

RepRCNN: A Structural Reparameterisation Convolutional Neural Network Object Detection Algorithm Based on Branch Matching

Abstract
:1. Introduction
2. Related Work
2.1. Structural Re-Parameterisation Method
2.2. NMS Design Methodology
3. Design of Algorithms
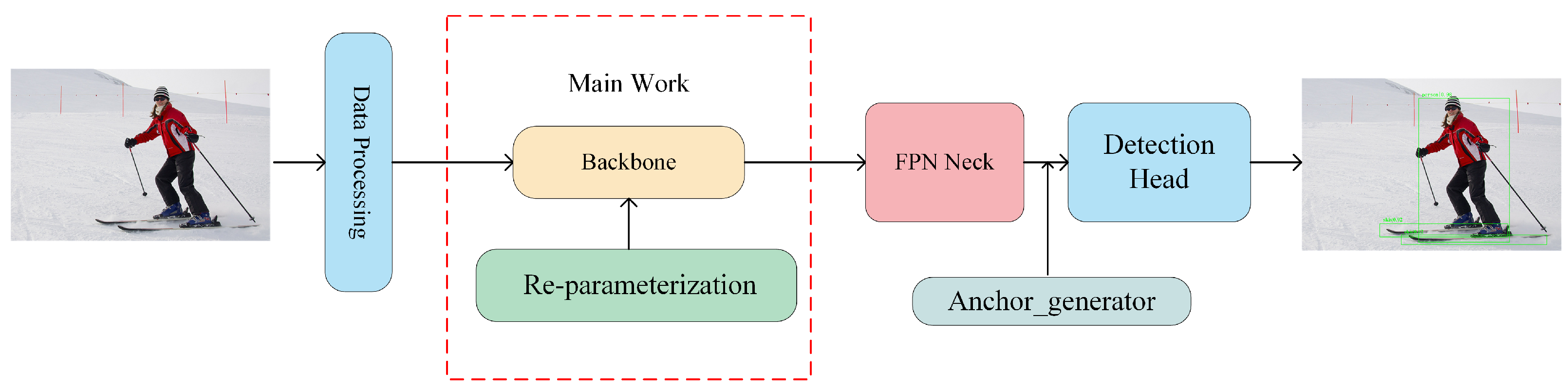
3.1. Design Ideas
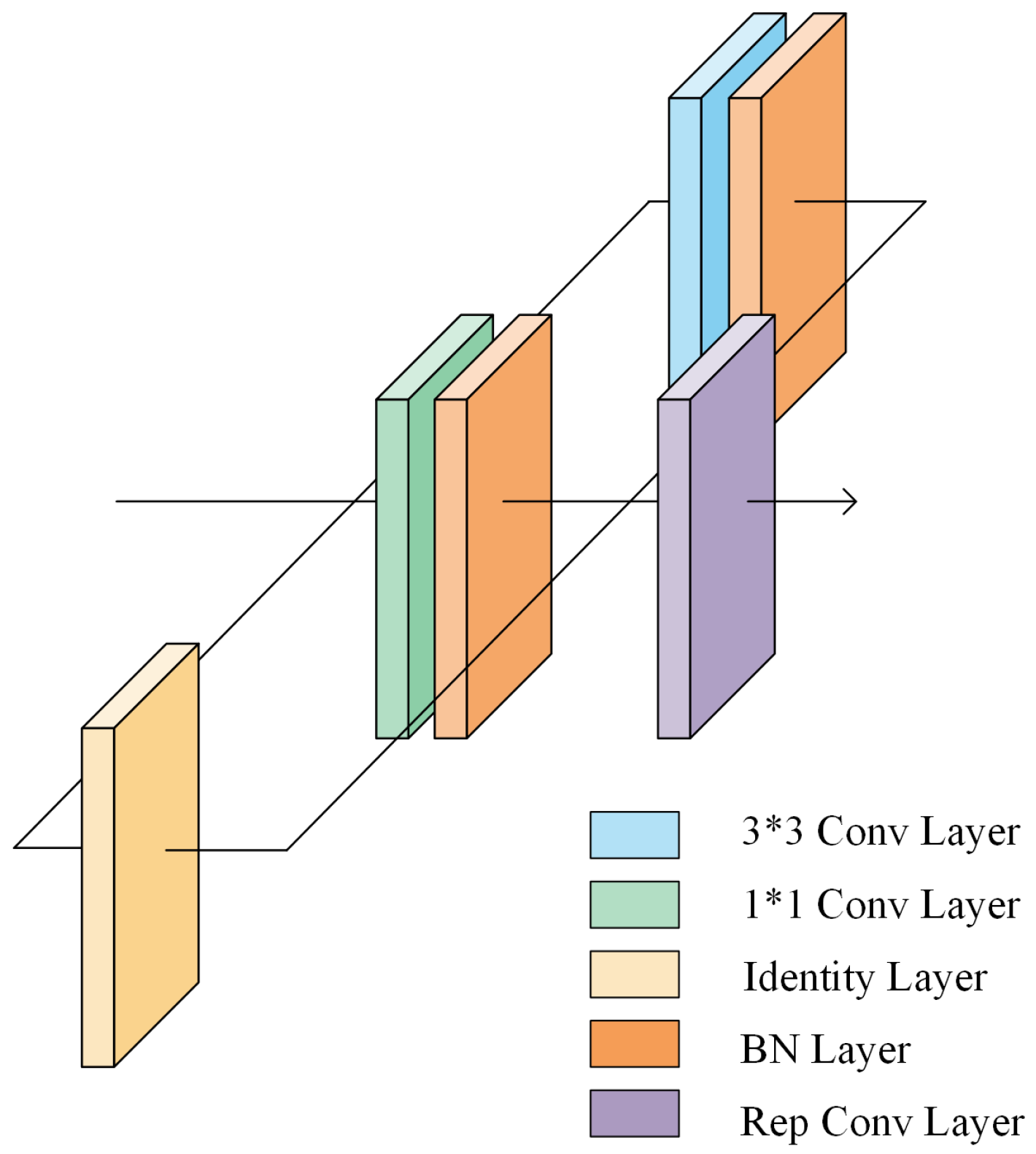
3.2. Structure Reparameterisation of the Backbone Network
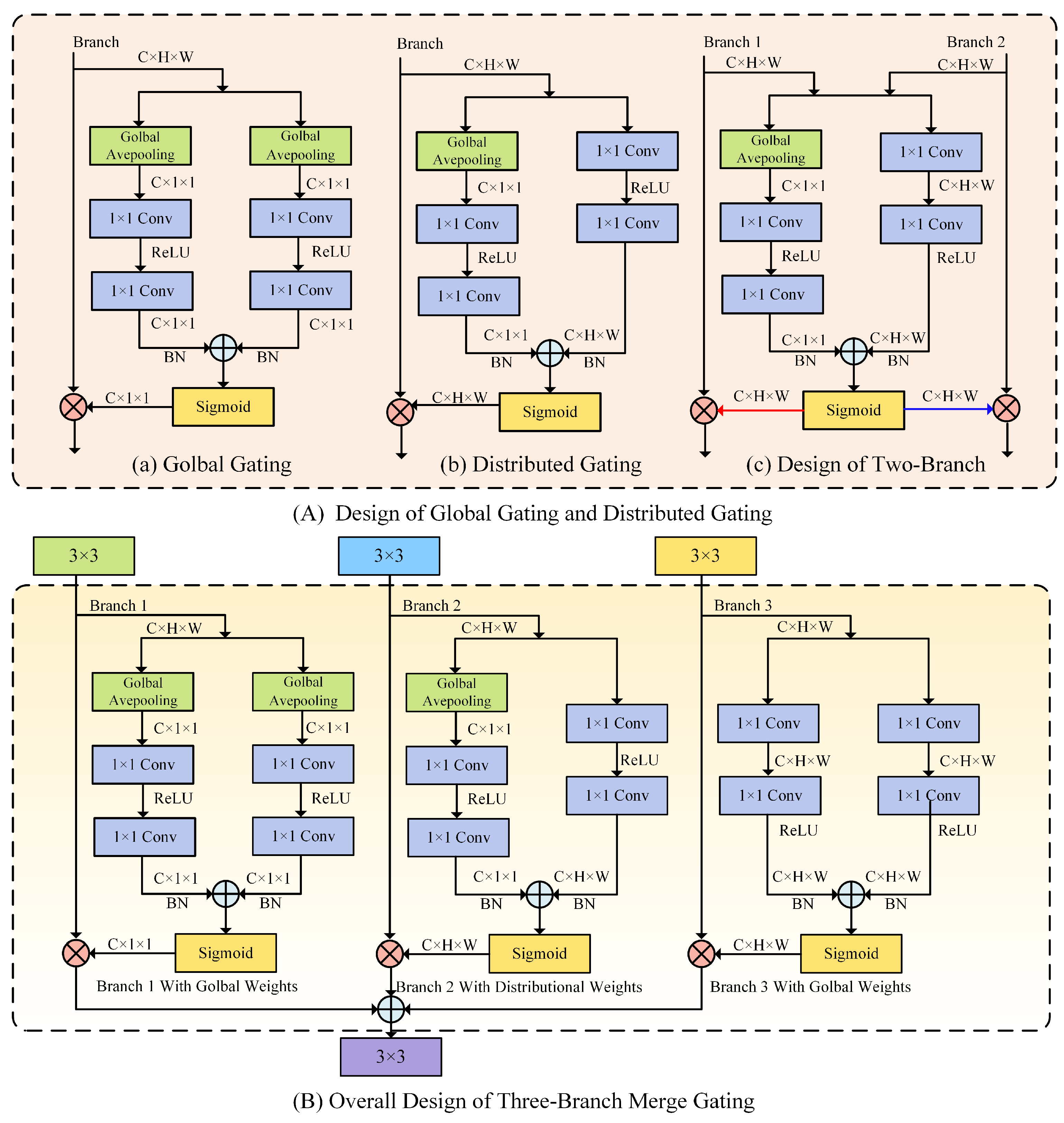
3.3. Attention Matching Strategies for Structural Branches
3.3.1. Characteristics of Different Branches
3.3.2. Three-Branch Merge Strategy
3.3.3. Implementation of Control Branch-Matching Attention
3.4. FPN Combined with Reparameterised Backbone Network
3.5. Head Achieves Detection
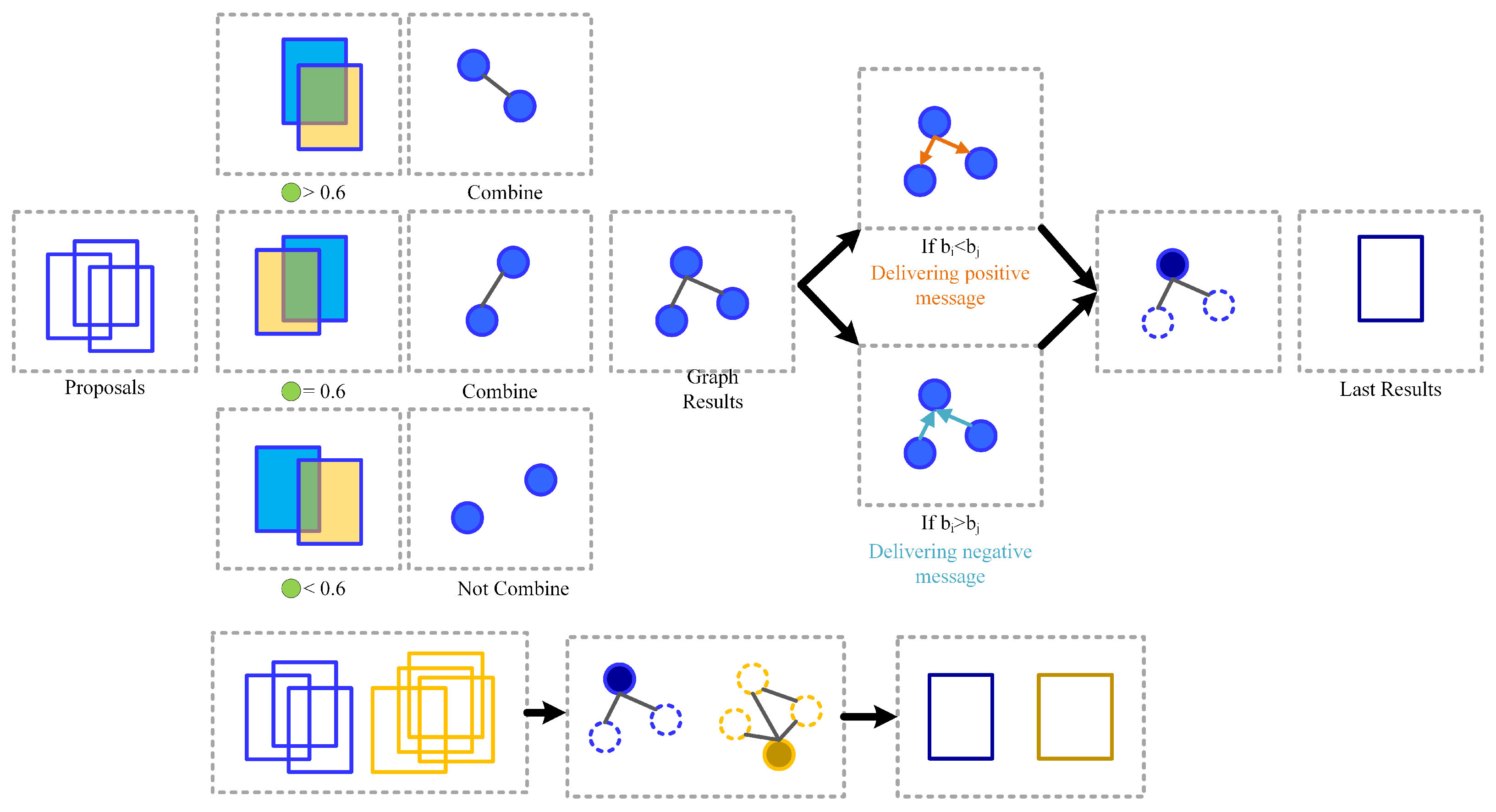
3.6. CPC NMS Strategy Application
3.7. Loss Function
3.8. Inference Process
4. Experiments
4.1. Dataset
4.2. Baseline Criteria and Evaluation Metrics
4.3. Experimental Setup
4.4. Ablation Experiments
4.5. Experimental Results and Analyses
4.5.1. PASCAL VOC2012 Performance
4.5.2. MS COCO2017 Performance
4.5.3. Visualisation of Detection Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings Part I 14. Springer: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14. Springer: Berlin, Germany, 2016; pp. 354–370. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. Up-detr: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1601–1610. [Google Scholar]
- Liu, C.; Wang, K.; Lu, H.; Cao, Z.; Zhang, Z. Robust Object Detection with Inaccurate Bounding Boxes. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 53–69. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Malsagov, M.Y.; Khayrov, E.M.; Pushkareva, M.M.; Karandashev, I.M. Exponential discretization of weights of neural network connections in pre-trained neural networks. Opt. Mem. Neural Netw. 2019, 28, 262–270. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ding, X.; Xia, C.; Zhang, X.; Chu, X.; Han, J.; Ding, G. Repmlp: Re-parameterizing convolutions into fully-connected layers for image recognition. arXiv 2021, arXiv:2105.01883. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10886–10895. [Google Scholar]
- Hu, M.; Feng, J.; Hua, J.; Lai, B.; Huang, J.; Gong, X.; Hua, X.S. Online convolutional re-parameterization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 568–577. [Google Scholar]
- Chu, X.; Li, L.; Zhang, B. Make RepVGG Greater Again: A Quantization-aware Approach. arXiv 2022, arXiv:2212.01593. [Google Scholar]
- He, Y.; Zhu, C.; Wang, J.; Savvides, M.; Zhang, X. Bounding box regression with uncertainty for accurate object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2888–2897. [Google Scholar]
- Ning, C.; Zhou, H.; Song, Y.; Tang, J. Inception single shot multibox detector for object detection. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 549–554. [Google Scholar]
- He, Y.; Zhang, X.; Savvides, M.; Kitani, K. Softer-nms: Rethinking bounding box regression for accurate object detection. arXiv 2018, arXiv:1809.08545. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Brazil, G.; Liu, X. M3d-rpn: Monocular 3d region proposal network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9287–9296. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Shen, Y.; Jiang, W.; Xu, Z.; Li, R.; Kwon, J.; Li, S. Confidence propagation cluster: Unleash full potential of object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1151–1161. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. arXiv 2018, arXiv:1804.06872. [Google Scholar]
- Zhang, X.; Yang, Y.; Feng, J. Learning to localize objects with noisy labeled instances. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9219–9226. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ji, R.; Ye, Q. Freeanchor: Learning to match anchors for visual object detection. arXiv 2019, arXiv:1909.02466. [Google Scholar]
- Wu, D.; Chen, P.; Yu, X.; Li, G.; Han, Z.; Jiao, J. Spatial Self-Distillation for Object Detection with Inaccurate Bounding Boxes. arXiv 2023, arXiv:2307.12101. [Google Scholar]
- Zhou, W.; Min, X.; Hu, R.; Long, Y.; Luo, H. FasterX: Real-Time Object Detection Based on Edge GPUs for UAV Applications. arXiv 2022, arXiv:2209.03157. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NMS | CPC | Rep | mAP | Parameter | Inf Time | Round |
|---|---|---|---|---|---|---|---|
| Base | N | N | N | 37.6 | 45 M | 12.1 | 1× |
| Base+NMS | Y | N | N | 37.7 | 45 M | 11.9 | 1× |
| Base+CPC | N | Y | N | 38.1 | 45 M | 12.5 | 1× |
| Base+Rep | N | N | Y | 38.7 | 38 M | 13.9 | 1× |
| Base+Rep+NMS | Y | N | Y | 39.1 | 38 M | 14.2 | 1× |
| Base+Rep+CPC | N | Y | Y | 39.5 | 38 M | 14.1 | 1× |
| Method | 3 × 3 Branch | 1 × 1 Branch | Residual | mAP |
|---|---|---|---|---|
| Base | None | None | None | 51.7 |
| Base+ Branch Matching | Global | Global | Global | 53.0 |
| Global | Distributions | Global | 53.2 | |
| Distributions | Global | Global | 52.2 | |
| Distributions | Distributions | Global | 51.5 |
| Method | Backbone | Train Data | mAP | AP50 | AP75 |
|---|---|---|---|---|---|
| Faster RCNN [5] | VGG-16 | VOC2012 | – | 67 | – |
| VOC2007+2012 | – | 70.4 | – | ||
| COCO+VOC2007+2012 | – | 75.9 | – | ||
| Ca.RCNN [6] | AlexNet | VOC2007 | 38.9 | 66.5 | 40.5 |
| VGG-16 | 51.2 | 79.1 | 56.3 | ||
| ResNet-50 | 51.8 | 78.5 | 57.1 | ||
| KL loss [24] | ResNet-50 | VOC2007 | – | 75.8 | – |
| Co-teaching [33] | ResNet-50 | VOC2007 | – | 75.4 | – |
| SD-LocNet [34] | ResNet-50 | VOC2007 | – | 75.7 | – |
| FreeAnchor [35] | ResNet-50 | VOC2007 | – | 73.0 | – |
| OA-MIL [13] | ResNet-50 | VOC2007 | – | 77.4 | – |
| SSD-Det [36] | ResNet-50 | VOC2007 | – | 77.1 | – |
| DETR/150 [11] | ResNet-50 | VOC2007 | 49.9 | 74.5 | 53.4 |
| DETR/300 [11] | ResNet-50 | VOC2007 | 54.1 | 78.0 | 58.3 |
| YOLOX-T [37] | ResNet-50 | VOC2012 | 35.4 | 57.9 | – |
| YOLOX-S [37] | ResNet-50 | VOC2012 | 42.6 | 64.5 | – |
| RepModel | RepRCNN-S | VOC2012 | 51.6 | 75.8 | 56.2 |
| RepRCNN-S | COCO+VOC2012 | 53.2 | 78.4 | 58.1 |
| Method | Backbone | mAP | AP50 | AP75 | Parameters | Inf Time |
|---|---|---|---|---|---|---|
| KL loss [24] | ResNet-50 | 31.0 | 54.3 | 30.3 | – | – |
| Co-teaching [33] | ResNet-50 | 30.5 | 54.9 | 30.5 | – | – |
| SD-LocNet [34] | ResNet-50 | 30.0 | 54.5 | 30.3 | – | – |
| FreeAnchor [35] | ResNet-50 | 28.6 | 53.1 | 28.5 | – | – |
| OA-MIL [13] | ResNet-50 | 32.1 | 55.3 | 33.2 | – | – |
| OREPA [22] | ResNet-50 | 37.4 | – | – | – | – |
| DETR [11] | ResNet-50 | 42.0 | 62.4 | 44.2 | – | – |
| UP-DETR [12] | ResNet-50 | 42.8 | 63.0 | 45.3 | – | – |
| YOLOV3 [3] | Darknet-53 | 36.2 | 60.6 | 38.2 | – | – |
| Faster RCNN [5] | ResNet-50 | 37.7 | 59.2 | 40.9 | 25 M | 13.6 |
| ResNet-101 | 40.0 | 61.8 | 43.7 | 45 M | 11.9 | |
| Ca.RCNN [6] | ResNet-50 | 41.3 | 59.4 | 45.3 | 25 M | 11.9 |
| ResNet-101 | 43.3 | 61.7 | 47.2 | 45 M | 10.3 | |
| YOLOX-T [37] | PANet | 32.8 | 50.3 | – | 5.1 M | 7.1 |
| YOLOX-S [37] | PANet | 40.5 | 59.3 | – | 9 M | 15.0 |
| YOLOv6-T [4] | EfficientRep | 40.3 | 56.6 | – | 15 M | 11.1 |
| YOLOv6-S [4] | EfficientRep | 43.2 | 60.4 | – | 17.2 M | 12.9 |
| YOLOv7-T [1] | EfficientRep | 37.4 | 55.2 | – | 6.2 M | 11.8 |
| RepModel | RepRCNN-T | 41.2 | 59.7 | 43.5 | 14 M | 14.1 |
| RepRCNN-S | 42.0 | 61.4 | 44.1 | 38 M | 12.3 | |
| New RepModel | RepRCNN-T | 41.8 | 60.2 | 43.7 | 14 M | 14.1 |
| RepRCNN-S | 43.3 | 62.1 | 45.6 | 38 M | 12.3 |
| Model | Backbone | AR1000 | Parameter | Training Time | Inf Time | Round |
|---|---|---|---|---|---|---|
| RPN | Resnet-50 | 57.6 | 25M | – | 17.7 | 2× |
| Resnet-101 | 59.1 | 45M | – | 14.4 | 2× | |
| RepRCNN | RepRCNN-T | 58.6 | 14M | 0.449 | 18.2 | 2× |
| RepRCNN-S | 59.9 | 38M | 0.512 | 15.6 | 2× |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Lv, X.; Sun, L.; Zhang, J.; Lan, R. RepRCNN: A Structural Reparameterisation Convolutional Neural Network Object Detection Algorithm Based on Branch Matching. Electronics 2023, 12, 4180. https://doi.org/10.3390/electronics12194180
Li X, Lv X, Sun L, Zhang J, Lan R. RepRCNN: A Structural Reparameterisation Convolutional Neural Network Object Detection Algorithm Based on Branch Matching. Electronics. 2023; 12(19):4180. https://doi.org/10.3390/electronics12194180
Chicago/Turabian StyleLi, Xudong, Xinyao Lv, Linghui Sun, Jingzhi Zhang, and Ruoming Lan. 2023. "RepRCNN: A Structural Reparameterisation Convolutional Neural Network Object Detection Algorithm Based on Branch Matching" Electronics 12, no. 19: 4180. https://doi.org/10.3390/electronics12194180