
Load Disaggregation Based on a Bidirectional Dilated Residual Network with Multihead Attention
Abstract
:1. Introduction
- An architecture combining a bidirectional TCN with multihead self-attention is constructed and trained to implement nonintrusive load disaggregation.
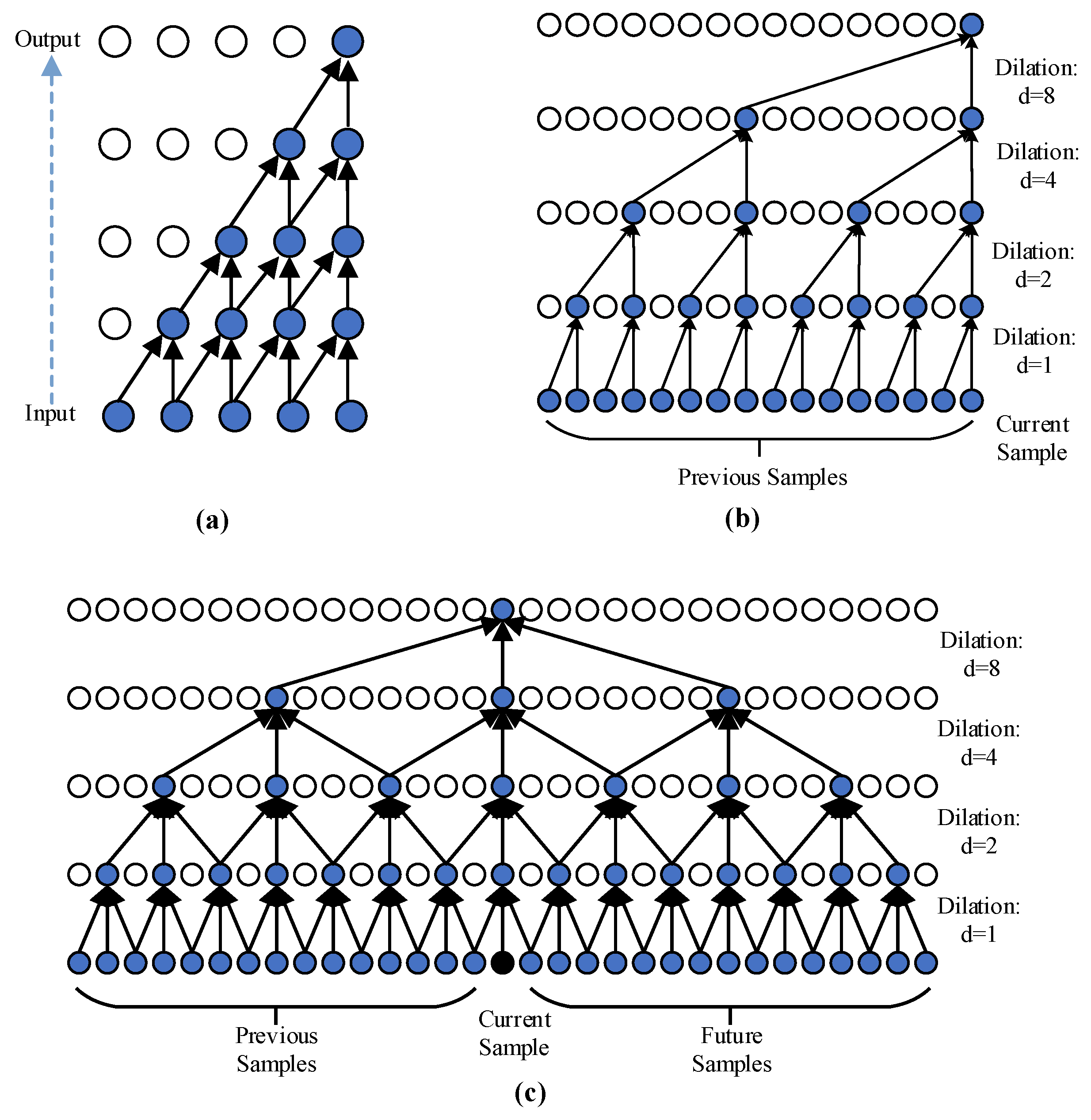
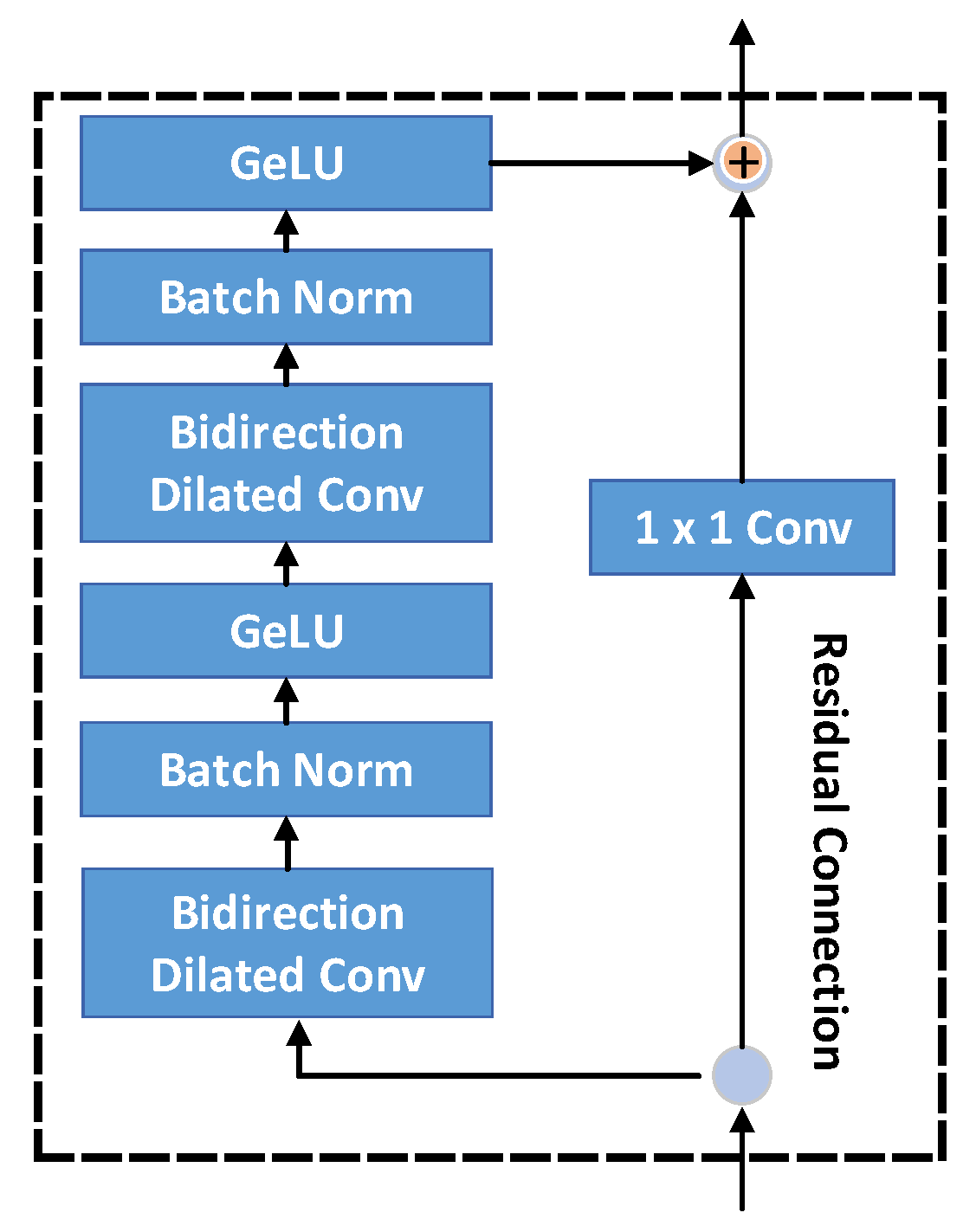
- Bidirectional dilated convolution within bidirectional TCN is employed to maximize the receptive field and improve the prediction from previous and future information; meanwhile, GeLU, integrating the properties of dropout and ReLU, is used as an active function to make the residual block compact.
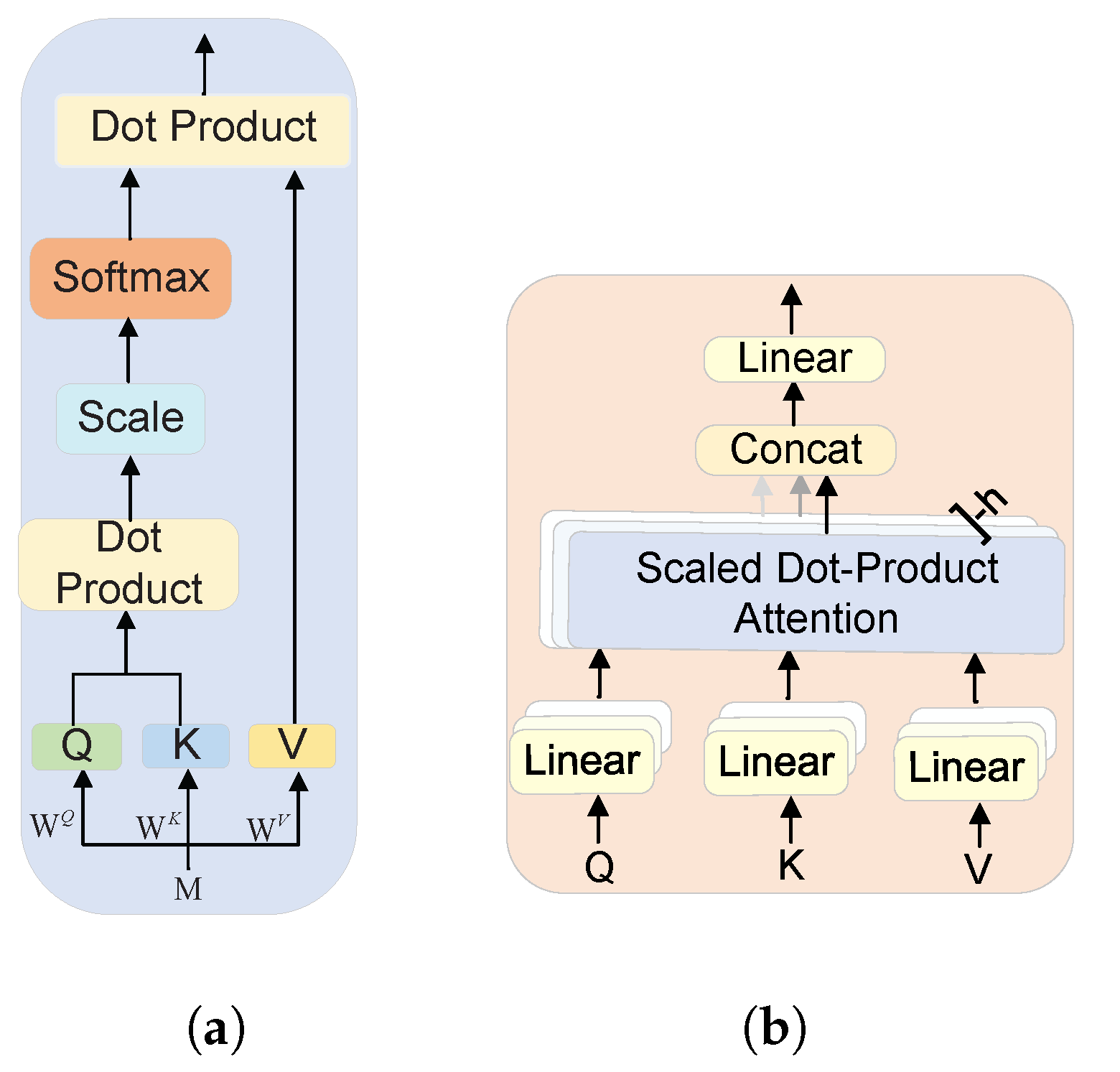
- Multihead self-attention within the proposed algorithm is utilized to capture the correlations of different-level load features.
- The REDD and UK-DALE datasets are used to validate the proposed algorithm, which achieves the least average errors for the disaggregation of four appliances in the REDD dataset and shows superior results in identifying the on/off states of four appliances in the UK-DALE dataset.
2. Problem Formulation
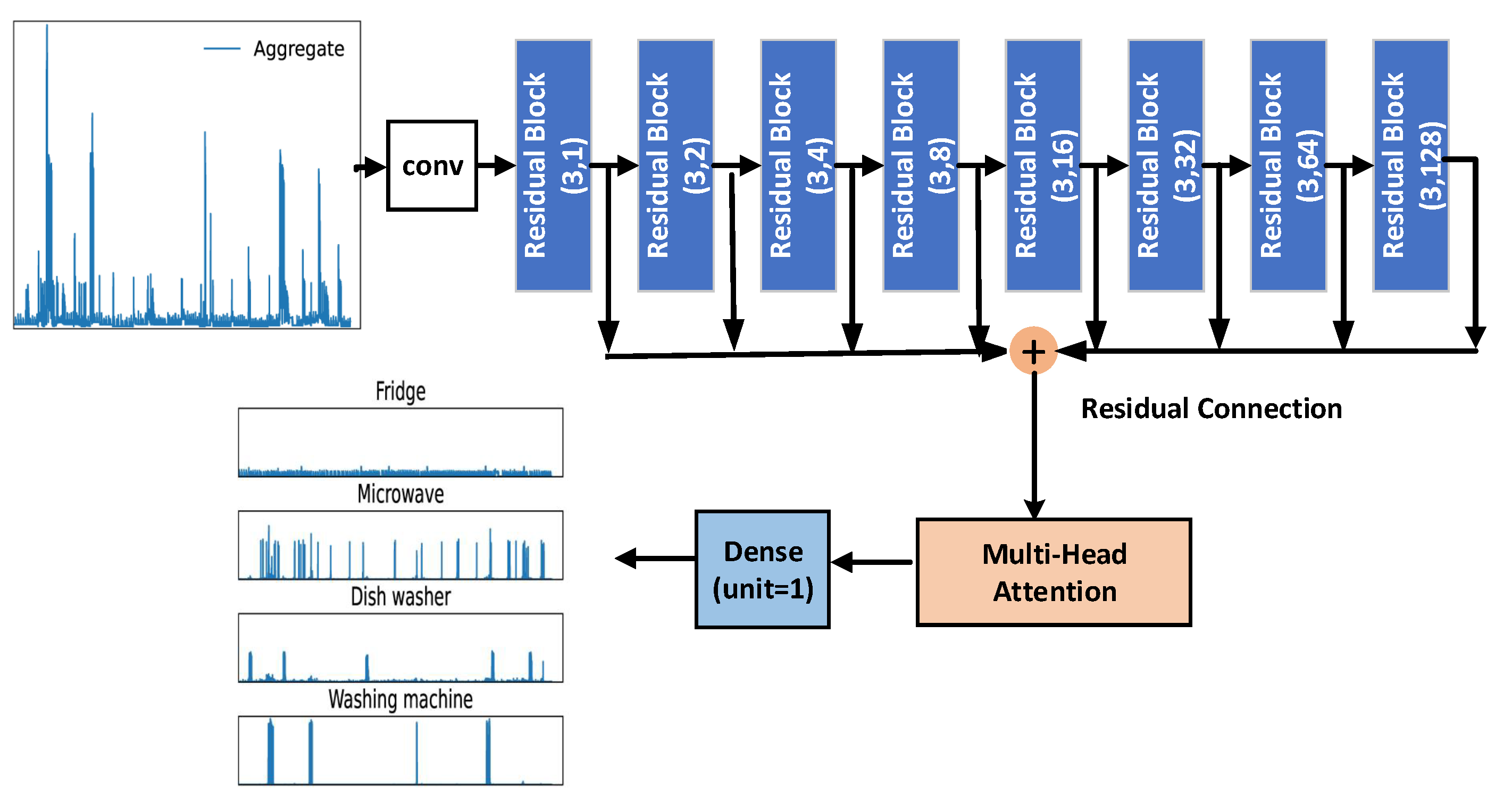
3. The Proposed Algorithm
3.1. Bidirectional Dilated Convolution
3.2. The Residual Block
3.3. Multihead Self-Attention
3.4. Training of the Proposed Network
4. Experimental Results
4.1. Dataset
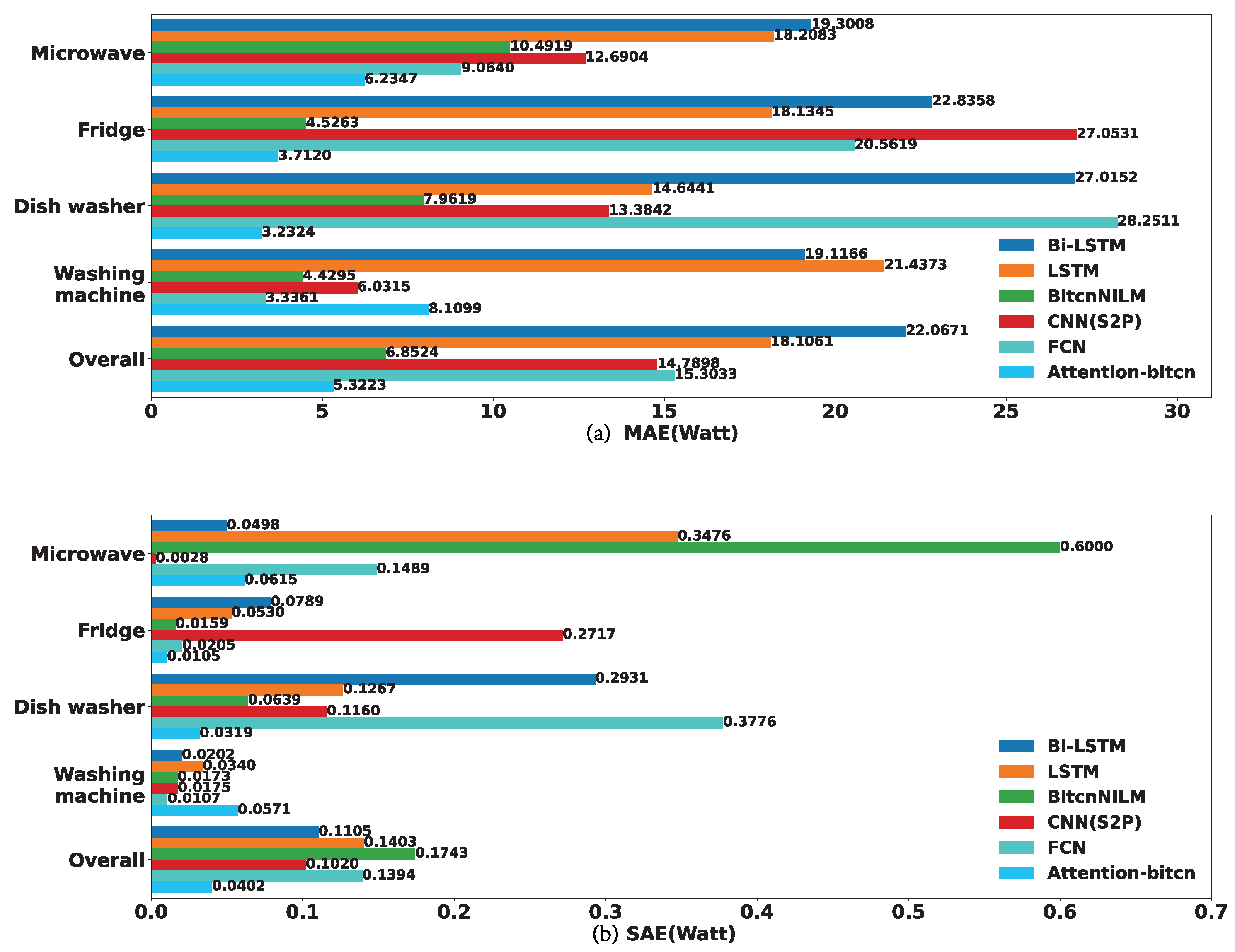
4.2. Evaluation Metrics
4.3. Experimental Results
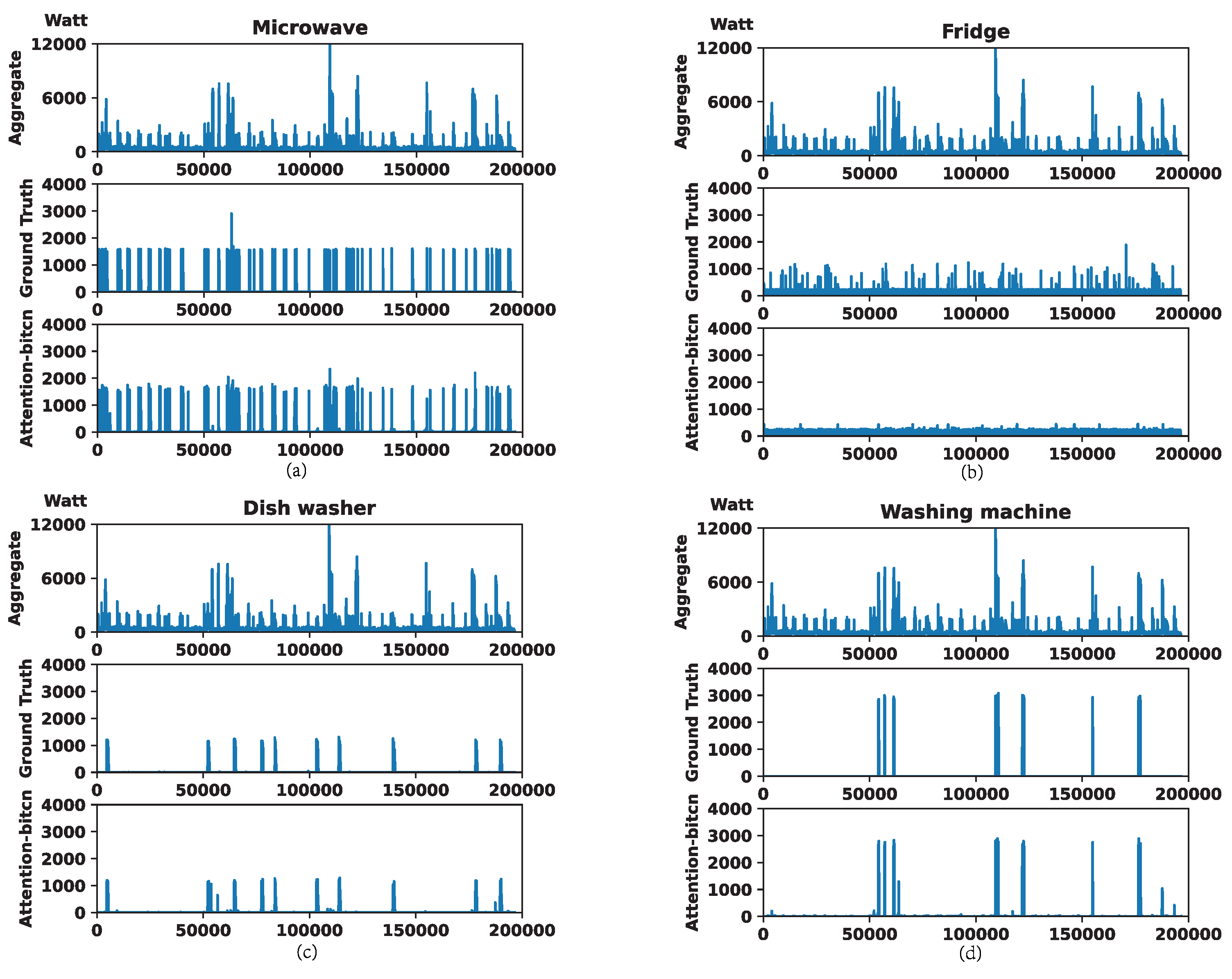
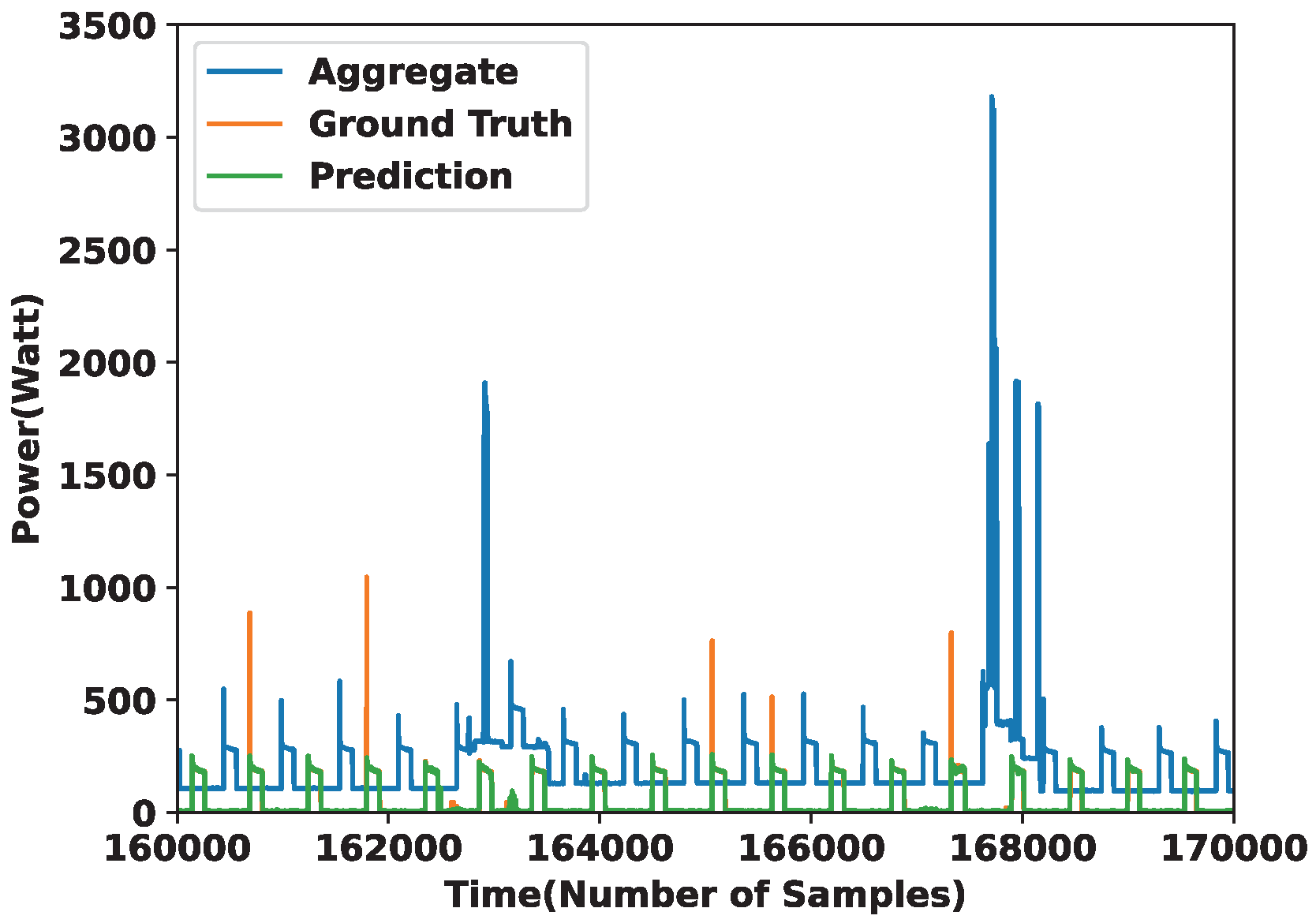
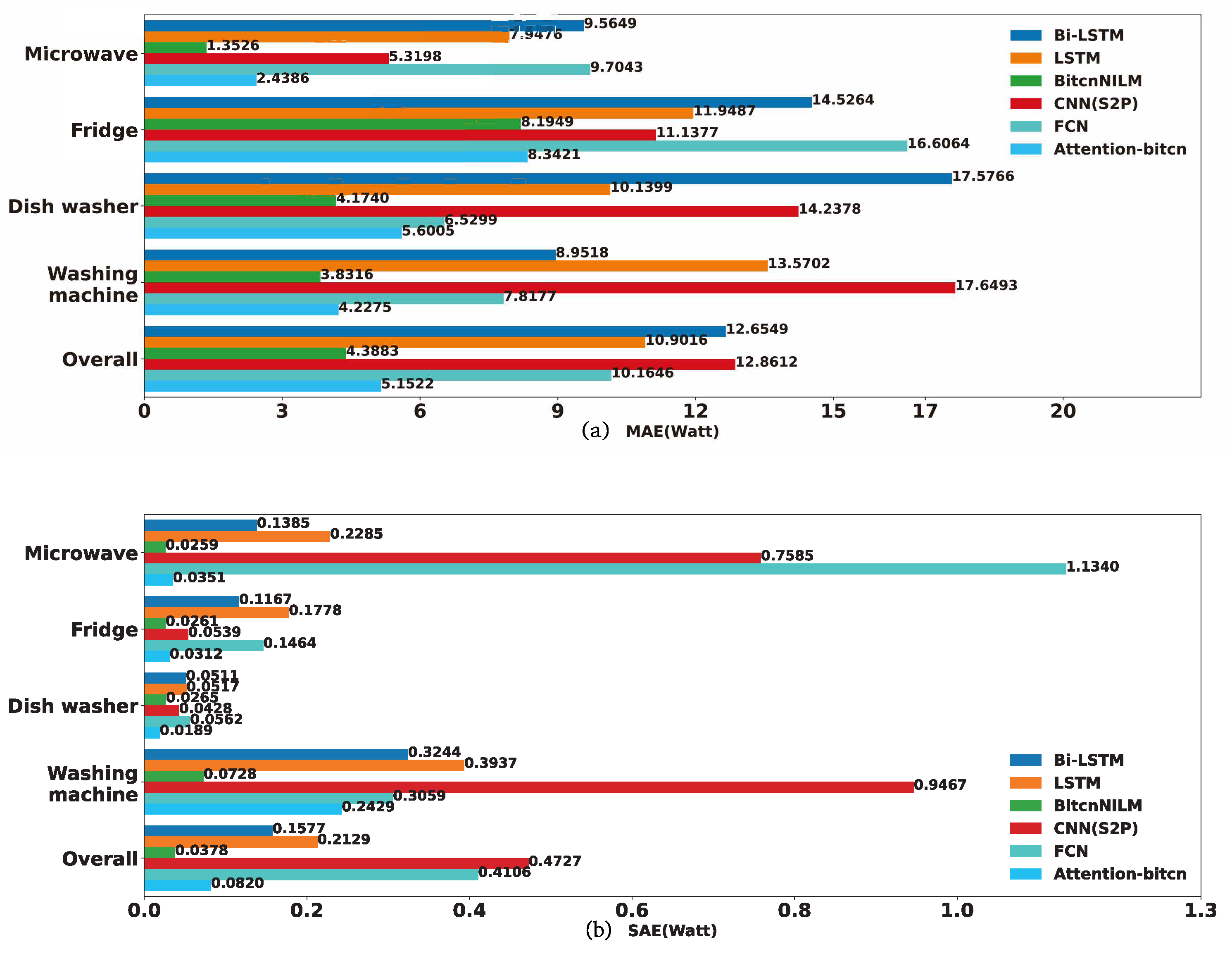
4.3.1. Experiments on REDD Dataset
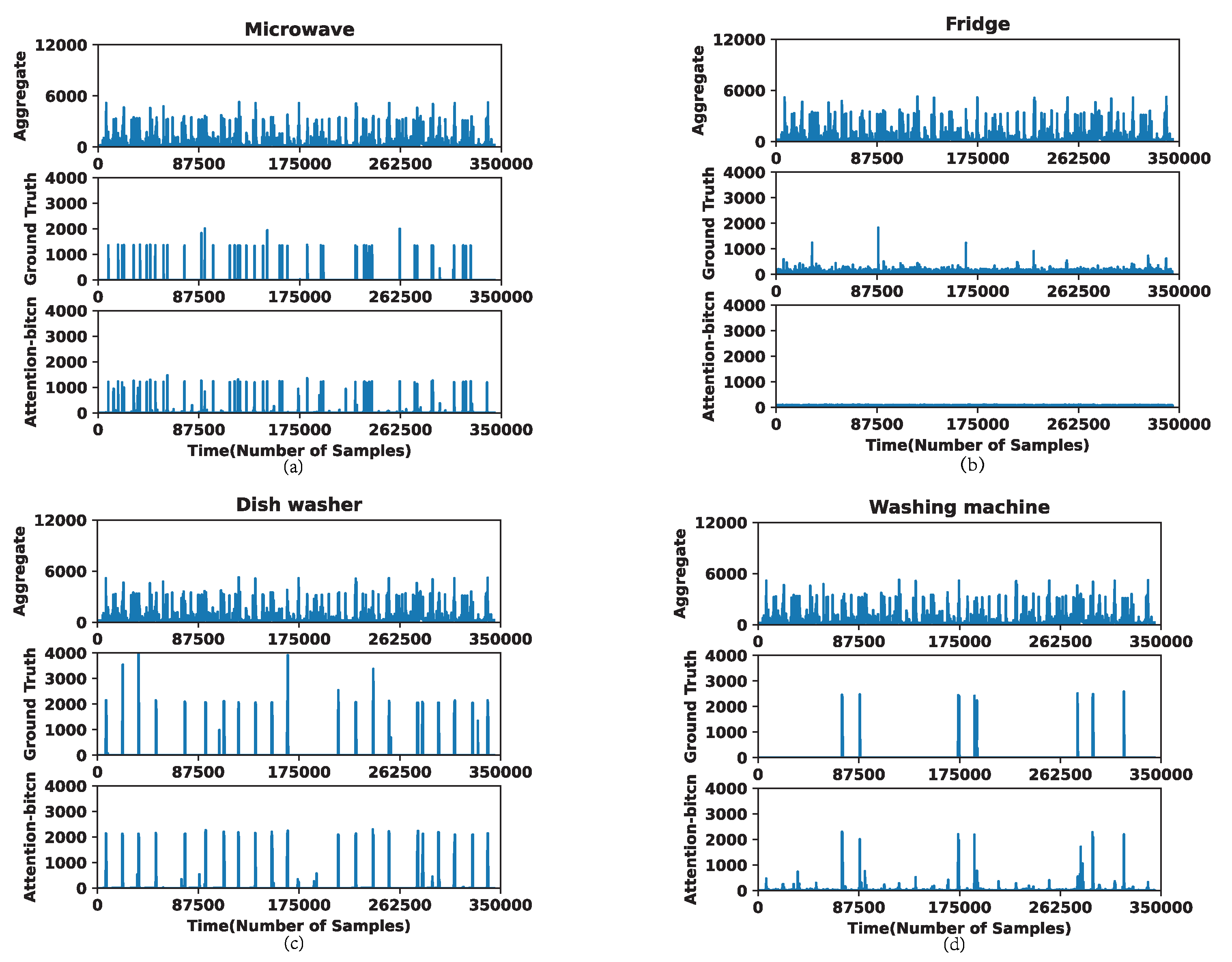
4.3.2. Experiments on UK-DALE Dataset
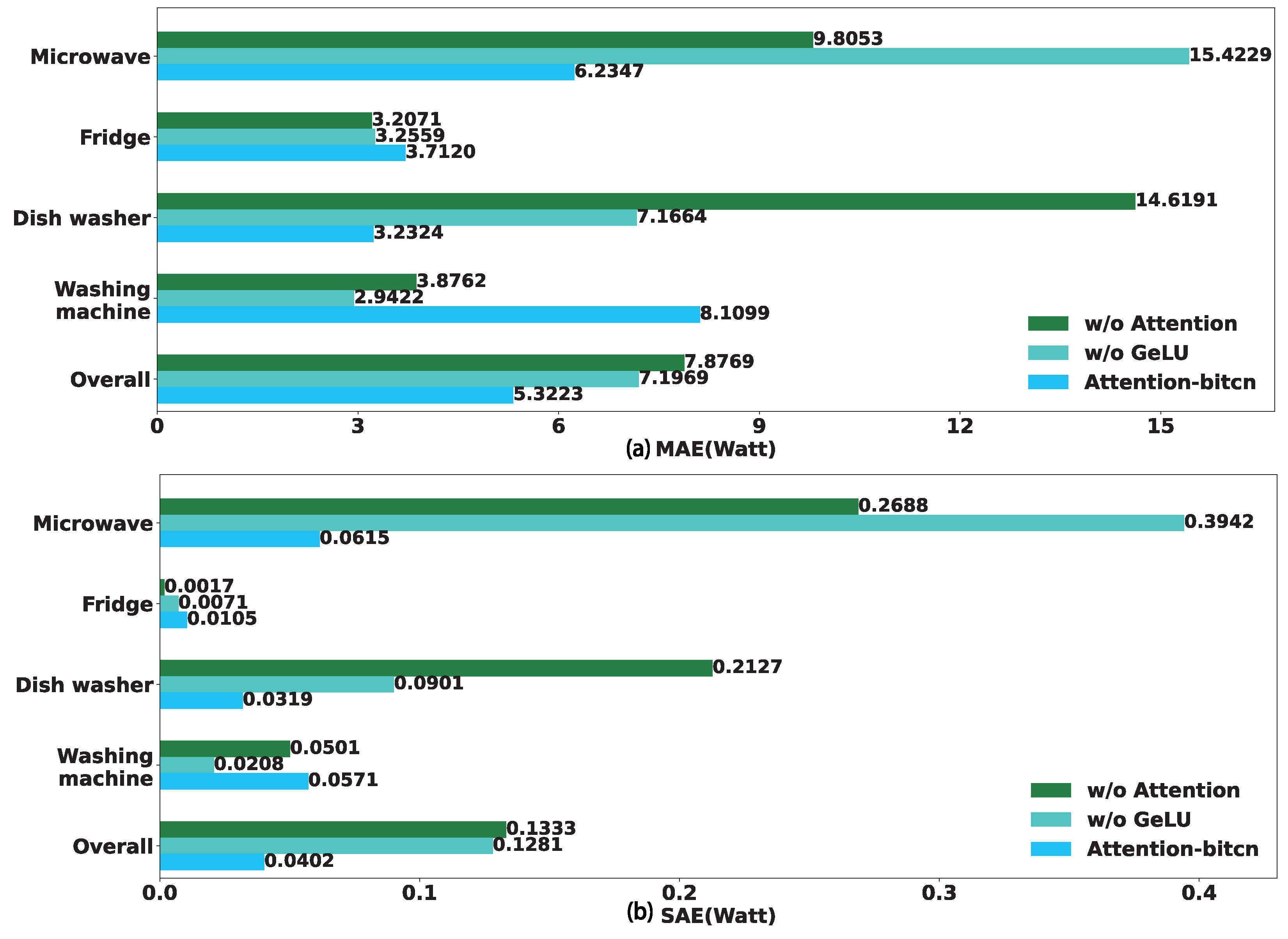
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hart, G.W. Nonintrusive appliance load monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Rajendiran, G.; Kumar, M.; Joshua, C.; Srinivas, K. Energy management using non-intrusive load monitoring techniques—State-of-the-art and future research directions. Sustain. Cities Soc. 2020, 62, 102411. [Google Scholar]
- Chang, H.H.; Lin, L.S.; Chen, N.; Lee, W.J. Particle-Swarm-Optimization-Based Nonintrusive Demand Monitoring and Load Identification in Smart Meters. IEEE Trans. Ind. Appl. 2013, 49, 2229–2236. [Google Scholar] [CrossRef]
- Piga, D.; Cominola, A.; Giuliani, M.; Castelletti, A.; Rizzoli, A.E. Sparse Optimization for Automated Energy End Use Disaggregation. IEEE Trans. Control. Syst. Technol. 2016, 24, 1044–1051. [Google Scholar] [CrossRef]
- Lin, S.; Zhao, L.; Li, F.; Liu, Q.; Li, D.; Fu, Y. A nonintrusive load identification method for residential applications based on quadratic programming. Electr. Power Syst. Res. 2016, 133, 241–248. [Google Scholar] [CrossRef] [Green Version]
- Kong, W.; Dong, Z.Y.; Hill, D.J.; Ma, J.; Zhao, J.H.; Luo, F.J. A Hierarchical Hidden Markov Model Framework for Home Appliance Modeling. IEEE Trans. Smart Grid 2018, 9, 3079–3090. [Google Scholar] [CrossRef]
- Bonfigli, R.; Principi, E.; Fagiani, M.; Severini, M.; Squartini, S.; Piazza, F. Non-intrusive load monitoring by using active and reactive power in additive Factorial Hidden Markov Models. Appl. Energy 2017, 208, 1590–1607. [Google Scholar] [CrossRef]
- He, K.; Stankovic, L.; Liao, J.; Stankovic, V. Non-Intrusive Load Disaggregation Using Graph Signal Processing. IEEE Trans. Smart Grid 2018, 9, 1739–1747. [Google Scholar] [CrossRef] [Green Version]
- Lima, D.A.; Oliveira, M.Z.; Zuluaga, E.O. Non-intrusive load disaggregation model for residential consumers with Fourier series and optimization method applied to White tariff modality in Brazil. Electr. Power Syst. Res. 2020, 184, 106277. [Google Scholar] [CrossRef]
- Dinesh, C.; Nettasinghe, B.W.; Godaliyadda, R.I.; Ekanayake, M.P.B.; Ekanayake, J.; Wijayakulasooriya, J.V. Residential Appliance Identification Based on Spectral Information of Low Frequency Smart Meter Measurements. IEEE Trans. Smart Grid 2016, 7, 2781–2792. [Google Scholar] [CrossRef]
- Liu, Q.; Kamoto, K.M.; Liu, X.; Sun, M.; Linge, N. Low-Complexity Non-Intrusive Load Monitoring Using Unsupervised Learning and Generalized Appliance Models. IEEE Trans. Consum. Electron. 2019, 65, 28–37. [Google Scholar] [CrossRef]
- Hassan, T.; Javed, F.; Arshad, N. An Empirical Investigation of V-I Trajectory Based Load Signatures for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2014, 5, 870–878. [Google Scholar] [CrossRef] [Green Version]
- Mauch, L.; Yang, B. A new approach for supervised power disaggregation by using a deep recurrent LSTM network. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Orlando, FL, USA, 14–16 December 2015; pp. 63–67. [Google Scholar]
- Kaselimi, M.; Doulamis, N.; Voulodimos, A.; Protopapadakis, E.; Doulamis, A. Context Aware Energy Disaggregation Using Adaptive Bidirectional LSTM Models. IEEE Trans. Smart Grid 2020, 11, 3054–3067. [Google Scholar] [CrossRef]
- Le, T.T.H.; Kim, J.; Kim, H. Classification performance using gated recurrent unit recurrent neural network on energy disaggregation. In Proceedings of the 2016 International Conference on Machine Learning and Cybernetics (ICMLC), Jeju Island, Republic of Korea, 10–13 July 2016; Volume 1, pp. 105–110. [Google Scholar]
- Chen, K.; Wang, Q.; He, Z.; Chen, K.; Hu, J.; He, J. Convolutional sequence to sequence non-intrusive load monitoring. J. Eng. 2018, 2018, 1860–1864. [Google Scholar] [CrossRef]
- Zhang, C.; Zhong, M.; Wang, Z.; Goddard, N.; Sutton, C. Sequence-to-point learning with neural networks for nonintrusive load monitoring. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Garcia, F.C.C.; Creayla, C.M.C.; Macabebe, E.Q.B. Development of an Intelligent System for Smart Home Energy Disaggregation Using Stacked Denoising Autoencoders. In Proceedings of the 2016 IEEE International Symposium on Robotics and Intelligent Sensors (IRIS 2016), Tokyo, Japan, 17–20 December 2016. [Google Scholar]
- Brewitt, C.; Goddard, N. Non-Intrusive Load Monitoring with Fully Convolutional Networks. arXiv 2018, arXiv:1812.03915. [Google Scholar]
- Athanasiadis, C.L.; Papadopoulos, T.A.; Doukas, D.I. Real-time non-intrusive load monitoring: A light-weight and scalable approach. Energy Build. 2021, 253, 111523. [Google Scholar] [CrossRef]
- Chen, T.; Qin, H.; Li, X.; Wan, W.; Yan, W. A Non-Intrusive Load Monitoring Method Based on Feature Fusion and SE-ResNet. Electronics 2023, 12, 1909. [Google Scholar] [CrossRef]
- D’Incecco, M.; Squartini, S.; Zhong, M. Transfer Learning for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2020, 11, 1419–1429. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Xiang, Y.; Xu, H.; Yi, Z.; Shi, D.; Wang, Z. A Novel Transfer Learning-Based Intelligent Nonintrusive Load-Monitoring With Limited Measurements. IEEE Trans. Instrum. Meas. 2021, 70, 1–8. [Google Scholar] [CrossRef]
- Angelis, G.F.; Timplalexis, C.; Krinidis, S.; Ioannidis, D.; Tzovaras, D. NILM applications: Literature review of learning approaches, recent developments and challenges. Energy Build. 2022, 261, 111951. [Google Scholar] [CrossRef]
- Dash, S.; Sahoo, N. Electric energy disaggregation via non-intrusive load monitoring: A state-of-the-art systematic review. Electr. Power Syst. Res. 2022, 213, 108673. [Google Scholar] [CrossRef]
- Schirmer, P.A.; Mporas, I. Non-Intrusive Load Monitoring: A Review. IEEE Trans. Smart Grid 2023, 14, 769–784. [Google Scholar] [CrossRef]
- Jia, Z.; Yang, L.; Zhang, Z.; Liu, H.; Kong, F. Sequence to point learning based on bidirectional dilated residual network for non-intrusive load monitoring. Int. J. Electr. Power Energy Syst. 2021, 129, 106837. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Nguyen, A.; Pham, K.; Ngo, D.; Ngo, T.; Pham, L. An Analysis of State-of-the-art Activation Functions For Supervised Deep Neural Network. In Proceedings of the 2021 International Conference on System Science and Engineering (ICSSE), Ho Chi Minh City, Vietnam, 26–28 August 2021; pp. 215–220. [Google Scholar]
- Deniz, O. ViolenceNet: Dense Multi-Head Self-Attention with Bidirectional Convolutional LSTM for Detecting Violence. Electronics 2021, 10, 1601. [Google Scholar]
- Hamad, R.A.; Kimura, M.; Yang, L.; Woo, W.L.; Wei, B. Dilated causal convolution with multi-head self attention for sensor human activity recognition. Neural Comput. Appl. 2021, 31, 13705–13722. [Google Scholar] [CrossRef]
- Kolter, J.Z.; Johnson, M.J. REDD: A Public Data Set for Energy Disaggregation Research. In Proceedings of the Workshop on Data Mining Applications in Sustainability (SIGKDD), San Diego, CA, USA, 21–24 August 2011. [Google Scholar]
- Kelly, J.; Knottenbelt, W. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2, 150007. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Microwave | Fridge | |||||||
|---|---|---|---|---|---|---|---|---|
| P | R | A | F1 | P | R | A | F1 | |
| Attention-bitcn | 0.9110 | 0.9546 | 0.9982 | 0.9323 | 0.9917 | 0.9972 | 0.9972 | 0.9944 |
| CNN(S2P) [17] | 0.7730 | 0.9933 | 0.9988 | 0.8694 | 0.9551 | 0.9240 | 0.9467 | 0.9392 |
| FCN [19] | 0.7857 | 0.9742 | 0.9963 | 0.8699 | 0.8126 | 0.9818 | 0.9392 | 0.8892 |
| BitcnNILM [27] | 0.9354 | 0.9275 | 0.9995 | 0.9314 | 0.9974 | 0.9965 | 0.9973 | 0.9969 |
| LSTM | 0.7439 | 0.9680 | 0.9873 | 0.8547 | 0.7733 | 0.9727 | 0.9219 | 0.8616 |
| Bi-LSTM | 0.4084 | 0.9873 | 0.9423 | 0.5778 | 0.7531 | 0.9703 | 0.9131 | 0.8480 |
| Dishwasher | Washing Machine | |||||||
| P | R | A | F1 | P | R | A | F1 | |
| Attention-bitcn | 0.8262 | 0.9921 | 0.9913 | 0.9016 | 0.5525 | 0.9950 | 0.9901 | 0.7105 |
| CNN(S2P) [17] | 0.4169 | 0.9817 | 0.9443 | 0.5853 | 0.5589 | 1.0000 | 0.9903 | 0.7170 |
| FCN [19] | 0.1613 | 0.9967 | 0.7910 | 0.2776 | 0.6417 | 0.9917 | 0.9931 | 0.7818 |
| BitcnNILM [27] | 0.3897 | 0.9859 | 0.9377 | 0.5586 | 0.4450 | 0.9963 | 0.9848 | 0.6152 |
| LSTM | 0.4061 | 0.9716 | 0.9420 | 0.5728 | 0.4178 | 1.0000 | 0.9828 | 0.5864 |
| Bi-LSTM | 0.3689 | 0.3274 | 0.9844 | 0.3470 | 0.4007 | 1.0000 | 0.9817 | 0.5721 |
| Microwave | Fridge | |||||||
|---|---|---|---|---|---|---|---|---|
| P | R | A | F1 | P | R | A | F1 | |
| Attention-bitcn | 0.9003 | 0.8857 | 0.9993 | 0.8929 | 0.8669 | 0.9451 | 0.9306 | 0.9043 |
| CNN(S2P) [17] | 0.6864 | 0.9693 | 0.9984 | 0.8037 | 0.8009 | 0.9530 | 0.9014 | 0.8703 |
| FCN [19] | 0.3225 | 0.9113 | 0.9932 | 0.4764 | 0.7891 | 0.9422 | 0.8925 | 0.8589 |
| BitcnNILM [27] | 0.8662 | 0.9002 | 0.9992 | 0.8828 | 0.8813 | 0.9512 | 0.9386 | 0.9150 |
| LSTM | 0.5843 | 0.8694 | 0.9966 | 0.7472 | 0.7031 | 0.7936 | 0.7318 | 0.8042 |
| Bi-LSTM | 0.5537 | 0.8521 | 0.9942 | 0.7017 | 0.6799 | 0.8081 | 0.8014 | 0.7385 |
| Dishwasher | Washing Machine | |||||||
| P | R | A | F1 | P | R | A | F1 | |
| Attention-bitcn | 0.8130 | 0.9627 | 0.9843 | 0.7771 | 0.8442 | 0.8860 | 0.9970 | 0.8646 |
| CNN(S2P) [17] | 0.8009 | 0.9530 | 0.9014 | 0.8703 | 0.2955 | 0.9492 | 0.9007 | 0.1736 |
| FCN [19] | 0.3383 | 0.9283 | 0.9404 | 0.4959 | 0.1167 | 0.9831 | 0.9178 | 0.2086 |
| BitcnNILM [27] | 0.7584 | 0.9139 | 0.9881 | 0.8289 | 0.7693 | 0.9341 | 0.9962 | 0.8437 |
| LSTM | 0.4470 | 0.8751 | 0.8906 | 0.5349 | 0.5880 | 0.8481 | 0.9734 | 0.7120 |
| Bi-LSTM | 0.6083 | 0.9393 | 0.9418 | 0.6942 | 0.5695 | 0.8905 | 0.8881 | 0.7039 |
| Microwave | Fridge | |||||||
|---|---|---|---|---|---|---|---|---|
| P | R | A | F1 | P | R | A | F1 | |
| Attention-bitcn | 0.9110 | 0.9546 | 0.9982 | 0.9323 | 0.9917 | 0.9972 | 0.9972 | 0.9944 |
| w/o Attention | 0.8929 | 0.9696 | 0.9994 | 0.9297 | 0.9975 | 0.9983 | 0.9981 | 0.979 |
| w/o GeLU | 0.7058 | 0.7818 | 0.9931 | 0.7419 | 0.9864 | 0.9980 | 0.9961 | 0.9922 |
| Dishwasher | Washing Machine | |||||||
| P | R | A | F1 | P | R | A | F1 | |
| Attention-bitcn | 0.8262 | 0.9921 | 0.9913 | 0.9016 | 0.5525 | 0.9950 | 0.9901 | 0.7105 |
| w/o Attention | 0.7978 | 0.9434 | 0.6495 | 0.1772 | 0.7154 | 0.9900 | 0.9951 | 0.8306 |
| w/o GeLU | 0.5412 | 0.9356 | 0.9657 | 0.6857 | 0.8136 | 0.9938 | 0.9971 | 0.8947 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shu, Y.; Kang, J.; Zhou, M.; Yang, Q.; Zeng, L.; Yang, X. Load Disaggregation Based on a Bidirectional Dilated Residual Network with Multihead Attention. Electronics 2023, 12, 2736. https://doi.org/10.3390/electronics12122736
Shu Y, Kang J, Zhou M, Yang Q, Zeng L, Yang X. Load Disaggregation Based on a Bidirectional Dilated Residual Network with Multihead Attention. Electronics. 2023; 12(12):2736. https://doi.org/10.3390/electronics12122736
Chicago/Turabian StyleShu, Yifei, Jieying Kang, Mei Zhou, Qi Yang, Lai Zeng, and Xiaomei Yang. 2023. "Load Disaggregation Based on a Bidirectional Dilated Residual Network with Multihead Attention" Electronics 12, no. 12: 2736. https://doi.org/10.3390/electronics12122736