1. Introduction
Since the outbreak of COVID-19, reliance on cyberspace has increased, and spam abuse is increasing as well. Smishing, a type of spam, is a combination of SMS and phishing and is a new fraudulent method that steals users’ financial information with spam messages containing malicious URLs. However, these smishing instances often show different aspects than previous types of spam. Firstly, there are increases in the rate of smishing, as well as in impersonating public institutions and acquaintances. Secondly, international spam crimes, which are no longer domestic but cross borders, are also emerging. According to the article [
1], Federal Trade Commission (FTC), the amount of damage caused by scam text is estimated to be USD 86 million. In addition, the reported number of damages is 334,524 per year, which is equal to 916 cases per day on average. Therefore, spam SMS detection is essential for damage prevention.
To solve this SMS smishing problem, various methods of spam detection have been proposed. In particular, a study [
2] classified recent spam detection methods into those using background information (including SMS messages, as well as accounts and behavior features) and those using content-level spam detection (focusing on the content of messages), finding that, among these spam detection methods, text-based spam detection was widely applied. Additionally, in [
3], a bag of words (BOW) was used as a text-based content-level spam detection method.
Existing spam detection methods essentially require natural language processing to process input text data. Many researchers have proposed English natural language processing, but the amount of papers with non-English natural language processing is relatively small. In addition, each language’s grammatical characteristics make it more complex to process spam content. For example, Korean has linguistic characteristics such as large differences between spoken and written language; honorifics according to relationships between listeners and speakers; semantic changes according to prosodic elements; frequent omissions of subjects, predicates, and objects; and difficulty in word spacing. However, since there are not many research methods available, it is difficult to process natural languages compared to English. Thus, it inevitably appears differently depending on the natural language processing method and level, as the characteristics are different for each language to detect content level. In a previous study [
4], multilingualism showed lower accuracy than English. The researchers proceeded with natural language processing for Spanish, Chinese, and Indonesian [
5], but as there were differences in character form and grammatical complexity, they found the same limitations as previous models. In the case of using OCR, spam messages are processed by applying deep learning after natural language processing. In addition, there are difficulties in applying existing detection models to the form of current spam text. Spammers intentionally make typos or alterations, such as creating spaces between words, and preprocessing cannot determine whether these words are spam. In response, ref. [
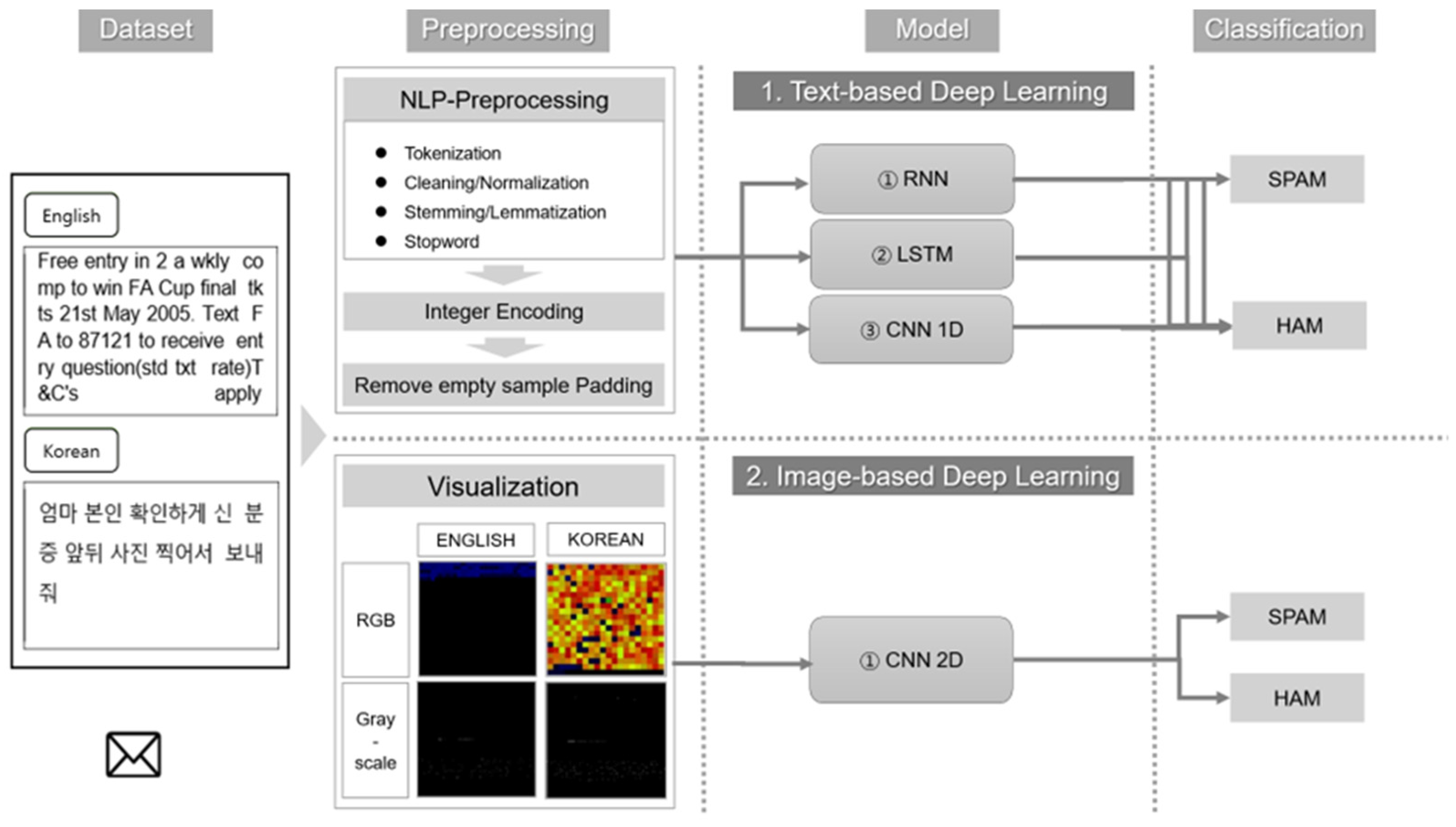
6] used CBOW and skip-gram methods to detect not only general strings, but also texts replaced with special symbols, languages of other countries, and numbers. In this paper, to conduct image-based detection research, spam and ham were classified by applying image-processed SMS to deep learning through separate visualization processing.
In this study, an image-based spam detection method using a CNN 2D model is used to generate Unicode-based images. We conduct research by converting English, which can be considered a basic sample, and Korean, which can be considered a unique sample, into Unicode in our dataset. Our study shows higher accuracy than existing methods. In addition, in another respect, it shows different characteristics from existing spam detection methods using deep learning.
Firstly, the Unicode-based image creation method eliminates preprocessing. Therefore, the comprehensive operation is possible for spam detection not only in English, but also in non-English languages that can be expressed in Unicode or in datasets with mixed languages.
Secondly, we propose an image-based spam detection method that is different from existing general text-based spam detection methods. In this method, the model learns spam and ham dataset images separately and extracts the features of the images to detect spam.
4. Discussion
Our work has potential for improvement. First, the UCI spam data used as the English dataset included about 5000 samples. Since more than 10,000 Korean datasets were used, there was a limitation in that the dataset was not balanced. Thus, the experiment could be conducted by adding more English spam data. Second, in addition to the spam SMS classification task, an image-processing method could be used for applications in more fields. Third, in this experiment, a standard CNN was used for image-based classification, but variations of CNN models could be applied. Fourth, in addition to Korean and English, other languages could also be applied. Finally, although this study used an existing model, further research should be expected to compare detection using a PLM model, one of the newly proposed detection models, or to study the efficiency of combinations with CNN models.
5. Conclusions
Existing spam detection methods are based on strings, and classification is performed through machine-learning or deep-learning models through natural language processing. In this paper, a visualization step was added to an existing detection process for effective spam SMS detection.
The visualization method was largely divided into two types. The first method converted each character’s Unicode value into a pair of coordinates. The second method stored each character’s Unicode value in an RGB tuple and returned it as a pixel in the image.
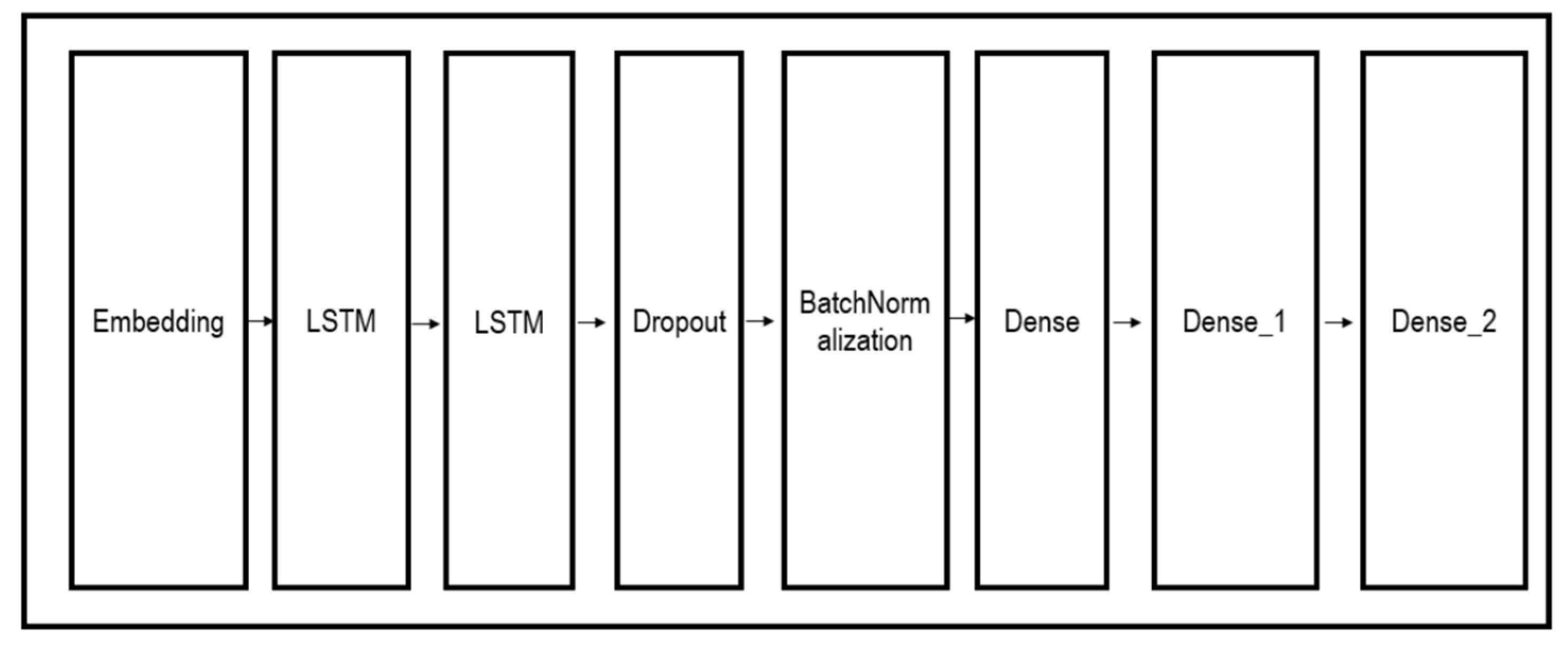
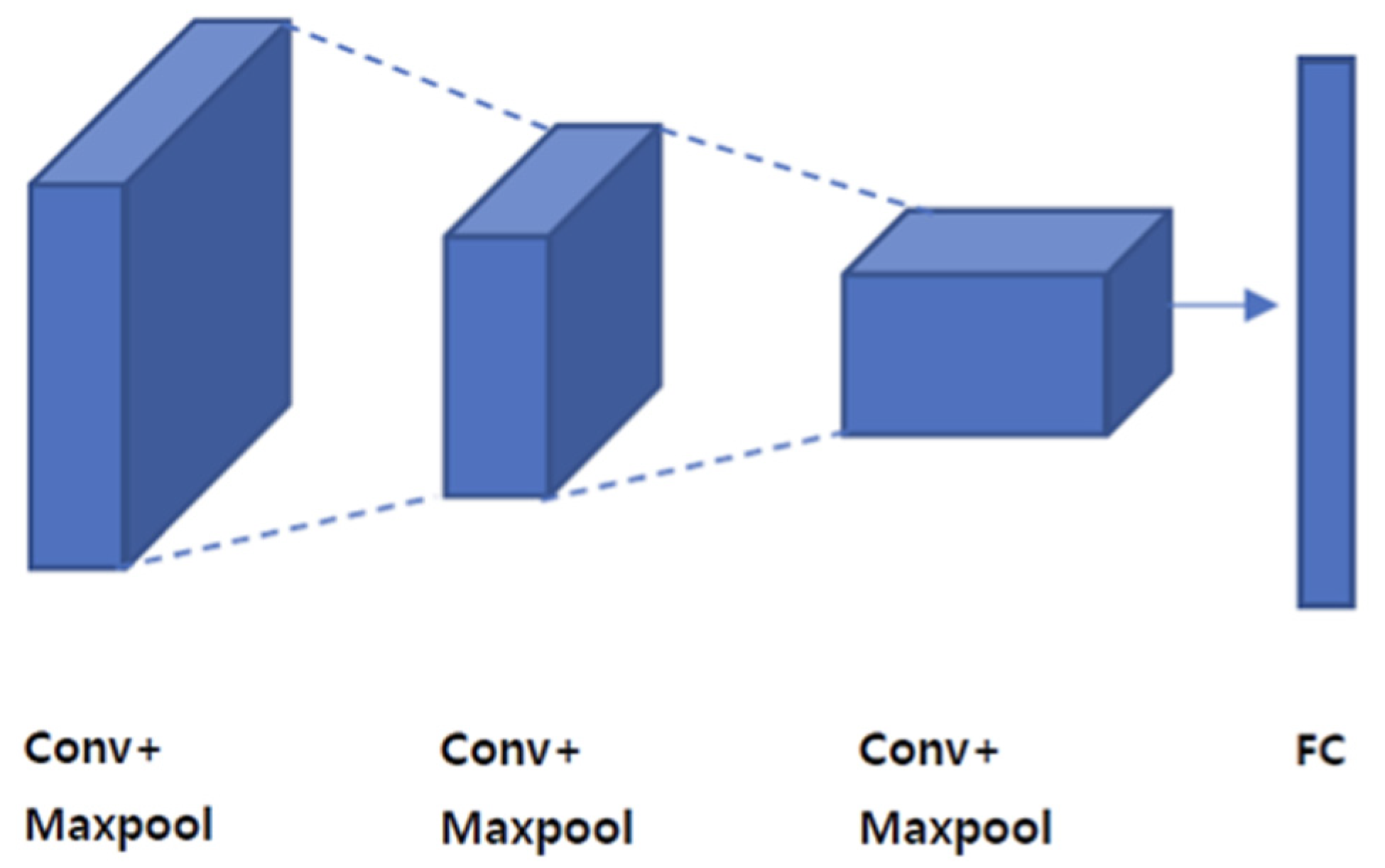
A CNN was used as a deep-learning model for spam SMS detection. As a result of applying the deep-learning model after visualization, it was confirmed that there was no difference from the results of the text-based classification experiment. The preprocessing step was eliminated through image processing, and the classification results were outperformed. The proposed visualization method could perform more efficient classification tasks by omitting preprocessing tasks, such as tokenization, stemming, and spell-checking.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}