

A Model for EEG-Based Emotion Recognition: CNN-Bi-LSTM with Attention Mechanism
Abstract
:1. Introduction
2. Materials and Methods
2.1. SEED Dataset
- (1)
- The length of the whole experiment should not be too long, so as not to cause fatigue in the subject.
- (2)
- The video can be understood without explanation.
- (3)
- The video should cause a single target emotion.
2.2. Data Pre-Processing
2.3. CNN-Bi-LSTM-Attention Model
2.3.1. Convolutional Neural Network
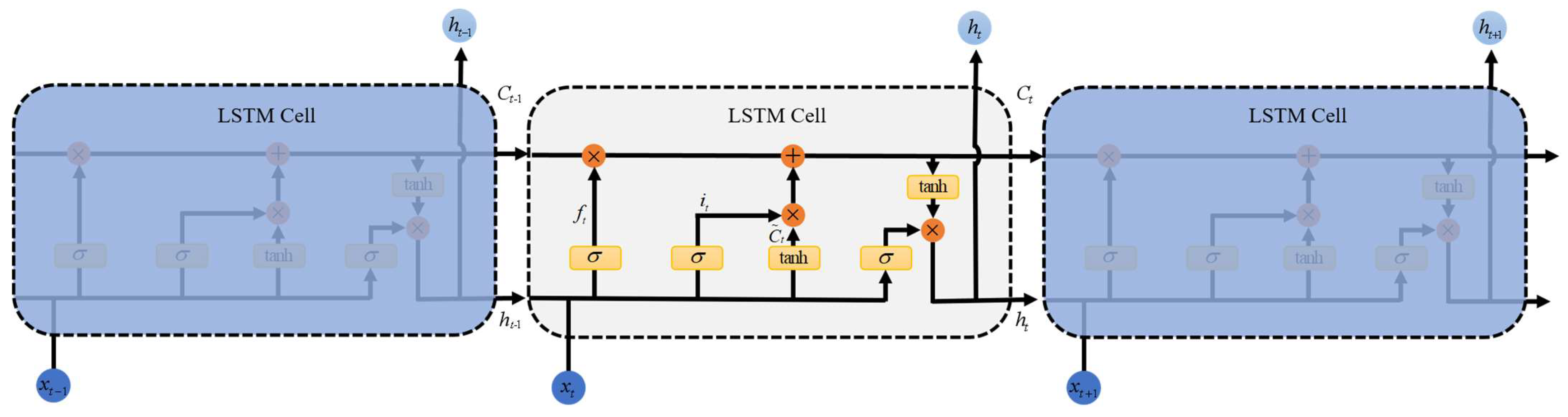
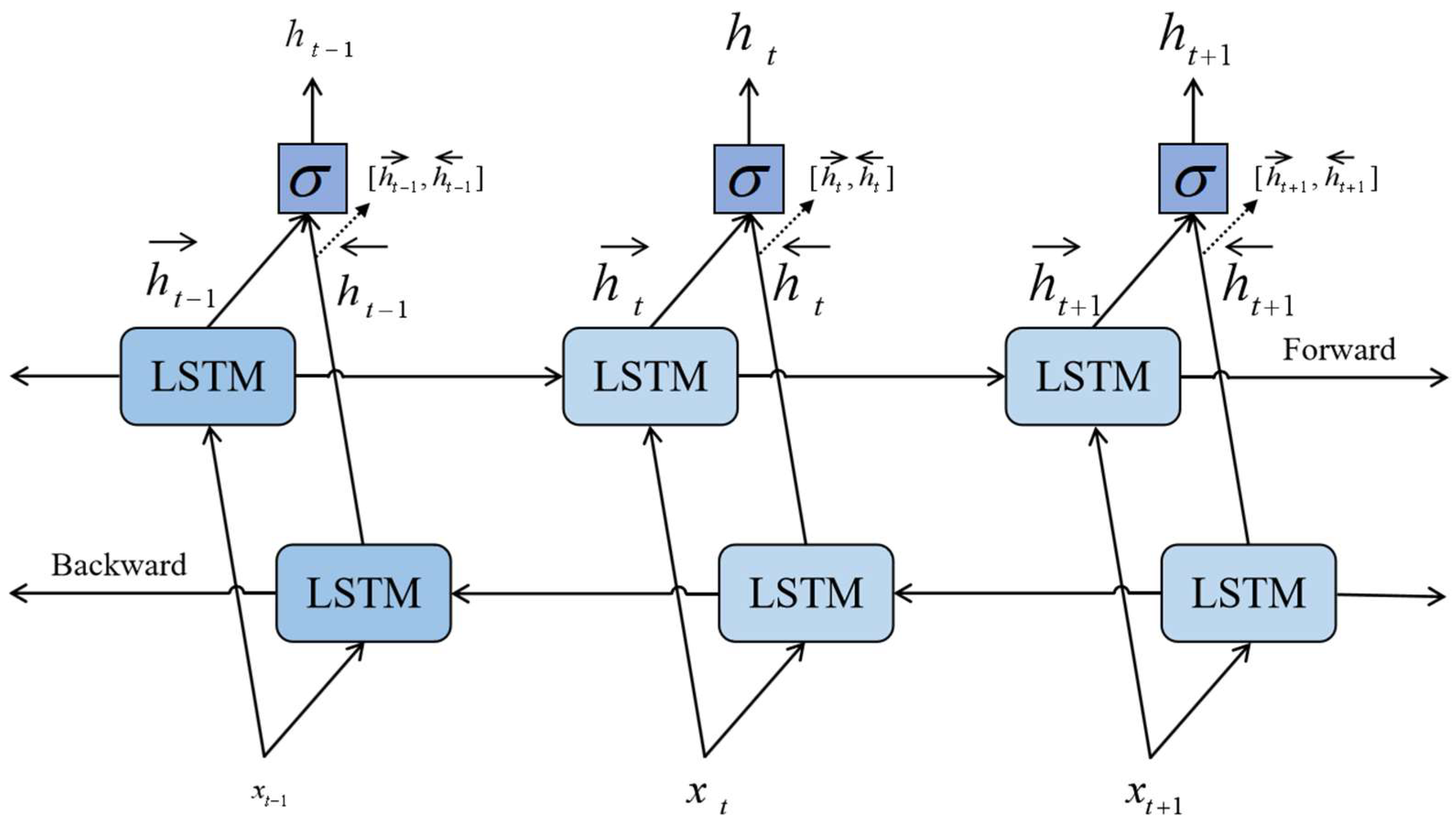
2.3.2. Bi-Directional Long Short-Term Memory
2.3.3. Attention Mechanism
2.3.4. Fully Connected Layer (FC)
2.3.5. Classifying
2.4. Evaluation Indexes
3. Experimental Results and Analysis
3.1. Experimental Setup
3.2. Recognition Results of Three and Four Classification Task
3.3. The Results of Ten-Fold Cross-Validation
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gabriels, K. Response to “uncertainty in emotion recognition”. J. Inf. Commun. Ethics Soc. 2019, 17, 295–298. [Google Scholar] [CrossRef]
- Kansizoglou, I.; Bampis, L.; Gasteratos, A. An active learning paradigm for online audio-visual emotion recognition. IEEE Trans. Affect. Comput. 2019, 13, 756–768. [Google Scholar] [CrossRef]
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J. Emotion recognition in human-computer interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Swangnetr, M.; Kaber, D.B. Emotional state classification in patient–robot interaction using wavelet analysis and statistics-based feature selection. IEEE Trans. Human-Mach. Syst. 2012, 43, 63–75. [Google Scholar] [CrossRef]
- Qureshi, S.A.; Dias, G.; Hasanuzzaman, M.; Saha, S. Improving depression level estimation by concurrently learning emotion intensity. IEEE Comput. Intell. Mag. 2020, 15, 47–59. [Google Scholar] [CrossRef]
- Hu, B.; Rao, J.; Li, X.; Cao, T.; Li, J.; Majoe, D.; Gutknecht, J. Emotion regulating attentional control abnormalities in major depressive disorder: An event-related potential study. Sci. Rep. 2017, 7, 13530. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, D.; Alsadoon, A.; Prasad, P.; Singh, A.; Elchouemi, A. An emotion recognition model based on facial recognition in virtual learning environment. Procedia Comput. Sci. 2018, 125, 2–10. [Google Scholar] [CrossRef]
- Li, T.M.; Shen, W.X.; Chao, H.C.; Zeadally, S. Analysis of students’ learning emotions using EEG. In Proceedings of the Innovative Technologies and Learning: Second International Conference, ICITL 2019, Tromsø, Norway, 2–5 December 2019; Proceedings 2. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 498–504. [Google Scholar]
- Huang, X.; Wang, S.-J.; Liu, X.; Zhao, G.; Feng, X.; Pietikainen, M. Discriminative spatiotemporal local binary pattern with revisited integral projection for spontaneous facial micro-expression recognition. IEEE Trans. Affect. Comput. 2017, 10, 32–47. [Google Scholar] [CrossRef] [Green Version]
- Petrushin, V. Emotion in speech: Recognition and application to call centers. Artif. Neural Netw. Eng. 1999, 710, 22. [Google Scholar]
- Yan, J.; Zheng, W.; Xin, M.; Yan, J. Integrating facial expression and body gesture in videos for emotion recognition. IEICE Trans. Inf. Syst. 2014, 97, 610–613. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Nejati, H.; Cheung, N.M. Deep neural networks on graph signals for brain imaging analysis. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3295–3299. [Google Scholar]
- Wang, X.-W.; Nie, D.; Lu, B.-L. Emotional state classification from EEG data using machine learning approach. Neurocomputing 2014, 129, 94–106. [Google Scholar] [CrossRef]
- Katsigiannis, S.; Ramzan, N. DREAMER: A database for emotion recognition through EEG and ECG signals from wireless low-cost off-the-shelf devices. IEEE J. Biomed. Health Inform. 2017, 22, 98–107. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hsu, Y.-L.; Wang, J.-S.; Chiang, W.-C.; Hung, C.-H. Automatic ECG-based emotion recognition in music listening. IEEE Trans. Affect. Comput. 2017, 11, 85–99. [Google Scholar] [CrossRef]
- Liu, Z.-T.; Xie, Q.; Wu, M.; Cao, W.-H.; Mei, Y.; Mao, J.-W. Speech emotion recognition based on an improved brain emotion learning model. Neurocomputing 2018, 309, 145–156. [Google Scholar] [CrossRef]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv 2015, arXiv:1511.06448. [Google Scholar]
- Gajic, D.; Djurovic, Z.; Gligorijevic, J.; Di Gennaro, S.; Savic-Gajic, I. Detection of epileptiform activity in EEG signals based on time-frequency and non-linear analysis. Front. Comput. Neurosci. 2015, 9, 38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gaur, P.; McCreadie, K.; Pachori, R.B.; Wang, H.; Prasad, G. Tangent space features-based transfer learning classification model for two-class motor imagery brain–computer interface. Int. J. Neural Syst. 2019, 29, 1950025. [Google Scholar] [CrossRef]
- Choi, H.; Park, J.; Yang, Y.-M. A Novel Quick-Response Eigenface Analysis Scheme for Brain–Computer Interfaces. Sensors 2022, 22, 5860. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V.; O’Sullivan, M.; Chan, A.; Diacoyanni-Tarlatzis, I.; Heider, K.; Krause, R.; LeCompte, W.A.; Pitcairn, T.; Ricci-Bitti, P.E.; et al. Universals and cultural differences in the judgments of facial expressions of emotion. J. Pers. Soc. Psychol. 1987, 53, 712–717. [Google Scholar] [CrossRef]
- Russell, J.A.; Barrett, L.F. Core affect, prototypical emotional episodes, and other things called emotion: Dissecting the elephant. J. Personal. Soc. Psychol. 1999, 76, 805. [Google Scholar] [CrossRef]
- Kim, K.H.; Bang, S.W.; Kim, S.R. Emotion recognition system using short-term monitoring of physiological signals. Med Biol. Eng. Comput. 2004, 42, 419–427. [Google Scholar] [CrossRef] [PubMed]
- Houssein, E.H.; Hammad, A.; Ali, A.A. Human emotion recognition from EEG-based brain–computer interface using machine learning: A comprehensive review. Neural Comput. Appl. 2022, 34, 12527–12557. [Google Scholar] [CrossRef]
- George, F.P.; Shaikat, I.M.; Hossain, P.S.F.; Parvez, M.Z.; Uddin, J. Recognition of emotional states using EEG signals based on time-frequency analysis and SVM classifier. Int. J. Electr. Comput. Eng. 2019, 9, 1012–1020. [Google Scholar] [CrossRef]
- Pandey, P.; Seeja, K. Subject independent emotion recognition from EEG using VMD and deep learning. J. King Saud Univ-Comput. Inf. Sci. 2022, 34, 1730–1738. [Google Scholar] [CrossRef]
- Thejaswini, S.; Ravikumar, K.M.; Jhenkar, L.; Natraj, A.; Abhay, K.K. Analysis of EEG based emotion detection for DEAP and SEED-IV databases using SVM 208 II. Lit. Rev. 2019, 1, 207–211. [Google Scholar]
- Alhagry, S.; Fahmy, A.A.; El-Khoribi, R.A. Emotion recognition based on EEG using LSTM recurrent neural network. Int. J. Adv. Comput. Sci. Appl. 2017, 8. [Google Scholar] [CrossRef] [Green Version]
- Yin, Y.; Zheng, X.; Hu, B.; Zhang, Y.; Cui, X. EEG emotion recognition using fusion model of graph convolutional neural networks and LSTM. Appl. Soft Comput. 2021, 100, 106954. [Google Scholar] [CrossRef]
- Cimtay, Y.; Ekmekcioglu, E. Investigating the use of pretrained convolutional neural network on cross-subject and cross-dataset EEG emotion recognition. Sensors 2020, 20, 2034. [Google Scholar] [CrossRef] [Green Version]
- Ozdemir, M.A.; Degirmenci, M.; Guren, O.; Akan, A. EEG based emotional state estimation using 2-D deep learning technique. In Proceedings of the 2019 Medical Technologies Congress (TIPTEKNO), Izmir, Turkey, 3–5 October 2019; pp. 1–4. [Google Scholar]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-end multimodal emotion recognition using deep neural networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef] [Green Version]
- Kansizoglou, I.; Misirlis, E.; Tsintotas, K.; Gasteratos, A. Continuous emotion recognition for long-term behavior modeling through recurrent neural networks. Technologies 2022, 10, 59. [Google Scholar] [CrossRef]
- Kwon, Y.-H.; Shin, S.-B.; Kim, S.-D. Electroencephalography based fusion two-dimensional (2D)-convolution neural networks (CNN) model for emotion recognition system. Sensors 2018, 18, 1383. [Google Scholar] [CrossRef] [Green Version]
- Thammasan, N.; Moriyama, K.; Fukui, K.-I.; Numao, M. Familiarity effects in EEG-based emotion recognition. Brain Informatics 2017, 4, 39–50. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhong, Q. Differential entropy feature signal extraction based on activation mode and its recognition in convolutional gated recurrent unit network. Front. Phys. 2021, 8, 629620. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, Q.; Fu, Y.; Chen, X. Continuous convolutional neural network with 3D input for EEG-based emotion recognition. In Neural Information Processing: 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, 13–16 December 2018; Proceedings, Part VII 25; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 433–443. [Google Scholar]
- Zheng, W.-L.; Lu, B.-L. Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks. IEEE Trans. Auton. Ment. Dev. 2015, 7, 162–175. [Google Scholar] [CrossRef]
- Duan, R.N.; Zhu, J.Y.; Lu, B.L. Differential entropy feature for EEG-based emotion classification. In Proceedings of the 2013 6th International IEEE/EMBS Conference on Neural Engineering (NER), San Diego, CA, USA, 6–8 November 2013; pp. 81–84. [Google Scholar]
- Zheng, W.-L.; Liu, W.; Lu, Y.; Lu, B.-L.; Cichocki, A. EmotionMeter: A multimodal framework for recognizing human emotions. IEEE Trans. Cybern. 2018, 49, 1110–1122. [Google Scholar] [CrossRef]
- Liu, C.; Liu, Y.; Yan, Y.; Wang, J. An intrusion detection model with hierarchical attention mechanism. IEEE Access 2020, 8, 67542–67554. [Google Scholar] [CrossRef]
- Huang, Z.; Ma, Y.; Wang, R.; Yuan, B.; Jiang, R.; Yang, Q.; Li, W.; Sun, J. DSCNN-LSTMs: A Lightweight and Efficient Model for Epilepsy Recognition. Brain Sci. 2022, 12, 1672. [Google Scholar] [CrossRef] [PubMed]
- Krichen, M.; Mihoub, A.; Alzahrani, M.Y.; Adoni, W.Y.H.; Nahhal, T. Are Formal Methods Applicable to Machine Learning And Artificial Intelligence? In Proceedings of the 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 9–11 May 2022; pp. 48–53. [Google Scholar]
- Raman, R.; Gupta, N.; Jeppu, Y. Framework for Formal Verification of Machine Learning Based Complex System-of-Systems. Insight 2013, 26, 91–102. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial NO. | Emotion Label | Film Clips’ Sources | Start Time Point | End Time Point |
|---|---|---|---|---|
| 01 | Lost in Thailand | happy | 0:06:13 | 0:10:11 |
| 02 | World Heritage in China | neutral | 0:00:50 | 0:04:36 |
| 03 | Aftershock | sad | 0:20:10 | 0:23:35 |
| 04 | Back to 1942 | sad | 0:49:58 | 0:54:00 |
| 05 | World Heritage in China | neutral | 0:10:40 | 0:13:44 |
| 06 | Lost in Thailand | happy | 1:05:10 | 1:08:29 |
| 07 | Back to 1942 | sad | 2:01:21 | 2:05:21 |
| 08 | World Heritage in China | neutral | 2:55 | 6:35 |
| 09 | Flirting Scholar | happy | 1:18:57 | 1:23:23 |
| 10 | Just Another Pandora’s Box | happy | 11:32 | 15:33 |
| 11 | World Heritage in China | neutral | 10:41 | 14:38 |
| 12 | Back to 1942 | sad | 2:16:37 | 2:20:37 |
| 13 | World Heritage in China | neutral | 5:36 | 9:36 |
| 14 | Just Another Pandora’s Box | happy | 35:00 | 39:02 |
| 15 | Aftershock | sad | 1:48:53 | 1:52:18 |
| Serial NO. | Emotion Label | Film Clips’ Sources | Start Time Point | End Time Point |
|---|---|---|---|---|
| 01 | Black Keys | sad | 42:32 | 45:41 |
| 02 | The Eye 3 | fear | 49:25:00 | 51:00:00 |
| 03 | Rob-B-Hood | happy | 41:07:00 | 45:06 |
| 04 | A Bite of China | neutral | 30:29 | 32:48 |
| 05 | The Child’s Eye | fear | 41:00 | 42:37 |
| 06 | A Bite of China | neutral | 5:19 | 8:05 |
| 07 | A Bite of China | neutral | 24:42 | 26:41 |
| 08 | Very Happy | sad | 17:09 | 21:13 |
| 09 | A Bite of China | neutral | 31:18 | 33:44 |
| 10 | A Wedding Invitation | sad | 1:34:04 | 1:38:50 |
| 11 | Bunshinsaba II | fear | 42:24 | 43:33 |
| 12 | Dearest | sad | 1:31:08 | 1:33:29 |
| 13 | Aftershock | sad | 20:13 | 24:14 |
| 14 | Foster Father | sad | 24:29 | 27:10 |
| 15 | Bunshinsaba III | fear | 1:04:52 | 1:09:49 |
| 16 | Promo for applying the Olympic Winter Games | happy | 0:00 | 2:54 |
| 17 | Hungry Ghost Ritual | fear | 45:07 | 46:48 |
| 18 | Hungry Ghost Ritual | fear | 1:10:21 | 1:13:33 |
| 19 | Very Happy | happy | 34:30 | 37:15 |
| 20 | You are my life more complete | happy | 39:32 | 40:44 |
| 21 | A Bite of China | neutral | 18:59 | 20:56 |
| 22 | Hear Me | happy | 1:33:27 | 96:10 |
| 23 | A Bite of China | neutral | 16:28 | 19:24 |
| 24 | Very Happy | happy | 12:48 | 15:31 |
| Parameter | Value |
|---|---|
| epoch number | 200 |
| learning rate | 0.001 |
| batch size | 1024 |
| optimizer | Adam |
| loss function | categorical_crossentropy |
| convolution kerne | 32 |
| activation function | ReLU |
| Bi-LSTM | 16 |
| FC1 | 32 |
| FC2 | 16 |
| classifier | Softmax |
| Random seed | 42 |
| Methods | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC (%) |
|---|---|---|---|---|---|
| CNN-RNN | 77.62 | 77.66 | 77.62 | 77.56 | 66.49 |
| CNN-LSTM | 94.69 | 94.70 | 94.69 | 94.69 | 92.04 |
| CNN-Bi-LSTM | 93.10 | 93.16 | 93.10 | 93.09 | 89.69 |
| DSCNN-RNN | 72.43 | 73.09 | 72.43 | 72.23 | 59.09 |
| DSCNN-LSTM | 94.03 | 94.04 | 94.03 | 94.03 | 91.05 |
| DSCNN-Bi-LSTM | 91.10 | 91.30 | 91.10 | 91.08 | 86.76 |
| 1D CAE | 95.92 | 95.92 | 95.92 | 95.91 | 93.88 |
| 1D InceptionV1 | 87.72 | 87.89 | 87.72 | 87.70 | 81.68 |
| Adaboost | 54.29 | 55.03 | 54.29 | 53.99 | 31.86 |
| Bayes | 40.95 | 42.97 | 40.95 | 35.88 | 13.77 |
| Decision Tree | 79.38 | 81.06 | 79.38 | 79.47 | 69.78 |
| KNN | 54.29 | 55.03 | 54.29 | 53.99 | 31.86 |
| Random Forest | 94.73 | 95.20 | 94.73 | 94.76 | 92.30 |
| XGBoost | 95.12 | 95.21 | 95.12 | 95.12 | 92.73 |
| CNN-Bi- LSTM-Attention | 99.44 | 99.45 | 99.44 | 99.44 | 99.16 |
| Methods | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC (%) |
|---|---|---|---|---|---|
| CNN-RNN | 56.87 | 57.72 | 56.87 | 56.91 | 42.72 |
| CNN-LSTM | 87.68 | 87.71 | 87.68 | 87.68 | 83.59 |
| CNN-Bi-LSTM | 85.43 | 85.52 | 85.43 | 85.45 | 80.59 |
| DSCNN-RNN | 55.35 | 55.48 | 55.35 | 54.75 | 40.78 |
| DSCNN-LSTM | 88.87 | 88.87 | 88.87 | 88.87 | 85.17 |
| DSCNN-Bi-LSTM | 84.08 | 84.08 | 84.08 | 84.08 | 78.78 |
| 1D CAE | 87.29 | 87.29 | 87.29 | 87.29 | 83.06 |
| 1D InceptionV1 | 78.06 | 78.17 | 78.06 | 78.07 | 70.77 |
| Adaboost | 37.49 | 37.52 | 37.49 | 37.41 | 16.69 |
| Bayes | 26.10 | 30.44 | 26.10 | 17.39 | 24.6 |
| Decision Tree | 88.46 | 88.63 | 88.46 | 88.50 | 84.65 |
| KNN | 37.49 | 37.52 | 37.49 | 37.41 | 16.69 |
| Random Forest | 96.65 | 96.75 | 96.65 | 96.66 | 95.56 |
| XGBoost | 87.23 | 87.34 | 87.23 | 87.24 | 82.99 |
| CNN-Bi- LSTM-Attention | 99.99 | 99.99 | 99.99 | 99.99 | 99.99 |
| Methods | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC (%) |
|---|---|---|---|---|---|
| CNN-RNN | 73.03 | 73.31 | 73.02 | 72.98 | 59.70 |
| CNN-LSTM | 93.28 | 93.29 | 93.27 | 93.28 | 89.92 |
| CNN-Bi-LSTM | 92.17 | 92.19 | 92.17 | 92.17 | 88.28 |
| DSCNN-RNN | 70.57 | 70.93 | 70.58 | 70.49 | 56.07 |
| DSCNN-LSTM | 92.96 | 92.98 | 92.96 | 92.96 | 89.46 |
| DSCNN-Bi-LSTM | 89.74 | 89.77 | 89.75 | 89.74 | 84.64 |
| 1D CAE | 92.07 | 9212 | 92.06 | 82.88 | 88.13 |
| 1D InceptionV1 | 82.27 | 82.60 | 82.27 | 82.25 | 73.58 |
| Adaboost | 52.63 | 53.38 | 52.64 | 52.35 | 29.35 |
| Bayes | 41.79 | 42.23 | 41.79 | 38.82 | 13.75 |
| Decision Tree | 81.08 | 81.08 | 81.08 | 81.08 | 71.62 |
| KNN | 92.24 | 92.27 | 92.24 | 92.24 | 88.38 |
| Random Forest | 97.26 | 97.27 | 97.26 | 97.25 | 95.90 |
| XGBoost | 90.69 | 90.91 | 90.69 | 90.69 | 86.14 |
| CNN-Bi- LSTM-Attention | 99.55 | 99.55 | 99.55 | 99.54 | 99.32 |
| Methods | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC (%) |
|---|---|---|---|---|---|
| CNN-RNN | 54.99 | 55.74 | 54.99 | 54.73 | 40.29 |
| CNN-LSTM | 83.65 | 83.70 | 83.64 | 83.65 | 78.21 |
| CNN-Bi-LSTM | 82.20 | 82.25 | 82.20 | 82.20 | 76.29 |
| DSCNN-RNN | 54.99 | 55.74 | 54.99 | 54.73 | 40.29 |
| DSCNN-LSTM | 81.15 | 81.18 | 81.15 | 81.14 | 74.88 |
| DSCNN-Bi-LSTM | 79.98 | 80.08 | 79.97 | 79.97 | 73.34 |
| 1D CAE | 83.20 | 83.26 | 83.20 | 83.20 | 77.63 |
| 1D InceptionV1 | 73.31 | 73.96 | 73.30 | 73.24 | 64.64 |
| Adaboost | 35.93 | 36.00 | 35.93 | 35.82 | 14.61 |
| Bayes | 25.77 | 28.84 | 25.77 | 17.34 | 16.60 |
| Decision Tree | 74.10 | 74.11 | 74.10 | 74.10 | 65.47 |
| KNN | 96.16 | 96.16 | 96.16 | 96.16 | 94.88 |
| Random Forest | 95.98 | 95.99 | 95.98 | 95.98 | 94.64 |
| XGBoost | 80.57 | 80.81 | 80.57 | 80.61 | 74.15 |
| CNN-Bi- LSTM-Attention | 99.79 | 99.79 | 99.79 | 99.79 | 99.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Ma, Y.; Wang, R.; Li, W.; Dai, Y. A Model for EEG-Based Emotion Recognition: CNN-Bi-LSTM with Attention Mechanism. Electronics 2023, 12, 3188. https://doi.org/10.3390/electronics12143188
Huang Z, Ma Y, Wang R, Li W, Dai Y. A Model for EEG-Based Emotion Recognition: CNN-Bi-LSTM with Attention Mechanism. Electronics. 2023; 12(14):3188. https://doi.org/10.3390/electronics12143188
Chicago/Turabian StyleHuang, Zhentao, Yahong Ma, Rongrong Wang, Weisu Li, and Yongsheng Dai. 2023. "A Model for EEG-Based Emotion Recognition: CNN-Bi-LSTM with Attention Mechanism" Electronics 12, no. 14: 3188. https://doi.org/10.3390/electronics12143188