5.1. Data Acquisition
A total of two means of manufacturing classified data were used for the experiments in this paper, as follows. The power system attack dataset [
16] was provided by Mississippi State University, which was generated by simulating a power system with complex electronic equipment and monitoring system interaction. The power system structure is shown in
Figure 5. G1 and G2 are power generators, IED1 through IED4 are Intelligent Electronic Devices (IEDs) that can switch the breakers (R1 through R4) on or off, and the substation network is responsible for controlling the relays and transmitting information. The IEDs use a distance protection scheme, which trips the breaker on detected faults, regardless of whether they are valid or faked, since they have no internal validation to detect the difference. The monitoring system records not only the physical information about the operation of each of the four relays, but also the panel, alarm, and relay log information of the corresponding relays. In addition to the normal operating outage events of this power system, as the substation is connected via the network, attackers can rely on the network to inject attack commands and disguise the system outage, thus disrupting the staff and ensuring that they are not able to identify the state of the outage event being attacked, which disrupts the normal operation of the system and causes the industrial data records to be untrue. The dataset contains 37 power system event scenarios, and the dichotomous dataset is a classification of the 37 event scenarios into attack scenarios (28) and normal events (9). Each data sample contains 128 feature messages, of which 116 feature messages consist of four phasor measurement units (PMUs); each PMU contains 29 types of measurement. The index of each column is in the form of ‘R#-Signal Reference’ that indicates a type of measurement from a PMU, specified by ‘R#’. For example, ‘R1-PA1:VH’ means the Phase A voltage phase angle measured by PMU IED1. After that, there are 12 columns for control panel information, Snort alerts, and relay logs of the 4 PMU/relay.
The Hard Drive Failure Detection Dataset [
17] is available in BackBlaze’s data center and the data collect the S.M.A.R.T. attributes of the ST4000DM000 model hard drive, a self-diagnostic technique that can be used to predict hard drive failures. This dataset contains information including the drive’s SMART attributes, as well as characteristics such as model, serial number, date, and capacity. After the dataset has been filtered and processed for valid information, the hard drive failure detection dataset has a feature count of 11, with two states of “normal” and “failed” hard drives.
5.2. Dirichlet Divides Heterogeneous Data
The Dirichlet distribution is a common multidimensional continuous distribution that plays an important role in probability statistics and is usually denoted by
. Its parameters are controlled by the positive real vector
, and the distribution of this vector is also a probability distribution, so the term “distribution of probability distributions” can also be used to describe the Dirichlet distribution. For the federated learning experimental scenario, the IID dataset is sampled according to the Dirichlet distribution to obtain the non-IID dataset. If there are
N category labels and
K clients, the samples of each category label need to be divided on different clients in different proportions. Let matrix
be the category label distribution matrix, whose row vector
represents the probability distribution vector of category
N on different clients (each dimension represents the proportion of samples of category
N divided on different clients), and this random vector is sampled from the Dirichlet distribution. Therefore, the local training datasets held by each participant can be obtained as non-IID datasets by sampling the source datasets with the same probability as the probability of the parameter vector
. A sample of participant non-IID data can be generated by sampling the probabilities of the Dirichlet distribution corresponding to Equation (
11):
By varying the values of the parameters, different participant local datasets can be sampled according to the probability distribution of Equation (
11). At
, the local data sample set for each participant is simply a random sample from a class of samples. At
, the prior distribution of the source dataset coincides with the distribution of the local data generated by each participant. That is, the smaller the
, the more dispersed the distribution; the larger the
, the more that distribution tends to be uniformly distributed. Therefore, if the prior distribution is IID, the distribution
q becomes increasingly different as
becomes smaller; as
increases, the distribution
q becomes increasingly similar.
The parameter
can have an impact on the range of bias in data generation. Taking the manufacturing data power system attack dataset [
15] as an example, the
axis in
Figure 6 indicates the ID of each participant in federated learning, the
axis indicates the label type of each participant’s sample set, and the
indicates the number of data samples in the corresponding category for each participant. In
Figure 6a, when
is set to 1, the data distribution of each participant is heavily skewed, with large differences in the number of samples for different participants in the same category, and the distribution of categories among different participants is also different. When
is taken as 10 in
Figure 6c, the data distribution across participants is skewed, but the variation is small and participants still hold different numbers of category labels. For
value of 50 in
Figure 6d, the data distribution across participants in this scenario is slightly skewed and the variation between participants is small, close to the distribution state of the IID dataset.
5.4. Experimenting with Data Heterogeneity in Smart Manufacturing
In this section, two separate experiments are conducted to better explore the effect of manufacturing data on FedAvg. Firstly, an experimental analysis of the effect of IID and non-IID data on FedAvg under different parameters is presented, and then the effect of different degrees of distribution on FedAvg under the non-IID setting is verified.
(1) Effect of IID and Non-IID data on FedAvg
IID data are a strong assumption in machine learning, especially since manufacturing data tend to exist as non-independent identical distributions. To verify the fact that the federated learning algorithm has significant accuracy degradation on non-IID manufacturing data, this section conducts comparative experiments on the power system attack dataset [
15], which is described in detail in
Section 4. The experiments are set up with five federated learning clients, and non-IID is partitioned according to a Dirichlet distribution with hyperparameter
. The number of federated global communications was set to 50, the classical FedAvg algorithm was used as the federated learning algorithm, and the MLP model was chosen for the network model. Three parameter settings were used experimentally for non-IID, as shown in
Table 1.
The specific experimental results are shown in
Figure 7, where
Figure 7a shows the accuracy variation graphs based on FedAvg using the MLP local model on the power system attack dataset, and
Figure 7b shows its loss degradation variation. There are three different non-IID parameter settings in
Figure 7a, with both ordinal numbers 1 and 3 showing some reduction in accuracy compared to the independent identically distributed setting of ordinal number 0, with an average drop in accuracy of 6.12% and 5.98% in the global iteration, respectively. Although the accuracy of ordinal number 2 is higher than the IID data in some of the communication rounds, its training process becomes more oscillating, with an average reduction in accuracy of 6.03% compared to the IID setting in the global iteration. The non-IID data in
Figure 7b showed a higher rate of decline than the IID data setting for all three parameter settings. Observing the curve changes, it can be seen that the IID data with the ordinal number 0 setting showed a stable loss decline with little fluctuation. For the non-IID data, the loss variation curves for each parameter setting fluctuated to varying degrees, with the largest oscillation in loss decline being noted for the No. 2 setting. The above experimental results can be interpreted as follows. Due to the different distributions of the non-IID data samples, the increased dispersion of data features may cause some samples to appear more frequently and some samples to appear less frequently. The model does not balance the contribution of each sample well during training and the features are not sufficiently learned, resulting in overfitting of the model to the samples that occur more frequently and large differences between local model parameters, causing large fluctuations in accuracy and loss variation.
(2) Effect of different degrees of Non-IID data on FedAvg
In addition, we also verified the effect of different degrees of non-independent identically distributed data on FedAvg by varying the hyperparameters
dividing different non-IID data experiments with Dirichlet. A total of four different degrees of non-independent identically distributed data were set up for the experiments, i.e., the hyperparameters
were set to 1, 5, 10, and 50, respectively, and the data distribution is illustrated in
Figure 6, where BatchSize was set to 10 and epoch to 1.
The performance of the FedAvg algorithm for different data distributions under the power system attack dataset is shown in
Figure 8. The rising variation in the accuracy of FedAvg is illustrated in
Figure 8a. As the parameter
becomes larger, the more homogeneously the data tend to become distributed and the better the model it obtains. This phenomenon can be interpreted as follows. As the data become more correlated, the relationships between them become more complex and subtle. The model can gain more information from these small differences, and this information can help the model to better capture the relationships between the data, and thus improve the algorithm performance. As can be seen in
Figure 8b, as the loss decreases as the parameter
changes, the smaller the
value, the more the data tend to be non-independently and identically distributed, and the larger the loss value obtained from training based on the data. This result can be explained by the fact that when the data are non-independently and identically distributed, the correlation between them may change, leading to larger errors in the model during training; therefore, the training loss increases. For example, when
, these data tend to be non-independently and identically distributed to a large extent, and it is difficult for the model to capture the correlation between the complex data; therefore, the model has large fluctuations in loss during training.
The FedAvg algorithm uses a gradient descent machine learning optimization algorithm, where each sample of data in the stochastic gradient descent algorithm represents the entire data distribution; because the training set for each client is IID, the gradient information calculated from the training set can also represent the gradient values of all the data. However, for non-independently distributed data, the gradients cannot be derived without error for all the data. In the FedAvg algorithm, each client performs the gradient descent algorithm based on the held data only, and the direction of parameter updates for each client will be skewed under non-independently and identically distributed data, leading to a reduction in model training efficiency.
5.5. Experiments Comparing Client Selection Methods
This section tests the training effectiveness and convergence of the methods in this chapter by comparing the random selection strategy of the FedAvg algorithm. To fairly verify the differences between this paper’s method and FedAvg, we set the parameter of this paper’s method FedMPCCS and the corresponding parameter C of FedAvg separately to ensure that the number of clients being selected was the same. The local model was chosen as MLP, consisting of an input layer, two implicit layers (containing 256 and 128 neurons, respectively), a dropout layer (where half of the neurons are inactivated), and an output layer. The training parameters were the same for each client, with , = 100, . Five federated learning clients were set up, and the data heterogeneity of each client was divided by Dirichlet distribution according to to construct a local dataset with uneven label categories. Since different datasets have different communication rounds for convergence in federated learning, global communication rounds of 200 and 50 were set on the power system attack dataset and the hard disk failure detection dataset, respectively.
Figure 9 shows the loss drop curves of FedMPCCS and FedAvg for the same number of clients on the power system attack datasets. In
Figure 9a, FedMPCCS suffered from a faster loss drop rate than FedAvg from Round = 0 to Round = 50, and in
Figure 9b with parameter setting
; after Round = 25, the rate of loss decline is significantly better for FedMPCCS than for FedAvg, and FedAvg declines slowly after Round = 100. In
Figure 9c, FedMPCCS loss is shown to decrease faster than FedAvg after Round = 50.
Again, the performance on the hard disk failure detection dataset is shown in
Figure 10, and it collectively appears that FedMPCCS with all three parameter settings outperforms FedAvg to varying degrees in terms of loss reduction rate.
Figure 11 shows the change in model accuracy for the same number of clients on the power system attack dataset for FedMPCCS and FedAvg. In
Figure 11a, the rate of improvement in accuracy between Round = 0 and Round = 100 is significantly higher for FedMPCCS than for the hyperparameter FedAvg. In
Figure 11b, FedMPCCS shows a significant improvement in accuracy after Round = 75 compared to FedAvg in terms of change in accuracy, while FedAvg’s change in accuracy tends to fit.
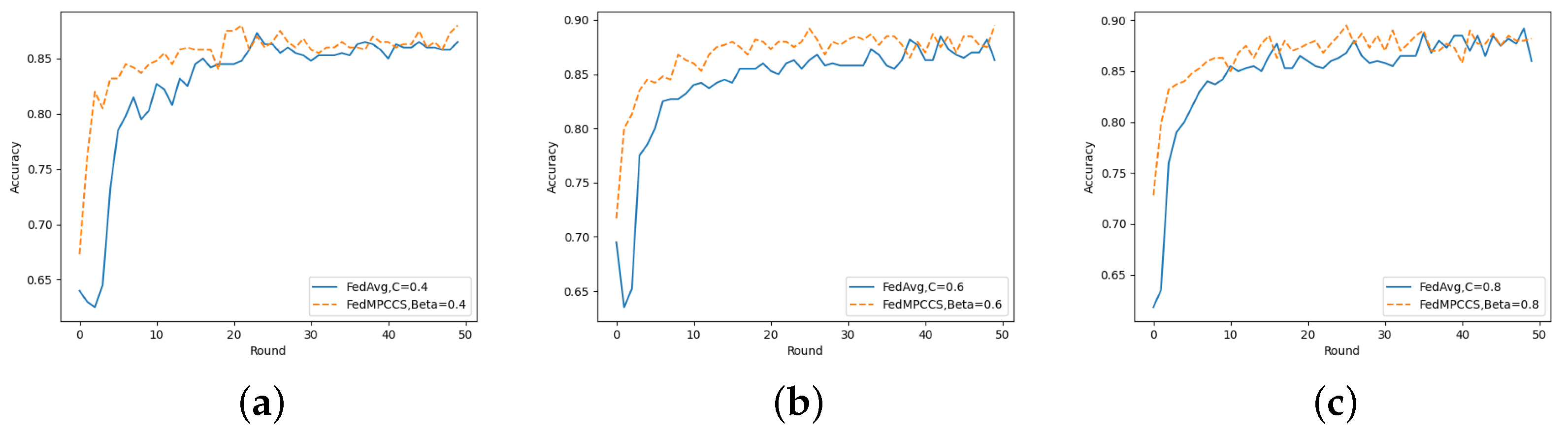
Figure 12 shows the variation in model accuracy for the same number of clients on the hard disk failure detection dataset for FedMPCCS and FedAvg. FedMPCCS in
Figure 12a shows a faster accuracy improvement than FedAvg up to Round = 20, and the accuracy improvement of both algorithms plateaus after Round = 20. In
Figure 12b, FedMPCCS has a significantly higher accuracy than FedAvg up to Round = 40. FedMPCCS in
Figure 12c outperforms FedAvg for the vast majority of global communication rounds.
To compare the magnitude of the improvement in FedMPCCS with FedAvg on the two datasets, we counted and compared the average improvement in global communication rounds in accuracy of FedMPCCS over FedAvg, and the results are shown in
Table 2:














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}