1. Introduction
Currently, the development of unsupervised vehicle Re-Identification (Re-ID) algorithms [
1,
2,
3,
4] for large-scale system monitoring systems [
5,
6] is predominantly reliant on clustering of unlabeled target domain data and knowledge transfer from labeled source domain data. However, the absence of labeled information to guide the clustering process poses a significant challenge in enabling the model to learn discriminative features. To address this limitation, unsupervised domain adaptation methods have been proposed. These methods typically involve pre-training the model using source domain data and subsequently fine-tuning the pre-trained model on the target domain. Despite the advancements brought about by unsupervised domain adaptation, the performance of vehicle Re-ID still falls short of that achieved by supervised learning methods [
7,
8,
9]. This performance gap can be attributed to the existing domain gap [
10] between the source and target domains, as well as the reliance on global features for pseudo-label assignment during fine-tuning. Therefore, there is a need for further refinement of unsupervised vehicle Re-ID algorithms to bridge the performance gap and enhance the accuracy of vehicle Re-ID in large-scale system monitoring scenarios.
Many existing re-identification methods aim to reduce the domain gap between different datasets by utilizing generative adversarial networks. During the fine-tuning stage, some methods [
11,
12,
13] incorporate intermediate-domain data or style transfer data to minimize the difference in data distribution between the pre-training dataset and the fine-tuning dataset. However, the introduction of source domain data during the fine-tuning stage can interfere with the model’s ability to learn target domain information. To overcome this challenge, some methods [
14] attempt to introduce style transfer data during the pre-training stage to obtain a well-initialized pre-trained model. However, these methods often assign hard labels from the source domain data directly to the style transfer data, resulting in a mismatch between the style transfer data and the hard labels. In this paper, we propose the cross-style semi-supervised pre-training (CSP) module, which adopts a semi-supervised approach that leverages both labeled source domain data and unlabeled style fusion data to alleviate the domain gap and enhance the model’s generalization ability. During the semi-supervised learning process, the CSP module generates soft labels for the style transfer data, allowing for better learning of the distribution of the style transfer data and effective mining of the target domain information embedded in the style transfer images.
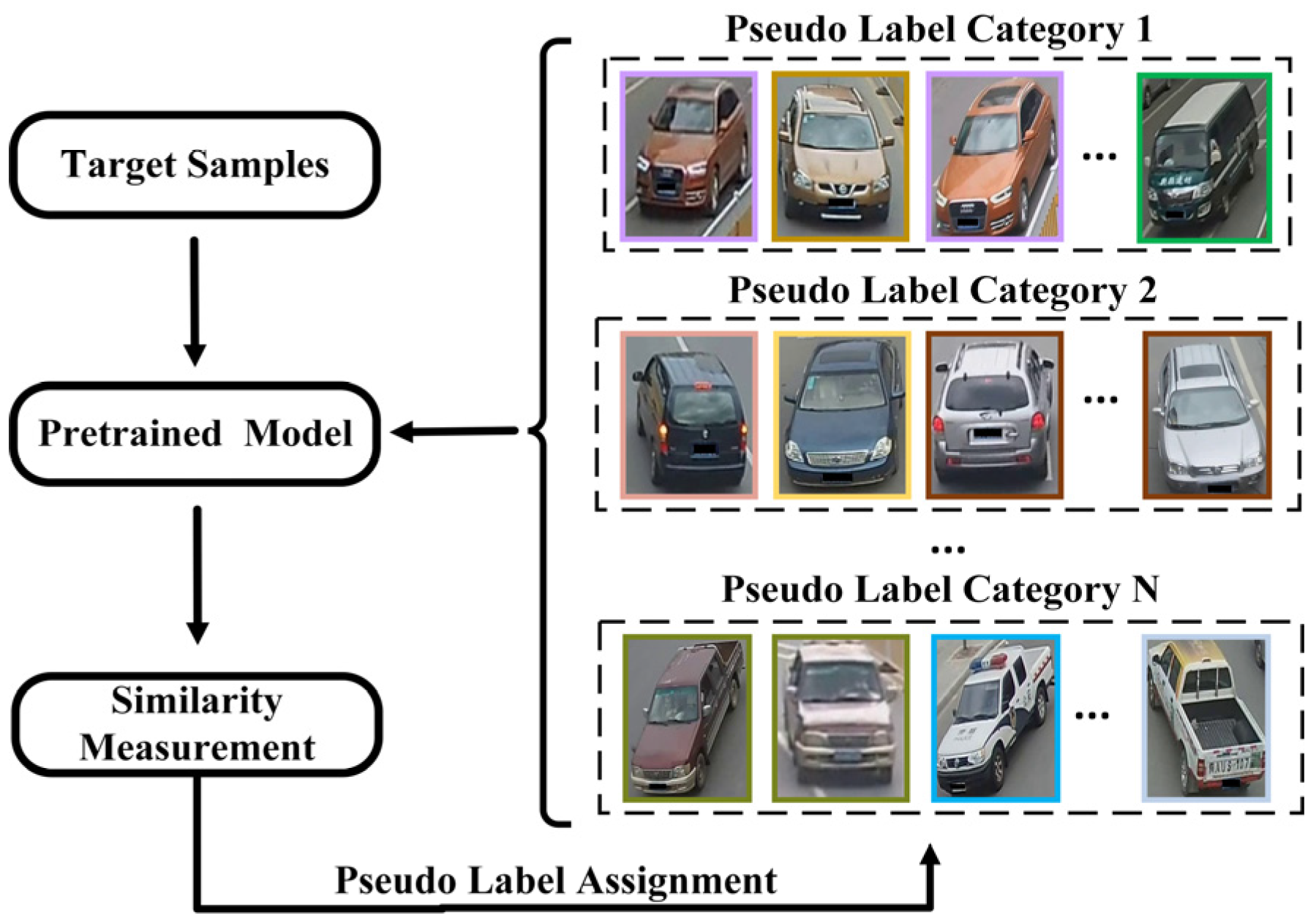
In current vehicle Re-ID methods, pseudo labels are assigned based solely on the clustering results of global features [
15,
16]. However, this approach often introduces label noise due to the limitations of clustering algorithms and the tendency of vehicle images with similar IDs to be assigned to the same category, as shown in
Figure 1. If not addressed, label noise can amplify during the training process and negatively impact the model’s performance. To mitigate this issue, some methods have proposed regional partitioning approaches [
17,
18]. For instance, Wang et al. [
19] proposed a method that extracts local features from different parts of the object and assigns class labels to these local features before performing classification. Similarly, Cho [
20] proposed a model that leverages the complementary relationship between global features and local features obtained after region segmentation to reduce label noise. However, these methods are more applicable to person Re-ID than to vehicle Re-ID, as person have a natural structural advantage allowing for segmentation based on head, upper body, and lower body regions, each containing sufficient discriminative features. In contrast, vehicles lack such structural advantages and have fewer discriminative features compared to person, resulting in some local regions containing limited discriminative information. To address this challenge, we propose a feature cross-division (FCD) method for model fine-tuning to obtain feature partitions. The FCD method ensures that each feature partition contains sufficient discriminative information while preserving the correlation between feature partitions. Specifically, in this paper, we perform cross-partitioning on the extracted whole feature during the fine-tuning stage, obtaining multiple edge-overlapping feature partitions. We then measure the similarity of these partitioned features separately, and ultimately, the similarity measurement results will be referenced by all partitioned features as well as the global features.
In summary, this paper makes the following contributions:
- (1)
Addressing the problem of mismatch between the style transfer data and the hard labels of the source domain in the pre-training stage of existing methods for solving domain gap. CSP proposes a semi-supervised training approach where the source domain and the style transfer data with the target domain style are jointly used, improving the generalization ability of the pre-trained model. During training, soft labels are generated for the style transfer data, with a portion of the weight assigned to the clustering categories of the target domain. This allows the pre-trained model to fully learn the information of the target domain and obtain a better initialized pre-trained model.
- (2)
Addressing the problem of severe noise in pseudo-labels caused by excessive reliance on global features in existing vehicle Re-ID methods. FCD obtains feature partitions by cross-division of the overall features, retaining some edge-overlapping features. The significance of setting feature partitions in this paper is that different feature partitions will yield different similarity measurement results, and measuring different results can enhance the confidence of pseudo-labels. This approach helps to mitigate label noise and improve the accuracy of pseudo-labels in vehicle re-identification.
3. Materials and Methods
The definition of the UDA tasks for Re-ID: Generally, UDA tasks for Re-ID need two datasets: a source domain dataset = {(, ),…,(, )}, where is the number of samples in the source domain, is the -th sample data, and is its corresponding label, and a target domain dataset = {,…,), where is the number of samples in the target domain, and there is no label information for the target domain data. The traditional UDA task pre-trains the model through the dataset , and then uses the obtained pre-trained model to extract the features of the target domain . Finally, pseudo-labels are generated for the unlabeled data through clustering, and the target domain data carrying the pseudo labels are used to continue training the Re-ID model until convergence.
Description of the overall framework of this paper: The overall framework of this paper is shown in
Figure 2. The implementation of the model includes the following three parts: (1) Firstly, the style transfer network is used to generate cross-domain style data, which are then used as unlabeled data for subsequent semi-supervised pre-training. (2) In the semi-supervised pre-training process, an initial network model is trained using the source domain data, and label prediction is performed on the generated cross-style data. At the same time, a pseudo-label reassignment strategy is designed, which replaces traditional hard labels with soft labels weighted by the target domain. (3) In the formal training process, the image similarity measurement is carried out by combining local features and partition features to more accurately predict the pseudo-labels of target samples.
3.1. Review of Generative Methods
Currently, the image transfer [
33] is a popular method used for achieving unsupervised domain adaptation that can automatically perform image-to-image translation without paired samples.
In the process of image style transfer, it is expected that the image transfer network can achieve the following operations on datasets and . Firstly, training a generator G that can convert the image style from the domain to the domain, i.e., , is achieved. Meanwhile, the image transfer network trains another generator that can learn the opposite mapping process, so that images from dataset can learn the style of dataset , i.e., . Secondly, two discriminators are used to identify the quality of generated images. If the image y′ generated by generator from is different from the image y, then the discriminator will give a low score; otherwise, the opposite occurs. Finally, to ensure that the image still retains its own content and only learns the style of domain, the image transfer network designs a cycle-consistency loss. In other words, the generated image will be input into generator and compared with image to ensure that the two images are as similar as possible.
Using the aforementioned features of the image transfer network, this paper performs a style transfer between the labeled source domain and unlabeled target domain to obtain datasets carrying the target domain style and carrying the source domain style.
3.2. Cross-Style Semi-Supervised Pre-Training
To address the domain gap problem in unsupervised domain adaptation, this section proposes a semi-supervised pre-training method based on cross-style learning.
There are various reasons for a domain gap between different datasets, such as differences in camera equipment and sample selection gap, which seriously affect the performance of model generalization. The key step in UDA is to transfer the pre-trained model on the source domain data to the unlabeled target domain, but, due to the existence of domain gap, the model’s performance will be greatly reduced. To alleviate this problem, this paper attempts to introduce data with target domain style generated by the image transfer network, denoted as , during the pre-training stage. It is hoped that multi-style data pre-training can reduce the model’s sensitivity to the target domain data and alleviate the impact of domain gap.
It should be noted that, in this paper, dataset
is generated from dataset
as unlabeled data. First, a model is trained on the existing labeled data
to obtain an initial model, which is then used to predict labels
for
. Second, the labeled
data and the unlabeled data
with assigned pseudo-labels
are combined as a new training set to train the Re-ID model, and then the labels of dataset
are predicted again. Meanwhile, more accurate pseudo labels can be obtained during this training process. Finally, the second process is reiterated until the model converges. Significantly, instead of using traditional hard labels as pseudo-labels for
, this paper designs a soft label assignment method for the features of
data, namely, the dual-domain style fusion pseudo-label reassignment strategy, which will be introduced in
Section 3.3.
The cross-entropy loss function is used for training the pre-training model, as shown in Equation (1).
where
represents the number of training samples,
represents the observed label, and
represents the predicted label, in the process of predicting soft labels for unlabeled data.
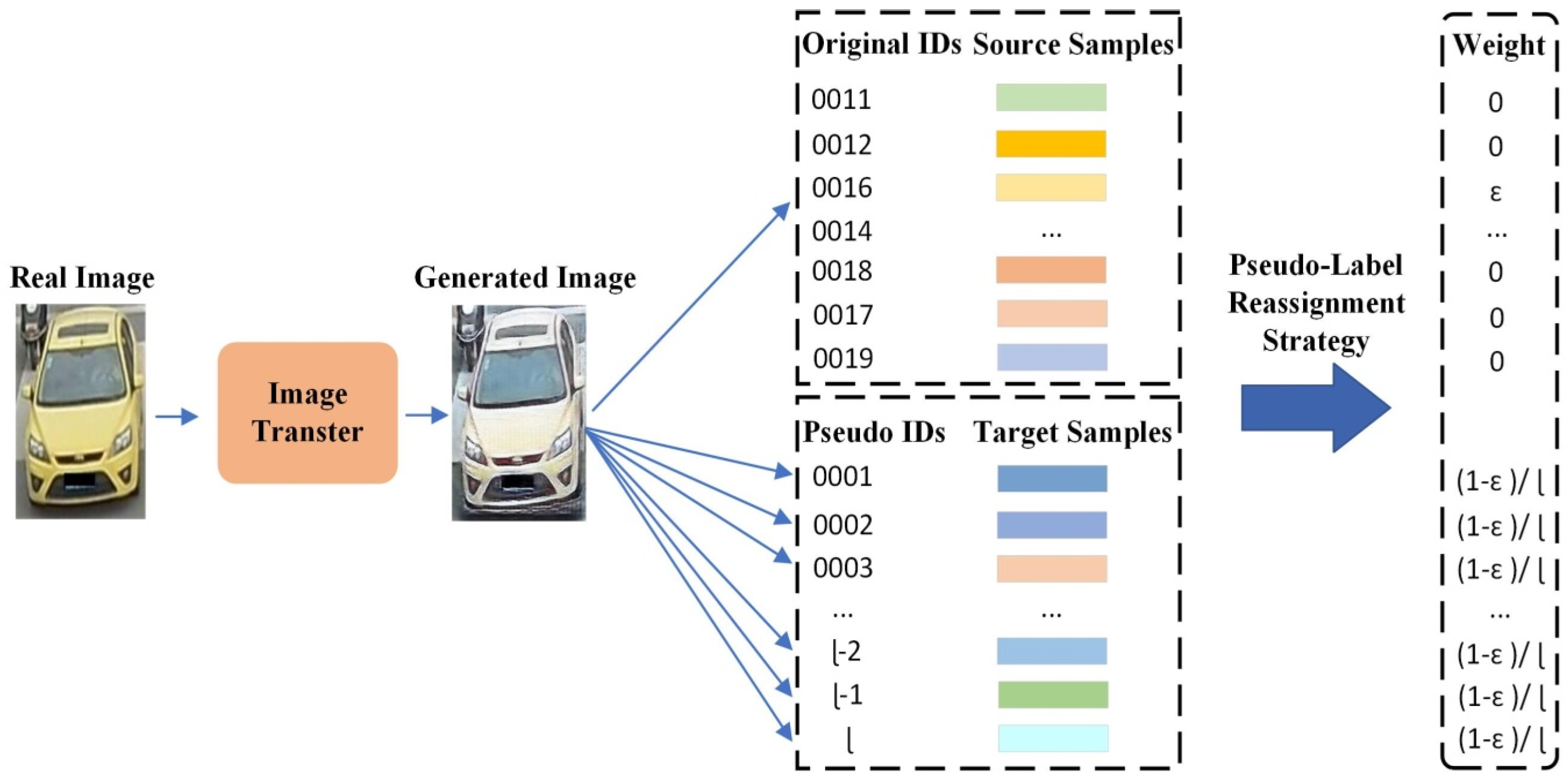
3.3. Pseudo-Label Reassignment Strategy Based on Dual-Domain Style Fusion
To fully utilize the label information of labeled samples and preliminarily understand the geometric feature distribution of the target data, this section proposes a pseudo-label reassignment strategy that combines target style learning. The weight distribution strategy is shown in
Figure 3.
This method abandons traditional hard labels and instead assigns a certain weight to each target domain sample class, allowing the labels to exist in the form of soft labels. The new samples generated by the style transfer network,
, participate in pre-training as an unlabeled dataset and obtain the soft labels assigned by the system. Inspired by the previous approach [
4], this section encourages the network to assign a small portion of weight to each target domain class and treat each target image as a separate class for weight assignment. In other words, this section guides the model to initially learn the unlabeled samples in the target domain by assigning weights to each target domain class. In this process, the computational complexity will increase but the increase is valuable because the soft label reassignment can solve the problem that images generated by style transfer network do not match with the hard label. For each generated image, the soft label generation strategy is shown as Formula (2).
In this formula,
represents the
-th unknown sample,
represents the class for which the weight is being calculated,
represents the source domain, and
represents the original label. For any generated image
, the corresponding loss function
for the pseudo-label reassignment process is shown as Formula (3):
In the initialization phase, represents the number of images in the target domain and, as the iteration proceeds, represents the number of clusters in the target domain. is the predicted possibility of the training sample belonging to label .
Based on the above analysis, the overall loss function during the pre-training stage is shown as Formula (4):
where
represents cross-entropy loss function,
is the loss function for the pseudo-label reassignment process mentioned in Equation (3), and
represents the loss function of the pre-training stage.
3.4. Fine-Tuning Based on Feature Cross-Devision
Because of the unknown total number of target classes and the lack of feature information mining, existing target domain fine-tuning methods based on complete features cannot effectively reduce pseudo-label noise. The main reason for the generation of pseudo-label noise during unsupervised fine-tuning is that the measurement of similarity between images is not accurate enough, leading to more errors in assigning pseudo-labels. To address this issue, this section proposes a fine-tuning method based on feature cross-division, which uses a more comprehensive similarity measure of the overall feature and partition features. When the similarity measurement of the overall features is incorrect and attempts to bring samples that do not belong to the same class closer together, the partitioned features may correct error. The partitioned features are more likely to discover more discriminative detailed features in the deep convolutional neural network due to the extracted partial features, thereby reducing the similarity scores between images of different categories and making images of different classes distinct from each other. The proposed method is shown in
Figure 4.
First, the features extracted by the convolutional neural network model from the target dataset are divided into N regions (i.e., ) for each image i. Compared with traditional feature partitioning methods, this method does not divide the feature map into independent partitions, but rather cross-partitions the feature map into N parts, meaning that there are overlapping regions between adjacent partitions. Through this approach, this section hopes to preserve the relationships between features to a greater extent and explore more similarities between features.
The similarity vectors corresponding to each partition are shown in Equation (5):
where
(
d = 1, 2
N) (
= 1, 2,
) represents the similarity vector between the feature partition of the
-th image and that of other samples.
represents the similarity measurement result between the
-th feature partition of
-th image and the same partition of all other images.
The results of each partition are added together to obtain the final direct distance measurement. To ensure the accuracy of the pseudo labels, this paper also includes the similarity calculated from the global features in the final direct distance measurement. The paper uses the total similarity vector as shown in Equation (6) to measure similarity:
represents the similarity measure results based on global features and represents the similarity measure results based on the -th feature partition.
During the optimization stage, this paper uses the commonly used cross-entropy loss function to optimize the network. Therefore, the total loss function of the framework is shown in Equation (7). Driven by the total loss function, the model in this paper performs outstandingly in addressing the domain gap and reducing the noise carried by images in different datasets.
where
represents the loss function of the fine-tuning.
4. Results
4.1. Experimental Dataset and Evaluation Metrics
The effectiveness of the proposed method was validated using datasets from real-world large-scale surveillance scenes, namely VeRi-776 [
34] and VehicleID [
35]. A summary of VeRi-776 and VehicleID is shown in
Table 1.
VeRi-776 is a large-scale dataset for vehicle re-identification, consisting of 49,357 images from 776 different vehicle IDs. Among them, 37,778 images (from 576 vehicles) are used for the training stage, and 13,257 images (from 200 vehicles) are used for the testing stage, including 11,579 images belonging to the gallery set and 1679 images belonging to the query set. VehicleID is a vehicle Re-ID dataset consisting of images captured by two cameras, with approximately 110,178 images from around 13,134 different vehicle IDs in the training set and 111,585 images of 13,113 vehicles in the test set. The test set consists of three subsets with different scales which contain 800, 1600, and 2400 vehicles in this paper, respectively.
Given a target vehicle or non-vehicle image, the Re-ID model extracts the feature of this image and then matches some of the nearest features to perform metric ranking; the top features are identified as the same ID as the target image.
To accurately evaluate the performance of the model, this paper uses Rank-k and mean Average Precision (mAP) as evaluation metric for performance. Rank-k refers to the accuracy of the top k images sorted by similarity results that belong to the same ID as the query image. mAP refers to the average value of AP for each image category. AP refers to the ratio of the sum of accuracies in the target class in the test set to the number of images belonging to the target class, as shown in Formula (8).
where
represents the number of vehicles involved in the calculation,
represents the order of vehicles retrieved,
represents the accuracy of the result at the
-th position, and
represents its value of 1 if the result at the
-th position is correct, otherwise 0.
The
AP results are then averaged to obtain the mAP, as shown in Formula (9).
where
T denotes the number of query samples.
4.2. Experimental Settings
This paper has experimented with using the proposed model on a LINUX operating system and Pytorch 1.4.0 deep learning experimental environment. The hardware resources used in this experiment were Xeon(R) E5-2650 v4 processor at 2.20 GHz and NVIDIA-Tesla-P40 GPU.
ResNet-50 [
36] was used as the baseline model in this paper, which was pre-trained on ImageNet [
37]. All input images were uniformly processed into a size of 256 × 256. This paper used the stochastic gradient descent and set the initial learning rate and decay rate as 0.05 and 5 × 10
−4; the batch size was set to 16 and the epoch was set to 10. Since CycleGAN has already shown good performance and applicability in existing works, CycleGAN was used as the style transfer network to provide unlabeled data with the target domain style. For the training of CycleGAN, this paper is set according to its original experimental details [
33].
4.3. Comparison with Existing Theoretical Methods
To confirm the performance of proposed model for vehicle Re-ID, this paper compares it with some recent research theories and shows the result in
Table 2 and
Table 3. G(X) represents source domain data with a target domain style; X and Y represent the source and target domains, respectively. Source_G(X) represents pre-training the model using only G(X); Target_G(X) represents pre-training the model using source domain images and then using G(X) as the training set during fine-tuning. ST_G(X) represents using G(X) not only to train the pre-trained model but also for fine-tuning. The specific information is shown in
Table 4. In all three processes, the FCD module proposed in this article is introduced during the fine-tuning stage. Part-based pseudo label refinement (PPLR) [
20] proposes a model that leverages the complementary relationship between global features and locally extracted features derived from region segmentation, with the objective of mitigating label noise. Cluster Contrast for Unsupervised Person Re-Identification (CCUP) [
15] proposes a new method called Cluster Contrast, which involves the storage of feature vectors and computation of contrastive loss at the cluster level. Additionally, this method introduces momentum update to strengthen the consistency of cluster-level features in the sequential space. Self-Paced Contrastive Learning framework (SPCL) [
38] proposes a simple and effective Self-Paced Contrastive Learning framework, whose core idea is to use multiple forms of category prototypes to provide mixed supervision, in order to achieve sufficient mining of all training data.
It can be observed from
Table 2 and
Table 3 that on the VeRi-776 to VehicleID task, our method improves an average of 0.63% in mAP, 0.73% in Rank-1, and 0.4% in Rank-5 compared with the best overall performing SPCL method. On the VehicleID to VeRi-776(%) task, our method respectively improves mAP, Rank-1, and Rank-5 by 0.9%, 1%, and 0.6% compared with PPLR. Compared with the remaining comparison experiments, the superiority of our method is more obvious.
4.4. Ablation Studies
4.4.1. Discussion on the Parameters of Pseudo-Label Reassignment Strategy
The pseudo label reassignment strategy updates the parameters in the pseudo-label generation strategy adaptively. The steps are as follows: (1) Initializing the parameters in the soft label generation strategy, i.e., , where represents the number of datasets involved in style transfer. (2) When training the model, the current soft label generation strategy is used to generate soft labels on the training data. Then the generated soft labels are used as the labels of the data generated by style transfer for model pre-training. (3) At the end of each epoch, the value in the pseudo generation strategy is adjusted according to the number of clusters.
4.4.2. Discussion on the Number of Feature Partitions N
In the fine-tuning stage of the proposed framework, to improve the algorithm’s performance, this paper divided the features extracted from each image into several cross partitions and used N to represent the number of partitions. The value of N plays a crucial role in the calculation of the final sample similarity. Therefore, this section shows the impact of N on the overall theoretical framework in
Table 5 and
Table 6. From these two tables, it can be observed that when
3, the Re-ID model achieved the best performance on both datasets. In other words, it can be concluded that this paper improves the accuracy of unsupervised data classification by using the method of combining global features and partition features to replace the sole use of global features for image similarity measurement. This is because when two images are highly similar, measuring their similarities through global features may assign them high similarity scores, leading to pseudo-labeling noise; however, when partition features are introduced, they can focus on more detailed features and obtain different similarity scores from global features, allowing the model to assign pseudo-labels based on different measurement criteria, thereby increasing the confidence of pseudo-labels. In the subsequent experimental process, the model will uniformly set N = 3 to obtain better performance. It is worth noting that the reason for choosing cross-division and retaining the common areas between partitions in this paper is to preserve the similarity between partitions and obtain more convincing results.
The specific description of feature partitioning in this paper is shown in
Table 7. Before feature partitioning, the dimension of all features was 1 × 2048, and the features were only partitioned based on the length of the feature dimension.
4.4.3. Effects of CSP and FCD on the Re-ID Model
To verify the effectiveness of cross-style semi-supervised pre-training (CSP) and feature cross-division (FCD) for fine-tuning, this paper conducted related experiments, and the experimental results are shown in
Table 8 and
Table 9.
This section mainly analyzes the following situations. In the first case, the direct transfer [
36] means the pre-trained model based on the source domain is directly used for classification of the target dataset. In the second case, the labeled source data are still used for pre-training the model, but FCD is used to calculate the similarity of images during fine-tuning. In the third case, pre-training is carried out according to the CSP proposed in this paper, and in the fine-tuning stage, the similarity of images is directly measured using global features. In the fourth case, the model proposed in this paper is used to realize the Re-ID task. The conclusion that can be drawn is that the application of each module proposed in this section improves the performance of the model compared to direct transfer. Moreover, the overall framework, including CSP and FCD, performs better than the single use of each module.
To demonstrate the role of each module in more detail, this article shows the accuracy changes in the last few iterations of the specific experimental iteration process in
Figure 5. It can be observed that during each iteration, the model using CSP+FCD has higher accuracy than the model using the two modules alone. At the same time, this paper also visualized the rank list during the last training process to support the role of the FCD module, as shown in
Figure 6.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}