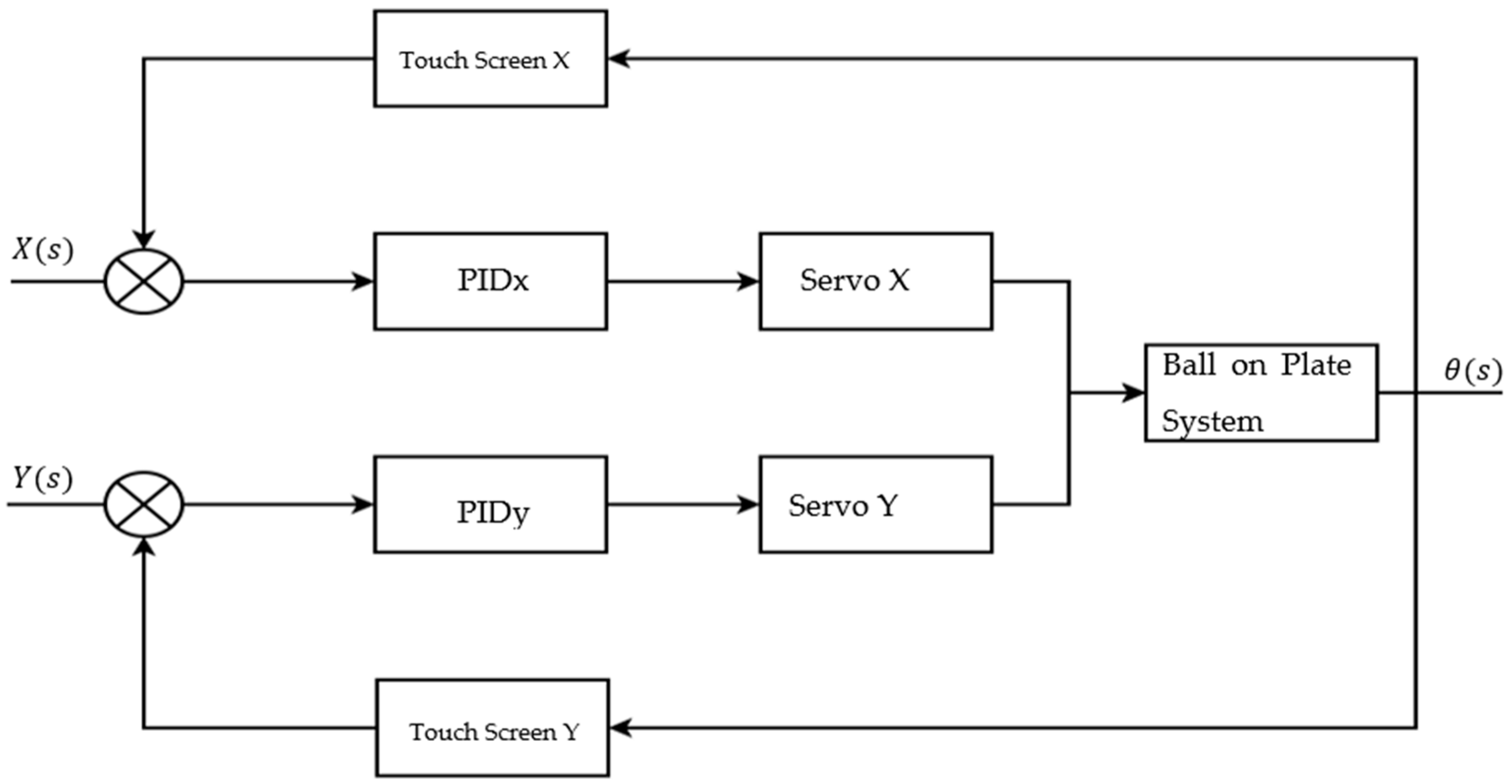
2.2. Control with Reinforcement Learning
| Algorithm 1: Deep Q-Learning |
| 1: Inputs: Episode length T, number of training iterations N, mini-batch size S, experience replay dataset size M, initial 𝜀, decay factor k, discount factor 𝛾 2: Output: Trained neural network 3: Initialize neural network and experience replay dataset D 4: Repeat 5: # Trial phase 6: Observe environment state 7: For t = 1..T do 8: With probability 𝜀 perform a random action 9: otherwise perform 10: Observe reward and next environment state 11: Store transition in D 12: Keep in D only transitions of the last M episodes 13: # Training phase 14: For N iterations do 15: Sample a random transition mini-batch from D 16: Compute loss according to Equation (10) using discount factor 𝛾 17: Perform an optimization step using Adam optimizer 18: 𝜀 ← k𝜀 19: Until the averaged reward stops increasing |
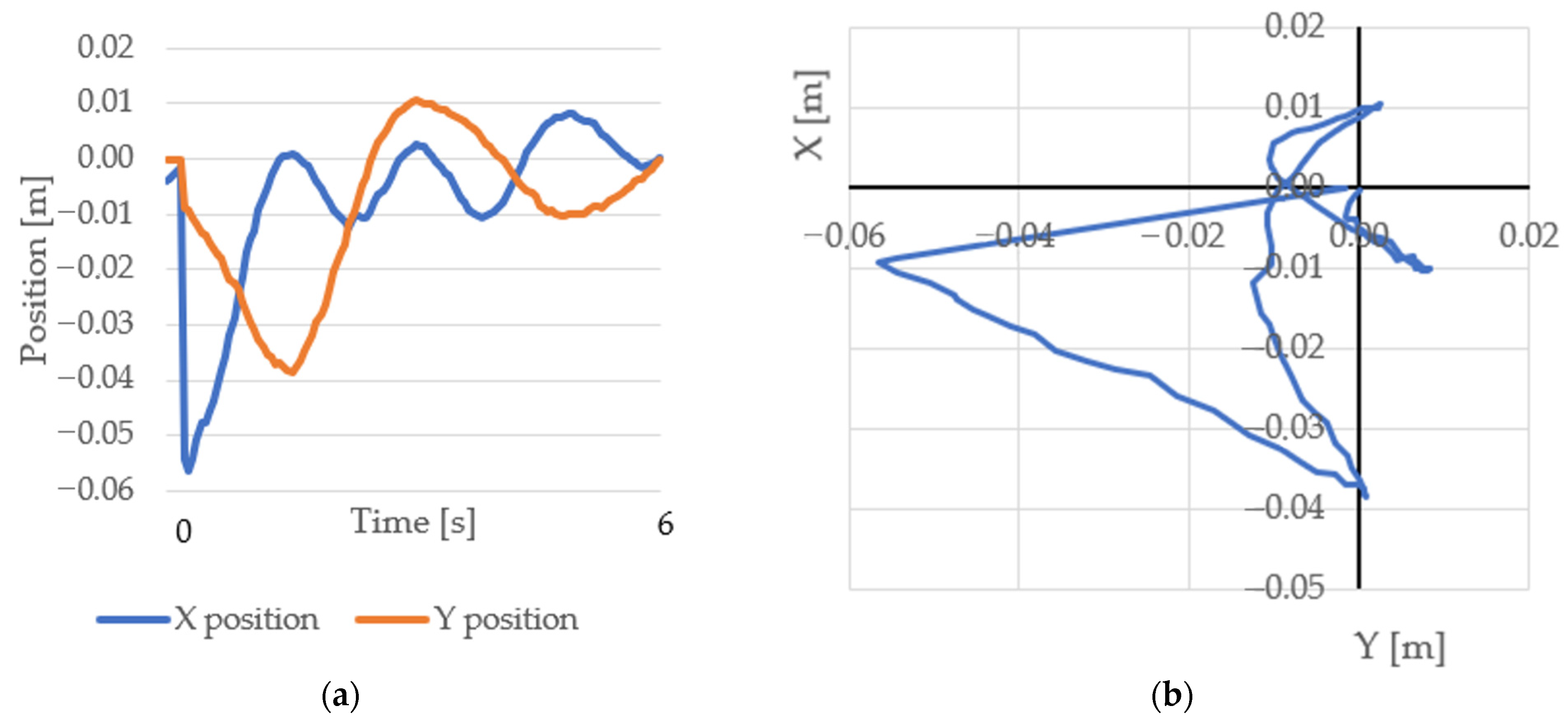
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shorya, A.; Bernard, N.; Boklud, A.; Master, D.; Ueda, K. Mechatronic design of a ball-on-plate balancing system. Mechatronics 2022, 12, 217–218. [Google Scholar]
- Zeeshan, A.; Nauman, A.; Jawad Khan, M. Design, Control and Implementation of a BaIlon Plate Balancing System. In Proceedings of the 2012 9th International Bhurban Conference on Applied Sciences & Technology (IBCAST), Islamabad, Pakistan, 9–12 January 2012; pp. 22–26. [Google Scholar] [CrossRef]
- Debono, A.; Bugeja, M. Application of Sliding Mode Control to the Ball and Plate Problem. In Proceedings of the 2015 12th International Conference on Informatics in Control, Automation and Robotics (ICINCO), Colmar, France, 21–23 July 2015; pp. 412–419. [Google Scholar]
- Bdoor, S.R.; Ismail, O.; Roman, M.R.; Hendawi, Y. Design and implementation of a vision-based control for a ball and plate system. In Proceedings of the 2016 2nd International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Chelyabinsk, Russia, 19–20 May 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Castro, R.D.; Flores, V.J.; Salton, A.T.; Pereira, L.F.A. A Comparative Analysis of Repetitive and Resonant Controllers to a Servo-Vision Ball and Plate System. IFAC Proc. Vol. 2014, 47, 1120–1125. [Google Scholar] [CrossRef] [Green Version]
- Wettstein, N. Balancing a Ball on a Plate Using Stereo Vision. Master’s Thesis, Institute for Dynamic Systems and Control Swiss Federal Institute of Technology (ETH), Zurich, Switzerland, 2013; pp. 2–10. [Google Scholar]
- Bang, H.; Lee, Y.S. Implementation of a Ball and Plate Control System Using Sliding Mode Control. IEEE Access 2018, 6, 32401–32408. [Google Scholar] [CrossRef]
- Borelli, F. Ball and Plate. Constrained Optim. Control Linear Hybrid Syst. 2003, 290, 177–183. [Google Scholar]
- Kopichev, M.M.; Puov, V.A.; Pashenko, N.A. Ball on the plate balancing control system. In IOP Conference Series: Materials Science and Engineering, Proceedings of the 2nd International Conference on Aeronautical, Aerospace and Mechanical Engineering Prague, Czech Republic, 26–28 July 2019; IOP Publishing: Bristol, UK, 2019; Volume 638, p. 012004. [Google Scholar] [CrossRef]
- Zhou, A.; Leuken, R.; Arriens, H.J. Modeling A Configurable Resistive Touch Screen System Using SystemC and SystemC-AMS. In Proceedings of the 20th Annual Workshop on Circuits, Systems and Signal Processing-ProRISC, Veldhoven, The Netherlands, 26–27 November 2009; pp. 393–398. [Google Scholar]
- Lin, C.-L.; Chang, Y.-M.; Hung, C.-C.; Tu, C.-D.; Chuang, C.-Y. Position Estimation and Smooth Tracking With a Fuzzy-Logic-Based Adaptive Strong Tracking Kalman Filter for Capacitive Touch Panels. IEEE Trans. Ind. Electron. 2015, 62, 5097–5108. [Google Scholar] [CrossRef]
- Xiyang, L.; Feng, S.; Xianmei, C.; Jinrong, L.; Yaochi, Z. Research Technologies of Projected Capacitive Touch Screen. In Proceedings of the 5th International Conference on Computer Sciences and Automation Engineering, Sanya, Hainan, China, 14–15 November 2015; pp. 63–69. [Google Scholar]
- Galvan-Colmenares, S.; Moreno-Armendáriz, M.A.; Rubio, J.J.; Ortíz-Rodriguez, F.; Yu, W.; Aguilar-Ibáñez, C.F. Dual PD Control Regulation with Nonlinear Compensation for a Ball and Plate System. Math. Probl. Eng. 2014, 2014, 894209. [Google Scholar] [CrossRef] [Green Version]
- Mochizuki, S.; Ichihara, H. I-PD controller design based on generalized KYP lemma for ball and plate system. In Proceedings of the 2013 European Control Conference (ECC), Zurich, Switzerland, 17–19 July 2013; pp. 2855–2860. [Google Scholar] [CrossRef]
- Colmenares, S.G.; Moreno-Armendáriz, M.A.; Yu, W.; Rodriguez, F.O. Modeling and nonlinear PD regulation for ball and plate system. In Proceedings of the World Automation Congress, Puerto Vallarta, Mexico, 24–28 June 2012; pp. 1–6. [Google Scholar]
- Jadlovská, A.; Jajčišin, Š. Modelling and pid control design of nonlinear educational model ball & plate. In Proceedings of the 17th International Conference on Process Control 2009, Štrbské Pleso, Slovakia, 9–12 June 2009; pp. 475–483. [Google Scholar]
- Lo, J.H.; Wang, P.K.; Huang, H.P. Reinforcement Learning and Fuzzy PID Control for Ball-on-plate Systems. In Proceedings of the International Automatic Control Conference (CACS), Kaohsiung, Taiwan, 3–6 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Hadoune, O.; Benouaret, M. Fuzzy-PID tracking control of a ball and plate system using a 6 Degrees-of-Freedom parallel robot. In Proceedings of the 19th International Multi-Conference on Systems, Signals & Devices (SSD), Sétif, Algeria, 6–10 May 2022; pp. 1906–1912. [Google Scholar] [CrossRef]
- Li, J.-F.; Xiang, F.H. RBF Network Adaptive Sliding Mode Control of Ball and Plate System Based on Reaching Law. Arab. J. Sci. Eng. 2021, 47, 9393–9404. [Google Scholar] [CrossRef]
- Kan, D.; Xing, B.; Xie, W. A minimum phase output based tracking control of ball and plate systems. Int. J. Dyn. Control. 2022, 10, 462–472. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Yang, J.; Zhang, Q.; Zhang, X. Improvement of Generalization Ability of Deep CNN via Implicit Regularization in Two-Stage Training Process. IEEE Access 2018, 6, 15844–15869. [Google Scholar] [CrossRef]
- Jin, B.; Cruz, L.; Gonçalves, N. Pseudo RGB-D Face Recognition. IEEE Sens. J. 2022, 22, 21780–21794. [Google Scholar] [CrossRef]
- Yao, T.; Qu, C.; Liu, Q.; Deng, R.; Tian, Y.; Xu, J.; Jha, A.; Bao, S.; Zhao, M.; Fogo, A.B.; et al. Compound Figure Separation of Biomedical Images with Side Loss. In Deep Generative Models, and Data Augmentation, Labelling, and Imperfections, Proceedings of the First Workshop, DGM4MICCAI 2021, and First Workshop, DALI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, 1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 13003, pp. 173–183. [Google Scholar]
- Zhao, M.; Liu, Q.; Jha, A.; Deng, R.; Yao, T.; Mahadevan-Jansen, A.; Tyska, M.J.; Millis, B.A.; Huo, Y. VoxelEmbed: 3D Instance Segmentation and Tracking with Voxel Embedding based Deep Learning. In Machine Learning in Medical Imaging, Proceedings of the 12th International Workshop, MLMI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, 27 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12966, pp. 437–446. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Dulac-Arnold, G.; Levine, N.; Mankowitz, D.J.; Li, J.; Paduraru, C.; Gowal, S.; Hester, T. Challenges of real-world reinforcement learning: Definitions, benchmarks and analysis. Mach. Learn. 2021, 110, 2419–2468. [Google Scholar] [CrossRef]
- Pan, X.; You, Y.; Wang, Z.; Lu, C. Virtual to Real Reinforcement Learning for Autonomous Driving. In Proceedings of the BMVC 2017, London, UK, 4–7 September 2017. [Google Scholar]
- Hasselt, H. Double Q-learning. Adv. Neural Inf. Process. Syst. 2011, 23, 2613–2622. [Google Scholar]
- Dewey, D. Reinforcement Learning and the Reward Engineering Principle. In Proceedings of the AAAI Spring Symposia, Palo Alto, CA, USA, 24–26 March 2014. [Google Scholar]
- Ball & Beam: Simulink Modeling. Available online: https://ctms.engin.umich.edu/CTMS/index.php?example=BallBeam§ion=SimulinkModeling (accessed on 18 November 2022).
- Nokhbeh, M.; Khashabi, D. Modelling and Control of Ball-Plate System. Final Project Report; Amirkabir University of Technology: Tehran, Iran, 2011; pp. 1–15. [Google Scholar]
- 4-Wire and 8-Wire Resistive Touch-Screen Controller Using the MSP430. Available online: http://dangerousprototypes.com/blog/2012/01/07/4-wire-and-8-wire-resistive-touch-screen-controller-using-the-msp430/ (accessed on 18 November 2022).
- Kóczi, D. Neurális Hálóval Vezérelt Kétdimenziós Pozícionáló Megtervezése és Kivitelezése. Master’s Thesis, University of Szeged, Szeged, Hungary, 2019. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| m | ball mass |
| R | ball diameter |
| d | shaft length |
| g | gravitational acceleration |
| L | table length |
| h | ball position |
| aX | Ball acceleration X component |
| aY | Ball acceleration Y component |
| α–alpha | table tilt angle-X |
| β–beta | table tilt angle-Y |
| Θ–theta | tilt angle of servo motor |
| Number | Description |
|---|---|
| 1 | Raspberry Pi 3B+ |
| 2 | Adafruit 16C PWM HAT |
| 3 | Arduino UNO Rev3 |
| 4 | DL3017 LV Digital Servo |
| 5 | 10.4″ Resistive touch panel (4 wire) |
| 6 | Power supply: 5 V DC 3.0 A |
| 7 | Power supply: 5 V DC 2.1 A |
| Name | Real Trained | Virtually Trained | Virtually Trained after Fine-Tuning | PID |
|---|---|---|---|---|
| Average Position error X [mm] | 2.1 | 45 | 3.1 | 2.1 |
| Average Position error Y [mm] | 2 | 61 | 5.7 | 2.2 |
| Average Settling time [s] | 3.4 | 5.6 | 2.8 | 1.3 |
| Average Ball speed [m/s] | 0.27 | 0.3 | 0.36 | 0.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kóczi, D.; Németh, J.; Sárosi, J. Two-Dimensional Positioning with Machine Learning in Virtual and Real Environments. Electronics 2023, 12, 671. https://doi.org/10.3390/electronics12030671
Kóczi D, Németh J, Sárosi J. Two-Dimensional Positioning with Machine Learning in Virtual and Real Environments. Electronics. 2023; 12(3):671. https://doi.org/10.3390/electronics12030671
Chicago/Turabian StyleKóczi, Dávid, József Németh, and József Sárosi. 2023. "Two-Dimensional Positioning with Machine Learning in Virtual and Real Environments" Electronics 12, no. 3: 671. https://doi.org/10.3390/electronics12030671