1. Introduction
Text classification is a fundamental NLP task that is widely leveraged across various domains, including but not limited to spam detection [
1], news categorization [
2], and e-commerce product evaluation [
3]. Research on text classification methods dates back to the early days of computing in the 1950s with the advent of rule-based approaches. In the 1990s, methods combining machine learning techniques such as feature engineering and classifiers became prevalent [
4]; presently, however, CNN [
5], RNN [
6,
7], attention mechanism [
8], and other deep learning techniques are more popular for text classification tasks.
Regardless of the chosen method, there are two primary issues that need to be considered: domain dependence and the requirement for a sizeable annotated corpus. Domain dependence pertains to the fact that a classifier trained on a specific domain may not perform as well in other domains due to differences in the meanings of vocabulary across domains, such that the same word may convey divergent meanings in different domains. As depicted in
Figure 1 and noted in the work of Cai et al. [
9], the word “infantile” frequently connotes a negative sentiment in the domain of movie reviews (for instance, “The idea of the movie is infantile”), whereas in evaluations of infant products (such as “The infantile toy was sold out yesterday”), there is typically no overt emotional valence. In order to train classifiers for different domains of text, it is crucial to have a sufficient amount of labeled data for each domain. Unfortunately, not all domains have an adequate amount of domain-specific text to train on. Therefore, we must leverage text corpora from diverse domains to effectively classify text from a specific domain. This approach is known as Multi-Domain Text Classification (MDTC) and has been explored in previous research [
10,
11]. However, conventional MDTC methods [
11,
12] tend to overlook an important piece of information: different domains present varying levels of difficulty in classification.
Different classification difficulties could stem from differences in feature extraction complexity, differences in data distribution, variations in emotional tones conveyed through certain vocabulary choices, differences in sentence lengths, and variety of vocabulary. Failing to account for these differences between domains and arbitrarily training the prediction models for each domain can lead to suboptimal performance when encountering difficult text classification tasks. Essentially, exposing the model to very complex domain texts at an earlier stage of training may impair its ability to learn explicit features of these texts well, resulting in less accurate predictions for challenging text domains.
The task of text classification in different domains varies in difficulty, and thus, this variability can be leveraged to train the model from easy to difficult data. This learning strategy, called curriculum learning [
13], mirrors the way humans learn, where simple concepts are first internalized before moving on to more complex ones. Curriculum learning has demonstrated significant improvements in various natural language processing tasks, including dialog state tracking [
14], few-shot text classification [
15], Chinese spell checking [
16], among others. The essence of curriculum learning lies in the measurement of data difficulty and scheduling.
Inspired by curriculum learning, we propose a mechanism for measuring domain text difficulty based on keyword weight ranking. The keywords of texts of a domain, which are the most closely related to the meaning of the text, effectively reflect the specific features of each domain. Extracting and analyzing such keywords allows us to comprehend domain-specific subjects and content, effectively revealing their core concepts. By identifying the keywords in domain texts, we are better able to understand their themes, key content, and underlying concerns, leading to a more comprehensive comprehension of the text. So the greater the weight of keywords in the text of a certain field, the clearer the core concept of this field, the simpler the data distribution, and the easier it is to extract text features.
By incorporating multi-domain text classification to extract both domain-shared and domain-specific features, we suggest utilizing the total weight of domain-specific keywords as a metric for the complexity of domain-adapted feature extraction. We then utilize this metric to optimize the order in which a specific domain corpus is presented to the model during training. Beginning with texts that have simple data distributions and easy-to-extract features allows the model to establish a foundation for developing its capabilities and then build upon this foundation as it encounters more challenging texts within the chosen domain. Through this incremental approach, the model can achieve enhanced learning performance and greater mastery of difficult texts within the designated domain.
Building upon the aforementioned motivations, we present a novel framework termed “Keyword-weight-aware Curriculum Learning” (KCL) for Multi-Domain Text Classification (MDTC). Our method is the first application of curriculum learning to multi-domain text classification. KCL incorporates two notable features:
(1) We calculate the weights of words in the texts and extract the Top-N words as domain-specific keywords. The sum of these N keywords’ weights is then utilized as a measurement to measure the level of complexity of each domain’s feature extraction. Higher sums indicate more apparent domain-specific features and simpler feature extraction, requiring prioritization of the domain corpus during model training.
(2) By employing varied approaches for keyword extraction and evaluating distinct quantities of keywords, we aim to identify the optimal domain order.
Experimental results demonstrate the efficacy of our proposed methodology in augmenting Multi-Domain Text Classification (MDTC) accuracy. Specifically, our approach reaches state-of-the-art outcomes on both the Amazon review and FDU-MTL datasets.
2. Related Work
Curriculum Learning: Bengio [
13] introduced the concept of curriculum learning, with its focal point being the difficulty measurer of sample data and the data scheduling scheme of the training process. The sample difficulty measurer can be classified into two types: automatic and manual. The automatic difficulty measurer entails measuring the difficulty of samples through the model’s performance, while the manual difficulty measurer is based on the grammatical and syntactic structure of the sample, such as measuring the number of nouns and sentence length. After years of development, curriculum learning strategies have exhibited impressive performance in the areas of response generation [
17] and Contrastive Learning [
18].
Pre-trained model: The process of utilizing pre-trained models in natural language processing (NLP) consists of two phases: pre-training and downstream task fine-tuning. Pre-training involves training the model on a vast corpus of data using a significant amount of computing resources. Once pre-training is complete, the model can then be applied to downstream tasks, and various parameters of the model can be fine-tuned during this stage of the training process. The use of pre-trained models has led to significant improvements in the performance of deep learning models in NLP, with models such as Bert surpassing human performance in SQuAD1.1 and achieving state-of-the-art (SOTA) results in 11 different NLP benchmarks. Consequently, these pre-trained models, including ELMO, XLNet, and ERNIE3.0, are widely applied in the NLP field due to their remarkable impact on the performance of deep learning models.
Multi-domain Text Classification: Li et al. [
10] originally proposed multi-domain text classification to enhance a model’s performance in a particular domain by combining data from multiple domains. The conventional approach was to adopt a shared-private structure to extract both domain-shared and domain-specific features. However, some teams subsequently applied adversarial learning [
11,
19] to differentiate between these features to avoid ambiguity. Attention mechanisms [
9] and pre-trained models [
12] have also been incorporated to improve the representation of text and to train more effective models.
4. Experiments
4.1. Datasets
We conducted experiments in the field of multi-domain text classification using two well-known datasets: the Amazon review dataset [
20,
21] and the FDU-MTL dataset [
22]. The Amazon review dataset is composed of product reviews in four diverse domains: DVD, Books, Electronics, and Kitchen, each with 1000 positive and negative reviews. The average length of all samples of the Amazon-review dataset is 140.88 words.
The FDU-MTL dataset is significantly larger than the Amazon review dataset, comprising a total of 16 domains: Books, Electronics, DVD, Kitchen, Apparel, Camera, Health, Music, Toys, Video, Baby, Magazine, Software, Sports, IMDB, and MR. The first 14 domains consist of product reviews sourced from Amazon, while IMDB and MR are movie reviews gathered from IMDB and Rotten Tomatoes, respectively. The average length of all samples of the FDU-MTL dataset is 131.73 words. Each domain within the FDU-MTL dataset comprises approximately 1600 labeled samples in the training set, 400 labeled samples in the test set, and 2000 unlabeled samples. The unlabeled sample data is suitable for training the .
In each of the two datasets, the number of samples falling within different length intervals can be described as
Table 1 and
Table 2.
4.2. Baselines
We researched some models that exhibit comparatively strong performance in multi-domain text classification, using these models as baselines to compare against our own model, including CAN [
23], CRAL [
19], COBE [
12], MLP [
11], MAN [
11], CNN [
9], and BERT [
9]. It is worth noting that CNN and BERT are single-task learning methods for single-domain text classification. In order to demonstrate the effectiveness of our proposed multi-domain text classification model, we compare the results of single-domain text classification models as well, namely the CNN, BERT, and MLP models, to highlight the potential improvements in classification accuracy across multiple domains.
CAN proposes a conditional adversarial network, which constructs a conditional domain discriminator to model the difference between domain-shared features and domain-specific features and uses entropy conditioning to ensure the generalization of domain-shared features between different domains.
CRAL uses a double-adversarial network; that is, for each domain, two sets of models are used to predict the labels of samples in that domain. Each model includes a domain-shared feature extractor and a domain-specific feature extractor, and penalizes the difference in the prediction results of the two models for the same sample. In addition, CRAL uses virtual adversarial training with entropy minimization to further enhance the classification effect.
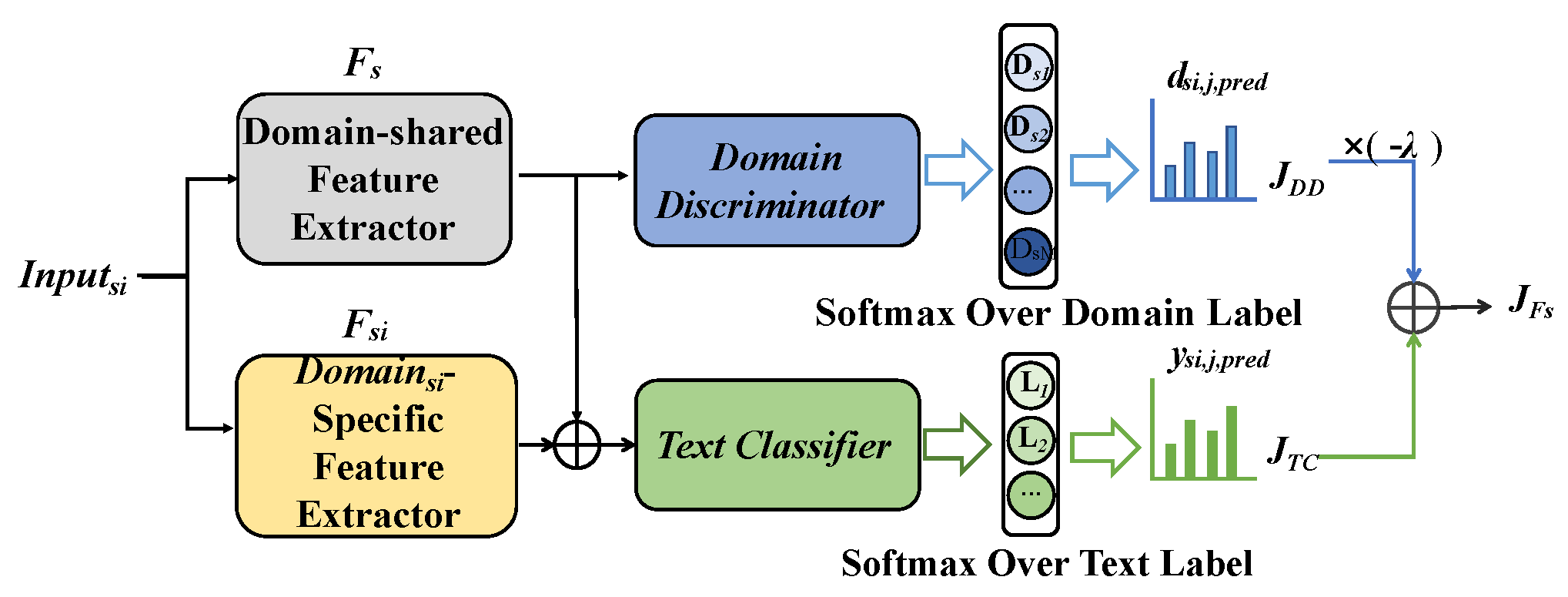
MAN consists of four components: a domain-shared feature extractor, domain-specific feature extractors, a domain discriminator, and a text classifier. The domain-shared feature extractor is responsible for extracting invariant features that are shared across domains. Each domain also has its own private feature extractor that captures domain-specific information. The domain discriminator is used to train the domain-shared feature extractor; its goal is to learn features that generalize well across domains, making it difficult for the domain discriminator to identify the source domain of a given sample. Finally, the text classifier takes as input the domain-shared features and domain-specific features of a sample and outputs its classification label.
COBE is a combination of Bert’s pre-training and contrastive learning. In the training stage, Bert is fine-tuned to obtain the representation of the sample, and then the K nearest neighbor algorithm is used to bring similar sentences closer and heterogeneous sentences farther away. After obtaining the representations of all training set samples and the fine-tuned Bert model in the training stage, the Bert model is used to obtain the representation of the test set samples in the testing phase. Note that one of the test set samples is , then retrieve the most similar 4 samples from all the training set samples, and then calculate the sum of similarities of the same sample separately. The label corresponding to the class with the highest sum of similarities, in the end, is the classification result of the test sample. Currently, COBE achieved very promising results on both datasets, second only to our model.
4.3. Implementation Details
In the training phase, we adopted techniques from the WGAN framework and separately trained the domain discriminator and text classifier for each batch. Initially, we fixed the domain-shared feature extractor, domain-specific feature extractors, text classifier, and then trained the domain discriminator for 100 iterations at each step. We then proceeded to freeze the domain discriminator’s parameters and trained the domain-shared and domain-specific feature extractors and text classifiers.
The domain discriminator and the other three modules were trained separately with the primary goal of improving the model’s stability and enhancing its generalization ability. The domain discriminator serves a crucial role in counteracting the effects of the classifier, and if both models were trained together, they could potentially interfere with each other and result in model instability. By training the domain discriminator separately from the domain-shared feature extractor and domain-specific feature extractor, we could reduce the difficulty of training the discriminator. Our experimental results have demonstrated the effectiveness of this training strategy, and we achieved remarkable results with only 15 epochs. Ultimately, this approach enhances generalization by allowing the discriminator to focus on learning the feature distribution of the data while the classifier can concentrate on mapping feature vectors to corresponding labels. Thus, the domain discriminator’s acquired characteristics can provide valuable assistance to the classifier in comprehending the data distribution, ultimately enhancing the classifier’s ability to generalize. The rationale behind training the domain discriminator one hundred times more often than the text classifier originates from the substantial disparities in data distribution present across various domains. Consequently, creating a resilient domain discriminator can aid the classifier in developing a superior understanding of domain-specific features and, in turn, elevate the efficacy of classification.
We used the bert-base-uncased as the domain-shared feature extractor in our approach. To implement domain-specific feature extraction, we utilized a CNN with an input layer, a single-layer convolutional layer, and a fully-connected layer as MAN [
11]. To achieve this, we utilized convolution kernels of 3 different sizes, constituting 200 kernels for each size, in the convolutional layer. Following the acquisition of characteristic features of various scales via convolutional kernels of diverse proportions, we performed global max pooling to compress the output tensors of 600 convolutions into a sole output layer containing 600 values, which we used for the fully connected layer. Additional information regarding our use of the CNN can be found in [
24]. Our domain discriminator and text classifier structures are relatively simple MLPs [
25].
4.4. Keyword Extraction Algorithms
The process of extracting and computing keyword weights through various methods results in differing outcomes. Different sets of keywords may be generated, and the weights assigned to each keyword may vary. To ascertain the effects of disparate keyword extraction methods, we have chosen to select 50 keywords and conduct experiments specifically aimed at comparing the performance of YAKE [
26], TextRank [
27], and KeyBERT [
28].
We chose to use these three keyword extraction algorithms for several reasons:
Wide Applicability. These algorithms have extensive applicability in both academic and industrial settings and are relatively easy to use.
High Processing Speed. All three algorithms are capable of processing large-scale text data and can complete the task of keyword extraction within a relatively short time frame.
High Accuracy of Results. These three algorithms are capable of extracting the most important keywords from text in practical applications with high accuracy.
Holistic Consideration of the Corpus. All three algorithms have the ability to model context, such as textRank and Yake, which can comprehensively consider the relationships between words in the corpus. KeyBert also utilizes language pre-training models to integrate contextual information.
High performance for long texts. All three algorithms have been found to be particularly effective in extracting keywords from long text.
In the following sections, we briefly introduce these three keyword extraction algorithms.
YAKE [
26]: The preprocessing of the text by YAKE mainly includes the following steps:
Split the text into sentences.
Split the sentence into chunks based on punctuation marks.
Split chunks into a series of tokens.
Tag the tokens in tokens(including Digit, Number, unparsable Content, Acronyms, Uppercase, and Parsable Content), convert the letters of tokens into lowercase letters, and judge whether they are stop words.
During feature extraction and weighting calculation stages, the YAKE algorithm first calculates various properties of each 1-gram term, such as term frequency, index of the sentence in the text that contains this term, number of times it appears as an abbreviation, and number of times it appears as a capitalized non-first word. It also calculates the co-occurrence probability of pairs of terms within a certain window size, creating a large co-occurrence matrix. Using this information, YAKE can construct more complex features and weight scores for each word and use them as the weight for each candidate keyword.
During the keyword extraction stage, the algorithm utilizes the previously calculated keyword weight to extract the top-ranking words as the final keywords.
TextRank [
27]: The TextRank algorithm is a graph-based text summarization algorithm. It uses the PageRank [
29] algorithm in graph theory to calculate the weights of keywords and sentences in the text and sorts them according to the weights to generate text summaries.
The algorithm steps are as follows:
The input text is segmented and part-of-speech tagged, and then an undirected graph is constructed based on the co-occurrence relationship between words. Each node represents a word, and the edges represent the co-occurrence relationship between words.
Calculate the weight of the nodes in the graph. The weight of a node is determined by the weight of the node and its surrounding nodes.
The nodes are sorted, and the sorting is based on the weight of the nodes. Top-ranked nodes represent important words.
Sentences corresponding to the top-ranked nodes are extracted to generate text summaries.
The advantage of TextRank is that it does not require prior knowledge and can automatically extract important information from the text, so it is widely used in tasks such as text summarization and keyword extraction.
KeyBERT [
28]: The KeyBERT algorithm is a keyword and phrase extraction algorithm based on the BERT pre-training model. It uses the BERT model to calculate the semantic similarity between words or phrases and the original text and sorts them according to the similarity to extract keywords in the text and phrases.
The algorithm steps are as follows:
Enter the text from which keywords and phrases need to be extracted.
Encode text into a sequence of word vectors using a BERT model.
Segments the input text, treating each paragraph as a separate document.
Cluster the sequence of word vectors in each document to generate several representative vectors, each corresponding to a cluster.
For each cluster, calculate the cosine similarity with each word vector in the original text so as to obtain a vector of similarity vectors with each word in the text.
The similarity vectors are sorted, and the top k words or phrases are taken out as keywords and phrases.
The advantage of the KeyBERT algorithm is that it can process long texts, and at the same time, it can take into account the semantic similarity of words or phrases in the entire text, thereby improving the accuracy of keyword and phrase extraction. It has been widely used in natural language processing, information retrieval, and other fields.
4.5. Main Results
We compared the performance of KCL and other baseline methods on the FDU-MTL dataset and the Amazon-review dataset, as shown in
Table 3 and
Table 4 with our experimental results. For consistency with previous multi-domain text classification experiments, our evaluation metric is the classification accuracy on the test set. The “KCL-XXX” column denotes the utilization of the XXX method for keyword extraction. KCL-r denotes that the order of domains is random. KCL-Y, KCL-TR, and KCL-KB correspond to the use of YAKE, TextRank, and KeyBERT, respectively, as the keyword extraction algorithms in our analysis. We followed the approach taken by MAN [
11] for the division of our experimental data, using 5-fold cross-validation to split the FDU-MTL and Amazon review datasets into training, validation, and testing sets in a 3:1:1 ratio. To obtain the final experimental results, we computed the average testing accuracy over 5-fold cross-validation runs and repeated this process 10 times to obtain the final outcome of our experiment. The experimental data of CNN, MLP, and MAN were obtained from MAN [
11]. Likewise, the experimental data of Bert and CRAL were obtained from CRAL [
19]. The experimental data for CAN were obtained from CAN [
23], while the experimental data for COBE were obtained from COBE [
12].
After reviewing
Table 3 and
Table 4, we can conclude that our method outperforms other baselines in 14 out of the 16 domains included in the FDU-MTL dataset. As for the Amazon-review dataset, which contains merely 4 domains, our method demonstrates significant superiority over other baselines across all of them. Among these baselines, COBE and CRAL were state-of-the-art in the field of multi-domain text classification on FDU-MTL and Amazon review datasets, respectively, before we proposed our method. In the FDU-MTL dataset, our method outperforms COBE by 1.13 points in average accuracy when using KeyBERT as the keyword extraction algorithm. Similarly, in the Amazon review dataset, our method outperforms CRAL by 3.27 points in average accuracy when employing TextRank as the keyword extraction algorithm.
Table 3 indicates that utilizing KeyBERT as the keyword extraction algorithm yields the most successful results on the FDU-MTL dataset, surpassing the random order by 1.55 points on average accuracy. The order of the domains of the FDU-MTL dataset is as follows: [Camera, Health, Kitchen, Software, MR, Apparel, Books, Magazine, Video, DVD, Music, Baby, Sports, IMDB, Toys, Electronics]. In addition,
Table 4 reveals that leveraging TextRank as the keyword extraction algorithm proves to be most effective on the Amazon review dataset, surpassing the random order by 1.79 points in average accuracy. The current ranking of the Amazon review dataset is as follows: [DVD, Books, Electronics, Kitchen]. Furthermore, we can find that our KCL excels in each domain relative to those single-task learning approaches.
4.6. Analysis
4.6.1. The Drawbacks of Previous Methods
In this subsection, we discuss two typical and effective models to illustrate the shortcomings of previous methods.
Firstly, CRAL employs adversarial networks for multi-domain text classification and has achieved good results. Compared with earlier models that used only one adversarial network, such as CAN and MAN, CRAL uses two adversarial networks for each domain. However, this method, which relies on stacking network models and parameters, is relatively dependent on computational resources and has a complex network structure. A simpler alternative would be to adjust the training order after considering the difficulty of domain feature extraction.
Secondly, COBE, which utilizes pre-trained models, contrastive learning, and the K-nearest neighbor algorithm, has achieved good results on the FDU-MTL dataset. However, during training, since the order of the training data was not taken into account, the pre-trained model may have processed domain texts with difficult feature extraction at the beginning. A more accurate approach would be to first arrange the training order of domain texts from easy to difficult and then extract more precise features for the domains with challenging feature extraction, resulting in more accurate standards.
4.6.2. Different Performance on Different Datasets
Different models show varying performances on Amazon review and FDU-MTL datasets, and we believe this is related to the characteristics of the keyword extraction algorithm. KeyBERT excels at extracting keywords from shorter texts, whereas the TextRank algorithm is good at extracting keywords from longer texts. To extract keywords from a specific domain, we aggregate all samples within that domain and apply the keyword extraction algorithm to the resulting whole. The average length of a domain in the FDU-MTL dataset is 208,865, whereas, in the Amazon review dataset, the average length is 221,889, exceeding that of the FDU-MTL dataset by over 20,000 words. Consequently, TextRank, which is better suited for processing longer texts, accurately extracts keywords and weights from the Amazon review dataset, resulting in superior performance on the Amazon review dataset.
4.6.3. The Number of Keywords
To determine the obviousness of domain-specific features, varying quantities of keywords can yield different ranking outcomes when considering the cumulative weighting factors. This is due to the possibility that a domain’s top N1 keywords may carry a greater total weight than any other domain. However, the combined weight of a domain’s first N2 (where N2 > N1) keywords may still be less than that of any other domain. Accordingly, we conducted experiments in this section to investigate how different numbers of keywords included in weight calculation impacted accuracy.
We conducted experiments using 20, 30, 40, 50, 60, 70, and 80 keywords to test their effects. The classification accuracy and average accuracy per domain are displayed in
Figure 5 and
Figure 6, respectively. Based on our findings, we observed that the most effective number of keywords was 50.
Based on
Figure 5a–d, it can be observed that when the keyword count is 50, the classification results of 15 out of 16 domains of the FDU-MTL dataset, except for the IMDB dataset perform the best. On the other hand, when the keyword count is too high or too low, the average classification accuracy even fails to match the COBE baseline. We attribute this to the fact that with too few keywords, the weights of the keywords differ only slightly from each other, mimicking random order and subsequently rendering it difficult to extract distinguishing features for each domain. Conversely, when there are too many keywords, irrelevant and insignificant keywords contribute to the weight computations, thus causing erroneous ordering.
As for the Amazon-review dataset, while there are two domains that achieve the best classification accuracy at both 40 and 50 keywords individually, the average classification accuracy across all domains is slightly higher for 50 keywords than for 40 keywords. Therefore, we still consider 50 keywords to be the optimal choice for ordering in this dataset.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}