

A Multilayered Preprocessing Approach for Recognition and Classification of Malicious Social Network Messages

Abstract
:1. Introduction
- A novel categorized dataset of malicious social media messages in the Lithuanian language is created with four classes of messages: aggressive, insulting, toxic, and malicious;
- A multilayered preprocessing approach of Lithuanian social media messages and a detailed experimental analysis to decide which machine learning algorithm would produce the best results for the classifier;
- The empirical quantification of message class recognition for the proposed approach, allowing us to achieve accuracy from 95% to 98% in classifying malicious social network messages.
2. Related Works
3. Materials and Methods
3.1. Essentials of Lithuanian Words Formation
- Stem—a part of a word without an ending, for example, “padainavim” in the word “padainavimas”;
- The prefix is the part of the stem that precedes the root, for example “pa” in the word “padainavimas”;
- The root is the main part of related words, for example, “dain” in the words “daina”, “priedainis”;
- The suffix is a part of the stem that follows the root, for example “el” in the word “dainelė”;
- The ending is the part of the end of the word that changes depending on the meaning and the grammatical relationship with other words, for example “a”, “os”, “oje” in the words “daina”, “dainos”, “dainoje”;
- Interjection—these are sounds interspersed in the root, as, for example, “n” and “m” in the words “sninga”, “limpa”;
- Particle—“si”, for example, in the word “pasiruošti”.
- Conjunctions (ir, kad, bet…);
- Coincidences (oh, brr, che…);
- Emoticons (o, a, ė, ak…);
- Particles (ne, nė, lyg, dar, argi…);
- Prepositions (ant, už, po…);
- Pronouns (jos, tas, mes, šis…).
3.2. Dataset for Recognition and Classification of Malicious Social Network Messages in Lithuanian Language
- Aggressive messages are written with a fixed or outright aggressive mood or tone. Such a message may be worded to provoke anger or objection and may even contain threatening or offensive content. Such a message can be used to achieve one’s goals, but it can also cause conflicts, worsen relationships, and harm the quality of communication;
- Insulting messages are written with an established or directly insulting mood or tone. Such a message may be worded in such a way that it may hurt another person, or his feelings or dignity, and may sometimes even contain threatening content or pose a security threat. An insulting message can cause emotional trauma, create tension and cause conflict between individuals. In addition, such messages can damage interpersonal relationships and create a negative reputation for the sender;
- Toxic messages written in such a way that it creates negative or harmful feelings for the recipient and has a negative impact on the relationship between them. Such a message may be worded in such a way as to provoke anger, hatred, insults, or may be intended to repel or criticize the recipient. A toxic message can be very damaging because of its effects on emotional, psychological, and physical health. The message text can cause stress, anxiety, depression, insecurity, and more. In addition, such messages can cause interpersonal conflicts and destroy relationships between individuals. All swear words are classified as toxic messages;
- Malicious messages are sent with the intention of causing panic or fear in a person to make a faster decision that will benefit the scammers. Such messages can be worded in such a way as to induce fear and panic in a person to click on a link or reply to the email, which can lead to financial losses or exposed personal information to fraudsters. The messages are often sent with dangerous messages such as “Your bank account has been frozen!”, “Your account has been compromised!”, “Your data is in dangerous hands!”, etc. Such messages are often sent with a request for an immediate response or to click on a link to resolve the issues. The malicious message may send applications (bots) that encrypt the user’s data, and then demands a ransom to be paid to restore the data. Often, such messages can be crafted to appear to be from your bank, insurance company, social network, or another trusted source.
3.3. Multilayered Preprocessing Approach for Social Media Messages in Lithuanian Language
- Layer 1. The message’s special characters are removed, and the text is changed to lowercase letters, leaving only words;
- Layer 2. The Lithuanian characters [ą,č,ę,ė,į,š,ų,ū,ž] are replaced by Latin characters accordingly [a,c,e,e,i,s,u,u,z] in the message;
- Layer 3. Endings such as -a, -as, -yje, -us, etc., are removed from each word;
- Layer 4. Words shorter than 4 characters are removed.
- analyzer = ‘word’. The parameter means that the unit of text analysis is a word, rather than some other unit of text, such as a character or part of a sentence bullet;
- binary = False. The parameter specifies whether the vector of words should be binary. When binary = False, the vector of words is numeric and indicates the number of times each word occurs in the text. For example, if the text contains the word “labas” 3 times, the corresponding value in the vector will be 3;
- decode_error = ‘strict’. The parameter is used to read text files when there are problems decoding text characters. It specifies how sequences of characters that cannot be decoded into text should be handled;
- min_df = 2. The parameter specifies the minimum number of words in the data at which a word must appear to be considered significant and included in the vector;
- ngram_range = (1, 3). The parameter indicates how many consecutive words will be combined.
3.4. Recognition and Classification Method for Social Media Messages in Lithuanian Language
- 1.
- A vectorized array of words was passed to the ML classifier, which used the predict_proba method of the Python library to predict the probability that the message belonged to the class;
- 2.
- Predictions were assessed, and if the message was more than 80% likely to be malicious, a report was generated with the metadata received from the HTML request and the ML classifier prediction results;
- 3.
- Following the generation of the report, it was determined whether a malicious message like this already existed in the created Lithuanian benchmark dataset;
- 4.
- If the message classified as malicious was missing from the created Lithuanian benchmark dataset, a new labeled message was added to the Lithuanian benchmark dataset based on the classifier’s findings.
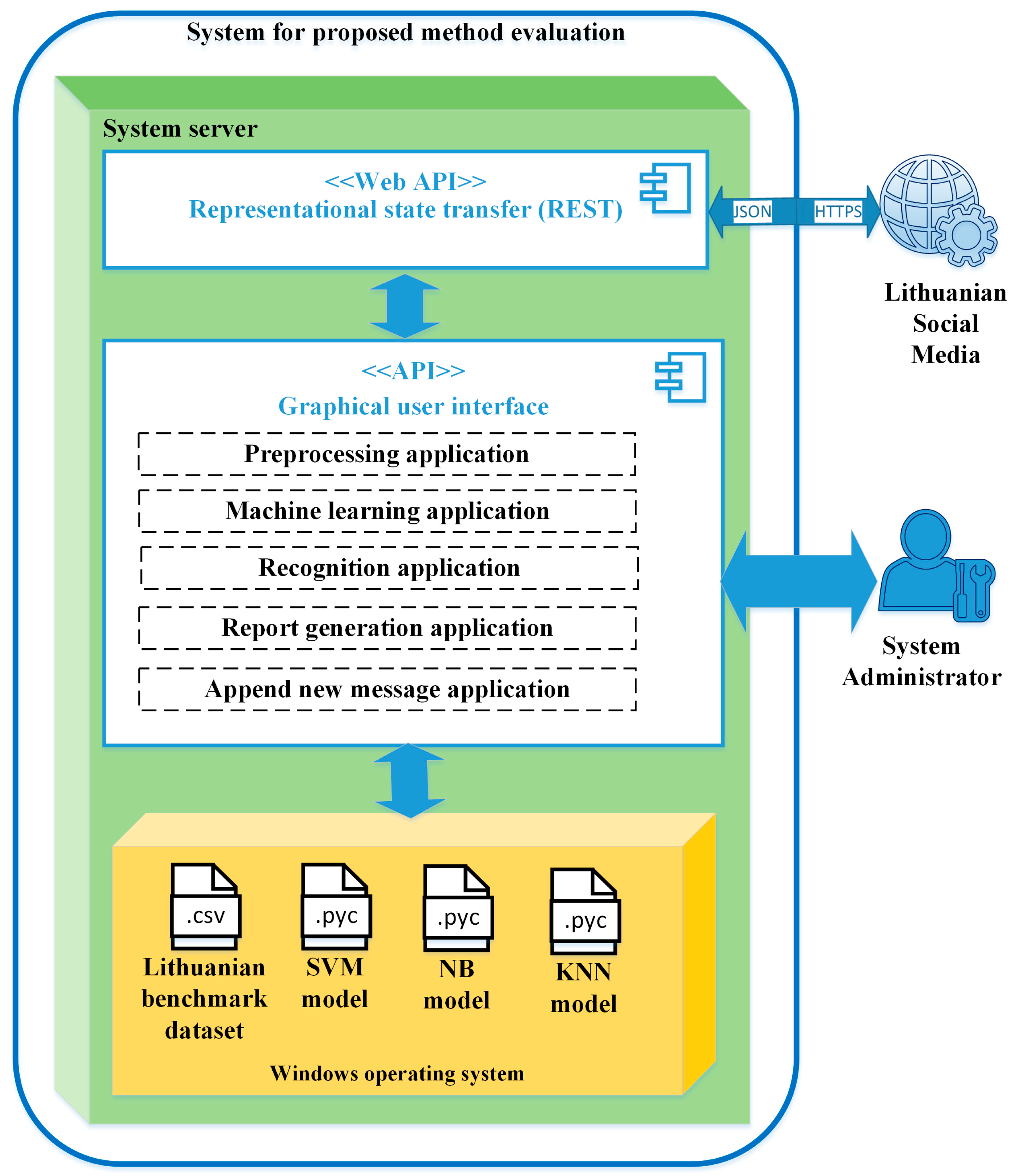
4. Experimental Settings and Results
- The labeled Lithuanian benchmark dataset in .csv file;
- The trained models for the Lithuanian benchmark dataset using SVM, NB, and KNN in .pyc files;
- The graphical user interface that includes tools for pre-processing messages obtained from the web, training and evaluating ML models, adding new malicious messages to the Lithuanian benchmark dataset, and generating reports;
- The interface was also designed to graphically display obtained results.
- ID—unique request number;
- Host—the domain from which the message was sent;
- Remote_Address—IP address;
- Timestamp—the time of the message when the sender wrote the message;
- Message—a message written by the sender;
- Results—results of the classifier;
- Metadata—HTML request metadata.
4.1. Experimental Settings
- 1.
- The Microsoft Visual Studio Code tool for creating software code due to the convenient use of plugins and writing software code;
- 2.
- The Python programming language, due to the fast processing of large amounts of data.
- 3.
- Open source libraries in the Python programming language:
- ○
- Pandas, a NumPy library with libraries for data analysis and table manipulation;
- ○
- Scikit-learn, which has machine learning-implemented algorithm libraries;
- ○
- The tornado web framework and asynchronous network library suitable for web applications and large amounts of data processing;
- ○
- The BeautifulSoup library for processing HTML and XML documents and analyzing web pages.
- 4.
- Machine learning algorithms:
- ○
- Support vector machine (SVM);
- ○
- Multinomial Naïve Bayes (NB);
- ○
- K-nearest neighbor (KNN).
- 5.
- Dataset in the Lithuanian language;
- 6.
- Using the REST API technology (GET and POST methods) for obtaining data from the social network and displaying the data.
- 7.
- Laptop for prototype development and prototype experimental testing:
- ○
- Operating system: Microsoft Windows 11;
- ○
- Processor: 11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80 GHz, 2803 Mhz, 4 Core(s), 8 Logical processors;
- ○
- Physical memory (RAM): 16.0 GB.
4.2. Experimental Results Evaluating Proposed Lithuanian Benchmark Dataset
- For SVM, the scikit-learn library SVC was used with an average setting of the balance between the error forgiveness and edge fitting, a linear function, a polynomial function with a degree of 3, an automatic gamma parameter, and a probability for each class (SVC (C = 1.0, kernel = ‘linear’, degree = 3, gamma = ‘auto’, probability = True));
- In the case of NB, the scikit-learn library MultinomialNB was used with the smoothing parameter 1 and the calculation set in frequency classes (MultinomialNB (alpha = 1.0, fit_prior = True));
- In the case of KNN, the scikit-learn library KNeighborsClassifier was used with a set parameter of 13 neighbors (KNeighborsClassifier (n_neighbors = 13)).
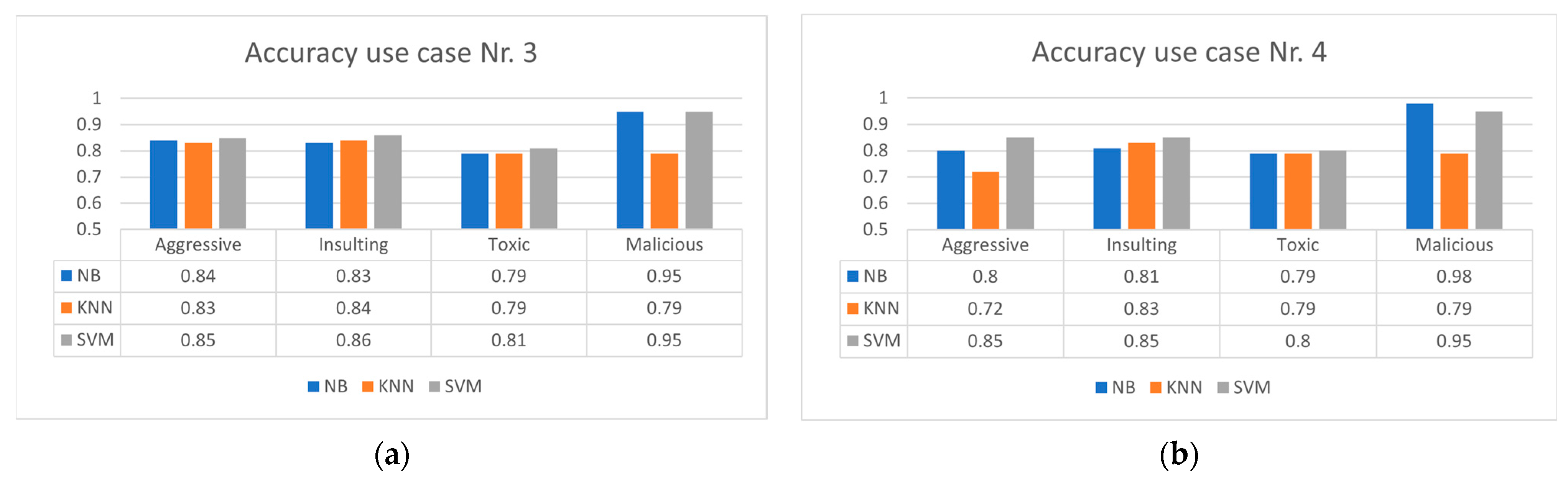
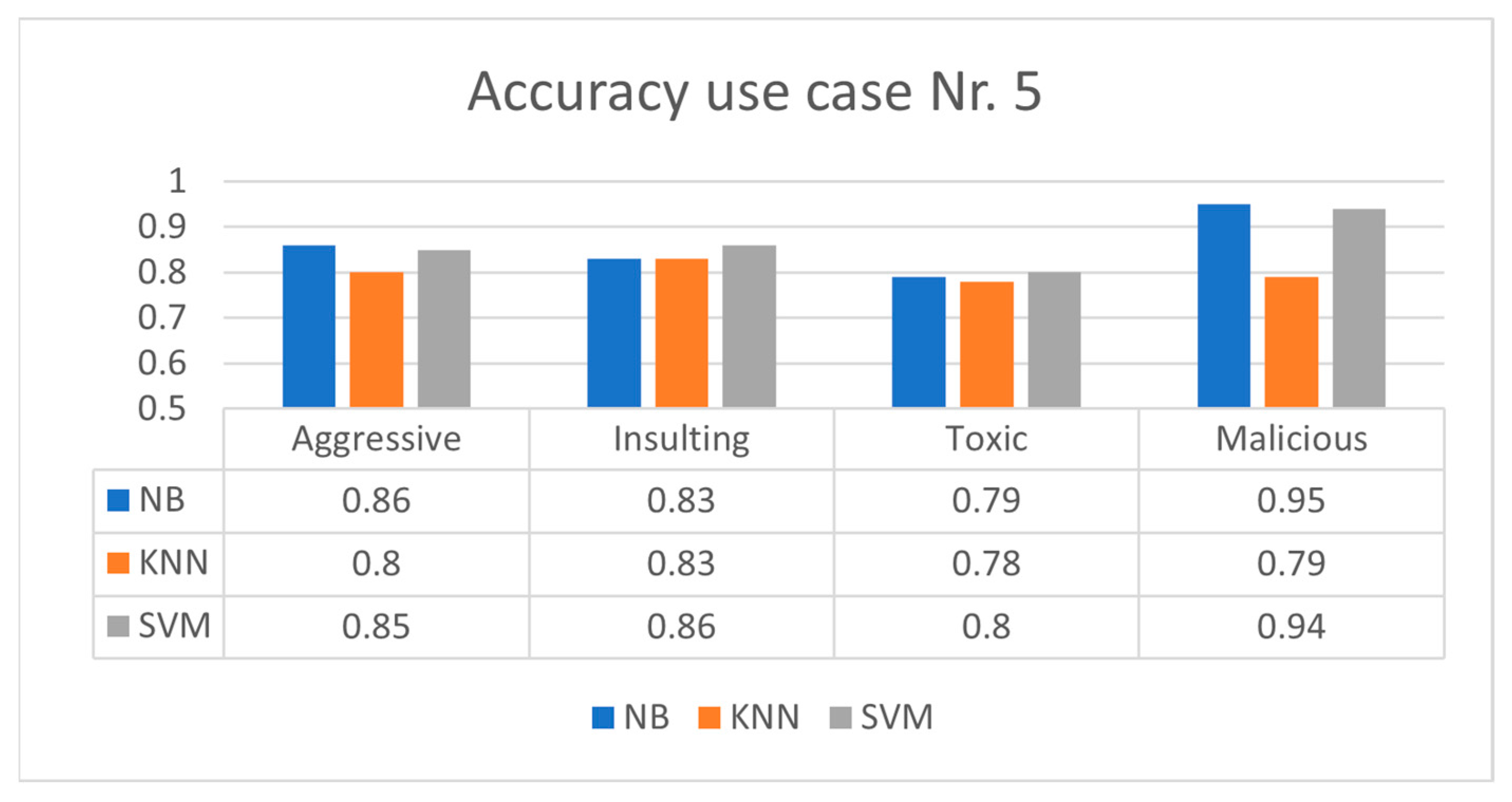
4.3. Experimental Results Applying Preprocessing Layers for Lithuanian OSN Messages
- TP_a—number of cases of the “Aggressive” class correctly predicted;
- TP_b—number of cases of the “Insulting” class correctly predicted;
- TP_c—number of cases of the “Toxic” class correctly predicted;
- TP_d—number of cases of the “Malicious” class correctly predicted;
- n_a—total number of the “Aggressive” class members;
- n_b—total number of the “Insulting” class members;
- n_c—total number of the “Toxic” class of members;
- n_d—Total number of the “ Malicious” members.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Luna, S.; Pennock, M.J. Social media applications and emergency management: A literature review and research agenda. Int. J. Disaster Risk Reduct. 2018, 28, 565–577. [Google Scholar] [CrossRef]
- Bhattacharjee, S.D.; Tolone, W.J.; Paranjape, V.S. Identifying malicious social media contents using multi-view Context-Aware active learning. Future Gener. Comput. Syst. 2019, 100, 365–379. [Google Scholar] [CrossRef]
- Soomro, T.R.; Hussain, M. Social Media-Related Cybercrimes and Techniques for Their Prevention. Appl. Comput. Syst. 2019, 24, 9–17. [Google Scholar] [CrossRef]
- Dixon, S. Social Media-Statistics & Facts. Available online: https://www.statista.com/topics/1164/social-networks/#topicOverview (accessed on 20 July 2023).
- Statista. Cyber Crime: Reported Damage to the IC3 2022. Available online: https://www.statista.com/statistics/267132/total-damage-caused-by-by-cyber-crime-in-the-us (accessed on 20 July 2023).
- Thakur, K.; Hayajneh, T.; Tseng, J. Cyber Security in Social Media: Challenges and the Way Forward. IT Prof. 2019, 21, 41–49. [Google Scholar] [CrossRef]
- Wanda, P.; Huang, J. Model of Sentiment Analysis with Deep Learning in Social Network Environment. In Proceedings of the 2nd International Conference on Electronic Information and Communication Technology (ICEICT), Harbin, China, 20–22 January 2019. [Google Scholar] [CrossRef]
- Wanda, P.; Jie, H.J. DeepSentiment: Finding Malicious Sentiment in Online Social Network based on Dynamic Deep Learning. IAENG Int. J. Comput. Sci. 2019, 46, 616–627. [Google Scholar]
- Mishra, S.; Shukla, P.; Agarwal, R. Analyzing Machine Learning Enabled Fake News Detection Techniques for Diversified Datasets. Wirel. Commun. Mob. Comput. 2022, 2022, 1575365. [Google Scholar] [CrossRef]
- Toshniwal, A.; Mahesh, K.; Jayashree, R. Overview of Anomaly Detection techniques in Machine Learning. In Proceedings of the Fourth International Conference on I-SMAC, Palladam, India, 7–9 October 2022. [Google Scholar] [CrossRef]
- Kondamudi, M.R.; Sahoo, S.R.; Chouhan, L.; Yadav, N. A comprehensive survey of fake news in social networks: Attributes, features, and detection approaches. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 101571. [Google Scholar] [CrossRef]
- Sharma, K.; Singh, A. A Systematic Review: Detection of Anomalies in Social Networks. In Proceedings of the International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 23–25 March 2023. [Google Scholar] [CrossRef]
- Koggalahewa, D.; Xu, Y.; Foo, E. An unsupervised method for social network spammer detection based on user information interests. J. Big Data 2022, 9, 7. [Google Scholar] [CrossRef]
- Rao, S.; Verma, A.K.; Bhatia, T. A review on social spam detection: Challenges, open issues, and future directions. Expert Syst. Appl. 2021, 186, 115742. [Google Scholar] [CrossRef]
- Al-Haija, Q.A.; Al-Fayoumi, M. An intelligent identification and classification system for malicious uniform resource locators (URLs). Neural Comput. Appl. 2023, 35, 16995–17011. [Google Scholar] [CrossRef]
- Martinez-Romo, J.; Araujo, L. Detecting malicious tweets in trending topics using a statistical analysis of language. Expert Syst. Appl. 2013, 40, 2992–3000. [Google Scholar] [CrossRef]
- Almutlaq, R.; Hafez, A. Detection Mechanism for Malicious Messages on KSU Student Social Network. Int. J. Data Sci. Technol. 2020, 6, 23–36. [Google Scholar] [CrossRef]
- Ellaky, Z.; Benabbou, F.; Ouahabi, S. Systematic Literature Review of Social Media Bots Detection Systems. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 101551. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Pattanaik, B.; Mandal, S.; Tripathy, R.M. A survey on rumor detection and prevention in social media using deep learning. Knowl. Inf. Syst. 2023, 65, 3839–3880. [Google Scholar] [CrossRef]
- Zhang, X.; Malkov, Y.; Florez, O.; Serim Park, S.; McWilliams, B.; Han, J.; El-Kishky, A. TwHIN-BERT: A Socially-Enriched Pre-trained Language Model for Multilingual Tweet Representations. arXiv 2022, arXiv:2209.07562. [Google Scholar] [CrossRef]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. arXiv 2019, arXiv:1901.02860. [Google Scholar] [CrossRef]
- Bello, A.; Ng, S.-C.; Leung, M.-F. A BERT Framework to Sentiment Analysis of Tweets. Sensors 2023, 23, 506. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Zhan, X.; Liu, G.; Zhan, X.; Deng, X. BSTC: A Fake Review Detection Model Based on a Pre-Trained Language Model and Convolutional Neural Network. Electronics 2023, 12, 2165. [Google Scholar] [CrossRef]
- Gani, R.; Chalaguine, L. Feature Engineering vs BERT on Twitter Data. arXiv 2022, arXiv:2210.16168. [Google Scholar] [CrossRef]
- Lample, G.; Conneau, A. Cross-lingual Language Model Pretraining. arXiv 2019, arXiv:1901.07291. [Google Scholar] [CrossRef]
- Kaddoura, S.; Chandrasekaran, G.; Popescu, D.E.; Duraisamy, J.H. A systematic literature review on spam content detection and classification. PeerJ Comput. Sci. 2022, 8, e830. [Google Scholar] [CrossRef] [PubMed]
- Bankar, S.H.; Shinde, S.A. Spammer Detection of Social Networking Sites Using 4 Novel Techniques. Available online: https://www.academia.edu/download/34105340/Sachin_Bankar.pdf (accessed on 20 July 2023).
- Odera, D.; Odiaga, G. A comparative analysis of recurrent neural network and support vector machine for binary classification of spam short message service. World J. Adv. Eng. Technol. Sci. 2023, 9, 127–152. [Google Scholar] [CrossRef]
- Kumar, R.M.; Bharathi, P.S. Detection of Malicious Social Bots with reinforcement learning technique with URL Features in Twitter Network with KNN in comparison with RNN. In Proceedings of the Eighth International Conference on Science Technology Engineering and Mathematics (ICONSTEM), Chennai, India, 6–7 April 2023. [Google Scholar] [CrossRef]
- Mbona, I.; Eloff, J.H.P. Classifying social media bots as malicious or benign using semi-supervised machine learning. J. Cybersecur. 2023, 9, tyac015. [Google Scholar] [CrossRef]
- Baccouche, A.; Ahmed, S.; Sierra-Sosa, D.; Elmaghraby, A. Malicious Text Identification: Deep Learning from Public Comments and Emails. Information 2020, 11, 312. [Google Scholar] [CrossRef]
- Alkhodair, S.A.; Ding, S.H.H.; Fung, B.C.M.; Liu, J. Detecting breaking news rumors of emerging topics in social media. Inf. Process. Manag. 2020, 57, 102018. [Google Scholar] [CrossRef]
- Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Syst. Appl. 2020, 153, 112986. [Google Scholar] [CrossRef]
- Kaliyar, R.H.; Goswami, A.; Narang, P.; Sinha, S. FNDNet—A deep convolutional neural network for fake news detection. Cogn. Syst. Res. 2020, 61, 32–44. [Google Scholar] [CrossRef]
- Băroiu, A.-C.; Trăușan-Matu, Ș. Comparison of Deep Learning Models for Automatic Detection of Sarcasm Context on the MUStARD Dataset. Electronics 2023, 12, 666. [Google Scholar] [CrossRef]
- Sharma, S.; Jain, A. Role of sentiment analysis in social media security and analytics. WIREs Data Min. Knowl. Discov. 2020, 10, 5. [Google Scholar] [CrossRef]
- Lippmann, R.P.; Campbell, W.M.; Weller-Fahy, D.J.; Mensch, A.C.; Zeno, G.M.; Campbell, J.P. Finding malicious cyber discussions in social media. Linc. Lab. J. 2016, 22, 46–59. Available online: https://apps.dtic.mil/sti/citations/AD1034416 (accessed on 3 August 2023).
- Rahman, M.S.; Halder, S.; Uddin, M.A.; Acharjee, U.K. An efficient hybrid system for anomaly detection in social networks. Cybersecurity 2021, 4, 10. [Google Scholar] [CrossRef]
- Krishna, Y.V.; Jahnavi, G.; Tharun, M.; Yegineti, S.G.; Raja, G.; Suneetha, B. Survey: Analysis of Security Issues on Social Media using Data Science techniques. In Proceedings of the International Conference on Inventive Computation Technologies (ICICT), Lalitpur, Nepal, 26–28 April 2023. [Google Scholar] [CrossRef]
- Siddiqui, T.; Hina, S.; Asif, R.; Ahmed, S.; Ahmed, M. An ensemble approach for the identification and classification of crime tweets in the English language. Comput. Sci. Inf. Technol. 2023, 4, 149–159. [Google Scholar] [CrossRef]
- Aun, Y.; Gan, M.; Wahab, N.H.B.A.; Guan, G.H. Social engineering attack classifications on social media using deep learning. Comput. Mater. Contin. 2023, 74, 4917–4931. [Google Scholar] [CrossRef]
- Damaševičius, R.; Venčkauskas, A.; Toldinas, J.; Grigaliūnas, Š. Ensemble-Based Classification Using Neural Networks and Machine Learning Models for Windows PE Malware Detection. Electronics 2021, 10, 485. [Google Scholar] [CrossRef]
- Stankevičius, L.; Lukoševičius, M. Testing pre-trained Transformer models for Lithuanian news clustering. arXiv 2020, arXiv:2004.03461. [Google Scholar] [CrossRef]
- Kalbos Pažinimas: Lietuvių Kalbos Žodžių Daryba, Kaityba, Sandara (Morfologija). Available online: https://lietuviu5-6.mkp.emokykla.lt/lt/mo/zinynas/kalbos_pazinimas_lietuviu_kalbos_zodziu_daryba_kaityba_sandara_morfologija/ (accessed on 3 August 2023).
- Boyd, K.L. Datasheets for Datasets help ML Engineers Notice and Understand Ethical Issues in Training Data. Proc. ACM Hum. -Comput. Interact. 2021, 5, 1–27. [Google Scholar] [CrossRef]
- Song, J.; Han, K.; Kim, S.-W. “I Have No Text in My Post”: Using Visual Hints to Model User Emotions in Social Media. In Proceedings of the ACM Web Conference, Lyon, France, 25–29 April 2022. [Google Scholar] [CrossRef]
- Barkovska, O.; Rusnak, P.; Tkachov, V.; Muzyka, T. Impact of Stemming on Efficiency of Messages Likelihood Definition in Telegram Newsfeeds. In Proceedings of the 2022 IEEE 3rd KhPI Week on Advanced Technology (KhPIWeek), Kharkiv, Ukraine, 3–7 October 2022. [Google Scholar] [CrossRef]
- Abbas, M.; Memon, K.A.; Jamali, A.A.; Memon, S.; Ahmed, A. Multinomial Naive Bayes classification model for sentiment analysis. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2019, 19, 62–67. [Google Scholar]
- Asogwa, D.C.; Chukwuneke, C.I.; Ngene, C.C.; Anigbogu, G.N. Hate Speech Classification Using SVM and Naive BAYES. IOSR J. Mob. Comput. Appl. (IOSR-JMCA) 2022, 9, 27–34. [Google Scholar] [CrossRef]
- Toktarova, A.; Iztaev, Z.; Kozhabekova, P.; Suieuova, N.; Opondo, R.O.; Kerimbekov, M.; Zhunisbekova, Z. Automated Hate Speech Classification using Emotion Analysis in Social Media User Generated Texts. J. Theor. Appl. Inf. Technol. 2022, 100, 6621–6634. [Google Scholar]
- Poojitha, K.; Charish, A.S.; Reddy, M.A.K.; Ayyasamy, S. Classification of social media Toxic comments using Machine learning models. Comput. Sci. Mach. Learn. 2023. [Google Scholar] [CrossRef]
- Fouad, K.M.; Sabbeh, S.F.; Medhat, W. Arabic fake news detection using deep learning. Comput. Mater. Contin. 2022, 71, 3647–3665. [Google Scholar] [CrossRef]
- Fortuna, P.; Soler-Company, J.; Wanner, L. How well do hate speech, toxicity, abusive and offensive language classification models generalize across datasets? Inf. Process. Manag. 2021, 58, 102524. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Aggressive | Insulting | Toxic | Malicious | Message Text in Lithuanian and English Translation |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | Mirė senelis, kuris kasė deimantus Afrikoje, paveldėjo turtą 1,000,000 $ |
| The grandfather who mined diamonds in Africa died, inherited a fortune of $1,000,000 data | |||||
| 1 | 0 | 0 | 1 | 0 | Po šimts gegučių |
| After a hundred cuckoos | |||||
| 2 | 0 | 1 | 0 | 0 | Žalčio koja pastaroji |
| The snake’s leg is the latter | |||||
| 3 | 1 | 0 | 0 | 0 | Suk tave devynios |
| Turn you nine | |||||
| 4 | 1 | 0 | 0 | 0 | Kad tu kiaurai žemę prasmegtum |
| So that you can penetrate the earth |
| Research | Language of the Dataset | Classes | Accuracy | ||
|---|---|---|---|---|---|
| SVM | NB | KNN | |||
| Abbas et al., 2019 [49] | English | Sentiment positive | - | 0.8992 | - |
| Sentiment negative | |||||
| Asogwa et al., 2022 [50] | English | Offensive | 0.99 | 0.50 | - |
| Non-offensive | |||||
| Toktarova et al., 2022 [51] | English | Hate speech | 0.92 | 0.89 | 0.90 |
| Other | |||||
| Poojitha et al., 2023 [52] | English | Toxic | 0.94 | - | 0.86 |
| Non-toxic | |||||
| Fouad et al., 2022 [53] | Arabic | Fake news | 0.859 | 0.823 | 0.806 |
| Non-fake news | |||||
| Proposed | Lithuanian | Malicious | 0.85 | 0.86 | 0.74 |
| Benign | |||||
| ML Algorithm | Accuracy | |||
|---|---|---|---|---|
| Aggressive | Insulting | Toxic | Malicious | |
| NB | 0.82 | 0.84 | 0.80 | 0.97 |
| KNN | 0.55 | 0.83 | 0.77 | 0.79 |
| SVM | 0.83 | 0.85 | 0.79 | 0.94 |
| Use Case | Layer 1. The Message’s Special Characters Are Removed, and the Text Is Changed to Lowercase Letters, Leaving Only Words. | Layer 2. The Lithuanian Characters [ą,č,ę,ė,į,š,ų,ū,ž] Are Replaced by Latin Characters Accordingly [a,c,e,e,i,s,u,u,z] in the Message | Layer 3. Endings Such as -a, -as, -yje, -us, etc., Are Removed from Each Word | Layer 4. Words Shorter than Four Characters Are Removed |
|---|---|---|---|---|
| 1. | Applicable | Applicable | Applicable | Applicable |
| 2. | Applicable | Not applicable | Applicable | Shorter than three |
| 3. | Applicable | Applicable | Not applicable | Shorter than three |
| 4. | Applicable | Applicable | Applicable | Shorter than three |
| 5. | Applicable | Not applicable | Not applicable | Shorter than three |
| ML Method | Average Accuracy Classification Score (Calculated Using Equation (2)) | ||||
|---|---|---|---|---|---|
| Use Case No. 1 | Use Case No. 2 | Use Case No. 3 | Use Case No. 4 | Use Case No. 5 | |
| NB | 0.86 | 0.86 | 0.85 | 0.85 | 0.86 |
| KNN | 0.74 | 0.8 | 0.81 | 0.78 | 0.8 |
| SVM | 0.85 | 0.86 | 0.87 | 0.86 | 0.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Čepulionytė, A.; Toldinas, J.; Lozinskis, B. A Multilayered Preprocessing Approach for Recognition and Classification of Malicious Social Network Messages. Electronics 2023, 12, 3785. https://doi.org/10.3390/electronics12183785
Čepulionytė A, Toldinas J, Lozinskis B. A Multilayered Preprocessing Approach for Recognition and Classification of Malicious Social Network Messages. Electronics. 2023; 12(18):3785. https://doi.org/10.3390/electronics12183785
Chicago/Turabian StyleČepulionytė, Aušra, Jevgenijus Toldinas, and Borisas Lozinskis. 2023. "A Multilayered Preprocessing Approach for Recognition and Classification of Malicious Social Network Messages" Electronics 12, no. 18: 3785. https://doi.org/10.3390/electronics12183785