
Progress of Placement Optimization for Accelerating VLSI Physical Design

Abstract
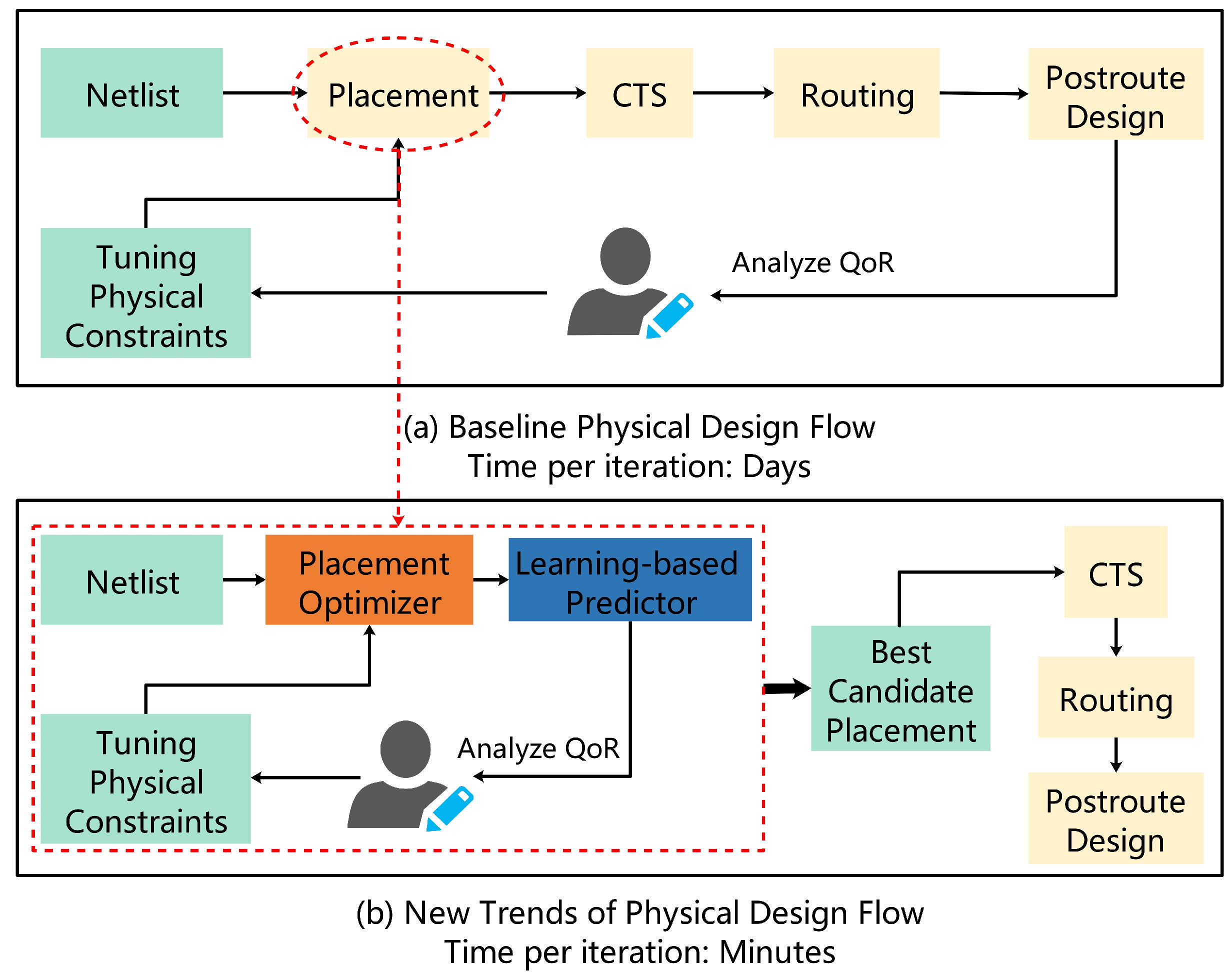
:1. Introduction
- 1.
- We provide a comprehensive overview of placement optimization from the perspective of accelerating VLSI PD. Problem definition, classical placement algorithms, computational acceleration, learning techniques, new trends, and new challenges are all well organized and discussed. The above are essential for understanding placement and advancing research but may have been simplified or ignored in previous reviews.
- 2.
- We observe a new trend of placement-centric VLSI PD flow and classify the placement development into optimizers and predictors. We discuss the deficiencies of classical placement algorithms in advanced technology nodes and point out future development directions for placement to consider accelerating VLSI PD.
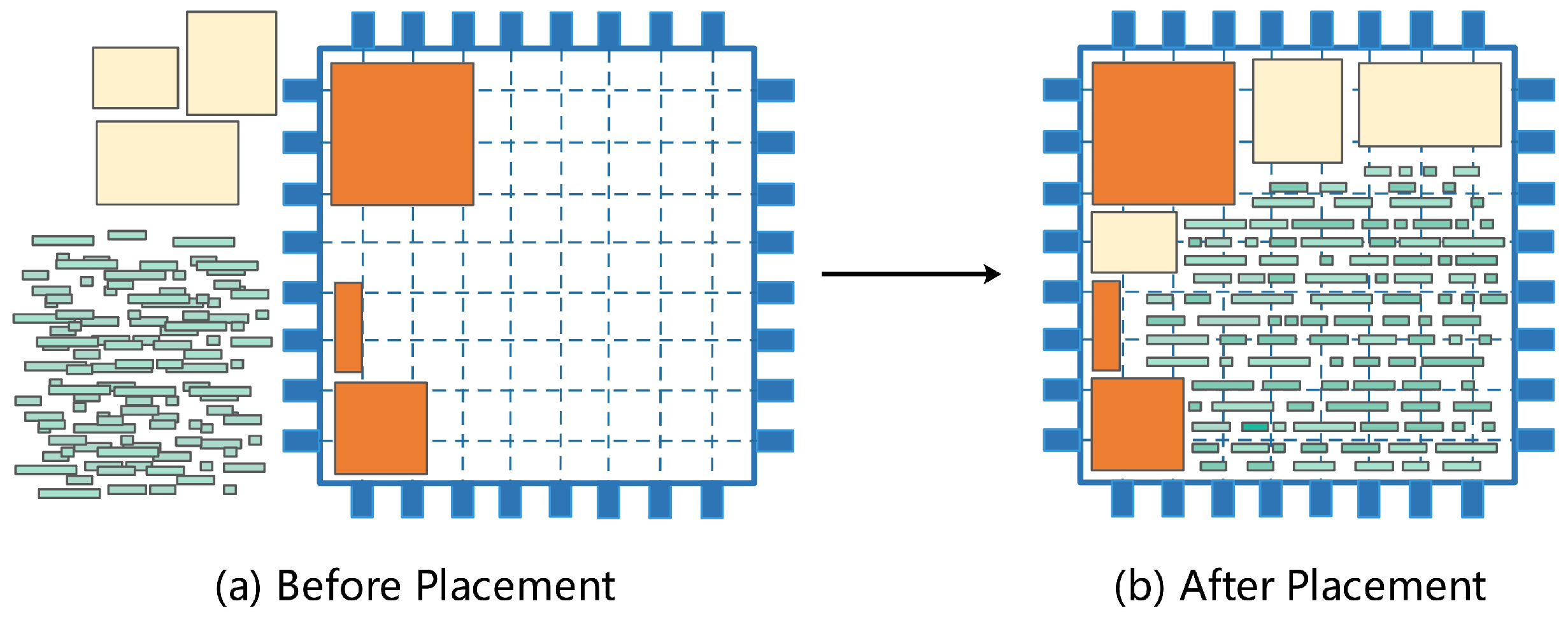
2. Problem Definition
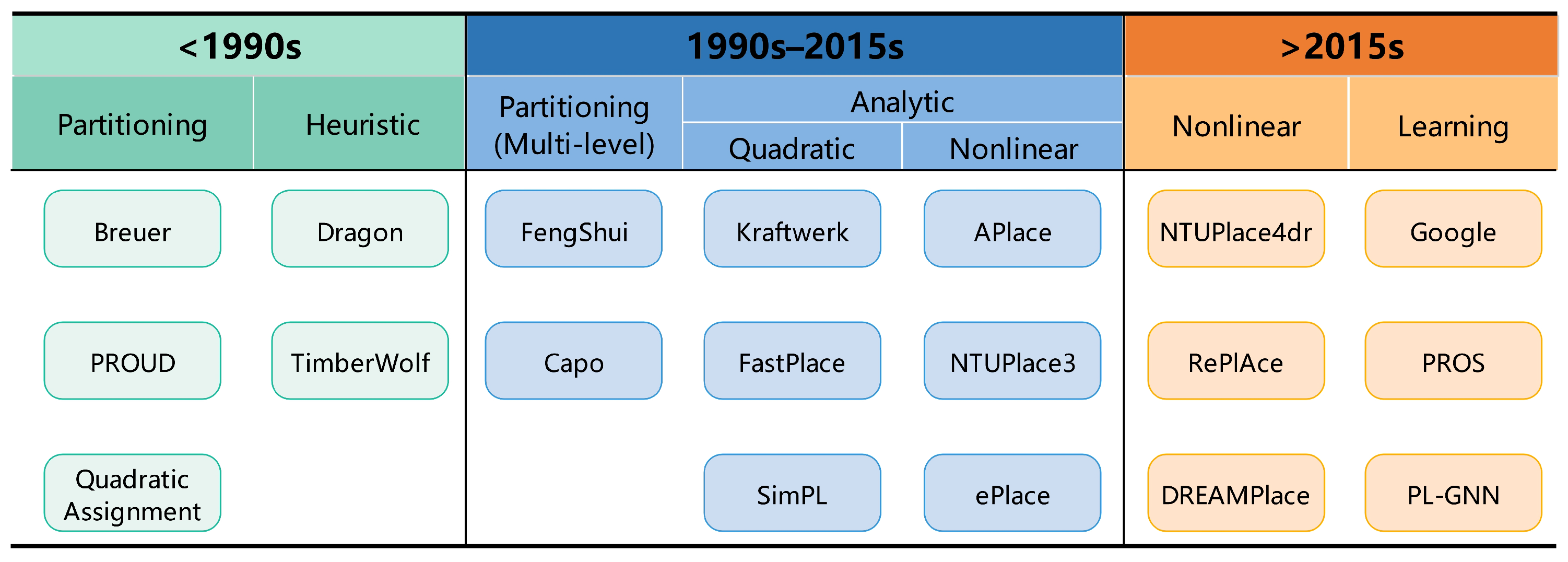
3. Classical Placement Algorithms
3.1. Partitioning-Based Algorithms
3.2. Heuristic Algorithms
3.3. Analytical Methods
3.4. Discussions
- 1.
- Classical placement algorithms have unsatisfactory solution quality. Limited by the huge solution space due to the large design scale, classical placement algorithms often have to compromise between runtime and solution quality, which brings suboptimal solutions.
- 2.
- Classical placement algorithms such as heuristics and nonlinear methods are very time-consuming when solving large-scale netlists. The vast time overhead does not help to complete VLSI PD quickly.
- 3.
- Classical placement algorithms lack foresight. Classical algorithms become complex or powerless when more optimization objectives and constraints are considered. Most classical algorithms in academic research only use wirelength as a metric for placement quality, which is far from predictive for downstream metrics. A poorly foresighted placement can lead to routing failures, costing time for design-flow iterations.
- 1.
- Algorithm improvements, including the improvement of classical placement algorithms and the newly proposed learning-based algorithms.
- 2.
- Computational acceleration, including the application of multi-threaded CPUs and GPUs to accelerate the placement-solution finding.
- 3.
- Learning-based predictors: application of ML or deep learning (DL) methods for predicting downstream metrics.
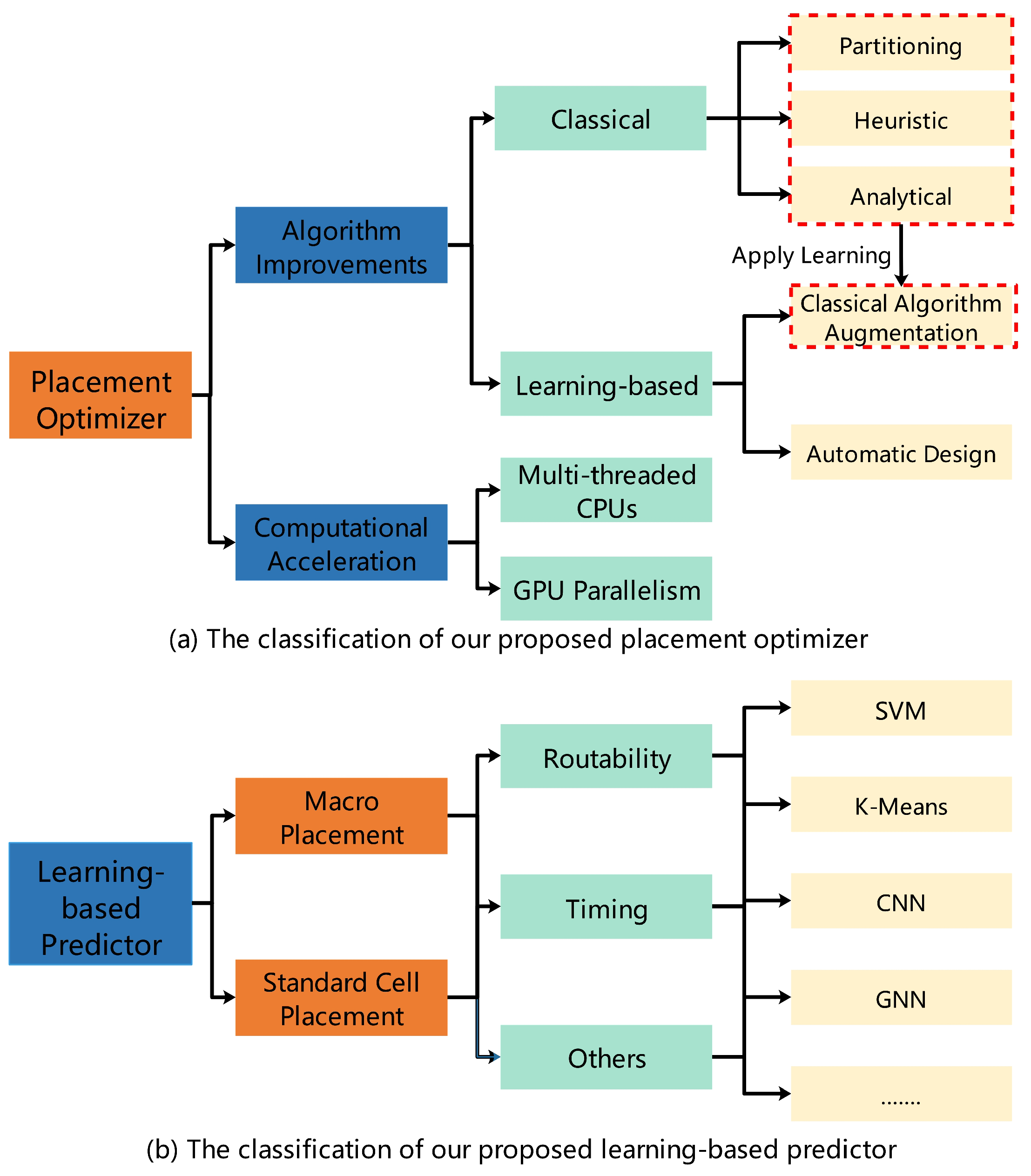
4. Placement Optimizer
4.1. Algorithm Improvements
4.1.1. Classical
4.1.2. Learning-Based
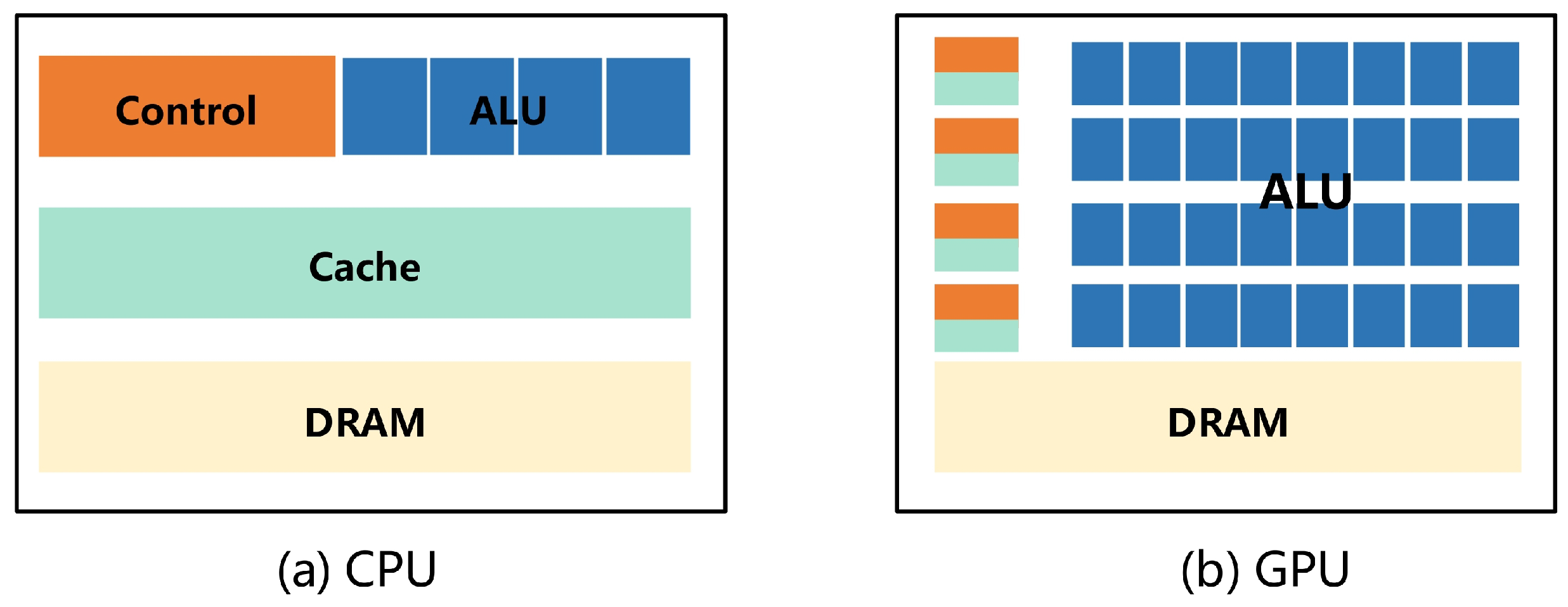
4.2. Computational Acceleration
5. Learning-Based Predictor
6. Open Challenges
- 1.
- Classical placement algorithms do not require large amounts of data for training compared to learning algorithms. However, the solution time may be too long to apply to increasingly complex designs. Keeping the classical placement algorithms feasible is a crucial challenge. It may be necessary to revisit the process of classical placement algorithms, rebalance solution time and algorithm quality, use learning algorithms to circumvent drawbacks, and so on.
- 2.
- Advanced challenges of GPU acceleration. These challenges include a lack of parallelism and irregular computation patterns, high expectations for quality and inevitable quality degradation, a lack of available baseline implementations, and high development cost. Future efforts on GPU acceleration include algorithmic innovation, pushing the speed limit on very hard kernels, and generating universal frameworks or programming models [93].
- 1.
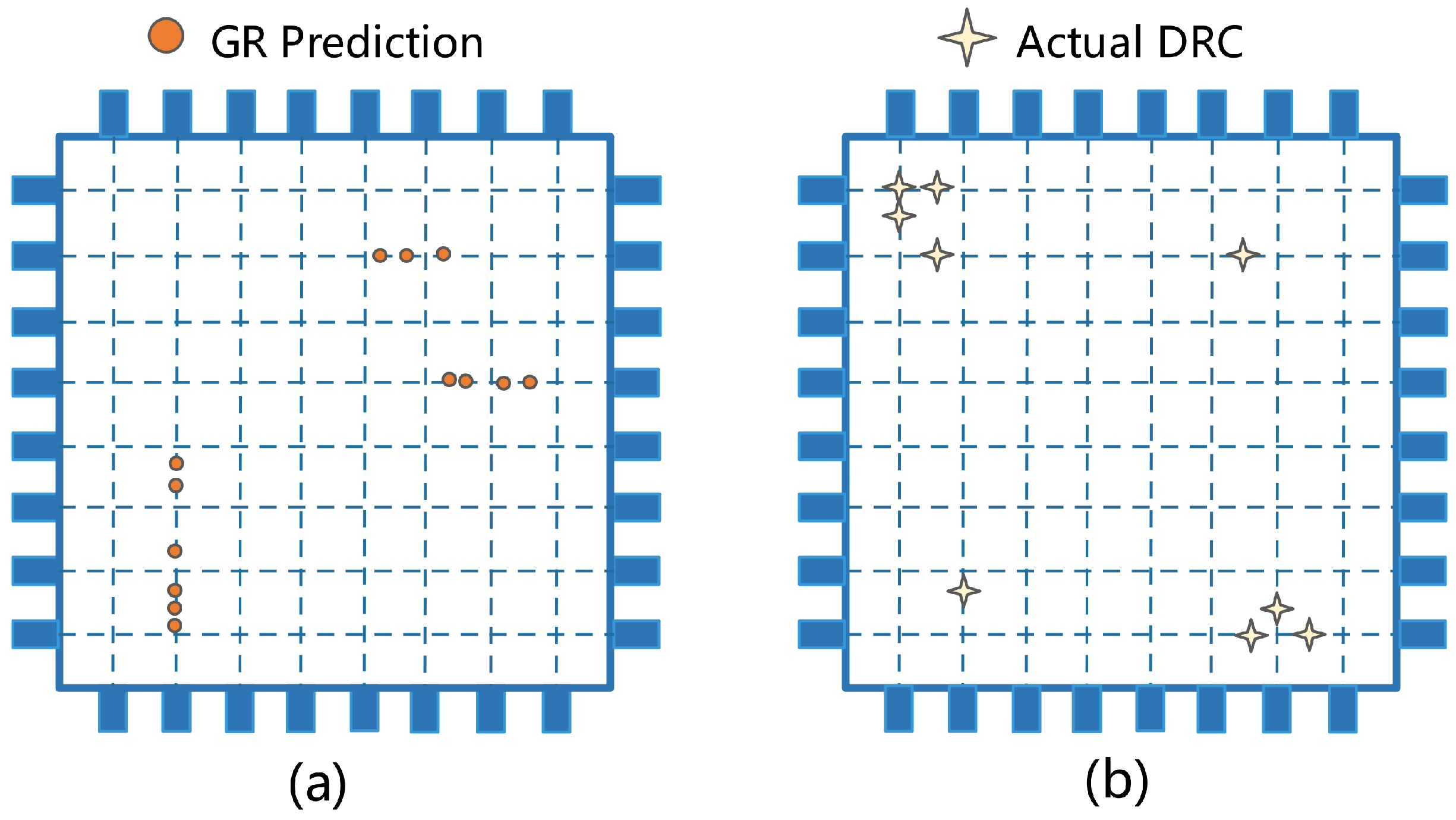
- What information needs to be predicted in different technology nodes. Each processing technology has its own rules. As a result, prediction for different technology nodes may require different methods and ML models. Taking routability prediction as an example, there is a large discrepancy between routing congestion and final detailed routing violations in advanced technology nodes, as shown in Figure 8. If routing congestion is predicted and placement is done under its guidance, it may lead to more modification work and a lengthy VLSI PD cycle.
- 2.
- Prediction needs to be more profound while maintaining accuracy. Prediction should increase its span across multiple design steps [121]. The authors of [122] also depicted that predicting post-route design quality during placement is preferred to predicting wirelength and congestion only. More profound predictions can help designers see further and avoid unnecessary iterations, thereby improving VLSI PD efficiency. However, the earlier the design, the fewer the features that can be extracted, which inevitably leads to a decline in model accuracy.
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Waldrop, M.M. The chips are down for Moore’s law. Nature 2016, 530, 144–147. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garey, M.R.; Johnson, D.S.; Stockmeyer, L. Some simplified NP-complete problems. In Proceedings of the STOC ’74, Sixth Annual ACM Symposium on Theory of Computing, Seattle, WA, USA, 30 April–2 May 1974; pp. 47–63. [Google Scholar] [CrossRef]
- Nam, G.J.; Alpert, C.J.; Villarrubia, P.; Winter, B.; Yildiz, M. The ISPD2005 placement contest and benchmark suite. In Proceedings of the ISPD ’05, 2005 International Symposium on Physical Design, San Francisco, CA, USA, 3–6 April 2005; pp. 216–220. [Google Scholar] [CrossRef]
- Nam, G.J. ISPD 2006 Placement Contest: Benchmark Suite and Results. In Proceedings of the ISPD ’06, 2006 International Symposium on Physical Design, San Jose, CA, USA, 9–12 April 2006; p. 167. [Google Scholar] [CrossRef]
- Viswanathan, N.; Alpert, C.J.; Sze, C.; Li, Z.; Nam, G.J.; Roy, J.A. The ISPD-2011 routability-driven placement contest and benchmark suite. In Proceedings of the ISPD ’11, 2011 International Symposium on Physical Design, Santa Barbara, CA, USA, 27–30 March 2011; pp. 141–146. [Google Scholar] [CrossRef]
- Yutsis, V.; Bustany, I.S.; Chinnery, D.; Shinnerl, J.R.; Liu, W.H. ISPD 2014 benchmarks with sub-45nm technology rules for detailed-routing-driven placement. In Proceedings of the 2014 on International Symposium on Physical Design-ISPD ’14, Petaluma, CA, USA, 30 March–2 April 2014; pp. 161–168. [Google Scholar] [CrossRef]
- Bustany, I.S.; Chinnery, D.; Shinnerl, J.R.; Yutsis, V. ISPD 2015 Benchmarks with Fence Regions and Routing Blockages for Detailed-Routing-Driven Placement. In Proceedings of the 2015 Symposium on International Symposium on Physical Design, Monterey, CA, USA, 29 March–1 April 2015; pp. 157–164. [Google Scholar] [CrossRef]
- Viswanathan, N.; Alpert, C.; Sze, C.; Li, Z.; Wei, Y. The DAC 2012 routability-driven placement contest and benchmark suite. In Proceedings of the 49th Annual Design Automation Conference on—DAC ’12, San Francisco, CA, USA, 3–7 June 2012; p. 774. [Google Scholar] [CrossRef]
- Viswanathan, N.; Alpert, C.; Sze, C.; Li, Z.; Wei, Y. ICCAD-2012 CAD contest in design hierarchy aware routability-driven placement and benchmark suite. In Proceedings of the International Conference on Computer-Aided Design-ICCAD ’12, San Jose, CA, USA, 5–8 November 2012; p. 345. [Google Scholar] [CrossRef]
- Kim, M.C.; Huj, J.; Viswanathan, N. ICCAD-2014 CAD contest in incremental timing-driven placement and benchmark suite: Special session paper: CAD contest. In Proceedings of the 2014 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 3–6 November 2014; pp. 361–366, ISSN 1558-2434. [Google Scholar] [CrossRef]
- Kim, M.C.; Hu, J.; Li, J.; Viswanathan, N. ICCAD-2015 CAD contest in incremental timing-driven placement and benchmark suite. In Proceedings of the 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 2–6 November 2015; pp. 921–926. [Google Scholar] [CrossRef]
- Mirhoseini, A.; Goldie, A.; Yazgan, M.; Jiang, J.W.; Songhori, E.; Wang, S.; Lee, Y.J.; Johnson, E.; Pathak, O.; Nazi, A.; et al. A graph placement methodology for fast chip design. Nature 2021, 594, 207–212. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Hu, J.; He, Y.; Liu, J.; Ma, M.; Shen, Z.; Wu, J.; Xu, Y.; Zhang, H.; Zhong, K.; et al. Machine Learning for Electronic Design Automation: A Survey. ACM Trans. Des. Autom. Electron. Syst. 2021, 26, 1–46. [Google Scholar] [CrossRef]
- Hao, R.; Cai, Y.; Zhou, Q. Intelligent and kernelized placement: A survey. Integration 2022, 86, 44–50. [Google Scholar] [CrossRef]
- Alpert, C.J.; Mehta, D.P.; Sapatnekar, S.S. (Eds.) Handbook of Algorithms for Physical Design Automation; OCLC: Ocn214935396; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Cheon, Y.; Ho, P.H.; Kahng, A.B.; Reda, S.; Wang, Q. Power-aware placement. In Proceedings of the DAC ’05, 42nd Annual Design Automation Conference, Anaheim, CA, USA, 13–17 June 2005; pp. 795–800. [Google Scholar] [CrossRef]
- Kahng, A.B.; Kang, S.M.; Li, W.; Liu, B. Analytical thermal placement for VLSI lifetime improvement and minimum performance variation. In Proceedings of the 2007 25th International Conference on Computer Design, Lake Tahoe, CA, USA, 7–10 October 2007; pp. 71–77, ISSN 1063-6404. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.C.; Chang, Y.W. Fogging Effect Aware Placement in Electron Beam Lithography. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Roy, J.A.; Papa, D.A.; Adya, S.N.; Chan, H.H.; Ng, A.N.; Lu, J.F.; Markov, I.L. Capo: Robust and scalable open-source min-cut floorplacer. In Proceedings of the ISPD ’05, 2005 International Symposium on Physical Design, San Francisco, CA, USA, 3–6 April 2005; pp. 224–226. [Google Scholar] [CrossRef]
- Can Yildiz, M.; Madden, P.H. Improved cut sequences for partitioning based placement. In Proceedings of the 38th Conference on Design Automation—DAC ’01, Las Vegas, NV, USA, 18–22 June 2001; pp. 776–779. [Google Scholar] [CrossRef]
- Wang, M.; Yang, X.; Sarrafzadeh, M. Dragon2000: Standard-cell placement tool for large industry circuits. In Proceedings of the IEEE/ACM International Conference on Computer Aided Design, San Jose, CA, USA, 5–9 November 2000; pp. 260–263, ISSN 1092-3152. [Google Scholar] [CrossRef]
- Sechen, C.; Sangiovanni-Vincentelli, A. The TimberWolf placement and routing package. IEEE J. Solid-State Circuits 1985, 20, 510–522. [Google Scholar] [CrossRef]
- Viswanathan, N.; Chu, C.N. FastPlace: Efficient analytical placement using cell shifting, iterative local refinement, and a hybrid net model. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2005, 24, 722–733. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Chu, C.; Wu, G. POLAR 3.0: An ultrafast global placement engine. In Proceedings of the 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 2–6 November 2015; pp. 520–527. [Google Scholar] [CrossRef]
- Kim, M.C.; Lee, D.J.; Markov, I.L. SimPL: An effective placement algorithm. In Proceedings of the 2010 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 7–11 November 2010; pp. 649–656. [Google Scholar] [CrossRef] [Green Version]
- Hsu, M.K.; Chen, Y.F.; Huang, C.C.; Chou, S.; Lin, T.H.; Chen, T.C.; Chang, Y.W. NTUplace4h: A Novel Routability-Driven Placement Algorithm for Hierarchical Mixed-Size Circuit Designs. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2014, 33, 1914–1927. [Google Scholar] [CrossRef]
- Lu, J.; Zhuang, H.; Chen, P.; Chang, H.; Chang, C.C.; Wong, Y.C.; Sha, L.; Huang, D.; Luo, Y.; Teng, C.C.; et al. ePlace-MS: Electrostatics-Based Placement for Mixed-Size Circuits. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2015, 34, 685–698. [Google Scholar] [CrossRef] [Green Version]
- Cheng, C.K.; Kahng, A.B.; Kang, I.; Wang, L. RePlAce: Advancing Solution Quality and Routability Validation in Global Placement. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2019, 38, 1717–1730. [Google Scholar] [CrossRef]
- Fogaça, M.; Kahng, A.B.; Reis, R.; Wang, L. Finding placement-relevant clusters with fast modularity-based clustering. In Proceedings of the ASPDAC ’19, 24th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 21–24 January 2019; pp. 569–576. [Google Scholar] [CrossRef]
- Kernighan, B.W.; Lin, S. An Efficient Heuristic Procedure for Partitioning Graphs. Bell Syst. Tech. J. 1970, 49, 291–307. [Google Scholar] [CrossRef]
- Fiduccia, C.; Mattheyses, R. A Linear-Time Heuristic for Improving Network Partitions. In Proceedings of the 19th Design Automation Conference, Las Vegas, NV, USA, 14–16 June 1982; pp. 175–181, ISSN 0146-7123. [Google Scholar] [CrossRef]
- Ou, S.; Pedram, M. Timing-driven bipartitioning with replication using iterative quadratic programming. In Proceedings of the ASP-DAC ’99 Asia and South Pacific Design Automation Conference 1999 (Cat. No.99EX198), Hong Kong, China, 21 January 1999; Volume 1, pp. 105–108. [Google Scholar] [CrossRef] [Green Version]
- Blutman, K.; Fatemi, H.; Kahng, A.B.; Kapoor, A.; Li, J.; de Gyvez, J.P. Floorplan and placement methodology for improved energy reduction in stacked power-domain design. In Proceedings of the 2017 22nd Asia and South Pacific Design Automation Conference (ASP-DAC), Chiba, Japan, 16–19 January 2017; pp. 444–449. [Google Scholar] [CrossRef]
- Sze, C.; Wang, T.-C. Performance-driven multi-level clustering for combinational circuits. In Proceedings of the ASP-DAC Asia and South Pacific Design Automation Conference, Kitakyushu, Japan, 21–24 January 2003; pp. 729–740. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.C.; Chang, Y.W. Modern floorplanning based on B/sup */-tree and fast simulated annealing. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2006, 25, 637–650. [Google Scholar] [CrossRef]
- Chen, X.; Lin, G.; Chen, J.; Zhu, W. An Adaptive Hybrid Genetic Algorithm for VLSI Standard Cell Placement Problem. In Proceedings of the 2016 3rd International Conference on Information Science and Control Engineering (ICISCE), Beijing, China, 8–10 July 2016; pp. 163–167. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Zaruba, D.; Zaporozhets, D.; Kureichik, V. Artificial Bee Colony Algorithm—A Novel Tool for VLSI Placement. In Proceedings of the First International Scientific Conference “Intelligent Information Technologies for Industry” (IITI’16), Rostov-on-Don–Sochi, Russia, 16–21 May 2016; Abraham, A., Kovalev, S., Tarassov, V., Snášel, V., Eds.; Series Title: Advances in Intelligent Systems and Computing. Springer International Publishing: Cham, Switzerland, 2016; Volume 450, pp. 433–442. [Google Scholar] [CrossRef]
- Spindler, P.; Schlichtmann, U.; Johannes, F. Kraftwerk2—A Fast Force-Directed Quadratic Placement Approach Using an Accurate Net Model. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2008, 27, 1398–1411. [Google Scholar] [CrossRef]
- Fan, S. An Introduction to Krylov Subspace Methods. arXiv 2018, arXiv:1811.09025. [Google Scholar]
- Kleinhans, J.; Sigl, G.; Johannes, F.; Antreich, K. GORDIAN: VLSI placement by quadratic programming and slicing optimization. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1991, 10, 356–365. [Google Scholar] [CrossRef] [Green Version]
- Brenner, U.; Struzyna, M. Faster and better global placement by a new transportation algorithm. In Proceedings of the 42nd Annual Conference on Design Automation—DAC ’05, San Diego, CA, USA, 13–17 June 2005; pp. 591–596. [Google Scholar] [CrossRef]
- Xiu, Z.; Rutenbar, R.A. Mixed-size placement with fixed macrocells using grid-warping. In Proceedings of the 2007 International Symposium on Physical Design—ISPD ’07, Austin, TX, USA, 18–21 March 2007; pp. 103–110. [Google Scholar] [CrossRef]
- Naylor, W.C.; Donelly, R.; Sha, L. Non-Linear Optimization System and Method for Wire Length and Delay Optimization for an Automatic Electric Circuit Placer. U.S. Patent 6301693B1, 9 October 2001. [Google Scholar]
- Hsu, M.K.; Chang, Y.W.; Balabanov, V. TSV-aware analytical placement for 3D IC designs. In Proceedings of the DAC ’11, 48th Design Automation Conference, San Diego, CA, USA, 5–10 June 2011; pp. 664–669. [Google Scholar] [CrossRef] [Green Version]
- Chou, S.; Hsu, M.K.; Chang, Y.W. Structure-aware placement for datapath-intensive circuit designs. In Proceedings of the DAC ’12, 49th Annual Design Automation Conference, San Francisco, CA, USA, 3–7 June 2012; pp. 762–767. [Google Scholar] [CrossRef]
- Chan, T.F.; Cong, J.; Shinnerl, J.R.; Sze, K.; Xie, M. mPL6: Enhanced multilevel mixed-size placement. In Proceedings of the 2006 International Symposium on Physical Design—ISPD ’06, San Jose, CA, USA, 9–12 April 2006; pp. 212–214. [Google Scholar] [CrossRef]
- Lu, J.; Chen, P.; Chang, C.C.; Sha, L.; Huang, D.J.H.; Teng, C.C.; Cheng, C.K. ePlace: Electrostatics-Based Placement Using Fast Fourier Transform and Nesterov’s Method. ACM Trans. Des. Autom. Electron. Syst. 2015, 20, 1–34. [Google Scholar] [CrossRef]
- Chen, T.C.; Jiang, Z.W.; Hsu, T.C.; Chen, H.C.; Chang, Y.W. NTUplace3: An Analytical Placer for Large-Scale Mixed-Size Designs With Preplaced Blocks and Density Constraints. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2008, 27, 1228–1240. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Chen, J.; Peng, Z.; Zhu, W.; Chang, Y.W. Generalized augmented lagrangian and its applications to VLSI global placement. In Proceedings of the 55th Annual Design Automation Conference, San Francisco, CA, USA, 24–29 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Mirhoseini, A.; Goldie, A.; Yazgan, M.; Jiang, J.; Songhori, E.; Wang, S.; Lee, Y.J.; Johnson, E.; Pathak, O.; Bae, S.; et al. Chip Placement with Deep Reinforcement Learning. arXiv 2020, arXiv:2004.10746. [Google Scholar]
- Chang, C.H.; Chang, Y.W.; Chen, T.C. A novel damped-wave framework for macro placement. In Proceedings of the 2017 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Irvine, CA, USA, 13–16 November 2017; pp. 504–511. [Google Scholar] [CrossRef]
- Vidal-Obiols, A.; Cortadella, J.; Petit, J.; Galceran-Oms, M.; Martorell, F. RTL-Aware Dataflow-Driven Macro Placement. In Proceedings of the 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 186–191. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.M.; Deng, Y.L.; Yang, Y.C.; Chen, J.J.; Chen, Y.C. A Novel Macro Placement Approach based on Simulated Evolution Algorithm. In Proceedings of the 2019 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Westminster, CO, USA, 4–7 November 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Lin, J.M.; Deng, Y.L.; Yang, Y.C.; Chen, J.J.; Lu, P.C. Dataflow-Aware Macro Placement Based on Simulated Evolution Algorithm for Mixed-Size Designs. IEEE Trans. VLSI Syst. 2021, 29, 973–984. [Google Scholar] [CrossRef]
- Shunmugathammal, M.; Columbus, C.C.; Anand, S. A nature inspired optimization algorithm for VLSI fixed-outline floorplanning. Analog. Integr. Circuits Signal Process. 2020, 103, 173–186. [Google Scholar] [CrossRef]
- Ye, Y.; Yin, X.; Chen, Z.; Hong, Z.; Fan, X.; Dong, C. A novel method on discrete particle swarm optimization for fixed-outline floorplanning. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Information Systems (ICAIIS), Dalian, China, 20–22 March 2020; pp. 591–595. [Google Scholar] [CrossRef]
- Zaporozhets, D.; Zaruba, D.; Kulieva, N. Hybrid Heuristic Algorithm for VLSI Placement. In Proceedings of the 2019 International Russian Automation Conference (RusAutoCon), Sochi, Russia, 8–14 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Sun, F.K.; Chang, Y.W. BiG: A Bivariate Gradient-Based Wirelength Model for Analytical Circuit Placement. In Proceedings of the 56th Annual Design Automation Conference 2019, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhu, W.; Huang, Z.; Chen, J.; Chang, Y.W. Analytical solution of Poisson’s equation and its application to VLSI global placement. In Proceedings of the International Conference on Computer-Aided Design, San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Huang, C.C.; Lee, H.Y.; Lin, B.Q.; Yang, S.W.; Chang, C.H.; Chen, S.T.; Chang, Y.W.; Chen, T.C.; Bustany, I. NTUplace4dr: A Detailed-Routing-Driven Placer for Mixed-Size Circuit Designs with Technology and Region Constraints. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 669–681. [Google Scholar] [CrossRef]
- Mangiras, D.; Stefanidis, A.; Seitanidis, I.; Nicopoulos, C.; Dimitrakopoulos, G. Timing-Driven Placement Optimization Facilitated by Timing-Compatibility Flip-Flop Clustering. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 2835–2848. [Google Scholar] [CrossRef]
- Arora, H.; Banerjee, A. A quadratic approach for routability driven placement design: Initial insight. In Proceedings of the 2015 International Conference on VLSI Systems, Architecture, Technology and Applications (VLSI-SATA), Bengaluru, India, 8–10 January 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Gu, J.; Jiang, Z.; Lin, Y.; Pan, D.Z. DREAMPlace 3.0: Multi-electrostatics based robust VLSI placement with region constraints. In Proceedings of the 39th International Conference on Computer-Aided Design, Virtual Event, 2–5 November 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Lu, J.; Zhuang, H.; Kang, I.; Chen, P.; Cheng, C.K. ePlace-3D: Electrostatics based Placement for 3D-ICs. In Proceedings of the ISPD ’16, 2016 on International Symposium on Physical Design, Santa Rosa, CA, USA, 3–6 April 2016; pp. 11–18. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.M.; Chen, T.T.; Chang, Y.F.; Chang, W.Y.; Shyu, Y.T.; Chang, Y.J.; Lu, J.M. A fast thermal-aware fixed-outline floorplanning methodology based on analytical models. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8, ISSN 1558-2434. [Google Scholar]
- Liu, S.; Sun, Q.; Liao, P.; Lin, Y.; Yu, B. Global Placement with Deep Learning-Enabled Explicit Routability Optimization. In Proceedings of the 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 1821–1824. [Google Scholar] [CrossRef]
- Liao, P.; Liu, S.; Chen, Z.; Lv, W.; Lin, Y.; Yu, B. DREAMPlace 4.0: Timing-driven Global Placement with Momentum-based Net Weighting. In Proceedings of the 2022 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, 14–23 March 2022; pp. 939–944. [Google Scholar] [CrossRef]
- Lin, J.M.; Huang, C.W.; Zane, L.C.; Tsai, M.C.; Lin, C.L.; Tsai, C.F. Routability-driven Global Placer Target on Removing Global and Local Congestion for VLSI Designs. In Proceedings of the 2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), Munich, Germany, 1–4 November 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Karypis, G.; Kumar, V. A Hypergraph Partitioning Package; Army HPC Research Center, Department of Computer Science & Engineering, University of Minnesota: Minneapolis, MN, USA, 1998. [Google Scholar]
- Lu, Y.C.; Pentapati, S.; Lim, S.K. The Law of Attraction: Affinity-Aware Placement Optimization using Graph Neural Networks. In Proceedings of the ISPD ’21, 2021 International Symposium on Physical Design, Virtual Event, 22–24 March 2021; pp. 7–14. [Google Scholar] [CrossRef]
- Lu, Y.C.; Lim, S.K. VLSI Placement Optimization using Graph Neural Networks. In Proceedings of the 34th Advances in Neural Information Processing Systems (NeurIPS) Workshop on ML for Systems, Virtual, 6–12 December 2020. [Google Scholar]
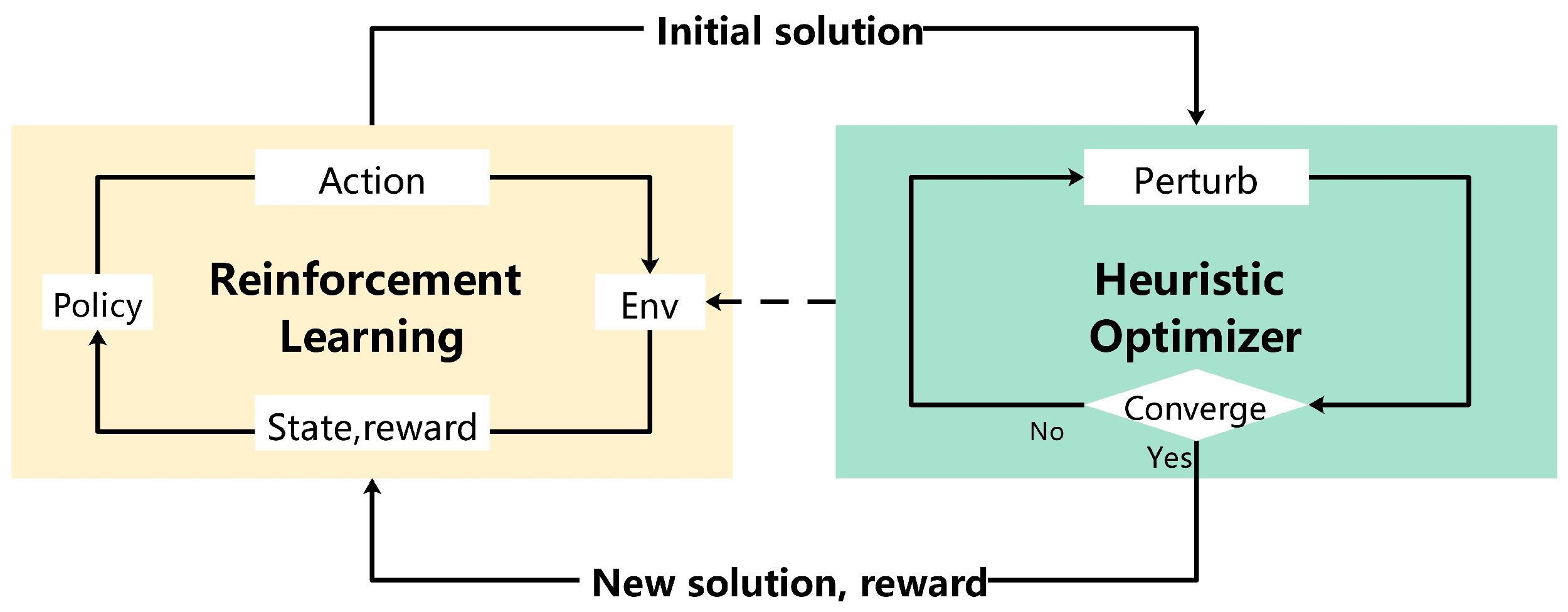
- Cai, Q.; Hang, W.; Mirhoseini, A.; Tucker, G.; Wang, J.; Wei, W. Reinforcement Learning Driven Heuristic Optimization. arXiv 2019, arXiv:1906.06639. [Google Scholar]
- Vashisht, D.; Rampal, H.; Liao, H.; Lu, Y.; Shanbhag, D.; Fallon, E.; Kara, L.B. Placement in Integrated Circuits using Cyclic Reinforcement Learning and Simulated Annealing. arXiv 2020, arXiv:2011.07577. [Google Scholar]
- Kirby, R.; Nottingham, K.; Roy, R.; Godil, S.; Catanzaro, B. Guiding Global Placement With Reinforcement Learning. CoRR 2021, abs/2109.02631. [Google Scholar]
- Agnesina, A.; Pentapati, S.; Lim, S.K. A General Framework For VLSI Tool Parameter Optimization with Deep Reinforcement Learning. In Proceedings of the NeurIPS 2020 Workshop on Machine Learning for Systems, Virtual, 6–12 December 2020. [Google Scholar]
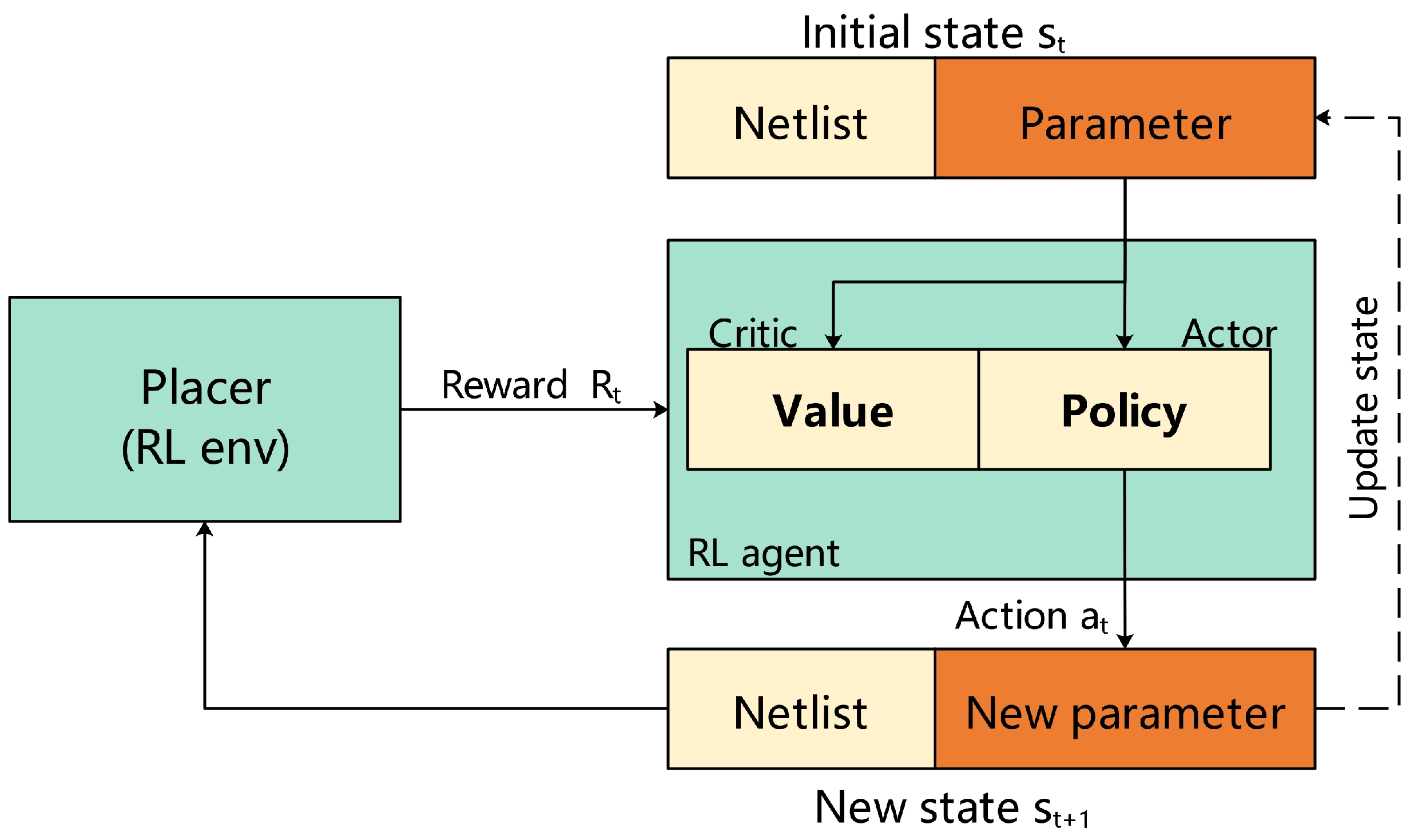
- Agnesina, A.; Chang, K.; Lim, S.K. VLSI placement parameter optimization using deep reinforcement learning. In Proceedings of the 39th International Conference on Computer-Aided Design, Virtual Event, 2–5 November 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Kwon, J.; Ziegler, M.M.; Carloni, L.P. A Learning-Based Recommender System for Autotuning Design Flows of Industrial High-Performance Processors. In Proceedings of the 56th Annual Design Automation Conference 2019, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Xie, Z.; Fang, G.Q.; Huang, Y.H.; Ren, H.; Zhang, Y.; Khailany, B.; Fang, S.Y.; Hu, J.; Chen, Y.; Barboza, E.C. FIST: A Feature-Importance Sampling and Tree-Based Method for Automatic Design Flow Parameter Tuning. arXiv 2020, arXiv:2011.13493. [Google Scholar] [CrossRef]
- Geng, H.; Xu, Q.; Ho, T.Y.; Yu, B. PPATuner: Pareto-driven tool parameter auto-tuning in physical design via gaussian process transfer learning. In Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 10–14 July 2022; pp. 1237–1242. [Google Scholar] [CrossRef]
- Geng, H.; Chen, T.; Ma, Y.; Zhu, B.; Yu, B. PTPT: Physical Design Tool Parameter Tuning via Multi-Objective Bayesian Optimization. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2022, 42, 178–189. [Google Scholar] [CrossRef]
- Geng, H.; Chen, T.; Sun, Q.; Yu, B. Techniques for CAD Tool Parameter Auto-tuning in Physical Synthesis: A Survey (Invited Paper). In Proceedings of the 2022 27th Asia and South Pacific Design Automation Conference (ASP-DAC), Taipei, Taiwan, 17–20 January 2022; pp. 635–640. [Google Scholar] [CrossRef]
- Goldie, A.; Mirhoseini, A. Placement Optimization with Deep Reinforcement Learning. In Proceedings of the 2020 International Symposium on Physical Design, Taipei, Taiwan, 20–23 September 2020; pp. 3–7. [Google Scholar] [CrossRef] [Green Version]
- Cheng, R.; Yan, J. On Joint Learning for Solving Placement and Routing in Chip Design. In Proceedings of the Advances in Neural Information Processing Systems 34, Virtual, 6–12 December 2020; pp. 16508–16519. [Google Scholar]
- Jiang, Z.; Songhori, E.; Wang, S.; Goldie, A.; Mirhoseini, A.; Jiang, J.; Lee, Y.J.; Pan, D.Z. Delving into Macro Placement with Reinforcement Learning. arXiv 2021, arXiv:2109.02587. [Google Scholar] [CrossRef]
- Lai, Y.; Mu, Y.; Luo, P. MaskPlace: Fast Chip Placement via Reinforced Visual Representation Learning. arXiv 2022, arXiv:2211.13382. [Google Scholar] [CrossRef]
- He, Z.; Ma, Y.; Zhang, L.; Liao, P.; Wong, N.; Yu, B.; Wong, M.D. Learn to Floorplan through Acquisition of Effective Local Search Heuristics. In Proceedings of the 2020 IEEE 38th International Conference on Computer Design (ICCD), Hartford, CT, USA, 18–21 October 2020; pp. 324–331. [Google Scholar] [CrossRef]
- Lin, Y.; Dhar, S.; Li, W.; Ren, H.; Khailany, B.; Pan, D.Z. DREAMPlace: Deep Learning Toolkit-Enabled GPU Acceleration for Modern VLSI Placement. In Proceedings of the 56th Annual Design Automation Conference 2019, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Lin, Y.; Li, W.; Gu, J.; Ren, H.; Khailany, B.; Pan, D.Z. ABCDPlace: Accelerated Batch-Based Concurrent Detailed Placement on Multithreaded CPUs and GPUs. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 5083–5096. [Google Scholar] [CrossRef]
- Al-Kawam, A.; Harmanani, H.M. A Parallel GPU Implementation of the Timber Wolf Placement Algorithm. In Proceedings of the 2015 12th International Conference on Information Technology—New Generations, Las Vegas, NV, USA, 13–15 April 2015; pp. 792–795. [Google Scholar] [CrossRef]
- Lin, C.X.; Wong, M.D.F. Accelerate analytical placement with GPU: A generic approach. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1345–1350, ISSN 1558-1101. [Google Scholar] [CrossRef]
- Lin, Y.; Pan, D.Z.; Ren, H.; Khailany, B. DREAMPlace 2.0: Open-Source GPU-Accelerated Global and Detailed Placement for Large-Scale VLSI Designs. In Proceedings of the 2020 China Semiconductor Technology International Conference (CSTIC), Shanghai, China, 26 June 2020–17 July 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Lin, Y. GPU acceleration in VLSI back-end design: Overview and case studies. In Proceedings of the 39th International Conference on Computer-Aided Design, Virtual, 2–5 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Guo, Z.; Mai, J.; Lin, Y. Ultrafast CPU/GPU Kernels for Density Accumulation in Placement. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 1123–1128. [Google Scholar] [CrossRef]
- Lee, C.K. Deep Learning Creativity in EDA. In Proceedings of the 2020 International Symposium on VLSI Design, Automation and Test (VLSI-DAT), Hsinchu, Taiwan, 10–13 August 2020; p. 1, ISSN 2472-9124. [Google Scholar] [CrossRef]
- Kahng, A.B. New directions for learning-based IC design tools and methodologies. In Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju, Republic of Korea, 22–25 January 2018; pp. 405–410. [Google Scholar] [CrossRef]
- Huang, Y.H.; Xie, Z.; Fang, G.Q.; Yu, T.C.; Ren, H.; Fang, S.Y.; Chen, Y.; Hu, J. Routability-Driven Macro Placement with Embedded CNN-Based Prediction Model. In Proceedings of the 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 180–185. [Google Scholar] [CrossRef]
- Chan, W.T.J.; Chung, K.Y.; Kahng, A.B.; MacDonald, N.D.; Nath, S. Learning-based prediction of embedded memory timing failures during initial floorplan design. In Proceedings of the 2016 21st Asia and South Pacific Design Automation Conference (ASP-DAC), Macao, China, 25–28 January 2016; pp. 178–185. [Google Scholar] [CrossRef]
- Cheng, W.K.; Guo, Y.Y.; Wu, C.S. Evaluation of routability-driven macro placement with machine-learning technique. In Proceedings of the 2018 7th International Symposium on Next Generation Electronics (ISNE), Taipei, Taiwan, 7–9 May 2018; pp. 1–3. [Google Scholar] [CrossRef]
- Cheng, W.K.; Wu, C.S. Machine Learning Techniques for Building and Evaluation of Routability-driven Macro Placement. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics—Taiwan (ICCE-TW), Yilan, Taiwan, 20–22 May 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Gao, X.; Jiang, Y.M.; Shao, L.; Raspopovic, P.; Verbeek, M.E.; Sharma, M.; Rashingkar, V.; Jalota, A. Congestion and Timing Aware Macro Placement Using Machine Learning Predictions from Different Data Sources: Cross-design Model Applicability and the Discerning Ensemble. In Proceedings of the ISPD ’22, 2022 International Symposium on Physical Design, Virtual, 27–30 March 2022; pp. 195–202. [Google Scholar] [CrossRef]
- Liang, R.; Xiang, H.; Pandey, D.; Reddy, L.; Ramji, S.; Nam, G.J.; Hu, J. DRC Hotspot Prediction at Sub-10 nm Process Nodes Using Customized Convolutional Network. In Proceedings of the ISPD ’20, 2020 International Symposium on Physical Design, Taipei, Taiwan, 20–23 September 2020; pp. 135–142. [Google Scholar] [CrossRef]
- Chen, J.; Kuang, J.; Zhao, G.; Huang, D.J.H.; Young, E.F.Y. PROS: A plug-in for routability optimization applied in the state-of-the-art commercial EDA tool using deep learning. In Proceedings of the 39th International Conference on Computer-Aided Design, Virtual, 2–5 November 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Chan, W.T.J.; Du, Y.; Kahng, A.B.; Nath, S.; Samadi, K. BEOL stack-aware routability prediction from placement using data mining techniques. In Proceedings of the 2016 IEEE 34th International Conference on Computer Design (ICCD), Scottsdale, AZ, USA, 2–5 October 2016; pp. 41–48. [Google Scholar] [CrossRef]
- Tabrizi, A.F.; Darav, N.K.; Rakai, L.; Kennings, A.; Behjat, L. Detailed routing violation prediction during placement using machine learning. In Proceedings of the 2017 International Symposium on VLSI Design, Automation and Test (VLSI-DAT), Hsinchu, Taiwan, 24–27 April 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Xie, Z.; Huang, Y.H.; Fang, G.Q.; Ren, H.; Fang, S.Y.; Chen, Y.; Corporation, N. RouteNet: Routability prediction for mixed-size designs using convolutional neural network. In Proceedings of the International Conference on Computer-Aided Design, San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Chan, W.T.J.; Ho, P.H.; Kahng, A.B.; Saxena, P. Routability Optimization for Industrial Designs at Sub-14nm Process Nodes Using Machine Learning. In Proceedings of the 2017 ACM on International Symposium on Physical Design, Portland, OR, USA, 19–22 March 2017; pp. 15–21. [Google Scholar] [CrossRef]
- Chen, L.C.; Huang, C.C.; Chang, Y.L.; Chen, H.M. A learning-based methodology for routability prediction in placement. In Proceedings of the 2018 International Symposium on VLSI Design, Automation and Test (VLSI-DAT), Hsinchu, Taiwan, 16–19 April 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Chen, X.; Di, Z.X.; Wu, W.; Feng, Q.Y.; Shi, J.Y. Detailed Routing Short Violations Prediction Method Using Graph Convolutional Network. In Proceedings of the 2020 IEEE 15th International Conference on Solid-State Integrated Circuit Technology (ICSICT), Kunming, China, 3–6 November 2020; pp. 1–3. [Google Scholar] [CrossRef]
- Tabrizi, A.F.; Rakai, L.; Darav, N.K.; Bustany, I.; Behjat, L.; Xu, S.; Kennings, A. A Machine Learning Framework to Identify Detailed Routing Short Violations from a Placed Netlist. In Proceedings of the 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Tabrizi, A.F.; Darav, N.K.; Rakai, L.; Bustany, I.; Kennings, A.; Behjat, L. Eh?Predictor: A Deep Learning Framework to Identify Detailed Routing Short Violations From a Placed Netlist. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 1177–1190. [Google Scholar] [CrossRef]
- Lu, Y.C.; Lee, J.; Agnesina, A.; Samadi, K.; Lim, S.K. GAN-CTS: A Generative Adversarial Framework for Clock Tree Prediction and Optimization. In Proceedings of the 2019 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Westminster, CO, USA, 4–7 November 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Liang, R.; Xie, Z.; Jung, J.; Chauha, V.; Chen, Y.; Hu, J.; Xiang, H.; Nam, G.J. Routing-Free Crosstalk Prediction. In Proceedings of the 2020 IEEE/ACM International Conference On Computer Aided Design (ICCAD), Virtual, 2–5 November 2020; pp. 1–9, ISSN 1558-2434. [Google Scholar]
- Lee, Y.Y.; Ruan, S.J.; Chen, P.C. Predictable Coupling Effect Model for Global Placement Using Generative Adversarial Networks with an Ordinary Differential Equation Solver. IEEE Trans. Circuits Syst. II 2021, 69, 2261–2265. [Google Scholar] [CrossRef]
- Wang, B.; Shen, G.; Li, D.; Hao, J.; Liu, W.; Huang, Y.; Wu, H.; Lin, Y.; Chen, G.; Heng, P.A. LHNN: Lattice hypergraph neural network for VLSI congestion prediction. In Proceedings of the DAC ’22, 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 10–14 July 2022; pp. 1297–1302. [Google Scholar] [CrossRef]
- Xie, Z.; Pan, J.; Chang, C.C.; Liang, R.; Barboza, E.C.; Chen, Y. Deep Learning for Routability. In Machine Learning Applications in Electronic Design Automation; Ren, H., Hu, J., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 35–61. ISBN 978-3-031-13074-8. [Google Scholar]
- Chen, G.; Pui, C.W.; Li, H.; Chen, J.; Jiang, B.; Young, E.F.Y. Detailed routing by sparse grid graph and minimum-area-captured path search. In Proceedings of the ASPDAC ’19, 24th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 21–24 January 2019; pp. 754–760. [Google Scholar] [CrossRef]
- Chai, Z.; Zhao, Y.; Lin, Y.; Liu, W.; Wang, R.; Huang, R. CircuitNet: An Open-Source Dataset for Machine Learning Applications in Electronic Design Automation (EDA). arXiv 2022, arXiv:2208.01040. [Google Scholar] [CrossRef]
- Kim, D.; Kwon, H.; Lee, S.Y.; Kim, S.; Woo, M.; Kang, S. Machine Learning Framework for Early Routability Prediction with Artificial Netlist Generator. In Proceedings of the 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 1809–1814. [Google Scholar] [CrossRef]
- Pan, J.; Chang, C.C.; Xie, Z.; Li, A.; Tang, M.; Zhang, T.; Hu, J.; Chen, Y. Towards collaborative intelligence: Routability estimation based on decentralized private data. In Proceedings of the DAC ’22, 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 10–14 July 2022; pp. 961–966. [Google Scholar] [CrossRef]
- Kahng, A.B. INVITED: Reducing Time and Effort in IC Implementation: A Roadmap of Challenges and Solutions. In Proceedings of the Proceedings of the 55th Annual Design Automation Conference, San Francisco, CA, USA, 24–29 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Khailany, B.; Ren, H.; Dai, S.; Godil, S.; Keller, B.; Kirby, R.; Klinefelter, A.; Venkatesan, R.; Zhang, Y.; Catanzaro, B.; et al. Accelerating Chip Design With Machine Learning. IEEE Micro 2020, 40, 23–32. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Description |
|---|---|
| Partitioning-based Algorithms | (*) Divide and conquer |
| (+) Efficient and scalable, can be used to solve large-scale circuits | |
| (−) Poor placement quality due to lack of global or local information | |
| (−) Harder to handle multiple objectives simultaneously | |
| ($) Capo [19] and FengShui [20] | |
| Heuristic Algorithms | (*) Stochastic/hill-climbing methods |
| (+) Simple to implement, high quality for small designs | |
| (+) Easier to handle multiple objectives simultaneously | |
| (−) Slower and less scalable for large-scale circuits | |
| ($) Dragon [21] and TimberWolf [22] | |
| Analytical Methods | (*) Mathematical programming |
| (+) More efficient and scalable | |
| (+) Better quality for even large-scale designs | |
| (+) Easier to consider multiple objectives simultaneously | |
| (−) Harder to optimize macro orientations | |
| ($) Quadratic: FastPlace [23], Polar [24], SimPL [25] | |
| ($) Nonlinear: NTUplace [26], ePlace [27], RePlAce [28] |
| Type | Description |
|---|---|
| Partitioning-based Algorithms | Improve the existing multilevel framework [52,53] |
| Identify placement relevant cell clusters [29] | |
| Heuristic Algorithms | Narrow the search space [54,55] |
| Design new heuristic algorithms [56,57,58] | |
| Analytical Methods | Optimize mathematical models [27,28,48,50,59,60] |
| Consider more new objectives and constraints [18,28,61,62,63,64,65,66,67,68,69] |
| Type | Description | Algorithm |
|---|---|---|
| Classical Algorithm Augmentation | Guide standard cells for partitioning [71,72] | K-Means GNN |
| Improve heuristic placement quality [73,74] | RL | |
| Explore better heuristic rules in analysis [75] | RL | |
| Automatic parameter tuning [76,77,78,79,80,81,82] | RL GNN Bayesian Opt | |
| Automatic Design | Automatic macro placement [12,51,83,84,85,86] | RL GCN CNN |
| Automatic heuristic design [87] | RL |
| Type | Description |
|---|---|
| Multi-threaded CPUs | POLAR 3.0, a quadratic placer using a multi-core system [24] |
| RePlace, a nonlinear placer with multi-threading support [28] | |
| GPUs Parallelism | GPU-accelerated implementation for the TimberWolf [90] |
| Exploit GPU parallelism to speed up nonlinear placement [91] | |
| DREAMPlace, a GPU-accelerated placement framework [64,68,88,92] | |
| An overview of GPU accelerated physical design [93] | |
| Accelerate density accumulation on GPU [94] |
| Input Stage | Evaluation Metrics | Algorithms |
|---|---|---|
| After Macro Placement | Timing failures [98] | SVM |
| HPWL and routing congestion [99] | Regression | |
| Routing congestion [100] | K-Means, Regression | |
| Routing congestion and WNS/TNS [101] | Ensemble learning | |
| The number of DRVs [97] | CNN | |
| After Standard Cell Placement | Routing congestion [67,103,115] | FCN, LHNN |
| The number of DRVs [104,105,106] | SVM, RUSBoost, CNN | |
| The locations of DRVs [102,106,107,108,109,110,111] | SVM, GCN, CNN | |
| Clock tree synthesis outcomes [112] | GAN, RL | |
| Crosstalk [113] | XGBoost, GNN | |
| Coupling effect [114] | GAN |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Y.; Xing, Y.; Zheng, X.; Gao, P.; Cai, S.; Xiong, X. Progress of Placement Optimization for Accelerating VLSI Physical Design. Electronics 2023, 12, 337. https://doi.org/10.3390/electronics12020337
Qiu Y, Xing Y, Zheng X, Gao P, Cai S, Xiong X. Progress of Placement Optimization for Accelerating VLSI Physical Design. Electronics. 2023; 12(2):337. https://doi.org/10.3390/electronics12020337
Chicago/Turabian StyleQiu, Yihang, Yan Xing, Xin Zheng, Peng Gao, Shuting Cai, and Xiaoming Xiong. 2023. "Progress of Placement Optimization for Accelerating VLSI Physical Design" Electronics 12, no. 2: 337. https://doi.org/10.3390/electronics12020337