
A Deep Learning-Enhanced Multi-Modal Sensing Platform for Robust Human Object Detection and Tracking in Challenging Environments
 , , , and
, , , and
Abstract
:1. Introduction
2. System Architecture
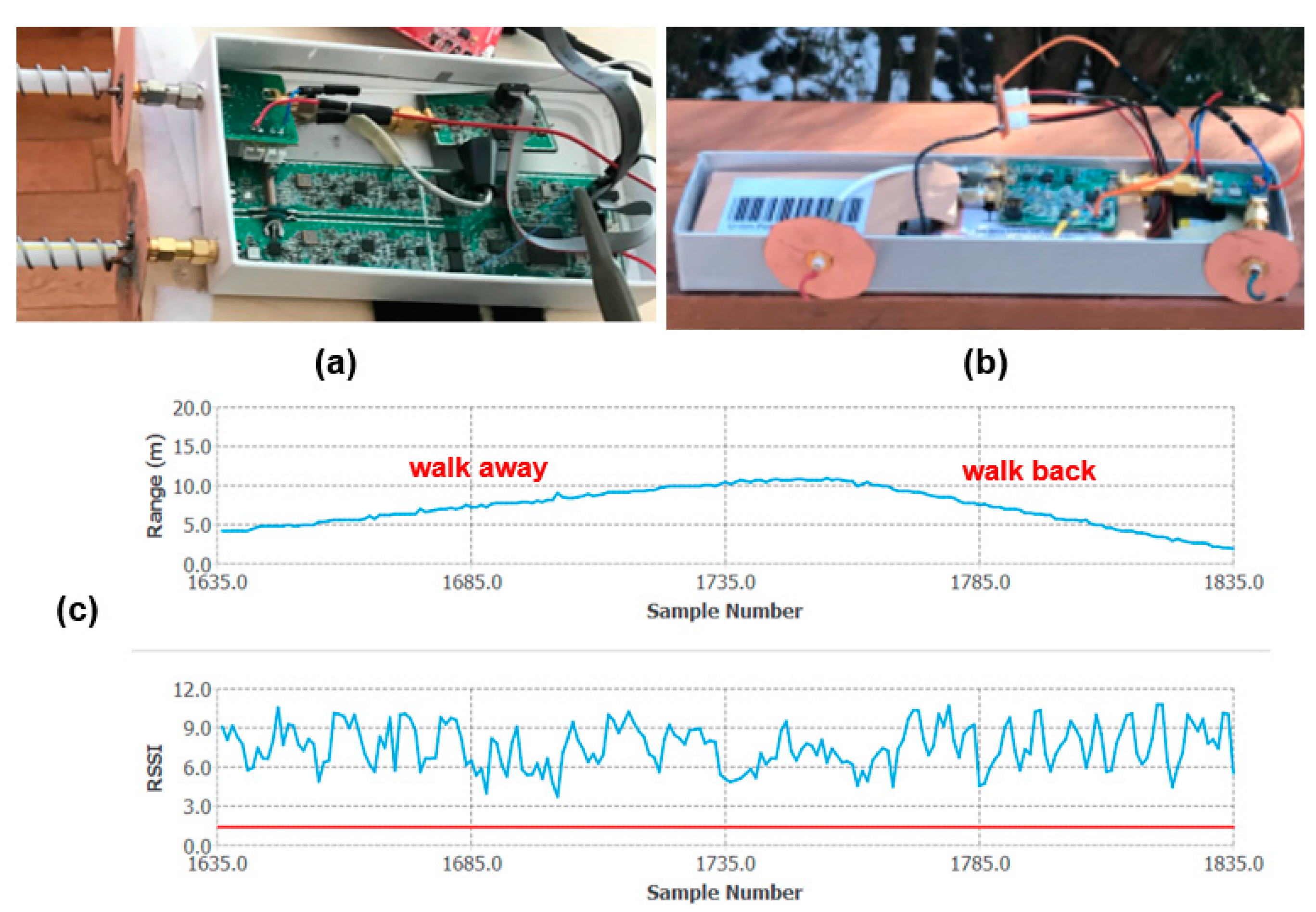
2.1. Radio Frequency (RF) Subsystem
- The RF signals were sampled multiple times, typically eight samples, and Fast Fourier Transform (FFT) calculations were performed on each sample. The results were then averaged, improving the SNR, and extending the detection range;
- Due to varying hardware gain responses across the baseband spectrum, it was necessary to determine the local signal noise floor as a reference. By comparing the real signal with the local noise floor instead of the entire baseband noise floor, accurate detection can be achieved;
- Local averaging windows were utilized to establish the appropriate reference level, contributing to improved detection accuracy.
2.2. EO/IR Subsystem
2.2.1. Electro-Optical (EO) Camera
2.2.2. Infrared (IR) Camera
2.2.3. Laser Rangefinder
2.3. Sensor System Integration
2.3.1. Hardware System Assembly
- (1)
- The radar sensor developed by Intelligent Fusion Technology, Inc., Germantown, MD, USA;
- (2)
- The 3D EO camera from Stereolabs, San Francisco, CA, USA;
- (3)
- The FLIR Boson 320 IR camera from Teledyne, Wilsonville, OR, USA;
- (4)
- The SF30/C laser rangefinder from Lightware, Boulder, Colorado, USA;
- (5)
- The HWT905 inertial measurement unit (IMU) sensor from Wit-Motion, Shenzhen, Guangdong, China;
- (6)
- X-RSW series motorized rotary stage from Zaber, Vancouver, BC, Canada;
- (7)
- The IG42 all-terrain robot from SuperDroid Robots, Fuquay-Varina, NC, USA.
2.3.2. Software Package
- (1)
- Display the image acquired from EO/IR cameras;
- (2)
- Configure the machine learning model for human object detection;
- (3)
- Receive and display the measurement results from the IMU sensor;
- (4)
- Receive and display the measurement results from the laser rangefinder;
- (5)
- Send the control command to the rotary stage;
- (6)
- Receive and display the measurement results from the radar;and
- (7)
- Perform real-time object tracking to follow the interested object.
3. Enhance the MIERFS System with Deep Learning Methods
3.1. Deep Learning-Based Algorithm for Human Object Detection
- (1)
- Human object detection in indoor environments;
- (2)
- Human object detection in outdoor environments;
- (3)
- Detection of multiple human objects within the same IR image;
- (4)
- Human object detection at different distances; and
- (5)
- Human object detection regardless of different human body gestures.
3.2. Sensor Fusion and Multi-Target Tracking
3.2.1. Sensor Fusion
3.2.2. DL-Based Algorithm for Human Object Tracking
4. Experiments and Results
4.1. Indoor Experiments
4.2. Outdoor Experiments
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Perera, F.; Al-Naji, A.; Law, Y.; Chahl, J. Human Detection and Motion Analysis from a Quadrotor UAV. IOP Conf. Ser. Mater. Sci. Eng. 2018, 405, 012003. [Google Scholar] [CrossRef]
- Rudol, P.; Doherty, P. Human body detection and geolocalization for uav search and rescue missions using color and thermal imagery. In Proceedings of the Aerospace Conference, Big Sky, MT, USA, 1–8 March 2008; pp. 1–8. [Google Scholar]
- Andriluka, M.; Schnitzspan, P.; Meyer, J.; Kohlbrecher, S.; Petersen, K.; von Stryk, O.; Roth, S.; Schiele, B. Vision based victim detection from unmanned aerial vehicles. In Proceedings of the Intelligent Robots and Systems (IROS), IEEE/RSJ International Conference onIntelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 1740–1747. [Google Scholar]
- Gay, C.; Horowitz, B.; Elshaw, J.J.; Bobko, P.; Kim, I. Operator suspicion and human-machine team performance under mission scenarios of unmanned ground vehicle operation. IEEE Access 2019, 7, 36371–36379. [Google Scholar] [CrossRef]
- Xia, X.; Meng, Z.; Han, X.; Li, H.; Tsukiji, T.; Xu, R.; Zheng, Z.; Ma, J. An automated driving systems data acquisition and analytics platform. Transp. Res. Part CEmerg. Technol. 2023, 151, 104120. [Google Scholar] [CrossRef]
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting tassels in RGB UAV imagery with improved YOLOv5 based on transfer learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2004, arXiv:2004.10934. [Google Scholar]
- Chen, N.; Chen, Y.; Blasch, E.; Ling, H.; You, Y.; Ye, X. Enabling Smart Urban Surveillance at The Edge. In Proceedings of the IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 3–5 November 2017; pp. 109–111. [Google Scholar]
- Munir, A.; Kwon, J.; Lee, J.H.; Kong, J.; Blasch, E.; Aved, A.J.; Muhammad, K. FogSurv: A Fog-Assisted Architecture for Urban Surveillance Using Artificial Intelligence and Data Fusion. IEEE Access 2021, 9, 111938–111959. [Google Scholar] [CrossRef]
- Blasch, E.; Pham, T.; Chong, C.-Y.; Koch, W.; Leung, H.; Braines, D.; Abdelzaher, T. Machine Learning/Artificial Intelligence for Sensor Data Fusion–Opportunities and Challenges. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 80–93. [Google Scholar] [CrossRef]
- He, Y.; Deng, B.; Wang, H.; Cheng, L.; Zhou, K.; Cai, S.; Ciampa, F. Infrared machine vision and infrared thermography with deep learning: A review. Infrared Phys. Technol. 2021, 116, 103754. [Google Scholar] [CrossRef]
- Huang, W.; Zhang, Z.; Li, W.; Tian, J. Moving object tracking based on millimeter-wave radar and vision sensor. J. Appl. Sci. Eng. 2018, 21, 609–614. [Google Scholar]
- Van Eeden, W.D.; de Villiers, J.P.; Berndt, R.J.; Nel, W.A.J. Micro-Doppler radar classification of humans and animals in an operational environment. Expert Syst. Appl. 2018, 102, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Majumder, U.; Blasch, E.; Garren, D. Deep Learning for Radar and Communications Automatic Target Recognition; Artech House: London, UK, 2020. [Google Scholar]
- Premebida, C.; Ludwig, O.; Nunes, U. LIDAR and vision-based pedestrian detection system. J. Field Robot. 2009, 26, 696–711. [Google Scholar] [CrossRef]
- Duan, Y.; Irvine, J.M.; Chen, H.-M.; Chen, G.; Blasch, E.; Nagy, J. Feasibility of an Interpretability Metric for LIDAR Data. In Proceedings of the SPIE 10645, Geospatial Informatics, Motion Imagery, and Network Analytics VIII, Orlando, FL, USA, 22 May 2018; p. 1064506. [Google Scholar]
- Salehi, B.; Reus-Muns, G.; Roy, D.; Wang, Z.; Jian, T.; Dy, J.; Ioannidis, S.; Chowdhury, K. Deep Learning on Multimodal Sensor Data at the Wireless Edge for Vehicular Network. IEEE Trans. Veh. Technol. 2022, 71, 7639–7655. [Google Scholar] [CrossRef]
- Sun, S.; Zhang, Y.D. 4D automotive radar sensing for autonomous vehicles: A sparsity-oriented approach. IEEE J. Sel. Top. Signal Process. 2021, 15, 879–891. [Google Scholar] [CrossRef]
- Roy, D.; Li, Y.; Jian, T.; Tian, P.; Chowdhury, K.; Ioannidis, S. Multi-Modality Sensing and Data Fusion for Multi-Vehicle Detection. IEEE Trans. Multimed. 2023, 25, 2280–2295. [Google Scholar] [CrossRef]
- Vakil, A.; Liu, J.; Zulch, P.; Blasch, E.; Ewing, R.; Li, J. A Survey of Multimodal Sensor Fusion for Passive RF and EO information Integration. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 44–61. [Google Scholar] [CrossRef]
- Vakil, A.; Blasch, E.; Ewing, R.; Li, J. Finding Explanations in AI Fusion of Electro-Optical/Passive Radio-Frequency Data. Sensors 2023, 23, 1489. [Google Scholar] [CrossRef]
- Liu, J.; Ewing, R.; Blasch, E.; Li, J. Synthesis of Passive Human Radio Frequency Signatures via Generative Adversarial Network. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 6–13 March 2021. [Google Scholar]
- Liu, J.; Mu, H.; Vakil, A.; Ewing, R.; Shen, X.; Blasch, E.; Li, J. Human Occupancy Detection via Passive Cognitive Radio. Sensors 2020, 20, 4248. [Google Scholar] [CrossRef]
- Meng, Z.; Xia, X.; Xu, R.; Liu, W.; Ma, J. HYDRO-3D: Hybrid Object Detection and Tracking for Cooperative Perception Using 3D LiDAR. IEEE Trans. Intell. Veh. 2023, 1–13. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Liu, S.; Gao, M.; John, V.; Liu, Z.; Blasch, E. Deep Learning Thermal Image Translation for Night Vision Perception. ACM Trans. Intell. Syst. Technol. 2020, 12, 1–18. [Google Scholar] [CrossRef]
- Liu, S.; Liu, H.; John, V.; Liu, Z.; Blasch, E. Enhanced Situation Awareness through CNN-based Deep MultiModal Image Fusion. Opt. Eng. 2020, 59, 053103. [Google Scholar] [CrossRef]
- Zheng, Y.; Blasch, E.; Liu, Z. Multispectral Image Fusion and Colorization; SPIE Press: Bellingham, WA, USA, 2018. [Google Scholar]
- Kaur, H.; Koundal, D.; Kadyan, V. Image fusion techniques: A survey. Arch. Comput. Methods Eng. 2021, 28, 4425–4447. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, J.; Zhou, Z.; An, Z.; Jiang, Q.; Demonceaux, C.; Sun, G.; Timofte, R. Object Segmentation by Mining Cross-Modal Semantics. arXiv 2023, arXiv:2305.10469. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Bao, Y.; Li, Y.; Huang, S.L.; Zhang, L.; Zheng, L.; Zamir, A.; Guibas, L. An information-theoretic approach to transferability in task transfer learning. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2309–2313. [Google Scholar]
- Xiong, Z.; Wang, C.; Li, Y.; Luo, Y.; Cao, Y. Swin-pose: Swin transformer based human pose estimation. In Proceedings of the 2022 IEEE 5th International Conference on Multimedia Information Processing and Retrieval (MIPR), Virtual, 2–4 August 2022; pp. 228–233. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXII. pp. 1–21. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. Crowdhuman: A benchmark for detecting human in a crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. Mot20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average Precision (AP) @[IoU = 0.50:0.95 | area = all | maxDets = 100] = 0.794 |
| Average Precision (AP) @[IoU = 0.50 | area = all | maxDets = 100] = 0.980 |
| Average Precision (AP) @[IoU = 0.75 | area = all | maxDets = 100] = 0.905 |
| Average Precision (AP) @[IoU = 0.50:0.95 | area = small | maxDets = 100] = −1.000 |
| Average Precision (AP) @[IoU = 0.50:0.95 | area = medium | maxDets = 100] = −1.000 |
| Average Precision (AP) @[IoU = 0.50:0.95 | area = large | maxDets = 100] = 0.794 |
| Average Recall (AR) @[IoU = 0.50:0.95 | area = all | maxDets = 1] = 0.422 |
| Average Recall (AR) @[IoU = 0.50:0.95 | area = all | maxDets = 10] = 0.812 |
| Average Recall (AR) @[IoU = 0.50:0.95 | area = all | maxDets = 100] = 0.812 |
| Average Recall (AR) @[IoU = 0.50:0.95 | area = small | maxDets = 100] = −1.000 |
| Average Recall (AR) @[IoU = 0.50:0.95 | area = medium | maxDets = 100] = −1.000 |
| Average Recall (AR) @[IoU = 0.50:0.95 | area = large | maxDets = 100] = 0.812 |
| Recall | Precision | MOTA | |
|---|---|---|---|
| Evaluation Result | 0.992 | 0.992 | 0.984 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, P.; Xiong, Z.; Bao, Y.; Zhuang, P.; Zhang, Y.; Blasch, E.; Chen, G. A Deep Learning-Enhanced Multi-Modal Sensing Platform for Robust Human Object Detection and Tracking in Challenging Environments. Electronics 2023, 12, 3423. https://doi.org/10.3390/electronics12163423
Cheng P, Xiong Z, Bao Y, Zhuang P, Zhang Y, Blasch E, Chen G. A Deep Learning-Enhanced Multi-Modal Sensing Platform for Robust Human Object Detection and Tracking in Challenging Environments. Electronics. 2023; 12(16):3423. https://doi.org/10.3390/electronics12163423
Chicago/Turabian StyleCheng, Peng, Zinan Xiong, Yajie Bao, Ping Zhuang, Yunqi Zhang, Erik Blasch, and Genshe Chen. 2023. "A Deep Learning-Enhanced Multi-Modal Sensing Platform for Robust Human Object Detection and Tracking in Challenging Environments" Electronics 12, no. 16: 3423. https://doi.org/10.3390/electronics12163423