This section outlines the comprehensive methodology used in our study.
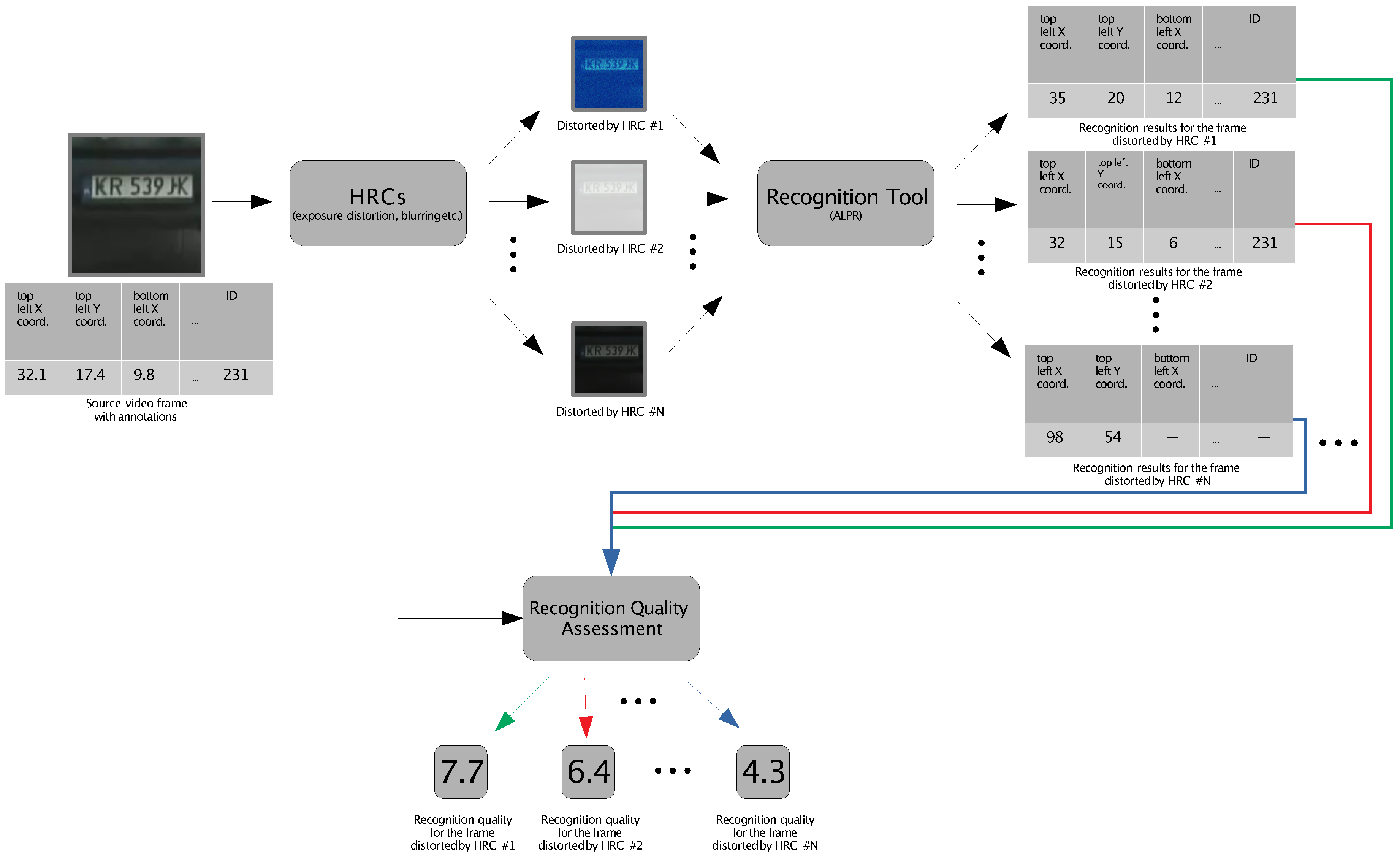
Figure 1 illustrates the general methodology flow chart, which encapsulates the core components of our research approach. Our experimental framework integrates a foundational dataset (denoted the Source Reference Circuits, SRCs,
Section 2.1) and a variety of visual impairments (termed Hypothetical Reference Circuits, HRCs,
Section 2.2). Each HRC imposes a specific type of degradation on an SRC. The analysis of the output video sequences is conducted through a computer vision library for Automatic License Plate Recognition (ALPR,
Section 2.3), combined with a Video Quality Indicator (VQI,
Section 2.4).
2.1. Collection of Pre-Existing Source Reference Circuits (SRCs)
This subsection delineates the technical attributes of the chosen SRCs and the specially assembled dataset used in this investigation. The corpus consisting of pre-existing original SRC video sequences was utilized.
The SRC repository encompasses a variety of video frames chosen according to a criterion aimed at compiling a comprehensive database encompassing a diverse array of characteristics. The details of the dataset are explained in the following section.
Within the scope of our experimental framework, a subset of the entire SRC collection was used. The initial step in curating this subset involved determining its magnitude. To this end, preliminary experimental runs, potential subsequent training iterations, and a validation experiment for the model were envisaged. The validation set is substantial, comprising roughly a quarter of the volume of a single training session, while the initial and any potential second training phases are composed of an equivalent number of samples.
An additional premise adopted for the experimental design, grounded in pragmatic considerations, stipulates that the duration of an experimental iteration shall not exceed one week. This temporal constraint influences the scale of the training sets, considering that the size of the test sets is a quarter of that of the training sets.
At this juncture, it is imperative to recognize that the computation time for a single frame exerts a significant impact on the volume of frames incorporated into each experiment. This time frame encompasses the aggregate duration of image processing for both the quality experiment (
Section 2.4) and the recognition experiment (
Section 2.3). With an understanding of the mean time taken to conduct the quality experiment on an individual frame and the mean time for the recognition experiment on the same, we are able to approximate the quantity of frames that can be processed weekly or the total number of frames that can be accommodated in a single experimental cycle.
Furthermore, it is essential to clarify that the figure yielded by the aforementioned procedure pertains to the count of feasible Processed Video Sequence (PVS) frames, as opposed to the count of utilizable SRC frames. To ascertain the tally of employable SRC frames, we take the total number of viable PVS frames and divide it by the quantity of the stipulated HRCs. The aggregate of the HRCs, including the original SRC, is 65.
Progressing to particular details, it has been ascertained that the average duration for processing a singular image in the quality experiment is within the magnitude of hundreds of seconds. In contrast, the average time taken to process an image in the recognition experiment is less than a second, which renders it comparatively negligible.
In light of the previously stated considerations, within a weekly time frame, it is feasible to process PVS images derived from 120 distinct SRC images. This allocation permits the arrangement of 80 SRC images for the initial training experiment, with an additional set of 20 SRC images (a quarter of the training set) for the testing phase and a further 20 SRC images (another quarter) for validation purposes. Each SRC image features a singular discernible entity (a vehicle’s license plate), culminating in a total of 120 individual entities.
As delineated earlier, a validation set of equivalent size to the test set has been assembled but is currently not processed.
Subsequent segments of this subsection elaborate on the complete collection (
Section 2.1.1) and the specific selection utilized for the experiment (
Section 2.1.2).
2.1.1. The Automatic License Plate Recognition Data Collection
The ALPR dataset examined was curated from CCTV footage. The video sequences of the source reference circuit (SRC) were recorded at the AGH University of Krakow, Lesser Poland, focusing on high traffic parking areas during peak hours [
2]. The compiled dataset encompasses approximately 15,500 frames in total.
Ground Truth Annotation
Ground truth coordinates were prepared to facilitate the assessment of Automatic License Plate Recognition. For each video in the dataset, a corresponding text file containing ground truth information was created. These annotations were compiled in July 2019. The text file adheres to the following naming convention:
video_name_anno.txt
Each of these files lists the coordinates specifying the location of the license plate in individual frames.
Coordinate Significance
The coordinates designate the following points on the license plate:
: Top-left corner of the license plate;
: Top-right corner of the license plate;
: Bottom-right corner of the license plate;
: Bottom-left corner of the license plate.
Special Cases
In cases where the license plate is fully occluded, all coordinates are annotated as zero. For example,
50.jpg 0 0 0 0 0 0 0 0
For partially occluded license plates, only the visible portions are annotated in the ground truth file.
2.1.2. The ALPR Subset
A subset is derived from the full assembly, allocating 120 images in a training, testing, and validation array in ratios of 80, 20, and 20, respectively. A compilation of the SRC images chosen for ALPR is depicted in
Figure 3.
Please refer to the
Appendix A for the complete list.
2.2. Making Hypothetical Reference Circuits (HRC)
This section addresses the various degradation scenarios, termed Hypothetical Reference Circuits (HRCs). The proposed array of HRCs encompasses a variety of impairments throughout the digital image acquisition process. The choice of HRCs is pivotal as it influences the applicability of the quality assessment methodology suggested here.
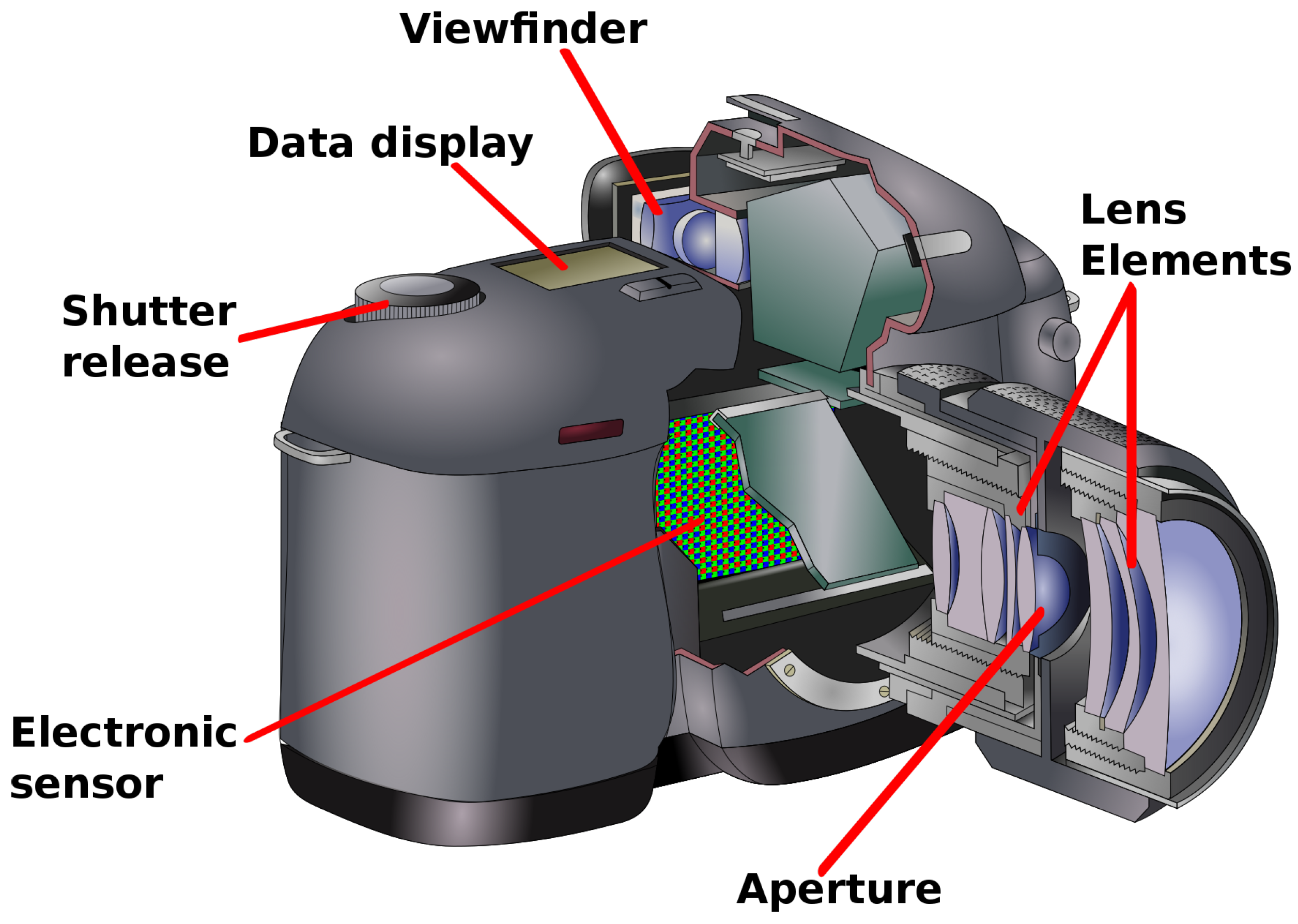
Currently, HRC selection utilizes two distinct types of camera model: a model of a digital single-lens reflex camera and a basic pinhole camera model. The latter is especially relevant to ALPR applications, as the detailed features of more elaborate camera models do not necessarily enhance the recognition task. The single lens reflex digital camera model is shown in
Figure 4, while the pinhole camera model schematic is shown in
Figure 5.
The operation of a digital camera is characterized by the manner in which light reflection from a subject is transformed into a digital image. Insufficient exposure to ambient light can attenuate the light before it reaches the lens system. Should the lens elements be misaligned, a blurred effect, known as defocus aberration, may ensue. Subsequently, the light interacts with an electronic sensor, the resolution of which is finite, potentially introducing Gaussian noise during analogue-to-digital conversion and subsequent signal amplification. Moreover, a prolonged exposure time can result in motion blur, while compression algorithms like JPEG may introduce artifacts in the final rendering of the digital image.
For the pinhole camera model, image formation is simplified; it assumes a single point where light rays pass through to form an image on an imaging surface. This model eliminates lens-induced aberrations, such as defocus and distortions. The simplicity of the pinhole camera model allows us to isolate other variables, such as exposure, motion blur, and sensor noise, in our quality assessment framework. The versatility of the pinhole camera model lies in its simplicity, which proves to be highly suitable for ALPR scenarios where diverse environmental factors, including fluctuating light conditions and varying distances from the camera to the license plate, can impact the quality of the captured image.
With this dual-model approach, we aim to offer a more comprehensive understanding of how different camera models can affect the quality and utility of TRVs in ALPR systems.
By incorporating the pinhole camera model into our HRC set, we aim to provide a more tailored approach to the evaluation of the video quality in ALPR applications. This modification aligns our work more closely with the practical needs of the ALPR community, which often employs simpler camera models because of their versatility and effectiveness across a wide range of conditions.
The distortion model is shown in
Figure 6.
We selected the following HRCs:
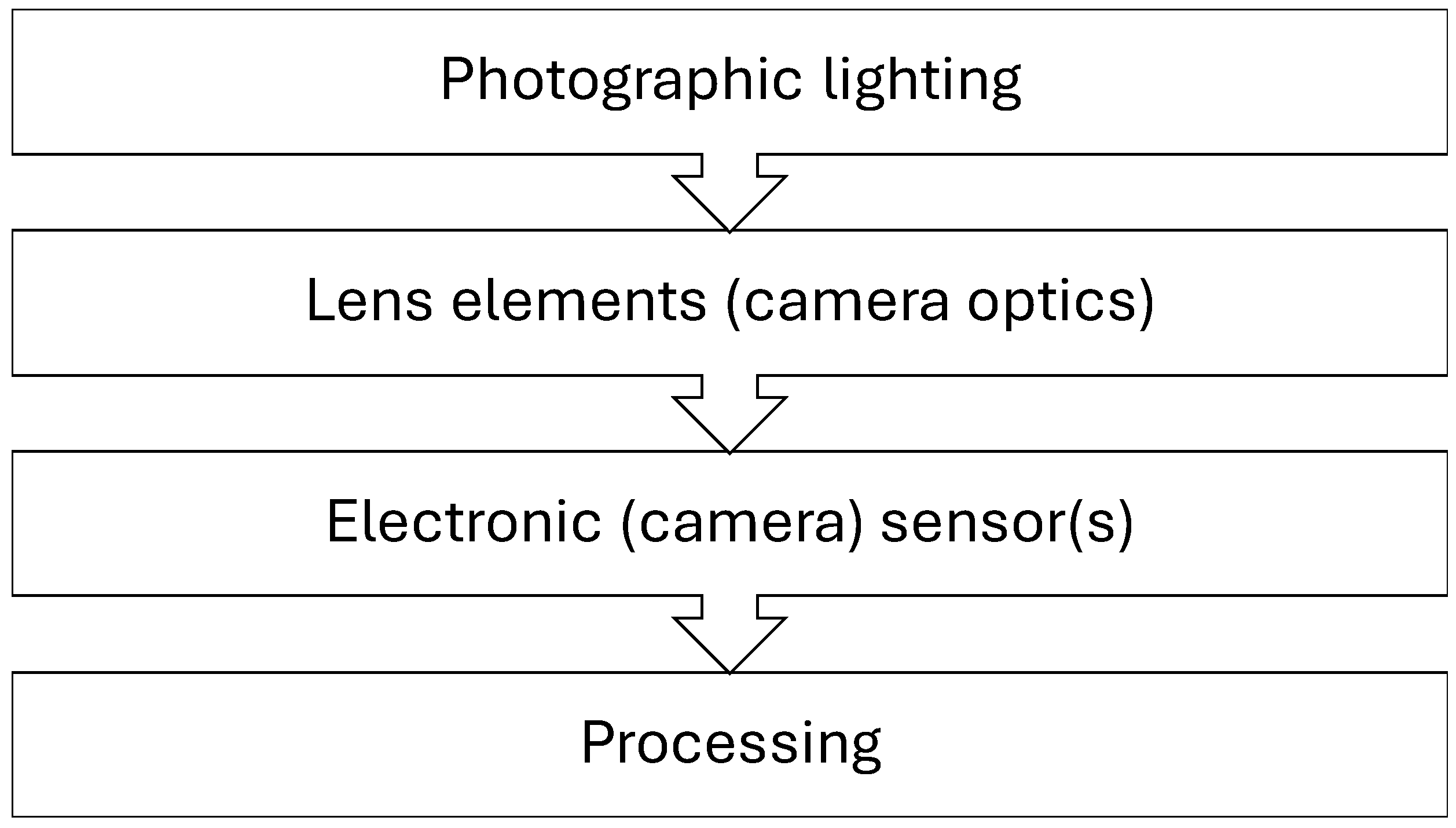
Photographic lighting HRC:
- 1.
Image under/overexposure
Camera optics lens elements HRC:
Electronic (camera) sensor(s) HRC:
- 3.
Gaussian noise
- 4.
Motion blur
Processing HRC:
2.2.1. Overview
The selection was made to utilize HRCs by incorporating tools from the resources [
14,
15], namely FFmpeg and ImageMagick, which offer a comprehensive suite of relevant filters. These tools facilitate the generation of the various distortions required; FFmpeg is utilized for the application of Gaussian noise and the adjustment of exposure levels, while ImageMagick is deployed for JPEG compression, motion blur simulation, and defocus effect creation.
Under the most demanding conditions, which involve enabling all available filters, the processing capability of the tool reaches a rate of 439 frames per minute. This performance benchmark was established through tests conducted on a conventional laptop equipped with an Intel i5 3317U processor and 16 GB of RAM.
Table 1 presents the established thresholds for various types of distortion, which are itemized in the rows of the table. These thresholds are typically derived to pinpoint the HRC value at which recognition ceases to occur; this identification represents the next-to-last stage, with an additional margin incorporated for precautionary reasons. The sequence of determination is direct and methodical.
Table 2 outlines the specific distortions and provides an approximation of the number of intensity levels for each type of distortion. It is noted that most distortions are categorized into six intensity levels. Exceptions include JPEG compression and exposure alterations, which require the number of levels to be doubled to account for their bidirectional impacts. Moreover, when distortions are combined (as shown in the last three rows, each corresponding to a distinct subsection), only five levels are delineated, because the most severe levels are already captured in the creation of individual distortions (referenced in the preceding subsections of the table).
The order of distortion application is pivotal when employing multiple distortions:
For the combination of motion blur and Gaussian noise, motion blur is applied initially;
In the case of over-exposure combined with Gaussian noise, over-exposure precedes;
For the under-exposure and motion blur combination, motion blur takes precedence due to technical constraints related to potential interpolation issues, despite under-exposure ideally being first.
Additionally, it is essential to include the scenario of “without distortion” (pristine SRC) within our distortion range. In total, this results in 64 HRC options (plus one unaltered SRC).
With the SRC selection finalized and the HRCs established, we can proceed to the actual video processing. This leads to the generation of a collection of processed video sequences, or PVSs, which are SRC frames affected by the HRC scenarios. The PVS corpus represents the anticipated result for this process.
The following is a detailed explanation of distortions and their applications. Our detailed description of the algorithms and configurations aims to add rigor and reproducibility to our methodology.
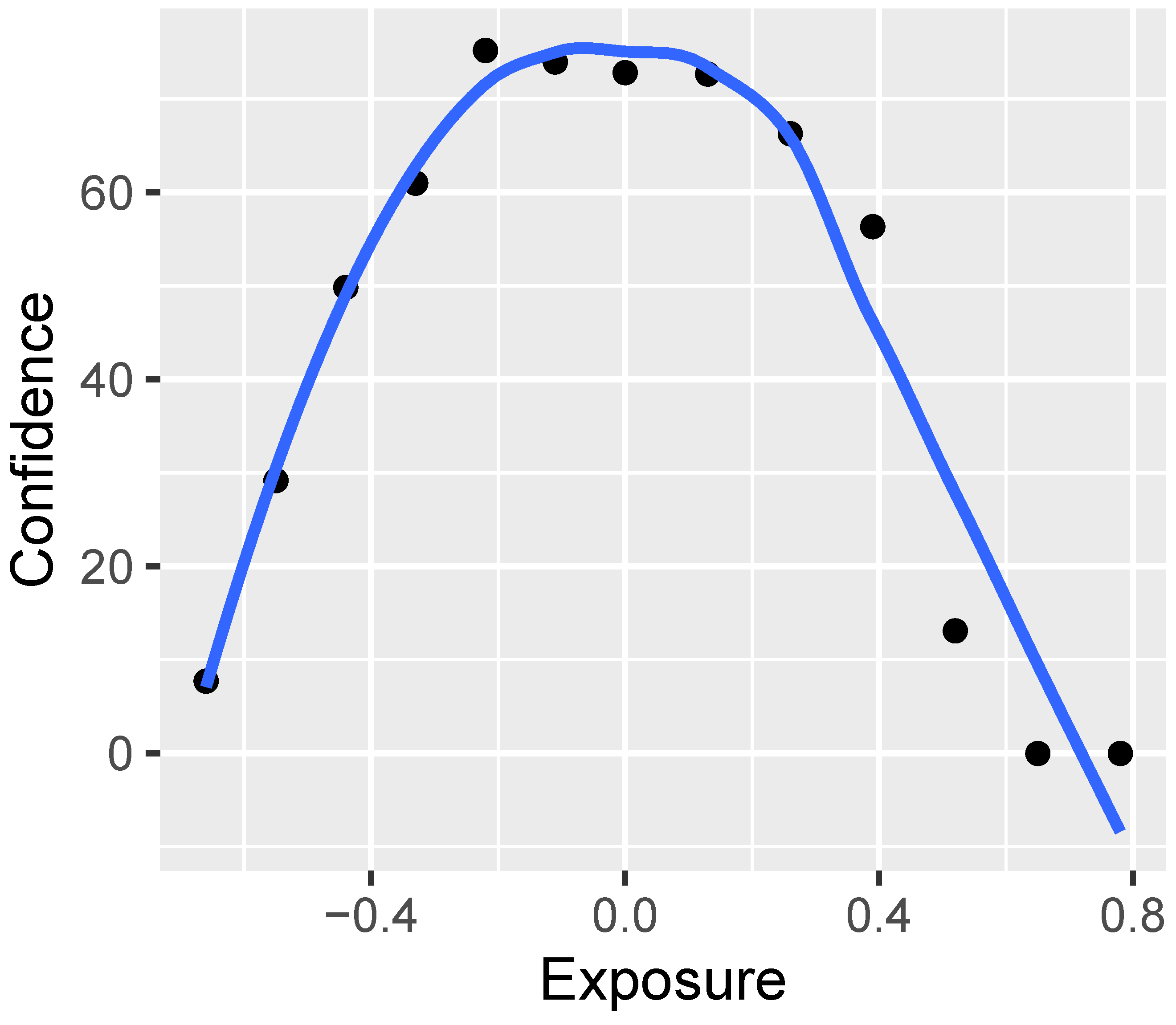
2.2.2. Exposure (Photography)
In the realm of photography, the term “exposure” delineates the quantum of light that reaches light-responsive substrates such as photographic film or digital sensors, playing an indispensable role in image capture. The exposure quotient is a composite function of the shutter velocity, the lens aperture scale, and the ISO sensitivity. Typically quantified in segments of seconds, exposure governs the duration that the aperture stays agape. An overabundance of light leads to overexposure, whereas a paucity thereof results in under-exposure [
16].
In creating our HRC set, we utilized the FFmpeg library’s “eq” (equalizer) filter to adjust attributes such as exposure. The “eq” filter operates through pixel-level transformations that alter the brightness and contrast levels. It is mathematically defined as , where contrast and brightness are user-defined parameters.
The “eq” filter also supports adjustments to the saturation and gamma levels. Standard image processing techniques are generally applied. Saturation is adjusted using linear transformations in the color space, whereas gamma adjustments are made through a power-law function applied to intensity values.
Excess exposure makes vehicle registration plates appear white and unreadable, while insufficient exposure leads to dark patches within the image. Details in over-exposed or under-exposed areas are irrecoverable.
Through intentional over-exposure and under-exposure, the FFmpeg filter allows for a wide range of exposure adjustments. This facilitates the creation of HRCs to evaluate the performance of ALPR systems. Extreme exposure settings make the automobile registration plate unrecognizable to the human eye, ensuring that the HRC spans the full visible range.
2.2.3. Defocus
Defocus is a form of distortion that occurs when an image is not properly focused. This aberration affects various devices equipped with lenses, such as cameras, telescopes, or microscopes. Defocus diminishes image contrast and object sharpness, making well-defined, high-contrast edges appear blurry and eventually unidentifiable. On the contrary, excessive sharpening results in a noticeable grainy effect [
17].
In our research, we used ImageMagick’s “blur” algorithm to introduce image distortions. The blur algorithm generally employs a Gaussian blur, characterized by a Gaussian distribution. It involves convolution with a Gaussian kernel, specified by two parameters: radius and standard deviation (). The Gaussian function is mathematically represented as .
ImageMagick offers fine-tuning through various command-line options. For example, the “-channel” option applies blur to specific color channels, while “-motion-blur” introduces directional blur to simulate motion. Motion blur in ImageMagick uses a linear combination of pixels along a trajectory to mimic object movement.
In this context, the sigma value serves as an estimate for pixel “dispersion” or blurring. According to the documentation, it is advisable to keep the radius parameter as small as possible.
ImageMagick enables accurate defocus degradation, allowing for precise adjustments. Even a slight change in the sigma parameter can make the vehicle registration plate unrecognizable. Consequently, in the generation of PVSs, it is imperative to administer the distortion at a level that precludes precipitous deterioration of the original material.
2.2.4. Gaussian Noise
Gaussian noise, recognized as statistical noise, exhibits a probability density function that conforms to a Gaussian distribution. Noise levels themselves follow a Gaussian distribution [
18].
Cameras typically include an automated denoising algorithm. Our aim is not arbitrary noise introduction but rather realistic noise simulation. We add noise using FFmpeg’s “noise” filter and subsequently apply denoising.
For denoising, we employ FFmpeg’s “bm3d” filter, which uses the Block Matching and 3D Filtering (BM3D) algorithm. This technique uses the high level of redundancy in natural video to remove noise while preserving detail. The algorithm involves a two-step process: block matching and collaborative filtering. In our setup, the denoising strength () is set to be equal to the added noise level, but it can be fine-tuned.
A higher noise value leads to significant visual distortions, complicating license plate recognition.
2.2.5. Motion Blur
Motion blur appears as a motion streak and is only visible in sequences that feature moving objects. It occurs when the object being recorded changes position during shooting. The appearance of blurred motion can be attributed to a combination of the fast movement of objects and prolonged exposure [
19].
Although FFmpeg does not provide a standalone motion blur filter, it offers filters such as “minterpolate” and “tblend” that can be configured to simulate motion blur. The “minterpolate” filter is based on motion estimation and frame interpolation algorithms, and “tblend” uses frame blending techniques. Although the specifics may vary depending on the filter configuration, these are general principles.
To simulate motion blur, we used ImageMagick’s radial blur function. This function is designed to simulate motion by convolving the image along a specific angle defined by the user, creating the appearance of a radial motion.
The function takes an angle parameter, which enables us to simulate different rotational speeds. A lower angle simulates slower rotation, while a higher angle indicates faster spin.
Among the various degradations, motion blur is often considered the most challenging. ImageMagick filters are our recommended solution to achieve optimal results when simulating motion blur degradation. For further information, see ImageMagick documentation at
http://www.imagemagick.org/Usage/blur/#radial-blur (accessed on 14 November 2023).
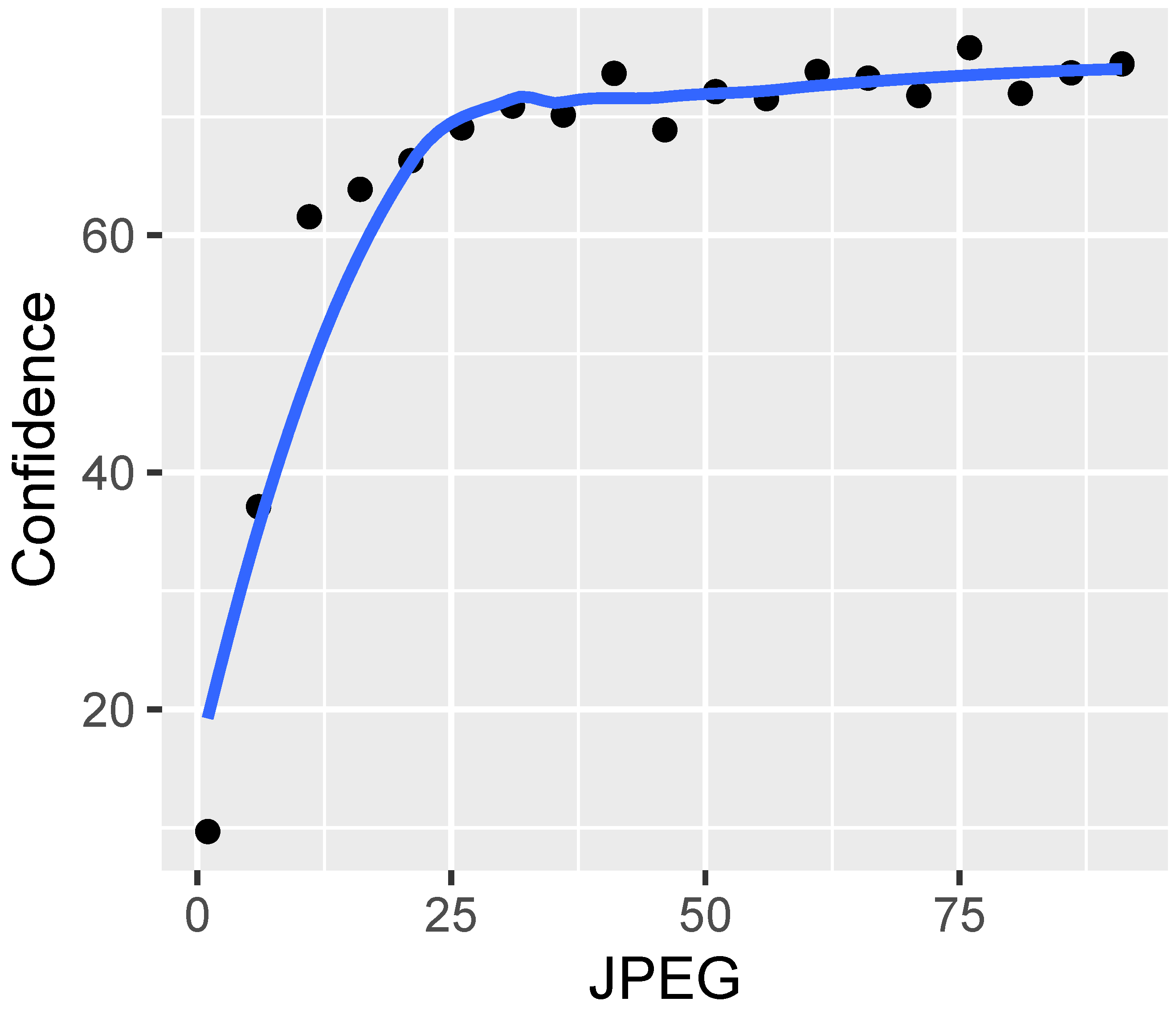
2.2.6. JPEG
The JPEG standard is commonly used for image compression and is a popular digital format. It plays a pivotal role in the creation of billions of JPEG images each day, especially in digital photography [
20].
We employ ImageMagick to compress the images to JPEG format, specifying the compression quality parameter using values ranging from 1 to 100: the lower the value, the higher the compression, and vice versa.
Lossy JPEG compression can cause recognizable artifacts, such as pixelation and a loss of fine details. In the case of license plates, higher compression ratios may render characters indistinct, complicating ALPR.
To optimize our methodology, we use the quality parameter to strike a balance between size and quality. The goal is to ensure that the compressed image retains enough quality to be useful for the evaluation of the ALPR system.
2.4. Quality Experiment
This section elaborates on the quality experiment, aimed at evaluating various Video Quality Indicators (VQIs) for their effectiveness and computational efficiency. The purpose of the experiment is to identify which VQIs are most suited for real-time video quality assessment. The first subsection (
Section 2.4.1) gives a broad overview, while the next subsection (
Section 2.4.2) provides specific information on the VQIs employed. Subsequent discussion in Subsection (
Section 2.4.3) covers the execution time of VQIs. The final subsection (
Section 2.4.4) includes examples of reference data.
2.4.1. Quality Experiment Overview
The procedure of the experiment encompasses the following steps:
Each video is broken down into individual frames;
A set of 19 VQIs is applied to each frame;
Execution times are recorded;
Quality metrics are stored as a vector of results.
Objective: The main objective is to compare the efficiencies of different VQIs to assess the video quality.
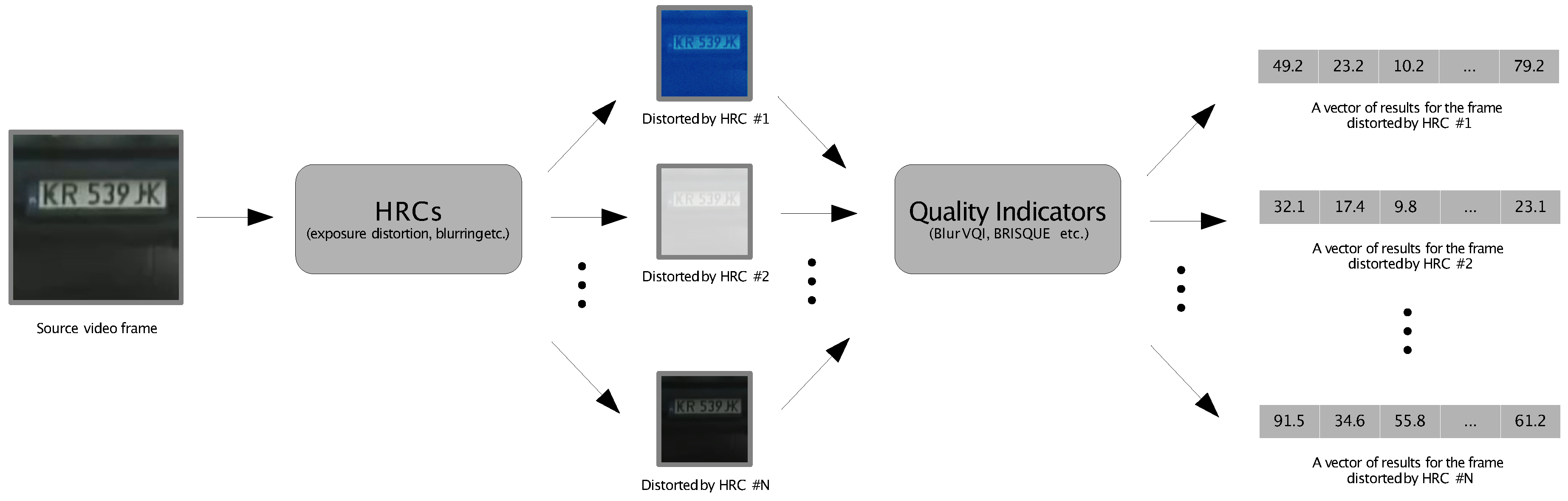
This experiment concentrates on single video frames, barring the Temporal Activity (TA) Video Quality Indicator (VQI). The application of a set of VQIs yields a vector of outcomes, with each VQI generating a distinct result. A detailed workflow is illustrated in
Figure 16, adapted from Leszczuk et al. [
2]. These findings are merged with those from the recognition test to produce input data for modeling.
The choice of programming language varies depending on the specific Video Quality Indicator (VQI) being utilized. For some VQIs, we employ C/C++ code, while for others, MATLAB code is used.
In order to streamline the execution of the experiment, we encapsulate all necessary components within a Python script. This script is designed to receive a list of filenames as input, allowing us to process a sizable batch of video frames simultaneously.
The quality experiment is just one of several software modules used in our workflow. All of these modules are controlled by a central Python script, known as the “master script”. As a result, the script employed in this particular experiment can generate its results either in the form of a JSON file or as a Python return value. An example of a JSON output file is provided in Listing 2.
| Listing 2. An exemplary output JSON file, as produced by the Python script (performing the quality experiment). |
![Electronics 12 04721 i002]() |
2.4.2. Indicators
We selected a total of 19 VQIs based on their potential effectiveness and computational requirements.
Our AGH Video Quality (VQ) team provided eleven (11) of these VQIs (they can be downloaded from the link provided in Section “
Supplementary Materials”):
AGH:
Commercial Black: An indicator that measures the level of black coloration in commercial content;
Blockiness [
2,
21]: Refers to the visual artifacts caused by block-based coding schemes, often seen as grid-like structures in the image or video;
Block Loss [
22]: Measures the instances where data blocks are lost during transmission or encoding, leading to visual corruption;
Blur [
1,
2,
21]: Quantifies the loss of edge sharpness in an image or video, leading to a less clear representation;
Contrast: An indicator of the difference in luminance or color that makes objects in an image distinguishable;
Exposure [
2]: Evaluates the balance of light in a photo or video, indicating over-exposure or under-exposure;
Interlacing [
23]: Relates to the visual artifacts arising from interlaced scanning methods in video, usually observed as a flickering effect;
Noise [
23]: Measures the amount of random visual static in an image or video, often arising from sensor or transmission errors;
Slice [
22]: Assesses the impact of slice loss, which refers to the loss of a data segment that leads to noticeable visual errors;
Spatial Activity [
2,
21]: Measures the level of detail or texture in a still image or in each frame of a video;
Temporal Activity [
2,
21]: Gauges the rate of change between frames in a video, usually related to the amount of motion or action.
The remaining eight (8) VQIs are provided by external laboratories:
LIVE:
- 12.
BIQI [
24]: A Blind Image Quality Index that provides a quality score without referencing the original image;
- 13.
BRISQUE [
25]: The Blind/Reference-less Image Spatial Quality Evaluator, which aims to assess the quality of images without a reference image;
- 14.
NIQE [
26]: The Naturalness Image Quality Evaluator evaluates the perceptual quality of an image in a completely blind manner;
- 15.
OG-IQA [
27]: Object Geometric-Based Image Quality Assessment focuses on evaluating the image quality based on geometric distortions;
- 16.
FFRIQUEE [
28]: A Free-Energy-based Fractal Reference-less Image Quality Evaluator that operates without needing a reference image;
- 17.
IL-NIQE [
29]: The Information-theoretic Local Naturalness Image Quality Evaluator uses local image statistics for the quality assessment;
UMIACS:
- 18.
CORNIA [
30]: The Codebook Representation for No-Reference Image Assessment evaluates the quality of images using a learned codebook representation;
BUPT:
- 19.
HOSA [
31]: The Higher-Order Statistics Aggregation for Blind Image Quality Assessment employs higher-order statistics to evaluate image quality.
The selection of MATLAB or C/C++ code depends on the specific VQI being utilized. The rationale behind the selection and omission of certain VQIs is detailed in the supplementary material section.
Table 3 presents a comprehensive list of all employed VQIs, accompanied by their descriptions and relevant references. The indicators highlighted with an asterisk (*) may not directly correlate with the precise objectives of the investigation, but they are included due to their potential value during the modeling stage. Additionally, their inclusion does not significantly impact the computation time overhead. UMIACS and BUPT are the initials for the University of Maryland Institute for Advanced Computer Studies (Language and Media Processing Laboratory) and the Beijing University of Posts and Telecommunications (School of Information and Communication Engineering, respectively.
During the preparatory phase of the experiment, we decided to exclude two measures, specifically (i) DIIVINE [
32] and (ii) BLIINDS-II [
33]. The removal of these indicators was due to their high computational demands, with BLIINDS-II requiring around 3 min to assess a single image’s quality. This exclusion was essential to maintain the experiment’s relevance concerning the quantity of Source Reference Codes (SRCs) that could be evaluated. Put simply, including DIIVINE and BLIINDS-II would significantly increase the duration of the experiment, rendering the assessment of a considerable number of SRCs impractical.
DIIVINE was excluded from the experiment in favor of a more refined alternative. We predict that FFRIQUEE will perform at least as well as DIIVINE. This assumption stems from the fact that FRIQUEE is built on the basis of DIIVINE.
In contrast, there is no alternative indication for BLIINDS-II at the moment. We chose to remove it, because it does not have the potential to outperform others. Based on existing research [
34], we do not expect BLIINDS-II to be one of the best performing indicators.
2.4.3. VQI Execution Time
This subsection provides an empirical analysis of the time complexity of each VQI to help to determine the feasibility of a real-time assessment. As mentioned above, to determine the number of SRCs that can be tested, it is important to know the computational time required for all VQIs.
Table 4 presents a summary of the execution times for each VQI. It is important to note that these timings were recorded on a laptop featuring an Intel Core i7-3537U CPU.
2.4.4. Data as an Example
This section contains instances of collected data.
Finally, we present examples of the data to give a snapshot of the type of results that can be expected from this experiment. Various forms of distortion were applied to the video frames to simulate real-world conditions.
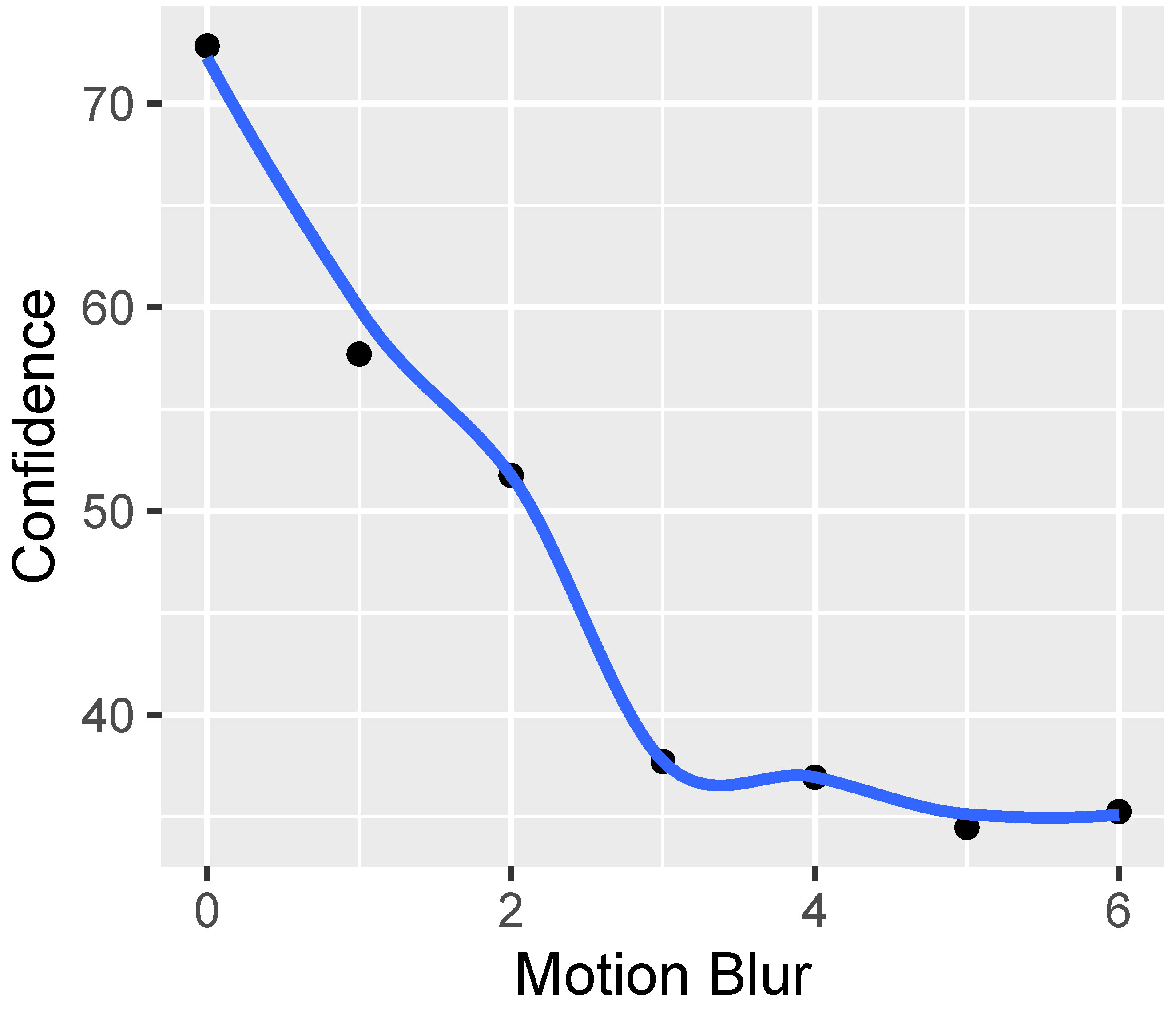
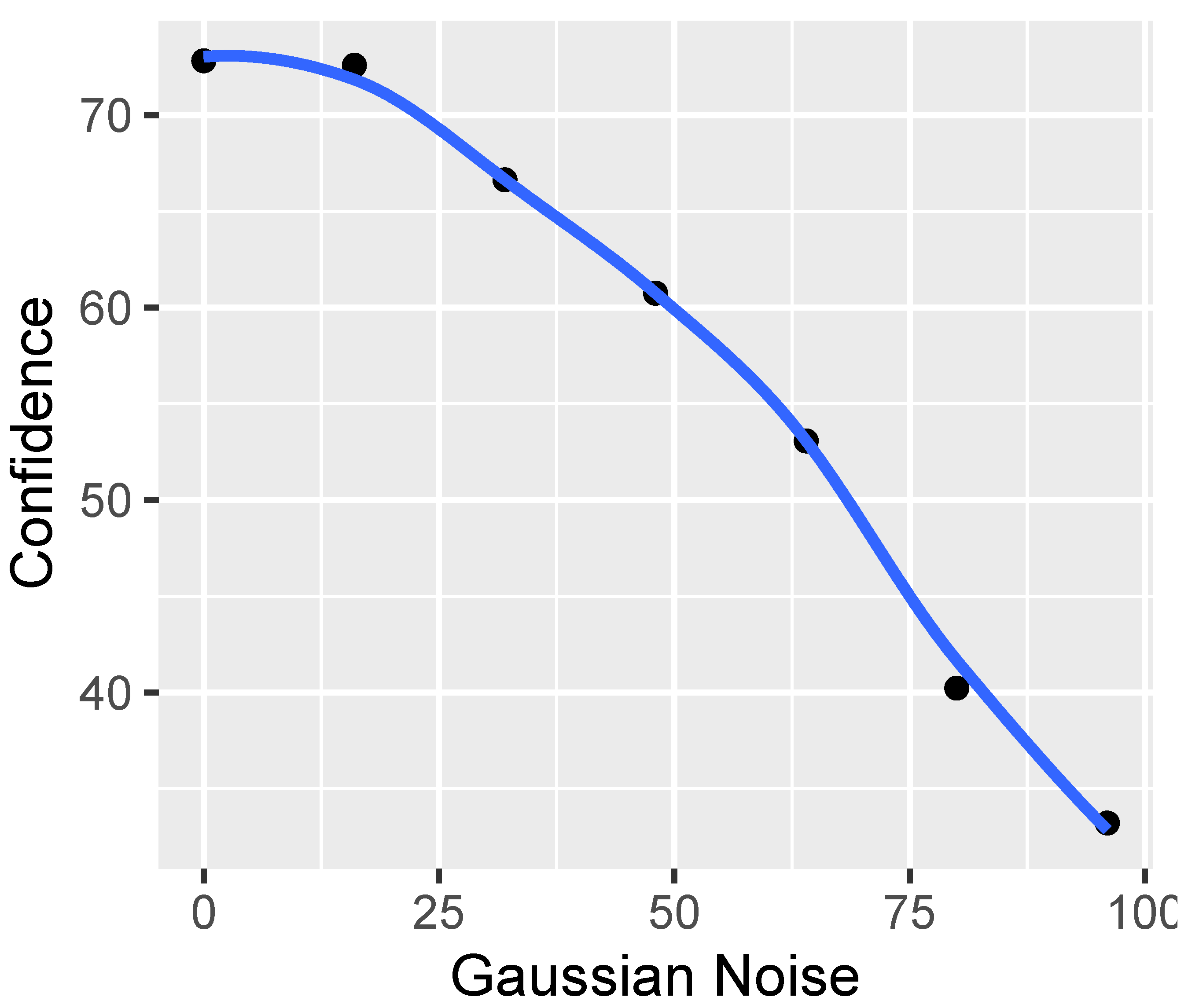
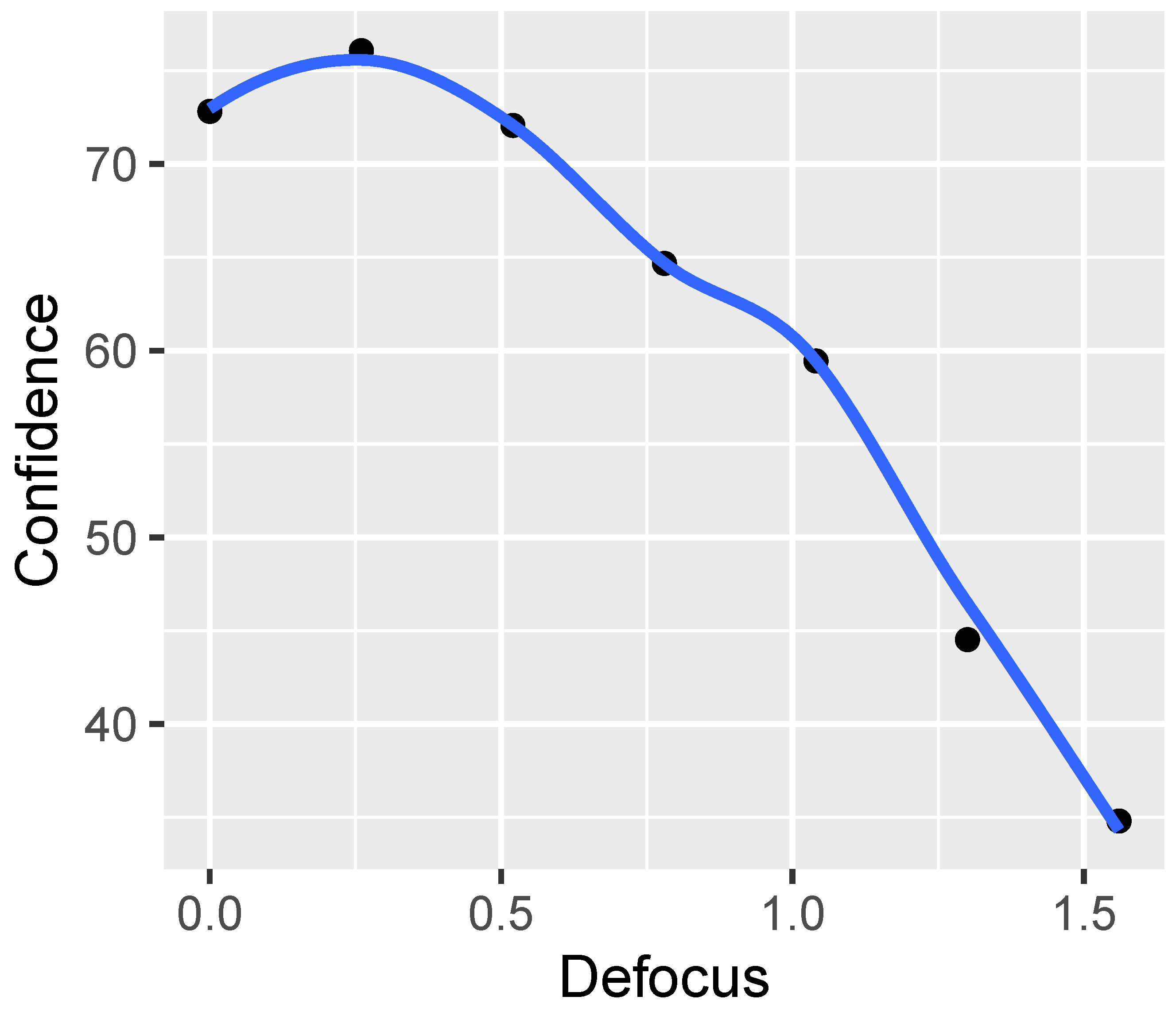
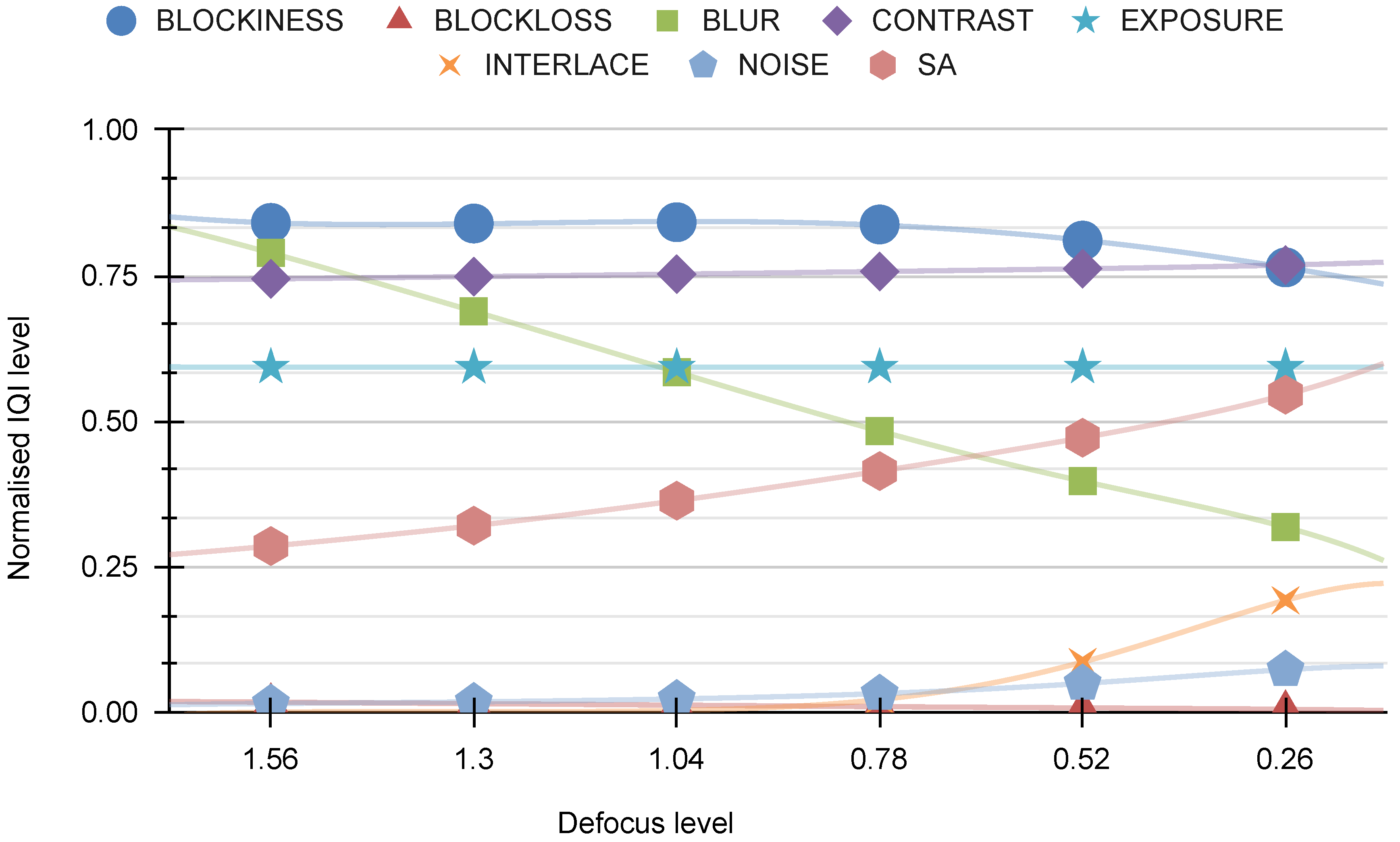
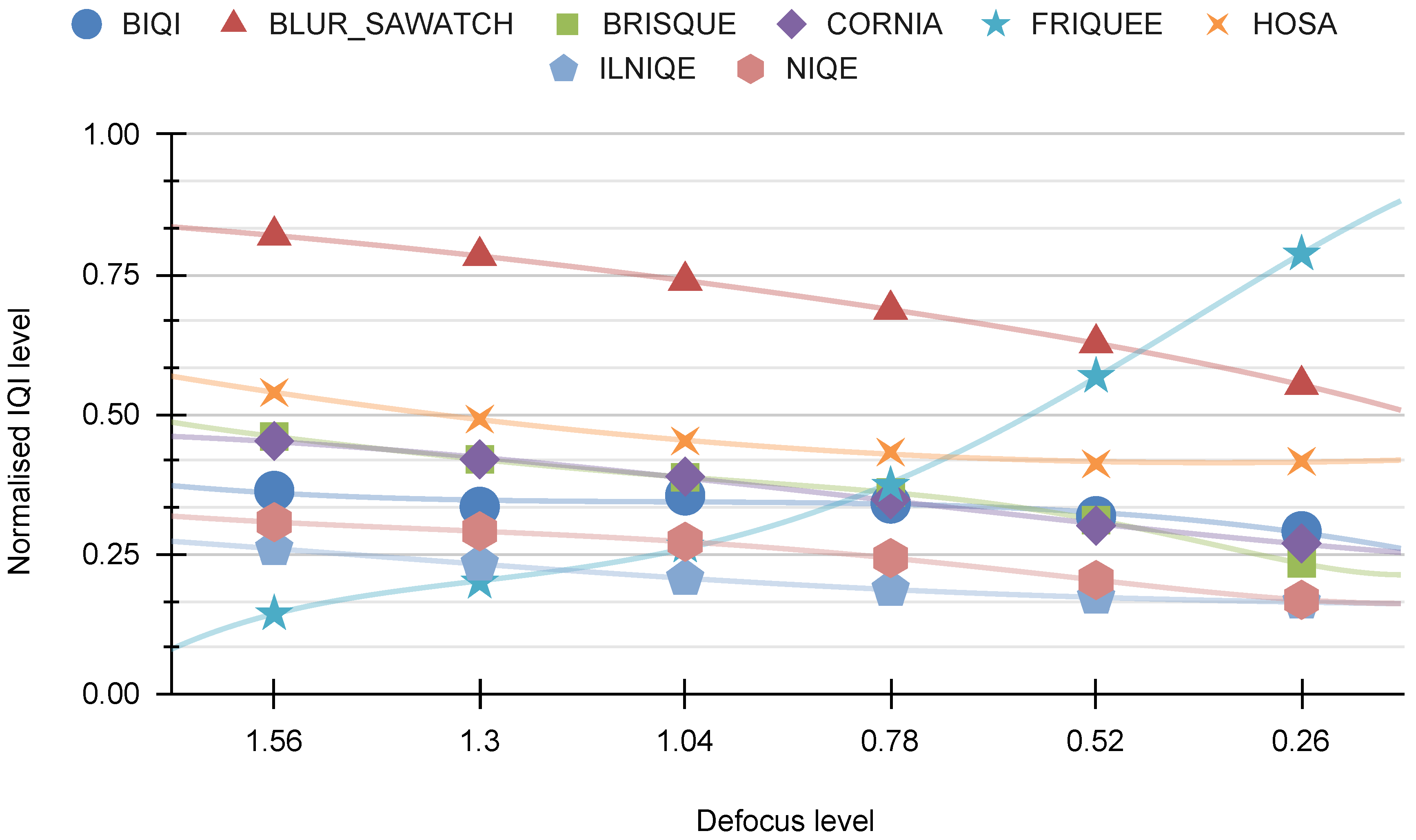
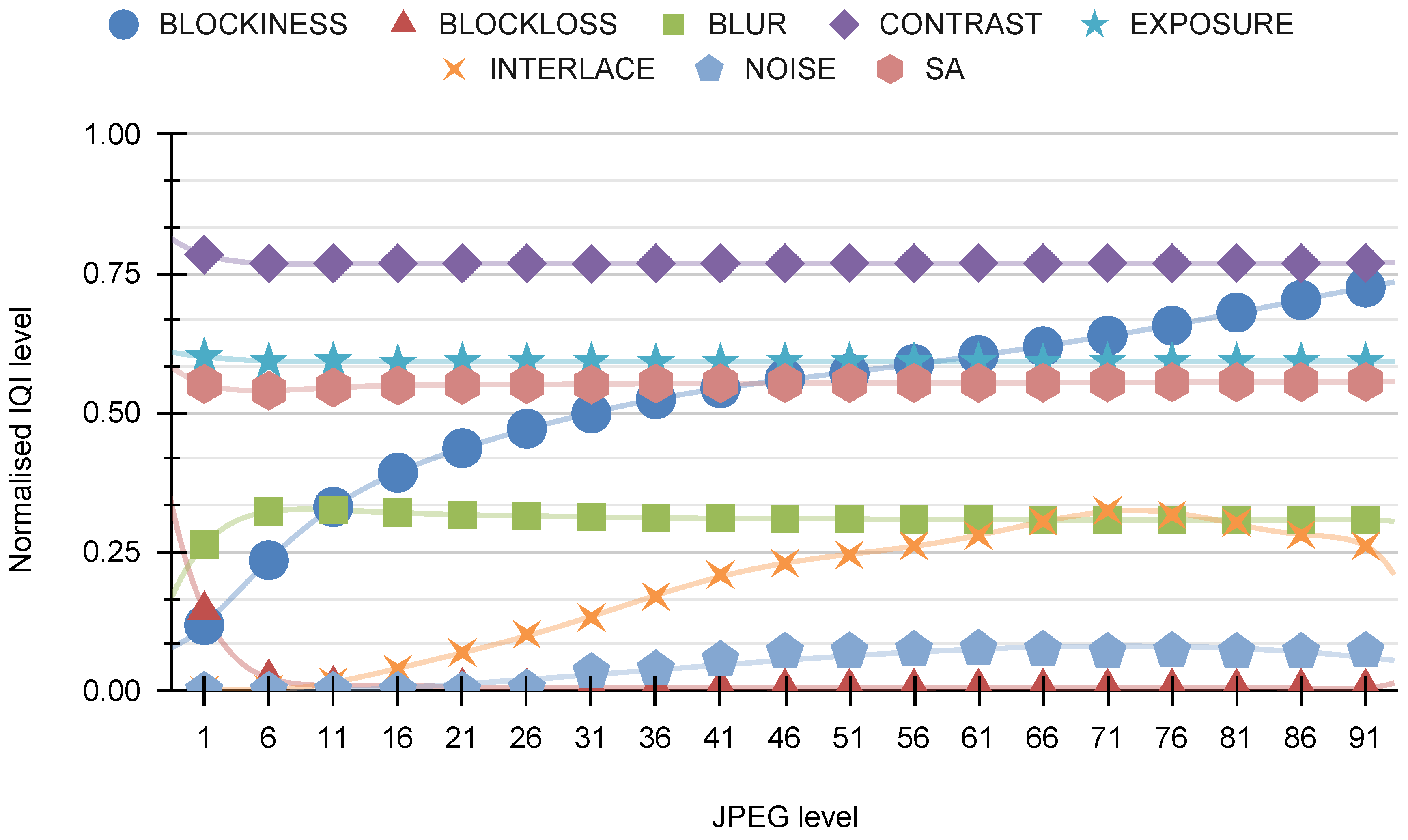
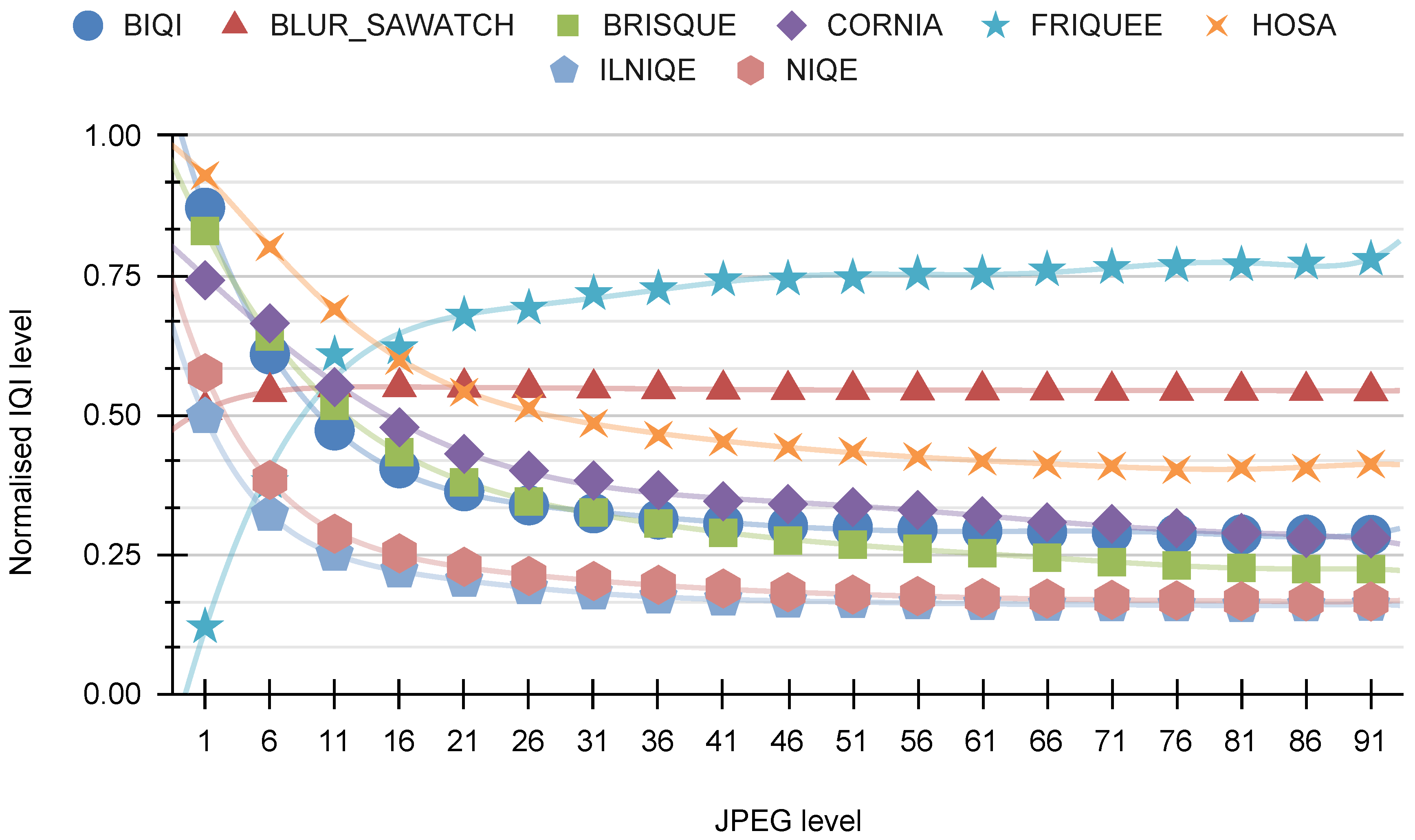
In the imaging process, we utilize four types of distortion (HRC): defocus, Gaussian noise, motion blur, and JPEG. For each HRC, two graphs are presented. The initial chart depicts eight representative visual indicators developed by our AGH team, including BLOCKINESS, BLOCK-LOSS, BLUR, CONTRAST, EXPOSURE, INTERLACE, NOISE, and SA. The subsequent graph illustrates eight visual indicators developed by various research groups: BIQI, BLUR-SAWATCH, CORNIA, FRIQUEE, HOSA, ILNIQE, and NIQE.
Figure 17 presents a comparative analysis of “our indicators” against defocus distortion. It is evident from the graph that this distortion significantly affects the BLUR indicator and has a somewhat lesser effect on the SA indicator.
The comparison between “other indications” and the defocus distortion is shown in
Figure 18. It is evident from the chart that this distortion notably impacts the FRIQUEE and, to a lesser degree, the NIQE indicators.
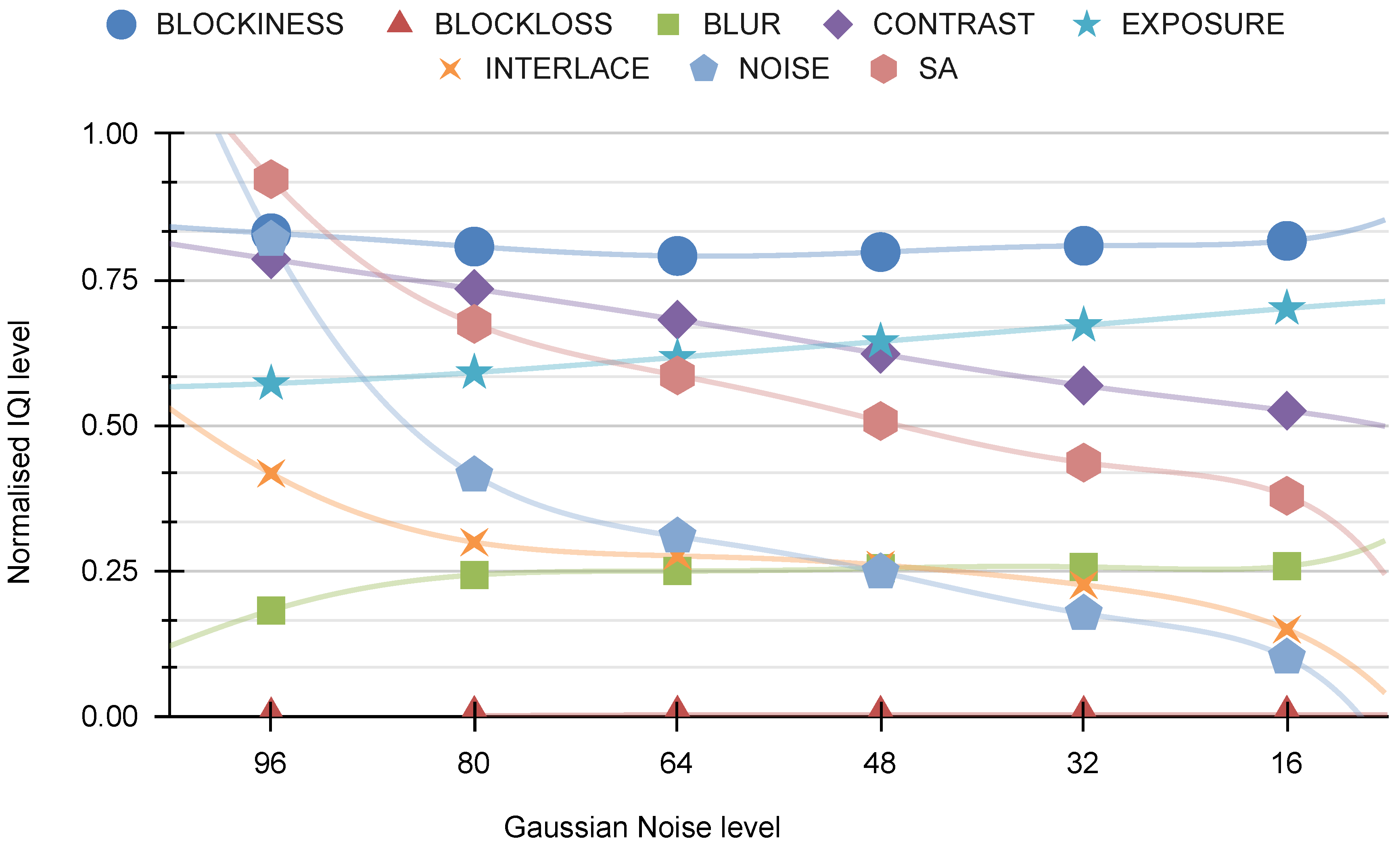
Figure 19 displays the correlation between “our indicators” and the Gaussian noise distortion. It is evident from the figure that this distortion primarily affects the NOISE indicator, with a minor impact on the SA indicator.
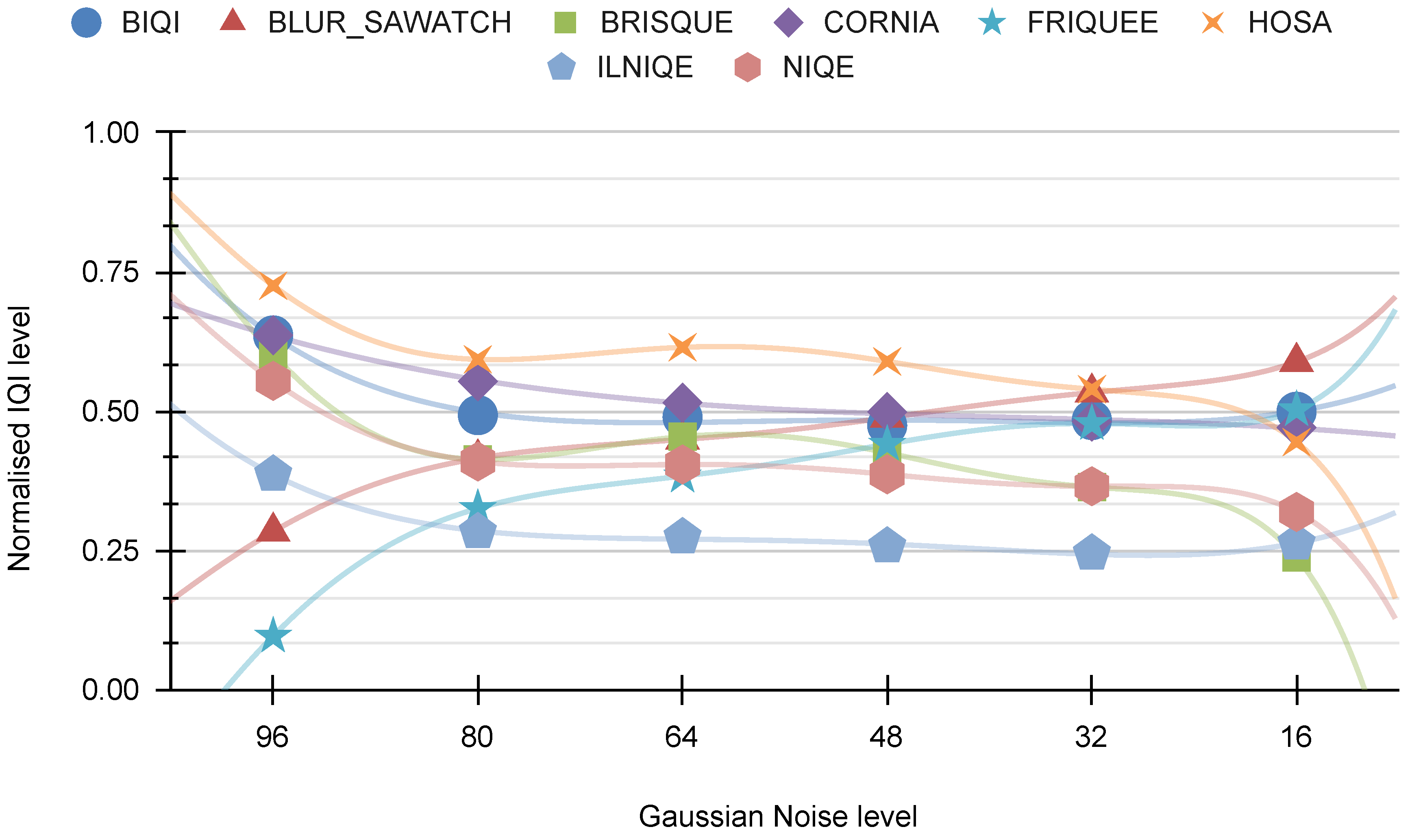
In
Figure 20, the relationship between “other indicators” and Gaussian noise is depicted. This distortion evidently affects the FRIQUEE and NIQE indicators, and, to a more moderate extent, the BRISQUE indicator.
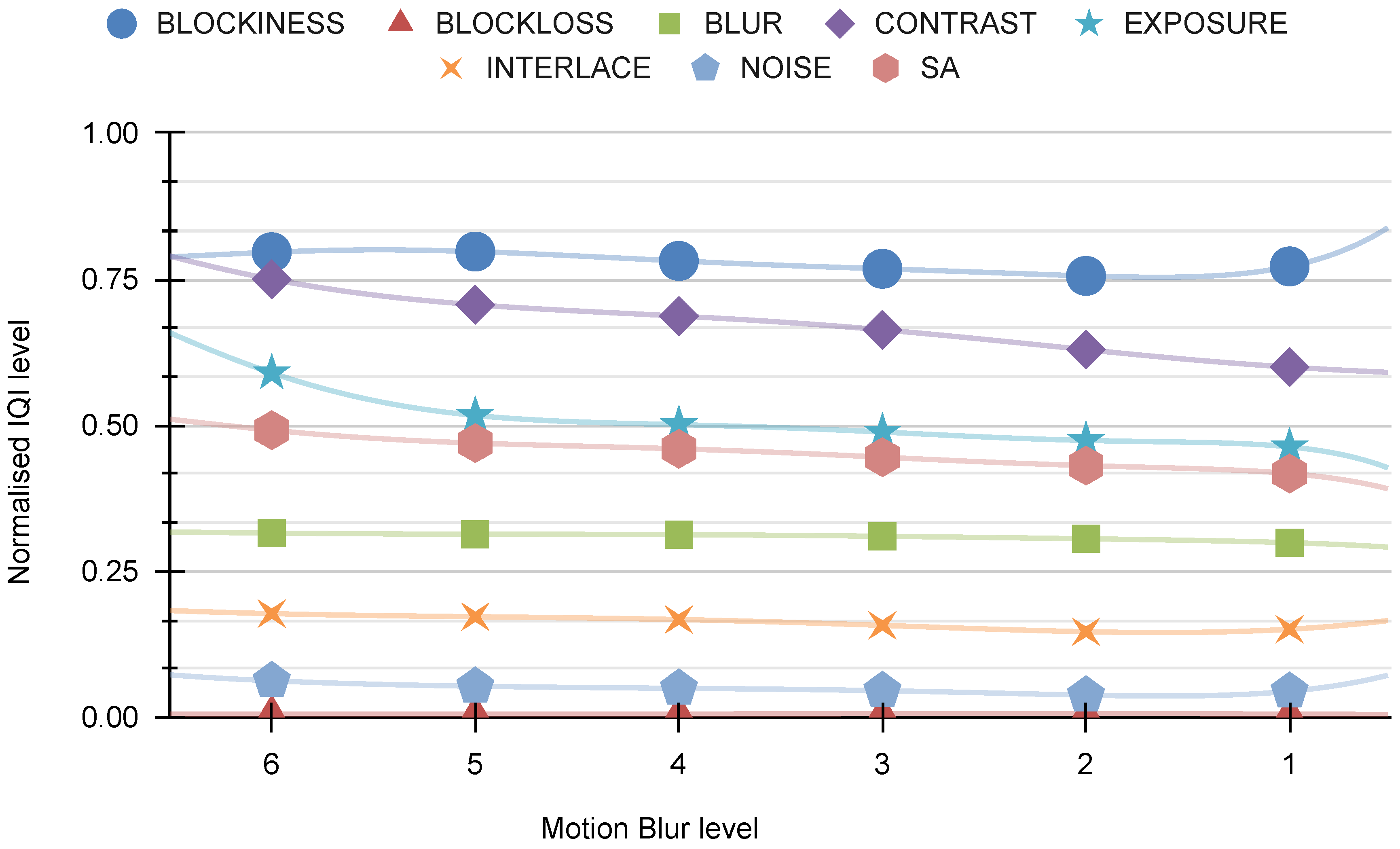
Figure 21 illustrates the relationship between “our indicators” and motion blur. It is discovered that this distortion has no discernible effect on any of the indicators.
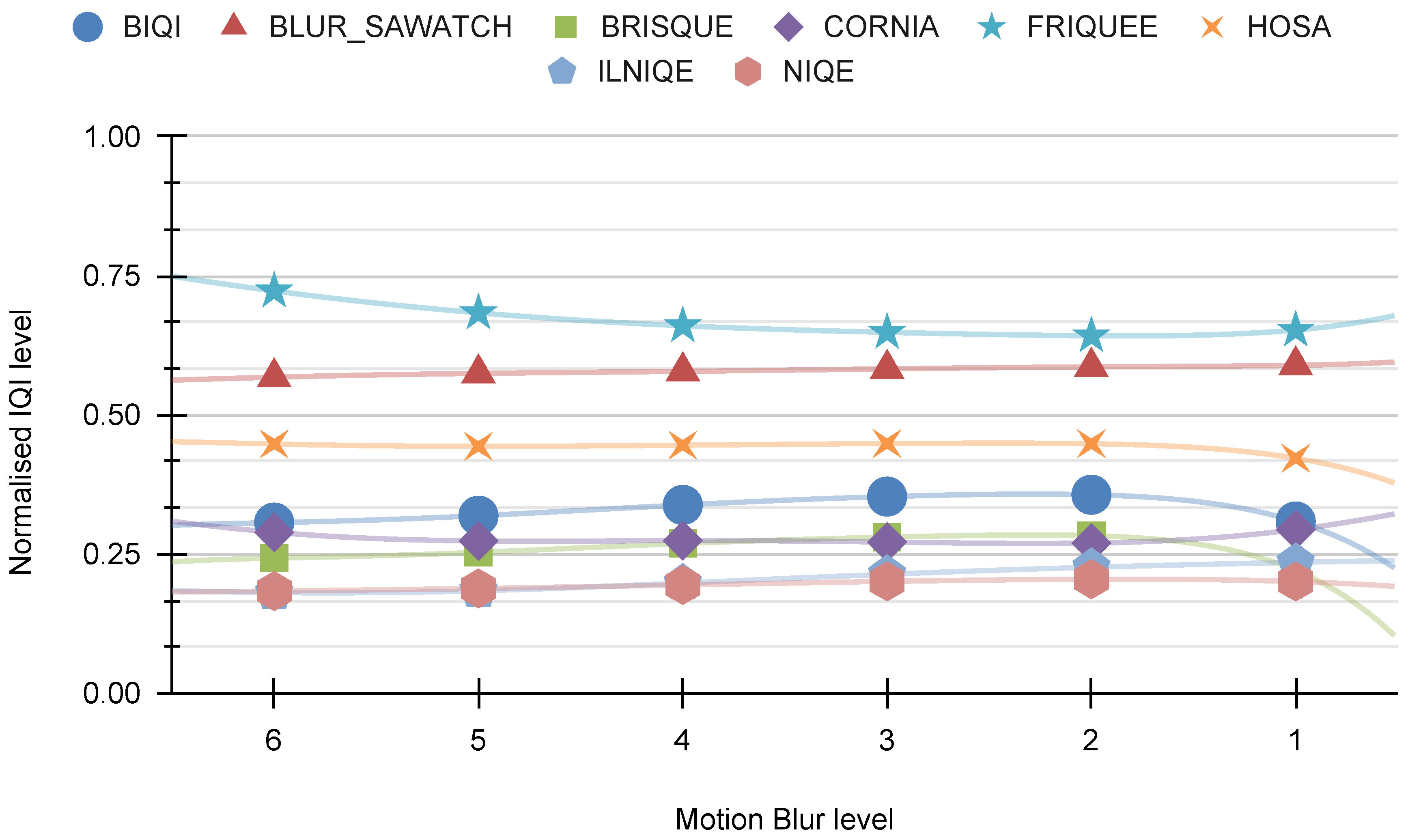
Figure 22 depicts the relationship between “other indicators” and motion blur. The analysis reveals that this distortion does not have any noticeable impacts on any of the indicators.
Figure 23 illustrates the correlation between “our indicators” and the distortion of the JPEG. It is evident that this distortion predominantly triggers a pronounced response in the BLOCKINESS indicator, which is expected, since this indicator is specifically designed for detecting JPEG artifacts.
Figure 24 shows the relationship between the “other indicators” and the JPEG distortion. This distortion clearly generates substantial responses from practically all indicators, particularly those in the lower range. However, the BLUR-SAWATCH indicator does not exhibit a strong response to JPEG distortion.

 ,
, 




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}