
A Sales Forecasting Model for New-Released and Short-Term Product: A Case Study of Mobile Phones


Abstract
:1. Introduction
2. Methodology
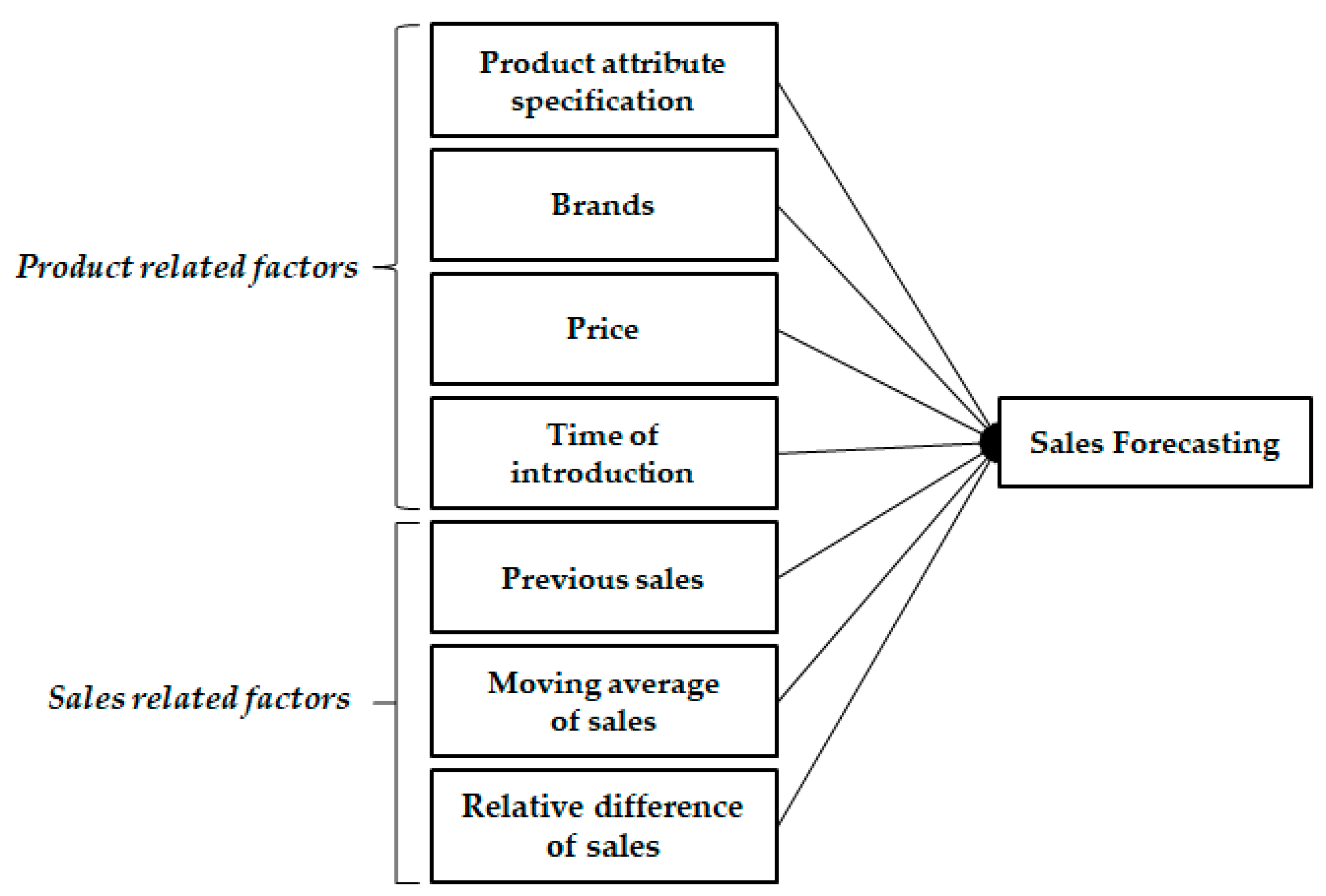
2.1. Sales Forecasting Related Factors
2.1.1. Product Related Factors
- Product attribute specification: Product attribute specifications play a crucial role in shaping consumers’ perception of a product’s relevance to their personal needs. Understanding consumer preferences across different lifestyles is essential since individuals prioritize their functional and hedonic needs to varying extents [39]. For instance, when purchasing a tablet computer, customers consider factors such as the operating system, battery life, screen size, and RAM level. Therefore, it is reasonable to take into account attribute levels when forecasting sales [40]. In this study, we consider 14 attributes, including the operating system, display size (mm), display resolution (ppi), CPU processor speed (GHz), number of processor cores, rear camera pixels (MP), front camera pixels (MP), storage (GB), width (mm), length (mm), depth (mm), weight (g), battery capacity (mAh), and RAM (GB).
- Brands: Brand image plays a vital role in building brand equity, which encompasses consumers’ overall perception and emotional response towards a brand, influencing their behaviors. Marketers aim to shape consumers’ perceptions and attitudes towards a brand through marketing activities. The goal is to establish a strong brand image in consumers’ minds, stimulate their purchasing behavior, boost sales, maximize market share, and develop brand equity [41].
- Price: Price plays a significant role in consumer purchasing decisions and is equally important for providers [42]. Lower pricing can impact sales volume, as some providers strategically price certain products low to attract the attention of consumers with the intention of selling them other, higher-priced items. However, consumers may question the quality of a product if the price is excessively low. Many consumers prioritize value over the lowest price and are willing to pay a price that reflects the worth of a product. Setting prices too low can create a perception among consumers that a product is less satisfactory compared to similar products on the market [43].
- Time of Introduction: Products like mobile phones have short release cycles, making it crucial to consider this factor when forecasting sales. Continuous releases of new mobile phone models in the market create competition, trends, and consumer demand [4]. Technology products, including mobile phones, often experience high sales immediately after their release, followed by a rapid decline in the sales curve. Therefore, the time elapsed since the product release is a significant factor in understanding the sales pattern [44,45]. The value assigned to the months after release starts with 1 for the month of release and incrementally increases by 1 for each subsequent month.
2.1.2. Sales Related Factors
- Previous sales: In the manufacturing industry, the previous month’s sales have been identified as a particularly influential parameter in sales forecasting [6]. This suggests that the sales performance in the immediately preceding month plays a significant role in predicting future sales. Furthermore, research conducted in this domain has consistently shown that not only the previous month’s sales but also the sales figures from the two to three months prior can impact the sales outcomes in the predicted months [7,8].
- Moving average of sales: Capturing the trend of sales is recognized as a crucial variable in related studies. One commonly employed method to represent this trend is the use of moving averages. It is a prevalent research practice to calculate the moving average of sales over a period of two to three months [6,7]. By calculating the average sales over this time window, the moving average provides a smoothed representation of the sales trend, allowing for a better understanding and prediction of sales patterns.
- Relative difference of sales: The majority of time series data commonly demonstrate discernible vibration patterns that can either exhibit a decreasing or increasing trend. These patterns are quantified as relative difference variables, which represent the growth rates of sales over time. Such variables hold significant importance as primary factors within sales forecasting models [46,47].
2.2. Machine Learning Methods
2.2.1. Ridge, Lasso Regression
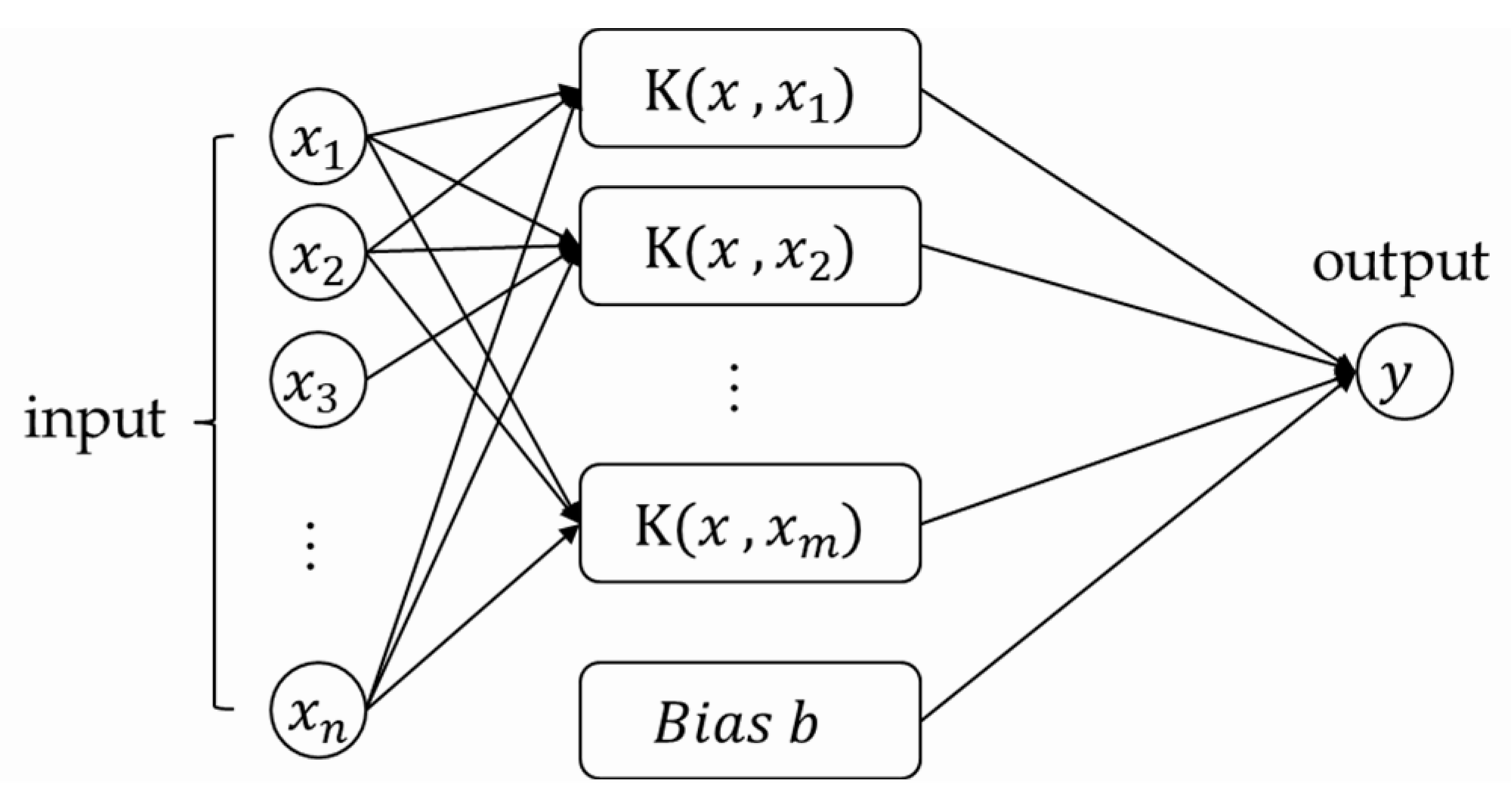
2.2.2. Support Vector Regression
2.2.3. Random Forest Regression
2.2.4. Gradient Boosting Regression
2.2.5. AdaBoost Regression
2.2.6. XGBoost Regression
2.2.7. Lightgbm Regression
2.2.8. CatBoost Regression
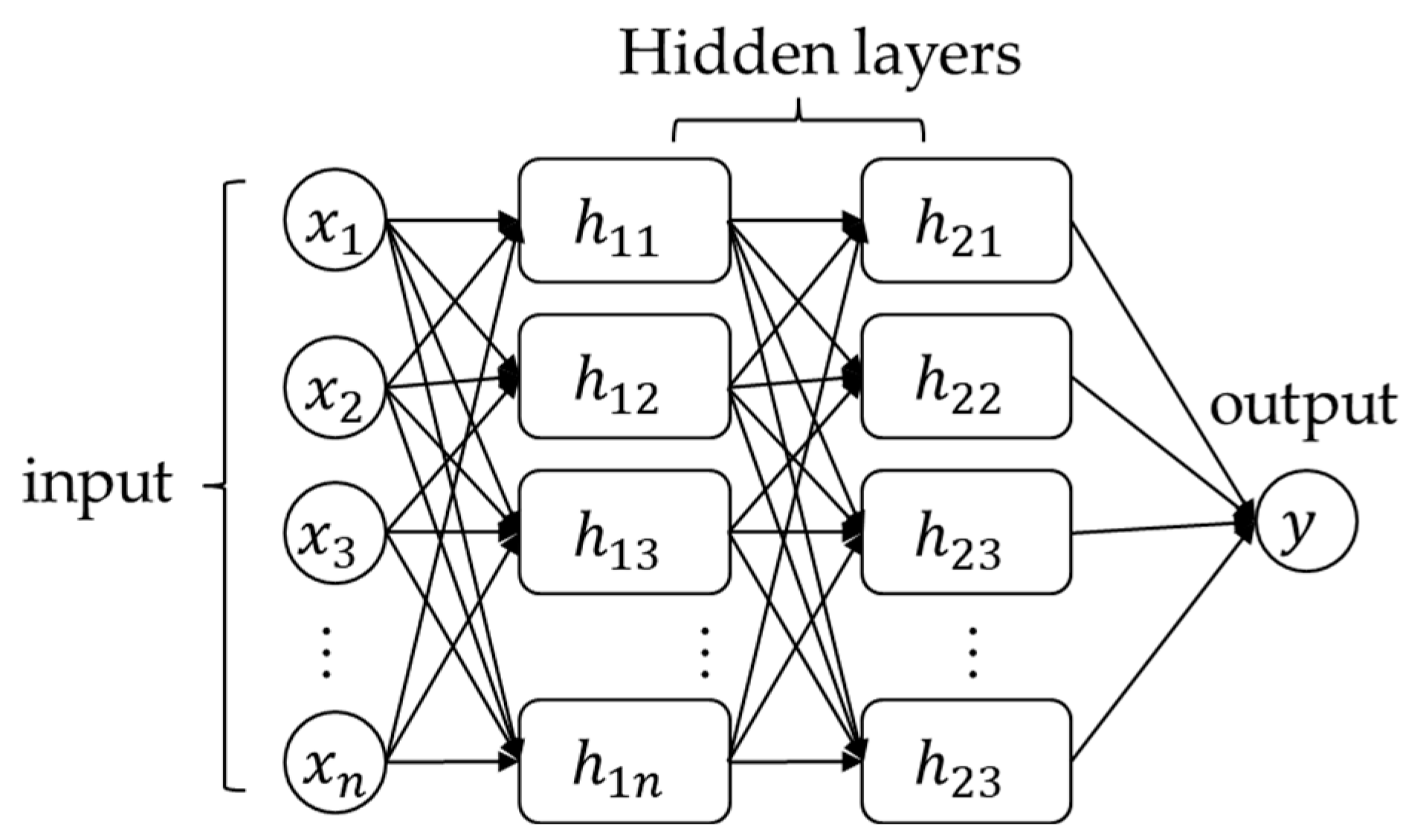
2.2.9. Deep Neural Network
2.2.10. Recurrent Neural Network
2.2.11. Long Short-Term Memory
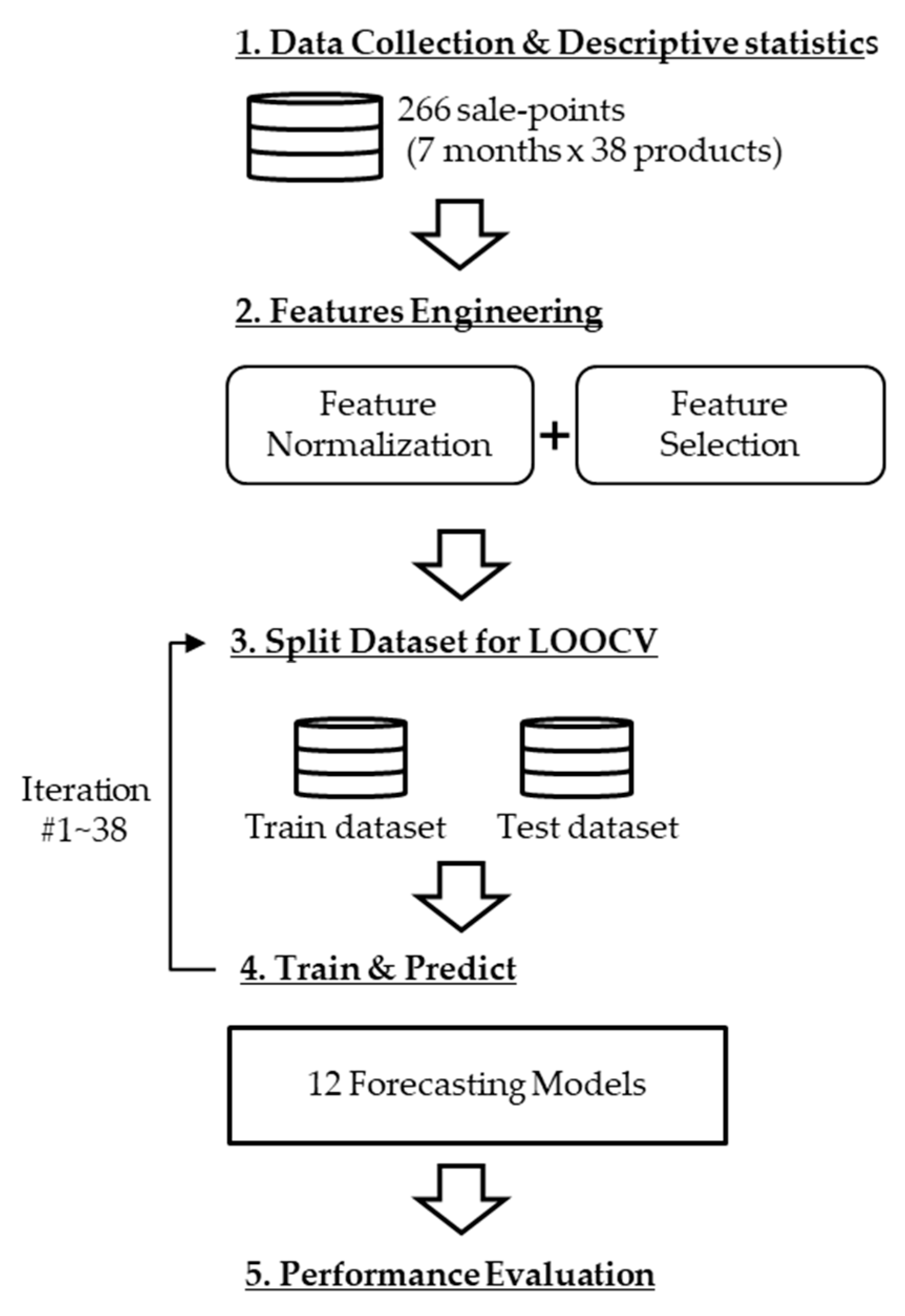
3. Experiments and Results
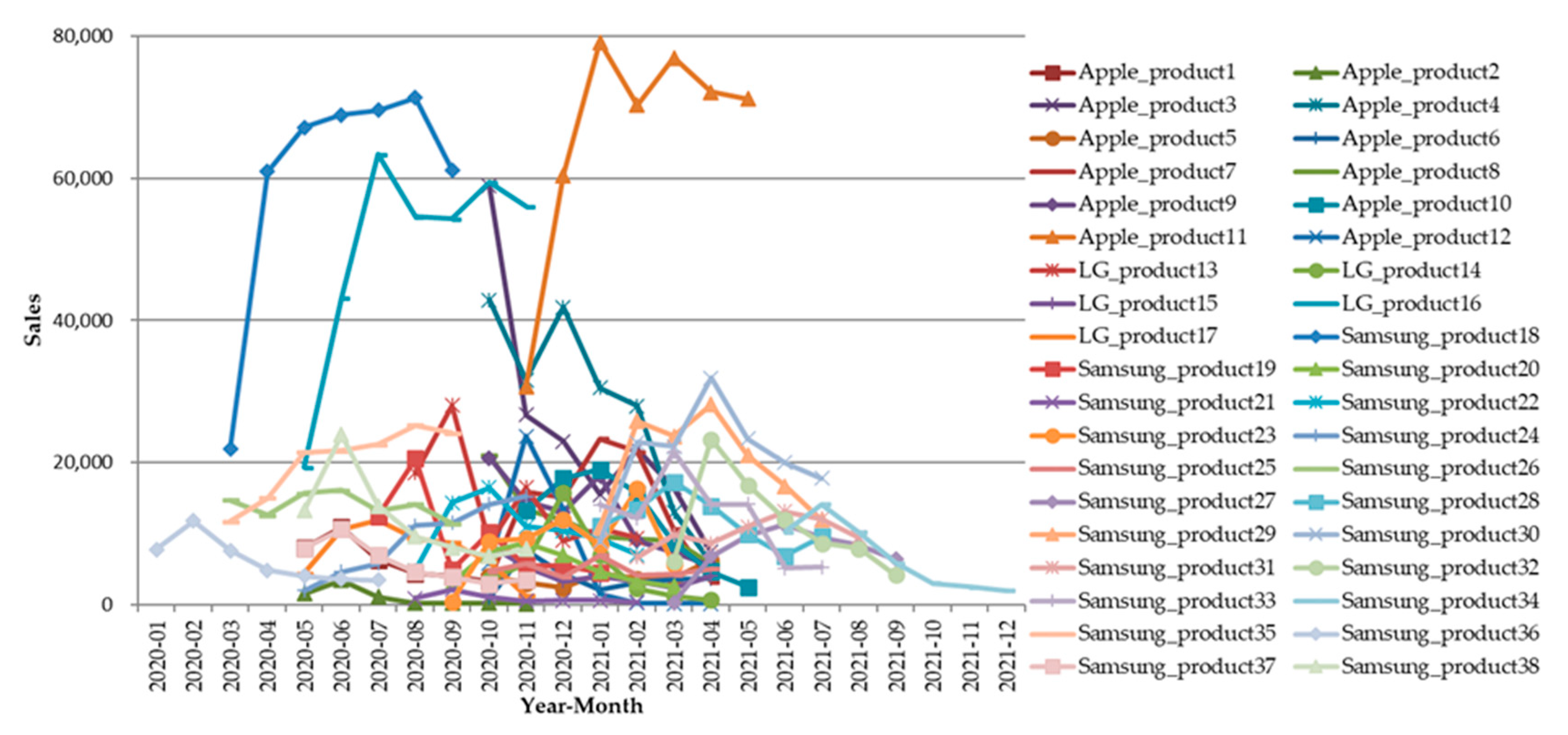
3.1. Data Collection and Descriptive Statistics
3.2. Feature Engineering
3.2.1. Feature Normalization
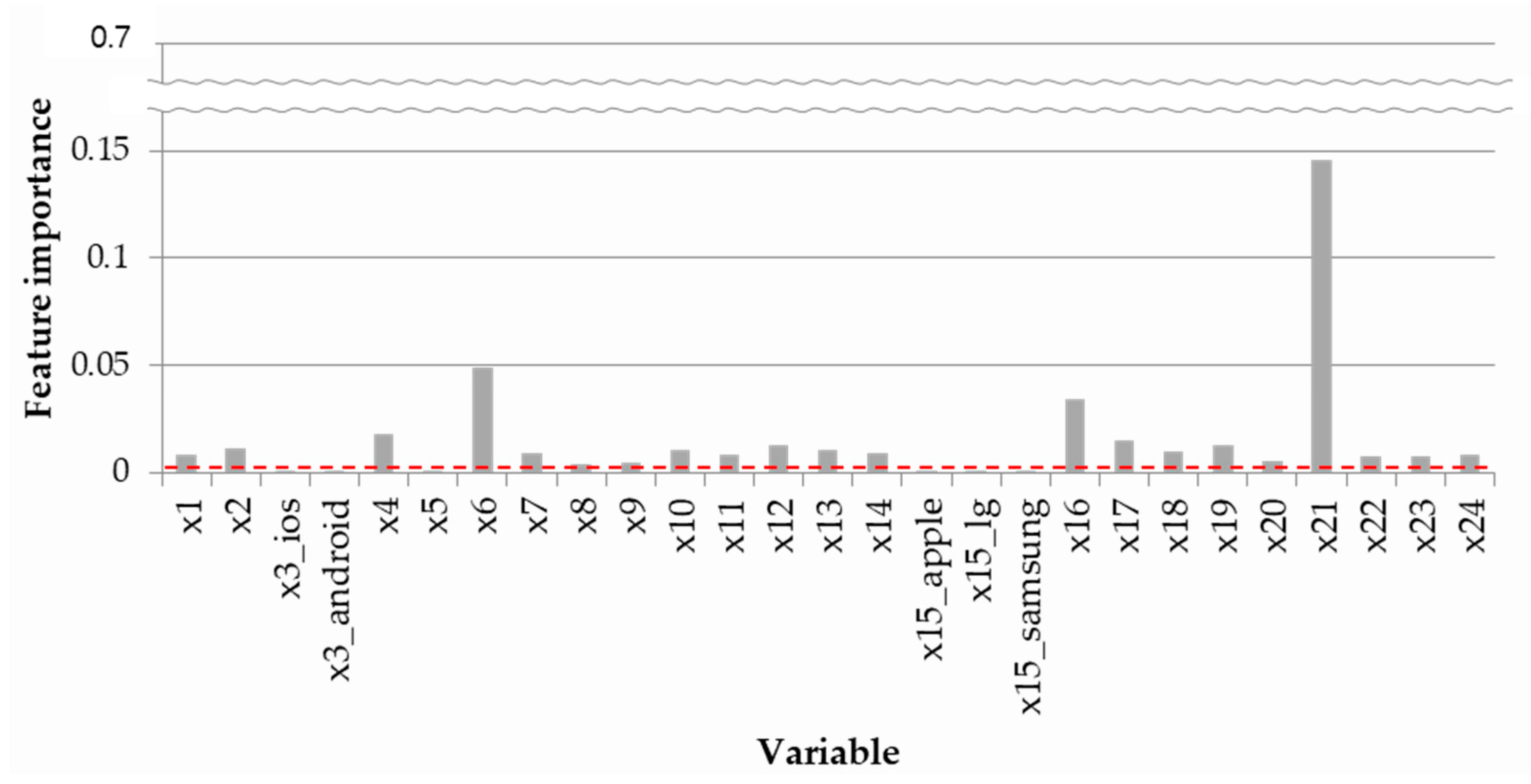
3.2.2. Feature Selection
3.3. Demand Forecasting Models
- (1).
- Ridge regression;
- (2).
- Lasso regression;
- (3).
- Support vector regression with non-linear kernel;
- (4).
- Random forest regression;
- (5).
- Gradient boosting regression;
- (6).
- AdaBoost regression;
- (7).
- Lightgbm regression;
- (8).
- XGBoost regression;
- (9).
- CatBoost regression;
- (10).
- DNN with two hidden layers, Relu activation function and rmsprop optimizer;
- (11).
- RNN with two hidden layers, Relu activation function and rmsprop optimizer;
- (12).
- LSTM with two hidden layers, Relu activation function and rmsprop optimizer.
3.4. Performance Comparison of Models
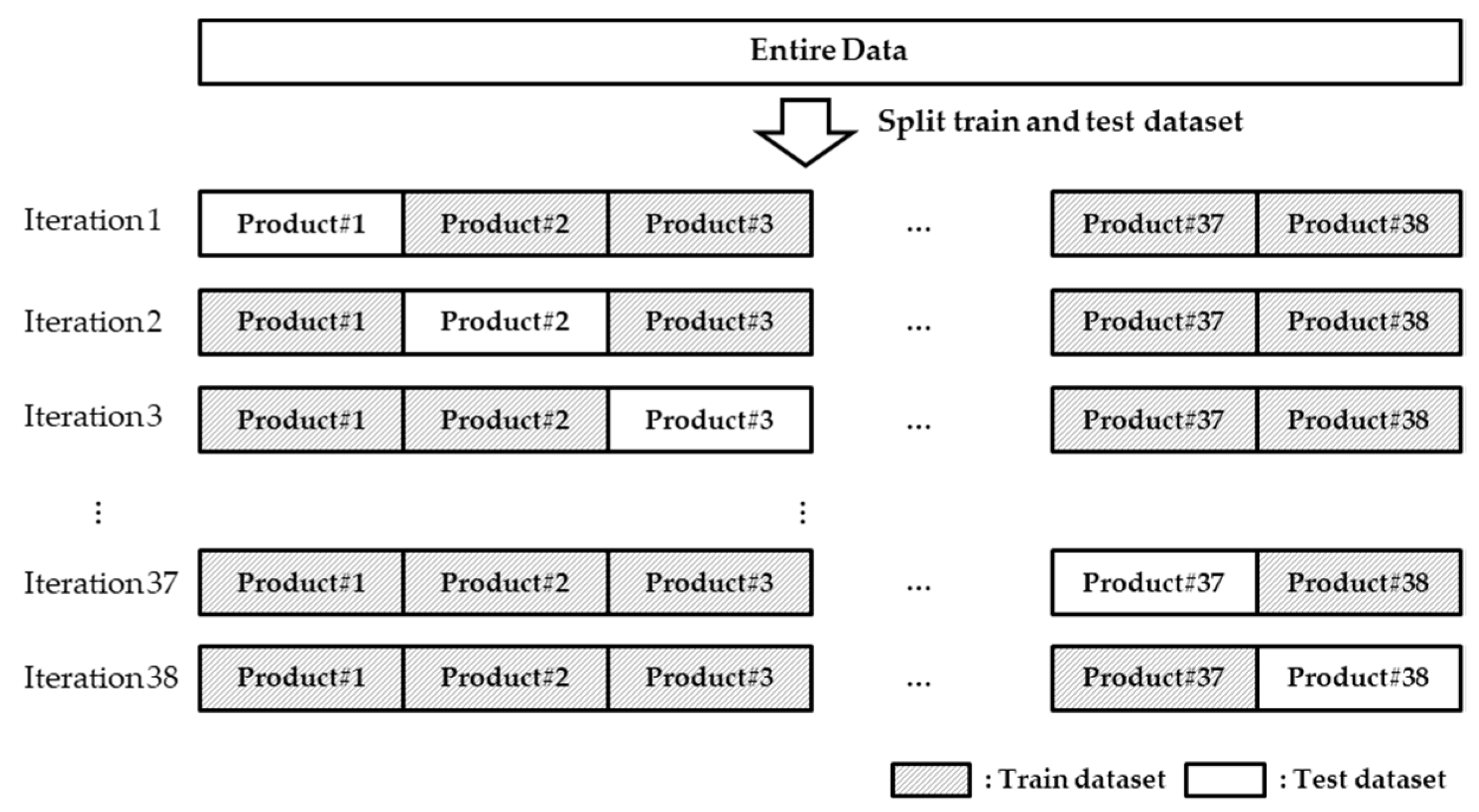
3.4.1. Leave-One-Out Cross Validation
3.4.2. Evaluation Metric
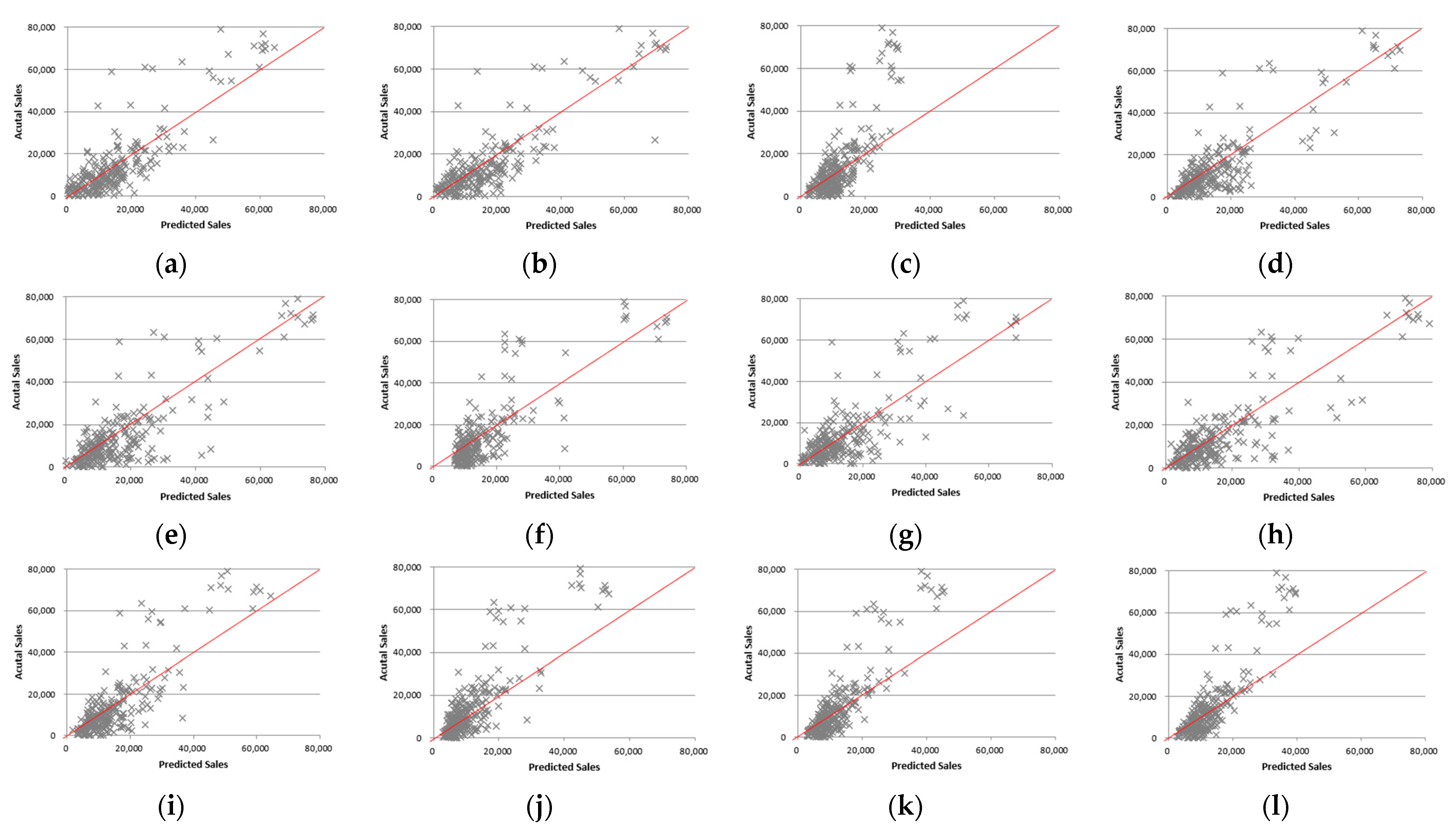
3.5. Predictive Performance
3.6. Comparison of Models
4. Conclusions
- For the mobile phone sales forecasting case, the previous 1–2 month’s moving average of sales for sales-related variables, and rear camera pixels, release price, and CPU processor speed for product-related variables were identified as variables that significantly affect sales.
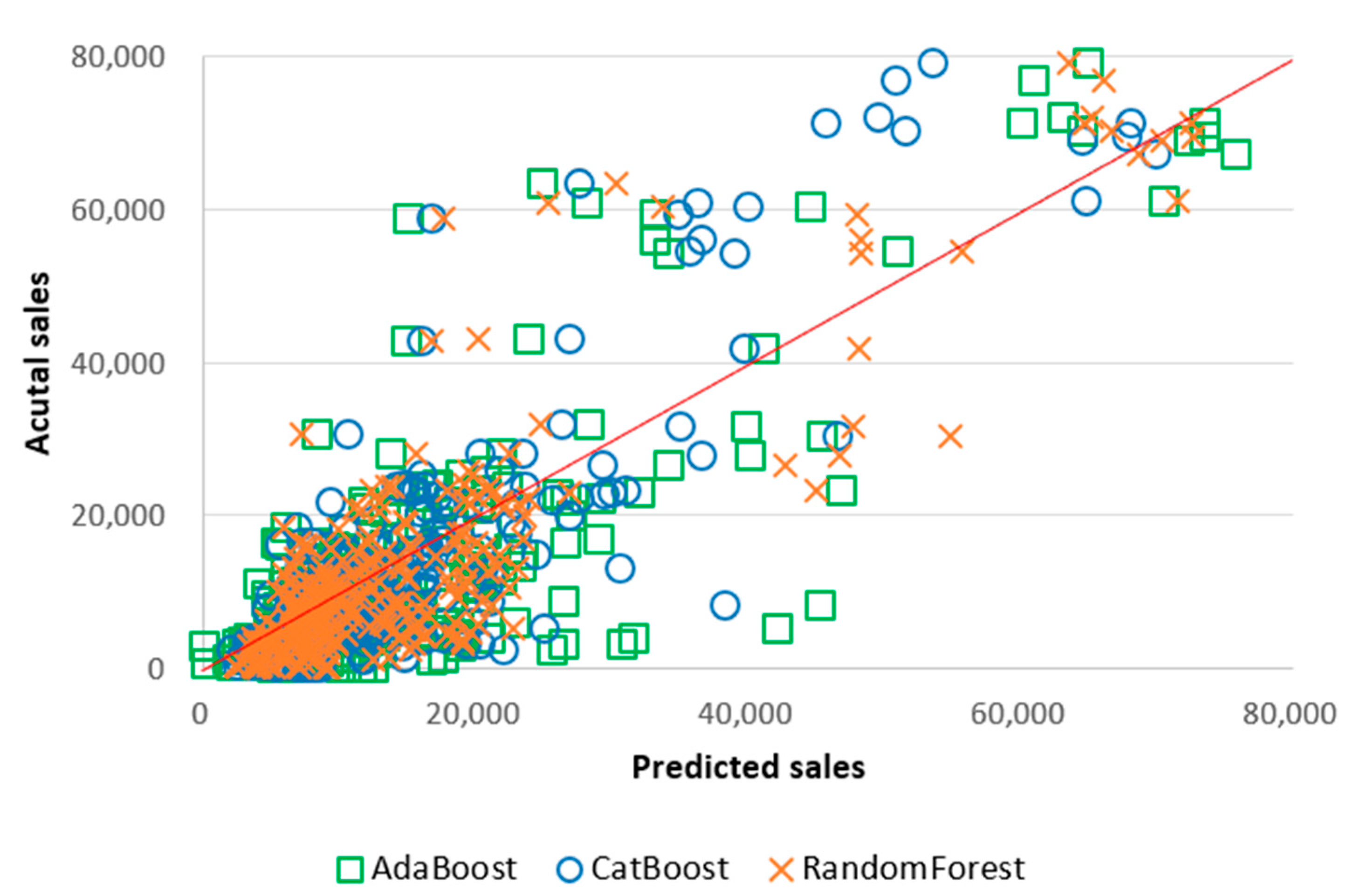
- The Random Forest model outperformed other models in sales forecasting, with the lowest-performing model, LSTM, exhibiting a significantly higher relative error percentage of 665% for MAPE and 86% for RMSE compared to Random Forest.
- The overall ranking order of the models, from best to worst performance, was as follows: Random Forest > CatBoost > AdaBoost > XGBoost > GBM > LightGBM > SVM > Ridge > Lasso > DNN > RNN > LSTM. Tree-based models (Random Forest, GBM, AdaBoost, LightGBM, XGBoost, CatBoost) outperformed neural network (DNN, RNN, LSTM) and linear (Ridge, Lasso) and SVM models.
- Consistent with previous studies [5], deep learning models such as DNN, RNN, and LSTM demonstrated lower performance than machine learning models when working with relatively small datasets.
- The Random Forest model, with the highest prediction performance, exhibited varying accuracy for each brand. The order of high accuracy was Samsung brand products > Apple brand products > LG brand products.
- Significant performance differences observed between the best and worst performance models highlight the need for informed decision making. Employing an unsuitable model can result in significant forecasting errors that accumulate over time, adversely impacting the entire supply chain. Thus, businesses should meticulously evaluate the specific characteristics of their sales data, consider the strengths and weaknesses of each model, and select the most suitable model aligned with their specific requirements and objectives.
- We believe that companies that produce short-term products can optimize the supply chain strategy by applying the Random Forest model or analysis process proposed by our study.
- The variation in predictive performance by brand may be attributed to differences in sales patterns resulting from brand-specific marketing strategies, including promotions and price policies [69,70]. To enhance forecasting accuracy, collecting additional data on promotion timing, price fluctuations, and advertising timing to reflect brand-specific marketing strategies would be beneficial.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fisher, M.; Rajaram, K. Accurate Retail Testing of Fashion Merchandise: Methodology and Application. Mark. Sci. 2000, 19, 266–278. [Google Scholar] [CrossRef]
- Berg, J.M. Balancing on the Creative Highwire. Adm. Sci. Q. 2016, 61, 433–468. [Google Scholar] [CrossRef]
- Lawrence, M.; Goodwin, P.; O’Connor, M.; Önkal, D. Judgmental Forecasting: A Review of Progress over the Last 25 years. Int. J. Forecast. 2006, 22, 493–518. [Google Scholar] [CrossRef] [Green Version]
- Tsang, M.M.; Ho, S.-C.; Liang, T.-P. Consumer Attitudes toward Mobile Advertising: An Empirical Study. Int. J. Electron. Commer. 2004, 8, 65–78. [Google Scholar] [CrossRef]
- Bailly, A.; Blanc, C.; Francis, É.; Guillotin, T.; Jamal, F.; Wakim, B.; Roy, P. Effects of Dataset Size and Interactions on the Prediction Performance of Logistic Regression and Deep Learning Models. Comput. Methods Programs Biomed. 2021, 213, 106504. [Google Scholar] [CrossRef]
- Sharma, R.; Sinha, A.K. Sales Forecast of an Automobile Industry. Int. J. Comput. Appl. 2012, 53, 25–28. [Google Scholar] [CrossRef]
- Lu, C.-J.; Lee, T.-S.; Lian, C.-M. Sales Forecasting for Computer Wholesalers: A Comparison of Multivariate Adaptive Regression Splines and Artificial Neural Networks. Decis. Support Syst. 2012, 54, 584–596. [Google Scholar] [CrossRef]
- Luxhøj, J.T.; Riis, J.O.; Stensballe, B. A Hybrid Econometric—Neural Network Modeling Approach for Sales Forecasting. Int. J. Prod. Econ. 1996, 43, 175–192. [Google Scholar] [CrossRef]
- Brühl, B.; Hülsmann, M.; Borscheid, D.; Friedrich, C.M.; Reith, D. A Sales Forecast Model for the German Automobile Market Based on Time Series Analysis and Data Mining Methods. In Advances in Data Mining, Proceedings of the Advances in Data Mining. Applications and Theoretical Aspects: 9th Industrial Conference, ICDM 2009, Leipzig, Germany, 20–22 July 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 146–160. [Google Scholar] [CrossRef]
- AlMamlook, R.E.; Kwayu, K.M.; Alkasisbeh, M.R.; Frefer, A.A. Comparison of Machine Learning Algorithms for Predicting Traffic Accident Severity. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019. [Google Scholar] [CrossRef]
- Liu, H.; Liu, Y.; Li, G.; Wen, L. Tourism Demand Nowcasting Using a LASSO-MIDAS Model. Int. J. Contemp. Hosp. Manag. 2021, 33, 1922–1949. [Google Scholar] [CrossRef]
- Carbonneau, R.; Laframboise, K.; Vahidov, R. Application of Machine Learning Techniques for Supply Chain Demand Forecasting. Eur. J. Oper. Res. 2008, 184, 1140–1154. [Google Scholar] [CrossRef]
- Güven, İ.; Şimşir, F. Demand Forecasting with Color Parameter in Retail Apparel Industry Using Artificial Neural Networks (ANN) and Support Vector Machines (SVM) Methods. Comput. Ind. Eng. 2020, 147, 106678. [Google Scholar] [CrossRef]
- Hong, W.-C.; Dong, Y.; Chen, L.-Y.; Lai, C.-Y. Taiwanese 3G Mobile Phone Demand Forecasting by SVR with Hybrid Evolutionary Algorithms. Expert Syst. Appl. 2010, 37, 4452–4462. [Google Scholar] [CrossRef]
- Xenochristou, M.; Hutton, C.; Hofman, J.; Kapelan, Z. Water Demand Forecasting Accuracy and Influencing Factors at Different Spatial Scales Using a Gradient Boosting Machine. Water Resour. Res. 2020, 56, e2019WR026304b. [Google Scholar] [CrossRef]
- Hasan, R.; Kabir, M.A.; Shuvro, R.A.; Das, P. A Comparative Study on Forecasting of Retail Sales. arXiv 2022, arXiv:2203.06848. [Google Scholar] [CrossRef]
- Henzel, J.; Sikora, M. Gradient Boosting Application in Forecasting of Performance Indicators Values for Measuring the Efficiency of Promotions in FMCG Retail. In Proceedings of the 2020 Federated Conference on Computer Science and Information Systems, Sofia, Bulgaria, 6–9 September 2020. [Google Scholar] [CrossRef]
- Panarese, A.; Settanni, G.; Vitti, V.; Galiano, A. Developing and Preliminary Testing of a Machine Learning-Based Platform for Sales Forecasting Using a Gradient Boosting Approach. Appl. Sci. 2022, 12, 11054. [Google Scholar] [CrossRef]
- Massaro, A.; Panarese, A.; Giannone, D.; Galiano, A. Augmented Data and XGBoost Improvement for Sales Forecasting in the Large-Scale Retail Sector. Appl. Sci. 2021, 11, 7793. [Google Scholar] [CrossRef]
- Ul, I.; Nazir, K. Predicting Future Gold Rates Using Machine Learning Approach. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 12. [Google Scholar] [CrossRef] [Green Version]
- Osman AI, A.; Ahmed, A.N.; Chow, M.F.; Huang, Y.F.; El-Shafie, A. Extreme Gradient Boosting (Xgboost) Model to Predict the Groundwater Levels in Selangor Malaysia. Ain Shams Eng. J. 2021, 12, 1545–1556. [Google Scholar] [CrossRef]
- Haselbeck, F.; Killinger, J.; Menrad, K.; Hannus, T.; Grimm, D.G. Machine Learning Outperforms Classical Forecasting on Horticultural Sales Predictions. Mach. Learn. Appl. 2021, 7, 100239. [Google Scholar] [CrossRef]
- Labib, M.F.; Rifat, A.S.; Hossain, M.M.; Das, A.K.; Nawrine, F. Road Accident Analysis and Prediction of Accident Severity by Using Machine Learning in Bangladesh. In Proceedings of the 2019 7th international conference on smart computing & communications (ICSCC), Sarawak, Malaysia, 28–30 June 2019. [Google Scholar] [CrossRef]
- Mitra, A.; Jain, A.; Kishore, A.; Kumar, P. A Comparative Study of Demand Forecasting Models for a Multi-Channel Retail Company: A Novel Hybrid Machine Learning Approach. In Operations Research Forum; Springer: Berlin/Heidelberg, Germany, 2022; Volume 3. [Google Scholar] [CrossRef]
- Kaya, A.; Kaya, G.; Çebi, F. Forecasting Automobile Sales in Turkey with Artificial Neural Networks. Int. J. Bus. Anal. 2019, 6, 50–60. [Google Scholar] [CrossRef]
- Ramyar, S.; Kianfar, F. Forecasting Crude Oil Prices: A Comparison between Artificial Neural Networks and Vector Autoregressive Models. Comput. Econ. 2017, 53, 743–761. [Google Scholar] [CrossRef]
- Saha, P.; Gudheniya, N.; Mitra, R.; Das, D.; Narayana, S.; Tiwari, M.K. Demand Forecasting of a Multinational Retail Company Using Deep Learning Frameworks. IFAC-Pap. 2022, 55, 395–399. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M. Optimal Deep Learning LSTM Model for Electric Load Forecasting Using Feature Selection and Genetic Algorithm: Comparison with Machine Learning Approaches. Energies 2018, 11, 1636. [Google Scholar] [CrossRef] [Green Version]
- Lorente-Leyva, L.L.; Alemany, M.; Peluffo-Ordóñez, D.H.; Araujo, R.A. Demand Forecasting for Textile Products Using Statistical Analysis and Machine Learning Algorithms. In Asian Conference on Intelligent Information and Database Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 181–194. [Google Scholar] [CrossRef]
- Seda Hatice, G.; Boran, S. Prediction of demand for red blood cells using ridge regression, artificial neural network, and integrated taguchi-artificial neural network approach. Int. J. Ind. Eng. 2022, 29, 1. [Google Scholar] [CrossRef]
- Huang, J.; Chen, Q.; Yu, C. A New Feature Based Deep Attention Sales Forecasting Model for Enterprise Sustainable Development. Sustainability 2022, 14, 12224. [Google Scholar] [CrossRef]
- Petroșanu, D.-M.; Pîrjan, A.; Căruţaşu, G.; Tăbușcă, A.; Zirra, D.-L.; Perju-Mitran, A. E-Commerce Sales Revenues Forecasting by Means of Dynamically Designing, Developing and Validating a Directed Acyclic Graph (DAG) Network for Deep Learning. Electronics 2022, 11, 2940. [Google Scholar] [CrossRef]
- Schmidt, A.; Kabir, M.W.U.; Hoque, M.T. Machine Learning Based Restaurant Sales Forecasting. Mach. Learn. Knowl. Extr. 2022, 4, 105–130. [Google Scholar] [CrossRef]
- Kim, M.; Lee, S.; Jeong, T. Time Series Prediction Methodology and Ensemble Model Using Real-World Data. Electronics 2023, 12, 2811. [Google Scholar] [CrossRef]
- Tkachenko, R.; Izonin, I.; Vitynskyi, P.; Lotoshynska, N.; Pavlyuk, O. Development of the Non-Iterative Supervised Learning Predictor Based on the Ito Decomposition and SGTM Neural-Like Structure for Managing Medical Insurance Costs. Data 2018, 3, 46. [Google Scholar] [CrossRef] [Green Version]
- Izonin, I.; Tkachenko, R.; Vitynskyi, P.; Zub, K.; Tkachenko, P.; Dronyuk, I. Stacking-Based GRNN-SGTM Ensemble Model for Prediction Tasks. In Proceedings of the 2020 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 8–9 November 2020. [Google Scholar] [CrossRef]
- Tang, L.; Wu, Y.; Yu, L. A Non-Iterative Decomposition-Ensemble Learning Paradigm Using RVFL Network for Crude Oil Price Forecasting. Appl. Soft Comput. 2018, 70, 1097–1108. [Google Scholar] [CrossRef]
- Tanaka, K. A Sales Forecasting Model for New-Released and Nonlinear Sales Trend Products. Expert Syst. Appl. 2010, 37, 7387–7393. [Google Scholar] [CrossRef]
- Zhu, H.; Wang, Q.; Yan, L.; Wu, G. Are Consumers What They Consume?—Linking Lifestyle Segmentation to Product Attributes: An Exploratory Study of the Chinese Mobile Phone Market. J. Mark. Manag. 2009, 25, 295–314. [Google Scholar] [CrossRef]
- Schneider, M.J.; Gupta, S. Forecasting Sales of New and Existing Products Using Consumer Reviews: A Random Projections Approach. Int. J. Forecast. 2016, 32, 243–256. [Google Scholar] [CrossRef]
- Zhang, Y. The Impact of Brand Image on Consumer Behavior: A Literature Review. Open J. Bus. Manag. 2015, 3, 58–62. [Google Scholar] [CrossRef] [Green Version]
- Walters, R.G. Assessing the Impact of Retail Price Promotions on Product Substitution, Complementary Purchase, and Interstore Sales Displacement. J. Mark. 1991, 55, 17–28. [Google Scholar] [CrossRef]
- Keefer, A. How Does Poor Pricing Affect the Success of a Product? Available online: https://smallbusiness.chron.com/poor-pricing-affect-success-product-36373.html (accessed on 28 March 2023).
- Burmester, A.B.; Becker, J.U.; van Heerde, H.J.; Clement, M. The Impact of Pre- and Post-Launch Publicity and Advertising on New Product Sales. Int. J. Res. Mark. 2015, 32, 408–417. [Google Scholar] [CrossRef]
- Tellis, G.J.; Stremersch, S.; Yin, E. The International Takeoff of New Products: The Role of Economics, Culture, and Country Innovativeness. Mark. Sci. 2003, 22, 188–208. [Google Scholar] [CrossRef] [Green Version]
- Huarng, K.; Yu, T.H.-K. Ratio-Based Lengths of Intervals to Improve Fuzzy Time Series Forecasting. IEEE Trans. Syst. Man Cybern. Part B 2006, 36, 328–340. [Google Scholar] [CrossRef]
- Lu, C.-J. Sales Forecasting of Computer Products Based on Variable Selection Scheme and Support Vector Regression. Neurocomputing 2014, 128, 491–499. [Google Scholar] [CrossRef]
- Marquardt, D.W.; Snee, R.D. Ridge Regression in Practice. Am. Stat. 1975, 29, 3. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso: A Retrospective. J. R. Stat. Soc. Ser. B 2011, 73, 273–282. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory—COLT ’92, Pittsburgh, PA, USA, 27–29 July 1992. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R. A Short Introduction to Boosting. J. Jpn. Soc. Artif. Intell. 1999, 14, 771–780. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’16, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process Syst. 2017, 30, 3149–3157. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. Neural Information Processing Systems. Available online: https://proceedings.neurips.cc/paper/2018/hash/14491b756b3a51daac41c24863285549-Abstract.html (accessed on 15 April 2023).
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial Neural Networks: A Tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef] [Green Version]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Kaastra, I.; Boyd, M. Designing a Neural Network for Forecasting Financial and Economic Time Series. Neurocomputing 1996, 10, 215–236. [Google Scholar] [CrossRef]
- Medsker, L.; Jain, L.C. Recurrent Neural Networks: Design and Applications; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Passalis, N.; Tefas, A.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Deep Adaptive Input Normalization for Time Series Forecasting. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3760–3765. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ambarwari, A.; Jafar Adrian, Q.; Herdiyeni, Y. Analysis of the Effect of Data Scaling on the Performance of the Machine Learning Algorithm for Plant Identification. J. RESTI 2020, 4, 117–122. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.-M.; Tuleau-Malot, C. Variable Selection Using Random Forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef] [Green Version]
- Kursa, M.B.; Rudnicki, W.R. The All Relevant Feature Selection using Random Forest. arXiv 2011, arXiv:1106.5112. [Google Scholar] [CrossRef]
- Behnamian, A.; Millard, K.; Banks, S.N.; White, L.; Richardson, M.; Pasher, J. A Systematic Approach for Variable Selection with Random Forests: Achieving Stable Variable Importance Values. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1988–1992. [Google Scholar] [CrossRef] [Green Version]
- Wong, T.-T. Performance Evaluation of Classification Algorithms by K-Fold and Leave-One-out Cross Validation. Pattern Recognit. 2015, 48, 2839–2846. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root Mean Square Error (RMSE) or Mean Absolute Error (MAE)?—Arguments against Avoiding RMSE in the Literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Ehrenberg, A.S.C.; Hammond, K.; Goodhart, G.J. The After-Effects of Price-Related Consumer Promotions. J. Advert. Res. 1994, 34, 11–22. [Google Scholar]
- Jee, T.W. The Perception of Discount Sales Promotions—A Utilitarian and Hedonic Perspective. J. Retail. Consum. Serv. 2021, 63, 102745. [Google Scholar] [CrossRef]
- Valaskova, K.; Durana, P.; Adamko, P. Changes in Consumers’ Purchase Patterns as a Consequence of the COVID-19 Pandemic. Mathematics 2021, 9, 1788. [Google Scholar] [CrossRef]
- Rossolov, A.; Aloshynskyi, Y.; Lobashov, O. How COVID-19 Has Influenced the Purchase Patterns of Young Adults in Developed and Developing Economies: Factor Analysis of Shopping Behavior Roots. Sustainability 2022, 14, 941. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| X1 | Display size (mm) |
| X2 | Display resolution (ppi) |
| X3 | Operate System |
| X4 | CPU processor speed (GHz) |
| X5 | Number of processor cores |
| X6 | Rear camera pixels (MP) |
| X7 | Front camera pixels (MP) |
| X8 | RAM (GB) |
| X9 | Storage (GB) |
| X10 | Width (mm) |
| X11 | Length (mm) |
| X12 | Depth (mm) |
| X13 | Weight (g) |
| X14 | Battery capacity (mAh) |
| X15 | Brand |
| X16 | Release price (KRW) |
| X17 | Time of introduction |
| X18 | Previous 1 month’s sales |
| X19 | Previous 2 month’s sales |
| X20 | Previous 3 month’s sales |
| X21 | Previous 1–2 month’s moving average of sales |
| X22 | Previous 1–3 month’s moving average of sales |
| X23 | Relative difference between the previous 1 month’s sales and the previous 2 month’s sales |
| X24 | Relative difference between the previous 1 month’s sales and the previous 3 month’s sales |
| Variable | Characteristics | Mean | Std. Dev | Min | Max |
|---|---|---|---|---|---|
| Y | continuous | 14,184.68 | 16,156.55 | 100 | 79,158 |
| X1 | continuous | 160.78 | 15.91 | 96.6 | 192.7 |
| X2 | continuous | 407.97 | 77.73 | 246 | 536 |
| X3 | discrete | - | - | - | - |
| X4 | continuous | 2.65 | 0.44 | 1.4 | 3.09 |
| X5 | continuous | 7.14 | 1.28 | 4 | 8 |
| X6 | continuous | 55.95 | 37.35 | 8 | 168 |
| X7 | continuous | 15.43 | 9.21 | 5 | 40 |
| X8 | continuous | 6.27 | 3.08 | 2 | 12 |
| X9 | continuous | 160.86 | 102.34 | 32 | 512 |
| X10 | continuous | 155.45 | 11.75 | 122 | 169.5 |
| X11 | continuous | 74.3 | 9.87 | 60.2 | 128.2 |
| X12 | continuous | 8.21 | 1.53 | 6.9 | 16.1 |
| X13 | continuous | 187.32 | 31.06 | 133 | 282 |
| X14 | continuous | 3751.14 | 1007.93 | 1812 | 5000 |
| X15 | discrete | - | - | - | - |
| X16 | continuous | 976,829.73 | 485,853.42 | 199,100 | 1,760,000 |
| X17 | continuous | 4 | 2 | 1 | 7 |
| X18 | continuous | 12,617.78 | 15,749.29 | 0 | 79,158 |
| X19 | continuous | 10,752.53 | 14,984.32 | 0 | 79,158 |
| X20 | continuous | 8721.73 | 13,868.59 | 0 | 79,158 |
| X21 | continuous | 10,873.87 | 15,032.38 | 0 | 74,744.50 |
| X22 | continuous | 8805.38 | 14,151.91 | 0 | 75,489.33 |
| X23 | continuous | −0.16 | 0.81 | −7.92 | 0.96 |
| X24 | continuous | −0.16 | 0.87 | −8.76 | 2.16 |
| Model | Hyperparameter | Candidate Values | Selected Value |
|---|---|---|---|
| Ridge | alpha | [0.1, 0.3, 0.5, 0.7, 0.9, 1, 3, 5] | 1 |
| Lasso | alpha | [0.1, 0.3, 0.5, 0.7, 0.9, 1, 3, 5] | 0.7 |
| SVM | cost | [1000, 2000, 3000, 4000, 5000] | 3000 |
| Random Forest | number of estimators | [100, 300, 500, 700, 900] | 300 |
| GBM | number of estimators | [100, 300, 500, 700, 900] | 100 |
| AdaBoost | number of estimators | [100, 300, 500, 700, 900] | 300 |
| Lightgbm | number of estimators | [100, 300, 500, 700, 900] | 300 |
| XGBoost | number of estimators | [100, 300, 500, 700, 900] | 500 |
| CatBoost | number of estimators | [100, 300, 500, 700, 900] | 300 |
| DNN | number of neurons | [16, 32, 64, 128] | 64 |
| RNN | number of neurons | [16, 32, 64, 128] | 32 |
| LSTM | number of neurons | [16, 32, 64, 128] | 32 |
| Model | MAPE | RMSE | Correlation | Rank for MAPE | Rank for RMSE | Rank for Correlation | Total Ranking |
|---|---|---|---|---|---|---|---|
| Ridge | 245.0623 | 9747.8058 | 0.8045 | 9 | 7 | 7 | 23 |
| Lasso | 116.9212 | 20,346.4701 | 0.5842 | 8 | 12 | 9 | 29 |
| SVM | 54.9216 | 12,307.4523 | 0.7904 | 6 | 8 | 8 | 21 |
| Random Forest | 42.6258 | 8443.3328 | 0.8629 | 1 | 1 | 1 | 3 |
| GBM | 54.8821 | 9643.082 | 0.8163 | 5 | 5 | 5 | 15 |
| AdaBoost | 46.5266 | 9354.7838 | 0.8285 | 3 | 4 | 3 | 10 |
| Lightgbm | 58.7273 | 9689.4442 | 0.8052 | 7 | 6 | 6 | 19 |
| XGBoost | 51.0913 | 9274.0941 | 0.8242 | 4 | 3 | 4 | 11 |
| CatBoost | 42.922 | 9201.2448 | 0.8434 | 2 | 2 | 2 | 6 |
| DNN | 293.7084 | 13,265.2662 | 0.4306 | 10 | 9 | 10 | 29 |
| RNN | 310.3341 | 13,835.2733 | 0.3706 | 11 | 10 | 11 | 32 |
| LSTM | 326.1333 | 15,673.6825 | 0.3229 | 12 | 11 | 12 | 35 |
| Brand | MAPE | RMSE | Correlation |
|---|---|---|---|
| Samsung | 35.2090 | 7075.6550 | 0.8952 |
| Apple | 47.83854 | 9665.8200 | 0.8634 |
| LG | 64.07153 | 40,535.66 | 0.3241 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, S.; Yoon, G.; Baek, E.; Jeon, B.-K. A Sales Forecasting Model for New-Released and Short-Term Product: A Case Study of Mobile Phones. Electronics 2023, 12, 3256. https://doi.org/10.3390/electronics12153256
Hwang S, Yoon G, Baek E, Jeon B-K. A Sales Forecasting Model for New-Released and Short-Term Product: A Case Study of Mobile Phones. Electronics. 2023; 12(15):3256. https://doi.org/10.3390/electronics12153256
Chicago/Turabian StyleHwang, Seongbeom, Goonhu Yoon, Eunjung Baek, and Byoung-Ki Jeon. 2023. "A Sales Forecasting Model for New-Released and Short-Term Product: A Case Study of Mobile Phones" Electronics 12, no. 15: 3256. https://doi.org/10.3390/electronics12153256