
Alleviating Class-Imbalance Data of Semiconductor Equipment Anomaly Detection Study


Abstract
:1. Introduction
1.1. Advanced Process Control in Semiconductor Process
1.2. Literature Review on FDC/APC
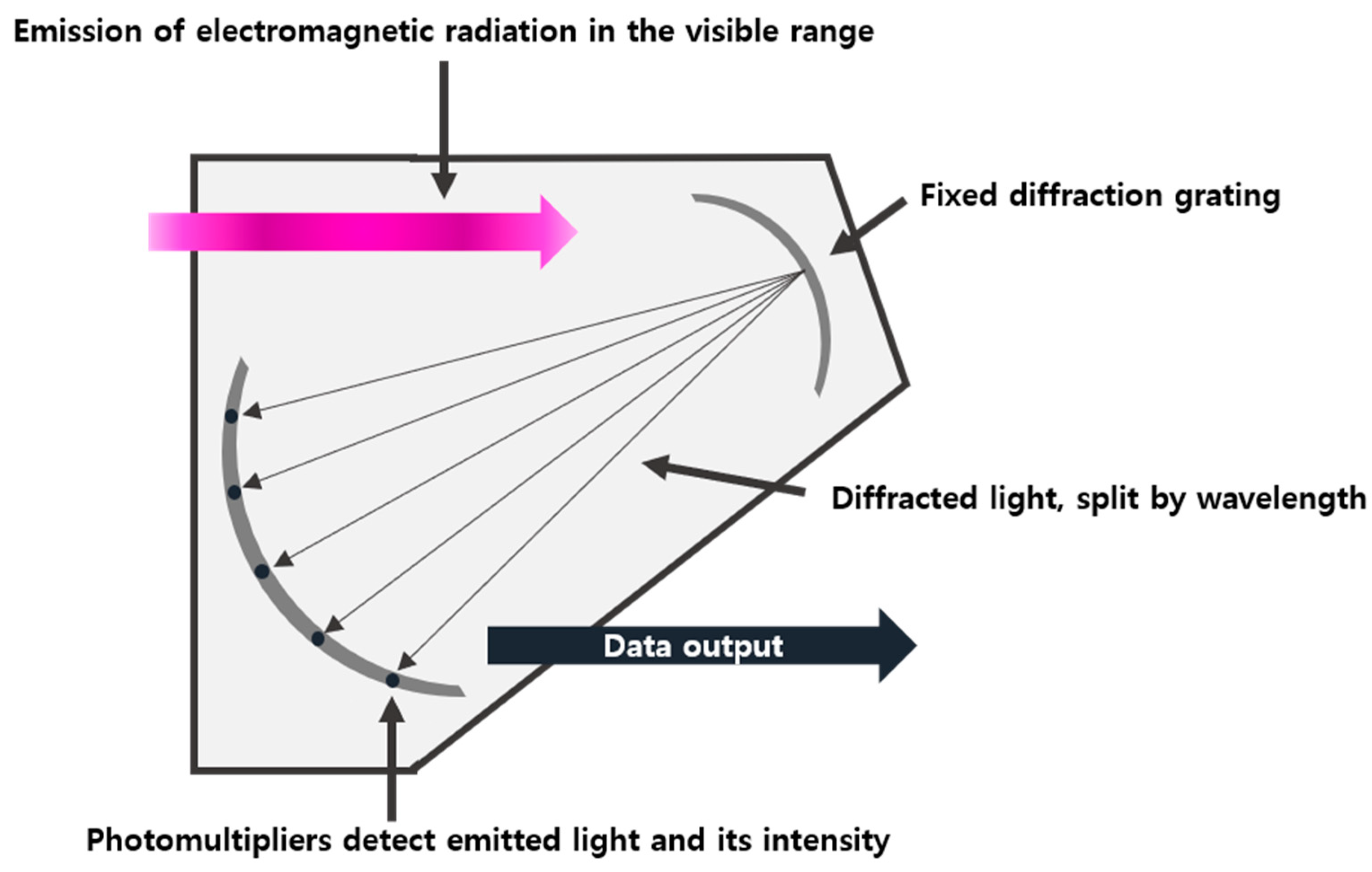
2. Experiment Apparatus
3. Data Generation Model
3.1. SMOTE-Based Model
3.2. GAN-Based Model
4. Experimental Designs
4.1. Data Acquisition
4.2. Oversampling and Undersampling with OES
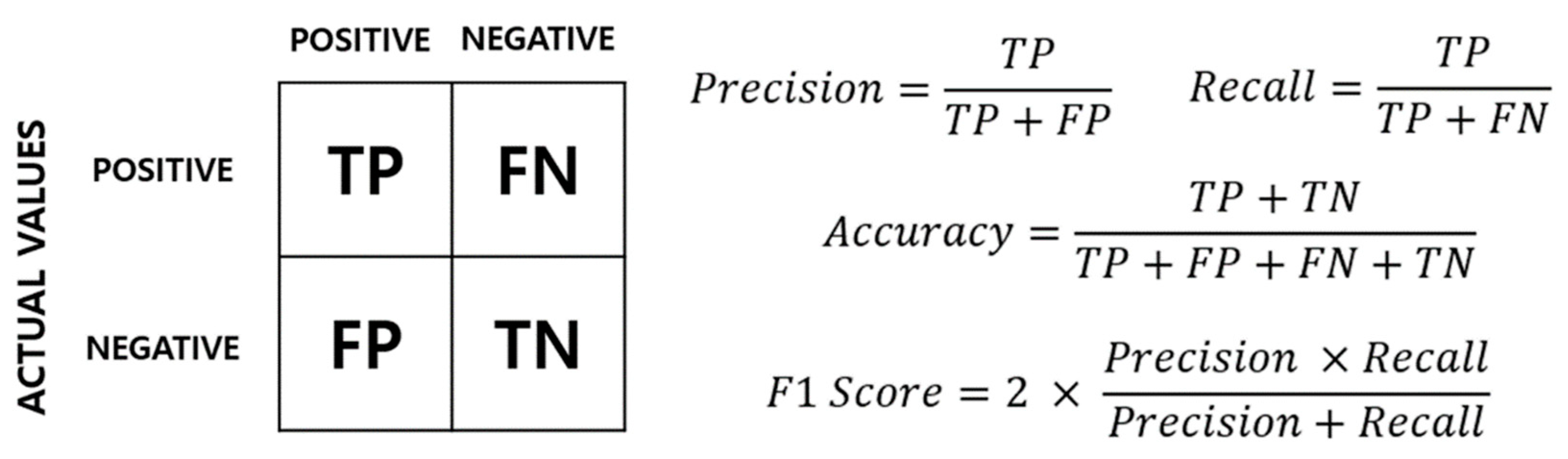
4.3. Fault Classification
5. Result and Conclusions
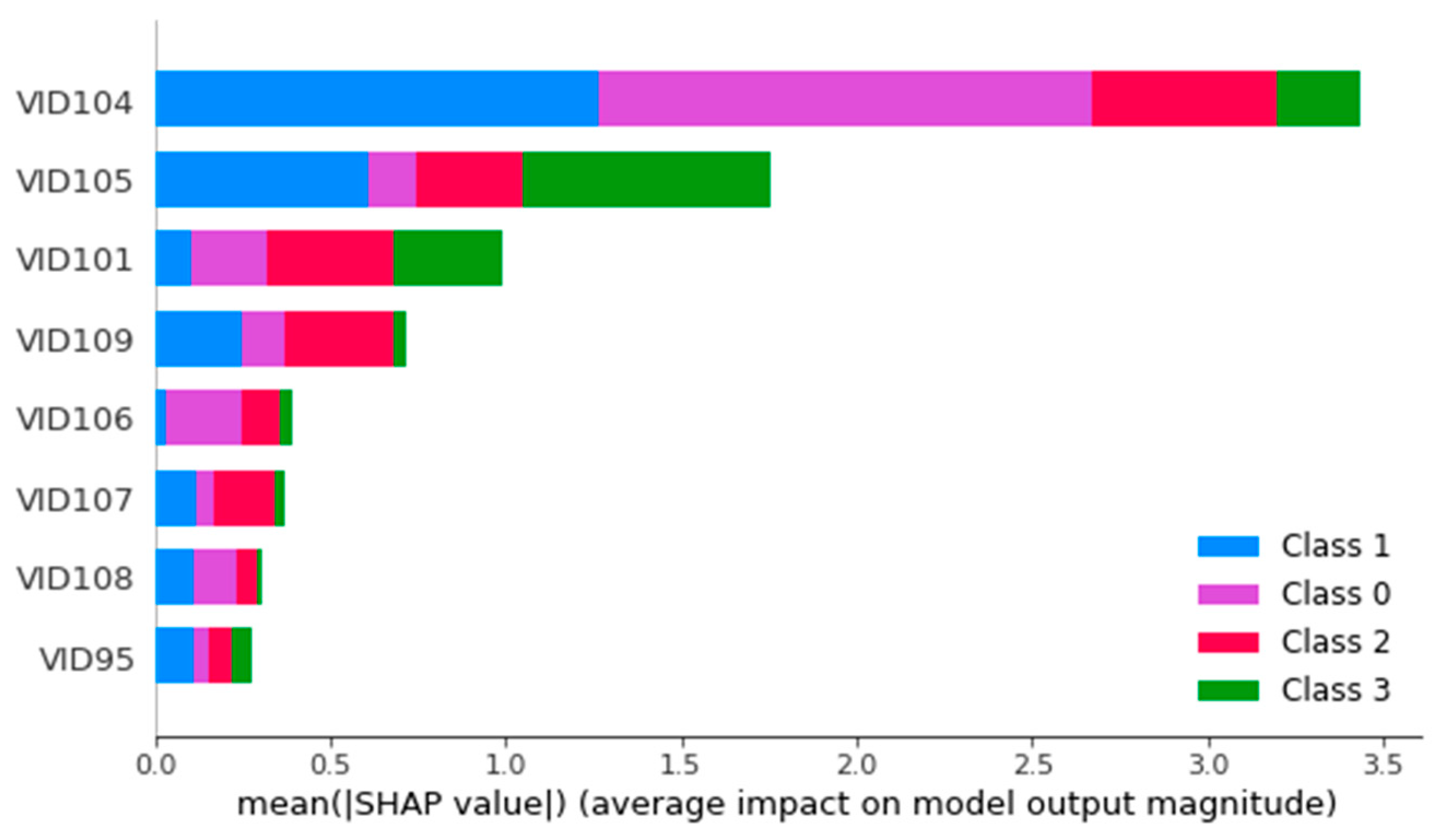
5.1. Result
5.2. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moyne, J.; Samantaray, J.; Armacost, M. Big Data Capabilities Applied to Semiconductor Manufacturing Advanced Process Control. TSM 2016, 29, 283–291. Available online: https://ieeexplore.ieee.org/document/7480394 (accessed on 18 December 2022). [CrossRef]
- Moyne, J.; Schulze, B.; Iskandar, J.; Armacost, M. Next Generation Advanced Process Control: Leveraging Big Data and Prediction. In Proceedings of the 2016 27th Annual SEMI Advanced Semiconductor Manufacturing Conference (ASMC), Saratoga Springs, NY, USA, 16 May 2016; pp. 191–196. [Google Scholar] [CrossRef]
- Moyne, J.; Iskandar, J. Big Data Analytics for Smart Manufacturing: Case Studies in Semiconductor Manufacturing. Processes 2017, 5, 39. [Google Scholar] [CrossRef] [Green Version]
- Park, H.; Choi, J.E.; Kim, D.; Hong, S.J. Artificial Immune System for Fault Detection and Classification of Semiconductor Equipment. Electronics 2021, 10, 944. [Google Scholar] [CrossRef]
- Jiang, D.; Lin, W.; Raghavan, N. A Novel Framework for Semiconductor Manufacturing Final Test Yield Classification Using Machine Learning Techniques. Access 2020, 8, 197885–197895. Available online: https://ieeexplore.ieee.org/document/9244159 (accessed on 18 December 2022). [CrossRef]
- Kim, S.H.; Kim, C.Y.; Seol, D.H.; Choi, J.E.; Hong, S.J. Machine Learning-Based Process-Level Fault Detection and Part-Level Fault Classification in Semiconductor Etch Equipment. TSM 2022, 35, 174–185. Available online: https://ieeexplore.ieee.org/document/9740077 (accessed on 18 December 2022). [CrossRef]
- Devi, D.; Biswas, S.K.; Purkayastha, B. A Review on Solution to Class Imbalance Problem: Undersampling Approaches, Piscataway. In Proceedings of the 2020 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, 2–4 July 2020; pp. 626–631. [Google Scholar] [CrossRef]
- Mathew, J.; Luo, M.; Pang, C.K.; Chan, H.L. Kernel-Based SMOTE for SVM Classification of Imbalanced Datasets. In Proceedings of the IECON 2015-41st Annual Conference of the IEEE Industrial Electronics Society, Yokohama, Japan, 9–12 November 2015; pp. 001127–001132. [Google Scholar] [CrossRef]
- Kim, D.H.; Choi, J.E.; Hong, S.J. Analysis of optical emission spectroscopy data during silicon etching in SF6/O2/Ar plasma. Plasma Sci. Technol. 2021, 23, 125501. [Google Scholar] [CrossRef]
- Qayyum, A.; Zeb, S.; Naveed, M.A.; Rehman, N.U.; Ghauri, S.A.; Zakaullah, M. Optical emission spectroscopy of Ar–N2 mixture plasma. J. Quant. Spectrosc. Radiat. Transf. 2007, 107, 361–371. [Google Scholar] [CrossRef]
- Kwon, H.; Hong, S.J. Use of Optical Emission Spectroscopy Data for Fault Detection of Mass Flow Controller in Plasma Etch Equipment. Electronics 2022, 11, 253. [Google Scholar] [CrossRef]
- Chawla, N.; Bowyer, K.; Hall, L.; Kegelmeyer, W. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. Available online: https://search.proquest.com/docview/2086828282 (accessed on 18 December 2022). [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, 1–8 June 2008; pp. 1322–1328. [Google Scholar] [CrossRef] [Green Version]
- Han, H.; Wang, W.; Mao, B. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. Lect. Notes Comput. Sci. 2005, 3644, 878. [Google Scholar] [CrossRef]
- Batista, Gustavo E A P A; Monard, M.C.; Bazzan, A.L.C. Balancing Training Data for Automated Annotation of Keywords: A Case Study. In Knowledge Exploration in Life Science Informatics; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar] [CrossRef]
- Wang, X.; Wang, K.; Li, X.; Lian, S. SMOTified-GAN for class imbalanced pattern classification problems. arXiv.org 2022. [Google Scholar]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Liao, Y.; Vemuri, V.R. Use of K-Nearest Neighbor classifier for intrusion detection. Comput. Secur. 2002, 21, 439–448. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T. Lightgbm: A Highly Efficient Gradient Boosting Decision Tree. NIPS. In In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar] [CrossRef]
- Buckland, M.; Gey, F. The relationship between recall and precision. J. Am. Soc. Inf. Sci. 1994, 45, 12–19. [Google Scholar] [CrossRef]
- Huang, Q.; Fang, C.; Mittal, S.; Blanton, R.D. Improving Diagnosis Efficiency via Machine Learning. In Proceedings of the 2018 IEEE International Test Conference (ITC), Phoenix, AZ, USA, 15–17 August 2018; pp. 1–10. Available online: https://ieeexplore.ieee.org/document/8624884 (accessed on 18 December 2022).
- Lundberg, S.M.; Lee, S. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems, NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017. [Google Scholar] [CrossRef]
- Umeda, S.; Tamaki, K.; Sumiya, M.; Kamaji, Y. Planned Maintenance Schedule Update Method for Predictive Maintenance of Semiconductor Plasma Etcher. IEEE Trans. Semicond. Manuf. 2021, 34, 296–300. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Number of Data | Proportion of Data |
|---|---|---|
| Normal | 12,014 | 62.5% |
| Abnormal_1 | 3238 | 16.9% |
| Abnormal_2 | 3208 | 16.7% |
| Abnormal_3 | 750 | 3.9% |
| FC Methods | Undersampling and Oversampling Methods | ||||||
|---|---|---|---|---|---|---|---|
| Real | SMOTE | Borderline SMOTE | SMOTE TOMEK | ADASYN | GAN | SMOTified GAN | |
| AdaBoost | 0.6500 | 0.8667 | 0.8367 | 0.9000 | 0.8333 | 0.7100 | 0.7833 |
| KNN | 0.6500 | 0.9000 | 0.8733 | 0.9333 | 0.8433 | 0.7067 | 0.7967 |
| LightGBM | 0.6667 | 0.8800 | 0.8833 | 0.9500 | 0.8400 | 0.8667 | 0.8167 |
| AVG | 0.6556 | 0.8822 | 0.8644 | 0.9278 | 0.8389 | 0.7611 | 0.7989 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seol, D.H.; Choi, J.E.; Kim, C.Y.; Hong, S.J. Alleviating Class-Imbalance Data of Semiconductor Equipment Anomaly Detection Study. Electronics 2023, 12, 585. https://doi.org/10.3390/electronics12030585
Seol DH, Choi JE, Kim CY, Hong SJ. Alleviating Class-Imbalance Data of Semiconductor Equipment Anomaly Detection Study. Electronics. 2023; 12(3):585. https://doi.org/10.3390/electronics12030585
Chicago/Turabian StyleSeol, Da Hoon, Jeong Eun Choi, Chan Young Kim, and Sang Jeen Hong. 2023. "Alleviating Class-Imbalance Data of Semiconductor Equipment Anomaly Detection Study" Electronics 12, no. 3: 585. https://doi.org/10.3390/electronics12030585