
PIRB: Privacy-Preserving Identity-Based Redactable Blockchains with Accountability

Abstract
:1. Introduction
- To tackle the challenges, we present a privacy-preserving identity-based redactable blockchain based on the chameleon hash with ephemeral trapdoors, denoted as PIRB, which contains two schemes, PIRB-I and PIRB-II. With an identity-based encryption scheme introduced, PIRB-I facilitates one-way access control, while PIRB-II achieves bilateral access control while upholding match privacy preservation. Moreover, we leverage the polynomial function technique to support one policy for a batch of users.
- To mitigate the potential misuse of editing privileges for malicious behaviors, the proxy re-encryption technique is introduced as an accountability mechanism.
- A formal theoretical analysis establishes the correctness, security, and complexity of PIRB. Correctness analysis proves the necessary and sufficient conditions for the accurate operation of PIRB, contingent upon the fulfillment of the policy by the identity-based attribute. Security analysis demonstrates that PIRB concurrently upholds trapdoor privacy, identity privacy, policy privacy, and match privacy under the chosen-plaintext attack model. Additionally, complexity analysis presents the computational and communication complexity of both PIRB-I and PIRB-II, comparing them with two existing attribute-based redactable blockchain schemes. Empirical experiments corroborate our scheme’s practical efficiency enhancements.
2. Problem Formulation
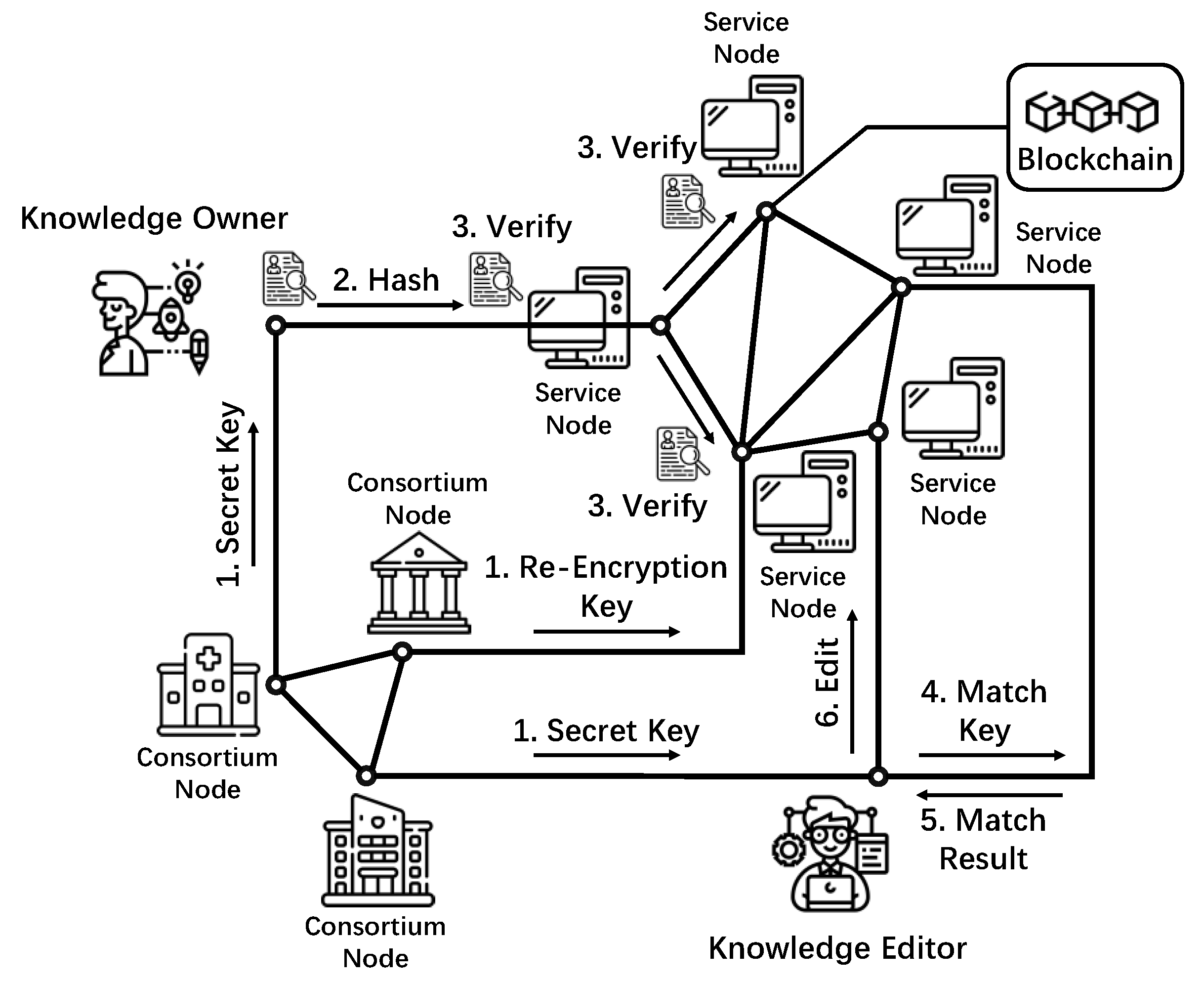
2.1. System Model
2.2. Threat Model
2.3. Problem Statement and Design Goals
3. Preliminaries
3.1. Chameleon Hash with Ephemeral Trapdoors
3.2. Identity-Based Encryption
3.3. Polynomial Function
4. Proposed Schemes
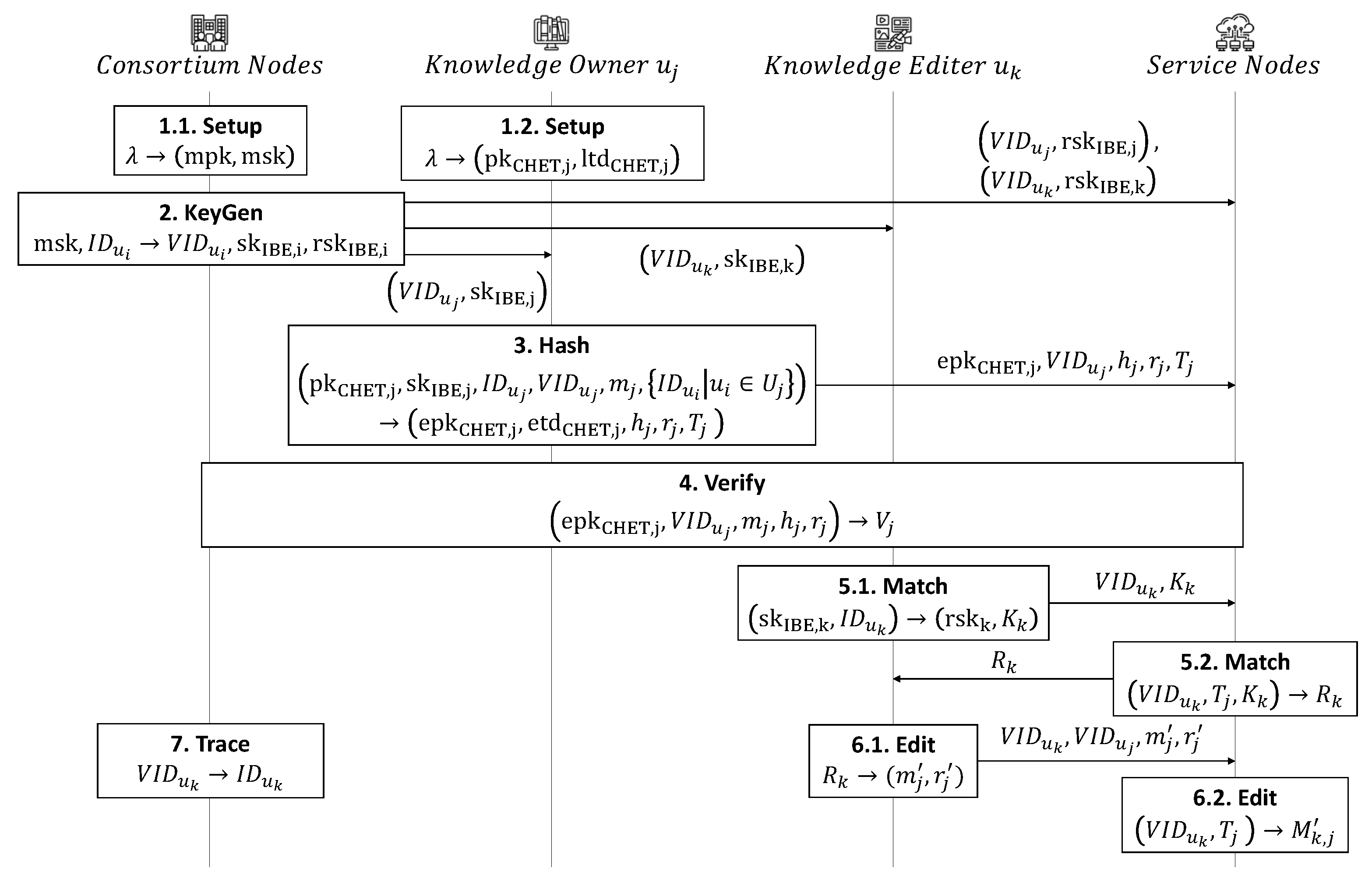
4.1. Proposed PIRB-I
4.1.1. Main Idea
4.1.2. Detailed Construction
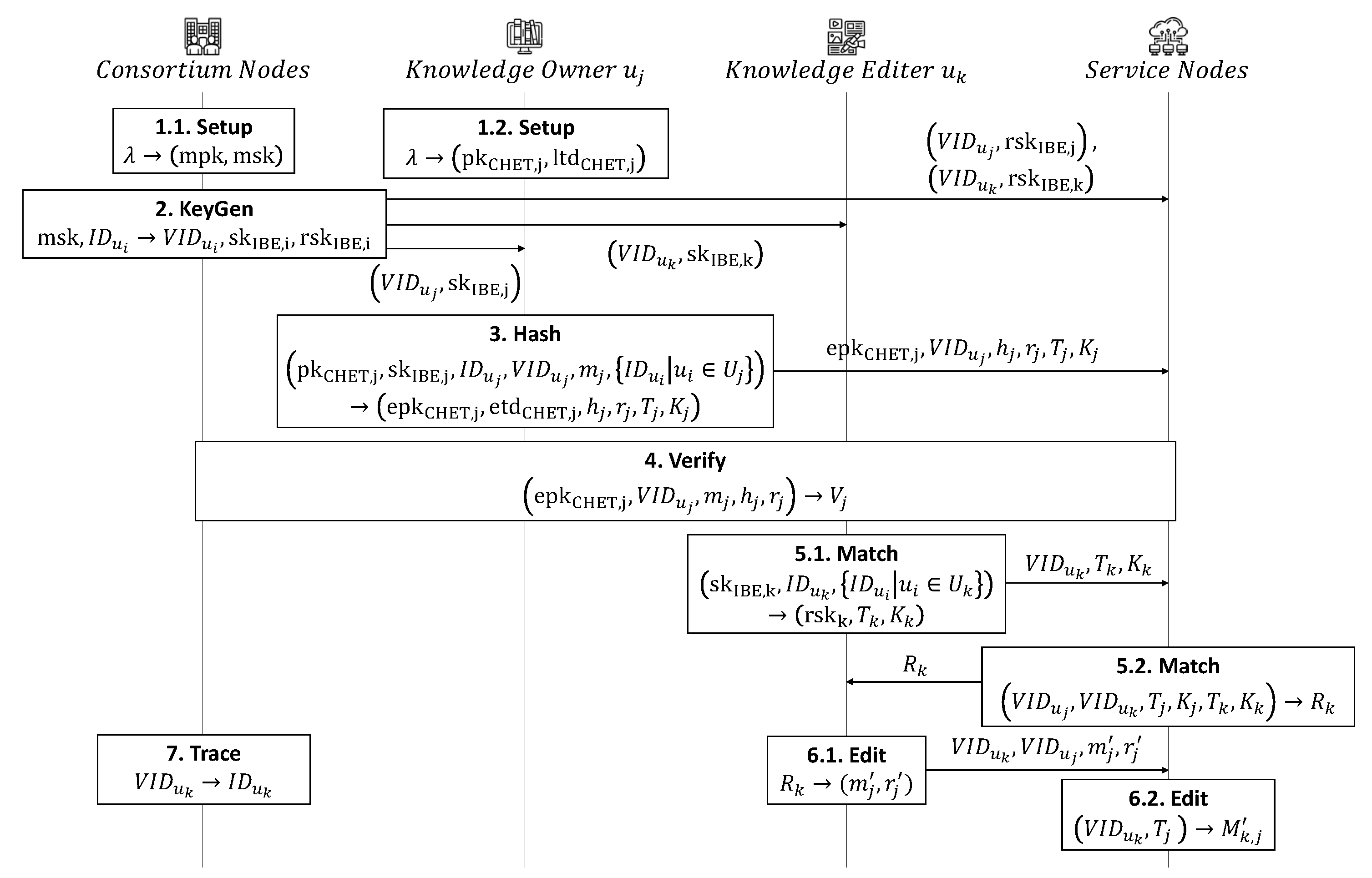
4.2. Proposed PIRB-II
4.2.1. Main Idea
4.2.2. Detailed Construction
5. Theoretical Analysis
5.1. Correctness Analysis
5.2. Security Analysis
| Algorithm 1 An experiment between the adversary and the challenger |
|
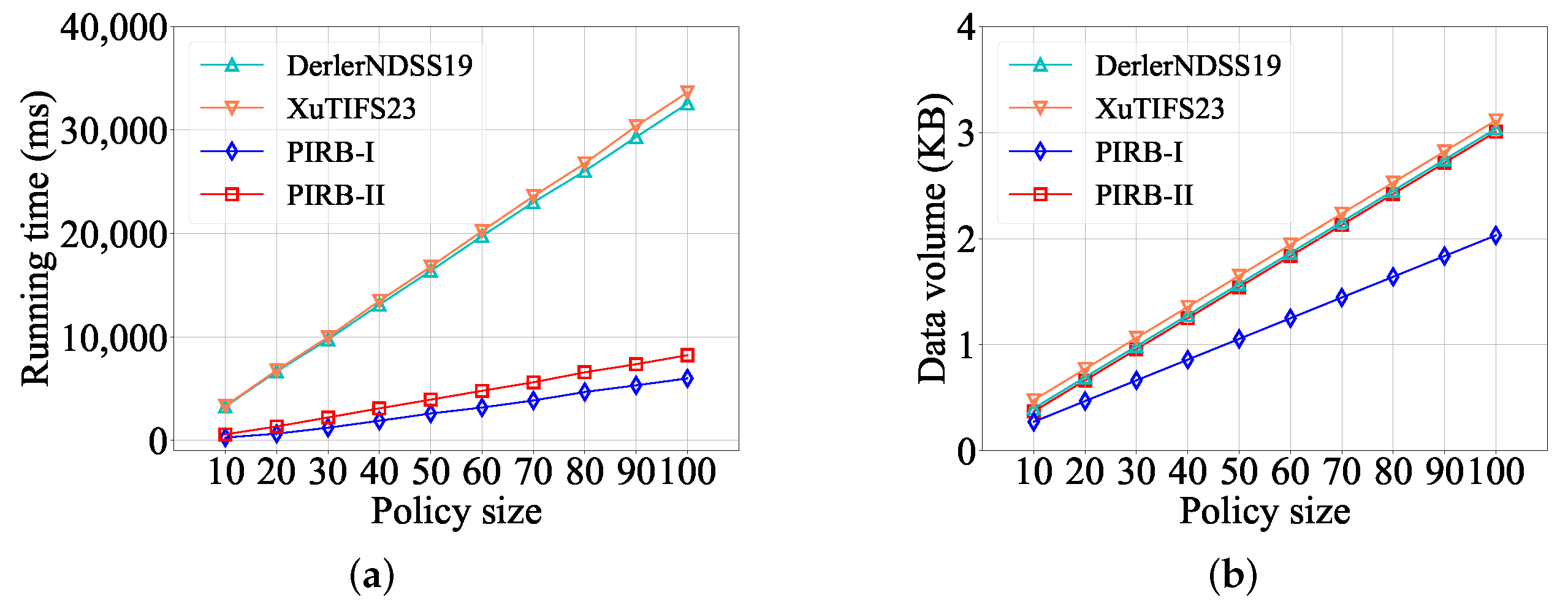
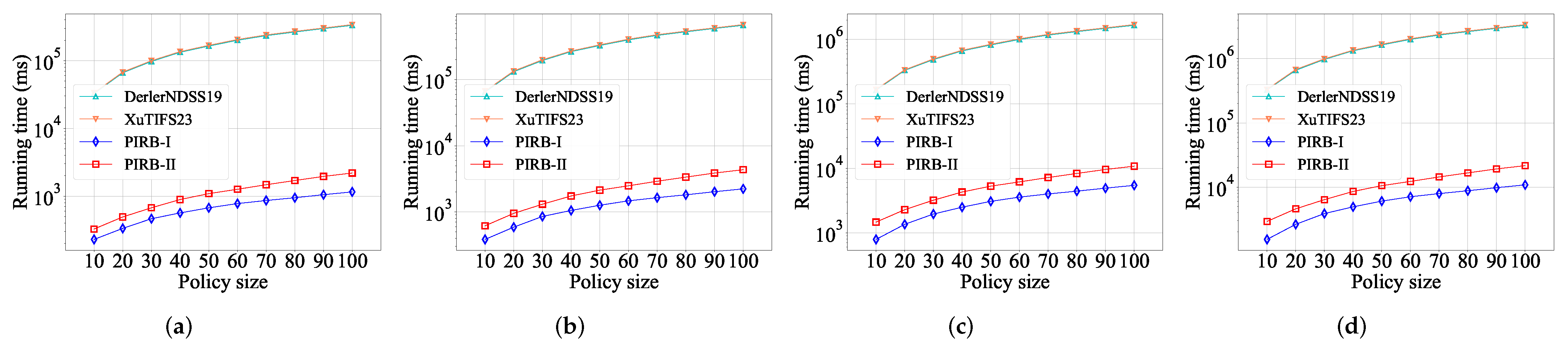
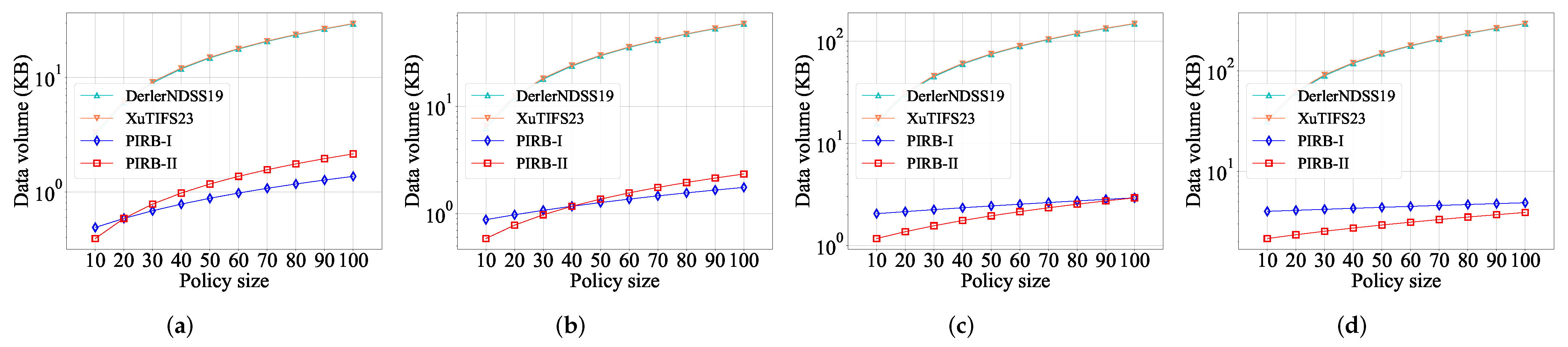
5.3. Complexity Analysis
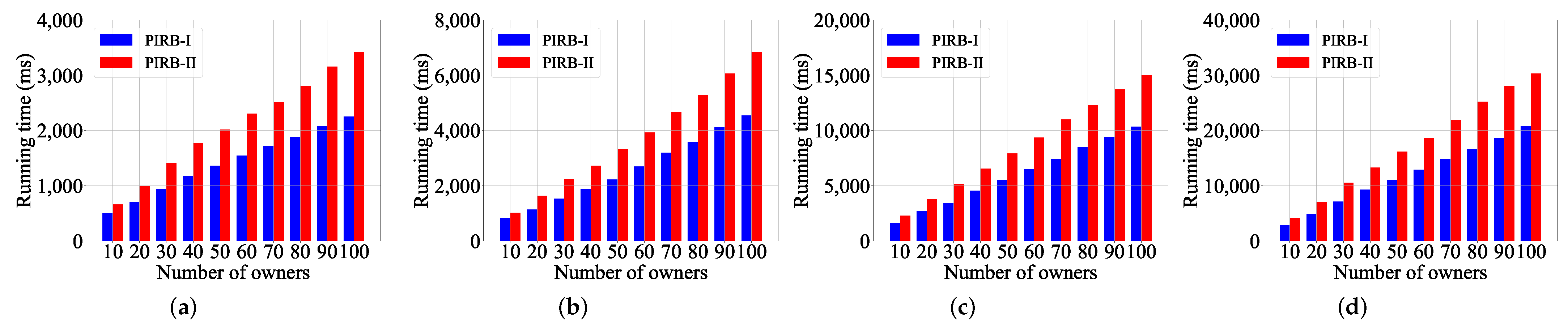
6. Performance Evaluation
6.1. Experimental Configuration
6.2. Experimental Evaluation
7. Related Works
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhou, B.; Li, H.; Xu, L. An Authentication Scheme Using Identity-based Encryption & Blockchain. In Proceedings of the 2018 IEEE Symposium on Computers and Communications (ISCC 2018), Natal, Brazil, 25–28 June 2018; pp. 556–561. [Google Scholar]
- Babu, E.S.; Dadi, A.K.; Singh, K.K.; Nayak, S.R.; Bhoi, A.K.; Singh, A. A distributed identity-based authentication scheme for internet of things devices using permissioned blockchain system. Expert Syst. J. Knowl. Eng. 2022, 39, e12941. [Google Scholar] [CrossRef]
- Huang, C.; Wang, W.; Liu, D.; Lu, R.; Shen, X. Blockchain-Assisted Personalized Car Insurance with Privacy Preservation and Fraud Resistance. IEEE Trans. Veh. Technol. 2023, 72, 3777–3792. [Google Scholar] [CrossRef]
- Xue, J.; Xu, C.; Zhao, J.; Ma, J. Identity-based public auditing for cloud storage systems against malicious auditors via blockchain. Sci. China Inf. Sci. 2019, 62, 32104:1–32104:16. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhang, J.; Xu, W.; Li, Z. Identity-based public data integrity verification scheme in cloud storage system via blockchain. J. Supercomput. 2022, 78, 8509–8530. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, M.; Li, Z.; Zhang, W.; Dong, J.; Wu, T.; Zhang, C.; Zhu, L. Achieving a Blockchain-based Privacy-preserving Quality-aware Knowledge Marketplace in Crowdsensing. In Proceedings of the 20th IEEE International Conference on Embedded and Ubiquitous Computing (EUC 2022), Wuhan, China, 9–11 December 2022; pp. 90–97. [Google Scholar]
- Ren, H.; Li, H.; Liu, D.; Xu, G.; Cheng, N.; Shen, X. Privacy-Preserving Efficient Verifiable Deep Packet Inspection for Cloud-Assisted Middlebox. IEEE Trans. Cloud Comput. 2022, 10, 1052–1064. [Google Scholar] [CrossRef]
- Sharma, P.; Moparthi, N.R.; Namasudra, S.; Shanmuganathan, V.; Hsu, C. Blockchain-based IoT architecture to secure healthcare system using identity-based encryption. Expert Syst. J. Knowl. Eng. 2022, 39, e12915. [Google Scholar] [CrossRef]
- Ren, H.; Xu, G.; Qi, H.; Zhang, T. PriFR: Privacy-preserving Large-scale File Retrieval System via Blockchain for Encrypted Cloud Data. In Proceedings of the 2023 IEEE 9th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), New York, NY, USA, 6–8 May 2023; pp. 16–23. [Google Scholar]
- Hu, C.; Zhang, C.; Lei, D.; Wu, T.; Liu, X.; Zhu, L. Achieving Privacy-Preserving and Verifiable Support Vector Machine Training in the Cloud. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3476–3491. [Google Scholar] [CrossRef]
- Zhang, C.; Hu, C.; Wu, T.; Zhu, L.; Liu, X. Achieving Efficient and Privacy-Preserving Neural Network Training and Prediction in Cloud Environments. IEEE Trans. Dependable Secur. Comput. 2022, 20, 4245–4257. [Google Scholar] [CrossRef]
- Huang, C.; Liu, D.; Yang, A.; Lu, R.; Shen, X. Multi-client Secure and Efficient DPF-based Keyword Search for Cloud Storage. IEEE Trans. Dependable Secur. Comput. 2023, 1–18. [Google Scholar] [CrossRef]
- Regulation, P. General data protection regulation. Intouch 2018, 25, 1–5. [Google Scholar]
- Wu, W.; Li, M.; Qu, K.; Zhou, C.; Shen, X.; Zhuang, W.; Li, X.; Shi, W. Split Learning Over Wireless Networks: Parallel Design and Resource Management. IEEE J. Sel. Areas Commun. 2023, 41, 1051–1066. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, M.; Zhu, L.; Zhang, W.; Wu, T.; Ni, J. FRUIT: A Blockchain-Based Efficient and Privacy-Preserving Quality-Aware Incentive Scheme. IEEE J. Sel. Areas Commun. 2022, 40, 3343–3357. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, F.; Susilo, W.; Tian, H.; Li, J.; Kim, K. Identity-Based Chameleon Hash Scheme without Key Exposure. In Proceedings of the Information Security and Privacy—15th Australasian Conference (ACISP 2010), Sydney, Australia, 5–7 July 2010; Lecture Notes in Computer Science. Steinfeld, R., Hawkes, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6168, pp. 200–215. [Google Scholar]
- Zhou, G.; Ding, X.; Han, H.; Zhu, A. Fine-Grained Redactable Blockchain Using Trapdoor-Hash. IEEE Internet Things J. 2023, 1. [Google Scholar] [CrossRef]
- Derler, D.; Samelin, K.; Slamanig, D.; Striecks, C. Fine-Grained and Controlled Rewriting in Blockchains: Chameleon-Hashing Gone Attribute-Based. In Proceedings of the 26th Annual Network and Distributed System Security Symposium (NDSS 2019), San Diego, CA, USA, 24–27 February 2019; The Internet Society: Reston, VA, USA, 2019. [Google Scholar]
- Xu, S.; Huang, X.; Yuan, J.; Li, Y.; Deng, R.H. Accountable and Fine-Grained Controllable Rewriting in Blockchains. IEEE Trans. Inf. Forensics Secur. 2023, 18, 101–116. [Google Scholar] [CrossRef]
- Ren, H.; Li, H.; Liu, D.; Xu, G.; Shen, X.S. Enabling Secure and Versatile Packet Inspection with Probable Cause Privacy for Outsourced Middlebox. IEEE Trans. Cloud Comput. 2022, 10, 2580–2594. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, M.; Wu, T.; Zhang, W.; Fan, Q.; Zhu, L. Towards Secure Bilateral Friend Query with Conjunctive Policy Matching in Social Networks. In Proceedings of the IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom 2022), Melbourne, Australia, 17–19 December 2022; pp. 98–105. [Google Scholar]
- Zhang, C.; Zhao, M.; Xu, Y.; Wu, T.; Li, Y.; Zhu, L.; Wang, H. Achieving fuzzy matching data sharing for secure cloud-edge communication. China Commun. 2022, 19, 257–276. [Google Scholar] [CrossRef]
- Wu, W.; Chen, N.; Zhou, C.; Li, M.; Shen, X.; Zhuang, W.; Li, X. Dynamic RAN Slicing for Service-Oriented Vehicular Networks via Constrained Learning. IEEE J. Sel. Areas Commun. 2021, 39, 2076–2089. [Google Scholar] [CrossRef]
- Ateniese, G.; Magri, B.; Venturi, D.; Andrade, E.R. Redactable Blockchain—or—Rewriting History in Bitcoin and Friends. In Proceedings of the 2017 IEEE European Symposium on Security and Privacy (EuroS&P 2017), Paris, France, 26–28 April 2017; pp. 111–126. [Google Scholar]
- Deuber, D.; Magri, B.; Thyagarajan, S.A.K. Redactable Blockchain in the Permissionless Setting. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP 2019), San Francisco, CA, USA, 19–23 May 2019; pp. 124–138. [Google Scholar]
- Tian, Y.; Li, N.; Li, Y.; Szalachowski, P.; Zhou, J. Policy-based Chameleon Hash for Blockchain Rewriting with Black-box Accountability. In Proceedings of the ACSAC ’20: Annual Computer Security Applications Conference, Austin, TX, USA, 7–11 December 2020; ACM: New York, NY, USA, 2020; pp. 813–828. [Google Scholar]
- Xu, S.; Ning, J.; Ma, J.; Huang, X.; Deng, R.H. K-Time Modifiable and Epoch-Based Redactable Blockchain. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4507–4520. [Google Scholar] [CrossRef]
- Jia, M.; Chen, J.; He, K.; Du, R.; Zheng, L.; Lai, M.; Wang, D.; Liu, F. Redactable Blockchain From Decentralized Chameleon Hash Functions. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2771–2783. [Google Scholar] [CrossRef]
- Ma, J.; Xu, S.; Ning, J.; Huang, X.; Deng, R.H. Redactable Blockchain in Decentralized Setting. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1227–1242. [Google Scholar] [CrossRef]
- Xie, Z.; Shen, Q.; Li, C.; Dong, J.; Fang, Y. Identity-Based Chameleon Hash without Random Oracles and Application in the Mobile Internet. In Proceedings of the ICC 2021—IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Li, C.; Shen, Q.; Xie, Z.; Dong, J.; Fang, Y.; Wu, Z. Efficient Identity-Based Chameleon Hash for Mobile Devices. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2022), Singapore, 23–27 May 2022; pp. 3039–3043. [Google Scholar]
- Krawczyk, H.; Rabin, T. Chameleon Signatures. In Proceedings of the Network and Distributed System Security Symposium (NDSS 2000), San Diego, CA, USA, 3–4 February 2000; The Internet Society: Reston, VA, USA, 2000. [Google Scholar]
- Camenisch, J.; Derler, D.; Krenn, S.; Pöhls, H.C.; Samelin, K.; Slamanig, D. Chameleon-Hashes with Ephemeral Trapdoors—And Applications to Invisible Sanitizable Signatures. In Proceedings of the Public-Key Cryptography—PKC 2017—20th IACR International Conference on Practice and Theory in Public-Key Cryptography, Amsterdam, The Netherlands, 28–31 March 2017; Proceedings, Part II; Lecture Notes in Computer Science. Fehr, S., Ed.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10175, pp. 152–182. [Google Scholar]
- Samelin, K.; Slamanig, D. Policy-Based Sanitizable Signatures. In Proceedings of the Topics in Cryptology—CT-RSA 2020—The Cryptographers’ Track at the RSA Conference 2020, San Francisco, CA, USA, 24–28 February 2020; Lecture Notes in Computer Science. Jarecki, S., Ed.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12006, pp. 538–563. [Google Scholar]
- Boneh, D.; Franklin, M.K. Identity-Based Encryption from the Weil Pairing. In Proceedings of the Advances in Cryptology—CRYPTO 2001, 21st Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2001; Lecture Notes in Computer Science. Kilian, J., Ed.; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2139, pp. 213–229. [Google Scholar]
- Ateniese, G.; de Medeiros, B. Identity-Based Chameleon Hash and Applications. In Proceedings of the Financial Cryptography, 8th International Conference (FC 2004), Key West, FL, USA, 9–12 February 2004; Revised Papers; Lecture Notes in Computer Science. Juels, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3110, pp. 164–180. [Google Scholar]
- Bao, F.; Deng, R.H.; Ding, X.; Lai, J.; Zhao, Y. Hierarchical Identity-Based Chameleon Hash and Its Applications. In Proceedings of the Applied Cryptography and Network Security—9th International Conference, ACNS 2011, Nerja, Spain, 7–10 June 2011; Lecture Notes in Computer Science. López, J., Tsudik, G., Eds.; Volume 6715, pp. 201–219. [Google Scholar]
- Guo, H.; Tao, X.; Zhao, M.; Wu, T.; Zhang, C.; Xue, J.; Zhu, L. Decentralized Policy-Hidden Fine-Grained Redaction in Blockchain-Based IoT Systems. Sensors 2023, 23, 7105. [Google Scholar] [CrossRef] [PubMed]
- Boneh, D.; Boyen, X. Efficient Selective-ID Secure Identity-Based Encryption without Random Oracles. In Proceedings of the Advances in Cryptology—EUROCRYPT 2004, International Conference on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, 2–6 May 2004; Lecture Notes in Computer Science. Cachin, C., Camenisch, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3027, pp. 223–238. [Google Scholar]
- Boneh, D.; Boyen, X. Secure Identity Based Encryption without Random Oracles. In Proceedings of the Advances in Cryptology—CRYPTO 2004, 24th Annual International CryptologyConference, Santa Barbara, CA, USA, 15–19 August 2004; Lecture Notes in Computer Science. Franklin, M.K., Ed.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3152, pp. 443–459. [Google Scholar]
- Waters, B. Efficient Identity-Based Encryption without Random Oracles. In Proceedings of the Advances in Cryptology—EUROCRYPT 2005, 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Aarhus, Denmark, 22–26 May 2005; Lecture Notes in Computer Science. Cramer, R., Ed.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3494, pp. 114–127. [Google Scholar]
- Gentry, C. Practical Identity-Based Encryption without Random Oracles. In Proceedings of the Advances in Cryptology—EUROCRYPT 2006, 25th Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, 28 May–1 June 2006; Lecture Notes in Computer Science. Vaudenay, S., Ed.; Volume 4004, pp. 445–464. [Google Scholar]
- Chen, J.; Wee, H. Fully, (Almost) Tightly Secure IBE and Dual System Groups. In Proceedings of the Advances in Cryptology—CRYPTO 2013—33rd Annual Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2013; Proceedings, Part II; Lecture Notes in Computer Science. Canetti, R., Garay, J.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8043, pp. 435–460. [Google Scholar]
- Boneh, D.; Raghunathan, A.; Segev, G. Function-Private Identity-Based Encryption: Hiding the Function in Functional Encryption. In Proceedings of the Advances in Cryptology—CRYPTO 2013—33rd Annual Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2013; Proceedings, Part II; Lecture Notes in Computer Science. Canetti, R., Garay, J.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8043, pp. 461–478. [Google Scholar]
- Sun, J.; Xu, G.; Zhang, T.; Yang, X.; Alazab, M.; Deng, R.H. Privacy-Aware and Security-Enhanced Efficient Matchmaking Encryption. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4345–4360. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, M.; Zhu, L.; Wu, T.; Liu, X. Enabling Efficient and Strong Privacy-Preserving Truth Discovery in Mobile Crowdsensing. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3569–3581. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Paradigm | Policy Privacy | Accountability | Flexible Policy | Access Control |
|---|---|---|---|---|---|
| [24] | public-key-based | ✘ | ✘ | ✘ | one-way |
| [18] | attribute-based | ✘ | ✘ | ✔ | one-way |
| [25] | consensus-based | ✘ | ✔ | ✔ | one-way |
| [26] | attribute-based | ✘ | ✔ | ✔ | one-way |
| [27] | attribute-based | ✘ | ✔ | ✔ | one-way |
| [28] | attribute-based | ✘ | ✔ | ✔ | one-way |
| [29] | attribute-based | ✘ | ✘ | ✔ | one-way |
| [19] | attribute-based | ✘ | ✔ | ✔ | one-way |
| [16] | identity-based | ✔ | ✘ | ✘ | one-way |
| [30] | identity-based | ✔ | ✘ | ✘ | one-way |
| [31] | identity-based | ✔ | ✘ | ✘ | one-way |
| [17] | identity-based | ✔ | ✘ | ✘ | one-way |
| PIRB-I | identity-based | ✔ | ✔ | ✔ | one-way |
| PIRB-II | identity-based | ✔ | ✔ | ✔ | bilateral |
| Notation | Description | Notation | Description |
|---|---|---|---|
| The description of the bilinear map. | Owner ’s ephemeral public key of CHET. | ||
| The master public key. | Owner ’s ephemeral trapdoor of CHET. | ||
| The master secret key. | Editor ’s edit re-encryption key. | ||
| The set of all users. | Owner ’s message. | ||
| The set of user ’s authorized editors or interested owners. | The hash of . | ||
| N | The preset maximum policy size. | The randomness of . | |
| The number of elements in . | Owner ’s match ciphertext. | ||
| User ’s identity. | Owner ’s trapdoor ciphertext. | ||
| User ’s virtual identity. | Owner ’s search ciphertext. | ||
| User ’s secret key of IBE. | Owner ’s return ciphertext. | ||
| User ’s re-encryption key of IBE. | Editor ’s match key. | ||
| Owner ’s long-term public key of CHET. | Editor ’s match result with owner . | ||
| Owner ’s long-term trapdoor of CHET. | The set of editor ’s match results. |
| Scheme | Entity | Computational Complexity | Communication Complexity |
|---|---|---|---|
| DerlerNDSS19 | Knowledge Owner | ||
| Service Node | — | ||
| Knowledge Editor | |||
| XuTIFS23 | Knowledge Owner | ||
| Service Node | — | ||
| Knowledge Editor | |||
| PIRB-I | Knowledge Owner | ||
| Service Node | |||
| Knowledge Editor | |||
| PIRB-II | Knowledge Owner | ||
| Service Node | |||
| Knowledge Editor |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Li, Z. PIRB: Privacy-Preserving Identity-Based Redactable Blockchains with Accountability. Electronics 2023, 12, 3754. https://doi.org/10.3390/electronics12183754
Xu Y, Li Z. PIRB: Privacy-Preserving Identity-Based Redactable Blockchains with Accountability. Electronics. 2023; 12(18):3754. https://doi.org/10.3390/electronics12183754
Chicago/Turabian StyleXu, Yuhua, and Zihan Li. 2023. "PIRB: Privacy-Preserving Identity-Based Redactable Blockchains with Accountability" Electronics 12, no. 18: 3754. https://doi.org/10.3390/electronics12183754