1. Introduction
A self-driving vehicle requires more attention to be paid to the execution time of their components, since this may save many lives every day [
1]. It must be ready to perform the right action in real time to prevent incidents. In order to achieve this level of control, the system should be built to provide rapid interaction between its components, to receive instant location information to perform the overtaking of vehicles and perform rapid path planning [
2]. Localization of the vehicles is an essential step to ensure the functionality of other components. The information provided can be used to identify the distances between the vehicles and the structures in the environment, which is crucial information needed to avoid collisions, find the shortest distance to the destination, and so on [
2]. Global navigation satellite systems (GNSS) are already equipped, in almost all autonomous vehicles, to provide position coordinates by triangulation using at least three satellites. However, this technology faces several issues for real-time execution when the satellite signals are interrupted, such as under bridges, in tunnels, and around tall buildings [
3,
4]. Several researchers have thought to localize the vehicle based on internal sensors, such as light detection and ranging (LiDAR), cameras, inertial measurement units (IMUs), or even radar sensors [
2].
Our review of the state-of-art in this area divides the related methods into two categories: direct methods and feature-based methods. Direct methods try to estimate vehicle’s position directly by calculating the distances between two positions and using dead reckoning (DR) to deduce the position. The IMU unit from the inertial navigation system (INS) is one of the methods that uses this approach [
5]. An IMU provides information about the acceleration and attitude rate of the vehicle. The double integration of the acceleration measurement will provide the position of the vehicle. However, the double integration is prone to errors that can be accumulated during the execution of the process [
5]. Several researchers have tried to correct these errors by sending them to a machine learning model, such as an input delay neural network (IDNN) [
6], multi-layer feed forward neural network (MFNN) [
7], recurrent neural network (RNN) [
8], or long short-term memory (LSTM) model [
9,
10]. For more information about deep learning (DL) methods in self-driving vehicles, the readers are referred to [
11].
Wheel odometry is a great tool for estimating the vehicle’s position that works by using the velocity and integrating it to get the position [
12]. However, as we mentioned before, the integration process provides an error that can be amplified and accumulated each time we re-execute the process. According to the article [
12], using wheel odometry is better than using an IMU accelerometer, since it needs less integration time. The wheel odometry neural network (WhONet) [
12] uses an RNN-based architecture to correct the wheel odometry errors, and an extensive experiment was performed during several GNSS outages.
Feature-based approaches for vehicle localization try to extract relevant features from data gathered from one or more sensors. We have surveyed in this work only LiDAR-based methods, since we believe that the camera images are easily affected by weather changes such as snow and rain [
1,
2]. Extracting features from LiDAR measurements has been the subject of several papers in the literature. LiDAR odometry and mapping (LOAM) [
13] distinguish edges and flat plan features to perform scan-to-scan and scan-to-map matching, which are techniques to track the vehicle’s motions (translation and rotation) between consecutive sequences. However, the process consumes too much time when executed, which is covered in the article introducing the LOAM_Velodyne [
14] method. To solve the same issue, lightweight and ground-optimized LOAM (LeGO-LOAM) [
15] and A-LOAM [
16] approaches remove noisy and useless features to reduce the computational time. Other methods, such LO-Net [
17] and LO-Net-M [
17], use end-to-end deep learning (DL) to improve the scan-to-matching process. SGLO [
18] extracts geometric line and plane features to improve the matching process, which has provided good results. However, the accuracy is dramatically affected by the initialization. Methods such as those of Kummerle et al. [
19], Weng et al. [
20], Sefati et al. [
21], and A. Schaefer et al. [
22] use a probabilistic perspective to localize the vehicles. Based on detecting poles and walls from LiDAR scans, the methods used a particle filter algorithm to correct the IMU’s accumulative errors. The method of Schaefer et al. [
22] achieved excellent results on the Kitti dataset [
23] and the University of Michigan North Campus Long-Term Vision and LiDAR Dataset (NCLT) [
24]. However, the features extracted for the operation may not exist in some environments, especially those with little in the way of texture, such as desert roads. That is why the work of Charroud et al. [
25] proposed using non-semantic features to help perform the measurement-update step in the particle filter. An extension of this work was presented in the article [
26], where the authors proposed a modified clustering particle filter that selects relevant particles to calculate the position by using sigma-point selection. Moreover, another extension of the work in [
25] is the article [
27], where it was proposed to extend the work on particle filters by selecting only the 10 best particles around the real position and regenerating the particles around them. This trick enables the particle filter to run fast and preserves the accuracy, as we generate particles close to the real position at each execution of the algorithm.
Our novel method uses non-semantic features as a pre-processing step to teach a machine-learning model the actual vehicle positions. The inputs are the extracted features, and the outputs are the positions. The model was extensively tested on short- and long-term trajectories using two benchmark datasets: Kitti [
23] and NCLT [
24]. In addition, the model is explained by studying the features that contribute positively or negatively to the output model. Based on the results of explaining the first model, another model was constructed and compared to evaluate the influence of the changes made. The article [
28] discusses the concept of explainable artificial intelligence (XAI), which refers to the development of AI systems that are able to provide clear, interpretable explanations for their decisions and actions. The authors provide an overview of the various types of XAI approaches that have been proposed, including post hoc explanation methods, integrated explanation methods, and interactive explanation methods. They also explore the potential benefits and challenges of XAI, and discuss the importance of responsible AI development in ensuring the transparency, accountability, and trustworthiness of AI systems.
This paper contains the following contributions:
As far as the authors are aware, this is the first method that uses only a few LiDAR cluster points to feed a deep-learning model for localization purposes.
The paper presents, in
Section 2, a robust mathematical formulation of the localization problem, which opens up some opportunities to develop more solutions based on optimization and stochastic-differential-equation-based methods.
Deep Learning explanation methods were employed to find the most contributing cluster features in order to optimize the proposed model.
The sections of the paper are organized as follows.
Section 2 provides an in-depth explanation of the problem and the architecture we propose to solve it.
Section 3 presents the steps followed to create the proposed model.
Section 4 presents the results of testing the model in the short and long-term scenarios. The contributions of the features are also discussed, and a comparison between the two models with further implications is presented in this section.
Section 5 provides some conclusions.
2. Problem Description and Proposed Architecture
As mentioned before, any autonomous system requires a localization and mapping method to facilitate the scheduling of other principal tasks, such as path planning and overtaking vehicles. [
1]. In particular, self-driving vehicles must be given more attention regarding the execution times of different components, since they need an instant interaction with the environment, which means that we need to ensure fast execution of the methods without hurting the accuracy too much. Quickness and accuracy are critical to getting a better experience from driving. Most of the state-of-the-art methods divide the process of localization and mapping into two parts: feature extraction and localization prediction. Extracting relevant features is a principal task in creating a global map, and helps to execute the localization task easily by providing the environmental objects or shapes around the vehicles.
Figure 1 presents a simple workflow architecture that consists of two major steps: feature extraction (A) and learning the positions (B). In this section, we want to give the theoretical intuitions about the approaches followed to solve the localization and mapping problem for self-driving vehicles, which could be extended to other autonomous systems. A practical implementation of the method is delivered in the next section.
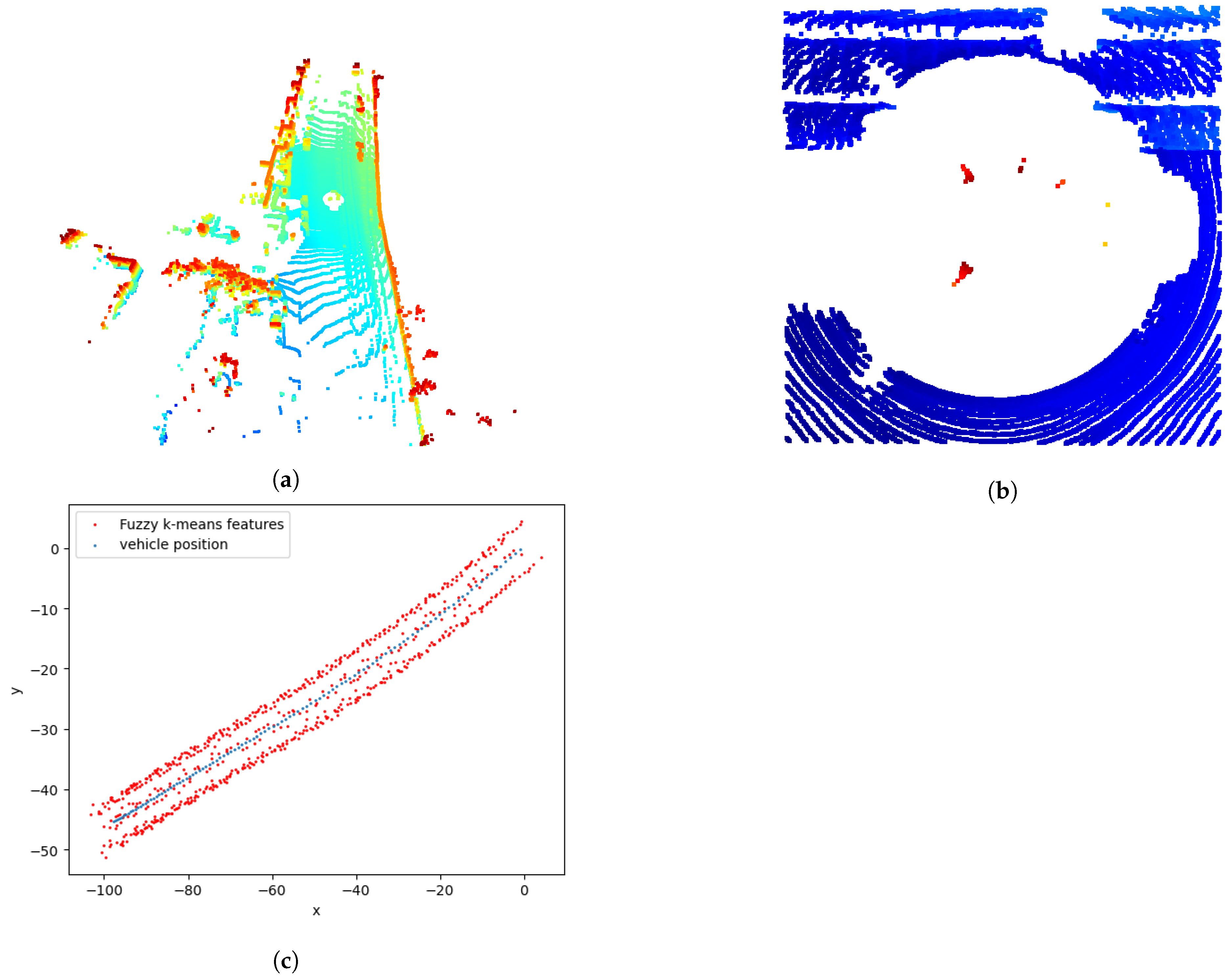
Our method localizes the vehicle based on LiDAR measurements only. We suppose that the LiDAR scans and the ground truth positions are in the body-frame coordinates, where at each timestamp each position has its corresponding scan. We use non-semantic features to distinguish some relevant prototype features. This technique can represent a wide range of objects inside the environment, in contrast to focusing on a single object (such as poles or edges), which is very advantageous to representing environments with less texture information. We chose to employ a clustering algorithm to extract clusters, which form our non-semantic features.
Let us have some mathematical formulation:
Let
be a LiDAR scan at time
t:
where
is the number of LiDAR points at time
t, and let also
be the real position at time
t (the z coordinate is supposed to be the same for the real position). We apply a clustering technique by fixing the number of centers to a certain value (discussed in the next section), so we have:
and
is the number of clusters,
is the group of center clusters, and
is the center of cluster
i, where
. For simplicity, below we consider that the number of clusters stays the same along the trajectory (
for all
t).
The main idea of this paper is to find
and a function
f that will minimize the problem
:
T is the last timestamp value. We try to estimate a function
f that will aggregate and manipulate the centers’ clusters
in order to get an estimated position that will be close to the real position
.
are some weights to ensure the reliability of the projection of the cluster from the 3D to the 2D environment. Scalars
are used to provide a percentage (probability) of the importance of the clusters
after manipulation with the function
f.
To solve the problem
, we established a method based on a deep learning approach that takes the cluster features as the input and returns back the estimated positions. The architecture was chosen manually by testing the capabilities and robustness of several time series regression methods, such as LSTM, GRU, and RNN. We envisaged that the proposed architecture in
Figure 2 is robust enough to learn and predict unseen data—i.e., that it has the capacity for generalization. The reader may remark that several convolutions were applied to eliminate the data outliers. LSTM and GRU are the main layers to create the memory inside the proposed model. We have demonstrated the capacity of this architecture by testing on several popular time-series methods.
Table 1 presents the results of comparing the training and validation MAE (mean absolute error) of our method and other architectures.
5. Conclusions
Localization and mapping in self-driving vehicles have been extensively treated with different approaches, including probabilistic, optimization, and other machine-learning methods. In this paper, we presented a novel deep-learning workflow for learning vehicle positions. The input features of the model were extracted from the LiDAR scans at each time point. The extraction process was based on the application of a fuzzy k-means algorithm that extracts features from clusters. The model architecture was based on a combination of LSTM and GRU model layers and smoothing with a 1D convolution. We tuned the model to obtain the best hyperparameters, and we trained the model with different parameters, such as early stopping, reduction of the learning rate in the case of constant metrics, etc. The model has obtained very good short- and long-term results in different challenging environmental scenarios, such as weather changes and various trajectory scenarios. The model is able to keep the mean absolute positioning error below 1 m for all sequences in short- and long-term trajectories.
We also provided possible explanations for the model’s results and examined the contribution of the clusters (features). We found that the mean of all the extracted clusters is the most important feature that contributes positively to the prediction result. We created a new explained model that takes only the mean of all clusters as input and ran the prediction again. According to the comparison results of both models, the new, more explainable model improves the accuracy of vehicle positioning and reduces the time and computational resources required to train and use these models.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}