
Linguistic Features and Bi-LSTM for Identification of Fake News

 ,
, 
Abstract
:1. Introduction
1.1. Contribution of the Article
- Statistical Word Embedding over Linguistic Features via Deep Learning (SWELDL Fake): The proposed model utilizes statistical word embedding techniques combined with deep learning to enhance the classification accuracy of fake news. This method proposes that linguistic characteristics be utilized to generate word embeddings, which are then integrated into a deep learning architecture to improve the classification model’s performance.
- The proposed model incorporates principal component analysis on the textual representations of fake news. PCA is a dimensionality-reduction technique that identifies the data’s most significant features or components.
- The proposed method is evaluated and compared with existing state-of-the-art techniques in fake news detection. By conducting such comparisons, the research aims to demonstrate the effectiveness and superiority of the proposed model in terms of classification accuracy.
1.2. Organization of the Article
2. Related Work
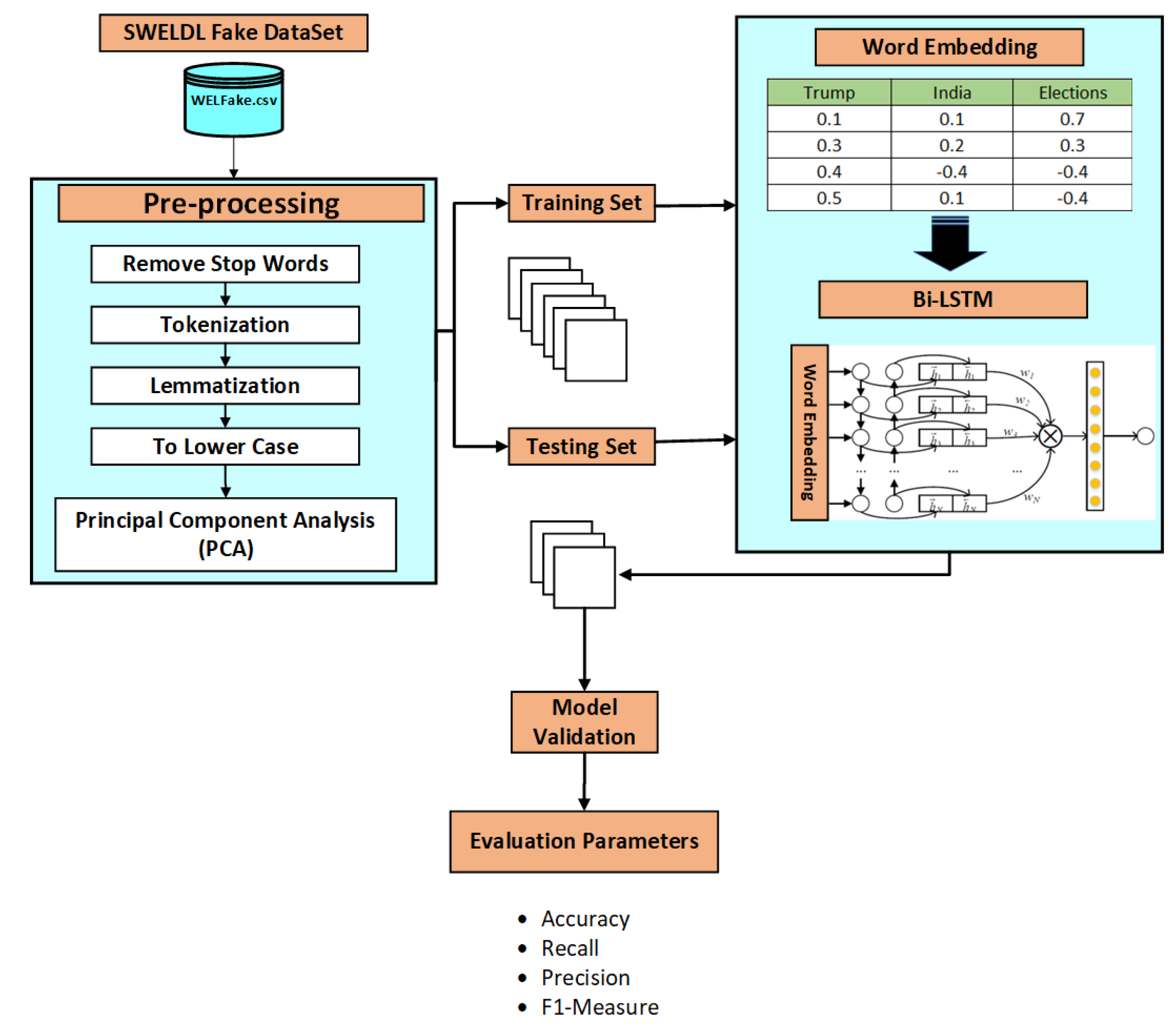
3. Proposed Model
3.1. Pre-Processing
3.2. Principal Component Analysis (PCA)
3.3. Embedding Layers
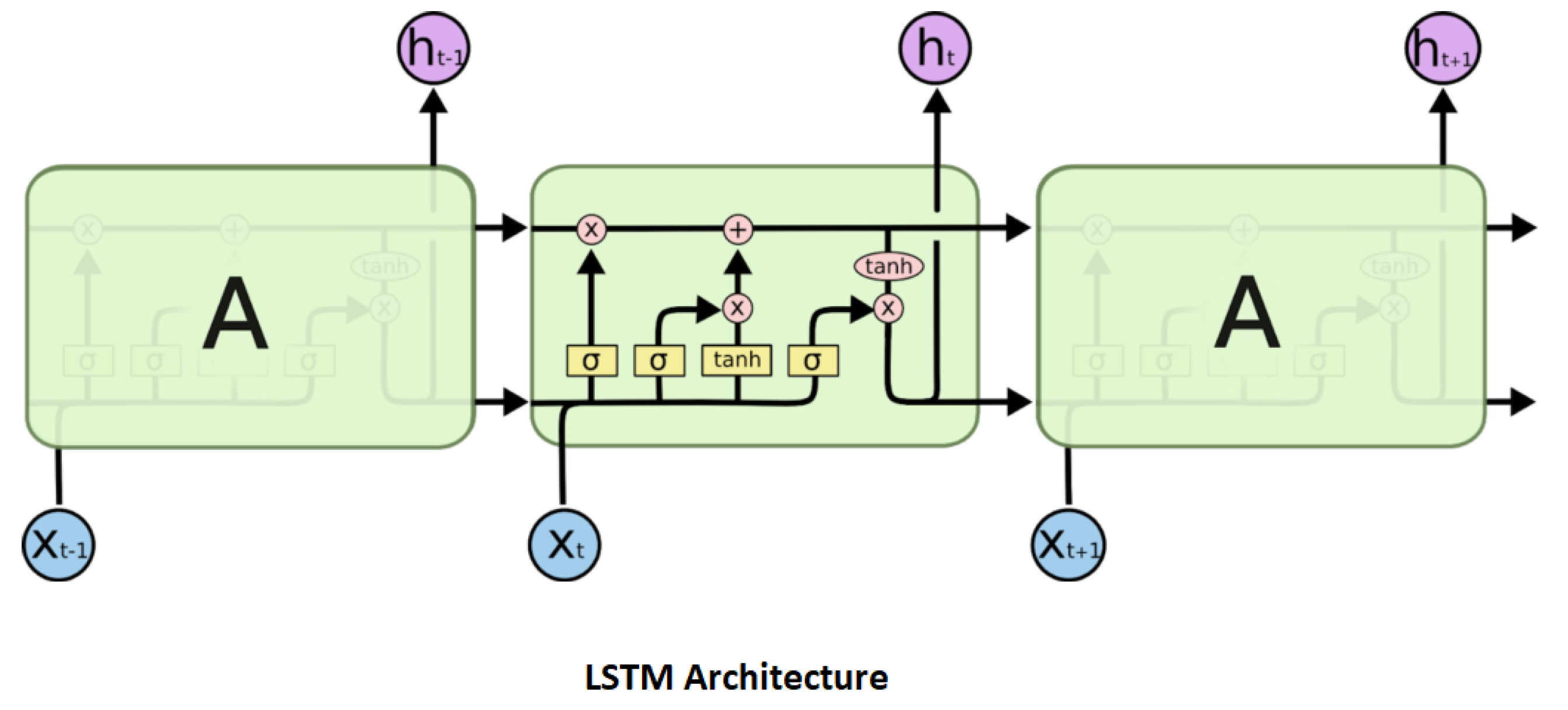
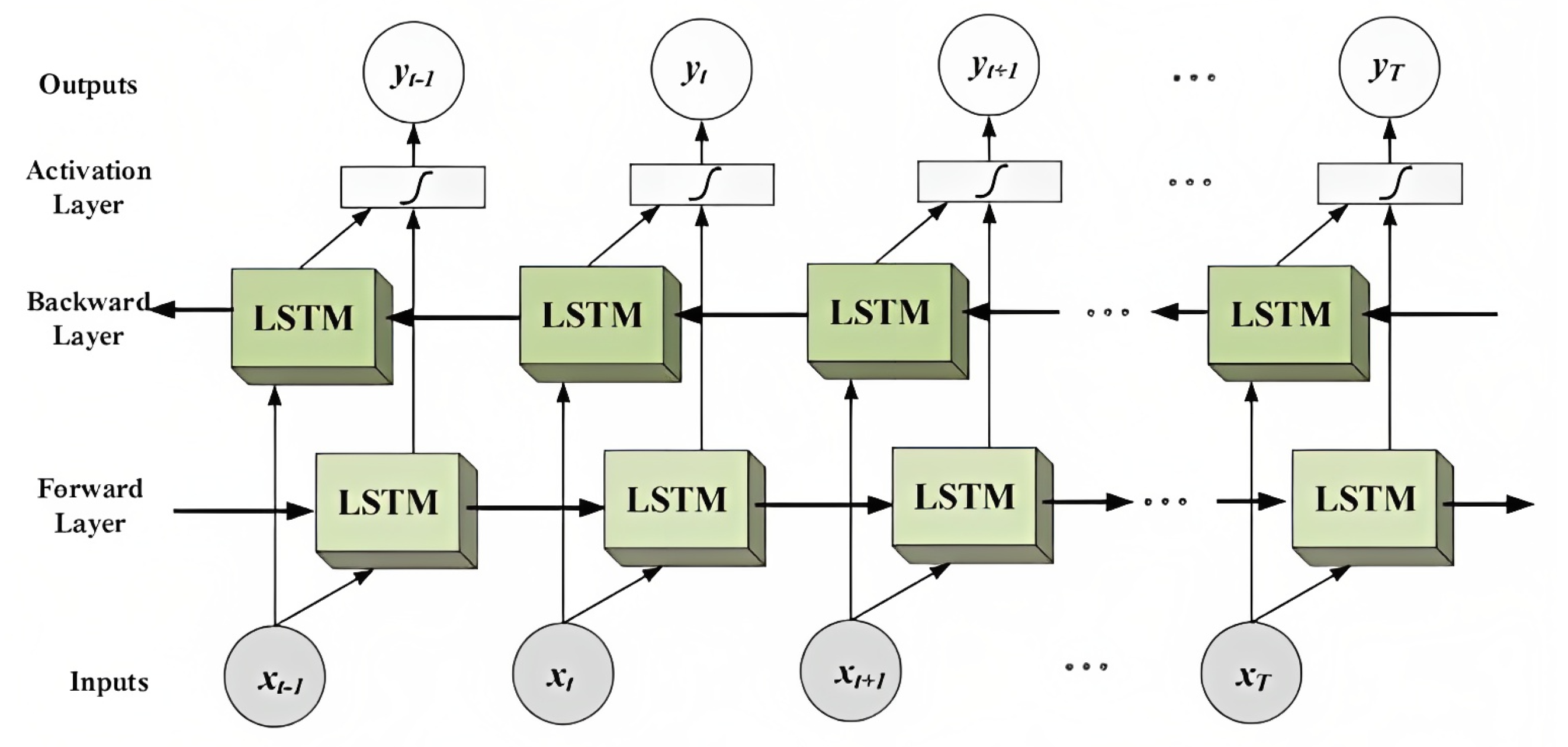
3.4. Bidirectional Long Short-Term Memory (LSTM)
- Cell State:
- Input Gate:
- Output Gate:
- Hidden State:
- Forgot Gate:
3.5. Evaluation Metrics
4. Simulation Results and Discussion
4.1. Dataset Description
- The readability index measures the text’s complexity (readability difficulties) using word length, syllable count and sentence length.
- Emotions, actions, persona and cognition are all described by psycho-linguistic characteristics.
- Stylistic elements describe a sentence’s style.
- User credibility characteristics explain the information provided by users.
- Quantity characteristics describe information in phrases.
4.2. Data Analysis
4.3. Evaluation of Proposed Model
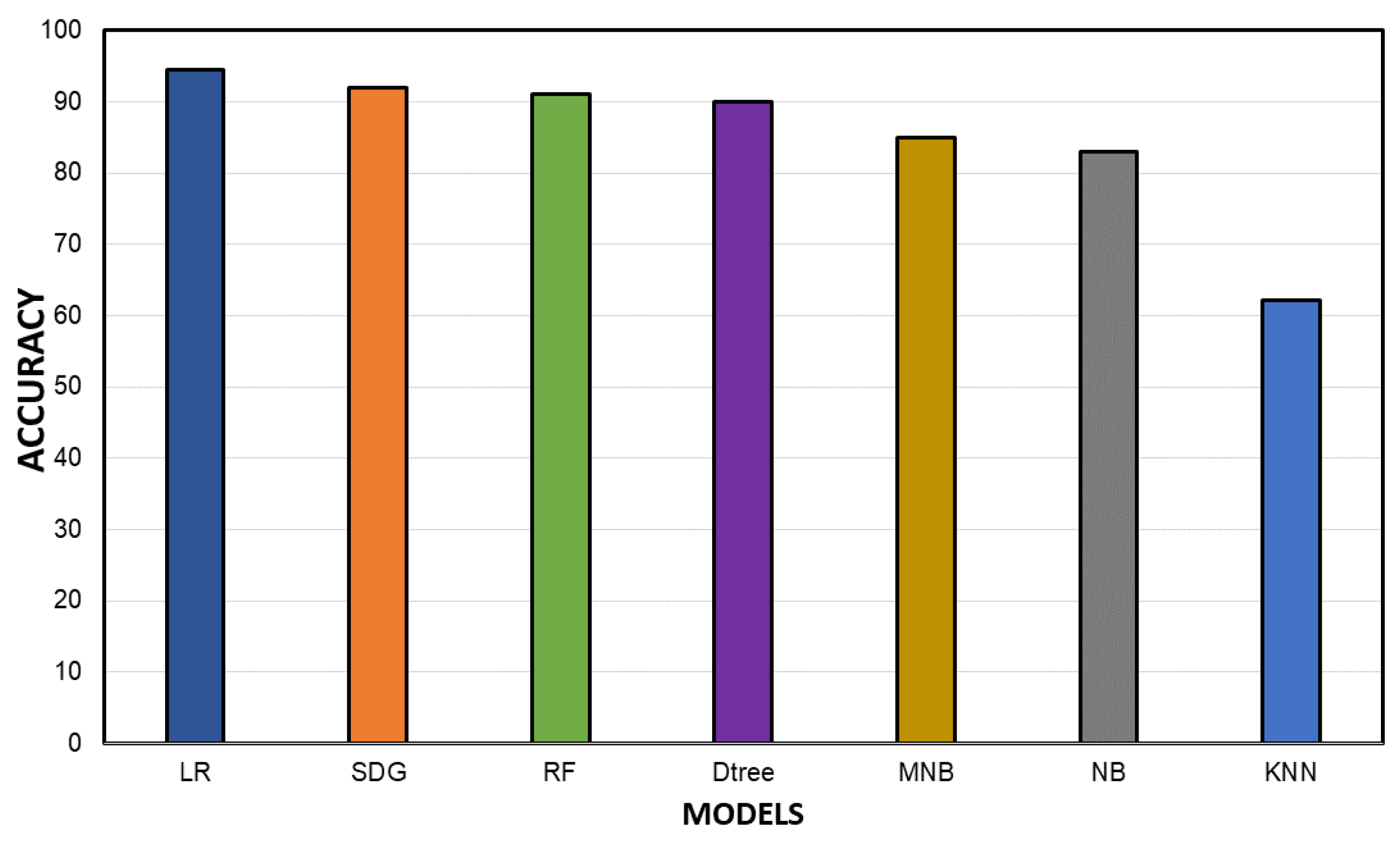
4.4. Machine Learning Algorithms’ Accuracy
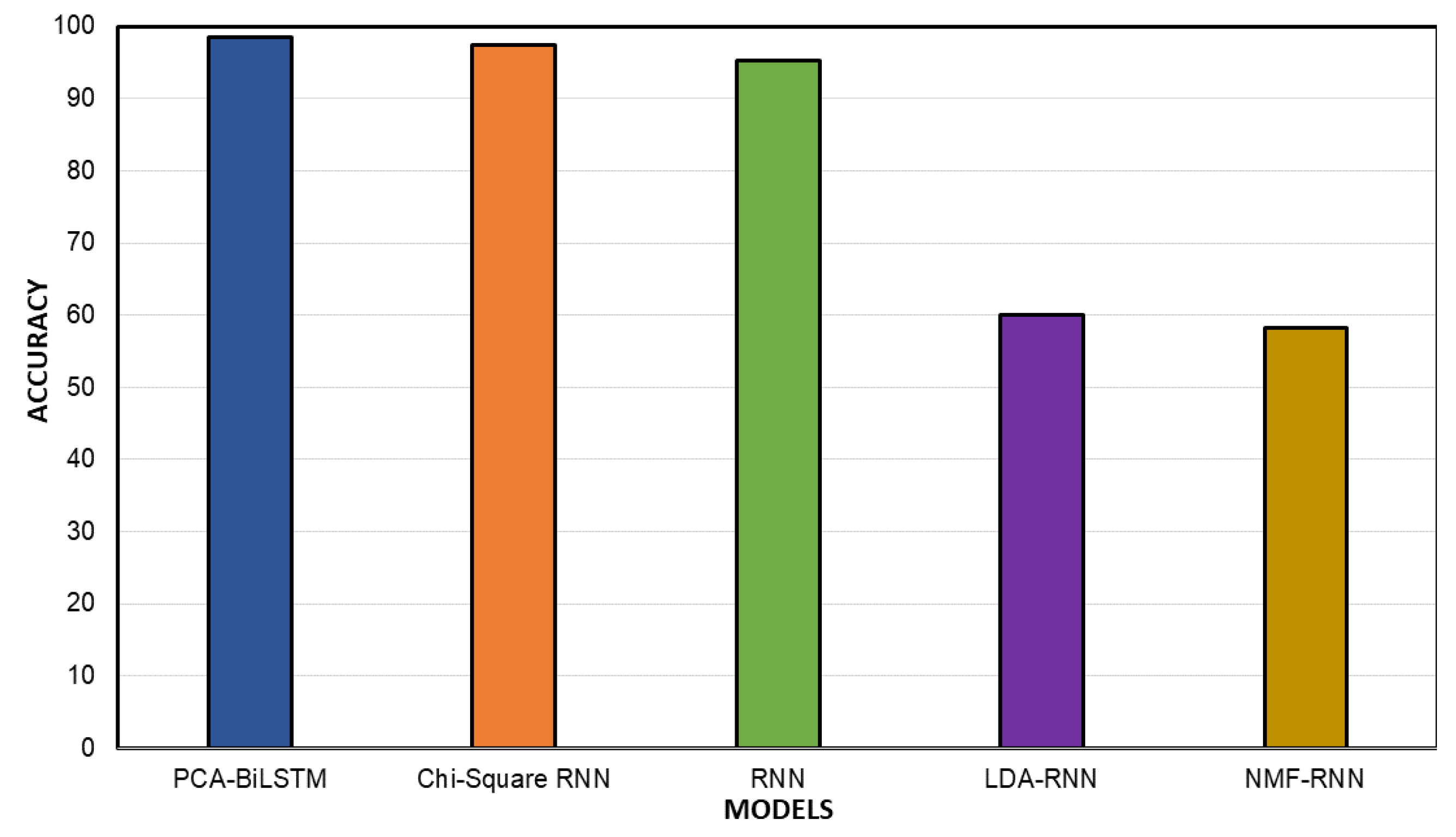
4.5. Deep Learning Algorithms’ Accuracy
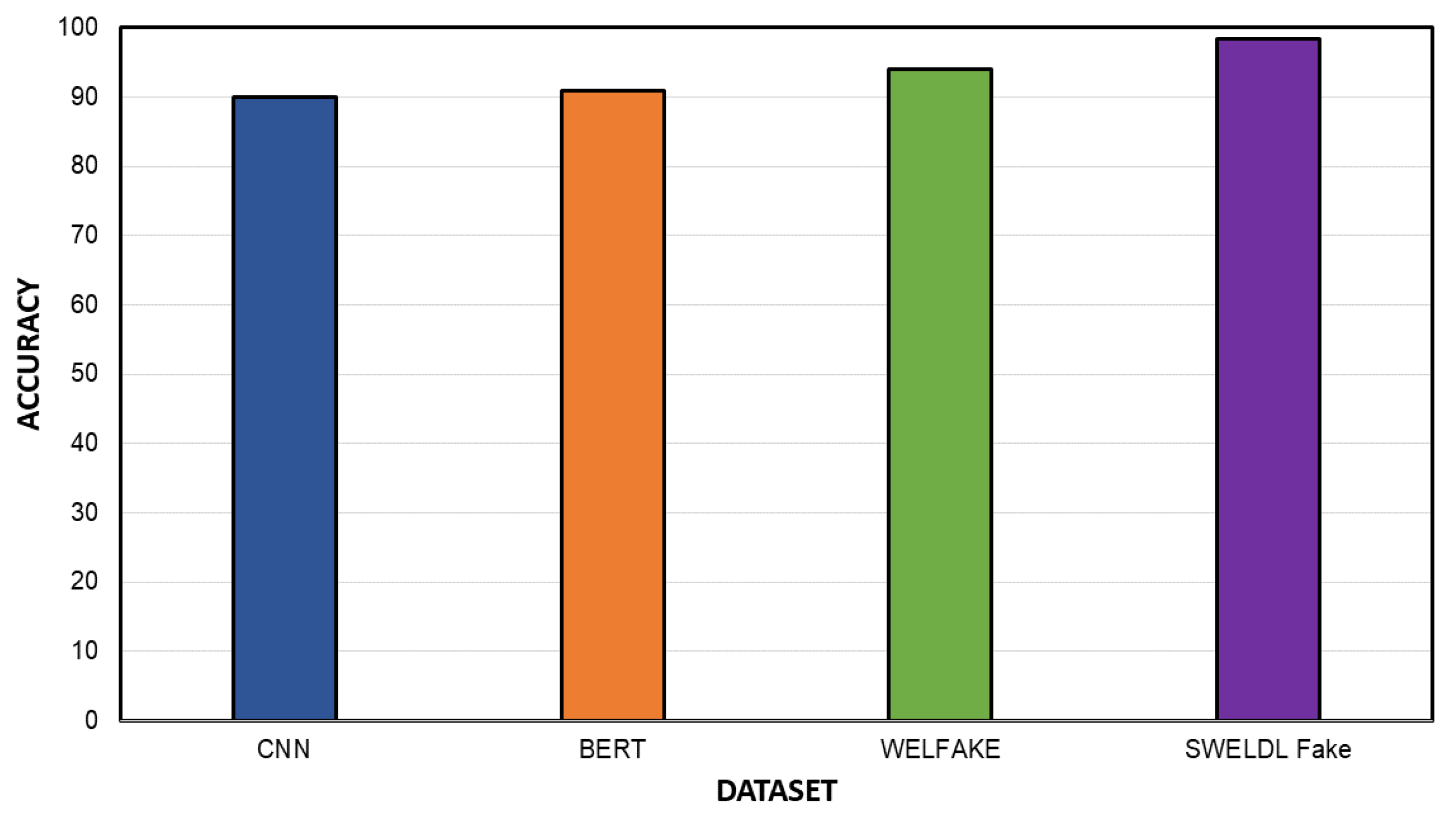
4.6. Comparative Text Classification
4.7. Comparative Analysis
4.8. Discussion on Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dixon, S. Number of monthly active Facebook users worldwide as of 2nd quarter 2022. Posjećeno 2022, 9, 2022. [Google Scholar]
- Siddiqui, S.; Singh, T. Social media its impact with positive and negative aspects. Int. J. Comput. Appl. Technol. Res. 2016, 5, 71–75. [Google Scholar] [CrossRef]
- Schiavone, J.; Lynch, J. Fake Financial News Is a Real Threat to Majority of Americans: New AICPA Survey. 2017. Available online: https://www.aicpa.org/press/pressreleases/2017/fake-financial-news-is-a-real-threatto-majority-of-americans-newaicpa-survey (accessed on 21 December 2022).
- Zhou, X.; Jain, A.; Phoha, V.V.; Zafarani, R. Fake news early detection: A theory-driven model. Digit. Threat. Res. Pract. 2020, 1, 1–25. [Google Scholar] [CrossRef]
- Shearer, E.; Gottfried, J. News use across social media platforms 2017. 2017. [Google Scholar]
- Fatima, M.; Ghauri, S.; Mohammad, N.; Adeel, H.; Sarfraz, M. Machine Learning for Masked Face Recognition in COVID-19 Pandemic Situation. Math. Model. Eng. Probl. 2022, 9, 283–289. [Google Scholar] [CrossRef]
- Shah, S.I.H.; Alam, S.; Ghauri, S.A.; Hussain, A.; Ansari, F.A. A novel hybrid cuckoo search-extreme learning machine approach for modulation classification. IEEE Access 2019, 7, 90525–90537. [Google Scholar] [CrossRef]
- Ghauri, S.A. KNN based classification of digital modulated signals. IIUM Eng. J. 2016, 17, 71–82. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.F.; Cha, M. Detecting rumors from microblogs with recurrent neural networks. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Ozbay, F.A.; Alatas, B. Fake news detection within online social media using supervised artificial intelligence algorithms. Phys. A Stat. Mech. Its Appl. 2020, 540, 123174. [Google Scholar] [CrossRef]
- Kaliyar, R.K.; Goswami, A.; Narang, P. Multiclass fake news detection using ensemble machine learning. In Proceedings of the 2019 IEEE 9th International Conference on Advanced Computing (IACC), Tiruchirappalli, India, 13–14 December 2019; pp. 103–107. [Google Scholar]
- Gilda, S. Notice of Violation of IEEE Publication Principles: Evaluating machine learning algorithms for fake news detection. In Proceedings of the 2017 IEEE 15th Student Conference on Research and Development (SCOReD), Wilayah Persekutuan Putrajaya, Malaysia, 13–14 December 2017; pp. 110–115. [Google Scholar]
- Della Vedova, M.L.; Tacchini, E.; Moret, S.; Ballarin, G.; DiPierro, M.; De Alfaro, L. Automatic online fake news detection combining content and social signals. In Proceedings of the 2018 22nd Conference of Open Innovations Association (FRUCT), Jyvaskyla, Finland, 15–18 May 2018; pp. 272–279. [Google Scholar]
- Shabani, S.; Sokhn, M. Hybrid machine-crowd approach for fake news detection. In Proceedings of the 2018 IEEE 4th International Conference on Collaboration and Internet Computing (CIC), Philadelphia, PA, USA, 18–20 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 299–306. [Google Scholar]
- Faustini, P.H.A.; Covoes, T.F. Fake news detection in multiple platforms and languages. Expert Syst. Appl. 2020, 158, 113503. [Google Scholar] [CrossRef]
- Jiang, T.; Li, J.P.; Haq, A.U.; Saboor, A.; Ali, A. A novel stacking approach for accurate detection of fake news. IEEE Access 2021, 9, 22626–22639. [Google Scholar] [CrossRef]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on twitter. In Proceedings of the 20th International World Wide Web Conference, Hyderabad, India, 28 March–1 April 2011; pp. 675–684. [Google Scholar]
- Verma, P.K.; Agrawal, P.; Amorim, I.; Prodan, R. WELFake: Word embedding over linguistic features for fake news detection. IEEE Trans. Comput. Soc. Syst. 2021, 8, 881–893. [Google Scholar] [CrossRef]
- Liu, P.; Qian, W.; Xu, D.; Ren, B.; Cao, J. Multi-Modal Fake News Detection via Bridging the Gap between Modals. Entropy 2023, 25, 614. [Google Scholar] [CrossRef]
- Truică, C.O.; Apostol, E.S. It’s All in the Embedding! Fake News Detection Using Document Embeddings. Mathematics 2023, 11, 508. [Google Scholar] [CrossRef]
- Mayopu, R.G.; Wang, Y.Y.; Chen, L.S. Analyzing Online Fake News Using Latent Semantic Analysis: Case of USA Election Campaign. Big Data Cogn. Comput. 2023, 7, 81. [Google Scholar] [CrossRef]
- Dhiman, P.; Kaur, A.; Iwendi, C.; Mohan, S.K. A scientometric analysis of deep learning approaches for detecting fake news. Electronics 2023, 12, 948. [Google Scholar] [CrossRef]
- Nadeem, M.I.; Ahmed, K.; Li, D.; Zheng, Z.; Alkahtani, H.K.; Mostafa, S.M.; Mamyrbayev, O.; Abdel Hameed, H. EFND: A Semantic, Visual and Socially Augmented Deep Framework for Extreme Fake News Detection. Sustainability 2023, 15, 133. [Google Scholar] [CrossRef]
- Umer, M.; Imtiaz, Z.; Ullah, S.; Mehmood, A.; Choi, G.S.; On, B.W. Fake news stance detection using deep learning architecture (CNN-LSTM). IEEE Access 2020, 8, 156695–156706. [Google Scholar] [CrossRef]
- Ajao, O.; Bhowmik, D.; Zargari, S. Fake news identification on twitter with hybrid cnn and rnn models. In Proceedings of the 9th International Conference on Social Media and Society, Copenhagen, Denmark, 18–20 July 2018; pp. 226–230. [Google Scholar]
- Roy, A.; Basak, K.; Ekbal, A.; Bhattacharyya, P. A deep ensemble framework for fake news detection and classification. arXiv 2018, arXiv:1811.04670. [Google Scholar]
- Monti, F.; Frasca, F.; Eynard, D.; Mannion, D.; Bronstein, M.M. Fake news detection on social media using geometric deep learning. arXiv 2019, arXiv:1902.06673. [Google Scholar]
- Reis, J.C.; Correia, A.; Murai, F.; Veloso, A.; Benevenuto, F. Supervised learning for fake news detection. IEEE Intell. Syst. 2019, 34, 76–81. [Google Scholar] [CrossRef]
- Yuan, C.; Ma, Q.; Zhou, W.; Han, J.; Hu, S. Early detection of fake news by utilizing the credibility of news, publishers and users based on weakly supervised learning. arXiv 2020, arXiv:2012.04233. [Google Scholar]
- Liu, Y.; Wu, Y.F.B. Fned: A deep network for fake news early detection on social media. ACM Trans. Inf. Syst. 2020, 38, 1–33. [Google Scholar] [CrossRef]
- Li, M.; Clinton, G.; Miao, Y.; Gao, F. Short text classification via knowledge powered attention with similarity matrix based CNN. arXiv 2020, arXiv:2002.03350. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, 18–20 October 2019; Proceedings 18. Springer: Berlin/Heidelberg, Germany, 2019; pp. 194–206. [Google Scholar]
- Alrubaian, M.; Al-Qurishi, M.; Hassan, M.M.; Alamri, A. A credibility analysis system for assessing information on twitter. IEEE Trans. Dependable Secur. Comput. 2016, 15, 661–674. [Google Scholar] [CrossRef]
- Verma, Y. Complete Guide To Bidirectional LSTM (With Python Codes). 2021. Available online: https://analyticsindiamag.com/complete-guide-to-bidirectional-lstm-with-python-codes/ (accessed on 9 February 2023).
- Gravanis, G.; Vakali, A.; Diamantaras, K.; Karadais, P. Behind the cues: A benchmarking study for fake news detection. Expert Syst. Appl. 2019, 128, 201–213. [Google Scholar] [CrossRef]
- Shu, K.; Mahudeswaran, D.; Wang, S.; Lee, D.; Liu, H. Fakenewsnet: A data repository with news content, social context and spatiotemporal information for studying fake news on social media. Big Data 2020, 8, 171–188. [Google Scholar] [CrossRef]
- Ahmed, H.; Traore, I.; Saad, S. Detection of online fake news using n-gram analysis and machine learning techniques. In Proceedings of the Intelligent, Secure and Dependable Systems in Distributed and Cloud Environments: First International Conference, ISDDC 2017, Vancouver, BC, Canada, 26–28 October 2017; Proceedings 1. Springer: Berlin/Heidelberg, Germany, 2017; pp. 127–138. [Google Scholar]
- Vicario, M.D.; Quattrociocchi, W.; Scala, A.; Zollo, F. Polarization and fake news: Early warning of potential misinformation targets. ACM Trans. Web 2019, 13, 1–22. [Google Scholar] [CrossRef]
- Verma, P.K.; Agrawal, P.; Prodan, R. WELFake Dataset for Fake News Detection in Text Data. 2021. Available online: https://zenodo.org/record/4561253 (accessed on 25 June 2023).
- Horne, B.; Adali, S. This just in: Fake news packs a lot in title, uses simpler, repetitive content in text body, more similar to satire than real news. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 759–766. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Methodology | Dataset | Limitations |
|---|---|---|---|
| [10] | DT, LR, RF, CNN + LSTM | BuzzFeed, ISOT, Politics News data | High time complexity |
| [11] | RF, MN-Naive Bayes, GB, DT, LR & SVM | Kaggle Fakenews Dataset | Low accuracy |
| [12] | DT, GB, SVM, RF, SGD. | - | Focused on pre-processing techniques. |
| [24] | CNN | Fake news Challenge Dataset | High time complexity |
| [25] | CNN + Bi-LSTM | 1356 news articles | Comparatively low accuracy |
| [26] | LSTM + CNN | 58,000 tweets | Low accuracy |
| [9] | CNN + Bi-LSTM | Liar Dataset | Low accuracy |
| [27] | LSTM, tah-RNN | Twitter and Weibo micro blogs. | Higher time complexity |
| [28] | Graph CNN | - | Only uses content data |
| [13] | SVM, K-NN, RF, Naive Bayes and XG-Boost | 2282 BuzzFeed news articles | Only identified important features. |
| [14] | LR | Real-world dataset | Low accuracy & Small dataset |
| [15] | LR, SVM, RF, GB, Neural Networks. | Querying google | High computational cost. |
| [16] | Naive Bayes (NB), KNN, SVM, RF | Btvlifestyl, FakeOrRealNews, FakeNewsData1, FakeBrCorpus, TwitterBr. | Only use news content features. |
| [29] | CNN, LSTM, GRU, DT, RF, KNN, LR, SVM | ISOT, KDnugget | High computational complexity |
| [30] | CNN with SMAN attention mechanism | Weibo dataset, Twitter dataset (Tweeter15 & Tweeter 16) | More time complexity |
| [31] | CNN + PU learning framework | Weibo dataset, Twitter dataset (Tweeter15 & Tweeter 16) | Low accuracy |
| [32] | CNN | WELFAKE dataset | Low accuracy |
| [33] | BERT | WELFAKE dataset | Low accuracy |
| [17] | NB, DT, RF | 489,330 Twitter accounts | Low accuracy |
| [18] | Model classification using a credibility | Twitter dataset | Low F1 score |
| LSTM Equation Symbols | Symbol Description |
|---|---|
| FG | |
| LS | |
| OG | |
| OL | |
| HL | |
| IG | |
| PCOS | |
| OS | |
| T | NOI |
| ESWF | |
| ISWF | |
| WF | |
| IS | |
| SWF | |
| ISIC | |
| , | SIC |
| ICES |
| Dataset | Real News | Fake News |
|---|---|---|
| McIntire | 3171 | 3164 |
| Reuters | 21,417 | 23,481 |
| BuzzFeed Political | 53 | 48 |
| SWELDL Fake | 35,028 | 37,106 |
| Linguistic Features | Benjamin Political News [35] | Behind the Cues [36] | Reuters [37] | Fake News Net [38] | Polarization & Fake News [39] | SWELDL Fake Dataset [40] |
|---|---|---|---|---|---|---|
| Readability index | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Psycho-linguistic | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ |
| Stylistic features | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ |
| User credibility | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ |
| Quantity features | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Technique | Feature |
|---|---|
| DL Techniques | Word2Vec |
| Tokenize | |
| BOW | |
| PCA | |
| ML Techniques | PCA |
| TF-IDF | |
| Count Vectorize |
| SWELDL Fake Dataset | |
|---|---|
| Accuracy | 98.52% |
| Precision | 98.63% |
| Recall | 98.89% |
| F1-Score | 98.75% |
| Parameter | [37] | [38] | [36] | WELFake [18] | Proposed Model (SWELDL Fake) |
|---|---|---|---|---|---|
| Dataset | Kaggle | 1. Politifact 2. Buzzfeed | 1. Kaggle 2. Buzzfeed 3. Politifact 4. McIntire 5. WELFake | 1. Kaggle 2. Buzzfeed 3. Reuters 4. McIntire 5. WELFake | 1. Kaggle 2. Buzzfeed 3. Reuters 4. McIntire 5. WELFake |
| Number of news article | 25,200 | 1. 240 2. 182 | 1. 23,340 2. 240 3. 182 4. 6310 5. 3404 | 1. 20,800 2. 101 3. 44,898 4. 6335 5. 72.134 | 1. 20,800 2. 101 3. 44,898 4. 6335 5. 72.134 |
| Linguistic features | No | Yes | Yes | Yes | Yes |
| WE | TF-IDF | No | Word2Vec | CV | Word2Vec |
| Accuracy | 92% | 87.8% | 95.0% | 96.73% | 98.52% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, A.A.; Latif, S.; Ghauri, S.A.; Song, O.-Y.; Abbasi, A.A.; Malik, A.J. Linguistic Features and Bi-LSTM for Identification of Fake News. Electronics 2023, 12, 2942. https://doi.org/10.3390/electronics12132942
Ali AA, Latif S, Ghauri SA, Song O-Y, Abbasi AA, Malik AJ. Linguistic Features and Bi-LSTM for Identification of Fake News. Electronics. 2023; 12(13):2942. https://doi.org/10.3390/electronics12132942
Chicago/Turabian StyleAli, Attar Ahmed, Shahzad Latif, Sajjad A. Ghauri, Oh-Young Song, Aaqif Afzaal Abbasi, and Arif Jamal Malik. 2023. "Linguistic Features and Bi-LSTM for Identification of Fake News" Electronics 12, no. 13: 2942. https://doi.org/10.3390/electronics12132942