

Combination of Fast Finite Shear Wave Transform and Optimized Deep Convolutional Neural Network: A Better Method for Noise Reduction of Wetland Test Images
Abstract
:1. Introduction
- Most nondeep learning algorithms require prior knowledge, such as noise density levels and noise distribution. However, in real-world environments, these influencing factors are often unclear, making it difficult to achieve satisfactory denoising results using existing algorithms.
- Multiscale geometric decomposition technique maps part of the image texture information to high-frequency sub-bands in the noise mapping process. However, when applying the threshold shrinkage method to denoise the high-frequency sub-band images, excessively high thresholds can cause the image to be excessively smoothed. This excessive smoothing phenomenon is caused by the incorrect removal of texture information in the high-frequency sub-bands, which is mistakenly identified as noise.
- Currently, most deep learning algorithms are constructed based on known noisy prior knowledge and can only effectively denoise at specific noise density levels, typically lacking strong adaptability. Due to the network effects generated during the upsampling process, some important image details are lost.
- A new image-denoising method based on the FFSTnet network model is proposed, which effectively overcomes the dependence of deep neural networks on large amounts of data. By decomposing the image into several sub-band images through FFST, the model still has good denoising effects with a small amount of data, and improves the model’s generalization ability.
- Due to the excellent properties of FFST and inverse FFST transforms, no information loss occurs during image decomposition, which better preserves the texture and edge details of the image.
- Various random training strategies are introduced during the model training process, which enables the model to handle the denoising of images with different noise density levels and actual noise, enhancing the flexibility of the model.
2. Methods
2.1. Fast Finite Shearlet Transform
- (1)
- The window function W used in FFST is a function established based on the frequency domain, and its selection needs to satisfy the following conditions:
- (2)
- In the multiscale decomposition process of FFST, a completely finite scale function is used, and its mathematical expression is:
- (3)
- In the process of FFST direction localization decomposition, the shear filter is used, and its mathematical expression is as follows:
2.2. Basic Model of the Convolutional Neural Network (CNN)
2.2.1. Convolution Layer
2.2.2. Pooling Layer
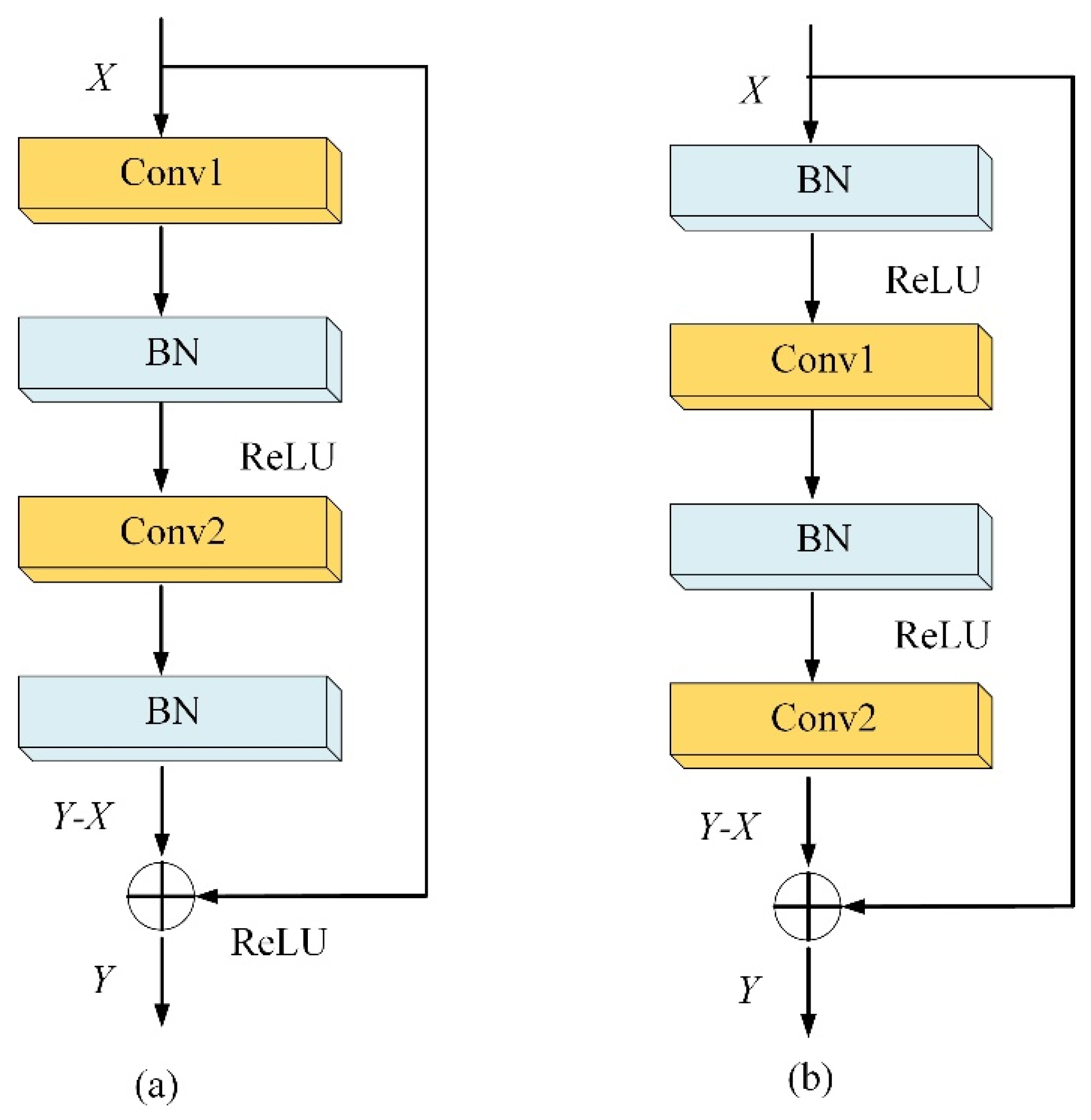
2.2.3. Residual Network
2.3. Important Parameters and Optimization Methods
2.3.1. Batch Normalization
2.3.2. Receptive Field
3. Image Denoising Network Model Based on FFSTnet
3.1. The Structure of the FFSTnet Denoising Model
3.2. FFSTnet Noise Reduction Model Detailed Description
3.3. FFSTnet Noise Reduction Model Important Parameter Description
4. Experimental Data Verification
4.1. Experimental Analysis of Real Image Noise Reduction
4.2. Simulation Experiment Analysis of Grayscale Image Denoising
4.2.1. Compared with Traditional Methods
4.2.2. Signal-to-Noise Ratio Analysis of the Denoising Effect
- Compared to the Meanfilter and Medianfilter denoising algorithms, the proposed FFSTnet denoising model in this paper has improved PSNR values by 5.14 dB and 5.41 dB, respectively, at σ = 15. This represents a significant improvement in image denoising, indicating that traditional filtering-based denoising algorithms cannot effectively preserve the texture information of the image in nonsmooth areas, resulting in poor denoising performance. Compared to deep learning algorithms, the FFSTnet model demonstrates better capability in extracting image features, leading to more ideal denoising results.
- Compared to the K-SVD and BM3D algorithms, the PSNR values of the proposed method generally improved by 0.19–4.24 dB, demonstrating good denoising performance. Firstly, the K-SVD denoising algorithm has a strong adaptive learning capability, which can effectively compensate for the limitations of traditional dictionary matrix bases in adapting to image textures and achieve good denoising results. However, a drawback is that it requires a large amount of computational power for dictionary updates. Secondly, the core idea of the BM3D denoising algorithm is to use search image similar blocks to filter in the transform domain, obtain a large number of overlapping local block estimates, and perform weighted averaging to achieve good denoising results. However, the proposed FFSTnet denoising model demonstrates a good ability to obtain optimal representations containing texture, contours, edges, etc., at different scales, directions, and resolutions when dealing with images with regular repetitive structures, resulting in decent denoising performance. Conversely, for images with irregular textures, this specific prior advantage may be lost, leading to suboptimal denoising results.
- Compared to the DnCNN denoising algorithm, the denoising performance of the FFSTnet model improved by 0.17 dB, 0.22 dB, and 0.27 dB, respectively, at σ = 15, 25, and 50, indicating that the FFSTnet model has better denoising capabilities under the same noise conditions, surpassing DnCNN. This is because when FFSTnet decomposes the image, the region size exceeds that of DnCNN. The larger the receptive field area, the more valuable spatial features and texture information can be extracted, which to some extent improves the denoising performance of the FFSTnet model.
- Compared with the DSTnet algorithm, when σ = 15, 25, and 50, the noise reduction effect is improved by 0.09 db, 0.09 db, and 0.05 db, respectively, which proves that the FFSTnet model has a better noise reduction effect than the DSTnet model because FFST is superior to DST in the characteristics of directional localization, different scales, and different directions.
- From the perspective of the average PSNR values, it is evident that the FFSTnet denoising model has higher PSNR values than other denoising algorithms under different noise conditions. A higher PSNR value indicates better denoising performance. The PSNR values are 33.34 dB, 30.99 dB, and 27.92 dB, respectively, further demonstrating the effectiveness of the proposed method.
4.3. Experimental Analysis of Real Image Noise Reduction
4.3.1. Comparative Analysis of Noise Reduction in Gray Level Image
- Each denoising algorithm achieved the expected results when denoising the third image. Secondly, K-SVD and BM3D denoising algorithms performed poorly when denoising the first, second, and fourth images in Figure 7. In comparison, the denoising effect of the FFSTnet denoising model on these images was significantly better than that of DnCNN and MWCNN. However, it should be noted that both FFSTnet and MWCNN exhibited over-smoothing in certain cases, which means that these two methods may partially lose the fine details of the image.
- The overall denoising performance of K-SVD and BM3D algorithms on real noisy images was poor. The main reason for this result is that the K-SVD algorithm has limited denoising effectiveness on the texture and edge parts of high-frequency and low-frequency images when optimizing the dictionary. Although the K-SVD algorithm performs well in some specific scenarios, it has certain limitations when dealing with images containing nonrepetitive structural noise. On the other hand, the BM3D algorithm denoises by utilizing the similarity between blocks. However, when processing images with nonrepetitive structural noise, the characteristics of this noise result in the low similarity between blocks, which affects the denoising effectiveness of the BM3D algorithm.
- Compared to DnCNN, MWCNN achieved better denoising performance. This result is mainly attributed to the excellent time-frequency localization characteristics and detail preservation ability of the discrete wavelet transform (DWT) used in MWCNN. Additionally, DWT can effectively balance the size of the receptive field and improve computational efficiency, thereby further enhancing the denoising effectiveness.
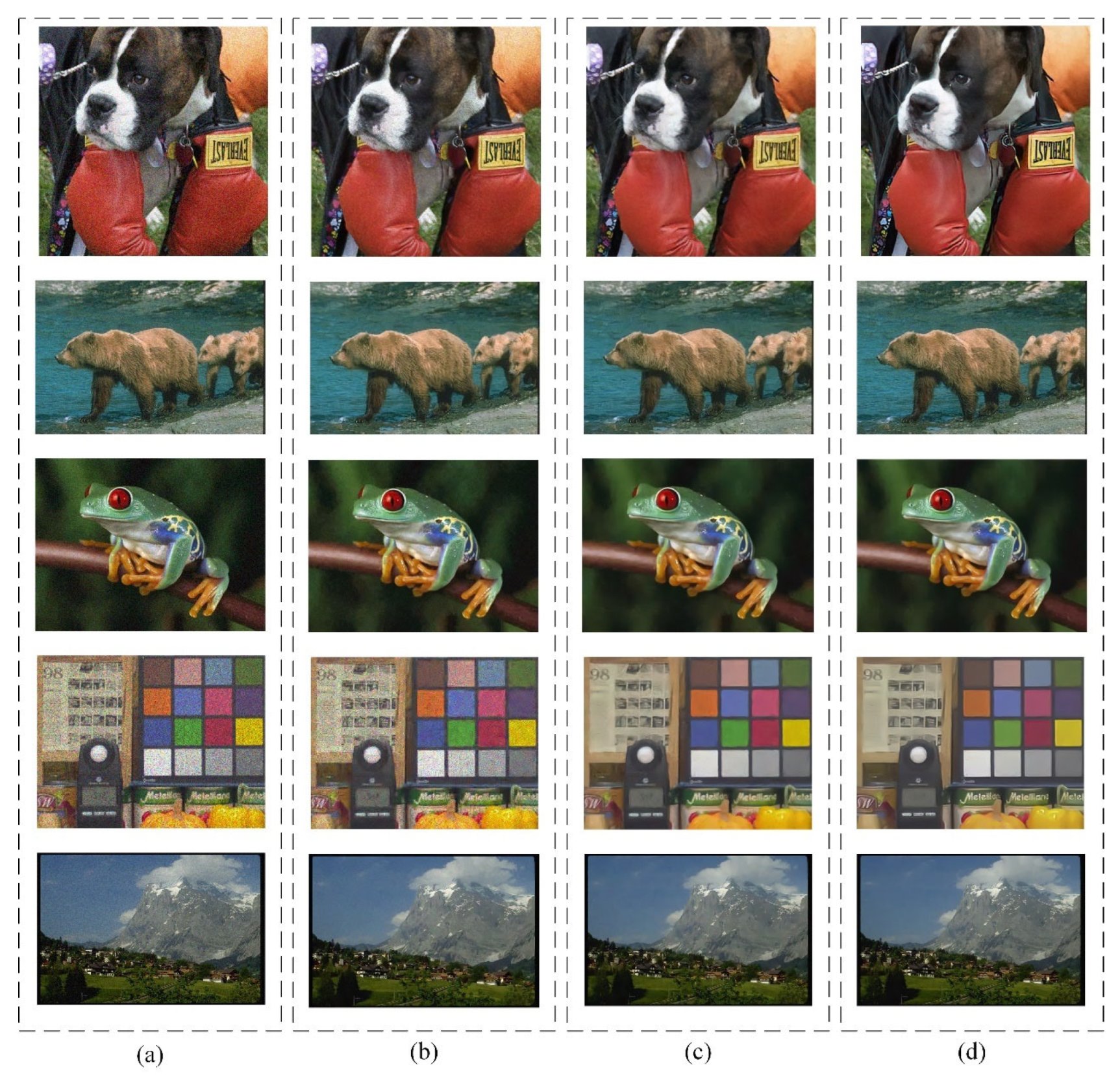
4.3.2. Contrastive Analysis of Noise Reduction in Color Images
4.4. Analysis of Computational Speed
- When removing noise from color images, all denoising algorithms require more time compared to processing grayscale images. This is because color images contain richer information, and the transformation of luminance and chrominance components requires more computational resources to support.
- DnCNN, MWCNN, and FFSTnet can effectively harness the powerful computing capabilities of GPUs. However, for the BM3D model, there is a lack of GPU acceleration support when processing color images, resulting in suboptimal computational speed.
- The FFSTnet denoising model performs exceptionally well in handling noise in both grayscale and color images, requiring the shortest processing time. Additionally, the model not only exhibits flexibility to adapt to various practical application scenarios, but also demonstrates outstanding denoising effectiveness. Therefore, FFSTnet has extensive application value and strong competitiveness in solving real-world problems.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, H.; Peng, L.; Zhang, H.; He, Y.; Cao, S.; Lu, L. Dynamic PET image denoising using deep image prior combined with regularization by denoising. IEEE Access 2021, 9, 52378–52392. [Google Scholar] [CrossRef]
- Tran, T.O.; Vo, T.H.; Le, N.Q.K. Omics-based deep learning approaches for lung cancer decision-making and therapeutics development. Brief. Funct. Genom. 2023, 7, elad031. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Q.; Chen, K.; Yu, Y.; Le, N.Q.K.; Chua, M.C.H. Prediction of anticancer peptides based on an ensemble model of deep learning and machine learning using ordinal positional encoding. Brief. Bioinform. 2023, 24, bbac630. [Google Scholar] [CrossRef] [PubMed]
- Shi, K.; Guo, Z. Non-Gaussian Noise Removal via Gaussian Denoisers with the Gray Level Indicator. J. Math. Imaging Vis. 2023, 1–17. [Google Scholar] [CrossRef]
- Li, P.; Liu, X.; Xiao, H. Quantum image median filtering in the spatial domain. Quantum Inf. Process. 2018, 17, 49. [Google Scholar] [CrossRef]
- Maria, H.H.; Jossy, A.M.; Malarvizhi, G.; Jenitta, A. Analysis of lifting scheme based double density dual-tree complex wavelet transform for de-noising medical images. Optik 2021, 241, 166883. [Google Scholar] [CrossRef]
- Lin, Z.; Jia, S.; Zhou, X.; Zhang, H.; Wang, L.; Li, G.; Wang, Z. Digital holographic microscopy phase noise reduction based on an over-complete chunked discrete cosine transform sparse dictionary. Opt. Lasers Eng. 2023, 166, 107571. [Google Scholar] [CrossRef]
- Ma, X.; Hu, S.; Liu, S. SAR image de-noising based on shift invariant K-SVD and guided filter. Remote Sens. 2017, 9, 1311. [Google Scholar] [CrossRef]
- Cho, S.I.; Kang, S.J. Gradient prior-aided CNN denoiser with separable convolution-based optimization of feature dimension. IEEE Trans. Multimed. 2018, 21, 484–493. [Google Scholar] [CrossRef]
- Hsu, L.Y.; Hu, H.T. QDCT-based blind color image watermarking with aid of GWO and DnCNN for performance improvement. IEEE Access 2021, 9, 155138–155152. [Google Scholar] [CrossRef]
- Arivazhagan, S.; Ganesan, L.; Kumar, T.G.S. Texture classification using ridgelet transform. Pattern Recognit. Lett. 2006, 27, 1875–1883. [Google Scholar] [CrossRef]
- Ma, J.; Plonka, G. The curvelet transform. IEEE Signal Process. Mag. 2010, 27, 118–133. [Google Scholar] [CrossRef]
- Senthilkumar, M.; Periasamy, P.S. RETRACTED: Contourlet transform and adaptive neuro-fuzzy strategy–based color image watermarking. Meas. Control 2020, 53, 287–295. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, S.; Wen, T.; Yang, H.; Niu, P. Coefficient difference based watermark detector in nonsubsampled contourlet transform domain. Inf. Sci. 2019, 503, 274–290. [Google Scholar] [CrossRef]
- Po, D.D.Y.; Do, M.N. Directional multiscale modeling of images using the contourlet transform. IEEE Trans. Image Process. 2006, 15, 1610–1620. [Google Scholar] [CrossRef]
- Zhang, H.; Cheng, J.; Tian, M.; Liu, J.; Shao, G.; Shao, S. A Reverberation Noise Suppression Method of Sonar Image Based on Shearlet Transform. IEEE Sens. J. 2022, 23, 2672–2683. [Google Scholar] [CrossRef]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, L.; Ding, X. SAR image despeckling with a multilayer perceptron neural network. Int. J. Digit. Earth 2019, 12, 354–374. [Google Scholar] [CrossRef]
- Chen, Y.; Pock, T. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1256–1272. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Singh, G.; Mittal, A.; Aggarwal, N. ResDNN: Deep residual learning for natural image denoising. IET Image Process. 2020, 14, 2425–2434. [Google Scholar] [CrossRef]
- Yu, X.; Cui, Y.; Wang, X.; Zhang, J. Image fusion algorithm in integrated space-ground-sea wireless networks of B5G. EURASIP J. Adv. Signal Process. 2021, 2021, 55. [Google Scholar] [CrossRef]
- Lyu, Z.; Zhang, C.; Han, M. DSTnet: A new discrete shearlet transform-based CNN model for image denoising. Multimed. Syst. 2021, 27, 1165–1177. [Google Scholar] [CrossRef]
- Agis, D.; Pozo, F. Vibration-Based Structural Health Monitoring Using Piezoelectric Transducers and Parametric t-SNE. Sensors 2020, 20, 1716. [Google Scholar] [CrossRef]
- Bnou, K.; Raghay, S.; Hakim, A. A wavelet denoising approach based on unsupervised learning model. EURASIP J. Adv. Signal Process. 2020, 2020, 36. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Gu, K.; Li, L.; Lu, H.; Min, X.; Lin, W. A fast reliable image quality predictor by fusing micro- and macro-structures. IEEE Trans. Ind. Electron. 2017, 64, 3903–3912. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level wavelet-CNN for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 773–782. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FFSTnet | FFSTnet | FFSTnet | FFSTnet | |
|---|---|---|---|---|
| Solver name (algorithm) | sgdm | sgdm | adam | adam |
| InitialLearnRate | 0.0005 | 0.0005 | 0.0005 | 0.0005 |
| MaxEpochs | 30 | 30 | 30 | 30 |
| MiniBatchSize | 64 | 128 | 64 | 128 |
| ValidationFrequency | 50 | 50 | 50 | 50 |
| Shuffle | Every epoch | Every epoch | Every epoch | Every epoch |
| ExecutionEnvironment | GPU | GPU | GPU | GPU |
| PSNR | 31.35 db | 32.27 db | 33.62 db | 35.12 db |
| No. | Noise Reduction Method | Type |
|---|---|---|
| 1 | Mean filtering | Belongs to linear filtering and denoising methods |
| 2 | Median filtering | Belongs to nonlinear filtering and denoising methods |
| 3 | K-SVD [25] | Belongs to adaptive overcomplete dictionary denoising methods |
| 4 | BM3D [26] | Belongs to nonlocal similarity denoising methods |
| 5 | DnCNN [20] | Belongs to discriminative learning denoising methods |
| Images | Starfish | House | test002 | test003 | test018 | test042 | Ave. |
|---|---|---|---|---|---|---|---|
| Noise level σ = 15 | |||||||
| Meanfilter | 29.98 | 27.59 | 27.89 | 25.85 | 30.65 | 26.10 | 28.01 |
| Medianfilter | 29.71 | 27.74 | 27.91 | 25.91 | 29.99 | 26.25 | 27.92 |
| K-SVD | 33.22 | 29.58 | 30.84 | 30.82 | 33.20 | 30.22 | 31.31 |
| BM3D | 34.93 | 34.87 | 34.97 | 35.03 | 35.03 | 35.00 | 34.97 |
| DnCNN | 34.95 | 32.03 | 32.68 | 32.52 | 35.25 | 32.03 | 33.24 |
| DSTnet | 35.03 | 32.06 | 32.71 | 32.57 | 35.28 | 32.09 | 33.29 |
| FFSTnet | 35.12 | 32.14 | 32.73 | 32.60 | 35.33 | 32.13 | 33.34 |
| Noise level σ = 25 | |||||||
| Meanfilter | 27.51 | 26.02 | 26.46 | 24.76 | 28.04 | 24.97 | 26.29 |
| Medianfilter | 26.48 | 25.31 | 25.84 | 24.30 | 26.82 | 24.49 | 25.54 |
| K-SVD | 30.65 | 26.85 | 28.25 | 28.06 | 30.66 | 27.92 | 28.73 |
| BM3D | 28.57 | 28.56 | 28.60 | 28.50 | 28.47 | 28.57 | 28.55 |
| DnCNN | 33.08 | 29.35 | 30.22 | 30.07 | 33.06 | 29.65 | 30.91 |
| DSTnet | 33.21 | 29.37 | 30.24 | 30.09 | 33.10 | 29.66 | 30.94 |
| FFSTnet | 33.30 | 29.40 | 30.27 | 30.12 | 33.14 | 29.69 | 30.99 |
| Noise level σ = 50 | |||||||
| Meanfilter | 22.76 | 22.27 | 22.85 | 21.73 | 23.07 | 21.85 | 22.42 |
| Medianfilter | 21.33 | 21.00 | 21.49 | 20.55 | 21.58 | 20.63 | 21.10 |
| K-SVD | 26.04 | 22.90 | 25.54 | 24.28 | 27.77 | 24.39 | 25.15 |
| BM3D | 26.62 | 26.64 | 26.63 | 26.65 | 26.65 | 26.65 | 26.64 |
| DnCNN | 30.01 | 25.75 | 27.28 | 26.93 | 30.36 | 26.68 | 27.84 |
| DSTnet | 30.23 | 25.77 | 27.29 | 26.89 | 30.41 | 26.69 | 27.88 |
| FFSTnet | 30.28 | 25.79 | 27.31 | 26.94 | 30.50 | 26.71 | 27.92 |
| Indicators | PSIM | SSIM | ||||
|---|---|---|---|---|---|---|
| Methods | FFSTnet | DSTnet | DnCNN | FFSTnet | DSTnet | DnCNN |
| Starfish | 0.9992 | 0.9986 | 0.9981 | 0.9449 | 0.9445 | 0.9422 |
| House | 0.9983 | 0.9979 | 0.9975 | 0.8876 | 0.8873 | 0.8855 |
| test002 | 0.9985 | 0.9980 | 0.9976 | 0.9183 | 0.9176 | 0.9148 |
| test003 | 0.9988 | 0.9983 | 0.9977 | 0.9214 | 0.9202 | 0.9171 |
| test018 | 0.9987 | 0.9982 | 0.9973 | 0.9525 | 0.9517 | 0.9493 |
| test042 | 0.9977 | 0.9974 | 0.9972 | 0.9112 | 0.9096 | 0.9088 |
| Ave. | 0.9985 | 0.9981 | 0.9976 | 0.9227 | 0.9218 | 0.9196 |
| Size | BM3D | DnCNN | MWCNN | FFSTnet | ||||
|---|---|---|---|---|---|---|---|---|
| Gray | Color | Gray | Color | Gray | Color | Gray | Color | |
| Device | CPU | GPU | GPU | GPU | ||||
| 256 × 256 | 0.67 | 1.36 | 0.019 | 0.022 | 0.067 | 0.077 | 0.014 | 0.013 |
| 512 × 512 | 2.85 | 4.23 | 0.039 | 0.051 | 0.109 | 0.186 | 0.022 | 0.029 |
| 1024 × 1024 | 10.61 | 22.74 | 0.135 | 0.163 | 0.372 | 0.431 | 0.043 | 0.051 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, X.; Bai, H.; Zhao, Y.; Wang, Z. Combination of Fast Finite Shear Wave Transform and Optimized Deep Convolutional Neural Network: A Better Method for Noise Reduction of Wetland Test Images. Electronics 2023, 12, 3557. https://doi.org/10.3390/electronics12173557
Cui X, Bai H, Zhao Y, Wang Z. Combination of Fast Finite Shear Wave Transform and Optimized Deep Convolutional Neural Network: A Better Method for Noise Reduction of Wetland Test Images. Electronics. 2023; 12(17):3557. https://doi.org/10.3390/electronics12173557
Chicago/Turabian StyleCui, Xiangdong, Huajun Bai, Ying Zhao, and Zhen Wang. 2023. "Combination of Fast Finite Shear Wave Transform and Optimized Deep Convolutional Neural Network: A Better Method for Noise Reduction of Wetland Test Images" Electronics 12, no. 17: 3557. https://doi.org/10.3390/electronics12173557