1. Introduction
Navigation has a long history of development and plays an indispensable role in human production and life. Traditional navigation systems such as satellite and inertial navigation can no longer meet the requirements of long-endurance and high-precision navigation development in applications [
1]. Geomagnetic navigation uses the features of the geomagnetic field for navigation and positioning, which has the advantages of being passive, all-day, and all-weather [
2,
3,
4,
5]. Additionally, it has become a new method for combined positioning of indoor and underground engineering [
6].
The accuracy of geomagnetic matching navigation positioning is related to a large extent to the suitability of the geomagnetic map [
7]. The suitability of the geomagnetic map represents the corresponding relationship between geomagnetic features and geographical location. The suitability directly affects the accuracy of geomagnetic matching navigation and positioning [
8,
9]. The matching area with good suitability contains more abundant geomagnetic features and information [
10,
11]. The analysis of geomagnetic suitability is the basis and premise of geomagnetic matching navigation positioning [
12]. Therefore, the study of geomagnetic suitability analysis is of great significance.
In the current literature, researchers mainly improve the geomagnetic suitability evaluation method by constructing comprehensive suitability feature parameters or introducing intelligent classification algorithms.
Chen Y.R. et al. [
13] used the fractal dimension as the feature parameter of geomagnetic suitability to evaluate the suitability. The outcomes demonstrated that this method had the advantages of a small calculation, good anti-interference, and simple implementation. Wang X.L. et al. [
14] compared the selection methods of matching area based on geomagnetic suitability feature parameters and based on the information entropy of geomagnetic suitability feature parameters. The latter was found to be more effective.
Zhao J.H. et al. [
15] proposed a matching area division method for underwater geomagnetic navigation based on the geomagnetic symbiosis matrix. This method can respond to the changing features of the geomagnetic field in multiple directions. Zhu Z.L. et al. [
16] studied the sensitivity of multi-attribute weight in geomagnetic suitability evaluation using the Weighted Product Model (WPM) method. This study obtained the order of sensitivity of geomagnetic suitability indicators, which had certain reference significance for setting the geomagnetic map suitability feature weights.
Huang Z.X. et al. [
17] adopted statistical parameters such as entropy and roughness as geomagnetic feature parameters. The correlation analysis of the feature parameters was carried out based on the matching test, and then the performance analysis of the matching area was realized. Liu Y.X. et al. [
18] presented a new approach to selecting geomagnetic matching areas by integrating multiple feature parameters. The proposed approach was proven to be feasible through the simulation test. Li D.W. et al. [
19] proposed a method to construct a comprehensive evaluation value based on factor analysis and entropy methods for suitability evaluation. The matching algorithm was used to simulate the experiment. The experiment verified the high agreement between comprehensive evaluation value and matching probability.
Wang Z. et al. [
20] defined the concept of credibility and analyzed the credibility between four commonly used geomagnetic feature parameters and matching probability. It was found that a single feature parameter cannot be used as an effective basis for geomagnetic suitability evaluation. Wang P. et al. [
21] comprehensively considered four characteristic parameters of a geomagnetic map. The decision method containing maximum deviation and entropy was used to construct the comprehensive evaluation value. The experiment was carried out to prove that the comprehensive evaluation value can be used as a quantitative basis for geomagnetic suitability analysis. Wang L.H. et al. [
22] proposed a fuzzy, vague set evaluation method with more information based on the fuzzy decision method. Based on this method, the comprehensive evaluation value was constructed, and the simulation experiment was carried out. It was found that the matching error of the region with a large comprehensive evaluation value was small. Zhu Z.L et al. [
23] fused the five indicators and used entropy technology to modify the weight of each indicator obtained based on traditional fuzzy evaluation methods to obtain the comprehensive evaluation value. The traditional Mean Square Differences (MSD) and Mean Absolute Differences (MAD) matching algorithms were used for simulation experiments. It was found that the comprehensive evaluation value and the matching probability were highly consistent, and the comprehensive evaluation value can comprehensively evaluate the geomagnetic suitability.
Zhong Y. et al. [
24] used five main feature parameters as fuzzy indicators for weighted analysis to obtain a comprehensive evaluation value. An experimental study was conducted on the basis of the non-tracking Kalman filter with geomagnetic anomalies and the anomaly grid data of some waters in the South China Sea. Experiments showed that the proposed method was reliable. Zhang H. et al. [
25] established a comprehensive evaluation model combining Principal Component Analysis (PCA) and Analytic Hierarchy Process (AHP) algorithms, which was used to evaluate the suitability. He Y.J. et al. conducted a comprehensive geomagnetic suitability evaluation based on AHP, the information entropy method [
26], and the gray correlation method [
27], respectively. The correlative matching algorithm was used to test it, and it was found that the comprehensive evaluation value and the matching probability are highly consistent.
Related experts and scholars on geomagnetic suitability evaluation have done a lot of work and achieved fruitful results by constructing the comprehensive evaluation value. The index system of this research is relatively simple, and the workload is large and cumbersome. There are a few types of research on suitability evaluation using classification algorithms. Additionally, most of them adopt the BPNN algorithm or an optimized BPNN algorithm. Zhang K. et al. [
28] suggested automatic recognition and division methods for background field matching/mismatch areas based on BPNN. On the basis of the BPNN algorithm, Wang C.Y. et al. [
29] combined PCA and GA to gain improved methods to evaluate geomagnetic suitability and improve classification accuracy. Wang J.H. et al. [
30] studied the suitability of downhole geomagnetism by using the BPNN algorithm based on contribution factors. The accuracy of training sets was 95%, and the accuracy of test sets was close to 73%. The intelligent classification algorithm for suitability evaluation can decrease the subjective impact. At the same time, more geomagnetic suitability feature indicators can be involved in the calculation, making the evaluation results more comprehensive and improving the efficiency of geomagnetic suitability evaluation. It will be the focus of future geomagnetic suitability research.
The GWO algorithm is a population intelligence algorithm that has the characteristics of simple operation, few parameters, and easy implementation. It is often used to optimize the BPNN algorithm and is applied in engineering practice. Bao W. et al. [
31], based on the battery operation data of the electric vehicle cloud platform with a sampling period of 10 s, used the data to test the unoptimized BPNN, GWO-BPNN, and PSO-BPNN. The experimental results indicate that the GWO-BPNN has high accuracy in predicting the SOC of electric vehicle batteries. Jing W.Q. et al. [
32] proposed an improved GWO-BPNN energy consumption prediction model, which was validated using actual operating data of an office building in Xi’an. The prediction results showed that the prediction accuracy of the improved GWO-BPNN model was much higher than that of traditional prediction models. Guo Cui et al. [
33] used the gray wolf population algorithm to optimize the BPNN to establish a dynamic model of the accelerometer and simulate the input and output signals. The results show that, compared with the BPNN algorithm, the algorithm has improved its solution accuracy by 43.4% after optimization and improvement. However, due to its tendency to fall into local optima, the GWO algorithm needs to be improved to achieve a balance between local and global search. Li Z. et al. [
34] proposed a binary version of the local adversarial learning golden sine gray wolf optimization algorithm and verified its high search accuracy. Pan H. et al. [
35] proposed an improved gray wolf optimization algorithm for feature selection of high-dimensional data. Pan T et al. [
36] integrated the nonlinear convergence factor and position mutation strategy into GWO to solve the problem of complex and non-linear components and prevent the gray wolf algorithm from falling into a local optimum.
Traditional suitability evaluation methods were mostly applied in the air and underwater. There was little research on downhole suitability evaluation methods. To select more suitable areas for matching, this paper constructs an intelligent model for geomagnetic suitability evaluation based on multi-algorithm coupling. Firstly, a mixed sampling method was constructed by combining SMOTE and Tomek Links to process the original datasets collected from 41 underground engineering projects and obtain a new dataset. Secondly, a hybrid optimization algorithm based on the DLH algorithm and the GWO algorithm is used to optimize the parameters of the BPNN algorithm, and the DLH-GWO-BPNN algorithm is used to construct a geomagnetic suitability model. Then, using accuracy, recall, AUC value, and ROC curve as evaluation indicators, PSO-BPNN, WOA-BPNN, GA-BPNN, and GWO-BPNN algorithms were selected as compared methods to verify the predictable ability of the DLH-GWO-BPNN. The results showed that this model can effectively evaluate geomagnetic suitability and has reference significance for intelligent geomagnetic navigation.
The remainder of this paper is organized as follows: The GWO algorithm and the BPNN algorithm are described in
Section 2; the DLH-GWO-BPNN model is shown in
Section 3;
Section 4 shows the data processing results and the analysis results; and the conclusion is given in
Section 5.
2. Related Work
2.1. GWO Algorithm
The gray wolf optimization (GWO) algorithm is an optimization method for swarm intelligence [
37]. It simulates the leading status and relatively complete hunting process of gray wolves in their natural environment. Additionally, it is widely used because of its simple structure, few adjustable parameters, and strong convergence performance.
The algorithmic content is as follows:
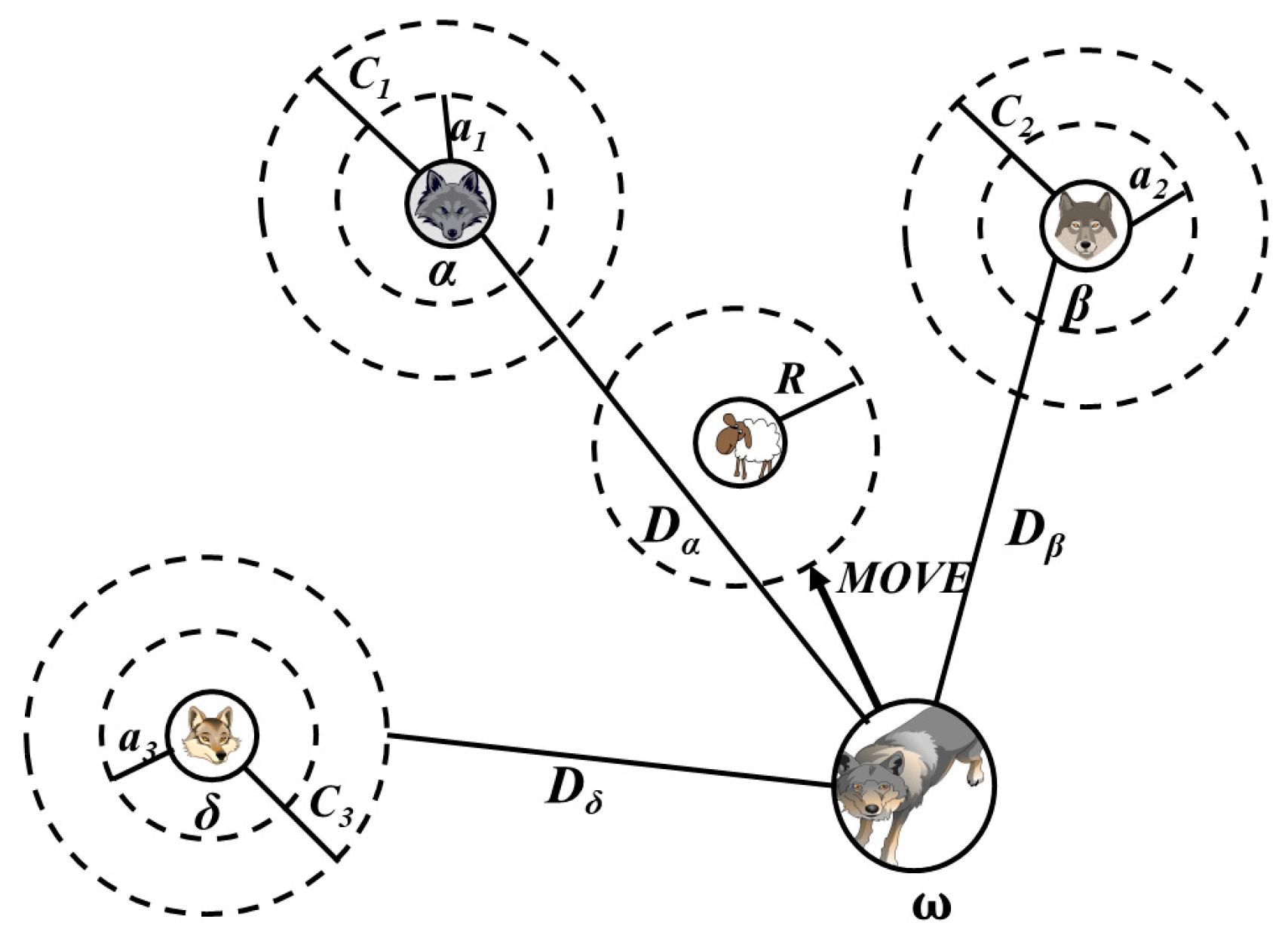
In GWO algorithm, there are four levels of wolves, as illustrated in
Figure 1.
α wolf is the head gray wolf.
α wolf, as the leader, is in charge of all kinds of activities among the wolves and is the most capable of managing them.
β wolf obeys the orders of
α, can dominate other gray wolves, and is the best successor of the head gray wolf.
δ wolf assists the decision-making of the
β wolf and obeys the management of the
α wolf and
β wolf. The
ω wolf is the last level of the social hierarchy, and its presence effectively prevents internal problems such as fighting each other.
The GWO algorithm includes five parts:
In GWO algorithm, there are four levels of gray wolf population: α, β, δ and ω. The rank of society is α, β, δ, and ω. The α, β, and δ are also the three gray wolves with the best fitness in each generation’s population, which are constantly updated in the iterative process of the GWO algorithm.
- (2)
Surrounding prey
α,
β, and
δ directly capture prey.
ω wolf surrounds prey. Its surrounding process is described by Formulas (1) and (2).
Formula (1) is the distance between any gray wolf in the gray wolf population and prey. Formula (2) is the updated formula for the offspring of the gray wolves.
Y(
t) and
Y(
t + 1) represent the positions of gray wolves after the
tth iteration and the (
t + 1)th iteration, respectively.
Yp(
t) is the position of prey.
A and
C are the coefficients, which are obtained according to Formulas (3) and (4):
a is a control factor, and it is linear. n1 is a random number between 0 and 1. The value range of n2 is within [0, 1].
- (3)
Hunting
α,
β, and
δ are the best three wolves. They find the location of prey, notify
ω, and round up the prey. The
α,
β, and
δ determine the location of prey.
ω, according to the positions of
α,
β, and
δ, constantly adjusts its position. The mathematical principle is described by the following formula:
Qα,
Qβ, and
Qδ are the distances between
α,
β, and
δ wolf and other individuals, respectively.
Yα(
t),
Yβ(
t), and
Yδ(
t) represent the positions of
α,
β, and
δ after the
tth iteration, respectively.
Ci is an adaptive vector.
Y1, Y2, and Y3 represent the direction and distance of the ω wolf to the α wolf, β wolf, and δ wolf, respectively. Formula (11) is the final position of the wolf pack. Ai is a random vector.
According to the above formulas, gray wolves track and round up prey, as shown in
Figure 2:
- (4)
Attacking prey
When the prey is still in place, the whole wolf pack attacks. The process of attacking prey in GWO is simulated. It can be seen from Formula (3) that as
a decreases,
A also decreases continuously. In the iteration process,
a decreases from 2 to 0, which is a linear change process, and
A also changes in the corresponding interval.
A controls the expansion and contraction of the encirclement circle of the gray wolf pack. When |
A| > 1, the whole wolf pack will move far away from the prey in order to find optimal prey; that is global search. When |
A| < 1, the whole wolf pack will move to the location of the prey and launch an attack; that is local search. The schematic diagram of this process is shown in
Figure 3.
- (5)
Searching prey
When |A| > 1, they will go away from the prey, then globally search for other better prey. Because of the randomness of the parameter C in finding prey, the algorithm has a stochastic search behavior. In the algorithm design, it has a certain avoidance effect on falling into the local optimum. It also acts as an obstacle in nature that prevents the wolf population from capturing prey easily.
2.2. BPNN Algorithm
BPNN algorithm has strong fault tolerance and generalization ability, which are applied in many fields [
38]. The structure of BPNN has three sections, the configuration of which is illustrated schematically in
Figure 4. The neurons in the input layer can obtain the dataset. The hidden layer is located in the middle of the input and output layers. The dataset of the input layer is transformed and processed by the hidden layer, and then sent to the output layer to obtain the final result.
The mathematical principles of BPNN are divided into the following two parts:
Forward propagation means that the neural network calculates and stores the intermediate variables in sequence, from input layer to hidden layer and then to output layer. After the parameters of BPNN are initialized, the training data are input from the input layer and then transmitted to the hidden layer, and the input of the neurons in the hidden layer is obtained.
Zj represents the input value of the jth neuron of the hidden layer. Xi represents the input value of the ith neuron of the input layer, namely the sample data. vij represents the connection weight.
The output values of neurons in the hidden layer are calculated according to the thresholds and the input values of the neurons in the hidden layer. The calculation formula for the output value is:
f1 represents the transfer function. aj is the threshold of the jth neuron in the hidden layer. Mj is the output value of the jth neuron in the hidden layer.
According to the output value
Mj of the hidden layer and the given weights, calculate the results and transfer them to the output layer as input values. The input of the output layer is obtained.
Ok represents the input value of the kth neuron in the output layer. wjk represents the weight.
According to the thresholds of neurons in the output layer and the input value of the output layer, the output value of the neurons in the output layer is calculated and obtained. The calculation formula for the output value is:
Nk is the output value of the kth neuron in the output layer. f2 is the transfer function. bk is the threshold of the kth neuron in the output layer.
- (2)
Back propagation
Back propagation refers to the calculation method of BPNN parameter gradient. According to the chain rule of calculus, the gradient of loss function for each parameter in the BPNN algorithm is calculated in sequence from the output to the input, and the parameters are updated with the optimization method to reduce the loss function.
According to
Nk and
Yk of each neuron, the error of BPNN is obtained.
E is the error in BPNN. Yk is the expected output value. Nk is the actual output value.
When the error is not within the acceptable range,
vij,
wjk,
aj, and
bk are adjusted according to the gradient descent theory and chain rule. The correction values of
vij,
wjk,
aj, and
bk are obtained.
η indicates learning rate. The value range of η is within [0, 1].
The revised weights and thresholds are:
After the weights and thresholds are updated, forward propagation is carried out to make the actual output approximate the theoretical output to the greatest extent.
2.3. The SMOTE and Tomek Links Method
- (1)
SMOTE
Synthetic Minority Oversampling Technique (SMOTE) is a classic oversampling method to deal with data imbalance. A synthetic sample is generated by taking the corresponding line segment of two minority samples as the endpoints to increase the number of minority samples and achieve the purpose of oversampling minority samples. The principle of SMOTE in making the new sample is shown in Formula (22).
xnew represents a new sample; x is a minority sample; means the nearest neighbor sample.
- (2)
Tomek Links
After oversampling, if the last two samples belong to two categories, the two samples are combined into a Tomek Links pair. One of the samples is noise data, and this sample is deleted. Tomek Links can effectively delete the overlapping data, which enables the classifier to classify better.
2.4. Evaluation Indicators of Model Performance
- (1)
Accuracy
For a given set of samples, the calculation formula for accuracy is defined as follows:
TP represents positive samples predicted by the model as positive classes; TN represents negative samples predicted by the model as negative classes; FP represents negative samples predicted by the model as positive; FN represents positive samples predicted by the model as negative classes.
- (2)
Recall
The calculation formula for recall is shown in Equation (24).
- (3)
ROC curve and AUC
ROC (Regional Operating Characteristic) curve and AUC (Area Under Curve) are indicators for the comprehensive evaluation of binary classification problem. ROC curve provides a new graphical measurement of algorithm performance. The curve, which is close to the upper left corner, indicates the corresponding algorithm has good performance. AUC is the area under the ROC curve, and its value is within [0, 1]. The value that is close to 1 indicates an excellent result. This value can quantify the performance of the classification algorithm. In this paper, the idea of the ROC curve applied to multi-class classification is to plot the average ROC curve. Convert the sample label to a binary-like form, and then calculate the probability value of each sample under each label, and the average ROC curve is obtained.
3. DLH-GWO-BPNN Model
The GWO algorithm based on DLH is applied to optimize BPNN and construct the DLH-GWO-BPNN model.
3.1. Improved GWO Algorithm Based on DLH
The candidate positions in the GWO algorithm are mainly determined by
α,
β, and
δ, which easily fall into the local optimal solution. To keep the balance between local and global search, the DLH algorithm is introduced to optimize the GWO algorithm. The inspiration for DLH comes from the hunting behavior of individuals in nature [
39]. In the GWO algorithm, the concept of neighborhood is introduced to provide a new choice of candidate location for every gray wolf. The improved GWO algorithm based on DLH consists of three stages: the initialization phase, the movement phase, and the selection and update phases.
- (1)
Initialization
According to Formula (25), determine the scope of the search space, in which
N gray wolves are randomly initialized.
Yk(t) = {yk1, yk2, …ykD} denotes the position of the kth gray wolf after the tth iteration. D is the dimension of the problem. The fitness function is f(x). Calculate Yk(t) fitness according to f(x).
- (2)
Movement
Individual hunting is not only an important behavior in the whole gray wolf population but also the inspiration for improving the GWO algorithm. In the DLH algorithm, every gray wolf is considered by their neighbors to be a candidate position after the tth iteration. The conventional GWO algorithm and the DLH algorithm generate new candidate positions as follows:
GWO: On the basis of the positions of α wolf, β wolf, and δ wolf and the calculated coefficients a, A, and C, determine the encirclement of the wolves. Then calculate the new candidate position Yk-GWO(t + 1) after the tth iteration of the kth gray wolf according to Formula (11).
DLH: Each gray wolf learns from its neighbors and other random individuals, resulting in the new candidate position Yk-DLH(t + 1) in the following steps.
Step 1: Calculate the euclidean distance between the current position and the candidate position
Yk-GWO(
t + 1) of each gray wolf of the GWO algorithm. According to this distance, calculate the search radius
Rk(
t) of every gray wolf.
Step 2: Determine the neighborhood of
Yk(
t) with the following expression.
Qk denotes the Euclidean distance between Yk(t) and Ym(t). Pop represents a matrix that stores wolves. It has N rows and D columns.
Step 3: Select randomly the neighborhood
Yn,d(
t) in
Nk(
t). Select randomly
Yr,d(
t) from
Pop. The new candidate position
Yk-DLH(
t + 1) is calculated according to these two quantities.
- (3)
Selection and updating
The excellent candidate position is selected by calculating and comparing the fitness of the two positions with the following mathematical expression.
Based on this principle, update the position of each gray wolf until it reaches the largest number of iterations.
3.2. DLH-GWO-BPNN Model
In the evaluation of geomagnetic suitability, in order to improve the accuracy of the traditional BPNN model, the collected test data are mixed-sampled. After data preparation, the DLH-GWO algorithm is used to optimize the traditional BPNN model and build the DLH-GWO-BPNN model.
The specific steps are as follows:
Step 1: Construction of a mixed sampling method based on the SMOTE and Tomek Links algorithms. The SMOTE algorithm is used to synthesize the unmatched samples, weakly matched samples, and matched samples in the original dataset. Use the Tomek Links algorithm for data cleaning. Then normalize the sampled dataset.
Step 2: Set the maximum number of iterations of the DLH-GWO algorithm. Determine the topology of BPNN.
Step 3: The initial dimension represents the initial weight and threshold of BPNN. Put it into BPNN for training. Calculate the fitness of each gray wolf in the wolf pack. Select the three gray wolves with the lowest fitness value. Ranked from small to large according to fitness, namely α, β, and δ.
Step 4: Update the position of each gray wolf according to Formulas (8)–(11), namely Yk-GWO(t + 1). Then construct a new neural network for training. Recalculate the fitness of each gray wolf. Select the three gray wolves with the lowest fitness value. Ranked from small to large according to fitness, namely α, β, and δ. Update the position of each gray wolf again, namely Yk-GWO(t + 1).
Step 5: Calculate the search radius of each gray wolf according to Formula (26). Then determine the neighborhood of each gray wolf according to Formula (27). Each time a gray wolf learns from its neighbors and other random individuals, a new candidate position is generated, namely Yk-DLH(t + 1).
Step 6: Calculate the fitness of Yk-GWO(t + 1) and Yk-DLH(t + 1). Compare and select excellent candidates for the position.
Step 7: Judge whether the maximum number of iterations of DLH-GWO has been reached. If not, return to Step 3. If so, record α corresponding initial weights and thresholds.
Step 8: Obtain the value range of the number of hidden layer nodes based on empirical formulas. Input the optimal initial weight and threshold into the BPNN for training. Set different numbers of nodes and activation functions for experiments. Carry out a comparative analysis and select the node number and activation function with the smallest error.
Step 9: Take the accuracy, recall, ROC curve, and AUC value as evaluation indicators and put the test set into the trained BPNN for validation analysis.
Traditional geomagnetic suitability evaluation models are mostly based on multiple geomagnetic features to build a comprehensive evaluation value. Then, through simulation experiments, verify the high consistency of the comprehensive evaluation value and the matching probability. Due to the numerous geomagnetic features, the selection of geomagnetic features for the construction of comprehensive evaluation values has greater subjectivity. In order to improve this situation, the data from the matching region is divided into four types of samples with different matching degrees according to the matching probability. The BPNN algorithm is introduced, and the geomagnetic features are taken as input and the matching labels are taken as output to evaluate suitability.
Because the BPNN algorithm is easy to overfit and excessively depends on the initial weight and threshold, the GWO algorithm is introduced to iteratively optimize the initial weight and threshold of the BPNN. The DLH algorithm is introduced to avoid the GWO algorithm falling into a local optimal solution. In addition, due to the imbalance of the proportion of each category of sample data selected, before training, a mixed sampling method is built based on the SMOTE and Tomek Links algorithms for data balance processing.
Figure 5 describes the overall concept of the model.
4. Experimental Simulation
4.1. Selection of Indicators
According to the existing research, there are various feature parameters to characterize geomagnetic maps, such as geomagnetic roughness, geomagnetic standard deviation, geomagnetic information entropy, etc. The features of a geomagnetic map are characterized from different angles. Due to the incompleteness of a single feature to characterize geomagnetic suitability, seven indicators are selected from three aspects in combination with the distribution characteristics of the downhole geomagnetic field: macroscopic features, microscopic features, and self-similar features, and the geomagnetic suitability is comprehensively measured. The feature parameters are defined as follows:
The span of latitude and longitude of a candidate geomagnetic field area is set as the B × L grid, and g(k, m) is the geomagnetic strength value at the grid point coordinate (k, m).
4.1.1. Macroscopic Features
- (1)
Geomagnetic standard deviation σ
σ is the reflection of the degree of dispersion of geomagnetic data and the general changes of the geomagnetic area in the candidate region. The large
σ corresponds to the area with the apparent variation of geomagnetic features, and it is beneficial for the analysis of geomagnetic suitability. It is defined as follows:
is the average geomagnetic field value, which is defined as follows:
- (2)
Kurtosis coefficient C1
C1 stands for the concentration degree of geomagnetic field data in the candidate region. The larger the
C1, the more data are concentrated near the average geomagnetic field value, which is not conducive to matching. It is defined as:
- (3)
Skewness coefficient C2
C2 represents the symmetry of the geomagnetic map and is proportional to the suitability, which is defined as:
4.1.2. Microscopic Features
- (1)
Geomagnetic information entropy H
H reflects the fluctuation features of the geomagnetic field data and the richness of geomagnetic information in the candidate region. The lower the
H, the better the matching effect. It is defined as:
- (2)
Geomagnetic roughness r
r reflects the local fluctuation state and average smoothness of the geomagnetic field in a candidate region. The greater the geomagnetic roughness, the more abundant the geomagnetic field information in the candidate region. It is defined as:
- (3)
Variance of geomagnetic roughness R
R indicates the local fluctuation of geomagnetic data in the candidate region. The more significant the
R, the more conducive the analysis of geomagnetic suitability is. It is defined as:
4.1.3. Self-Similar Features
- (1)
Correlation coefficient p
The
p reflects the independence of geomagnetic field values in the candidate region. A small correlation coefficient corresponds to good matching performance. It is defined as:
4.2. Matching Labels
Calculate the matching probability of the selected sample area according to the matching algorithm. According to the matching probability, samples are divided into four kinds of matching labels: 0 (mismatch), 1 (weak match), 2 (match), and 3 (strong match), as shown in
Table 1 [
30].
4.3. Data Source and Data Processing
The model is trained with geomagnetic feature data and matching labels. The data are the geomagnetic features dataset collected by 41 underground projects of about 3 m, which is derived from the relevant data published in the related literature [
30].
The data are processed as follows:
The original data contains five unmatched samples, six weakly matched samples, ten matched samples, and twenty strongly matched samples. This dataset is unbalanced and has a small amount of data. To improve the accuracy of the model, balance the data. SMOTE is used for oversampling the other three types of small samples except for strongly matched samples, and then the Tomek Links algorithm is used to delete overlapping samples between classes.
Finally, 68 samples were obtained, and
Table 2 shows part of the samples.
- (2)
Normalization
The dataset is normalized to eliminate the impact of dimension.
4.4. Parameter Selection of BPNN
- (1)
Selection of neuron numbers
The number range of neurons in the hidden layer of BPNN is determined according to the empirical Formula (39).
m,
n, and
l represent the number of neurons in the input, hidden, and output layers, respectively.
a is an integer within [
1,
10].
The value within the range is selected as the number of neurons in the hidden layer, respectively. The average accuracy of the training set and test set is obtained through 70 tests to choose the optimal number.
- (2)
Selection of the activation function of BPNN
Activation functions are set in the input-hidden layer and hidden-output layer, respectively. The softmax function is suitable for multi-classification neural network output, so the softmax function is selected as the activation function in the hidden-output layer. Carry out ten experiments and take the tansig, softmax, purelin, and radbas functions as activation functions in the input-hidden layer, respectively, then calculate and compare the average accuracy of the training and test sets under the training of the BPNN algorithm.
- 2.
softmax function
- 3.
purelin function
- 4.
radbas function
4.5. Experimental Comparison
To verify the predictability of the proposed algorithm, comparative experiments were conducted. The BPNN is optimized by using five different optimization algorithms, namely WOA, GA, PSO, GWO, and DLH-GWO, and the model is constructed. Train the model with geomagnetic features as input and matching labels as output. By adjusting the main hyperparameter of each model, the optimal parameters of each model are obtained, respectively, and then the optimal model is constructed. Place the test set into the optimal model obtained, with geomagnetic features as input and matching labels as output. Evaluate the effect of each model using accuracy, recall, AUC value, and ROC curve as indicators.
5. Results and Analysis
5.1. Selection of Neuron Numbers
According to the empirical Formula (39), the number range of neurons in the hidden layer is within [
4,
14]. Different numbers of neurons are set, respectively, and experiments are conducted to obtain the corresponding average accuracy. The results are shown in
Figure 6.
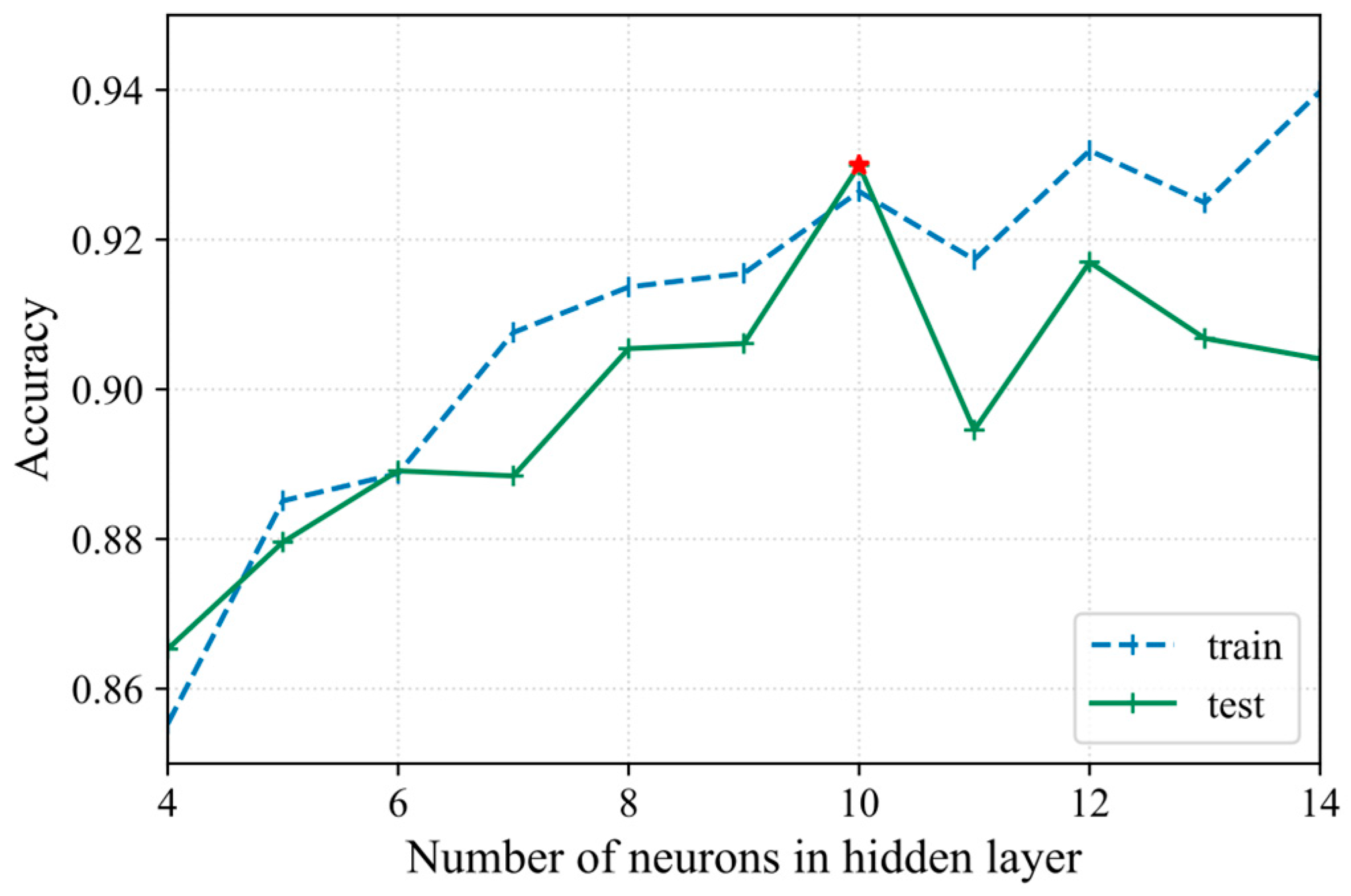
According to
Figure 6, when the number of neurons is 10, the average accuracy in the test set reaches its highest, at 0.9299. Meanwhile, the average accuracy of the training set at this point is relatively high, at 0.9264. When the number of neurons is 12 or 14, the average accuracy in the training set is higher than that when the number of neurons is 10, but the average accuracy of the test set at these two points is lower in comparison. The average accuracy in the test set no longer increases more than that of the number of neurons, which is 10. Thus, the optimal number of neurons is 10.
5.2. Selection of Activation Function
The softmax function is suitable for multi-classification neural network output, so the softmax function is set as the activation function between the hidden layer and the output layer. Take tansig, softmax, purelin, and radbas functions as activation functions between the input layer and the hidden layer, respectively. Carry out 10 experiments and calculate and compare the average accuracy of the DLH-GWO-BPNN model in the training set and test set. The results are shown in
Table 3.
Using tansig, softmax, purelin, and radbas functions between the input layer and the hidden layer, respectively, the accuracy of the training set and the test set is different. When the purelin function or softmax function is used, the average accuracy of the test set and training set is below 90%. The softmax function has a good advantage for the output of the multi-classification neural network, but it is not ideal when used as the activation function in the input-hidden layer. When the radbas function is used, the average accuracy of the training set reaches 93.83%, but the average accuracy of the test set is relatively low. When the tansig function is used, the average accuracy of the test set and training set is above 90%, and identification ability is the best in comparison.
Therefore, the tansig function is used in the input-hidden layer, and the softmax function is used in the hidden-output layer.
5.3. Parameter Selection
Through training, the optimal main parameters of five models, namely WOA-BPNN, GA-BPNN, PSO-BPNN, GWO-BPNN, and DLH-GWO-BPNN, were obtained. The results are shown in
Table 4:
5.4. Validation Analysis of the Suitability Evaluation Model
- (1)
Comparing the predictive ability of models with their accuracy
In order to verify the predictable ability of the DLH-GWO-BPNN model, five geomagnetic suitability evaluation models were established, namely PSO-BPNN, GA-BPNN, WOA-BPNN, GWO-BPNN, and DLH-GWO-BPNN, for comparative analysis. Using accuracy as an indicator, the classification effects of five models are as follows:
From
Table 5, it can be seen that the WOA-BPNN model performs the worst on both the training and testing sets. There is a significant difference in accuracy between the PSO-BPNN model training set and the test set. The accuracy of the GA-BPNN model training set and test set is 87.23% and 85.71%, respectively, with a small difference and good generalization ability. The accuracy of the GWO-BPNN model and the DLH-GWO-BPNN model training set is the same, at 91.49%, but the accuracy of the DLH-GWO-BPNN model testing set is much higher than that of the GWO-BPNN model. At the same time, the accuracy of the DLH-GWO-BPNN model training set and test set is not significantly different and is higher than that of the GA-BPNN model. Therefore, the DLH-GWO-BPNN model has the best classification performance.
- (2)
Comparing the predictive ability of models from the recall
Using the recall as an indicator to evaluate the classification performance of PSO-BPNN, GA-BPNN, WOA-BPNN, GWO-BPNN, and DLH-GWO-BPNN models, the results are as follows:
From
Table 6, it can be seen that the WOA-BPNN model has a poor recall of 0.64 for label 1 in the training set, indicating a poor training effect. However, its recall under label 1 in the test set is 100%. The model is unstable. The WOA-BPNN model has a recall of 20% in the test set and 60% in the training set under label 3, indicating poor model performance. The WOA-BPNN model performs well under the other two types of labels. The recall of the PSO-BPNN model in the training and testing sets under label 3 is 70% and 20%, respectively, indicating poor performance of the model. However, the model has a higher recall under other labels in both the test set and the training set. The recall of the GA-BPNN model in the training and testing sets under label 3 is 60% and 40%, respectively, indicating poor performance of the model. However, the model has a higher recall under other labels in both the test set and the training set. The GWO-BPNN model has a recall of 40% in the test set under label 3, which results in poor performance. The accuracy of the DLH-GWO-BPNN model in both the training and testing sets under four labels is within an acceptable range. The model has the highest recall under lable 0, with a recall of 100% for the test set and training set, respectively. The recall of the test set under label 1 is 75%, and the recall of the training set is 100%, which is acceptable. Overall, the DLH-GWO-BPNN model has the best performance.
- (3)
Comparing the predictive ability of models using the AUC and ROC curve
The method of calculating the AUC value of multi-classification is used to calculate the AUC values of five models, namely PSO-BPNN, GA-BPNN, WOA-BPNN, GWO-BPNN, and DLH-GWO-BPNN models. The ROC curves of each model are drawn, as shown in
Figure 12 and
Figure 13:
From the figure, it can be seen that the AUC values of the WOA-BPNN model in the training and test sets are 0.90 and 0.91, respectively, indicating good model performance. The AUC values of the GA-BPNN model in the training and test sets are 0.95 and 0.96, respectively, indicating good generalization ability of the model. The AUC values of the PSO-BPNN model in the training and test sets are 0.96 and 0.97, respectively. The AUC values of the GWO-BPNN model in the two datasets are 0.94 and 0.93, respectively. The DLH-GWO-BPNN model performed well in the training set with an AUC value of 0.96, and the test set showed the best results with an AUC of 0.99, indicating that the model has excellent generalization ability.
In summary, the DLH-GWO-BPNN model has shown good classification performance on all four indicators.
6. Conclusions and Outlooks
In this paper, an evaluation model based on the data reconstruction model and the DLH-GWO-BPNN classification algorithm was proposed for downhole geomagnetic suitability analysis. The PSO-BPNN, GA-BPNN, WOA-BPNN, and GWO-BPNN algorithms were used to compare and analyze the proposed model, and the conclusions are as follows: A data reconstruction model based on SMOTE and Tomek Links was employed to extend the original data set, remove the sample redundancy, which can also solve the problem of data imbalance and small amounts of data, and provide better data set support for model training. The technology of DLH improved the GWO algorithm to prevent it from falling into a local optimum. The BPNN algorithm was optimized by the improved GWO to enhance its performance. The accuracy, recall, ROC curve, and AUC value were selected as evaluation indicators for model training and testing. The accuracy of the training set and the test set of the model are 91.49 % and 95.24 %, respectively. The recall of the model in the training set is relatively high. The recall labels 0, 2, and 3 in the test set are 1, and the recall of label 1 is 0.75. In addition, the AUC values of the model training set and test set are 0.96 and 0.99, respectively. The comparison of PSO-BPNN, GA-BPNN, WOA-BPNN, GWO-BPNN, and DLH-GWO-BPNN models verifies the good classification effect of the DLH-GWO-BPNN model under different evaluation indicators. The DLH-GWO-BPNN model can efficiently and accurately solve the problem of downhole geomagnetic suitability evaluation and provide a theoretical basis for underground intelligent geomagnetic navigation. Meanwhile, future research will continue to improve sampling methods and algorithm optimization methods, as well as consider deep learning structures to improve the model.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}