

INNT: Restricting Activation Distance to Enhance Consistency of Visual Interpretation in Neighborhood Noise Training

Abstract
:1. Introduction
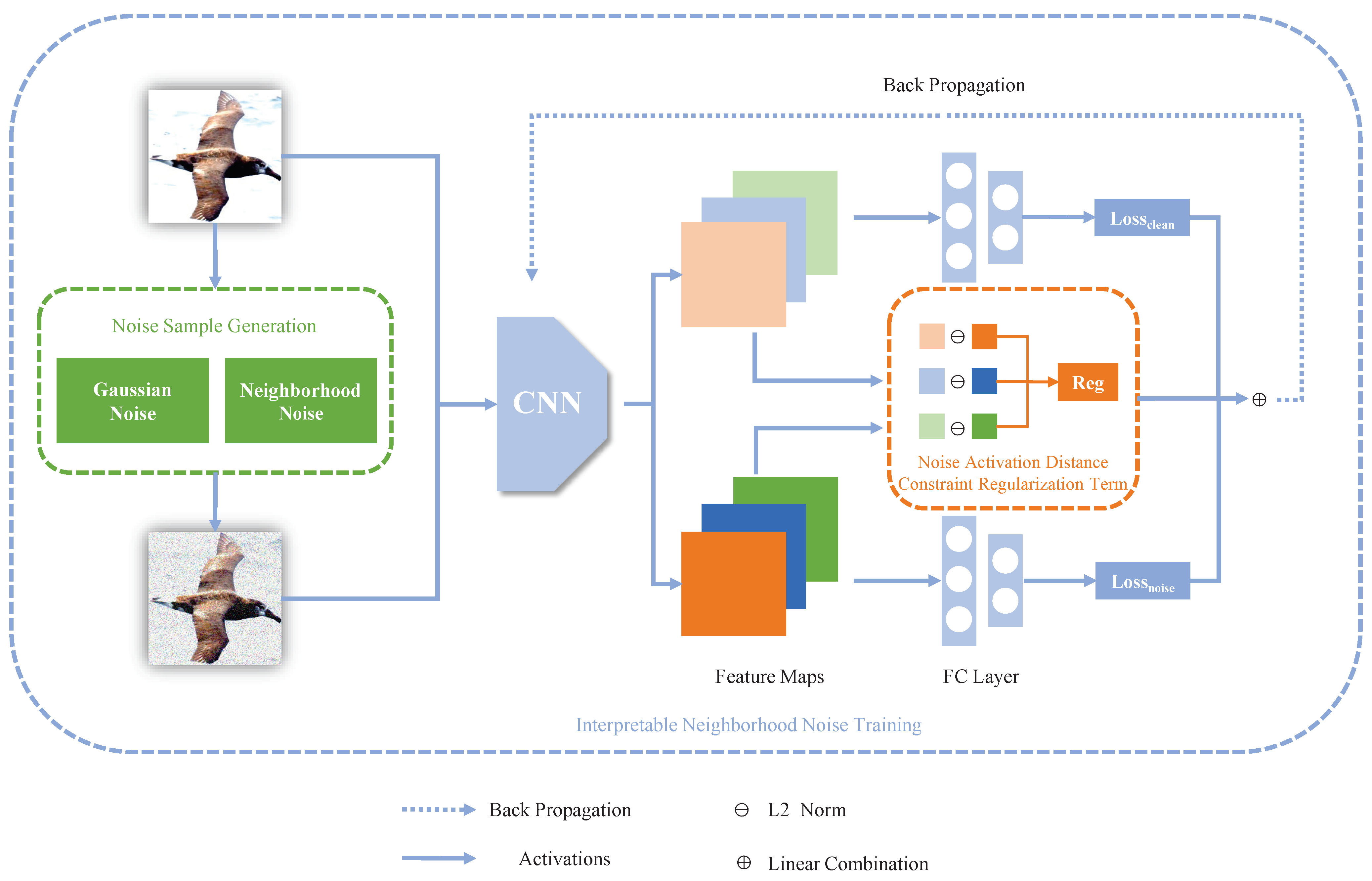
- We introduce an end-to-end framework called Interpretable Neighborhood Noise Training (INNT), along with a noise activation distance-constrained regularization term. For specific types of noise, this enables visually interpretable noise training, and it can be broadly applied to common deep convolutional neural network architectures.
- We propose neighborhood noise, a method for generating image noise by uniformly sampling tiny neighborhoods around each pixel. This approach allows generate visually similar noise images in a more controlled manner. And it can more effectively represent the approximate neighborhoods of the images.
- We applied Interpretable Neighborhood Noise Training (INNT) to AlexNet, VGG16, and ResNet, validating the effectiveness of INNT on the CUB-200-2011 and CIFAR-10 datasets. Our method demonstrated superior visual interpretability consistency and achieved closer predictive accuracy on similar images.
2. Related Works
2.1. Image Corruption
2.2. Robustness Enhancements
2.3. CNN Visual Interpretation
3. Methods
3.1. Noise Training and Saliency Maps
3.1.1. Noise Training
3.1.2. Saliency Map
3.2. Noise Activation Distance Constraint Regularization Term
3.3. Noise Sample Generation
- The noise function is widely applicable and can represent common image corruptions or natural disturbances.
- The amplitude of the noise generated by the function is controlled by a limited number of adjustable parameters.
- The noise generated by the function can effectively interfere with the classification decisions of the image classification system while keeping the noise amplitude at a low level.
3.3.1. Gaussian Noise
3.3.2. Neighborhood Noise
3.4. Interpretable Neighborhood Noise Training
4. Experiments
4.1. Dataset
4.1.1. CUB-200-2011 Dataset
4.1.2. CIFAR-10
4.2. Implementation Details
4.3. Evaluation Metrics
4.3.1. Faithfulness Evaluation via Image Recognition
4.3.2. Localization Evaluation
4.4. Interpretability Enhancement
4.5. Predictive Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. Stat 2015, 1050, 20. [Google Scholar]
- Tsipras, D.; Santurkar, S.; Engstrom, L.; Turner, A.; Madry, A. Robustness May Be at Odds with Accuracy. In Proceedings of the International Conference on Learning Representations, New Orleans, LO, USA, 6–9 May 2019. [Google Scholar]
- Rusak, E.; Schott, L.; Zimmermann, R.S.; Bitterwolf, J.; Bringmann, O.; Bethge, M.; Brendel, W. A simple way to make neural networks robust against diverse image corruptions. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 53–69. [Google Scholar]
- Dodge, S.; Karam, L. Understanding how image quality affects deep neural networks. In Proceedings of the 2016 Eighth International Conference on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016; pp. 1–6. [Google Scholar]
- Geirhos, R.; Janssen, D.H.; Schütt, H.H.; Rauber, J.; Bethge, M.; Wichmann, F.A. Comparing deep neural networks against humans: Object recognition when the signal gets weaker. arXiv 2017, arXiv:1706.06969. [Google Scholar]
- Hendrycks, D.; Dietterich, T. Benchmarking Neural Network Robustness to Common Corruptions and Perturbations. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Mu, N.; Gilmer, J. Mnist-c: A robustness benchmark for computer vision. arXiv 2019, arXiv:1906.02337. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2574–2582. [Google Scholar]
- Rony, J.; Granger, E.; Pedersoli, M.; Ben Ayed, I. Augmented Lagrangian Adversarial Attacks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 7738–7747. [Google Scholar]
- Duan, R.; Chen, Y.; Niu, D.; Yang, Y.; Qin, A.K.; He, Y. AdvDrop: Adversarial Attack to DNNs by Dropping Information. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 7506–7515. [Google Scholar]
- Michaelis, C.; Mitzkus, B.; Geirhos, R.; Rusak, E.; Bringmann, O.; Ecker, A.S.; Bethge, M.; Brendel, W. Benchmarking robustness in object detection: Autonomous driving when winter is coming. arXiv 2019, arXiv:1907.07484. [Google Scholar]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; Van Der Maaten, L. Exploring the limits of weakly supervised pretraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 181–196. [Google Scholar]
- Laermann, J.; Samek, W.; Strodthoff, N. Achieving generalizable robustness of deep neural networks by stability training. In Pattern Recognition, Proceedings of the 41st DAGM German Conference, DAGM GCPR 2019, Dortmund, Germany, 10–13 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 360–373. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10687–10698. [Google Scholar]
- Zhang, R. Making convolutional networks shift-invariant again. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7324–7334. [Google Scholar]
- Schneider, S.; Rusak, E.; Eck, L.; Bringmann, O.; Brendel, W.; Bethge, M. Improving robustness against common corruptions by covariate shift adaptation. Adv. Neural Inf. Process. Syst. 2020, 33, 11539–11551. [Google Scholar]
- Pang, T.; Lin, M.; Yang, X.; Zhu, J.; Yan, S. Robustness and accuracy could be reconcilable by (proper) definition. In Proceedings of the International Conference on Machine Learning. PMLR, Baltimore, MI, USA, 17–23 July 2022; pp. 17258–17277. [Google Scholar]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Piscataway, NJ, USA, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Bishop, C.M. Training with noise is equivalent to Tikhonov regularization. Neural Comput. 1995, 7, 108–116. [Google Scholar] [CrossRef]
- Gilmer, J.; Ford, N.; Carlini, N.; Cubuk, E. Adversarial Examples Are a Natural Consequence of Test Error in Noise. In Proceedings of the 36th International Conference on Machine Learning Research, Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; IEEE: New York, NY, USA, 2019; Volume 97, pp. 2280–2289. [Google Scholar]
- Vasiljevic, I.; Chakrabarti, A.; Shakhnarovich, G. Examining the impact of blur on recognition by convolutional networks. arXiv 2016, arXiv:1611.05760. [Google Scholar]
- Zhang, Q.; Wu, Y.N.; Zhu, S.C. Interpretable convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8827–8836. [Google Scholar]
- Kuo, C.C.J. Understanding convolutional neural networks with a mathematical model. J. Vis. Commun. Image Represent. 2016, 41, 406–413. [Google Scholar] [CrossRef]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harv. J. Law Technol. 2017, 31, 841. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Computer Vision—ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part I 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing higher-layer features of a deep network. Univ. Montr. 2009, 1341, 1. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S.; Mardziel, P.; Hu, X. Score-CAM: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 24–25. [Google Scholar]
- Jiang, P.T.; Zhang, C.B.; Hou, Q.; Cheng, M.M.; Wei, Y. Layercam: Exploring hierarchical class activation maps for localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef] [PubMed]
- Bau, D.; Zhou, B.; Khosla, A.; Oliva, A.; Torralba, A. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6541–6549. [Google Scholar]
- Cohen, J.; Rosenfeld, E.; Kolter, Z. Certified adversarial robustness via randomized smoothing. In Proceedings of the International Conference on Machine Learning—PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 1310–1320. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. Caltech-UCSD Birds 200; Technical Report CNS-TR-2011-001; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Adv. Neural Inf. Process. Syst. 2016, 29, 2180–2188. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Bai, S.; Bai, X. Sparse contextual activation for efficient visual re-ranking. IEEE Trans. Image Process. 2016, 25, 1056–1069. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Li, S.; Shen, Y.; Liu, C.H.; Wang, S. On the Difficulty of Unpaired Infrared-to-Visible Video Translation: Fine-Grained Content-Rich Patches Transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 1631–1640. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Configuration |
|---|---|
| Operating System | Ubuntu 22.04 |
| CPU | Intel(R) Xeon(R) Gold 6248R CPU @ 3.00GHz |
| GPU | NVIDIA RTX A6000 48GB |
| Memory | 128GB |
| Python | 3.9.13 |
| Pytorch | 1.13.0 |
| CUDA | 11.7 |
| Hyperparameters | Value |
|---|---|
| 0.7 | |
| 0.15 | |
| 1.0 |
| Models | Gaussian Noise | Neighborhood Noise | |||||
|---|---|---|---|---|---|---|---|
| AD | AI | AEPE | AD | AI | AEPE | ||
| ResNet | ResNet | 0.9216 | 0.0397 | 0.1158 | 0.8928 | 0.0405 | 0.1277 |
| ResNet NT | 0.6283 | 0.1798 | 0.1277 | 0.5228 | 0.2008 | 0.0802 | |
| ResNet INNT | 0.4189 | 0.2354 | 0.0795 | 0.3067 | 0.2354 | 0.0547 | |
| VGG16 | vgg16 | 0.7442 | 0.1591 | 0.1245 | 0.7191 | 0.0960 | 0.1037 |
| vgg16 NT | 0.4730 | 0.2135 | 0.0871 | 0.3255 | 0.1798 | 0.0763 | |
| vgg16 INNT | 0.4097 | 0.2453 | 0.0738 | 0.3001 | 0.2211 | 0.0590 | |
| AlexNet | AlexNet | 0.8002 | 0.1201 | 0.1576 | 0.7226 | 0.1463 | 0.1280 |
| AlexNet NT | 0.5350 | 0.2781 | 0.1076 | 0.2699 | 0.3126 | 0.0724 | |
| AlexNet INNT | 0.4109 | 0.3013 | 0.1000 | 0.2078 | 0.3578 | 0.0395 | |
| Models | Gaussian Noise | Neighborhood Noise | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Clean | Noise | Acc Gap | Clean | Noise | Acc Gap | |||||||
| Top1% | Top5% | Top1% | Top5% | Top1% | Top5% | Top1% | Top5% | Top1% | Top5% | Top1% | Top5% | |
| ResNet | 81.50 | 95.71 | 31.78 | 57.42 | 49.72 | 38.29 | 81.50 | 95.71 | 46.72 | 71.65 | 34.78 | 24.06 |
| NT | 76.62 | 93.16 | 72.53 | 91.96 | 4.09 | 1.20 | 78.67 | 95.13 | 73.24 | 94.03 | 5.43 | 1.10 |
| INNT | 78.32 | 94.82 | 74.12 | 93.40 | 4.20 | 1.42 | 78.05 | 94.66 | 75.41 | 93.84 | 2.64 | 0.82 |
| VGG16 | 73.79 | 93.65 | 15.21 | 33.88 | 58.58 | 59.77 | 74.32 | 93.13 | 33.46 | 59.65 | 40.86 | 33.48 |
| NT | 76.20 | 93.08 | 65.65 | 88.15 | 10.55 | 4.93 | 78.20 | 93.64 | 72.40 | 91.06 | 5.80 | 2.58 |
| INNT | 72.93 | 92.40 | 68.71 | 89.98 | 4.22 | 2.42 | 76.89 | 93.98 | 73.20 | 92.16 | 3.69 | 1.82 |
| AlexNet | 61.02 | 86.54 | 7.12 | 18.66 | 53.90 | 67.88 | 61.02 | 86.54 | 17.18 | 38.67 | 43.84 | 47.87 |
| NT | 49.58 | 79.66 | 39.95 | 69.44 | 9.63 | 10.22 | 52.75 | 79.54 | 47.43 | 74.36 | 5.43 | 5.18 |
| INNT | 57.87 | 83.73 | 54.94 | 80.88 | 2.93 | 2.85 | 58.34 | 85.38 | 54.23 | 81.64 | 4.11 | 3.74 |
| Models | Gaussian Noise | Neighborhood Noise | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Clean | Noise | Acc Gap | Clean | Noise | Acc Gap | |||||||
| Top1% | Top5% | Top1% | Top5% | Top1% | Top5% | Top1% | Top5% | Top1% | Top5% | Top1% | Top5% | |
| ResNet | 96.76 | 99.94 | 18.63 | 81.69 | 78.13 | 18.25 | 96.76 | 99.94 | 52.78 | 94.52 | 43.98 | 5.42 |
| NT | 95.66 | 99.92 | 94.67 | 99.90 | 0.99 | 0.02 | 96.48 | 99.94 | 95.32 | 99.88 | 1.16 | 0.06 |
| INNT | 95.76 | 99.88 | 95.07 | 99.87 | 0.69 | 0.01 | 95.80 | 99.89 | 95.33 | 99.89 | 0.47 | 0.00 |
| VGG16 | 92.93 | 99.87 | 10.01 | 50.43 | 82.92 | 49.44 | 92.93 | 99.87 | 11.67 | 60.26 | 81.26 | 39.61 |
| NT | 91.33 | 99.60 | 88.55 | 99.47 | 2.78 | 0.13 | 92.34 | 99.85 | 89.60 | 99.72 | 2.74 | 0.13 |
| INNT | 91.39 | 99.71 | 90.53 | 99.70 | 0.86 | 0.01 | 93.84 | 99.85 | 92.32 | 99.75 | 1.52 | 0.10 |
| AlexNet | 92.85 | 99.76 | 25.66 | 68.28 | 67.19 | 31.48 | 92.85 | 99.76 | 43.77 | 86.39 | 49.08 | 13.37 |
| NT | 90.83 | 99.73 | 89.76 | 99.63 | 1.07 | 0.10 | 92.25 | 99.79 | 90.52 | 99.66 | 1.73 | 0.13 |
| INNT | 90.64 | 99.74 | 90.17 | 99.69 | 0.47 | 0.05 | 91.43 | 99.75 | 90.88 | 99.72 | 0.55 | 0.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Ma, R.; He, J.; Zhang, T.; Wang, X.; Xue, J. INNT: Restricting Activation Distance to Enhance Consistency of Visual Interpretation in Neighborhood Noise Training. Electronics 2023, 12, 4751. https://doi.org/10.3390/electronics12234751
Wang X, Ma R, He J, Zhang T, Wang X, Xue J. INNT: Restricting Activation Distance to Enhance Consistency of Visual Interpretation in Neighborhood Noise Training. Electronics. 2023; 12(23):4751. https://doi.org/10.3390/electronics12234751
Chicago/Turabian StyleWang, Xingyu, Rui Ma, Jinyuan He, Taisi Zhang, Xiajing Wang, and Jingfeng Xue. 2023. "INNT: Restricting Activation Distance to Enhance Consistency of Visual Interpretation in Neighborhood Noise Training" Electronics 12, no. 23: 4751. https://doi.org/10.3390/electronics12234751