
A Fast Gradient Iterative Affine Motion Estimation Algorithm Based on Edge Detection for Versatile Video Coding

Abstract
:1. Introduction

2. Related Work
3. Materials and Methods
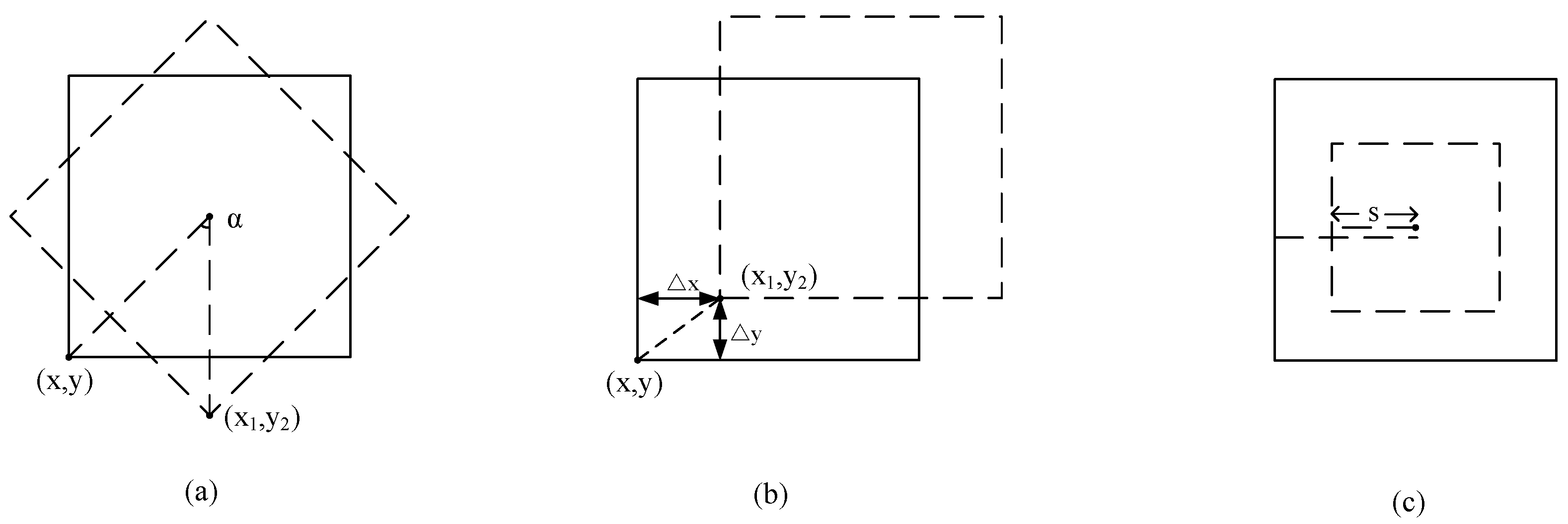
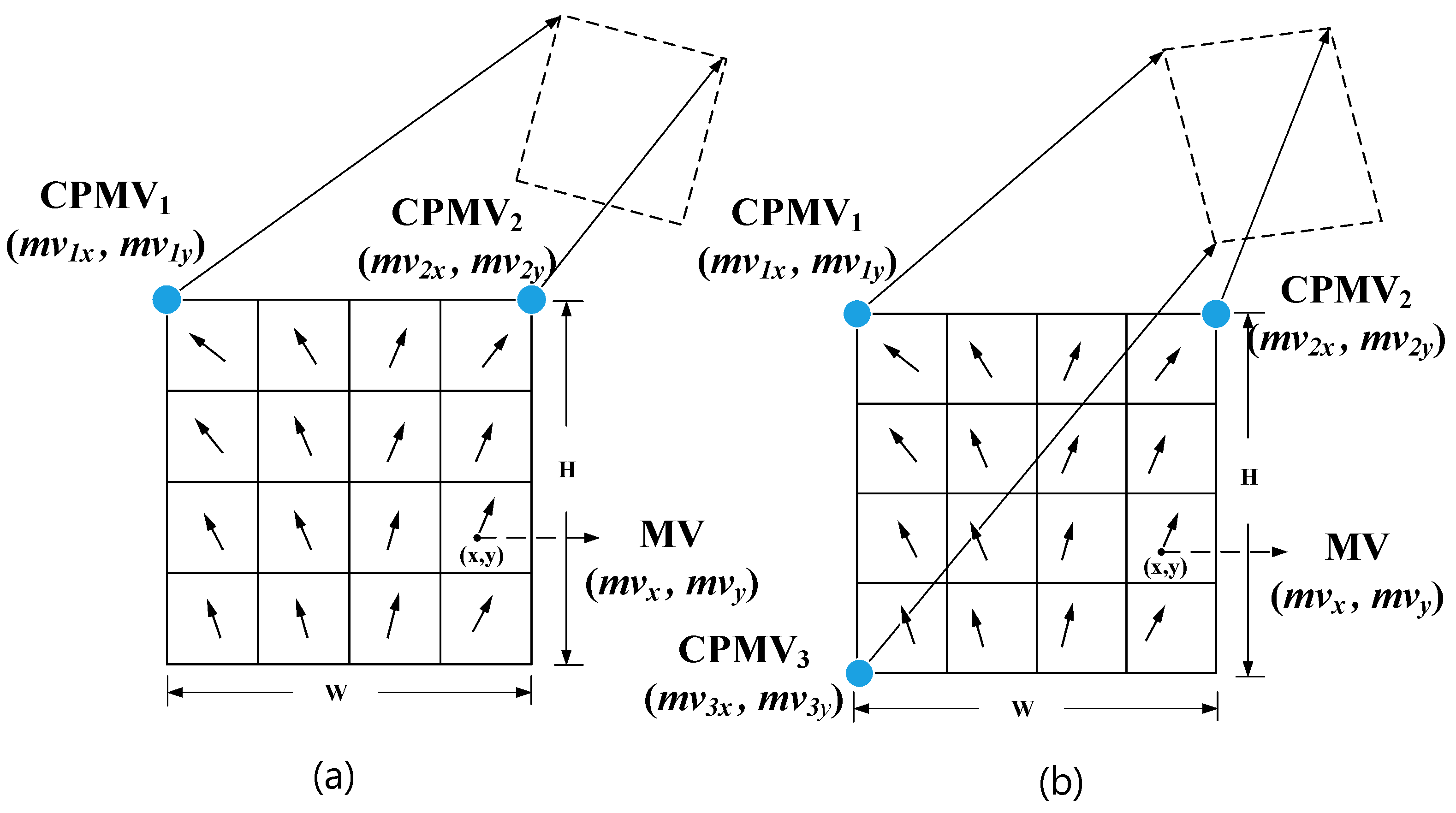
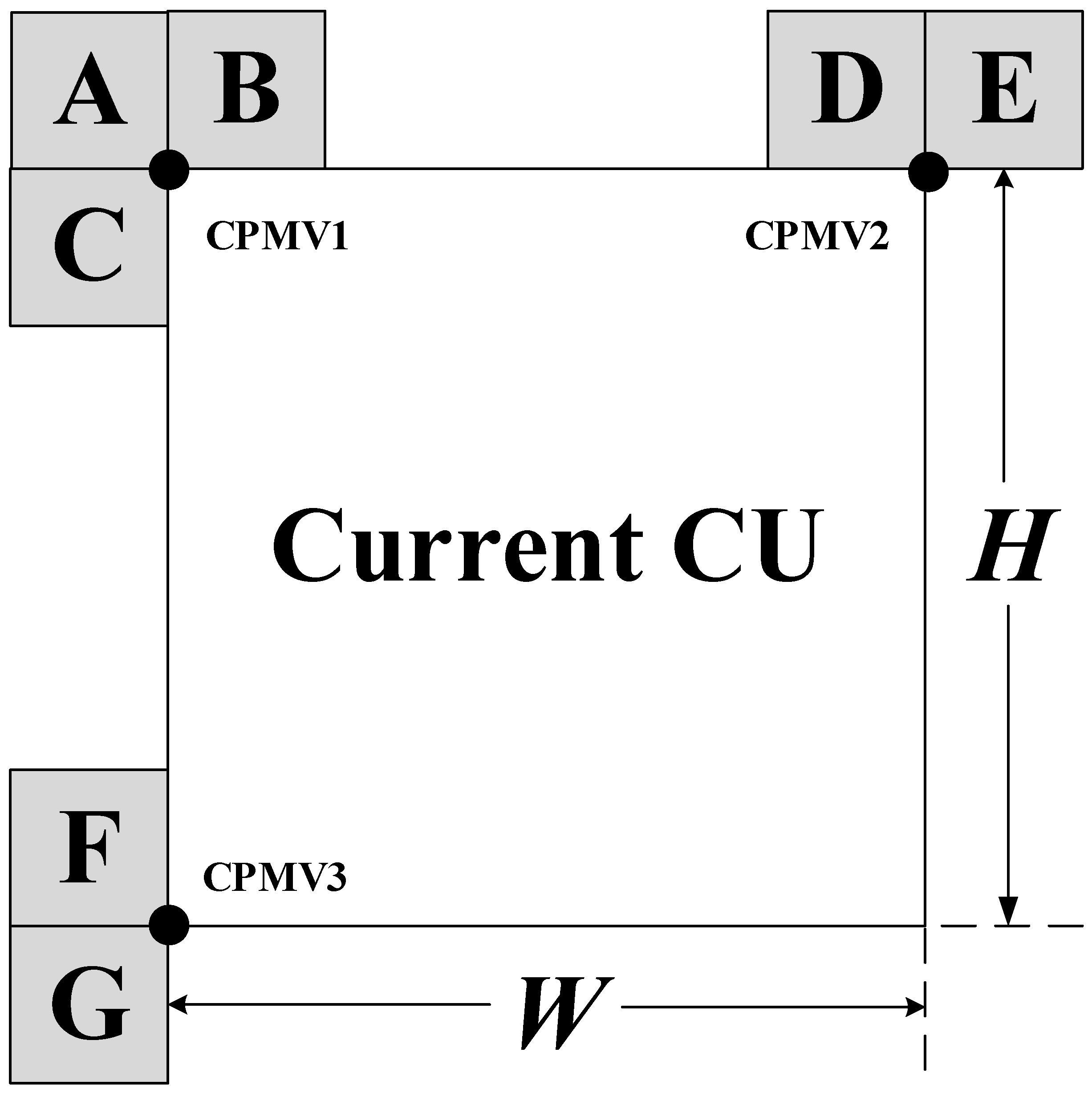
3.1. Affine Advanced Motion Vector Prediction
3.2. The Iterative Search of Affine Motion Vectors
- Obtain the original data of the image, initialize the variable, cache, and mark the image with calculated edges.
- By traversing each pixel of the image, calculate the gradient and error at each pixel position. If isCannyComputed is false, it indicates that the Canny edge image needs to be recalculated for the first time; otherwise, skip.
- Traverse the image and repeat the calculation.
| Algorithm 1: xAffineMotionEstimation. |
 |
4. Experiments and Results Analysis
4.1. Simulation Setup
4.2. Performance and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bross, B.; Chen, J.; Liu, S. Versatile Video Coding (Draft 1). In Proceedings of the 10th JVET Meeting, San Diego, CA, USA, 10–20 April 2018. [Google Scholar]
- Bross, B.; Chen, J.; Ohm, J.R.; Sullivan, G.J.; Wang, Y.K. Developments in international video coding standardization after avc, with an overview of versatile video coding (vvc). Proc. IEEE 2021, 109, 1463–1493. [Google Scholar] [CrossRef]
- Hamidouche, W.; Biatek, T.; Abdoli, M.; François, E.; Pescador, F.; Radosavljević, M.; Menard, D.; Raulet, M. Versatile video coding standard: A review from coding tools to consumers deployment. IEEE Consum. Electron. Mag. 2022, 11, 10–24. [Google Scholar] [CrossRef]
- Sidaty, N.; Hamidouche, W.; Déforges, O.; Philippe, P.; Fournier, J. Compression performance of the versatile video coding: HD and UHD visual quality monitoring. In Proceedings of the 2019 Picture Coding Symposium (PCS), Ningbo, China, 12–15 November 2019; pp. 1–5. [Google Scholar]
- Li, X.; Chuang, H.; Chen, J.; Karczewicz, M.; Zhang, L.; Zhao, X.; Said, A. Multi-type-tree, document JVET-D0117. In Proceedings of the 4th JVET Meeting, Chengdu, China, 17–21 October 2016. [Google Scholar]
- Schwarz, H.; Nguyen, T.; Marpe, D.; Wiegand, T. Hybrid video coding with trellis-coded quantization. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; pp. 182–191. [Google Scholar]
- Zhao, X.; Chen, J.; Karczewicz, M.; Said, A.; Seregin, V. Joint separable and non-separable transforms for next-generation video coding. IEEE Trans. Image Process. 2018, 27, 2514–2525. [Google Scholar] [CrossRef] [PubMed]
- Sethuraman, S. CE9: Results of dmvr related tests CE9. 2.1 and CE9. 2.2. Jt. Video Expert. Team (JVET) ITU-T SG 2019, 16, 9–18. [Google Scholar]
- Xiu, X.; He, Y.; Ye, Y.; Luo, J. Complexity Reduction and Bit-Width Control for Bi-Directional Optical Flow. U.S. Patent 11,470,308, 11 October 2022. [Google Scholar]
- Kato, Y.; Toma, T.; Abe, K. Simplification of BDOF, document JVET-O0304. In Proceedings of the 15th JVET Meeting, Gothenburg, Sweden, 1–9 October 2019; pp. 3–12. [Google Scholar]
- Lin, S.; Chen, H.; Zhang, H.; Maxim, S.; Yang, H.; Zhou, J. Affine transform prediction for next generation video coding, document COM16-C1016. In Proceedings of the Huawei Technologies, International Organisation for Standardisation Organisation Internationale De Normalisation ISO/IEC JTC1/SC29/WG11 Coding of Moving Pictures and Audio, ISO/IEC JTC1/SC29/WG11 MPEG2015/m37525, Geneva, Switzerland, 1 January 2017. [Google Scholar]
- Chen, J.; Karczewicz, M.; Huang, Y.W.; Choi, K.; Ohm, J.R.; Sullivan, G.J. The joint exploration model (JEM) for video compression with capability beyond HEVC. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1208–1225. [Google Scholar] [CrossRef]
- Zhao, X.; Seregin, V.; Said, A.; Zhang, K.; Egilmez, H.E.; Karczewicz, M. Low-complexity intra prediction refinements for video coding. In Proceedings of the 2018 Picture Coding Symposium (PCS), San Francisco, CA, USA, 24–27 June 2018; pp. 139–143. [Google Scholar]
- Zhang, X.; Ma, S.; Wang, S.; Zhang, X.; Sun, H.; Gao, W. A joint compression scheme of video feature descriptors and visual content. IEEE Trans. Image Process. 2016, 26, 633–647. [Google Scholar] [CrossRef]
- Tang, N.; Cao, J.; Liang, F.; Wang, J.; Liu, H.; Wang, X.; Du, X. Fast CTU partition decision algorithm for VVC intra and inter coding. In Proceedings of the 2019 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Bangkok, Thailand, 11–14 November 2019; pp. 361–364. [Google Scholar]
- Zhang, Q.; Zhao, Y.; Jiang, B.; Huang, L.; Wei, T. Fast CU partition decision method based on texture characteristics for H. 266/VVC. IEEE Access 2020, 8, 203516–203524. [Google Scholar] [CrossRef]
- Li, X.; He, J.; Li, Q.; Chen, X. An Adjacency Encoding Information-Based Fast Affine Motion Estimation Method for Versatile Video Coding. Electronics 2022, 11, 3429. [Google Scholar] [CrossRef]
- Guan, X.; Sun, X. VVC fast ME algorithm based on spatial texture features and time correlation. In Proceedings of the 2021 International Conference on Digital Society and Intelligent Systems (DSInS), Chengdu, China, 3–4 December 2021; pp. 371–377. [Google Scholar]
- Zhao, J.; Wu, A.; Zhang, Q. SVM-based fast CU partition decision algorithm for VVC intra coding. Electronics 2022, 11, 2147. [Google Scholar] [CrossRef]
- Khan, S.N.; Muhammad, N.; Farwa, S.; Saba, T.; Khattak, S.; Mahmood, Z. Early Cu depth decision and reference picture selection for low complexity Mv-Hevc. Symmetry 2019, 11, 454. [Google Scholar] [CrossRef] [Green Version]
- Park, S.H.; Kang, J.W. Fast affine motion estimation for versatile video coding (VVC) encoding. IEEE Access 2019, 7, 158075–158084. [Google Scholar] [CrossRef]
- Zhang, K.; Chen, Y.W.; Zhang, L.; Chien, W.J.; Karczewicz, M. An improved framework of affine motion compensation in video coding. IEEE Trans. Image Process. 2018, 28, 1456–1469. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Li, H.; Liu, D.; Li, Z.; Yang, H.; Lin, S.; Chen, H.; Wu, F. An efficient four-parameter affine motion model for video coding. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1934–1948. [Google Scholar] [CrossRef] [Green Version]
- Kordasiewicz, R.C.; Gallant, M.D.; Shirani, S. Affine motion prediction based on translational motion vectors. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1388–1394. [Google Scholar] [CrossRef]
- Fortun, D.; Storath, M.; Rickert, D.; Weinmann, A.; Unser, M. Fast piecewise-affine motion estimation without segmentation. IEEE Trans. Image Process. 2018, 27, 5612–5624. [Google Scholar] [CrossRef] [Green Version]
- Meuel, H.; Ostermann, J. Analysis of affine motion-compensated prediction in video coding. IEEE Trans. Image Process. 2020, 29, 7359–7374. [Google Scholar] [CrossRef]
- Guan, B.; Zhao, J.; Li, Z.; Sun, F.; Fraundorfer, F. Relative pose estimation with a single affine correspondence. IEEE Trans. Cybern. 2021, 52, 10111–10122. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, S.; Zhang, X.; Wang, S.; Ma, S. Three-zone segmentation-based motion compensation for video compression. IEEE Trans. Image Process. 2019, 28, 5091–5104. [Google Scholar] [CrossRef]
- Zhu, C.; Xu, J.; Feng, D.; Xie, R.; Song, L. Edge-based video compression texture synthesis using generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7061–7076. [Google Scholar] [CrossRef]
- Huang, J.C.; Hsieh, W.S. Automatic feature-based global motion estimation in video sequences. IEEE Trans. Consum. Electron. 2004, 50, 911–915. [Google Scholar] [CrossRef]
- Pfaff, J.; Schwarz, H.; Marpe, D.; Bross, B.; De-Luxán-Hernández, S.; Helle, P.; Helmrich, C.R.; Hinz, T.; Lim, W.Q.; Ma, J.; et al. Video compression using generalized binary partitioning, trellis coded quantization, perceptually optimized encoding, and advanced prediction and transform coding. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1281–1295. [Google Scholar] [CrossRef]
- Jung, S.; Jun, D. Context-based inter mode decision method for fast affine prediction in versatile video coding. Electronics 2021, 10, 1243. [Google Scholar] [CrossRef]
- Ren, W.; He, W.; Cui, Y. An improved fast affine motion estimation based on edge detection algorithm for VVC. Symmetry 2020, 12, 1143. [Google Scholar] [CrossRef]
- Bossen, F.; Boyce, J.; Li, X.; Seregin, V.; Sühring, K. JVET common test conditions and software reference configurations for SDR video. In Proceedings of the Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11 10th Meeting, San Diego, CA, USA, 10–20 April 2018; Volume 16, pp. 19–27. [Google Scholar]
- Gisle, B. Improvements of the BD-PSNR model. In Proceedings of the ITUT SG16/Q6, 34th VCEG Meeting, Berlin, Germany, 16–18 July 2008. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Descriptions |
|---|---|
| Software | VTM-10.0 |
| Configuration file | encoder_lowdelay_P_vtm.cfg |
| Number of frames to be coded | 30 |
| Quantization parameter | 22, 27, 32, 37 |
| Search range | 64 |
| CU size/depth | 64/4 |
| Sampling of luminance to chrominance | 4:2:0 |
| Sequences | Size | Bit-Depth | Frame Rate |
|---|---|---|---|
| BasketballDrive | 1920 × 1080 | 8 | 50 |
| Cactus | 1920 × 1080 | 10 | 50 |
| FourPeople | 1280 × 720 | 8 | 60 |
| KristenAndSara | 1280 × 720 | 8 | 60 |
| BasketballDrill | 832 × 480 | 8 | 50 |
| PartyScene | 832 × 480 | 8 | 50 |
| RaceHorses | 416 × 240 | 8 | 30 |
| BQSquare | 416 × 240 | 8 | 60 |
| BasketballPass | 416 × 240 | 8 | 50 |
| Sequences | BDBR/% | BD-PSNR/dB | EncTall/% | EncTaff/% |
|---|---|---|---|---|
| BasketballPass | 0.34 | −0.063 | 11.12 | 31.80 |
| BQSquare | 0.84 | −0.115 | 9.05 | 32.11 |
| RaceHorses | 0.83 | −0.037 | 8.23 | 23.59 |
| PartyScene | 0.93 | −0.040 | 6.92 | 18.96 |
| BasketballDrill | 0.50 | −0.019 | 3.27 | 15.39 |
| KristenAndSara | 1.06 | −0.028 | 4.81 | 32.98 |
| FourPeople | 0.39 | −0.018 | 4.33 | 27.13 |
| Cactus | 0.51 | −0.012 | 4.36 | 20.47 |
| BasketballDrive | 1.50 | −0.030 | 3.89 | 20.66 |
| Average | 0.76 | −0.040 | 6.22 | 24.79 |
| Sequence Name | Ren et al. [33] | Proposed | ||
|---|---|---|---|---|
| BDBR/% | SavTall/% | BDBR/% | SavTall/% | |
| BasketballDrive | 0.08 | 5.00 | 1.50 | 3.89 |
| Cactus | 0.11 | 6.00 | 0.51 | 4.36 |
| BasketballDrill | 0.06 | 3.00 | 0.50 | 3.27 |
| PartyScene | 0.26 | 4.00 | 0.93 | 6.92 |
| RaceHorses | 0.08 | 5.00 | 0.83 | 8.23 |
| BasketballPass | 0.08 | 2.00 | 0.34 | 11.12 |
| Average | 0.11 | 4.16 | 0.77 | 6.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, J.; Dong, Z.; Zhang, X.; Song, N.; Cao, P. A Fast Gradient Iterative Affine Motion Estimation Algorithm Based on Edge Detection for Versatile Video Coding. Electronics 2023, 12, 3414. https://doi.org/10.3390/electronics12163414
Hong J, Dong Z, Zhang X, Song N, Cao P. A Fast Gradient Iterative Affine Motion Estimation Algorithm Based on Edge Detection for Versatile Video Coding. Electronics. 2023; 12(16):3414. https://doi.org/10.3390/electronics12163414
Chicago/Turabian StyleHong, Jingping, Zhihong Dong, Xue Zhang, Nannan Song, and Peng Cao. 2023. "A Fast Gradient Iterative Affine Motion Estimation Algorithm Based on Edge Detection for Versatile Video Coding" Electronics 12, no. 16: 3414. https://doi.org/10.3390/electronics12163414