

Intelligent Random Access for Massive-Machine Type Communications in Sliced Mobile Networks

 ,
,
Abstract
:1. Introduction
- We propose a network slicing-enabled mMTC random access framework, which leverages the customization capabilities of network slicing for the provisioning of differentiated QoS in multi-application coexisting mMTC scenarios.
- A novel concept of sPreamble is presented, which can scale the number of available preambles by a factor of N, where N is the number of network slices deployed in the system.
- A reinforcement learning-based dynamic sharing scheme ACRS is proposed to intelligently allocate the PDCCH resources to individual network slices in dynamic environments. By using ACRS, the limited PDCCH resources can be effectively multiplexed by the network slices, thereby improving the access capability of the Radio Access Network (RAN).
- We verify the efficacy of the proposed framework through extensive numerical simulations. The simulation results demonstrate that the proposed framework can increase the access capability of the RAN and reduce the access delay significantly.
2. Related Work
2.1. Coordinated RA
2.2. FUG-Based RA
2.3. Network Slicing-Enabled RA
3. Network Slicing-Enabled RA Framework
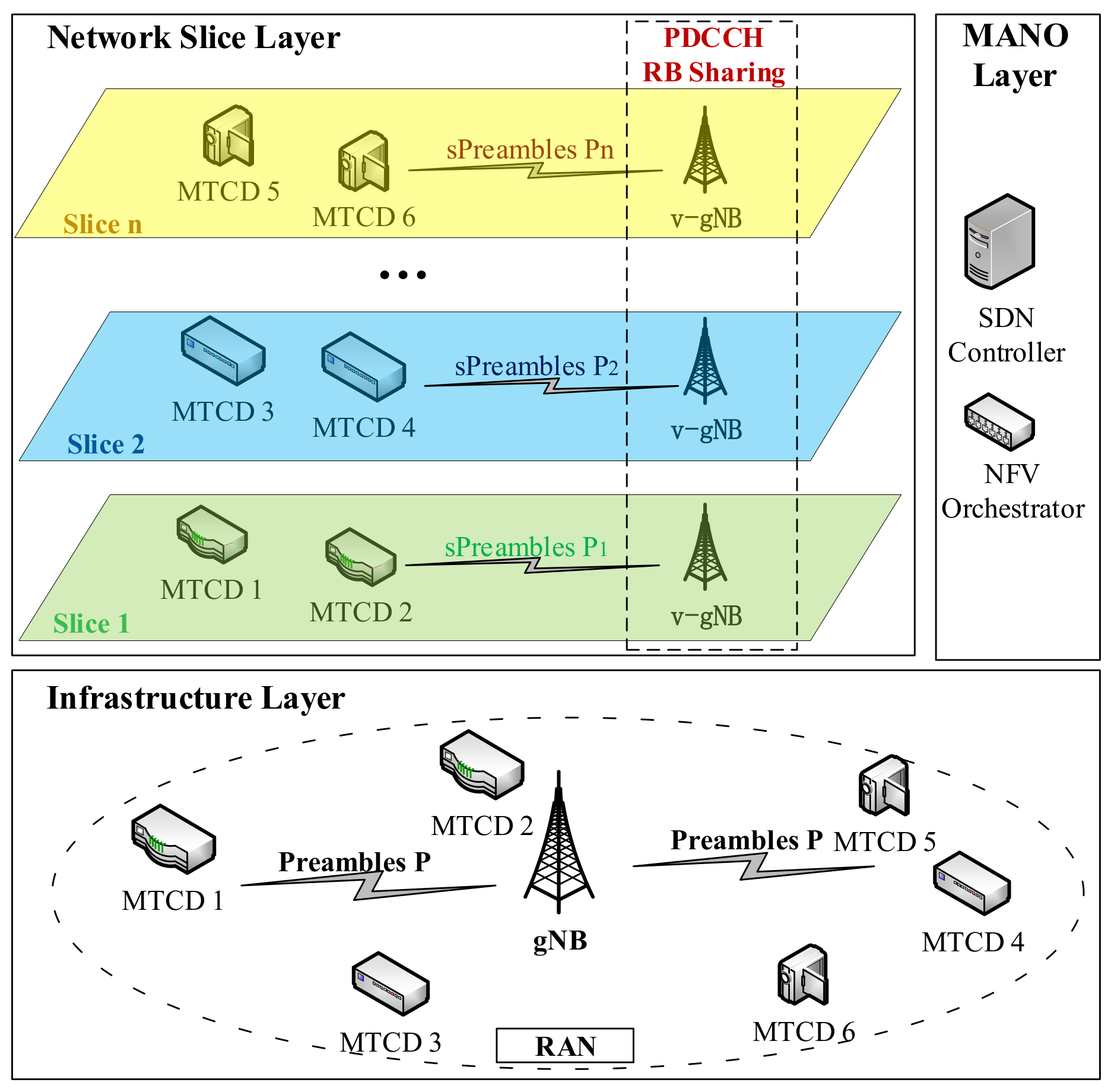
3.1. Architecture of Network Slicing-Enabled mMTC System
3.1.1. Infrastructure Layer
3.1.2. Network Slice Layer
3.1.3. MANO Layer
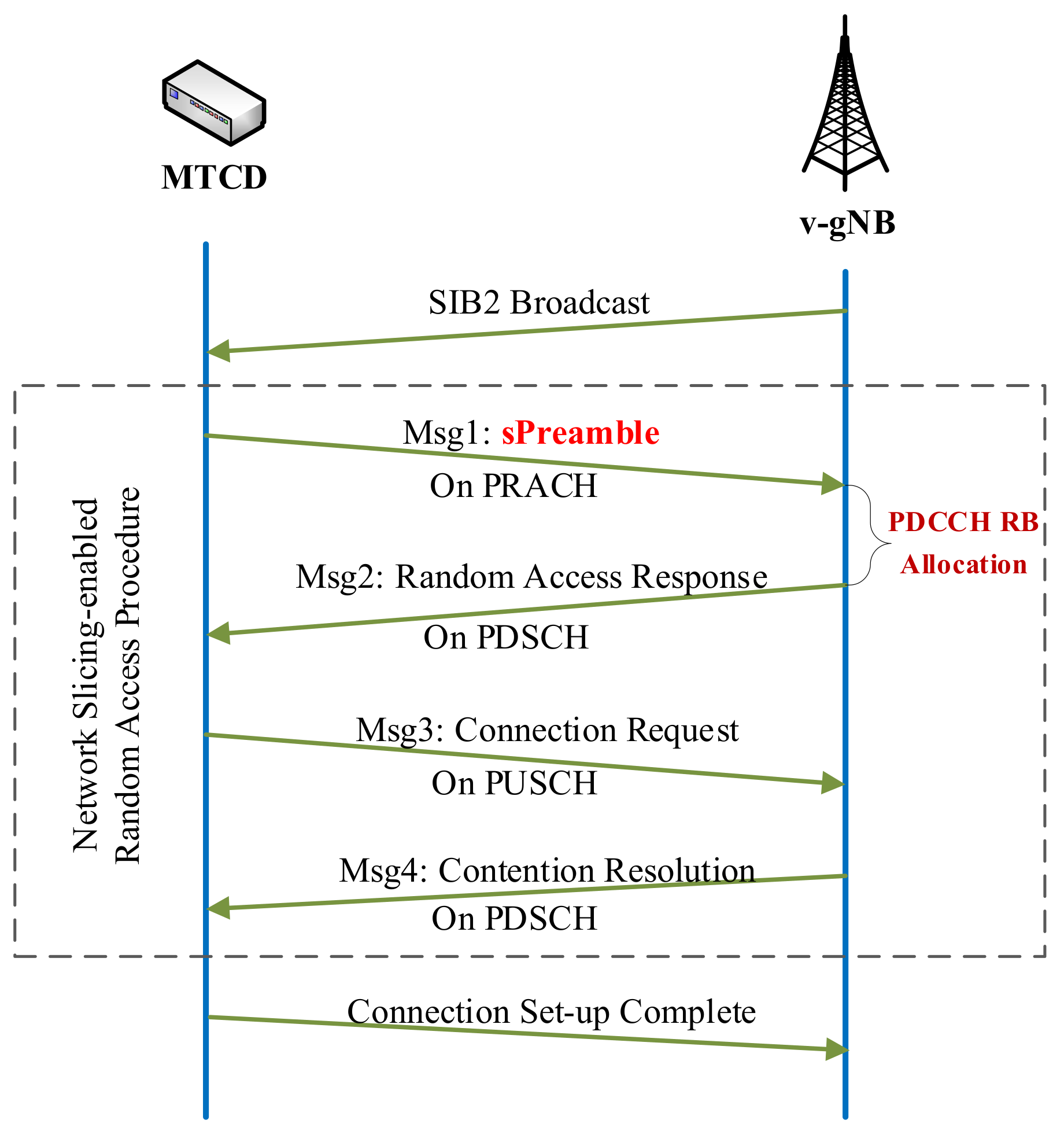
3.2. Network Slicing-Enabled Random Access Procedure
3.2.1. The Concept of Sliced Preambles
3.2.2. The RA Procedure in the Sliced mMTC Network
- Message 1: In the first stage, each MTCD will send an RA request (Message 1), which contains a randomly selected sPreamble through the Physical Random Access CHannel (PRACH).
- Message 2: If there are no collisions in the first step, the v-gNB replies to the MTCD with an RA response (RAR), which is Message 2 that includes an uplink grant and the Physical Uplink Shared CHannel (PUSCH) allocation information for the third step. The RAR is sent over the Physical Downlink Shared CHannel (PDSCH), which needs to be scheduled on the PDCCH [25].
- Message 3: After successfully receiving the RAR from the v-gNB, the MTCD will send a connection request (Message 3) using the resource blocks announced by Message 2.
- Message 4: The v-gNB sends a contention resolution (Message 4) to the MTCD through the PDSCH to indicate the success of the RA procedure. Again, the PDSCH needs to be scheduled on the PDCCH.
4. Dynamic PDCCH Resource Allocation Problem
4.1. Network Model
4.1.1. Physical Network Model
- The MTCDs that fail to access the v-gNB before the current time slot will be added to the current MTCD set;
- Stochastic arrival and departure of MTCDs in each slice.
4.1.2. Network Slice
4.2. Traffic Model
4.2.1. Stable Backlog
4.2.2. Unstable Backlog
4.3. Problem Formulation and Analysis
5. Actor–Critic-Based Dynamic Resource Allocation Scheme
5.1. The MDP Reformulation of DPRAP
5.1.1. State Space
5.1.2. Action Space
5.1.3. State Transitions
5.1.4. Reward Function
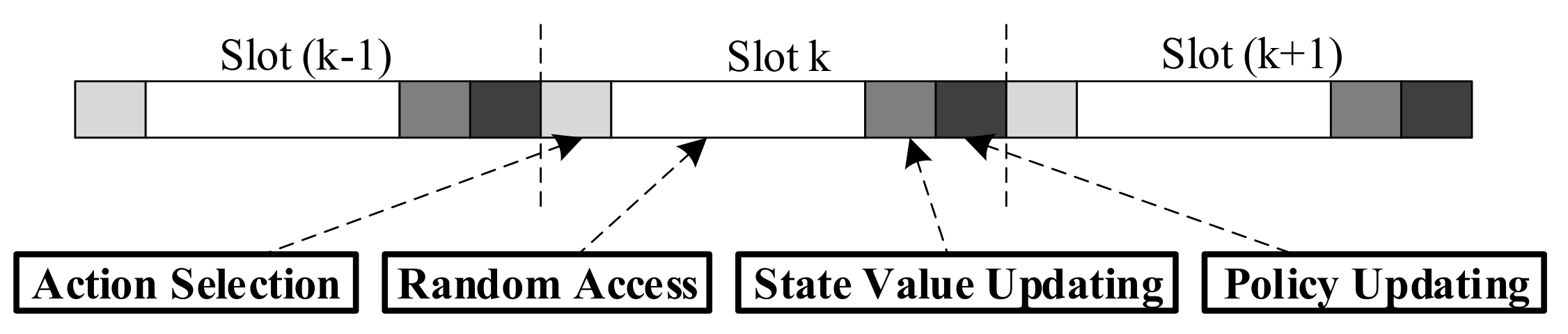
5.2. The AC-Based Resource Sharing Algorithm
| Algorithm 1: Actor-Critic-based Resource Sharing Scheme (ACRS) for DPRAP |
 |
5.2.1. Action Selection
5.2.2. mMTC Random Access
5.2.3. State-Value Function Updating
5.2.4. Policy Updating
5.3. Convergence Analysis
6. Numerical Results
6.1. Simulation Settings
6.2. Simulation Results and Discussions
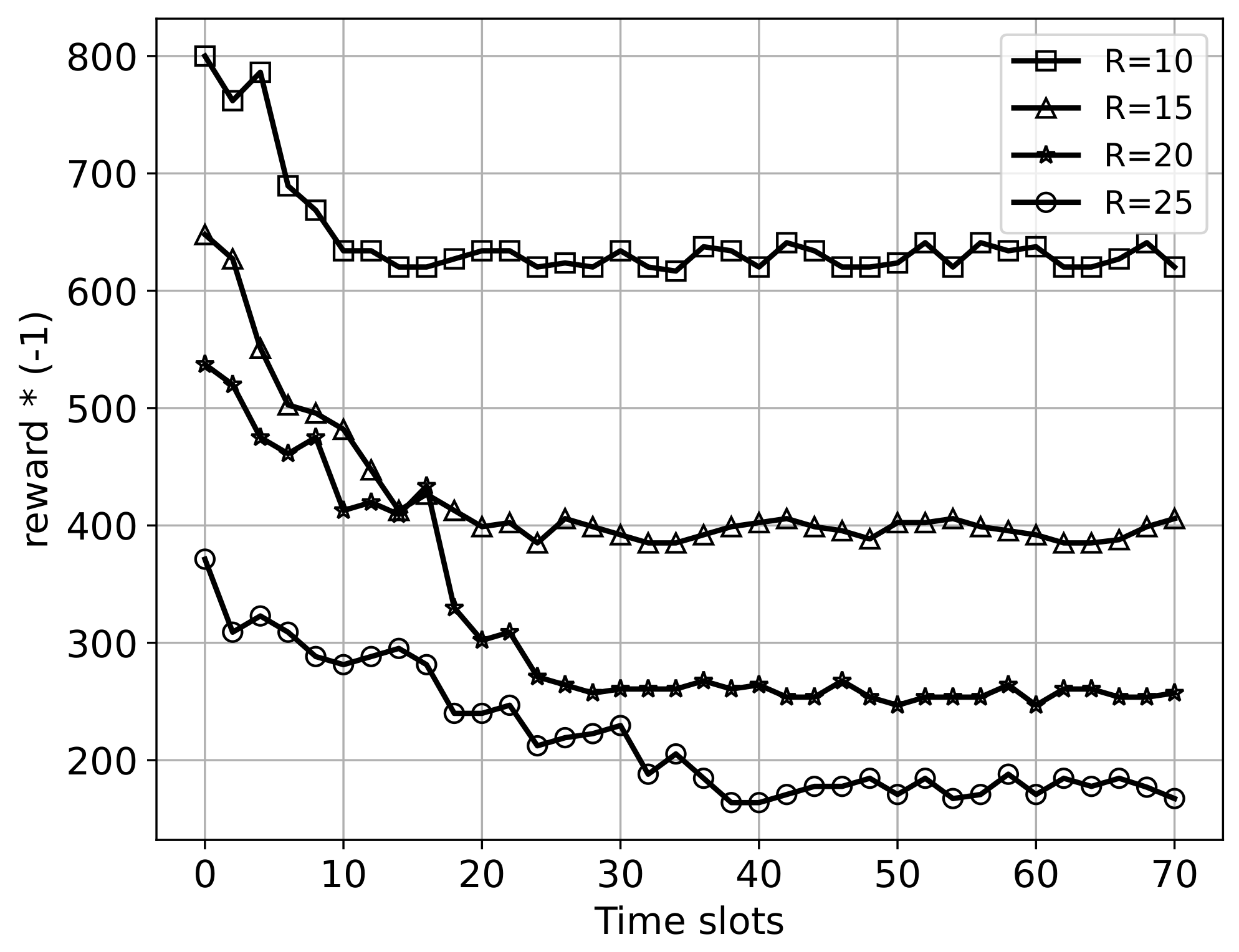
6.2.1. Convergence Performance
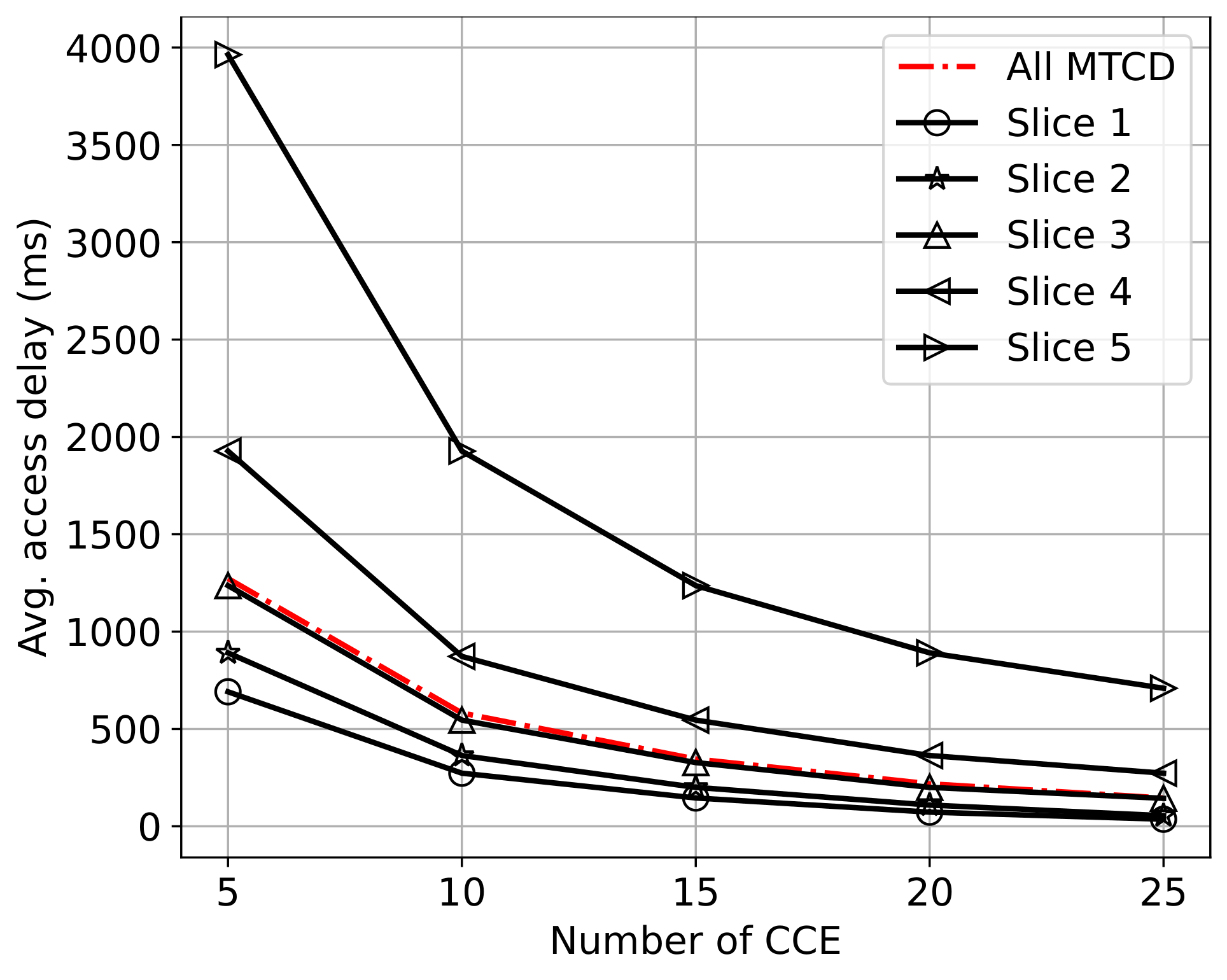
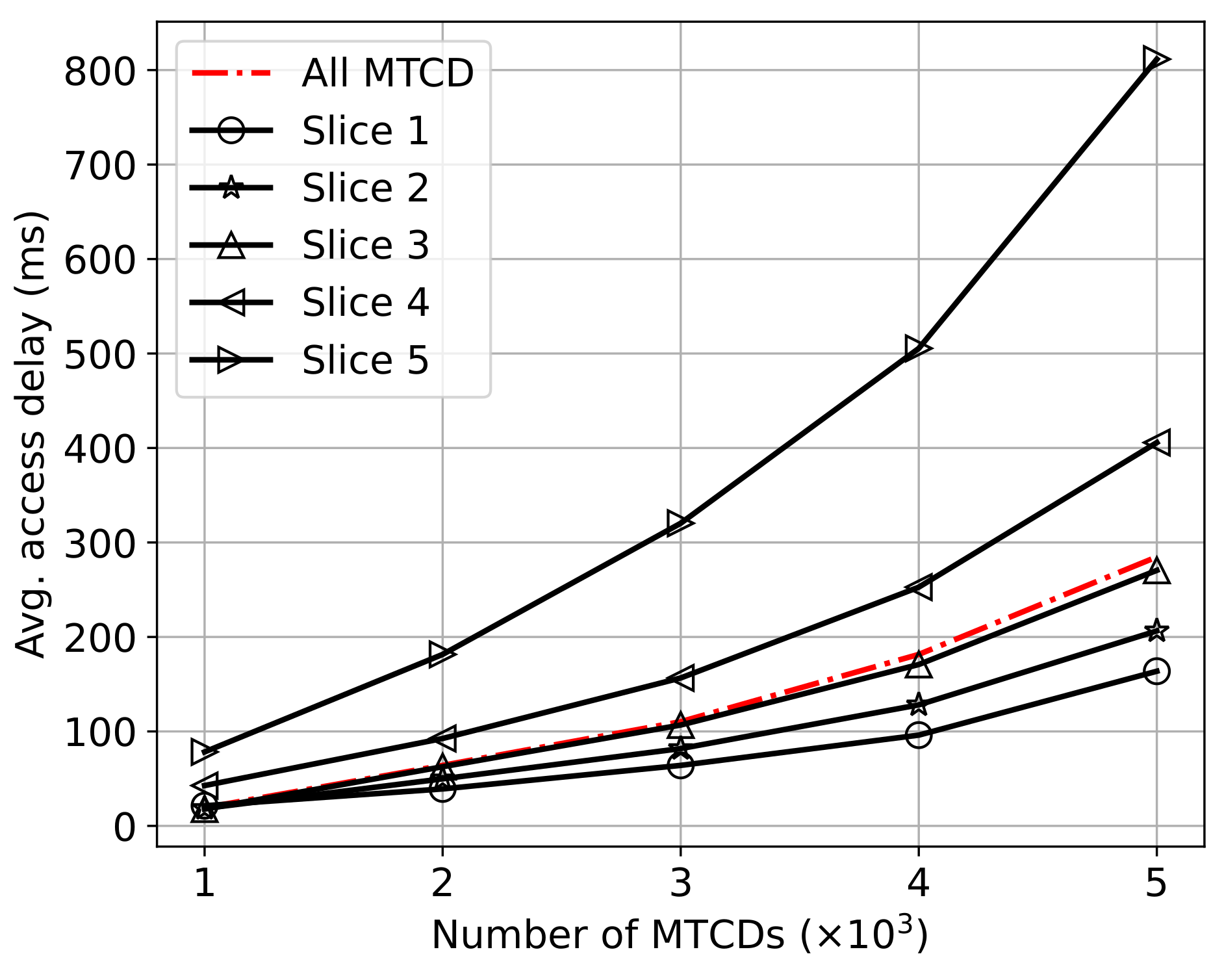
6.2.2. Performance under Different Parameters
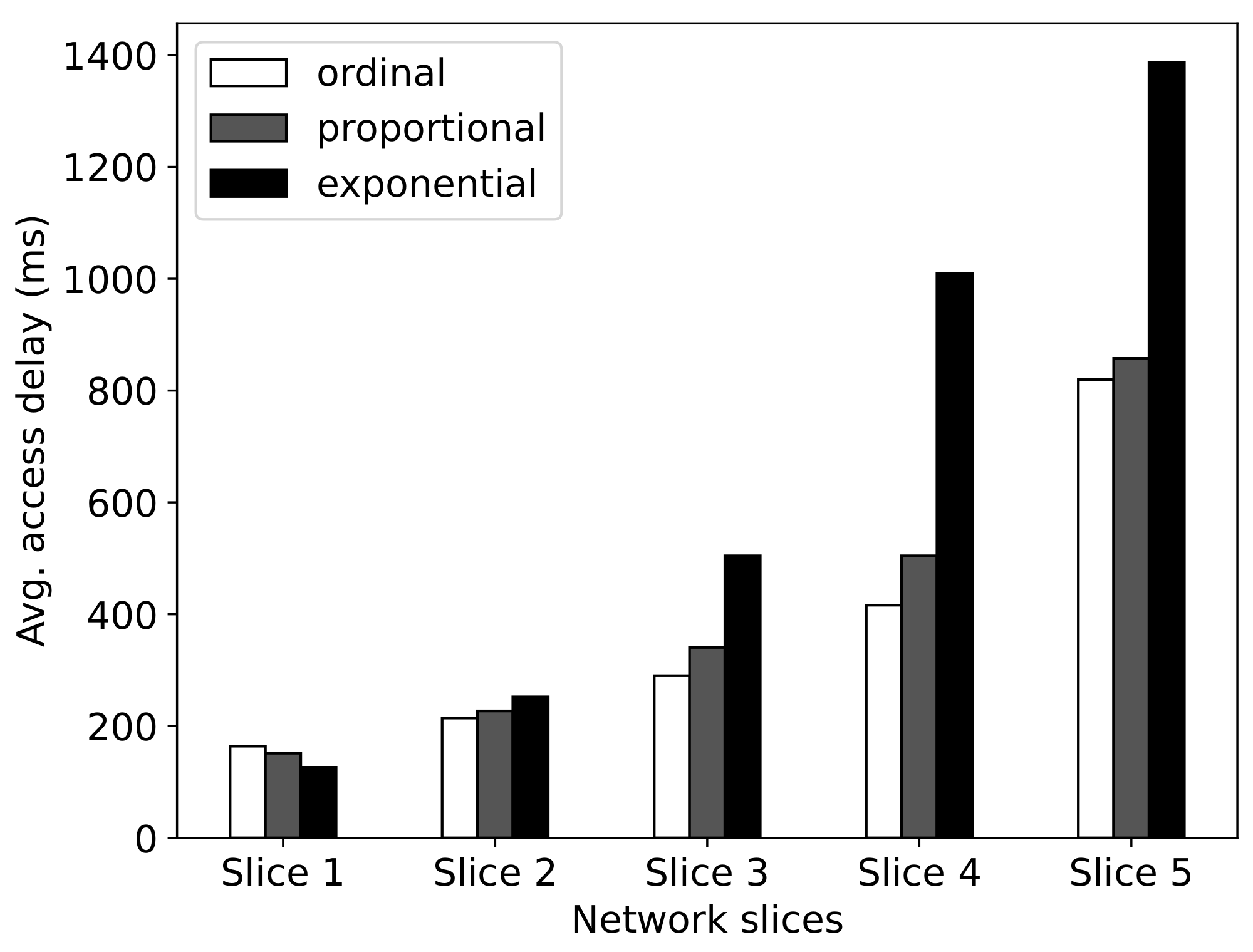
- Ordinal priority: First, we sort the network slices in descending order according to the resource price (i.e., ) they paid to the InP. Then we successively assign the priorities to individual slices.
- Exponential priority: Similar to the ordinal priority mechanism, we first sort the network slices in descending order according to . Then we successively assign the priorities to individual slices.
- Proportional priority: The priority of slice n is proportional to the resource price it paid to the InP, i.e., ).
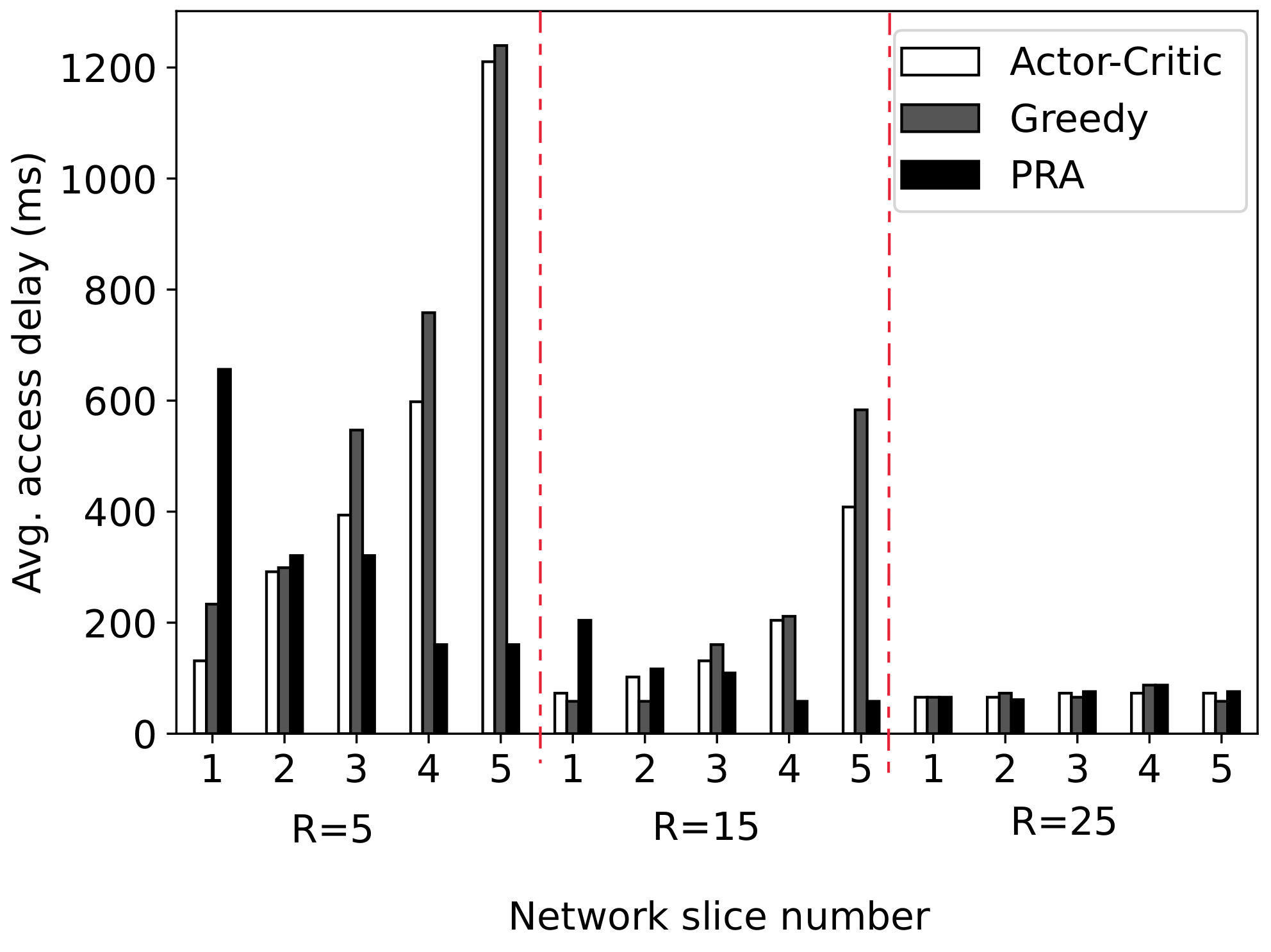
6.2.3. Comparison with Benchmarks
- Proportional Resource Allocation (PRA): In this algorithm, the amount of resources allocated to each slice is proportional to the number of MTCDs associated with it. Formally, is given by:
- Greedy: In this algorithm, each slice greedily requests PDCCH resources to minimize their instantaneous average delay at each time slot.
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cao, Y.; Jiang, T.; Han, Z. A survey of emerging M2M systems: Context, task, and objective. IEEE Internet Things J. 2016, 3, 1246–1258. [Google Scholar] [CrossRef]
- Ratasuk, R.; Mangalvedhe, N.; Bhatoolaul, D.; Ghosh, A. LTE-M Evolution Towards 5G Massive MTC. In Proceedings of the 2017 IEEE Globecom Workshops (GC Wkshps), Piscataway, NJ, USA, 4–8 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ericsson. Ericsson Mobility Report. Technical Report. Available online: https://www.ericsson.com/49d3a0/assets/local/reports-papers/mobility-report/documents/2022/ericsson-mobility-report-june-2022.pdf (accessed on 23 November 2022).
- Sharma, S.K.; Wang, X. Toward Massive Machine Type Communications in Ultra-Dense Cellular IoT Networks: Current Issues and Machine Learning-Assisted Solutions. IEEE Commun. Surv. Tutor. 2020, 22, 426–471. [Google Scholar] [CrossRef] [Green Version]
- Chowdhury, M.R.; De, S. Delay-Aware Priority Access Classification for Massive Machine-Type Communication. IEEE Trans. Veh. Technol. 2021, 70, 13238–13254. [Google Scholar] [CrossRef]
- Osti, P.; Lassila, P.; Aalto, S.; Larmo, A.; Tirronen, T. Analysis of PDCCH Performance for M2M Traffic in LTE. IEEE Trans. Veh. Technol. 2014, 63, 4357–4371. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, G.; Yi, H.; Zhang, W. Priority-based Distributed Queuing Random Access Mechanism for mMTC/uRLLC Terminals Coexistence. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Virtual Event, 25–28 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Weerasinghe, T.N.; Balapuwaduge, I.A.M.; Li, F.Y. Preamble Reservation Based Access for Grouped mMTC Devices with URLLC Requirements. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhao, L.; Xu, X.; Zhu, K.; Han, S.; Tao, X. QoS-based Dynamic Allocation and Adaptive ACB Mechanism for RAN Overload Avoidance in MTC. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Shahab, M.B.; Abbas, R.; Shirvanimoghaddam, M.; Johnson, S.J. Grant-Free Non-Orthogonal Multiple Access for IoT: A Survey. IEEE Commun. Surv. Tutor. 2020, 22, 1805–1838. [Google Scholar] [CrossRef]
- Xiao, H.; Chen, W.; Fang, J.; Ai, B.; Wassell, I.J. A Grant-Free Method for Massive Machine-Type Communication With Backward Activity Level Estimation. IEEE Trans. Signal Process. 2020, 68, 6665–6680. [Google Scholar] [CrossRef]
- Ali, S.; Ferdowsi, A.; Saad, W.; Rajatheva, N.; Haapola, J. Sleeping Multi-Armed Bandit Learning for Fast Uplink Grant Allocation in Machine Type Communications. IEEE Trans. Commun. 2020, 68, 5072–5086. [Google Scholar] [CrossRef] [Green Version]
- El Tanab, M.; Hamouda, W. Efficient Resource Allocation in Fast Uplink Grant for Machine-Type Communications With NOMA. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Comprehensive review of neural network-based prediction intervals and new advances. IEEE Trans. Neural Netw. 2011, 22, 1341–1356. [Google Scholar] [CrossRef]
- Gu, Y.; Cui, Q.; Ye, Q.; Zhuang, W. Game-Theoretic Optimization for Machine-Type Communications Under QoS Guarantee. IEEE Internet Things J. 2019, 6, 790–800. [Google Scholar] [CrossRef] [Green Version]
- Bui, A.T.H.; Pham, A.T. Deep Reinforcement Learning-Based Access Class Barring for Energy-Efficient mMTC Random Access in LTE Networks. IEEE Access 2020, 8, 227657–227666. [Google Scholar] [CrossRef]
- Ali, S.; Rajatheva, N.; Saad, W. Fast Uplink Grant for Machine Type Communications: Challenges and Opportunities. IEEE Commun. Mag. 2019, 57, 97–103. [Google Scholar] [CrossRef] [Green Version]
- Eldeeb, E.; Shehab, M.; Alves, H. A Learning-Based Fast Uplink Grant for Massive IoT via Support Vector Machines and Long Short-Term Memory. IEEE Internet Things J. 2022, 9, 3889–3898. [Google Scholar] [CrossRef]
- Wei, F.; Qin, S.; Feng, G.; Sun, Y.; Wang, J.; Liang, Y.C. Hybrid Model-Data Driven Network Slice Reconfiguration by Exploiting Prediction Interval and Robust Optimization. IEEE Trans. Netw. Serv. Manag. 2022, 19, 1426–1441. [Google Scholar] [CrossRef]
- Mancuso, V.; Castagno, P.; Sereno, M.; Marsan, M.A. Slicing Cell Resources: The Case of HTC and MTC Coexistence. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 667–675. [Google Scholar] [CrossRef]
- Mancuso, V.; Castagno, P.; Sereno, M. Modeling MTC and HTC Radio Access in a Sliced 5G Base Station. IEEE Trans. Netw. Serv. Manag. 2021, 18, 2208–2225. [Google Scholar] [CrossRef]
- Tong, L.; Zhang, C.; Huang, R. Research on intelligent logic design and application of campus MMTC scene based on 5G slicing technology. China Commun. 2021, 18, 307–315. [Google Scholar] [CrossRef]
- Elayoubi, S.E.; Jemaa, S.B.; Altman, Z.; Galindo-Serrano, A. 5G RAN Slicing for Verticals: Enablers and Challenges. IEEE Commun. Mag. 2019, 57, 28–34. [Google Scholar] [CrossRef] [Green Version]
- Hossain, A.; Ansari, N. 5G Multi-Band Numerology-Based TDD RAN Slicing for Throughput and Latency Sensitive Services. IEEE Trans. Mob. Comput. 2021. [Google Scholar] [CrossRef]
- 3GPP TS 38.331, v16.4.1. Radio Resource Control (RRC) Protocol Specification (Release 16). 3GPP. 2021. Available online: https://www.etsi.org/deliver/etsi_ts/138300_138399/138331/16.04.01_60/ts_138331v160401p.pdf (accessed on 23 November 2022).
- Kim, J.S.; Lee, S.; Chung, M.Y. Efficient Random-Access Scheme for Massive Connectivity in 3GPP Low-Cost Machine-Type Communications. IEEE Trans. Veh. Technol. 2017, 66, 6280–6290. [Google Scholar] [CrossRef]
- 3GPP. 5G; 5G System; Network Slice Selection Services. In Technical Report 3GPP TS 29.531; Version 15.6.0, Release 15; 3GPP. 2021. Available online: https://www.etsi.org/deliver/etsi_ts/129500_129599/129531/15.06.00_60/ts_129531v150600p.pdf (accessed on 23 November 2022).
- Laya, A.; Alonso, L.; Alonso-Zarate, J. Is the Random Access Channel of LTE and LTE-A Suitable for M2M Communications? A Survey of Alternatives. IEEE Commun. Surv. Tutor. 2014, 16, 4–16. [Google Scholar] [CrossRef] [Green Version]
- Vaezi, M.; Azari, A.; Khosravirad, S.R.; Shirvanimoghaddam, M.; Azari, M.M.; Chasaki, D.; Popovski, P. Cellular, Wide-Area, and Non-Terrestrial IoT: A Survey on 5G Advances and the Road Toward 6G. IEEE Commun. Surv. Tutor. 2022, 24, 1117–1174. [Google Scholar] [CrossRef]
- Koseoglu, M. Lower Bounds on the LTE-A Average Random Access Delay Under Massive M2M Arrivals. IEEE Trans. Commun. 2016, 64, 2104–2115. [Google Scholar] [CrossRef]
- Sutton, R.S.B. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Konda, V.; Tsitsiklis, J. Actor-Critic Algorithms. Adv. Neural Inf. Process. Syst. 1999, 12, 1008–1014. [Google Scholar]
- Wang, J.; Paschalidis, I.C. An actor-critic algorithm with second-order actor and critic. IEEE Trans. Autom. Control 2016, 62, 2689–2703. [Google Scholar] [CrossRef]
- Berenji, H.R.; Vengerov, D. A Convergent Actor-Critic-based FRL Algorithm with Application to Power Management of Wireless Transmitters. IEEE Trans. Fuzzy Syst. 2003, 11, 478–485. [Google Scholar] [CrossRef]
- Karim, L.; Mahmoud, Q.H.; Nasser, N.; Anpalagan, A.; Khan, N. Localization in Terrestrial and Underwater Sensor-based M2M Communication Networks: Architecture, Classification and Challenges. Int. J. Commun. Syst. 2017, 30, e2997. [Google Scholar] [CrossRef]
- Popp, J.; Lex, C.; Robert, J.; Heuberger, A. Simulating MTC data transmission in LTE. In Proceedings of the Second International Conference on Internet of things, Data and Cloud Computing, Pittsburgh, PA, USA, 18–21 April 2017; pp. 1–8. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Parameters | |
| T | The duration of a time slot |
| Set of network slices | |
| Set of MTCDs at time slot k | |
| The cardinality of the set | |
| Set of MTCDs associated with slice n at slot k | |
| The cardinality of the set | |
| The j-th MTCDs associated with slice n | |
| The number of available sPreambles in slice n | |
| R | The number of available CCEs in the RAN |
| The time separation between two consecutive RAOs in slice n | |
| The price paid by slice n at the k-th time slot | |
| The priority factor of slice n at the k-th time slot | |
| Decision Variables | |
| Integer variable indicates the number of CCEs allocated to slice n at k-th time slot | |
| Parameter | Value |
|---|---|
| Simulation duration | 50–100 time slots |
| Radius of the network | 1 km |
| Number of MTCDs | 50 to 5000 |
| RA requests distribution | Uniform distribution |
| Number of network slices N | 5 |
| Proportion of mMTC services | |
| Priority factor ratio of the network slices | |
| Packet size of the access requests | 1 KB/500 KB/1 MB |
| Transmit power of MTCDs | 100 mW |
| Power of background noise | 1 mW |
| Path loss | 8 + 37.6(d(m)) |
| Number of CCEs of PDCCH resources | 25 |
| Number of preambles | 54 |
| Number of sPreambles |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, B.; Wei, F.; She, X.; Jiang, Z.; Zhu, J.; Chen, P.; Wang, J. Intelligent Random Access for Massive-Machine Type Communications in Sliced Mobile Networks. Electronics 2023, 12, 329. https://doi.org/10.3390/electronics12020329
Yang B, Wei F, She X, Jiang Z, Zhu J, Chen P, Wang J. Intelligent Random Access for Massive-Machine Type Communications in Sliced Mobile Networks. Electronics. 2023; 12(2):329. https://doi.org/10.3390/electronics12020329
Chicago/Turabian StyleYang, Bei, Fengsheng Wei, Xiaoming She, Zheng Jiang, Jianchi Zhu, Peng Chen, and Jianxiu Wang. 2023. "Intelligent Random Access for Massive-Machine Type Communications in Sliced Mobile Networks" Electronics 12, no. 2: 329. https://doi.org/10.3390/electronics12020329