
Micro-Expression Spotting Based on VoVNet, Driven by Multi-Scale Features
Abstract
:1. Introduction
2. Related Work
3. Proposed Method
3.1. Micro-Expression Spotting Method Based on VoVNet
3.2. Optical Flow
3.3. VoVNet Module
3.4. FPN Module
3.5. Loss Function
4. Experiment
4.1. Dataset
4.2. Experimental Environment and Hyper-Parameters
4.3. Evaluation Metrics
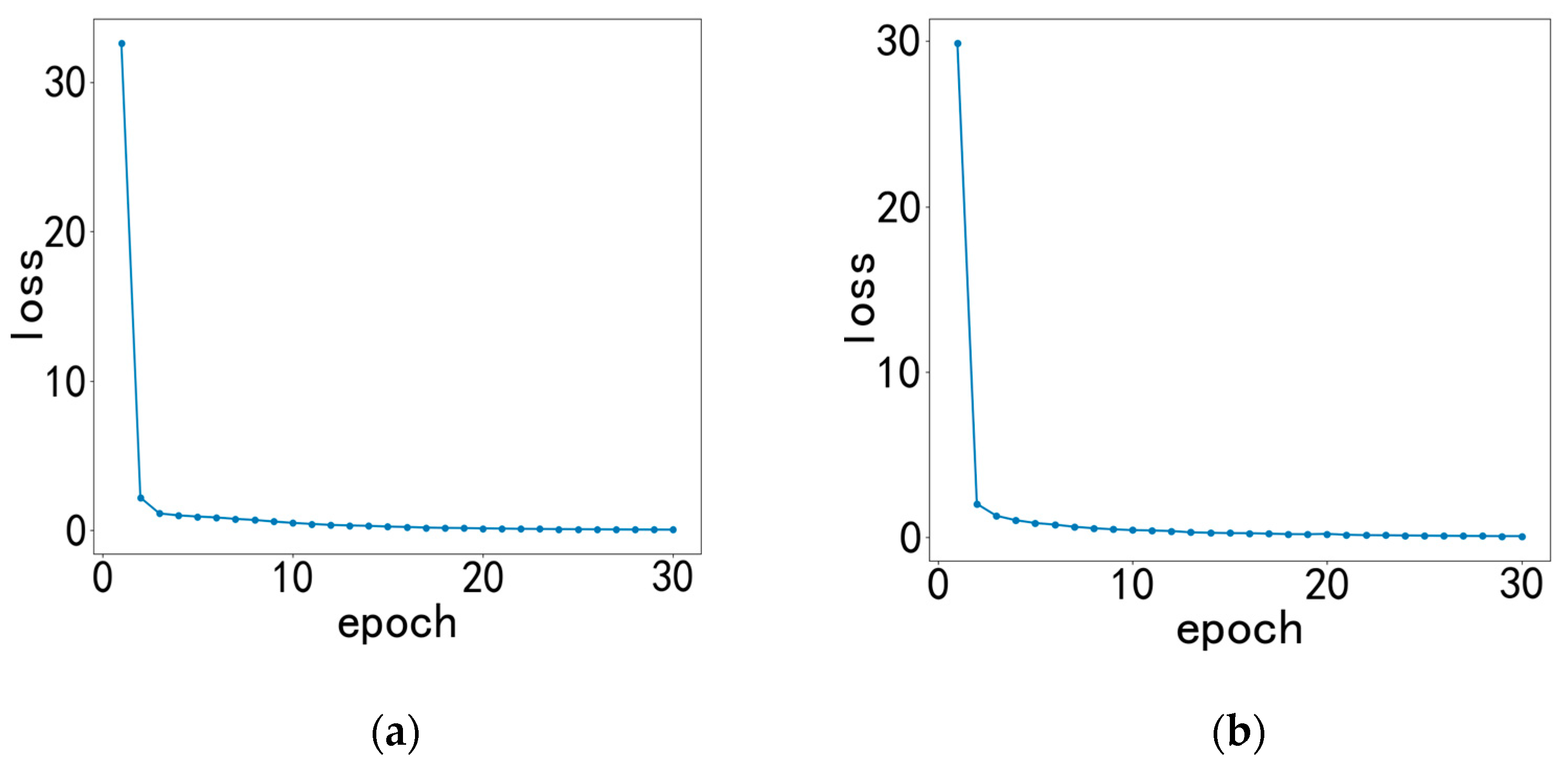
4.4. Results and Discussion
4.5. Ablation Experiment
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, W.W.; Yang, K.F.; Yan, H.M.; Li, Y.J. Weakly-supervised Micro-and Macro-expression Spotting Based on Multi-level Consistency. arXiv 2023, arXiv:2305.02734. [Google Scholar]
- Weinberger, S. Airport security: Intent to deceive? Nature 2010, 465, 412–416. [Google Scholar] [CrossRef] [PubMed]
- Owayjan, M.; Kashour, A.; Al Haddad, N.; Fadel, M.; Al Souki, G. The design and development of a lie detection system using facial micro-expressions. In Proceedings of the 2012 2nd International Conference on Advances in Computational Tools for Engineering Applications (ACTEA), Beirut, Lebanon, 12–15 December 2012; pp. 33–38. [Google Scholar]
- Russell, T.A.; Green, M.J.; Simpson, I.; Coltheart, M. Remediation of facial emotion perception in schizophrenia: Concomitant changes in visual attention. Schizophr. Res. 2008, 103, 248–256. [Google Scholar] [CrossRef] [PubMed]
- Yu, W.W.; Jiang, J.; Li, Y.J. LSSNet: A two-stream convolutional neural network for spotting macro-and micro-expression in long videos. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, China, 20–24 October 2021; pp. 4745–4749. [Google Scholar]
- Lee, Y.; Hwang, J.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Shreve, M.; Godavarthy, S.; Manohar, V.; Goldgof, D.; Sarkar, S. Towards macro-and micro-expression spotting in video using strain patterns. In Proceedings of the 2009 Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–6. [Google Scholar]
- Moilanen, A.; Zhao, G.; Pietikäinen, M. Spotting rapid facial movements from videos using appearance-based feature difference analysis. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1722–1727. [Google Scholar]
- Patel, D.; Zhao, G.; Pietikäinen, M. Spatiotemporal integration of optical flow vectors for micro-expression detection. In Proceedings of the Advanced Concepts for Intelligent Vision Systems: 16th International Conference, ACIVS 2015, Catania, Italy, 26–29 October 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 369–380. [Google Scholar]
- Li, J.; Soladié, C.; Séguier, R.; Wang, S.-J.; Yap, M.H. Spotting micro-expressions on long videos sequences. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- He, Y.; Wang, S.J.; Li, J.; Yap, M.H. Spotting macro-and micro-expression intervals in long video sequences. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition, Buenos Aires, Argentina, 16–20 November 2020; pp. 742–748. [Google Scholar]
- Xia, Z.; Feng, X.; Peng, J.; Peng, X.; Zhao, G. Spontaneous micro-expression spotting via geometric deformation modeling. Comput. Vis. Image Underst. 2016, 147, 87–94. [Google Scholar] [CrossRef]
- Hong, X.; Tran, T.K.; Zhao, G. Micro-expression spotting: A benchmark. arXiv 2017, arXiv:1710.02820. [Google Scholar]
- Nag, S.; Bhunia, A.K.; Konwer, A.; Roy, P.P. Facial micro-expression spotting and recognition using time contrasted feature with visual memory. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2022–2026. [Google Scholar]
- Verburg, M.; Menkovski, V. Micro-expression detection in long videos using optical flow and recurrent neural networks. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–6. [Google Scholar]
- Pan, H.; Xie, L.; Wang, Z. Local bilinear convolutional neural network for spotting macro-and micro-expression intervals in long video sequences. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition, Buenos Aires, Argentina, 16–20 November 2020; pp. 749–753. [Google Scholar]
- Yap, C.H.; Yap, M.H.; Davison, A.; Kendrick, C.; Li, J.; Wang, S.-J.; Cunningham, R. 3d-cnn for facial micro-and macro-expression spotting on long video sequences using temporal oriented reference frame. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 7016–7020. [Google Scholar]
- Liong, G.B.; See, J.; Wong, L.K. Shallow optical flow three-stream CNN for macro-and micro-expression spotting from long videos. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2643–2647. [Google Scholar]
- Fang, Y.; Deng, D.; Wu, L.; Jumelle, F.; Shi, B. RMES: Real-Time Micro-Expression Spotting Using Phase from Riesz Pyramid. arXiv 2023, arXiv:2305.05523. [Google Scholar]
- Li, J.; Dong, Z.; Liu, Y.; Wang, S.-J.; Zhuang, D. A micro-expression spotting method based on human attention mechanism. Adv. Psychol. Sci. 2019, 30, 2143–2153. [Google Scholar] [CrossRef]
- Cao, R. Micro-Expression Detection for Long Videos Based on Outlier Detection; South Western University of Finance and Economics: Chengdu, China, 2022. [Google Scholar]
- Li Song, Y. Research on Micro-Expression Spotting and Recognition Based on Convolutional Neural Networks; Shandong University: Jinan, China, 2021. [Google Scholar]
- Liu, L. Inverted Non-maximum Suppression for more Accurate and Neater Face Detection. arXiv 2023, arXiv:2305.10593. [Google Scholar]
- Ci, Y.; Wang, Y.; Chen, M.; Tang, S.; Bai, L.; Zhu, F.; Zhao, R.; Yu, F.; Qi, D.; Ouyang, W. UniHCP: A Unified Model for Human-Centric Perceptions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17840–17852. [Google Scholar]
- Oublal, K.; Dai, X. An advanced combination of semi-supervised Normalizing Flow & Yolo (YoloNF) to detect and recognize vehicle license plates. arXiv 2022, arXiv:2207.10777. [Google Scholar]
- Liong, S.T.; Gan, Y.S.; Zheng, D.; Li, S.-M.; Xu, H.-X.; Zhang, H.-Z.; Lyu, R.-K.; Liu, K.-H. Evaluation of the spatio-temporal features and gan for micro-expression recognition system. J. Signal Process. Syst. 2020, 92, 705–725. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Lee, Y.; Kim, H.; Park, E.; Cui, X.; Kim, H. Wide-residual-inception networks for real-time object detection. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 758–764. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22 October 2017; pp. 2980–2988. [Google Scholar]
- Yan, W.J.; Wu, Q.; Liu, Y.J.; Wang, S.-J.; Fu, X. CASME database: A dataset of spontaneous micro-expressions collected from neutralized faces. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–7. [Google Scholar]
- Li, X.; Pfister, T.; Huang, X.; Zhao, G.; Pietikäinen, M. A spontaneous micro-expression database: Inducement, collection and baseline. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Shanghai, China, 22–26 April 2013; pp. 1–6. [Google Scholar]
- Yan, W.J.; Li, X.; Wang, S.J.; Zhao, G.; Liu, Y.J.; Chen, Y.H.; Fu, X. CASME II: An improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef]
- Davison, A.K.; Lansley, C.; Costen, N.; Tan, K.; Yap, M.H. Samm: A spontaneous micro-facial movement dataset. IEEE Trans. Affect. Comput. 2016, 9, 116–129. [Google Scholar] [CrossRef]
- Qu, F.; Wang, S.J.; Yan, W.J.; Li, H.; Wu, S.; Fu, X. CAS(ME)2: A Database for Spontaneous Macro-Expression and Micro-Expression Spotting and Recognition. IEEE Trans. Affect. Comput. 2017, 9, 424–436. [Google Scholar] [CrossRef]
- Yap, C.H.; Kendrick, C.; Yap, M.H. Samm long videos: A spontaneous facial micro-and macro-expressions dataset. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition, Buenos Aires, Argentina, 16–20 November 2020; pp. 771–776. [Google Scholar]
- Ben, X.; Ren, Y.; Zhang, J.; Wang, S.J.; Kpalma, K.; Meng, W.; Liu, Y.J. Video-based facial micro-expression analysis: A survey of datasets, features and algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5826–5846. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Dong, Z.; Lu, S.; Wang, S.J.; Yan, W.J.; Ma, Y.; Liu, Y.; Huang, C.; Fu, X. CAS (ME)3: A third generation facial spontaneous micro-expression database with depth information and high ecological validity. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2782–2800. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Soladie, C.; Seguier, R. Local temporal pattern and data augmentation for micro-expression spotting. IEEE Trans. Affect. Comput. 2020, 14, 811–822. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Pan, H.; Xie, L.; Wang, Z. Spatio-temporal convolutional attention network for spotting macro-and micro-expression intervals. In Proceedings of the 1st Workshop on Facial Micro-Expression: Advanced Techniques for Facial Expressions Generation and Spotting, Virtual, China, 24 October 2021; pp. 25–30. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | VoVNet |
|---|---|
| Inception | 3 × 3conv, 64, stride = 2 3 × 3conv, 128, stride = 2 |
| OSA 1 | 3 × 3conv, 64, ×5 concat: 1 × 1conv, 128 |
| OSA 2 | 3 × 3conv, 80, ×5 concat: 1 × 1conv, 256 |
| OSA 3 | 3×3conv, 96, ×5 concat: 1 × 1conv, 384 |
| OSA 4 | 3 × 3conv, 112, ×5 concat: 1 × 1conv, 1 |
| Type | FPN |
|---|---|
| layer 1 | 3 × 1conv, 512 × 64, stride = 2 |
| layer 2 | 3 × 1conv, 1024 × 32, stride = 2 |
| layer3 | 3 × 1conv, 1024 × 16, stride = 2 |
| layer4 | 3 × 1conv, 1024 × 8, stride = 2 |
| layer5 | 3 × 1conv, 2048 × 4, stride = 2 |
| Dataset | Time | Resolution | Frame Rate | Number of Participants | Number of Samples | Number of Emotions | |
|---|---|---|---|---|---|---|---|
| CAS(ME)2 | 2018 | 640 × 480 | 30 | 22 | 300 (macro) 57 (micro) | 4 | |
| SAMM Long Videos | 2019 | 2040 × 1088 | 200 | 29 | 343 (macro) 159 (micro) | / | |
| MMEW | 2021 | 1920 × 1080 | 90 | 36 | 900 (macro) 300 (micro) | 7 | |
| CASME III | A | 2022 | 1280 × 720 | 30 | 100 | 3364 (macro) 1030 (micro) | 7 |
| B | 116 | ||||||
| C | 31 | ||||||
| Model | SAMM Long Video | CAS(ME)2 | ||||
|---|---|---|---|---|---|---|
| MaE | ME | Overall | MaE | ME | Overall | |
| Baseline [11] | 0.1863 | 0.0409 | 0.1193 | 0.0401 | 0.0118 | 0.0304 |
| MDMD [12] | 0.0629 | 0.0364 | 0.445 | 0.1196 | 0.0082 | 0.0376 |
| STCAN [42] | 0.1469 | 0.0125 | 0.1257 | 0.1250 | 0.0250 | 0.1168 |
| SOFTNet [19] | 0.2169 | 0.1520 | 0.1881 | 0.2410 | 0.1173 | 0.2022 |
| Article | 0.3849 | 0.1626 | 0.3156 | 0.2998 | 0.0689 | 0.2745 |
| Type | SAMM Long Video | CAS(ME)2 | ||||
|---|---|---|---|---|---|---|
| MaE | ME | Overall | MaE | ME | Overall | |
| No optical flow | 0.2500 | 0.0696 | 0.2162 | 0.2883 | 0.0344 | 0.2620 |
| Optical flow | 0.3849 | 0.1626 | 0.3156 | 0.2998 | 0.0689 | 0.2745 |
| Model | CAS(ME)2 | ||
|---|---|---|---|
| MaE | ME | Overall | |
| ResNet | 0.2495 | 0.0421 | 0.2253 |
| DenseNet | 0.3026 | 0.0459 | 0.2596 |
| VoVNet | 0.2998 | 0.0689 | 0.2745 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Wu, Z.; Wu, R. Micro-Expression Spotting Based on VoVNet, Driven by Multi-Scale Features. Electronics 2023, 12, 4459. https://doi.org/10.3390/electronics12214459
Yang J, Wu Z, Wu R. Micro-Expression Spotting Based on VoVNet, Driven by Multi-Scale Features. Electronics. 2023; 12(21):4459. https://doi.org/10.3390/electronics12214459
Chicago/Turabian StyleYang, Jun, Zilu Wu, and Renbiao Wu. 2023. "Micro-Expression Spotting Based on VoVNet, Driven by Multi-Scale Features" Electronics 12, no. 21: 4459. https://doi.org/10.3390/electronics12214459