1. Introduction
Object detection is a computer vision and image-processing technique, widely used in many applications, such as face detection, video surveillance, image annotation, activity recognition, autonomous driving, quality inspection, etc. [
1]. Among several object-detection algorithms, the most-popular and fastest algorithm is the Single-shot Multibox Detector (SSD) algorithm [
2]. The SSD is used for detecting objects from a predefined set of detection classes in images and videos, by a single deep neural network. The main idea of the proposed object detector is to discretize the output space of the so-called bounding boxes into a set of default ones, using different scales and aspect ratios. During the inference, the SSD network outputs the probability that each detection class is detected within each of the default bounding boxes, but also outputs the coordinate adjustments with respect to the coordinates of the default boxes to better “match” the detected objects. By combining the predictions from feature maps of different resolutions, the proposed object detector leads to the accurate detection of both large and small objects from a detection class set. As shown in [
2], the SSD architecture is significantly faster than multi-stage object detectors, such as Faster R-CNN [
3], while having significantly better accuracy compared to other single-shot object detectors, such as Yolo [
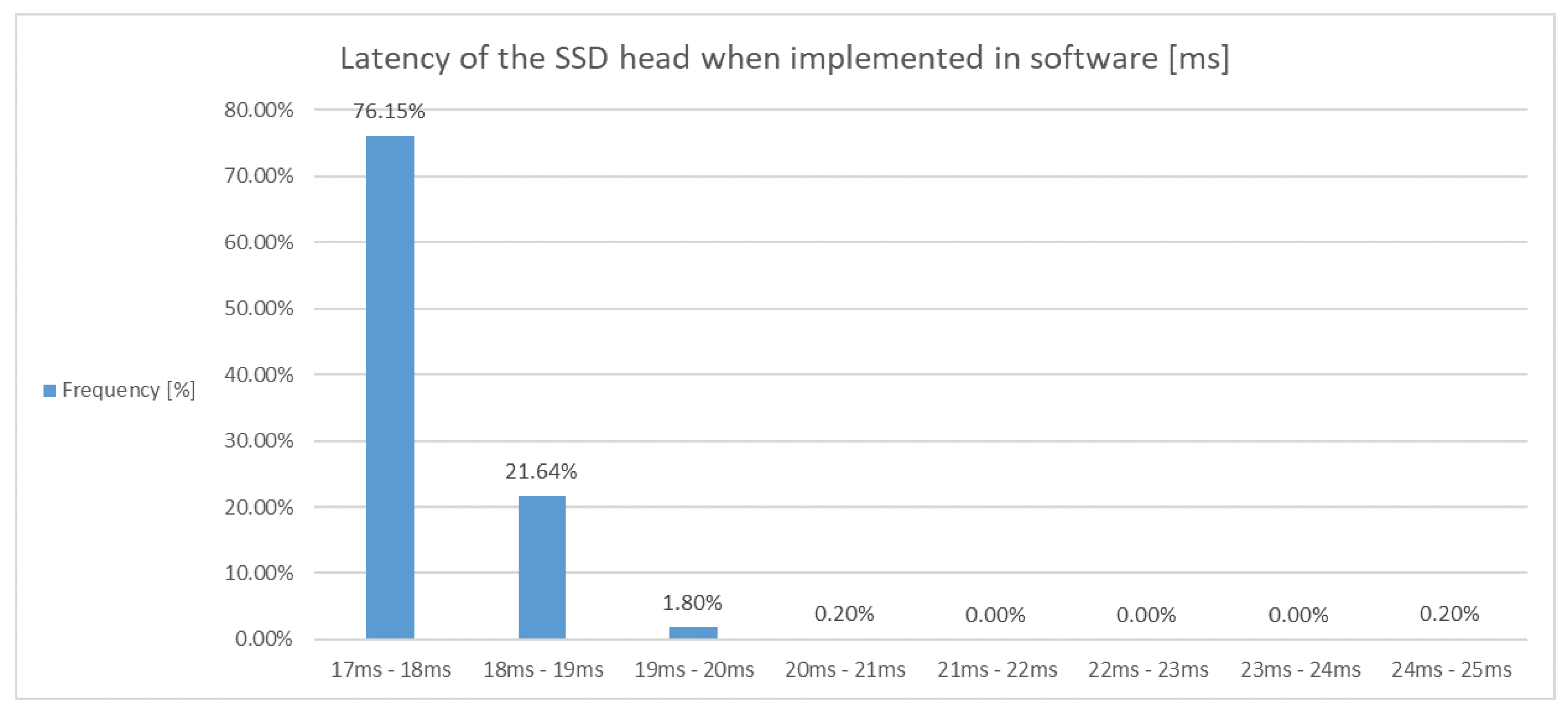
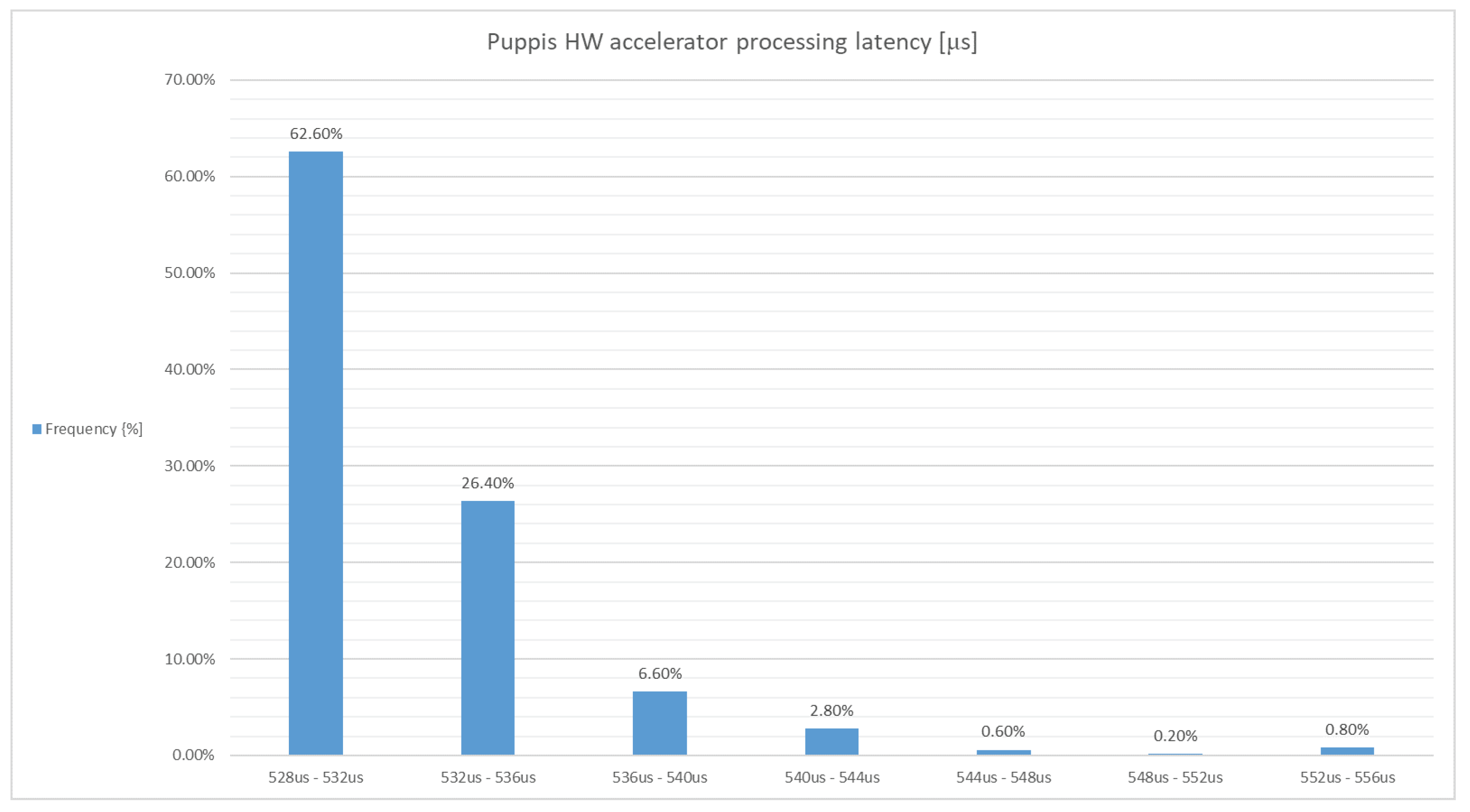
4]. Even though the SSD post-processing algorithm is not the most-complex segment of the overall object-detection network, it is very computationally demanding and can be a bottleneck with respect to the processing latency and power consumption, especially in edge applications with limited resources. Motivated by this, in this paper, we propose Puppis, an architecture for the SSD hardware accelerator, which reduces the duration of the software-implemented SSD post-processing by 97%, on average, as we show in the section presenting the experimental results.
Despite the evolution of the original object detectors [
5,
6,
7], deep networks for detecting objects based on the SSD are still among the most-widely used, while the scientific community has proposed many improvements to the original SSD algorithm during the years that have followed, besides the proposals for SSD algorithm speedup through GPU acceleration, as in [
8]. The authors in [
9] proposed a slightly slower, but more-accurate object detector based on an enhanced SSD with a feature fusion module, while the authors in [
10] additionally optimized their SSD-based network for small object detection. In [
11], the classification accuracy of the SSD architecture was improved by the introduction of an Inception block, which replaced the extra layers in the original SSD approach, as well as an improved non-maximum suppression method. An attention single-shot multibox detector was proposed in [
12], where irrelevant information within the feature maps was suppressed in favor of the useful feature map regions. There are also multiple real-time system proposals based on the single-shot multibox detector algorithm, where either modified convolutional layers are used, as in [
13], a complete backbone CNN is simplified, as in [
14], or a multistage bidirectional feature fusion network based on the single-shot multibox detector is used for object detection, as in [
15].
While there are numerous proposals for algorithmic improvements of the original SSD algorithm available, despite existing proposals for the hardware acceleration of other object detection architectures [
16,
17,
18,
19], there are not many proposals for the hardware acceleration of a single-shot multibox detector algorithm in the available literature. The authors are aware of only two previously published papers [
20,
21], who presented the acceleration of the convolutional blocks within the SSD network, without focusing on the SSD post-processing part of the network. In this paper, we propose a system for the hardware acceleration of a complete single-shot multibox detector algorithm and show how it can be integrated with a slightly modified backbone classifier (MobileNetV1) to obtain a fast and accurate object detector architecture, when implemented in an FPGA. When using hardware accelerators for the implementation of the backbone CNN in low-end, low-frame-rate applications, SSD post-processing implemented in software is acceptable since the introduced latency is significantly shorter than the latency of the backbone CNN processing. Hence, it can be either neglected or even hidden by pipelining to increase the throughput, even though the latency remains the same. Our work was motivated by the fact that SSD post-processing becomes a bottleneck for high-end applications where high frame rates are required. The results from the experimental section will show how our proposal resulted in an average SSD post-processing speedup greater than 33-times and an average complete CNN network processing speedup greater than 36-times, compared with the pure software implementation, when the MobileNetV1 SSD network was used for object detection. The rest of the paper is structured as follows: After the introductory section, in
Section 2, we elaborate on the general structure of the SSD network and the purpose of accelerating the SSD post-processing algorithm. In
Section 3, we show which algorithms from the SSD post-processing step are accelerated and how, while the accelerator architecture is presented in
Section 4. The experimental results are shown in
Section 5, while the conclusion is given in the last section.
2. Overview of Proposed System for Hardware Accelerator of Complete SSD Network
2.1. General Structure of SSD Network
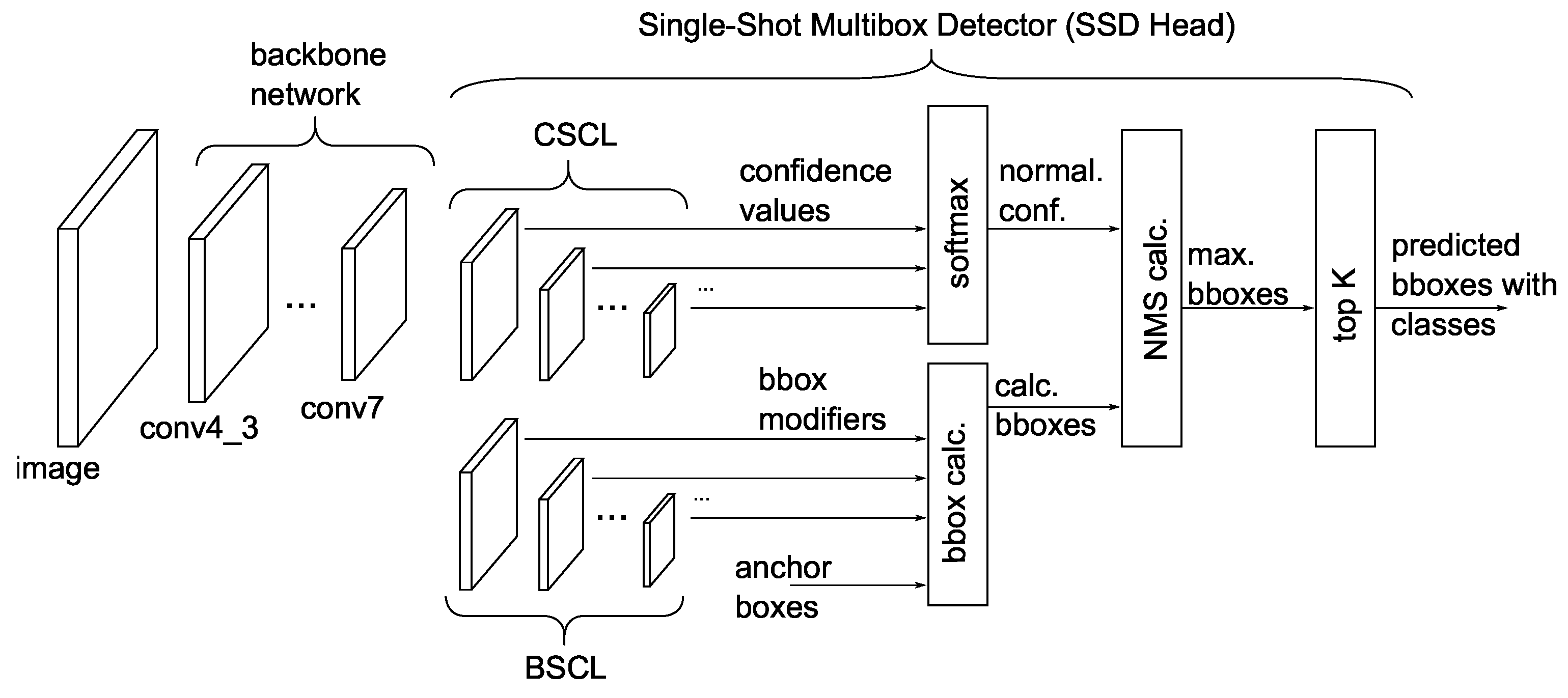
Figure 1 shows the general structure of the SSD network. The backbone network is the first component of the SSD network and employs a standard CNN such as VGG, MobileNet, ResNet, Inception, or EfficientNet. The backbone network’s objective is to extract features from the input image automatically, enabling the system to identify bounding boxes accurately.
The second part of the SSD network is the single-shot multibox detector, the SSD Head for short. The purpose of the SSD Head is to calculate the bounding boxes for every class from the results computed by the backbone part of the network. The SSD Head consists of additional convolutional layers and four other functions: softmax calculation, bounding box calculation, the Non-Maximum Suppression (NMS) function, and top-K sorting.
In the SSD Head, there are always paired convolutional layers. One layer determines the confidence values, marked as the Confidence SSD Convolutional Layer (CSCL), while the other calculates the bounding box modifiers, referred to as the Bounding Box SSD Convolutional Layer (BSCL). Additionally, there is a third layer that calculates the anchor boxes. These boxes are trainable parameters of the network, but they remain constant for every SSD network once trained.
2.2. System for HW Acceleration of Complete SSD Architecture
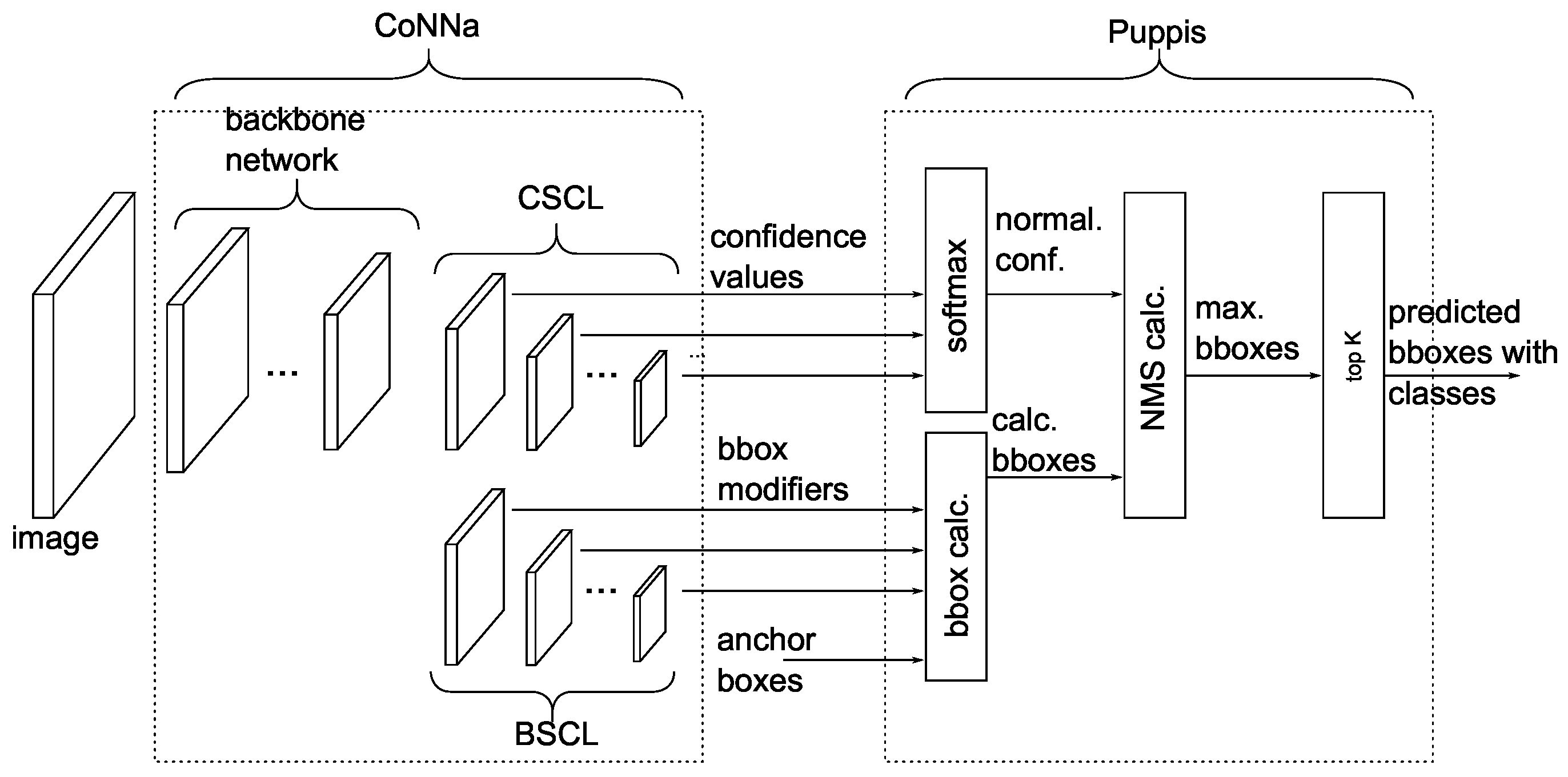
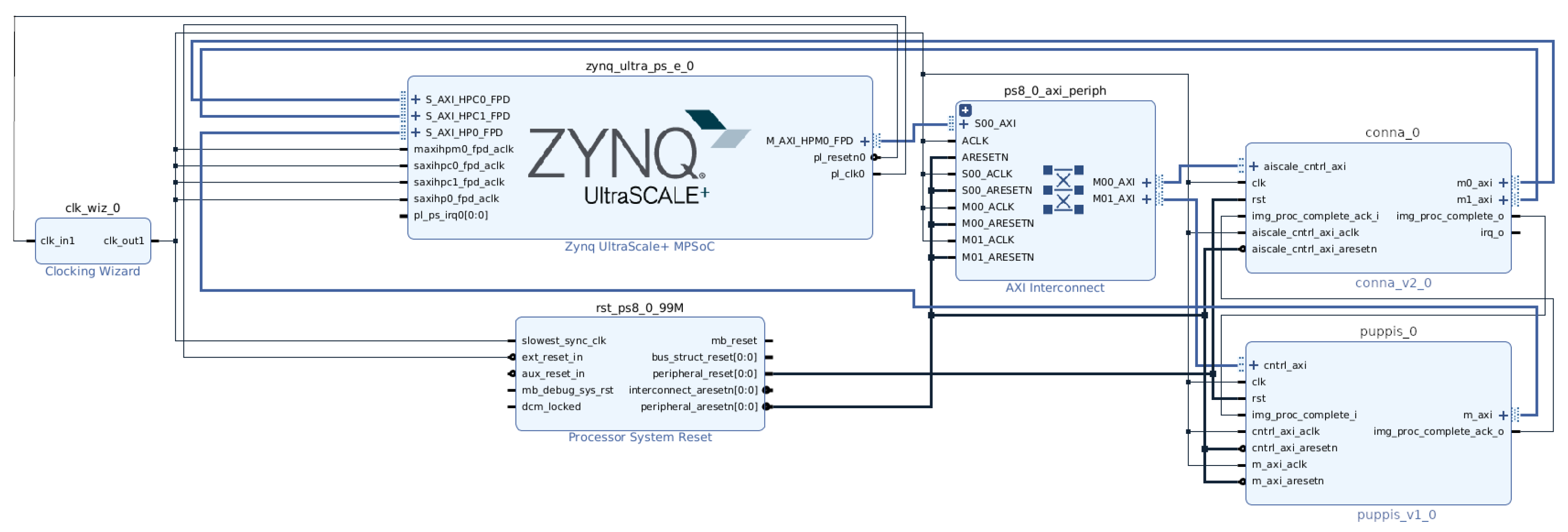
The overall system for the hardware acceleration of the complete SSD network, including Puppis, is shown in
Figure 2. The Puppis accelerator must be coupled with a CNN accelerator to enable complete SSD network acceleration in hardware. The CNN accelerator will speed up both the backbone CNN network and the additional convolutional layers in the SSD Head. This paper used a modified version of the CoNNa CNN HW accelerator, proposed in [
22] for this purpose. In contrast, the Puppis HW accelerator will accelerate the remaining calculating functions from the SSD Head: softmax, bounding box, non-maximum suppression, and top-K sorting. By working together, CoNNa and Puppis enable the hardware acceleration of the complete SSD network.
The Puppis uses two handshake interfaces, enabling an easy and generic way of connecting to the selected CNN accelerator. Please notice that, if the CNN accelerator does not already have this handshake interface, it must be adapted to support it. However, due to the simplicity of the handshake interface used, this poses no significant problem.
Figure 3 shows the proposed interfaces between the two accelerators. These two interfaces will be called the SSD-CNN handshake.
Both interfaces contain only two signals. In
Figure 3, the first one consists of the
cnn_done and
ssd_ack signals. When the CNN accelerator finishes processing the backbone network with the current input image, it asserts
cnn_done. The Puppis asserts
ssd_ack to acknowledge that and starts executing its part of the complete SSD algorithm using the feature maps provided by the CNN accelerator, computed using the last input image.
The second interface includes the ssd_done and cnn_ack signals. Here, Puppis asserts ssd_done when processing is complete, and cnn_ack is triggered when the CNN accelerator acknowledges it and switches to process the following input feature map.
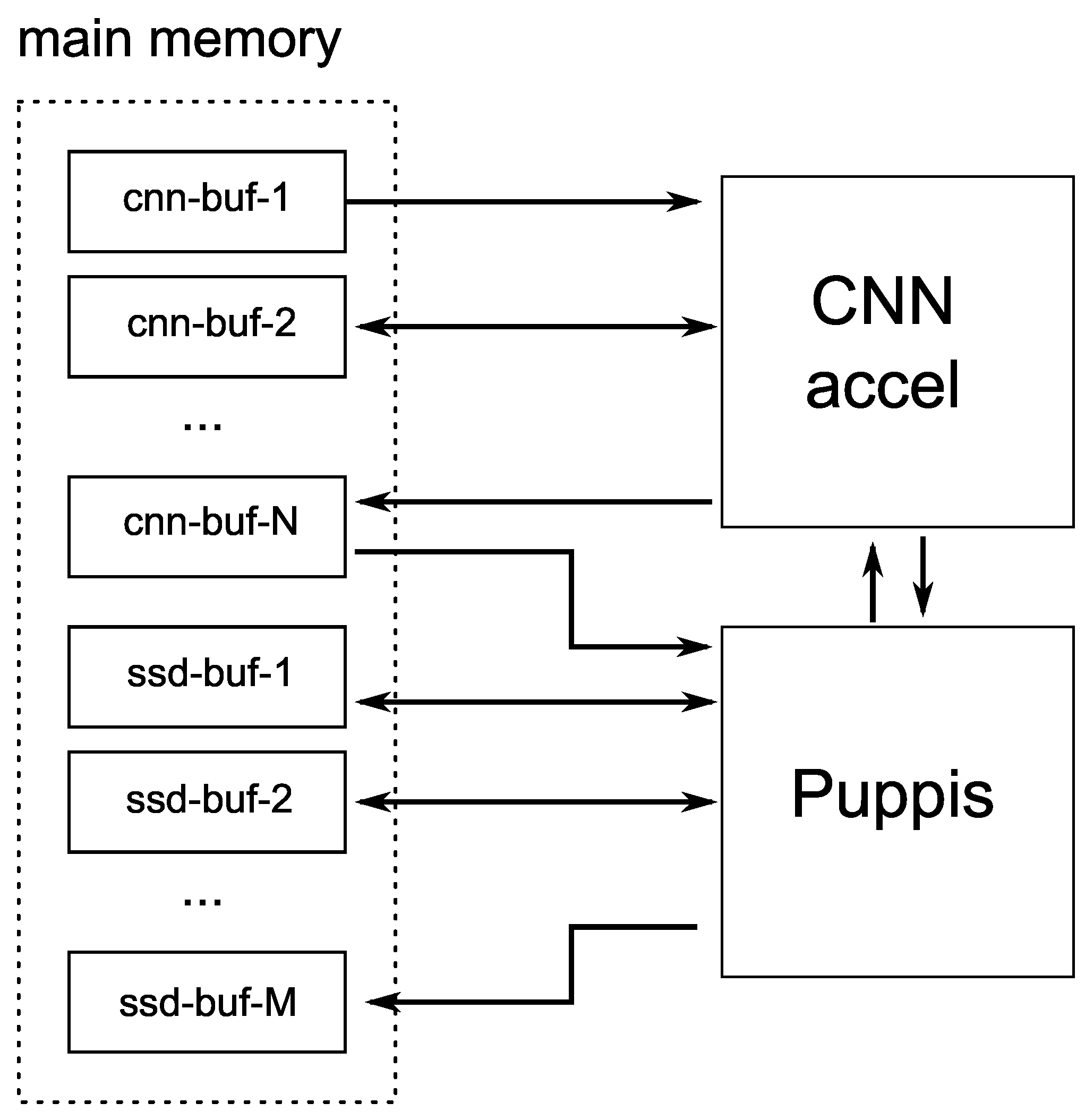
As can be seen from the previous explanation, these two interfaces enable the synchronization and reliable transfer of data between the selected CNN accelerator and Puppis SSD Head accelerator. Feature maps computed by the CNN accelerator are transferred to the Puppis using a shared memory buffer. The information presented in
Figure 4 demonstrates using buffer
cnn-buf-1 as the input buffer for the SSD network’s image processing. After processing the first layer, the buffer
cnn-buf-2 stores the result. That buffer is then input for the next layer, and so on.
The results of processing the final layers from the CSCL and BSCL are stored in couple of last cnn-buf buffers, depending on the number of these final layers. For example, if there are k final layers, then cnn-buf-N-k up to cnn-buf-N buffers would be used to store their output values. These buffers are actually the input buffers for the Puppis HW accelerator. During its operation, Puppis uses additional memory buffers: ssd-buf-1 up to ssd-buf-M. These buffers are used to store intermediate results, computed as the Puppis HW accelerator operates on the input data. The final results are stored in the output buffer ssd-buf-M. From this buffer, the software can read the final results of the SSD network processing, containing the detected objects’ bounding box information.
Please notice that the described setup enables the implementation of a coarse-grained pipelining technique during the processing of a complete SSD network by the proposed system. While the Puppis HW accelerator processes CNN-generated information for the input image i, the CNN HW accelerator can already start processing input image i+1. This setup can significantly increase the processing throughput of the complete system, although the processing latency will remain unchanged. In applications where achieving a high frame rate is of interest, this could prove highly beneficial.
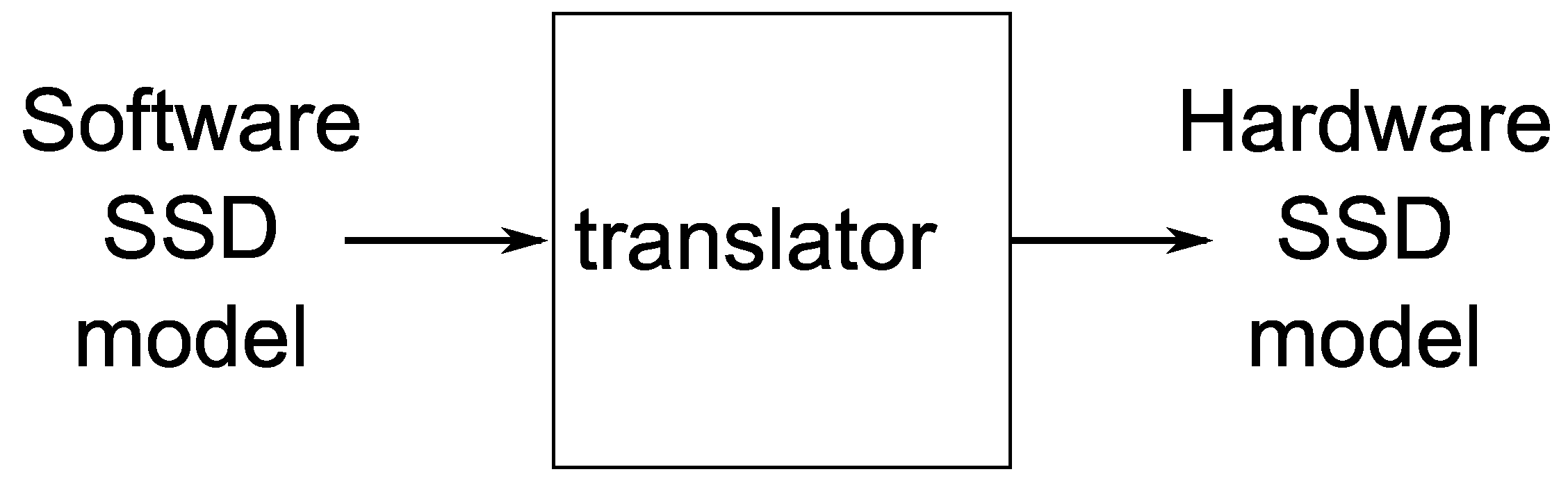
In order to be able to process the selected SSD network, both the CNN and Puppis HW accelerators require that the SSD network be represented in an accelerator-specific binary format, as shown in
Figure 5. During the development of Puppis, such a tool for translating the high-level model of the SSD network (developed, for example, using Keras, PyTorch, or some other framework) into this accelerator-specific binary model was also developed.
In the process of SSD model translation, the translator tool also determines the optimal fixed-point number format that will be used to store various SSD-model-related data during the SSD network processing. Then, it translates the model parameters to this number format and stores them in buffers, which are located in the main memory of the SSD accelerator. For the anchor boxes, it prepares special buffers for Puppis, so that it can just load those values from the memory system, without any calculation. In short, this tool prepares the model to be successfully processed by the CoNNa and Puppis accelerators.
3. Accelerated SSD Head Computation Algorithms
The part of the single-shot multibox detector algorithm that is implemented by the Puppis HW accelerator contains four main computational steps:
The first three steps are more computationally complex, and the following sections contain detailed descriptions. The last part of the calculation, top-K sorting, determines the best K bounding boxes within the results calculated in the non-maximum suppression block using a simple bubble-sort algorithm.
3.1. The Softmax Calculation
The softmax calculation is the first step executed by the Puppis accelerator. The inputs for the softmax calculation are the confidence values of the SSD convolutional layers and Exponential Confidence Look-Up Tables (ECLUTs), while the outputs are the score predictions for all boxes. The confidence values are the outputs from the backbone network and the CSCL, and in our setup of the complete SSD network hardware accelerator, the modified CoNNa CNN accelerator will provide these as its output. The ECLUT is an array of samples of exponential functions in the floating-point format, which is calculated by the translator and stored in the main memory.
Equation (
1) represents the softmax formula, which determines the normalized values.
Subscript k is an index of the current class (); S is the input from the confidence layers; N is the number of classes; are the normalized confidence scores.
The hardware accelerator implementation mainly uses two number formats: fixed-point or floating-point. The simpler or energy-efficient hardware accelerators use the fixed-point format, while applications requiring a wide dynamic range utilize the floating-point format. We used a hybrid approach in this architecture, which a later section will describe. Softmax calculation uses an exponential function over a wide range of values. Therefore, if the architecture uses only the fixed-point format, it will require many bits to cover the number range. Using only the floating-point hardware would be too expensive because the floating-point calculation uses too many hardware resources. Therefore, the optimal solution requires a mix of floating-point and fixed-point numbers. In that way, we keep the hardware utilization close to the fixed-point representation and still cover the required range of values, as if the solution uses the floating-point number representation.
Inside the calculation logic, there are hardware blocks that determine the format used for representing the fixed-point numbers. The pseudocode of the algorithm for the calculation of Equation (
1), with some hardware-related details, is shown below.
The parameter SCN is the current number of SSD convolutional layer pairs that the network uses and is a configurable runtime parameter. The variable confs is an input array that contains the confidence values. The confs array is stored in the main memory of the system, while the variable box_cnt counts all boxes requiring the score prediction values.
The algorithm iterates through the output feature maps generated by each CSCL shown in
Figure 1. For each output point of any CSCL and for all boxes corresponding to that layer, the list of confidence values for each class (
conf_box = conf[i][j][k]) is read from memory. The algorithm also reads the corresponding floating-point value from the ECLUT memory and calculates the maximum value. The comparison between
exp_vals[cls] and
exp_val_max is a floating-point comparison. According to the comparison result, the algorithm determines the fixed-point representation used later in the calculation. The ECLUT contains samples of exponential functions for each class used in the network: each class has 4096 samples within the ECLUT, while the translator creates the table that contains the required samples, which are represented as 16 bit-wide fixed-point numbers. The
exp_sum_reduce variable stores the computed format. This number determines how much the values are shifted during the calculation, representing the number of bits after the fixed-point. The architecture uses the 32 bit IEEE 754 standard when interpreting the floating-point numbers.
The function
getFormatFromFloat determines the format according to the value of the
exp_val_max variable. The following loop in the code calculates the sum of all exponential function values, computing the value of the denominator from Equation (
1), which is needed to determine the softmax score box predictions. If there is an overflow during a sum calculation, the fixed-point is shifted one position to the left,
exp_sum_reduce += 1, and the sum is divided by 2 to be correctly interpreted by a new fixed-point format.
Finally, the new normalized score predictions, , are calculated for all classes. A computed denominator value divides the confidence value for every class, and a score prediction array stores the result. This array’s location is in the main system memory.
3.2. The Bounding Box Calculation
The bounding box calculation is the next step in the accelerator calculation flow. For every output point in the convolutional layer that calculates the bounding box modifiers and for every anchor box, the accelerator calculates one resulting bounding box. The following formulas express the bounding box calculation procedure.
and are the predicted center of the bounding box. , , , and are four predicted input values from the convolutional layers. and are the so-called variance values, which are trainable parameters of the SSD network, stored within a binary description of a network by the translator. The values and are the width and heights of the current anchor box, and the values and specify the center of the current anchor box. The values and are the output values of the convolutional layer used to calculate the width and height of the bounding box. The values and are the variance values determined during the training. Finally, the values and specify the upper left corner of the predicted bounding box, while (, ) specify the lower right corner of the computed bounding box.
Puppis uses the 16 bit fixed-point number representation for all calculations (
2)–(
9), while the translator determines the exact position of the decimal point. Opposite the calculation of an exponential function as a part of a softmax calculation, the exponential functions in Equations (
4) and (
5) are calculated using look-up tables.
3.3. Non-Maximum Suppression Calculation
Once the bounding box calculation is complete, the third step is to perform the NMS calculation. This is an important algorithm that helps to remove overlapping boxes that have been placed around the same object with high confidence. The goal is to have only one bounding box around one object, so the NMS calculation removes any boxes that overlap enough (the algorithm parameter). This step ensures that there is only one bounding box around each object, even if there were originally several boxes before this step.
The pseudo-code for this algorithm is listed below. The inputs for this algorithm are the confidence values after the softmax calculation, calculated in Step 1, and the bounding box locations calculated in the second step. These inputs are represented as the in_confs variable for the confidences and in_bboxes for the bounding boxes. confs is a 2D array because it holds the normalized confidence values for all the classes and all the bounding boxes.
The algorithm iterates over all classes, where the variable cnt_class represents the current class. The variable box_ind represents the indices of the confidence values more significant than the input threshold TVAL. The variable confs is all the confidence values greater than TVAL, and the variable bboxes is the corresponding bounding boxes. If no such values exist, the algorithm iterates to the next class. The variable areas represents areas of all bboxes, while the variable sort_ind is a sorted version of box_ind, and the indices are sorted based on their corresponding confidence values. The value gt_ind represents the index of the bounding box with the maximum confidence value for the current class. The outputs of the algorithm are the bounding boxes for which the confidence value is greater than a user-defined parameter TOVER. Each of these bounding boxes is accompanied with its class membership information. The algorithm calculates the overlap between the current best bounding box and all other bounding boxes, so the subsequent while loop iteration only processes indices with overlaps less than a threshold value of TOVER. The while loop terminates if no such indices exist (the sort_ind list is empty), and the algorithm outputs all possible bounding boxes for each class with a confidence value above the TVAL parameter, for which it holds that the overlap with the best confidence box that is lower than TOVER.
Function
calc_overlap calculates the overlap between two boxes, after receiving two rectangles as inputs. The first rectangle is defined by two points,
and
, and the second by
and
. The function calculates the overlap value according to the following formulas:
where the points
and
define an overlapping rectangle. The overlapping area is
;
is a non-overlapping area, while the values
and
represent the areas of the two bounding boxes, for which the calculation is performed. The value
is always the area of the bounding box with the greatest confidence value for the current class, while the output of the function
O represents a ratio between
and
.
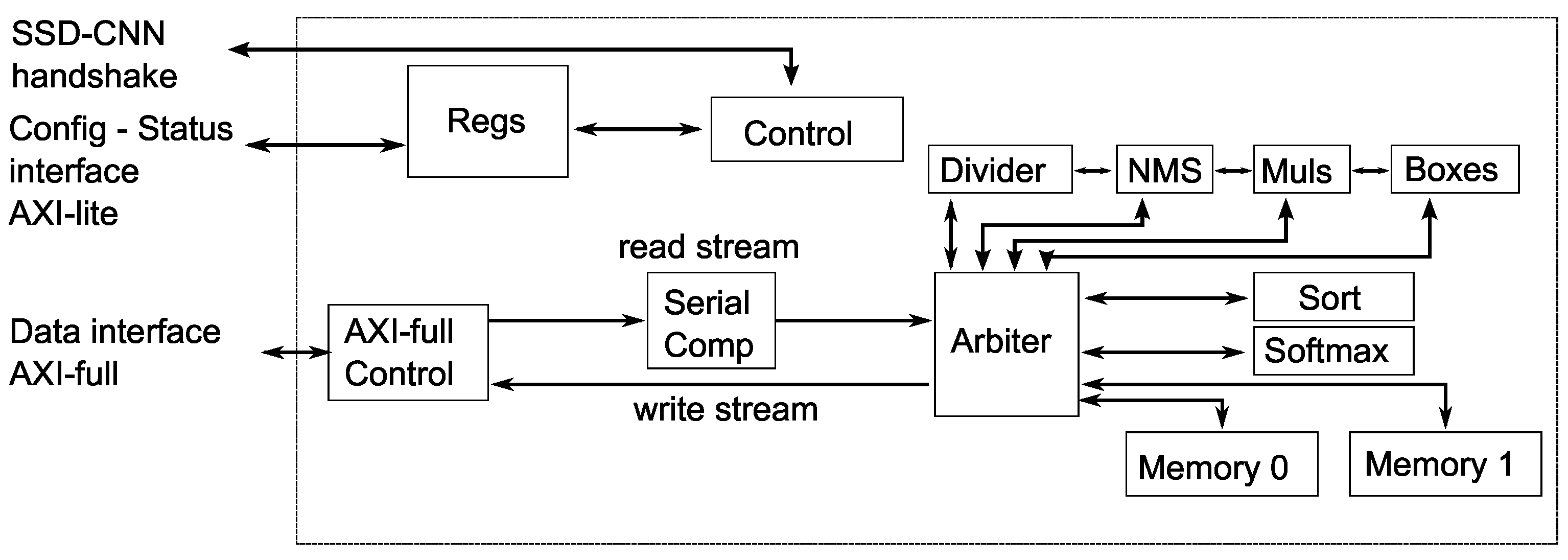
4. Puppis HW Accelerator Architecture
Figure 6 provides an overview of the architecture of the Puppis hardware accelerator. It shows the interfaces and central building blocks at the highest abstraction level. Puppis uses three interfaces to connect to surrounding modules: the configuration and status AXI-Lite interface, the data transfer AXI-Full interface, and the SSD-CNN handshake explained earlier in
Section 2.2.
The AXI-Lite interface configures and checks the accelerator status, while the AXI-Full interface transfers data to and from the accelerator. The Arbiter module is responsible for routing data throughout the accelerator. Additionally, the SSD-CNN handshake interface enables the calculation of the entire SSD CNN without needing processor intervention.
At the top level, Puppis has multiple modules. Among them is the Regs module, which comprises the accelerator’s configuration registers. Additionally, Puppis has status registers accessible through the AXI-Lite interface. The configuration settings impact the functionality of the central controller module, represented as
Control in
Figure 6.
The
Control module coordinates the other modules’ operations to calculate the SSD Head output. Depending on the configuration and calculation state, this module controls the routing and timing of data transfers through the accelerator’s calculation modules and their internal pipeline stages. Although it has connections to all other modules,
Figure 6 does not show these connections for clarity. The following section will provide a more-detailed description of this module.
The Arbiter module serves as the primary data-routing unit in Puppis. Its interconnect architecture allows for seamless data transfer from its source to its destination, making it an integral part of the Puppis accelerator. The main Control module is responsible for controlling the Arbiter module’s operations.
The main calculation modules of Puppis are
Softmax, Boxes, and NMS. The
Softmax module calculates the softmax function, given by Equation (
1) and Listing 1. The Boxes module calculates the bounding boxes, Equations (
2)–(
9). The NMS module calculates the NMS function of the SSD calculation; see Listing 2. The following sections will describe these modules in more detail.
| Listing 1. Softmax pseudocode. |
| |
| box_cnt = 0 |
| for ci in (0 to SCN): |
| conf = confs [ ci ] |
| for i in (0 to Heights [ ci ]): |
| for j in (0 to Widths [ ci ]): |
| for k in (0 to Box [ ci ]): |
| conf_box = conf [ i ][ j ][ k ] |
| exp_val_max = 0 |
| for cls in (0 to ClassN): |
| exp_in_val = conf_box[cls] >> 4 |
| exp_vals[cls] = ECLUT[ci][exp_in_val] |
| if (exp_vals[cls] > exp_val_max): |
| exp_val_max = exp_vals[cls] |
| |
| exp_fmt = getFormatFromFloat(exp_val_max) |
| exp_sum = 0 |
| exp_sum_reduce = 0 |
| for cls in (0 to ClassN): |
| exp_vals_sum[cls] = |
| floatToFixedConv(exp_vals[cls], exp_fmt) |
| exp_sum += exp_vals_sum[cls] |
| if (overflow(exp_sum)): |
| exp_sum /= 2 |
| exp_sum_reduce += 1 |
| |
| for cls in (0 to ClassN): |
| exp_val = exp_vals_sum[cls] >> exp_sum_reduce |
| scores_predictions[cls][box_cnt] = exp_val / exp_sum |
| box_cnt += 1 |
| Listing 2. NMS pseudocode. |
| |
| for_each cnt _ class in classes |
| box_cnt += 1for_each cnt_class in classes |
| box_ind = indices_greater_than_value(cnt_cls, in_confs, TVAL) |
| confs = values_from_indices(in_confs, box_ind) |
| bboxes = values_from_indices(in_bboxes, box_ind) |
| |
| if confs empty go to next class |
| |
| for_each box in bboxes |
| areas = area_of(box) |
| |
| sort_ind = sort_indices_by_conf( box_ind, confs ) |
| while sort_int not empty |
| gt_ind = sort_ind[0] |
| resutls_add(bboxed[gt_ind], cnt_class, confs[gt_ind]) |
| for_each ind in sort_ind except gt_ind |
| put calc_ovelap(bboxed[gt_ind], bboxed[ind]) into overs |
| sort_ind = get_indices_for_which_overlap_less_than( |
| sort_ind, overs, TOVER) |
The other helper calculation modules of Puppis are: Divider, Muls, and Sort. Specifically, the Divider module implements the division operation of two fixed-point numbers, used in the Softmax and NMS computational steps of the SSD algorithm. It uses a pipelined architecture to achieve a similar operating frequency as the other modules. The Muls module calculates the multiplication of two fixed-point numbers represented with the same number of bits. This module is pipelined and has four lanes to calculate four multiplications simultaneously. The Sort module sorts values and is used during the NMS calculation and for selecting the final top K results.
Puppis uses two internal caching memories: Memories 0 and 1. They store the configuration parameters and intermediate results during the SSD calculation. The memories are configurable and have several purposes during the SSD calculation process, which the following sections will describe in more detail.
The Arbiter module enables communication between the calculation modules and the memories. Additionally, some communication lines connect the calculation modules directly: Divider to NMS, NMS to Muls, and finally, Muls to Boxes. These lines stream intermediate results, without buffering, between modules.
An AXI-Full interface enables communication to the external main memory. The AXI-Full Control module implements the AXI-Full protocol. This module receives two AXI-Stream data streams, a read stream and a write stream, and combines them into a single AXI-Full interface.
The Serial Comp module connects to the Arbiter and the AXI-Full Control module’s read interface. The module reads the confidence predictions from the main memory and passes only those predictions greater than the predefined threshold to the Arbiter module. Furthermore, the Serial Comp module can transfer other data types without discrimination.
The forthcoming sections will concisely explain the most-essential modules’ operational principles. The descriptions will omit specific details to offer a broad overview of each modules’ functioning and facilitate comprehension.
4.1. Control Module
The
Control module sends control signals to all the other modules in the architecture. It implements a Finite-State Machine (FSM), which sequentially processes the input through several steps of the SSD Head computation algorithm explained earlier.
Figure 7 shows the simplified FSM.
In the READY state, Puppis is ready to receive the subsequent input. In this state, the module AXI-Lite can change configuration to prepare calculation blocks to process the input. In the next state, Softmax, the Control module sends control signals to read the input confidence values from memory, calculate the softmax algorithm with those inputs, and write the normalized values into the main memory. In the Boxes state, Puppis reads the bounding box modifiers from the main memory and anchor boxes, then calculates the bounding boxes. Internal memory modules store the resulting bounding boxes. In the NMS state, the Control unit sends control signals to receive the normalized confidence values from the main memory and the bounding boxes from the internal memory. Then, the NMS algorithm processes those inputs, and the internal memory stores the resulting output. Finally, in the Sort state, the inputs from the NMS step are read from the internal memory, and the best calculated K results are stored in the main memory as the final result of the input processing. Then, the Puppis accelerator switches to the READY state, being ready to receive the next input.
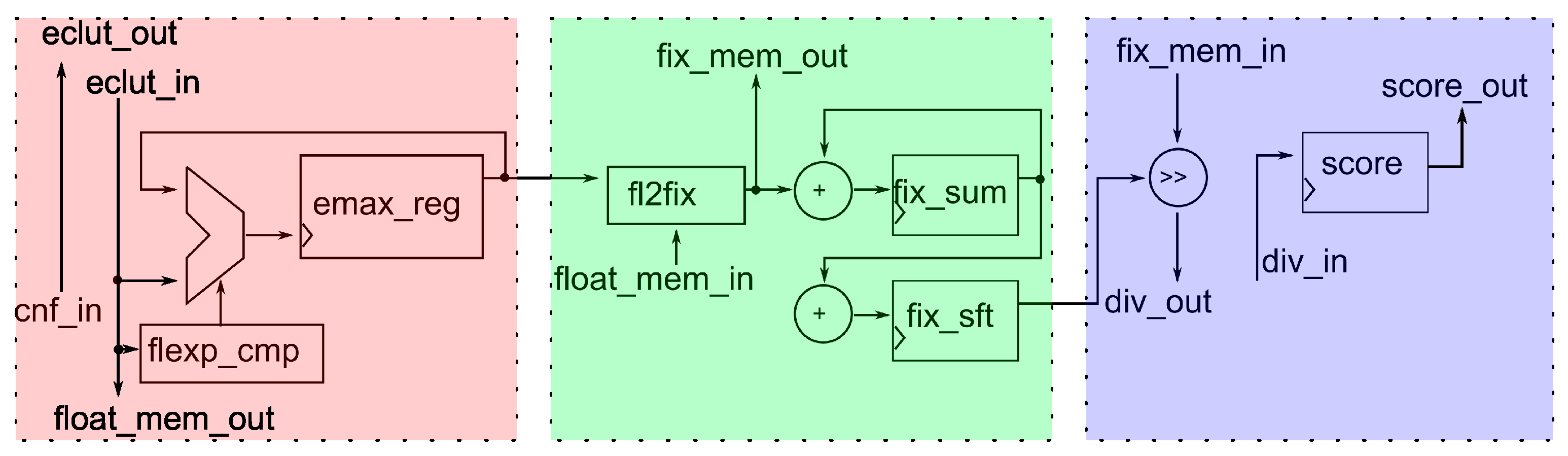
4.2. Softmax Module
Figure 8 shows the top-level block diagram of the
Softmax module. The block diagram presents a model of the
Softmax module close to the Register Transfer Level (RTL), but some details are abstracted. In this way, the model is easier to explain. For example, the model does not show the control signals from the
Control module. We call this model the abstracted RTL model. The
Softmax module contains three pipeline stages.
The module receives confidence values from the main memory in the first pipeline processing stage. The module determines the maximum value of the floating-point exponent by utilizing samples of a floating-point function stored in the ECLUT memory. This value is stored in the output register flexp_cmp and serves as the input for the second pipeline stage.
Based on the format determined in the first phase, the module converts all floating-point values
from the Formula (
1) into the fixed-point format in the second phase of the pipeline processing. The internal memory receives the numbers in the new number format through the
fix_mem_out port. Additionally, this module computes the sum from the Formula (
1). If overflow occurs, the module adjusts the number format accordingly.
The module divides the fixed-point values
in the third phase by the computed sum. During this calculation, the module utilizes the
Divider module. The final result, representing normalized values from the Formula (
1), is stored in internal memory with the
score_out port, making it available for other modules for further processing.
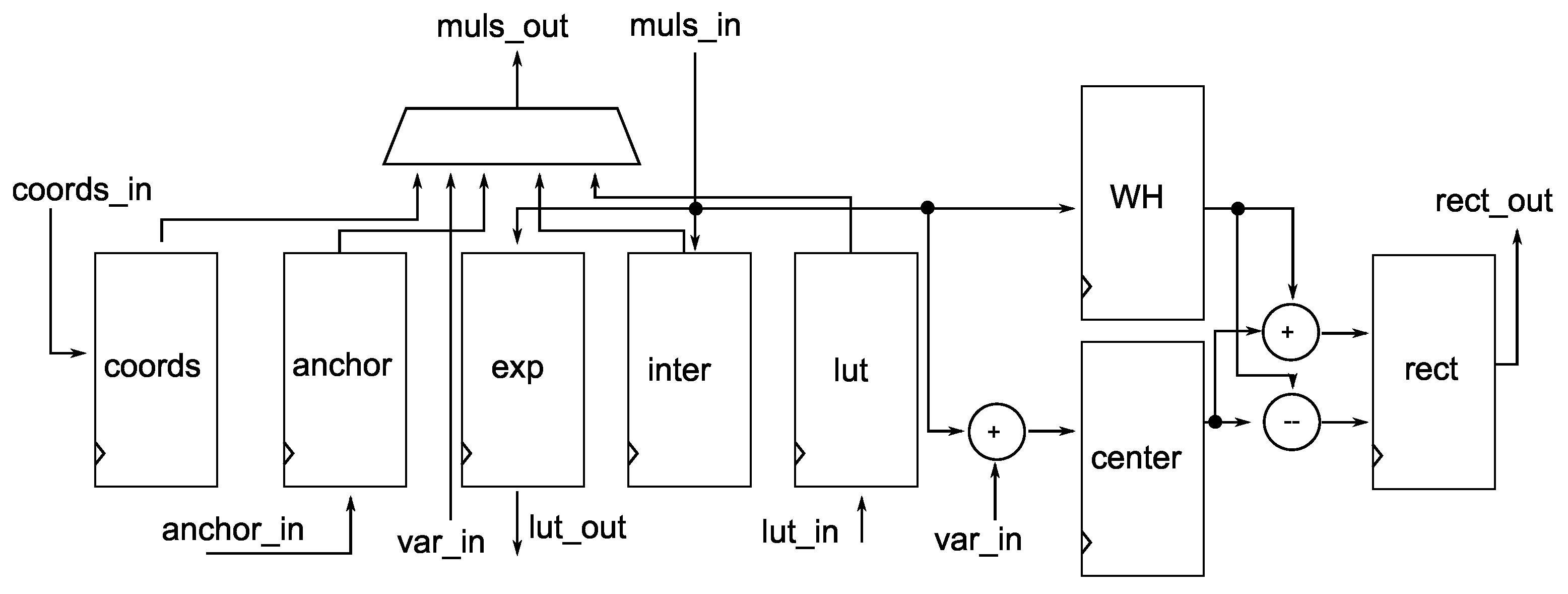
4.3. Bounding Box Module
Figure 9 shows the abstracted RTL model for the
Bounding box module. The module uses several registers to store intermediate calculation results for Equations (
2)–(
9). The top of
Figure 9 shows the multiplexer, which the
Control module uses to select which arguments to send to the
Muls module.
This module encompasses numerous registers designed to store intermediate computation results. Over several clock cycles, the center coordinates of the bounding box are computed and stored in the center register, while the register, denoted as WH, holds the calculated width and height values. The module computes the resulting rectangle, utilizing these center coordinates and dimensions, and forwards it to the internal memories through the port rect_out, making it available for other modules.
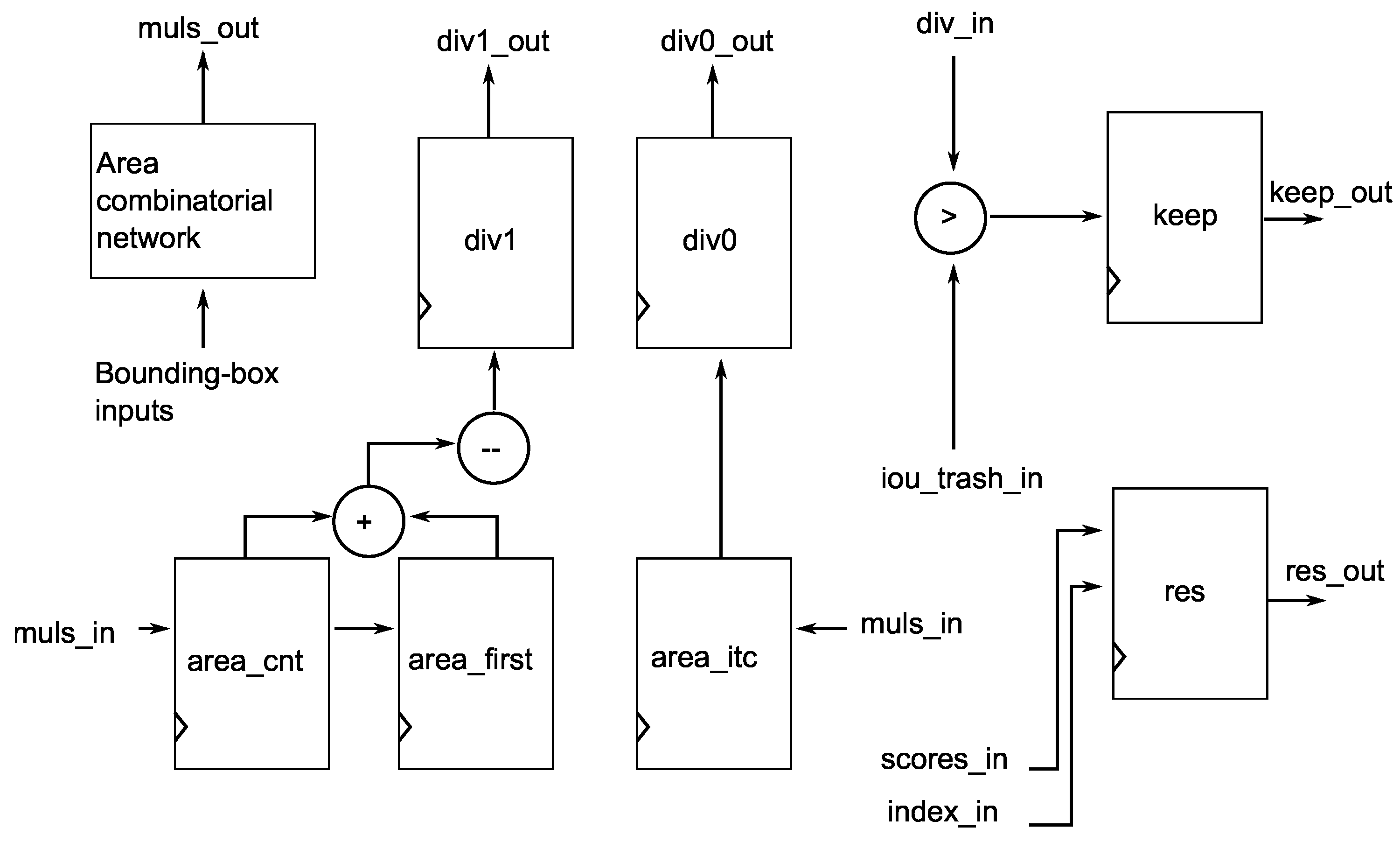
4.4. NMS Module
The
Control module guides the NMS module through Listing 2. The core of that algorithm is Equations (
10)–(
16).
Figure 10 shows an abstract RTL schematic of the NMS module. The following is a description of how the module calculates these equations.
In the initial step, this module calculates the areas of the bounding boxes based on the results computed by the Bounding box module. During its operation, for all multiplication operations, this module utilizes the Muls block. For all boxes, except the first one, the module calculates
O from Equation (
16). The Divider block is employed when division is required, and the module obtains the
O value through the
dib_in port. Subsequently,
O is compared to a threshold parameter to determine whether the module retains the bounding box. The
keep register holds this information. Along with this information, the module sends the confidence and computed bounding box values (
res register) needed for final result sorting.
4.5. Sort Module
The computation’s last step is the top-K sorting procedure, which identifies the top-K bounding boxes from the results obtained through the non-maximum suppression block. The implemented sorting procedure is a simple bubble-sort algorithm. Since this step does not require much computation, a simple sequential architecture is used for this module.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}