
Skeleton-Based Human Action Recognition Based on Single Path One-Shot Neural Architecture Search
 ,
,
Abstract
:1. Introduction
- To improve the search efficiency and reduce the NAS search time, the optimization operation of the NAS search space is simplified. Secondly, a single-path one-shot weight-sharing model is proposed to replace the original weight-sharing strategy.
- To automatically sample candidate networks from the super-net, a new covariance matrix adaptation evolution strategy is employed.
2. Related Work
2.1. Skeleton Recognition Based on GCN
2.2. Neural Architecture Search
2.3. Graph Convolutional Networks Based on Neural Architecture Search
3. Methods
3.1. GCN-Based Skeleton Recognition Network
3.2. A Single Path One-Shot NAS Method
3.2.1. One-Shot Weight Sharing Method
3.2.2. Single Path One-Shot Algorithm
3.3. GCN Search Space Design
3.3.1. Feature Structure Choice Blocks
3.3.2. Chebyshev Choice Block
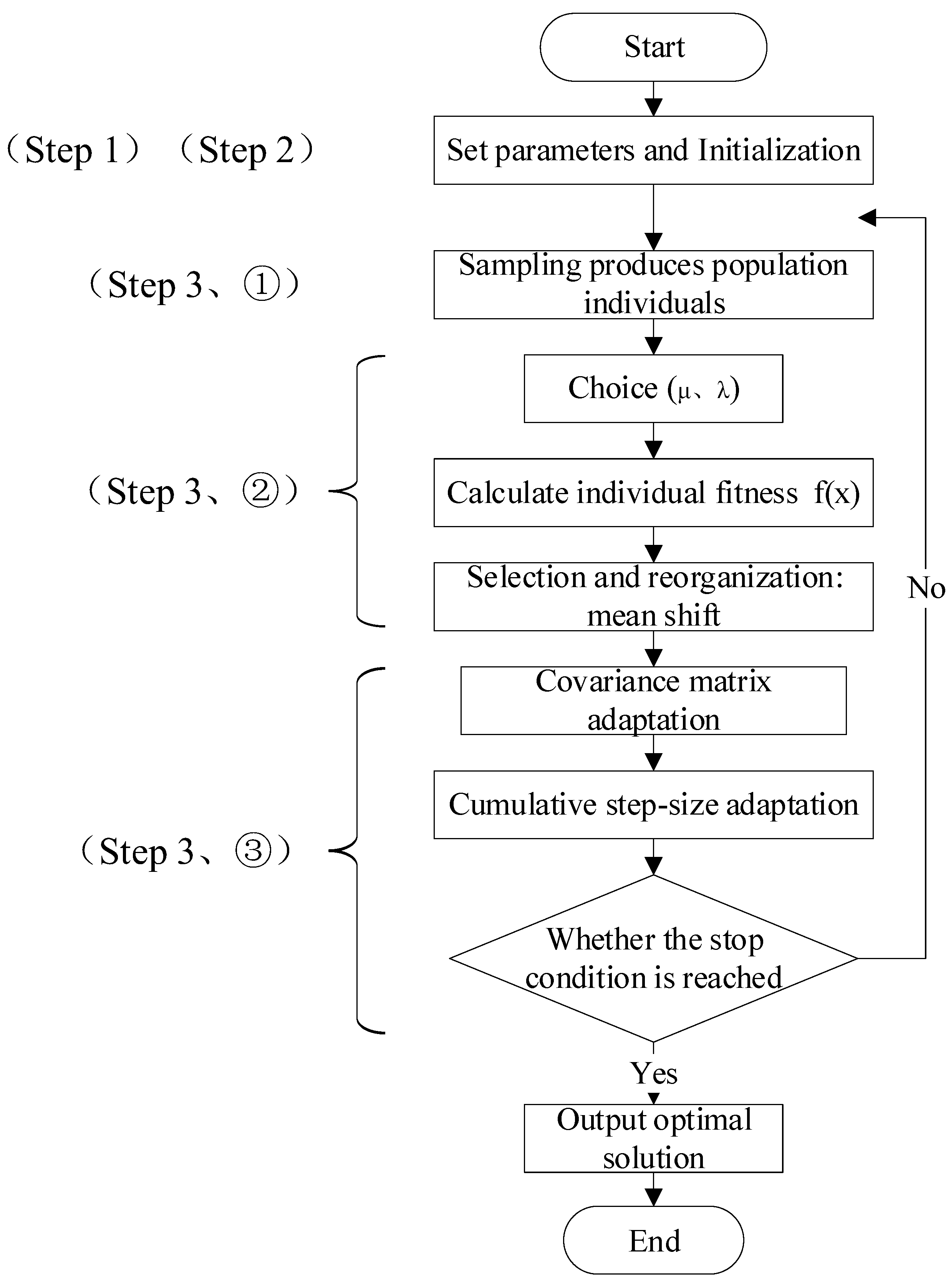
3.4. Search Strategy Algorithm
| Algorithm 1: CMA—ES algorithm |
| set {\displaystyle\lambda} // number of samples per iteration, at least two, generally >4 initialize {\displaystyle m} // initialize state variables while not terminate do // iterate for i {\displaystyle i} in {\displaystyle \{1\ldots \lambda \}} do // sample {\displaystyle \lambda } new solutions and evaluate them {\displaystyle x_{i}={}} sample_multivariate_normal(mean = m {\displaystyle {}=m} , covariance_matrix {\displaystyle {}=\sigma ^{2}C} ) {\displaystyle f_{i}=\operatorname {fitness} (x_{i})} {\displaystyle x_{1\laots \lambda }} {\displaystyle x_{s(1)\ldots s(\lambda)}} with {\displaystyle s(i)=\operatorname {argsort} (f_{1\ldots \lambda },i)} // sort solutions {\displaystyle m′=m} // need later {\displaystyle m-m′} and {\displaystyle x_{i}-m′} {\displaystyle m} ← update_m {\displaystyle (x_{1},\ldots,x_{\lambda })} // move means to better solutions {\displaystyle p_{\sigma }} ← update_ps {\displaystyle (p_{\sigma },\sigma ^{-1}C^{-1/2}(m-m′))} // update isotropic evolution path {\displaystyle p_{c}} ← update_pc {\displaystyle (p_{c},\sigma ^{-1}(m-m′),\|p_{\sigma }\|)} // update anisotropic evolution path {\displaystyle C} ← update_C {\displaystyle (C,p_{c},(x_{1}-m′)/\sigma,\ldots,(x_{\lambda }-m′)/\sigma)} // update covariance matrix {\displaystyle \sigma } ← update_sigma {\displaystyle (\sigma,\|p_{\sigma }\|)} // update step-size using isotropic path length return {\displaystyle m} or {\displaystyle x_{1}} |
3.5. Summary
4. Experiments
4.1. Dataset and Evaluation Metrics
4.2. Experimental Details
4.2.1. Ablation Study
4.2.2. Search Cost Analysis
- Cost analysis of search space
- 2.
- Comparison of search costs with the baseline model
4.2.3. Comparison with State-of-the-Art (SOTA)
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sijie, Y.; Xiong, Y.; Lin, D. Spatial-temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Perez-Rua, J.-M.; Vielzeuf, V.; Pateux, S.; Baccouche, M.; Jurie, F. Mfas: Multimodal fusion architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Peng, W.; Hong, X.; Chen, H.; Zhao, G. Learning graph convolutional network for skeleton-based human action recognition by neural searching. Proc. AAAI Conf. Artif. Intell. 2020, 34, 2669–2676. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.-T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. Proc. IEEE Int. Conf. Comput. Vis. 2017, 41, 1963–1978. [Google Scholar]
- Soo, K.T.; Reiter, A. InterpreTable 3d human action analysis with temporal convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, M.; Liu, H.; Chen, C. Enhanced skeleton visualization for view invariant human action recognition. Pattern Recognit. 2017, 68, 346–362. [Google Scholar] [CrossRef]
- Ullah, K.I.; Afzal, S.; Lee, J.W. Human activity recognition via hybrid deep learning based model. Sensors 2022, 22, 323. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.; Shin, J.; Shin, J.; Lee, D.; Choi, A. Robust human activity recognition by integrating image and accelerometer sensor data using deep fusion network. Sensors 2021, 22, 174. [Google Scholar] [CrossRef] [PubMed]
- Monti, F.; Boscaini, D.; Masci, J.; Rodolà, E.; Svoboda, J.; Bronstein, M.M. Geometric deep learning on graphs and manifolds using mixture model cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Smash: One-shot model architecture search through hypernetworks. arXiv 2017, arXiv:1708.05344. [Google Scholar]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.-J.; Fei-Fei, L.; Yuille, A.; Huang, J.; Murphy, K. Progressive neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Perez-Rua, J.-M.; Baccouche, M.; Pateux, S. Efficient progressive neural architecture search. arXiv 2018, arXiv:1808.00391. [Google Scholar]
- Pham, H.; Guan, M.Y.; Zoph, B.; Le, Q.V.; Dean, J. Efficient neural architecture search via parameters sharing. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Barret, Z.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Yao, Y.; Liu, R.; Zhang, J.; Zhong, W.; Fan, X.; Luo, Z. Hardware-Aware Low-Light Image Enhancement via One-Shot Neural Architecture Search with Shrinkage Sampling. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021. [Google Scholar]
- Luo, R.; Tian, F.; Qin, T.; Chen, E.; Liu, T.Y. Neural architecture optimization. Adv. Neural Inf. Process. Syst. 2018, 31, 1–12. [Google Scholar]
- Zhu, H.; An, Z.; Yang, C.; Xu, K.; Zhao, E.; Xu, Y. EENA: Efficient evolution of neural architecture. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Chu, X.; Zhang, B.; Xu, R. Fairnas: Rethinking evaluation fairness of weight sharing neural architecture search. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Liang, T.; Wang, Y.; Tang, Z.; Ling, H. Opanas: One-shot path aggregation network architecture search for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Guo, Z.; Zhang, X.; Mu, H.; Heng, W.; Liu, Z.; Wei, Y.; Sun, J. Single path one-shot neural architecture search with uniform sampling. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Bender, G.; Kindermans, P.J.; Zoph, B.; Vasudevan, V.; Le, Q. Understanding and simplifying one-shot architecture search. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Gao, Y.; Yang, H.; Zhang, P.; Zhou, C.; Hu, Y. Graphnas: Graph neural architecture search with reinforcement learning. arXiv 2019, arXiv:1904.09981. [Google Scholar]
- Zhou, K.; Song, Q.; Huang, X.; Hu, X. Auto-gnn: Neural architecture search of graph neural networks. arXiv 2019, arXiv:1909.03184. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Yao, Q.; Zhao, H.; Zhang, T. Diffmg: Differentiable meta graph search for heterogeneous graph neural networks. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021. [Google Scholar]
- Cai, S.; Li, L.; Deng, J.; Zhang, B.; Zha, Z.-J.; Su, L.; Huang, Q. Rethinking graph neural architecture search from message-passing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Li, G.; Qian, G.; Delgadillo, I.C.; Müller, M.; Thabet, A.; Ghanem, B. Sgas: Sequential greedy architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, H.; Jin, Y.; Hao, K. Evolutionary search for complete neural network architectures with partial weight sharing. IEEE Trans. Evol. Comput. 2022, 26, 1072–1086. [Google Scholar] [CrossRef]
- Xia, X.; Xiao, X.; Wang, X.; Zheng, M. Progressive Automatic Design of Search Space for One-Shot Neural Architecture Search. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar]
- Michaël, D.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Zhang, C.; Xiao, C.; Guo, X. Covariance Matrix Evolutionary Preference-based Policy Search for Robot Confrontation. In Proceedings of the 2022 7th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar]
- Nilotpal, S.; Chen, K.-W. Neural Architecture Search using Covariance Matrix Adaptation Evolution Strategy. arXiv 2021, arXiv:2107.07266. [Google Scholar]
- Zhang, J.; Qi, H.; Ji, Y.; Ren, Y.; He, M.; Su, M.; Cai, X. Nonlinear acoustic tomography for measuring the temperature and velocity fields by using the covariance matrix adaptation evolution strategy algorithm. IEEE Trans. Instrum. Meas. 2021, 71, 4500214. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4 December 2017. [Google Scholar]
- Zhang, H.; Hou, Y.; Wang, P.; Guo, Z.; Li, W. SAR-NAS: Skeleton-based action recognition via neural architecture searching. J. Vis. Commun. Image Represent. 2020, 73, 102942. [Google Scholar] [CrossRef]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. arXiv 2018, arXiv:1804.06055. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Xing, H.; Burschka, D. Skeletal human action recognition using hybrid attention based graph convolutional network. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Joint (%) | Search Time per Epoch (mins) |
|---|---|---|
| Ours (T) | 93.8 | 20.46 |
| Ours (ST) | 93.8 | 16.26 |
| Ours (S + T + ST) | 93.7 | 24.19 |
| Ours (T + Cheb2) | 94.2 | 20.53 |
| Ours (ST + Cheb2) | 94.2 | 16.28 |
| Ours (S + T + ST + Cheb2) | 94.1 | 24.22 |
| Ours(SNAS-GCN) | 94.3 | 17.43 |
| Methods | Joint (%) | Search Time per Epoch (mins) |
|---|---|---|
| Ours(S + T + ST + Cheb2) | 94.1 | 24.22 |
| GCN-NAS(S + T + ST + Cheb2) | 94.3 | 25.1 |
| Ours(7 Categories) | 94.4 | 25.2 |
| GCN-NAS(7 Categories) | 94.6 | 26.1 |
| Ours (single path NAS) | 94.3 | 17.43 |
| Method | Training Time | Search Time | Total Time | CV (Joint) (%) |
|---|---|---|---|---|
| MFAS [3] | -- | 150.91 h | -- | 93.46 |
| GCN-NAS [4] | 24 h | 46.2 h | 70.2 h | 94.6 |
| SAR-NAS [39] | -- | 29 h | -- | 94.3 |
| Ours (Joint) | 17.7 h | 34.4 h | 52.1 | 94.3 |
| Architecture | CS (%) | CV (%) | Time-Consuming Search |
|---|---|---|---|
| HCN [40] | 86.5 | 91.1 | -- |
| ST-GCN [1] | 81.5 | 88.3 | -- |
| AS-GCN [41] | 86.8 | 94.2 | -- |
| DARTS [42] | 83.9 | 92.0 | -- |
| SAR-NAS [39] | 86.4 | 94.3 | 29 h+ |
| MFAS [3] | -- | 93.46 | 150.91 h+ |
| 2S-AGCN [2] | 88.5 | 95.1 | -- |
| NAS-GCN [4] | 89.4 | 95.7 | 70.2 h |
| 2s HA-GCN [43] | 91.5 | 96.6 | -- |
| Ours (Joint) | 87.1 | 94.3 | 52.1 h |
| Ours (Bone) | 86.0 | 94.0 | -- |
| Ours(Joint + Bone) | 89.0 | 95.0 | -- |
| Model | Top-1 (%) | Top-5 (%) |
|---|---|---|
| ST-GCN [1] | 30.7 | 52.8 |
| AS-GCN [41] | 34.8 | 56.5 |
| DARTS [42] | 32.1 | 54.0 |
| 2S-AGCN [2] | 36.1 | 58.7 |
| SAR-NAS [39] | 33.6 | 56.3 |
| NAS-GCN (Joint) [4] | 35.5 | 57.9 |
| NAS-GCN (Bone) [4] | 34.9 | 57.1 |
| NAS-GCN [4] | 37.1 | 60.1 |
| 2s HA-GCN [43] | 37.4 | 60.5 |
| Ours (Joint) | 35.6 | 57.9 |
| Ours (Bone) | 34.8 | 57.0 |
| Ours (Joint + Bone) | 37.0 | 60.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Yu, S.; Wang, T.; Sun, Z.; Wang, S. Skeleton-Based Human Action Recognition Based on Single Path One-Shot Neural Architecture Search. Electronics 2023, 12, 3156. https://doi.org/10.3390/electronics12143156
Jiang Y, Yu S, Wang T, Sun Z, Wang S. Skeleton-Based Human Action Recognition Based on Single Path One-Shot Neural Architecture Search. Electronics. 2023; 12(14):3156. https://doi.org/10.3390/electronics12143156
Chicago/Turabian StyleJiang, Yujian, Saisai Yu, Tianhao Wang, Zhaoneng Sun, and Shuang Wang. 2023. "Skeleton-Based Human Action Recognition Based on Single Path One-Shot Neural Architecture Search" Electronics 12, no. 14: 3156. https://doi.org/10.3390/electronics12143156