
A Systematic Review on Deep-Learning-Based Phishing Email Detection

Abstract
:1. Introduction
1.1. Our Contribution
- 1.
- This systematic literature review aims to provide a comprehensive overview of the current state of research on the use of deep learning techniques for phishing detection.
- 2.
- The review explores the various deep learning techniques used for phishing detection, their effectiveness, and areas for future research.
- 3.
- By synthesizing the findings of relevant studies, this review helps to identify the strengths and limitations of different approaches and provide insights into the challenges that need to be addressed to improve the accuracy and effectiveness of phishing detection.
1.2. Organization of the Document
2. Methodology
2.1. Research Question and Search Strategy
2.2. Study Selection
2.3. Data Extraction and Analysis
2.4. Quality Assessment
2.5. Inclusion and Exclusion Criteria
2.5.1. Inclusion Criteria
- The paper must contain empirical results on deep-learning-based phishing detection.
- The paper must be published in the English language.
2.5.2. Exclusion Criteria
- The paper is not available in full-text format.
- The paper is not related to the research question.
- The paper is a duplicate publication. The paper is a review article or a meta-analysis.
- The paper is a conference abstract or poster presentation.
- The paper is a book, book chapter, or thesis.
- The paper is of low quality, as determined by the QATQS.
3. Literature Survey and Findings
3.1. Research Papers Published in 2017 and Before
3.2. Research Papers Published in 2018
3.3. Research Papers Published in 2019
3.4. Research Papers Published in 2020
3.5. Research Papers Published in 2021
3.6. Research Papers Published in 2022
3.7. Research Papers Published in 2023
4. Results and Analysis
4.1. Findings of Data Analysis
4.2. Limitations Found
4.3. Future Direction
4.3.1. Privacy Preservation
4.3.2. Increasing Dataset Size and Optimizing Feature Selection
4.3.3. Broader Email Content Analysis
4.3.4. Handling Modern Phishing Techniques
4.3.5. Handling Concept Drift
4.3.6. Consideration of Additional Factors
4.3.7. Comparison with State-of-the-Art Techniques
4.3.8. Hyperparameter Optimization and More Deep Learning Architectures
4.3.9. Real-Time Dataset and Processing
4.3.10. Exploration of Other Machine Learning Techniques
4.3.11. Incorporating Additional Data Sources
4.3.12. Enriching the Dataset
4.3.13. Exploring Attackers’ Behavior and Modus Operandi
4.3.14. Testing on Other Domains
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alshingiti, Z.; Alaqel, R.; Al-Muhtadi, J.; Haq, Q.E.U.; Saleem, K.; Faheem, M.H. A Deep Learning-Based Phishing Detection System Using CNN, LSTM, and LSTM-CNN. Electronics 2023, 12, 232. [Google Scholar] [CrossRef]
- Tsohou, A.; Diamantopoulou, V.; Gritzalis, S.; Lambrinoudakis, C. Cyber insurance: State of the art, trends and future directions. Int. J. Inf. Secur. 2023, 22, 737–748. [Google Scholar] [CrossRef]
- Sheng, S.; Wardman, B.; Warner, G.; Cranor, L.; Hong, J.; Zhang, C. An Empirical Analysis of Phishing Blacklists. In Proceedings of the Sixth Conference on Email and Anti-Spam, Mountain View, CA, USA, 16–17 July 2009. [Google Scholar]
- Edge, M.E.; Sampaio, P.R.F. A survey of signature based methods for financial fraud detection. Comput. Secur. 2009, 28, 381–394. [Google Scholar] [CrossRef]
- Safi, A.; Singh, S. A systematic literature review on phishing website detection techniques. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 590–611. [Google Scholar] [CrossRef]
- Aldawood, H.; Skinner, G. An Advanced Taxonomy for Social Engineering Attacks. Int. J. Comput. Appl. 2020, 177, 1–11. [Google Scholar] [CrossRef]
- Aleroud, A.; Zhou, L. Phishing environments, techniques, and countermeasures: A survey. Comput. Secur. 2017, 68, 160–196. [Google Scholar] [CrossRef]
- Kocher, G.; Kumar, G. Machine learning and deep learning methods for intrusion detection systems: Recent developments and challenges. Soft Comput. 2021, 25, 9731–9763. [Google Scholar] [CrossRef]
- Chen, D.; Wawrzynski, P.; Lv, Z. Cyber security in smart cities: A review of deep learning-based applications and case studies. Sustain. Cities Soc. 2021, 66, 102655. [Google Scholar] [CrossRef]
- Adebowale, M.A.; Lwin, K.T.; Hossain, M.A. Deep learning with convolutional neural network and long short-term memory for phishing detection. In Proceedings of the 2019 13th International Conference on Software, Knowledge, Information Management and Applications (SKIMA), Island of Ulkulhas, Maldives, 26–28 August 2019; pp. 1–8. [Google Scholar]
- Thomas, B.; Ciliska, D.; Dobbins, M.; Micucci, S. A Process for Systematically Reviewing the Literature: Providing the Research Evidence for Public Health Nursing Interventions. Worldviews Evid.-Based Nurs. 2004, 1, 176–184. [Google Scholar] [CrossRef]
- Nosseir, A.; Nagati, K.; Taj-Eddin, I. Intelligent word-based spam filter detection using multi-neural networks. Int. J. Comput. Sci. Issues (IJCSI) 2013, 10 Pt 1, 17. [Google Scholar]
- Almomani, A.; Gupta, B.B.; Wan, T.C.; Altaher, A.; Manickam, S. Phishing dynamic evolving neural fuzzy framework for online detection zero-day phishing email. Indian J. Sci. Technol. 2013, 6, 3960–3964. [Google Scholar] [CrossRef]
- Hamid, I.R.A.; Abawajy, J.; Kim, T.H. Using feature selection and classification scheme for automating phishing email detection. Stud. Inform. Control. 2013, 22, 61–70. [Google Scholar] [CrossRef]
- Jameel, N.G.M.; George, L.E. Detection of phishing emails using feed forward neural network. Int. J. Comput. Appl. 2013, 77, 10–15. [Google Scholar]
- Soni, A.N. Spam-e-mail-detection-using-advanced-deep-convolution-neuralnetwork-algorithms. J. Innov. Dev. Pharm. Tech. Sci. 2019, 2, 74–80. [Google Scholar]
- Zhang, N.; Yuan, Y. Phishing Detection Using Neural Network. Available online: http://cs229.stanford.edu/proj2012/ZhangYuan-PhishingDetectionUsingNeuralNetwork.pdf (accessed on 1 October 2023).
- Kufandirimbwa, O.; Gotora, R. Spam detection using artificial neural networks (perceptron learning rule). Online J. Phys. Environ. Sci. Res. 2012, 1, 22–29. [Google Scholar]
- Abu-Nimeh, S.; Nappa, D.; Wang, X.; Nair, S. A comparison of machine learning techniques for phishing detection. In Proceedings of the Anti-Phishing Working Groups 2nd Annual eCrime Researchers Summit, Pittsburgh, PA, USA, 4–5 October 2007; pp. 60–69. [Google Scholar]
- Chandan, C.J.; Chheda, H.P.; Gosar, D.M.; Shah, H.R.; Bhave, P.U. A Machine learning approach for detection of phished websites using neural networks. Int. J. Recent Innov. Trends Comput. Commun. 2014, 2, 42054209. [Google Scholar]
- Alkaht, I.J.; Al Khatib, B. Filtering SPAM Using Several Stages Neural Networks. Int. Rev. Comput. Softw. (IRECOS) 2016, 11, 123–132. [Google Scholar] [CrossRef]
- Coyotes, C.; Mohan, V.S.; Naveen, J.; Vinayakumar, R.; Soman, K.P.; Verma, A.D.R. ARES: Automatic rogue email spotter. In Proceedings of the 1st AntiPhishing Shared Pilot at 4th ACM International Workshop on Security and Privacy Analytics (IWSPA), Tempe, AZ, USA, 1–11 March 2018. [Google Scholar]
- Smadi, S.; Aslam, N.; Zhang, L. Detection of online phishing email using dynamic evolving neural network based on reinforcement learning. Decis. Support Syst. 2018, 107, 88–102. [Google Scholar] [CrossRef]
- Hiransha, M.; Unnithan, N.A.; Vinayakumar, R.; Soman, K.; Verma, A.D.R. Deep learning based phishing e-mail detection. In Proceedings of the 1st AntiPhishing Shared Pilot at 4th ACM International Workshop Security Privacy Analytics (IWSPA), Tempe, AZ, USA, 1–11 March 2018; pp. 1–5. [Google Scholar]
- Barushka, A.; Hajek, P. Spam filtering using integrated distribution-based balancing approach and regularized deep neural networks. Appl. Intell. 2018, 48, 3538–3556. [Google Scholar] [CrossRef]
- Fang, Y.; Zhang, C.; Huang, C.; Liu, L.; Yang, Y. Phishing Email Detection Using Improved RCNN Model With Multilevel Vectors and Attention Mechanism. IEEE Access 2019, 7, 56329–56340. [Google Scholar] [CrossRef]
- Harikrishnan, N.B.; Vinayakumar, R.; Soman, K.P.; Poornachandran, P. Time split based pre-processing with a data-driven approach for malicious url detection. Cybersecur. Secur. Inf. Syst. Chall. Solut. Smart Environ. 2019, 43–65. [Google Scholar] [CrossRef]
- Ali, W.; Ahmed, A.A. Hybrid intelligent phishing website prediction using deep neural networks with genetic algorithm-based feature selection and weighting. IET Inf. Secur. 2019, 13, 659–669. [Google Scholar] [CrossRef]
- Oña, D.; Zapata, L.; Fuertes, W.; Rodríguez, G.; Benavides, E.; Toulkeridis, T. Phishing attacks: Detecting and preventing infected e-mails using machine learning methods. In Proceedings of the 2019 3rd Cyber Security in Networking Conference (CSNet), IEEE, Quito, Ecuador, 23–25 October 2019; pp. 161–163. [Google Scholar]
- Nguyen, M.; Nguyen, T.; Nguyen, T.H. A deep learning model with hierarchical lstms and supervised attention for anti-phishing. CEUR Workshop Proc. 2018, 2124, 29–38. [Google Scholar]
- Wei, B.; Hamad, R.A.; Yang, L.; He, X.; Wang, H.; Gao, B.; Woo, W.L. A deep-learning-driven light-weight phishing detection sensor. Sensors 2019, 19, 4258. [Google Scholar] [CrossRef] [PubMed]
- Vinayakumar, R.; Soman, K.P.; Poornachandran, P.; Akarsh, S.; Elhoseny, M. Deep learning framework for cyber threat situational awareness based on email and url data analysis. In Cybersecurity and Secure Information Systems: Challenges and Solutions in Smart Environments; Springer: Berlin/Heidelberg, Germany, 2019; pp. 87–124. [Google Scholar]
- Yang, P.; Zhao, G.; Zeng, P. Phishing Website Detection Based on Multidimensional Features Driven by Deep Learning. IEEE Access 2019, 7, 15196–15209. [Google Scholar] [CrossRef]
- Saha, I.; Sarma, D.; Chakma, R.J.; Alam, M.N.; Sultana, A.; Hossain, S. Phishing attacks detection using deep learning approach. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), IEEE, Tirunelveli, India, 20–22 August 2020; pp. 1180–1185. [Google Scholar]
- Thapa, C.; Tang, J.W.; Abuadbba, A.; Gao, Y.; Camtepe, S.; Nepal, S.; Almashor, M.; Zheng, Y. Evaluation of Federated Learning in Phishing Email Detection. Sensors 2023, 23, 4346. [Google Scholar] [CrossRef] [PubMed]
- Adebowale, M.A.; Lwin, K.T.; Hossain, M.A. Intelligent phishing detection scheme using deep learning algorithms. J. Enterp. Inf. Manag. 2020, 36, 747–766. [Google Scholar] [CrossRef]
- Alotaibi, R.; Al-Turaiki, I.; Alakeel, F. Mitigating email phishing attacks using convolutional neural networks. In Proceedings of the 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS), IEEE, Riyadh, Saudi Arabia, 19–21 March 2020; pp. 1–6. [Google Scholar]
- Baccouche, A.; Ahmed, S.; Sierra-Sosa, D.; Elmaghraby, A. Malicious text identification: Deep learning from public comments and emails. Information 2020, 11, 312. [Google Scholar] [CrossRef]
- Soon, G.K.; On, C.K.; Rusli, N.M.; Fun, T.S.; Alfred, R.; Guan, T.T. March. Comparison of simple feedforward neural network, recurrent neural network and ensemble neural networks in phishing detection. J. Phys. Conf. Ser. 2020, 1502, 012033. [Google Scholar] [CrossRef]
- Alauthman, M. Botnet Spam E-Mail Detection Using Deep Recurrent Neural Network. Int. J. Emerg. Trends Eng. Res. 2020, 8, 1979–1986. [Google Scholar] [CrossRef]
- Eryılmaz, E.E.; Şahin, D.Ö.; Kılıç, E. Filtering turkish spam using LSTM from deep learning techniques. In Proceedings of the 2020 8th International Symposium on Digital Forensics and Security, ISDFS, IEEE, Beirut, Lebanon, 1–2 June 2020; pp. 1–6. [Google Scholar]
- Halgaš, L.; Agrafiotis, I.; Nurse, J.R. Catching the Phish: Detecting phishing attacks using recurrent neural networks (RNNs). In Proceedings of the Information Security Applications: 20th International Conference, WISA 2019, Jeju Island, Republic of Korea, 21–24 August 2019; pp. 219–233. [Google Scholar]
- Isik, S.; Kurt, Z.; Anagun, Y.; Ozkan, K. Spam E-mail Classification Recurrent Neural Networks for Spam E-mail Classification on an Agglutinative Language. Int. J. Intell. Syst. Appl. Eng. 2020, 8, 221–227. [Google Scholar] [CrossRef]
- AlEroud, A.; Karabatis, G. Bypassing detection of URL-based phishing attacks using generative adversarial deep neural networks. In Proceedings of the Sixth International Workshop on Security and Privacy Analytics, New Orleans, LA, USA, 18 March 2020; pp. 53–60. [Google Scholar]
- Castillo, E.; Dhaduvai, S.; Liu, P.; Thakur, K.S.; Dalton, A.; Strzalkowski, T. Email threat detection using distinct neural network approaches. In Proceedings of the First International Workshop on Social Threats in Online Conversations: Understanding and Management, Marseille, France, 11–16 May 2020; pp. 48–55. [Google Scholar]
- Kumar, A.; Chatterjee, J.M.; Díaz, V.G. A novel hybrid approach of SVM combined with NLP and probabilistic neural network for email phishing. Int. J. Electr. Comput. Eng. (IJECE) 2020, 10, 486–493. [Google Scholar] [CrossRef]
- Opara, C.; Wei, B.; Chen, Y. HTMLPhish: Enabling phishing web page detection by applying deep learning techniques on HTML analysis. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- AbdulNabi, I.; Yaseen, Q. Spam Email Detection Using Deep Learning Techniques. Procedia Comput. Sci. 2021, 184, 853–858. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef]
- Alhogail, A.; Alsabih, A. Applying machine learning and natural language processing to detect phishing email. Comput. Secur. 2021, 110, 102414. [Google Scholar] [CrossRef]
- Bagui, S.; Nandi, D.; Bagui, S.; White, R.J. Machine learning and deep learning for phishing email classification using one-hot encoding. J. Comput. Sci. 2021, 17, 610–623. [Google Scholar] [CrossRef]
- Lee, J.; Tang, F.; Ye, P.; Abbasi, F.; Hay, P.; Divakaran, D.M. D-Fence: A flexible, efficient, and comprehensive phishing email detection system. In Proceedings of the 2021 IEEE European Symposium on Security and Privacy (EuroS&P), IEEE, Vienna, Austria, 7–11 September 2021; pp. 578–597. [Google Scholar]
- Manaswini, M.; Srinivasu, D.N. Phishing Email Detection Model using Improved Recurrent Convolutional Neural Networks and Multilevel Vectors. Ann. Rom. Soc. Cell Biol. 2021, 25, 16674–16681. [Google Scholar]
- Ghaleb, S.A.A.; Mohamad, M.; Fadzli, S.A.; Ghanem, W.A.H.M. Training Neural Networks by Enhance Grasshopper Optimization Algorithm for Spam Detection System. IEEE Access 2021, 9, 116768–116813. [Google Scholar] [CrossRef]
- Eckhardt, R.; Bagui, S. Convolutional Neural Networks and Long Short Term Memory for Phishing Email Classification. Int. J. Comput. Sci. Inf. Secur. 2021, 19, 27–35. [Google Scholar]
- Sheneamer, A. Comparison of Deep and Traditional Learning Methods for Email Spam Filtering. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 560–565. [Google Scholar] [CrossRef]
- Dubey, K.A.; Ganesh, K.B.; Gowtham, V.; Balakrishnan, M.D. Phishing email detection. Int. J. Emerg. Technol. Comput. Sci. Electron. (IJETCSE) 2021, 28, 1–4. [Google Scholar]
- Samarthrao, K.V.; Rohokale, V.M. Enhancement of email spam detection using improved deep learning algorithms for cyber security. J. Comput. Secur. 2022, 30, 231–264. [Google Scholar] [CrossRef]
- Dewis, M.; Viana, T. Phish Responder: A Hybrid Machine Learning Approach to Detect Phishing and Spam Emails. Appl. Syst. Innov. 2022, 5, 73. [Google Scholar] [CrossRef]
- Khan, S.A.; Iqbal, K.; Mohammad, N.; Akbar, R.; Ali, S.S.A.; Siddiqui, A.A. A Novel Fuzzy-Logic-Based Multi-Criteria Metric for Performance Evaluation of Spam Email Detection Algorithms. Appl. Sci. 2022, 12, 7043. [Google Scholar] [CrossRef]
- Malhotra, P.; Malik, S. Spam Email Detection Using Machine Learning and Deep Learning Techniques. In Proceedings of the International Conference on Innovative Computing & Communication (ICICC), Delhi, India, 24 June 2022. [Google Scholar] [CrossRef]
- Korkmaz, M.; Koçyiğit, E.; Şahingöz, Ö.; Diri, B. A Hybrid Phishing Detection System by Using Deep Learning-Based URL and Content Analysis. Elektron. Ir Elektrotechnika 2022, 28, 80–89. [Google Scholar] [CrossRef]
- Zhu, E.; Yuan, Q.; Chen, Z.; Li, X.; Fang, X. CCBLA: A Lightweight Phishing Detection Model Based on CNN, BiLSTM, and Attention Mechanism. Cogn. Comput. 2022, 15, 1320–1333. [Google Scholar] [CrossRef]
- Nooraee, M.; Ghaffari, H. Optimization and Improvement of Spam Email Detection Using Deep Learning Approaches. J. Comput. Robot. 2022, 15, 61–70. [Google Scholar]
- Prosun, P.R.K.; Alam, K.S.; Bhowmik, S. Improved Spam Email Filtering Architecture Using Several Feature Extraction Techniques. In Proceedings of the International Conference on Big Data, IoT, and Machine Learning: BIM 2021, Cox’s Bazar, Bangladesh, 23–25 September 2021; Springer: Singapore, 2021; pp. 665–675. [Google Scholar]
- Jafar, M.T.; Al-Fawa’reh, M.; Barhoush, M.; Alshira’H, M.H. Enhanced Analysis Approach to Detect Phishing Attacks During COVID-19 Crisis. Cybern. Inf. Technol. 2022, 22, 60–76. [Google Scholar] [CrossRef]
- Do, N.Q.; Selamat, A.; Krejcar, O.; Herrera-Viedma, E.; Fujita, H. Deep Learning for Phishing Detection: Taxonomy, Current Challenges and Future Directions. IEEE Access 2022, 10, 36429–36463. [Google Scholar] [CrossRef]
- Zhou, M.-G.; Liu, Z.-P.; Yin, H.-L.; Li, C.-L.; Xu, T.-K.; Chen, Z.-B. Quantum Neural Network for Quantum Neural Computing. Research 2023, 6, 0134. [Google Scholar] [CrossRef] [PubMed]
- Rafat, K.F.; Xin, Q.; Javed, A.R.; Jalil, Z.; Ahmad, R.Z. Evading obscure communication from spam emails. Math. Biosci. Eng. 2021, 19, 1926–1943. [Google Scholar] [CrossRef] [PubMed]
- Rathee, D.; Mann, S. Detection of E-Mail Phishing Attacks – using Machine Learning and Deep Learning. Int. J. Comput. Appl. 2022, 183, 1–7. [Google Scholar] [CrossRef]
- Mughaid, A.; AlZu’bi, S.; Hnaif, A.; Taamneh, S.; Alnajjar, A.; Abu Elsoud, E. An intelligent cyber security phishing detection system using deep learning techniques. Clust. Comput. 2022, 25, 3819–3828. [Google Scholar] [CrossRef] [PubMed]
- Butt, U.A.; Amin, R.; Aldabbas, H.; Mohan, S.; Alouffi, B.; Ahmadian, A. Cloud-based email phishing attack using machine and deep learning algorithm. Complex Intell. Syst. 2022, 9, 3043–3070. [Google Scholar] [CrossRef]
- Logavarshini, G.; Yogalakshmi, S. E-Mail Spam Classification Via Deep Learning and Natural Language Processing. Int. J. Res. Publ. Rev. 2022, 2582, 7421. [Google Scholar]
- Ghaleb, S.A.A.; Mohamad, M.; Ghanem, W.A.H.M.; Nasser, A.B.; Ghetas, M.; Abdullahi, A.M.; Saleh, S.A.M.; Arshad, H.; Omolara, A.E.; Abiodun, O.I. Feature Selection by Multiobjective Optimization: Application to Spam Detection System by Neural Networks and Grasshopper Optimization Algorithm. IEEE Access 2022, 10, 98475–98489. [Google Scholar] [CrossRef]
- Babu, D.K. Phishing Detection in Emails Using Multi-Convolutional Neural Network Fusion. Ph.D. Thesis, National College of Ireland, Dublin, Ireland, 2022. [Google Scholar]
- Shmalko, M.; Abuadbba, A.; Gaire, R.; Wu, T.; Paik, H.Y.; Nepal, S. Profiler: Profile-Based Model to Detect Phishing Emails. arXiv 2022, arXiv:2208.08745. [Google Scholar]
- Muralidharan, T.; Nissim, N. Improving malicious email detection through novel designated deep-learning architectures utilizing entire email. Neural Networks 2023, 157, 257–279. [Google Scholar] [CrossRef]
- Bountakas, P.; Xenakis, C. HELPHED: Hybrid Ensemble Learning PHishing Email Detection. J. Netw. Comput. Appl. 2023, 210, 103545. [Google Scholar] [CrossRef]
- Wen, T.; Xiao, Y.; Wang, A.; Wang, H. A novel hybrid feature fusion model for detecting phishing scam on Ethereum using deep neural network. Expert Syst. Appl. 2023, 211, 118463. [Google Scholar] [CrossRef]
- Liu, Z.-P.; Zhou, M.-G.; Liu, W.-B.; Li, C.-L.; Gu, J.; Yin, H.-L.; Chen, Z.-B. Automated machine learning for secure key rate in discrete-modulated continuous-variable quantum key distribution. Opt. Express 2022, 30, 15024–15036. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
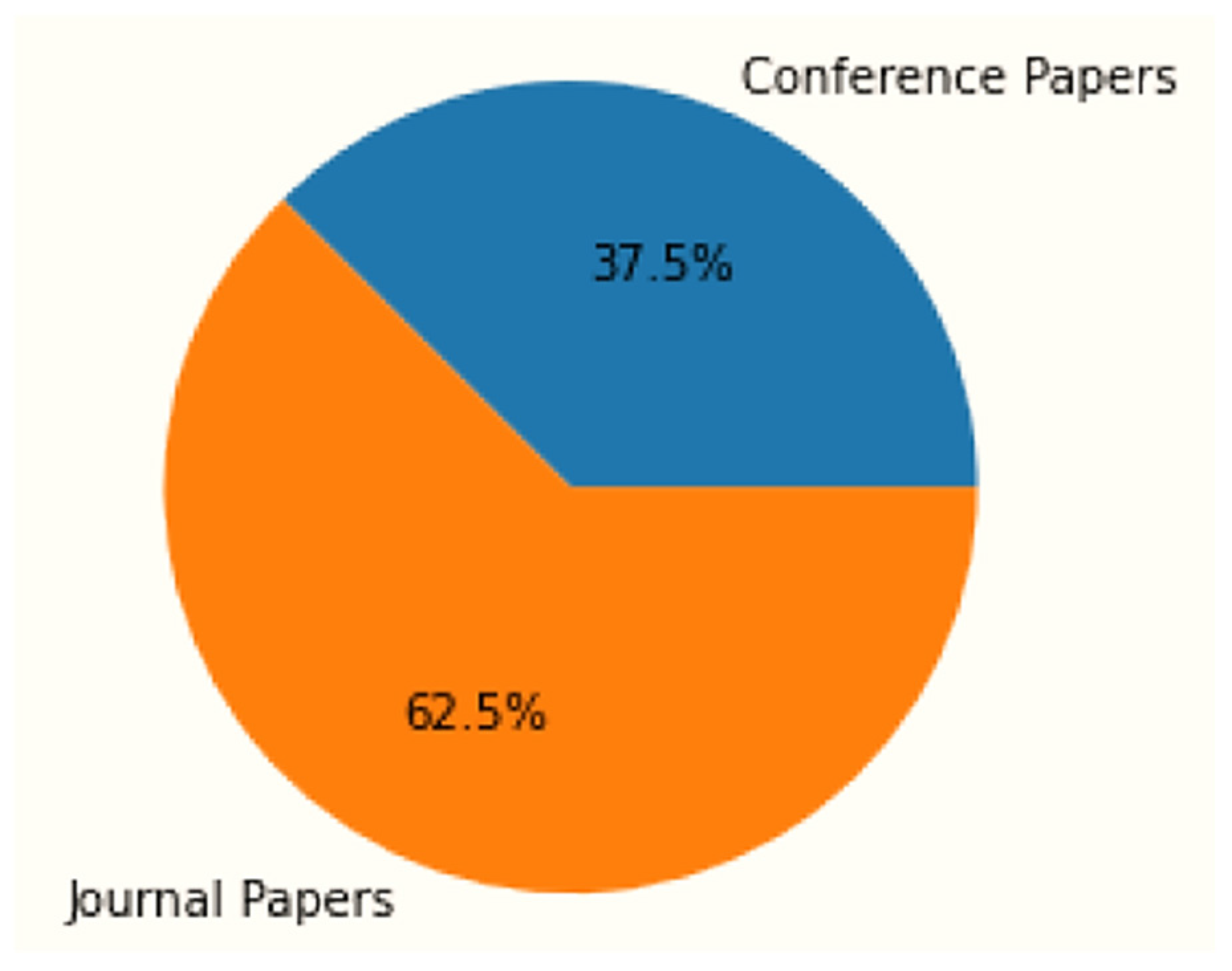{kind=link}
{kind=link}
{kind=link}
| Ref | Method | Data | Result | Innovations | Limitations |
|---|---|---|---|---|---|
| [22] | CNN, MLP, RNN | Self-generated emails dataset | Accuracy: 93.1% | Highlighted issues related to imbalance data | Highly imbalanced nature of the dataset |
| [23] | NN | SpanAssian | Accuracy: 99.07% | Provided guidelines to improve offline data | Needed to enrich the offline dataset to enhance model performance |
| [24] | CEN-Deepspam | Self-generated emails dataset | Accuracy: 95.5% | Larger dataset could improve accuracy | Additional dataset required to validate the result |
| [25] | DBB-RDNN-ReL | Enron, SpamAssassin, SMS Spam Colection | Accuracy: 96.1% | DBBRDNN-ReL model outperformed compared to other models | Slow processing |
| Ref | Method | Data | Result | Innovations | Limitations |
|---|---|---|---|---|---|
| [26] | THEMIS | Enron and SpamAssassin | Accuracy: 99.85% | Utilized unbalanced dataset | Limited to detecting phishing emails with header |
| [27] | NB, DT, AB, RF, DNN, RNN, CNN | PhishTank | Accuracy: 88.5% | Tf-idf presentation is better than feature hashing and embedding | Limited real-time dataset |
| [28] | DNN | UCI phishing websites | Accuracy: 95% | Hybrid model performs better for classification | Feature selection requires longer time |
| [29] | NN | Debian and PhishTank | Accuracy: 93.9% | Better accuracy | Limited use of deep learning |
| [30] | LSTM | Data-no-header and data-full-header | Accuracy: 89.34% | - | Low effectiveness |
| [31] | Multi-spatial CNN | Self-generated emails dataset | Accuracy: 86.63% | 30% reduction in the execution time | Did not compare model’s performance with other state-of-the-art methods |
| [32] | CNN, RNN, CNN-RNN, CNN-LSTM | Spam dataset. URL dataset | Recall: 99% | Better performance in detecting malware | Performance could be improved by adding sub-modules |
| [33] | CNN, RNN, LSTM, CNN-RNN | Self-generated emails dataset | Accuracy: 98.99% | High accuracy and low FPR | Focused on a single type of phishing attack |
| Ref | Method | Data | Result | Innovations | Limitations |
|---|---|---|---|---|---|
| [36] | IPDS | URLs | Accuracy: 93.28% | Novel approach to differentiate phishing and legitimate URLs | Ensuring the availability of the dataset would be challenging |
| [37] | CNN | PhishingCorpus and SpamAssasin | Accuracy: 99.42% | Used a huge dataset to detect phishing emails | Used a smaller dataset |
| [38] | Multi-label LSTM | Self-generated emails dataset | Accuracy: 92.7% | Used combined dataset | No comparison of the results |
| [40] | GRU-RNN+SVM | Spambase dataset | Accuracy: 98.7% | Claimed higher accuracy | Limited to one dataset |
| [41] | LSTM+Keras | 800 Turkish emails dataset | Accuracy: 100% | Proposed hybrid model | Limited dataset |
| [42] | RNNs | SA-JN and En-JN datasets | Accuracy: 98.91% and 96.74% | Outperformed state-of-the-art systems | Unrealistically hard |
| [43] | ANN, LSTM, and BILSTM | Self-generated Turkish emails dataset | Accuracy: 100% | Highest accuracy | Focused on the Turkish language only |
| [44] | GAN-based | PhishTank and MillerSmiles | TPR: 97% | Has used actual phishing dataset | Controlled environment |
| [45] | ML, DL, NLP | Rnron, APWG | Accuracy: 93% | - | Limited dataset |
| [46] | SVM combined with NLP and PNN | Self-generated emails dataset | Accuracy: 89% | Probabilistic NN would be more accurate in phishing detection | Only works on a small phishing dataset |
| [47] | CNN | HTML documents | Accuracy: 93% | Automatic phishing web page detection | Limited to HTML document analysis |
| Ref | Method | Data | Result | Innovations | Limitations |
|---|---|---|---|---|---|
| [50] | GCN+NLP | Self-generated email body text dataset | Accuracy: 98.2% | Enhance phishing detection on the email body text | Tested only English corpus |
| [51] | CNN and LSTM | Self-generated emails dataset | Accuracy: 96.34% | CNN with word embedding is most accurate | Tested only English corpus |
| [52] | D-Fence | Self-generated emails dataset | Accuracy: 99% | D-Fence maintained a high detection rate | Relied on multiple modules |
| [53] | Themis | Self-generated emails dataset | Accuracy: 99.87% | Combined email head and body | Focused only on analyzing the email structure |
| [54] | MLP | SpamBase, SpamAssassin, UK-2011 Webspam | Accuracy: 98.1% | Used several dataset and features | Spam detection study is inadequate |
| [55] | CNN and LSTM | Two datasets | Accuracy: 98.3% | Adam optimizer outperformed the SGD optimizer | Comparison limited to textual data classification |
| [56] | CNN | Self-generated emails dataset | Accuracy: 96.52% | Automated features extraction | Limited datasets |
| Ref | Method | Data | Result | Innovations | Limitations |
|---|---|---|---|---|---|
| [58] | Fitness-oriented, Levy improvement-based Dragonfly | N/A | Accuracy: 14.93% | Better performance than DT, KNN, and SVM | Misclassification existed |
| [59] | DL+NLP | Text-based and numerical-based datasets | Accuracy: 99% (text-based) and 94% (numerical-based) | Phish Responder better than other models | Limited data used; no explanation on the dataset employed |
| [61] | ML and DL | N/A | Accuracy: 98.5% | BiLSTM classifier performed better | Dataset did not contain variety of spam emails |
| [62] | TshPhish | PhishTank | Accuracy: 98.37% | Improved feature selection through evolutionary algorithms | Low recall rate |
| [63] | CCBLA | Two datasets | Accuracy: 99.85% | Combined CNN, bi-directional LSTM, and attention mechanism | Huge time consumption |
| [64] | LSTM and Glove word embedding | Two datasets | Accuracy: 98.39% and 99.49% | Used multiple datasets | Limited to one language |
| [65] | ML-based voting model | N/A | Accuracy: 98% | Used various feature retrieval algorithms | Lack of benchmark datasets |
| [66] | GRU-based Phishing URL detection | Phishing URLs | Accuracy: 98.30% | Highly accurate classifier | Limited detection of phishing attacks during COVID-19 |
| [67] | Deep learning | N/A | Accuracy: 92% | Incorporated less explored DL techniques | No details of empirical analysis |
| [69] | ML and DL | Spamassassin | Precision: 95.26%, recall: 97.18%, F1-score: 96% | Focused on the limitations of ML and DL algorithms | Broader email content analysis |
| [71] | DL | Email text | Accuracy: 88–100% | - | Cannot effectively handle modern phishing techniques |
| [73] | RCNN | Email Structure | N/A | Examined emails at multiple levels, including the header, body, character, and words | Limited to detecting phishing emails with header |
| [74] | Multiobjective optimization | SpamBase, SpamAssassin, and UK-2011 datasets | Accuracy: 97.5%, 98.3%, and 96.4% | - | Limited to detecting spam |
| Ref | Method | Data | Result | Innovations | Limitations |
|---|---|---|---|---|---|
| [77] | Deep ensemble learning | Email segments | AUC of 0.993 and TPR of 5% | Higher AUC result | Focus on privacy preservation in future work. |
| [78] | HELPHED | Imbalanced | F1-score: 99.42% | Superior result in the imbalance dataset | Focused on the detection and did not address prevention or mitigation of attacks. The dataset was imbalanced. |
| [79] | LBPS | Ethereum data | F1-score: 97.86% | Phishing scam account detection model | Tested the LBPS model only on Ethereum data. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thakur, K.; Ali, M.L.; Obaidat, M.A.; Kamruzzaman, A. A Systematic Review on Deep-Learning-Based Phishing Email Detection. Electronics 2023, 12, 4545. https://doi.org/10.3390/electronics12214545
Thakur K, Ali ML, Obaidat MA, Kamruzzaman A. A Systematic Review on Deep-Learning-Based Phishing Email Detection. Electronics. 2023; 12(21):4545. https://doi.org/10.3390/electronics12214545
Chicago/Turabian StyleThakur, Kutub, Md Liakat Ali, Muath A. Obaidat, and Abu Kamruzzaman. 2023. "A Systematic Review on Deep-Learning-Based Phishing Email Detection" Electronics 12, no. 21: 4545. https://doi.org/10.3390/electronics12214545