

A Lightweight Network Based on Improved YOLOv5s for Insulator Defect Detection
Abstract
:1. Introduction
- (1)
- Replacement of lightweight backbone modules. By incorporating the C3Ghost and GhostConv structures, derived from the lightweight Ghost model, as replacements for the original YOLOv5s’ C3 and CBS structures, remarkable reductions in model parameters are achieved. This optimization leads to a substantial improvement in the real-time performance of object detection models on mobile or embedded devices, simultaneously reducing their computational and storage demands.
- (2)
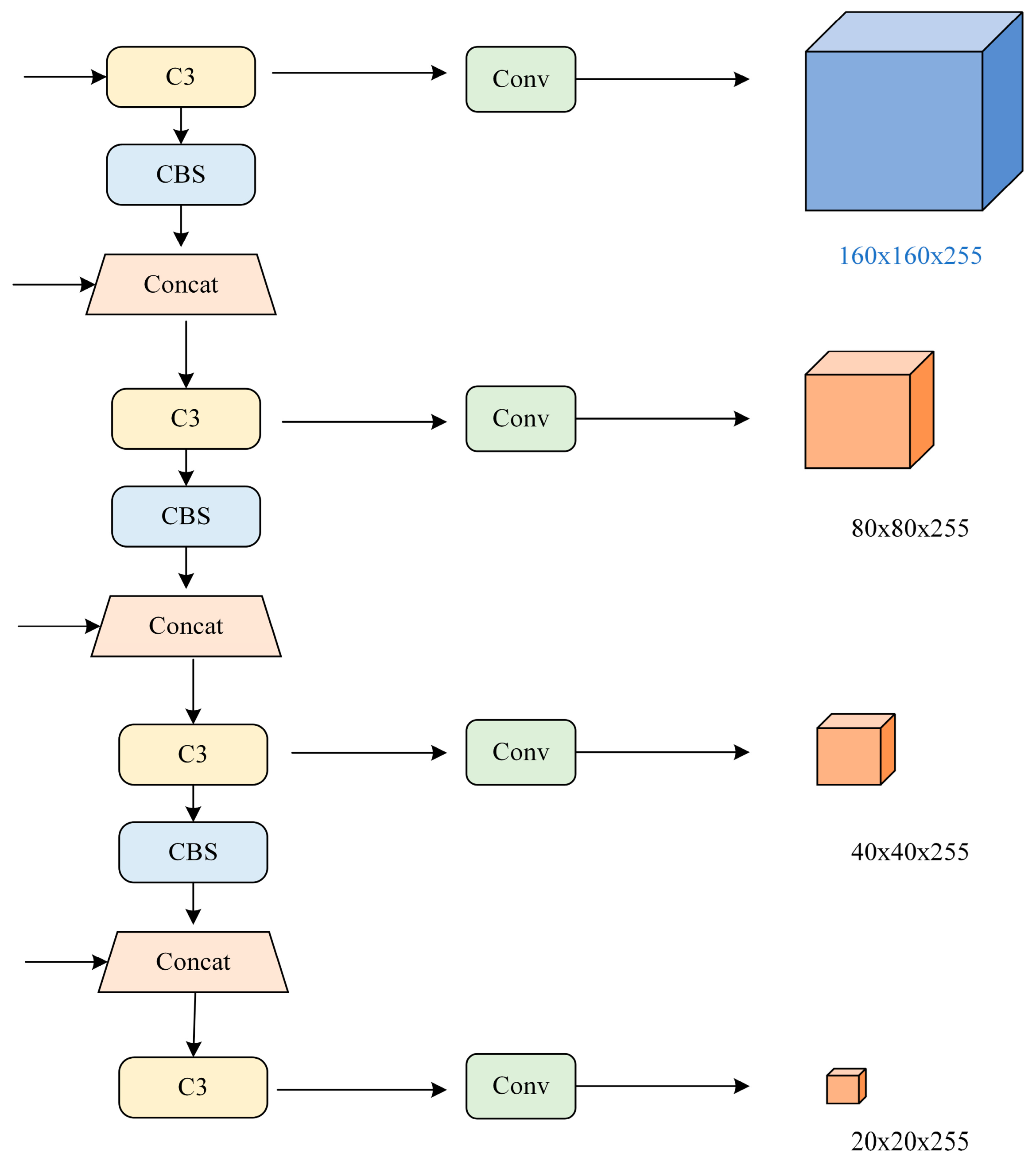
- Adding a small target detection layer and embedding an attention mechanism. A 160 × 160 scale output is added to the prediction section, while the ACmix attention mechanism is embedded in front of the 80 × 80 and 160 × 160 scales, which is used to reduce the missed and false detection of small target defects.
- (3)
- To optimize the prior bounding boxes and loss functions, EIoU Loss is replaced as the loss function of the proposed algorithm. It is more sensitive to the localization accuracy and can better reflect the object shape. Compared with the original loss function, it can make the model converge faster. At the same time, the anchors are clustered using K-means++, which makes the priori bounding boxes match better.
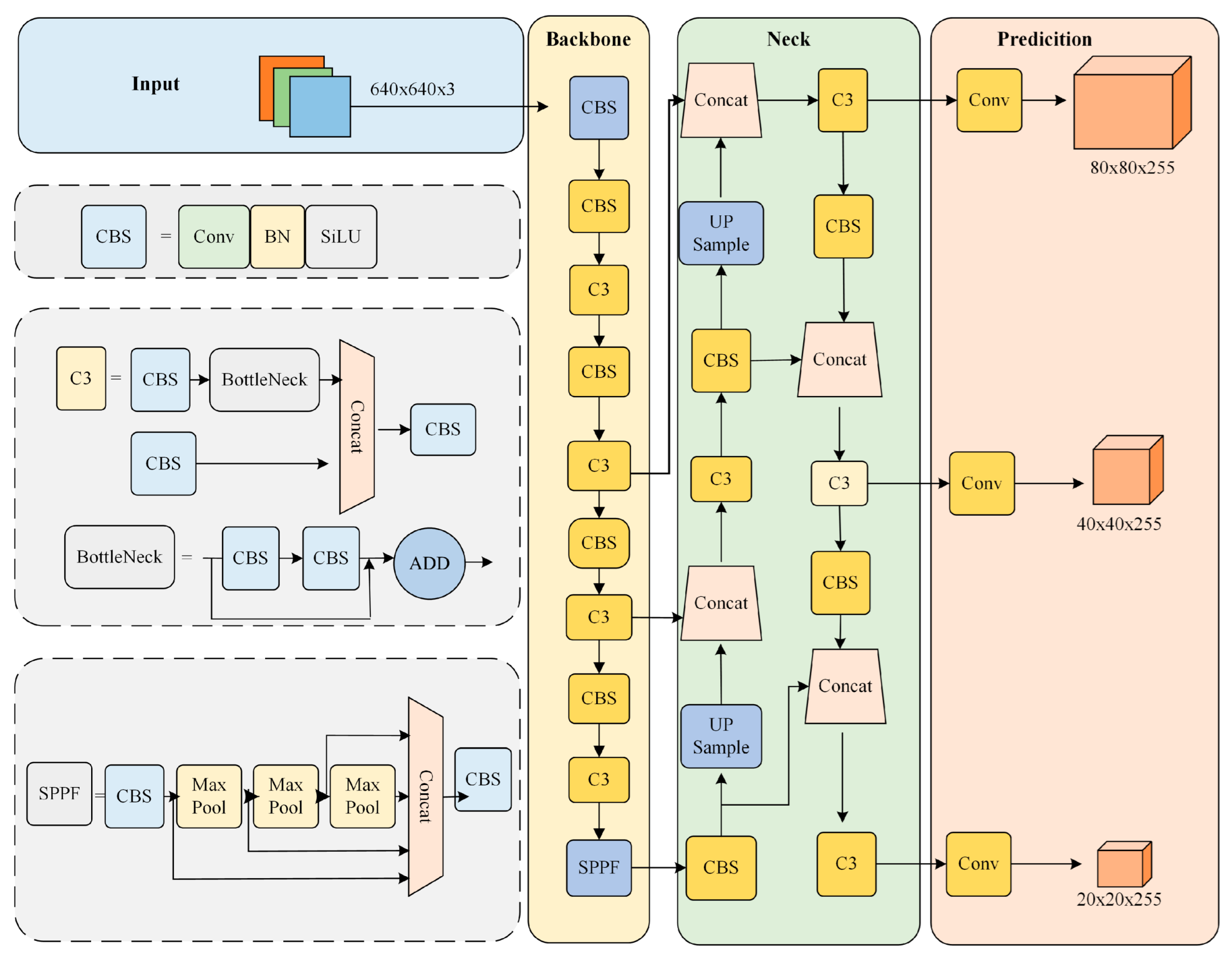
2. Original YOLOv5s and Improved YOLOv5s
3. Related Work
3.1. C3Ghost Module
3.2. Detection Layer for Small Object
3.3. On the Integration of Self-Attention and Convolution
3.4. Optimization of Loss Function
3.5. Optimisation of Anchor Frame Clustering
- 1.
- Determine the number of clustering centers k and the set of heights and widths for the dataset in this paper.
- 2.
- Randomly choose a point from the set to satisfy the initial clustering center .
- 3.
- Determine the distance between each remaining point x in the set M of and its nearest clustering center . The greater the distance between the previous box and the next clustering center, the greater the probability . This step should be repeated until k clustering centers are found.
- 4.
- Determine the distance between all points in the set and the cluster centers, and place the point in the category of cluster centers with the smallest distance. For the clustering results, recalculate each cluster category center .
- 5.
- When the cluster center of each clustering category no longer changes, repeat Step 2 and output cluster center results.
4. Experiment and Analysis
4.1. Data Acquisition and Pre-Processing
4.2. Experiment Environment
4.3. Evaluation Metrics of the Model
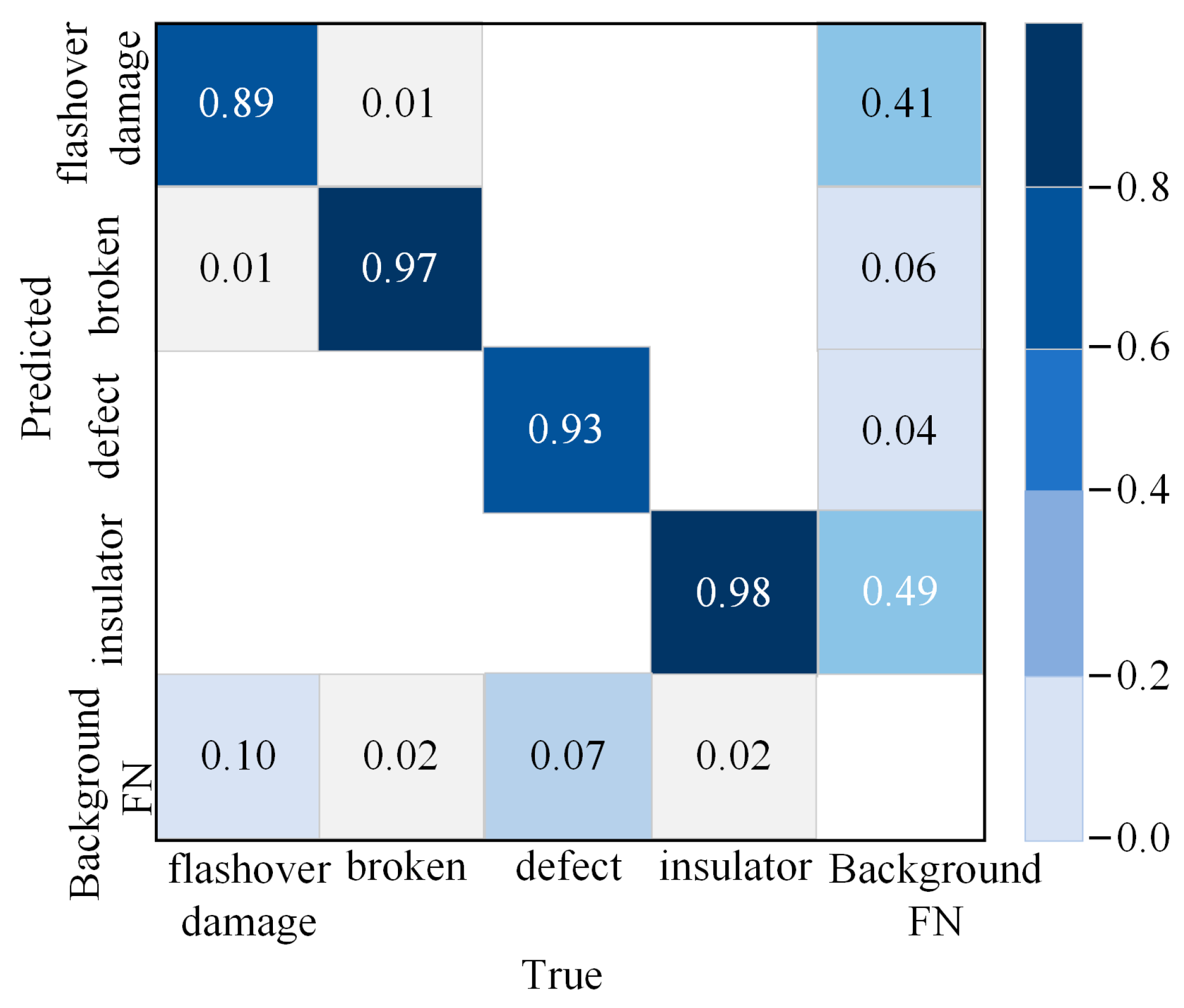
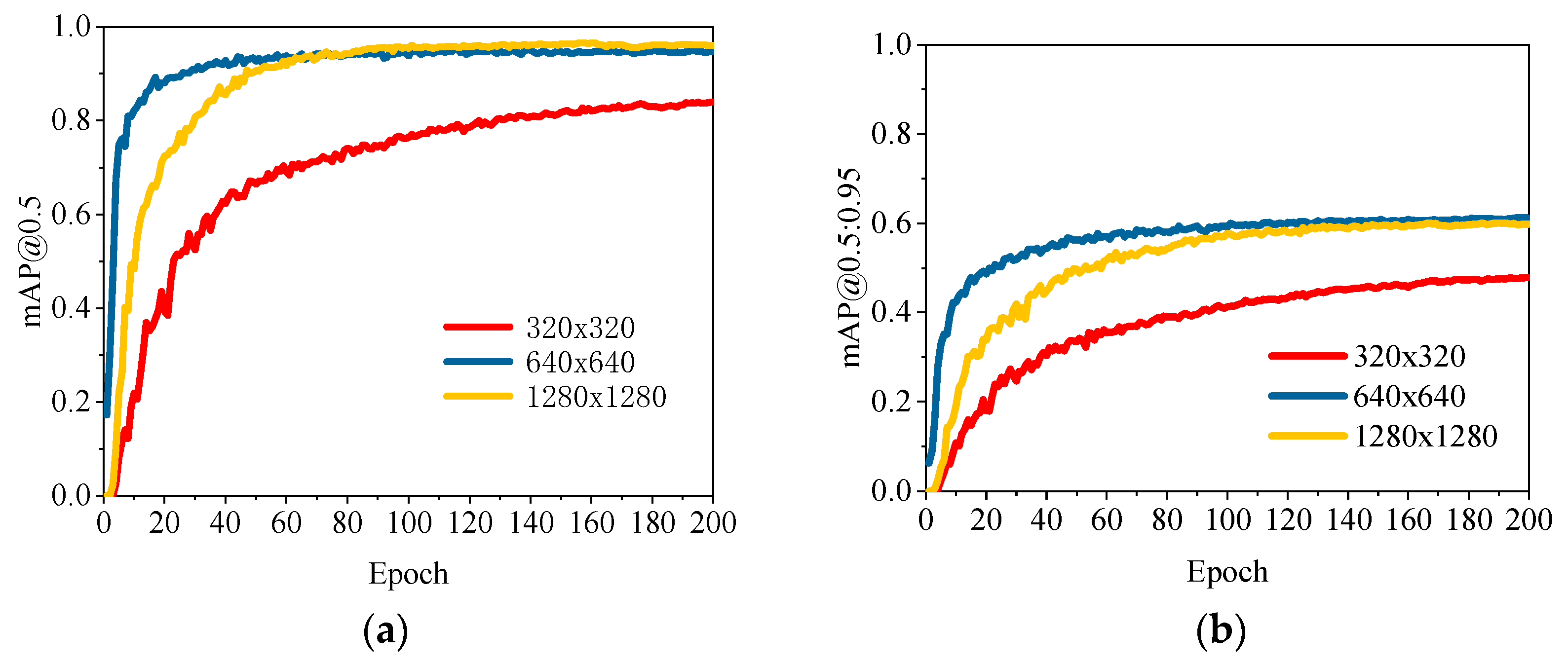
4.4. Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, L.; Fan, J.; Liu, Y. A review on state-of-the-art power line inspection techniques. IEEE Trans. Instrum. Meas. 2020, 69, 9350–9365. [Google Scholar] [CrossRef]
- Liu, J.J.; Liu, C.A.Y.; Wu, Y.Q. An Improved Method Based on Deep Learning for Insulator Fault Detection in Diverse Aerial Images. Energies 2021, 14, 4365. [Google Scholar] [CrossRef]
- Xiao, Y.Z.; Tian, Z.Q.; Yu, J.C. A review of object detection based on deep learning. Multim. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Guo, Z.M.; Tian, Y.Y.; Mao, W.D. A Robust Faster R-CNN Model with Feature Enhancement for Rust Detection of Transmission Line Fitting. Sensors 2022, 22, 7961. [Google Scholar] [CrossRef]
- Ou, J.H.; Wang, J.G.; Xue, J. Infrared Image Target Detection of Substation Electrical Equipment Using an Improved Faster R-CNN. IEEE Trans. Power Deliv. 2023, 38, 387–396. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D. SSD: Single shot multibox detector. In Proceedings of the 2016 European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Wei, B.Q.; Xie, Z.X.; Liu, Y.D. Online Monitoring Method for Insulator Self-explosion Based on Edge Computing and Deep Learning. CSEE J. Power Energy Syst. 2022, 8, 1684–1696. [Google Scholar]
- Liu, C.Y.; Wu, Y.Q.; Liu, J.J. Improved YOLOv3 Network for Insulator Detection in Aerial Images with Diverse Background Interference. Electronics 2021, 10, 771. [Google Scholar] [CrossRef]
- Yang, Z.S.; Xu, Z.; Wang, Y.H. Bidirection-Fusion-YOLOv3: An Improved Method for Insulator Defect Detection Using UAV Image. IEEE Trans. Instrum. Meas. 2022, 71, 3521408. [Google Scholar] [CrossRef]
- Han, G.J.; Zhao, L.; Li, Q. A Lightweight Algorithm for Insulator Target Detection and Defect Identification. Sensors 2023, 23, 1216. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ding, J.; Cao, H.A.; Ding, X.L. High Accuracy Real-Time Insulator String Defect Detection Method Based on Improved YOLOv5. Front. Energy Res. 2022, 10, 928164. [Google Scholar] [CrossRef]
- Li, Y.H.; Zou, G.P.; Zou, H.L. Insulators and Defect Detection Based on the Improved Focal Loss Function. Appl. Sci. 2022, 12, 10529. [Google Scholar] [CrossRef]
- Zhang, Z.D.; Zhang, B.; Lan, Z.C. FINet: An Insulator Dataset and Detection Benchmark Based on Synthetic Fog and Improved YOLOv5. IEEE Trans. Instrum. Meas. 2022, 71, 6006508. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the integration of self-attention and convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 815–825. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T.J.N. Focal and efficient IOU loss for accurate bounding box regression. arXiv 2022, arXiv:2101.08158. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clustering Algorithm | Recall | Fitness | Anchors |
|---|---|---|---|
| K-means | 0.9952 | 0.74872 | (13, 12) (26, 16) (17, 25) |
| (36, 29) (120, 24) (71, 45) | |||
| (37, 149) (187, 42) (409, 97) | |||
| K-means++ | 0.9981 (+0.29%) | 0.77200 (+2.32%) | (13, 13) (25, 18) (17, 70) |
| (43, 31) (117, 23) (115, 41) | |||
| (45, 165) (364, 52) (421, 71) | |||
| (402, 93) (427, 130) (365, 191) |
| Group | Model | Precision (%) | Recall (%) | mAP@0.5 (%) | Parameters (M) | FPS (f/s) |
|---|---|---|---|---|---|---|
| A | YOLOv5s (320 × 320) | 89.1 | 80.3 | 83.9 | 7.03 | 32.89 |
| B | YOLOv5s (640 × 640) | 95.4 | 91.9 | 94.6 | 7.03 | 32.36 |
| C | YOLOv5s (1280 × 1280) | 96.3 | 94.2 | 96.2 | 7.03 | 31.84 |
| D | YOLOv5s (640) + C3Ghost | 93.4 | 89.1 | 92.2 | 3.69 | 35.21 |
| E | YOLOv5s (640) + C3Ghost + 4Head | 93.0 | 89.4 | 92.4 | 4.06 | 33.22 |
| F | YOLOv5s (640) + C3Ghost + 4Head + ACmix | 95.0 | 90.4 | 93.5 | 4.14 | 32.89 |
| G | YOLOv5s (640) + C3Ghost + 4Head + ACmix + EIoU+K-means++ | 95.8 | 92.2 | 94.8 | 4.14 | 32.52 |
| Model | Input Size | Precision (%) | Recall (%) | mAP@0.5 (%) | Parameters (M) |
|---|---|---|---|---|---|
| Faster R-CNN | 640 × 640 | 96.8 | 93.2 | 95.5 | 108.9 |
| SSD | 640 × 640 | 88.7 | 85.2 | 88.6 | 26.93 |
| Centernet | 640 × 640 | 95.3 | 87.9 | 94.5 | 32.45 |
| YOLOv3 | 640 × 640 | 95.6 | 91.7 | 93.8 | 61.7 |
| YOLOv3-tiny | 640 × 640 | 91.2 | 86.8 | 90.2 | 8.7 |
| YOLOv5s | 640 × 640 | 95.4 | 91.9 | 94.6 | 7.03 |
| YOLOv7 | 640 × 640 | 94.7 | 90.9 | 93.7 | 37.2 |
| YOLOv8s | 640 × 640 | 96.9 | 93.8 | 96.4 | 11.14 |
| Ours | 640 × 640 | 96.2 | 92.9 | 94.8 | 4.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Yi, W.; Liu, M.; Wang, Y.; Hu, S.; Wu, M. A Lightweight Network Based on Improved YOLOv5s for Insulator Defect Detection. Electronics 2023, 12, 4292. https://doi.org/10.3390/electronics12204292
Liu C, Yi W, Liu M, Wang Y, Hu S, Wu M. A Lightweight Network Based on Improved YOLOv5s for Insulator Defect Detection. Electronics. 2023; 12(20):4292. https://doi.org/10.3390/electronics12204292
Chicago/Turabian StyleLiu, Cong, Wentao Yi, Min Liu, Yifeng Wang, Sheng Hu, and Minghu Wu. 2023. "A Lightweight Network Based on Improved YOLOv5s for Insulator Defect Detection" Electronics 12, no. 20: 4292. https://doi.org/10.3390/electronics12204292