
MFLCES: Multi-Level Federated Edge Learning Algorithm Based on Client and Edge Server Selection


Abstract
:1. Introduction
- A multi-level federated edge learning algorithm is proposed based on geographic location and distribution of client computing power. Compared to the current three-level federated learning, the algorithm significantly increases the scalability of the system by fully utilizing the edge server’s capacity to accept additional clients and train a model across a wide geographic area. Simultaneously, the number of communications with the cloud center server is reduced, thus improving the efficiency of model training and reducing the energy loss from communication with the cloud center server.
- A client and edge server selection algorithm were designed. Specifically, we have developed a greedy algorithm that sets a deadline for edge server model aggregation and client model updates and uploads. Starting from the cloud center server and moving down each level, the algorithm selects edge servers that can complete model aggregation and upload within the specified time. Similarly, in the second layer, clients who can complete model updates and upload them within the specified time are selected to participate in model training. Compared to the traditional way of randomly selecting a fixed number of devices to participate in training, this algorithm enables the system to aggregate as many edge servers and clients as possible in the same time frame to participate in model training and updates, thereby improving the training accuracy of the model.
- We conducted simulation experiments on the multi-level federated edge learning algorithm and the client and edge server selection algorithm. The results show that the multi-level federated edge learning algorithm can effectively reduce model training time and improve efficiency as the number of clients increases. Furthermore, compared to the baseline algorithm, the client and edge server selection algorithm can aggregate more clients for training in the same time frame, thereby improving the training accuracy of the model.
2. Related Work
3. System Model
3.1. Multi-Level Federated Edge Learning Algorithm Based on Client and Edge Server Selection
- Local model update
- Local model transmission
- Edge model aggregation
- Edge model transmission
| Algorithm 1: Multi-level federated edge learning algorithm based on client and edge server selection. |
| 1 Initialization: currLevel =Y, , 2 while T < or currAccuracy < A do 3 while currLevel > 0 do 4 Resource aggregation and analysis; 5 currLevel --; 6 end while 7 while currLevel < Y do 8 Client and Edge server selection; 9 currLevel ++; 10 end while 11 While currLevel > 0 do 12 Model downward distribution; 13 currLevel --; 14 end while 15 While currLevel < Y do 16 Client Scheduled Update and Upload; 17 edge server Aggregation model in a certain time; 18 currLevel ++; 19 end while 20 While currLevel = Y do 21 S aggregate the model; 22 end while 23 end while |
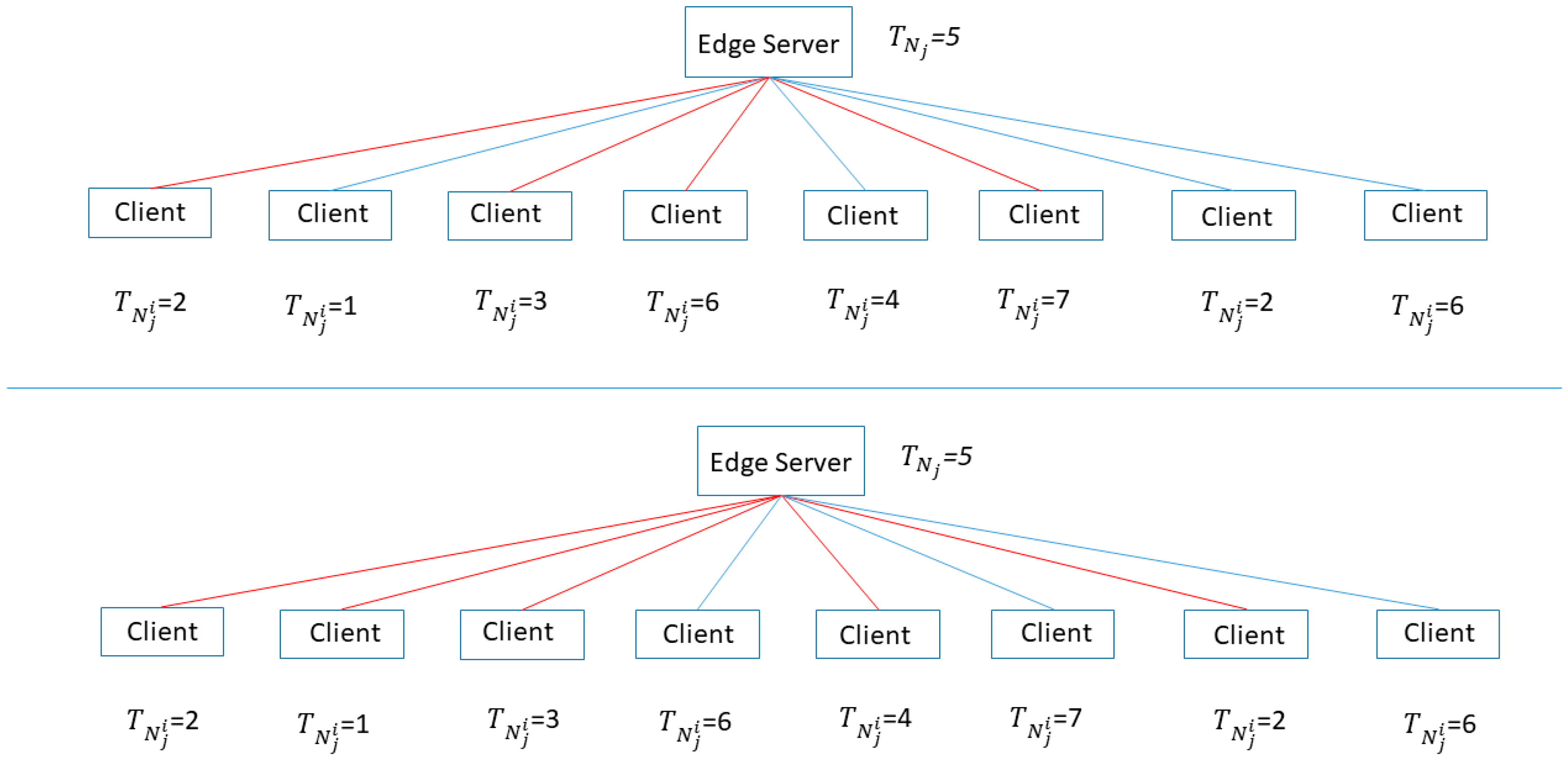
3.2. Client and Edge Server Selection Algorithm ()
- (1)
- Edge server selection:
- (2)
- Client selection
| Algorithm 2: Client and Edge server selection algorithm. |
| 1 Initialization , , , 2 If currLevel > 2 and currLevel < Y then 3 for in do 4 ; 5 then 6 Add to ; 7 end if 8 end for 9 end if 10 If currLevel = 2 then 11 for in do 12 ; 13 ; 14 if then 15 Add to ; 16 end if 17 end for 18 end if |
4. Experiment
4.1. Simulation Settings
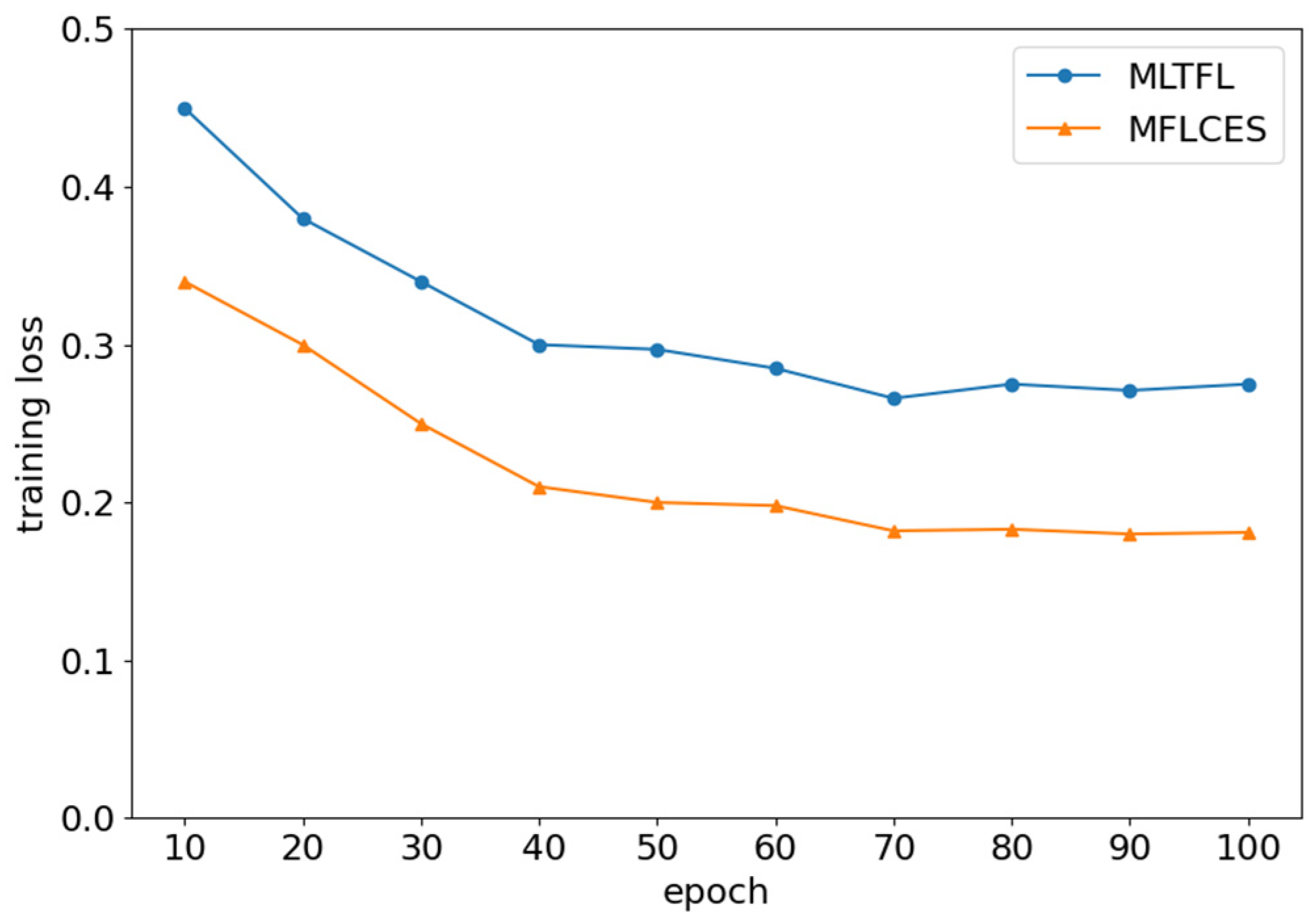
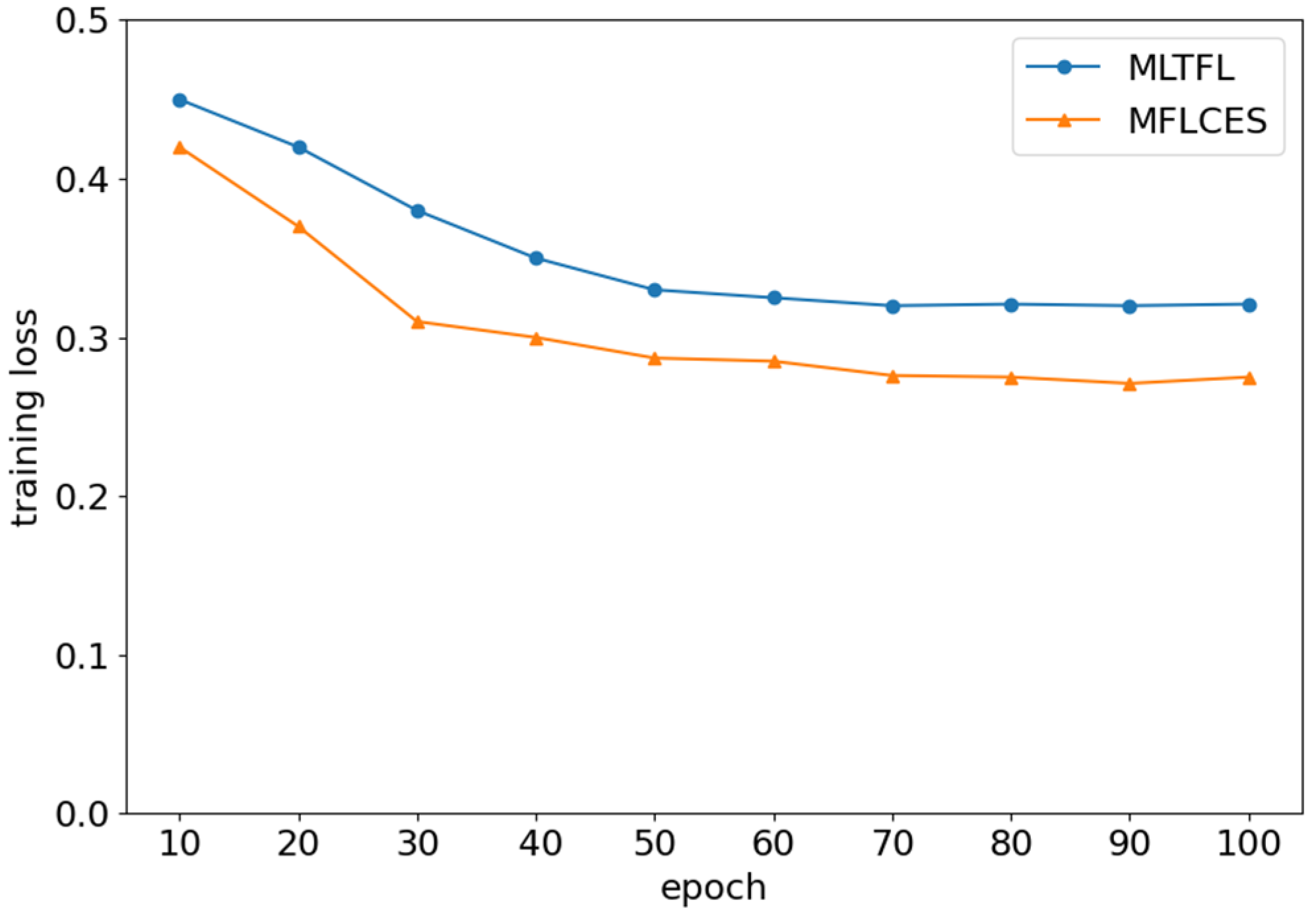
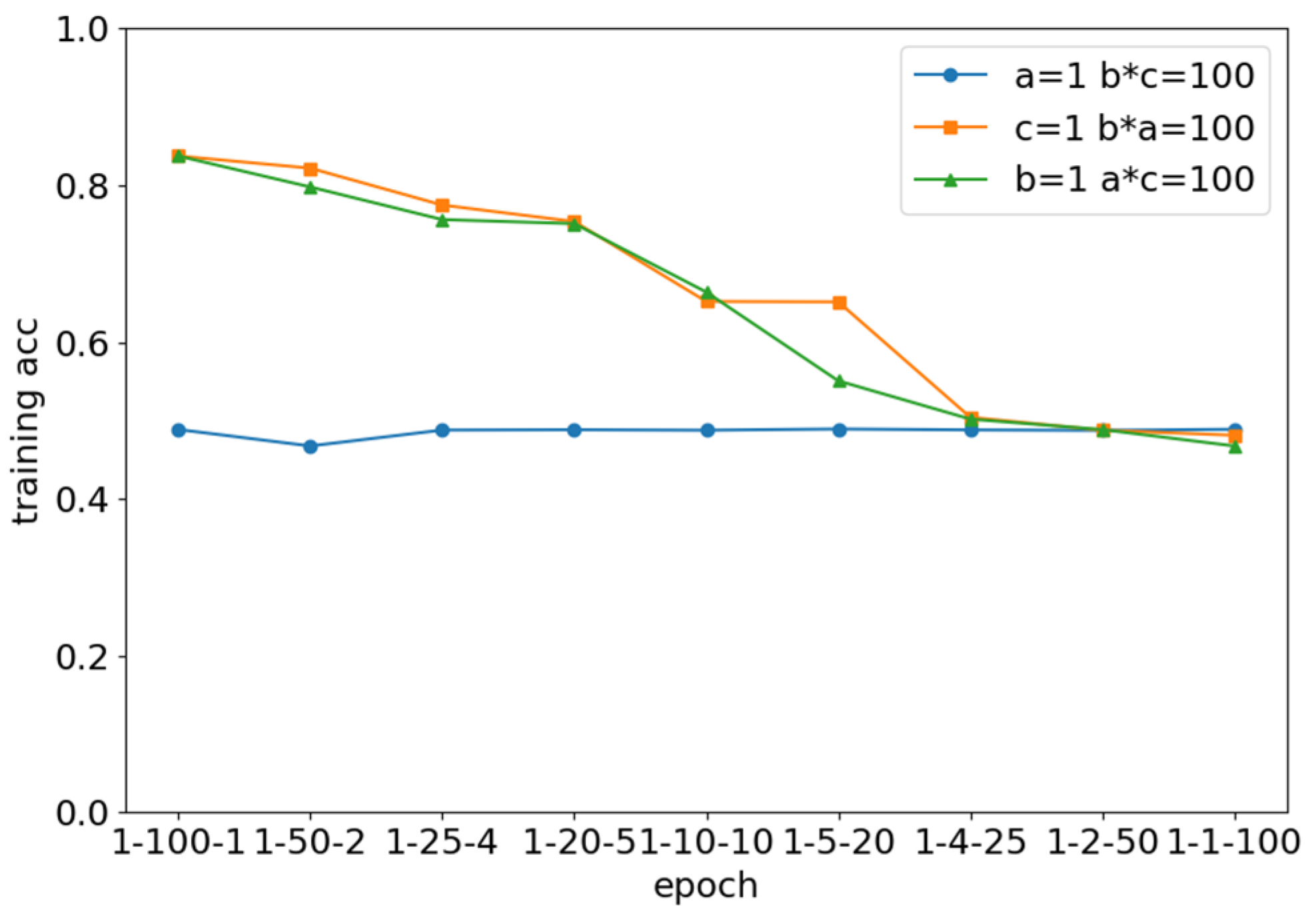
4.2. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Matteussi, K.J.; Zanchetta, B.F.; Bertoncello, G.; Santos, J.D.D.D.; Anjos, J.C.S.D.; Geyer, C.F.R. Analysis and Performance Evaluation of Deep Learning on Big Data. In Proceedings of the 2019 IEEE Symposium on Computers and Communications (ISCC), Barcelona, Spain, 29 June–3 July 2019; pp. 1–6. [Google Scholar]
- Tak, A.; Cherkaoui, S. Federated Edge Learning: Design Issues and Challenges. IEEE Netw. 2021, 35, 252–258. [Google Scholar] [CrossRef]
- Mcmahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 20–22 April 2017; Available online: https://arxiv.org/abs/1602.05629 (accessed on 18 May 2023).
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Communication-Efficient Federated Learning for Digital Twin Edge Networks in Industrial IoT. IEEE Trans. Ind. Inform. 2021, 17, 5709–5718. [Google Scholar] [CrossRef]
- Han, D.J.; Choi, M.; Park, J.; Moon, J. FedMes: Speeding Up Federated Learning with Multiple Edge Servers. IEEE J. Sel. Areas Commun. 2021, 39, 3870–3885. [Google Scholar] [CrossRef]
- Zhou, T.; Li, X.; Pan, C.; Zhou, M.; Yao, Y. Multi-server federated edge learning for low power consumption wireless resource allocation based on user QoE. J. Commun. Netw. 2021, 23, 463–472. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; Song, S.H.; Letaief, K.B. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Mills, J.; Hu, J.; Min, G. Multi-Task Federated Learning for Personalised Deep Neural Networks in Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 630–641. [Google Scholar] [CrossRef]
- Briggs, C.; Andras, P.; Zhong, F. A Review of Privacy Preserving Federated Learning for Private IoT Analytics. arXiv 2020, arXiv:2004.11794. [Google Scholar]
- Nishio, T.; Yonetani, R. Client Selection for Federated Learning with Heterogeneous Resources in Mobile Edge. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Tran, N.H.; Bao, W.; Zomaya, A.; Nguyen, M.N.H.; Hong, C.S. Federated Learning over Wireless Networks: Optimization Model Design and Analysis. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1387–1395. [Google Scholar]
- Liu, D.; Deng, H.; Huang, L.; Zhang, S.; Yin, Y.; Fu, Z. LoAdaBoost: Loss-based AdaBoost federated machine learning with reduced computational complexity on IID and non-IID intensive care data. arXiv 2018, arXiv:1811.12629. [Google Scholar]
- Ren, J.; Yu, G.; Ding, G. Accelerating DNN Training in Wireless Federated Edge Learning Systems. IEEE J. Sel. Areas Commun. 2021, 39, 219–232. [Google Scholar] [CrossRef]
- Zeng, Q.; Du, Y.; Huang, K.; Leung, K.K. Energy-Efficient Radio Resource Allocation for Federated Edge Learning In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops). Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Yoshida, N.; Nishio, T.; Morikura, M.; Yamamoto, K.; Yonetani, R. Hybrid-FL for Wireless Networks: Cooperative Learning Mechanism Using Non-IID Data. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–7. [Google Scholar]
- Luo, S.; Chen, X.; Wu, Q.; Zhou, Z.; Yu, S. HFEL: Joint Edge Association and Resource Allocation for Cost-Efficient Hierarchical Federated Edge Learning. IEEE Trans. Wirel. Commun. 2020, 19, 6535–6548. [Google Scholar] [CrossRef]
- Chai, H.; Leng, S.; Chen, Y.; Zhang, K. A Hierarchical Blockchain-Enabled Federated Learning Algorithm for Knowledge Sharing in Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3975–3986. [Google Scholar] [CrossRef]
- Wu, J.; Liu, Q.; Huang, Z.; Ning, Y.; Wang, H.; Chen, E.; Yi, J.; Zhou, B. Hierarchical Personalized Federated Learning for User Modeling. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 957–968. [Google Scholar]
- Su, Z.; Wang, Y.; Luan, T.H.; Zhang, N.; Li, F.; Chen, T.; Cao, H. Secure and Efficient Federated Learning for Smart Grid with Edge-Cloud Collaboration. IEEE Trans. Ind. Inform. 2022, 18, 1333–1344. [Google Scholar] [CrossRef]
- Shi, L.; Shu, J.; Zhang, W.; Liu, Y. HFL-DP: Hierarchical Federated Learning with Differential Privacy. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–7. [Google Scholar]
- Majidi, F.; Khayyambashi, M.R.; Barekatain, B. HFDRL: An Intelligent Dynamic Cooperate Cashing Method Based on Hierarchical Federated Deep Reinforcement Learning in Edge-Enabled IoT. IEEE Internet Things J. 2022, 9, 1402–1413. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Ng, J.S.; Xiong, Z.; Jin, J.; Zhang, Y.; Niyato, D.; Leung, C.; Miao, C. Decentralized Edge Intelligence: A Dynamic Resource Allocation Framework for Hierarchical Federated Learning. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 536–550. [Google Scholar] [CrossRef]
- Abad, M.; Ozfatura, E.; Gunduz, D.; Ercetin, O. Hierarchical Federated Learning ACROSS Heterogeneous Cellular Networks. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2020, Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Briggs, C.; Fan, Z.; Andras, P. Federated learning with hierarchical clustering of local updates to improve training on non-IID data. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar]
- Luo, L.; Cai, Q.; Li, Z.; Yu, H. Joint Client Selection and Resource Allocation for Federated Learning in Mobile Edge Networks. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 1218–1223. [Google Scholar]
- Yu, C.; Shen, S.; Zhang, K.; Zhao, H.; Shi, Y. Energy-Aware Device Scheduling for Joint Federated Learning in Edge-assisted Internet of Agriculture Things. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 1140–1145. [Google Scholar]
- Sun, F.; Zhang, Z.; Zeadally, S.; Han, G.; Tong, S. Edge Computing-Enabled Internet of Vehicles: Towards Federated Learning Empowered Scheduling. IEEE Trans. Veh. Technol. 2022, 71, 10088–10103. [Google Scholar] [CrossRef]
- Liu, J.; Xu, H.; Wang, L.; Xu, Y.; Qian, C.; Huang, J.; Huang, H. Adaptive Asynchronous Federated Learning in Resource-Constrained Edge Computing. IEEE Trans. Mob. Comput. 2023, 22, 674–690. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, L.; Ma, C.; Li, J.; Wang, J.; Wang, Q.; Yu, S. LSFL: A Lightweight and Secure Federated Learning Scheme for Edge Computing. IEEE Trans. Inf. Secur. 2023, 18, 365–379. [Google Scholar] [CrossRef]
- Gao, Y.; Li, J.; Zhou, Y.; Xiao, F.; Liu, H. Optimization Methods For Large-Scale Machine Learning. In Proceedings of the 2021 18th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 17–19 December 2021; pp. 304–308. [Google Scholar]
- Konečný, J.; Qu, Z.; Richtárik, P. Semi-stochastic coordinate descent. Optim. Methods Softw. 2017, 32, 993–1005. [Google Scholar] [CrossRef] [Green Version]
- Vu, T.T.; Ngo, D.T.; Tran, N.H.; Ngo, H.Q.; Dao, M.N.; Middleton, R.H. Cell-Free Massive MIMO for Wireless Federated Learning. IEEE Trans. Wirel. Commun. 2020, 19, 6377–6392. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Advantages | Disadvantages | |
|---|---|---|
| Two-level Federated Learning | Faster training speed with fewer clients | Weak device scalability. Large training delay when there are many clients. |
| Three-level Federated Learning | Strong device scalability, while reducing training latency and energy consumption. | Usually designed as three tiers and has not been explored for model training over larger geographic areas. |
| Two-level Federated Learning | [8,9,10,11,14,15,17] |
| Three-level Federated Learning | [6,12,13,16,18,19,20,24,25,26,27,28,29,30,31] |
| Symbols | Definition | Symbols | Definition |
|---|---|---|---|
| Global model parameters | Bandwidth allocation ratio for client | ||
| A set of clients | Achievable transmission rate of client | ||
| The -th client of the first level | Channel background noise | ||
| The second-level -th edge server connected to the client in the first level. | Transmitted power | ||
| The -th edge server of the -th level ) | Channel gain of client | ||
| The -th sample of the -th client and its corresponding tagged output | Data size of the client model parameter | ||
| System levels | Dataset of all clients under edge server | ||
| Cloud center server | Rate of edge server upload model | ||
| The dataset owned by the -th client | Latency of edge servers to upload their edge models | ||
| Global loss function | Dataset of all clients under the cloud center server | ||
| Local loss function | Final cut-off time | ||
| Updating the index of a step | The final accuracy to be achieved | ||
| Gradient descent step | Edge server selection deadline | ||
| The required accuracy of the model trained by the client | Client selection cut-off time | ||
| Number of client local iterations | Time required for edge server aggregation | ||
| A constant related to the number of training iterations for a client | frequency assigned to client | ||
| Number of cycles required for client to process one sample data | Total delay of local iterations of client | ||
| Total bandwidth provided by | Transmission delay of model parameters uploaded by client |
| The number of clients | 400 | 600 | 800 | 1000 |
| The number of edge servers in the second level | 40 | 60 | 80 | 100 |
| The number of edge servers in the third level | 20 | 30 | 40 | 50 |
| The number of cloud center servers | 1 | 1 | 1 | 1 |
| The number of clients | 400 | 600 | 800 | 1000 |
| The number of cloud center servers | 1 | 1 | 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Duan, S.; Wang, S.; Liu, Y.; Li, X. MFLCES: Multi-Level Federated Edge Learning Algorithm Based on Client and Edge Server Selection. Electronics 2023, 12, 2689. https://doi.org/10.3390/electronics12122689
Liu Z, Duan S, Wang S, Liu Y, Li X. MFLCES: Multi-Level Federated Edge Learning Algorithm Based on Client and Edge Server Selection. Electronics. 2023; 12(12):2689. https://doi.org/10.3390/electronics12122689
Chicago/Turabian StyleLiu, Zhenpeng, Sichen Duan, Shuo Wang, Yi Liu, and Xiaofei Li. 2023. "MFLCES: Multi-Level Federated Edge Learning Algorithm Based on Client and Edge Server Selection" Electronics 12, no. 12: 2689. https://doi.org/10.3390/electronics12122689