

Deep Learning-Based Context-Aware Recommender System Considering Change in Preference


Abstract
:1. Introduction
2. Related Works
2.1. Context-Aware Recommender Systems
2.2. Dynamic Recommender Systems
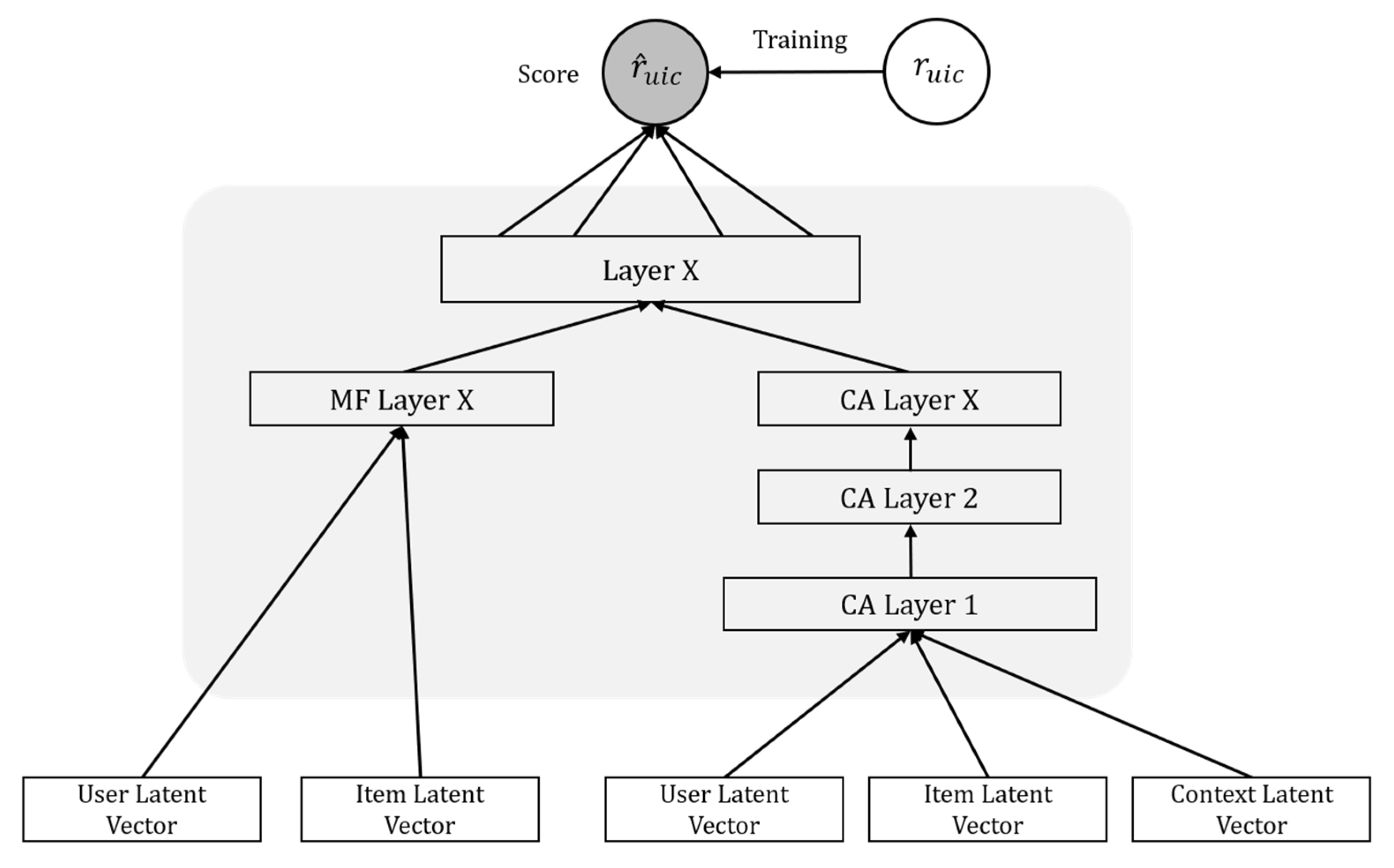
3. Proposed Model
3.1. Matrix Factorization to Account for Changing User Preferences
3.2. Context-Aware Recommender System Considering Change in Preference
4. Experiments
4.1. Data Sets
- -
- The University Cafeteria dataset is from a food court at Chungnam National University, Korea. To distinguish individual users, they were identified by their encrypted credit card numbers. There are four contextual dimensions: time, day, weather, and temperature. Time of day has three contextual conditions: Breakfast, Lunch, and Dinner. Day of the week has 6 contextual conditions: Mon, Tue, Wed, Thu, Fri, Sat. Weather has 3 contextual conditions: Sunny, Rain, Snow. Temperature has 4 contextual conditions: Hot, Warm, Cool, Cold.
- -
- The Instacart dataset is from Instacart, an online-based fresh food delivery service in the United States. It has user_id, which identifies the user, and order_id, which is the order number. The order_id can be thought of as the identification number of a shopping cart that contains multiple items. There are about 30 million rows of order_product, which is the product in the order_id. The Instacart dataset has the day of purchase, time of purchase, and time since purchase, but we don’t know the exact date of purchase, so we assigned the first purchase date as January. There are three contextual dimensions: day of the week, time of day, and weekday/weekend.
4.2. Evaluation Measures
4.3. Compared Methods
4.4. Results of the Experiments
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. (CSUR) 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Chen, J.; Dong, H.; Wang, X.; Feng, F.; Wang, M.; He, X. Bias and debias in recommender system: A survey and future directions. ACM Trans. Inf. Syst. 2023, 41, 1–39. [Google Scholar] [CrossRef]
- Zheng, X.; Zhao, G.; Zhu, L.; Zhu, J.; Qian, X. What you like, what I am: Online dating recommendation via matching individual preferences with features. IEEE Trans. Knowl. Data Eng. 2022, 35, 5400–5412. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Recommender Systems; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Sarker, I.H. Context-aware rule learning from smartphone data: Survey, challenges and future directions. J. Big Data 2019, 6, 1–25. [Google Scholar] [CrossRef]
- Casillo, M.; Gupta, B.B.; Lombardi, M.; Lorusso, A.; Santaniello, D.; Valentino, C. Context aware recommender systems: A novel approach based on matrix factorization and contextual bias. Electronics 2022, 11, 1003. [Google Scholar] [CrossRef]
- Batmaz, Z.; Yurekli, A.; Bilge, A.; Kaleli, C. A review on deep learning for recommender systems: Challenges and remedies. Artif. Intell. Rev. 2019, 52, 1–37. [Google Scholar] [CrossRef]
- Zhao, G.; Liu, Z.; Chao, Y.; Qian, X. CAPER: Context-aware personalized emoji recommendation. IEEE Trans. Knowl. Data Eng. 2020, 33, 3160–3172. [Google Scholar] [CrossRef]
- Kalloori, S.; Chalumattu, R.; Yang, F.; Klingler, S.; Gross, M. Towards Recommender Systems in Augmented Reality for Tourism. Inf. Commun. Technol. Tour. 2023, 2023, 267–272. [Google Scholar]
- Zheng, Y.; Mobasher, B.; Burke, R.D. Incorporating Context Correlation into Context-Aware Matrix Factorization. In Proceedings of the 2015 International Conference on Constraints and Preferences for Configuration and Recommendation and Intelligent Techniques for Web Personalization, Buenos Aires, Argentina, 25–27 July 2015; Volume 1440. [Google Scholar]
- Suhaim, A.B.; Berri, J. Context-aware recommender systems for social networks: Review, challenges and opportunities. IEEE Access 2021, 9, 57440–57463. [Google Scholar] [CrossRef]
- Baltrunas, L.; Ludwig, B.; Ricci, F. Matrix factorization techniques for context aware recommendation. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 301–304. [Google Scholar] [CrossRef]
- Baltrunas, L.; Ricci, F. Experimental evaluation of context-dependent collaborative filtering using item splitting. User Model. User-Adapt. Interact. 2014, 24, 7–34. [Google Scholar] [CrossRef]
- Zheng, Y.; Mobasher, B.; Burke, R. CSLIM: Contextual SLIM recommendation algorithms. In Proceedings of the 8th ACM Conference on Recommender Systems; 2014; pp. 301–304. [Google Scholar]
- Jeong, S.Y.; Kim, Y.K. Deep learning-based context-aware recommender system considering contextual features. Appl. Sci. 2022, 12, 45. [Google Scholar] [CrossRef]
- Livne, A.; Unger, M.; Shapira, B.; Rokach, L. Deep context-aware recommender system utilizing sequential latent context. arXiv 2019, arXiv:1909.03999. [Google Scholar] [CrossRef]
- Mohamed, S.A.E.M.; Soliman, T.H.A.; Sewisy, A.A. A context-aware recommender system for personalized places in mobile applications. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 442–448. [Google Scholar]
- Bahramian, Z.; Abbaspour, R.A.; Claramunt, C. A Context-Aware Tourism Recommender System Based on a Spreading Activation Method. International Archives of the Photogrammetry. Remote Sens. Spat. Inf. Sci. 2017, 42, 333–339. [Google Scholar] [CrossRef]
- Achmad, K.A.; Nugroho, L.E.; Djunaedi, A. Tourism contextual information for recommender system. In Proceedings of the 2017 7th International Annual Engineering Seminar (InAES), Yogyakarta, Indonesia, 1–2 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Rana, C.; Jain, S.K. A study of the dynamic features of recommender systems. Artif. Intell. Rev. 2018, 43, 141–153. [Google Scholar] [CrossRef]
- Lopes, P.; Roy, B. Dynamic recommendation system using web usage mining for e-commerce users. Procedia Comput. Sci. 2015, 45, 60–69. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Ding, Y.; Li, X. Time weight collaborative filtering. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2005; pp. 485–492. [Google Scholar]
- Chen, C.; Yin, H.; Yao, J.; Cui, B. Terec: A temporal recommender system over tweet stream. Proc. VLDB Endow. 2013, 6, 1254–1257. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, C.; Liu, B.; Qu, M.; Xiong, H. Unified point-of-interest recommendation with temporal interval assessment. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1015–1024. [Google Scholar] [CrossRef]
- Jin, Z.; Zhang, Y.; Mu, W.; Wang, W.; Jin, H. Leveraging the dynamic changes from items to improve recommendation. In Conceptual Modeling: 37th International Conference, ER 2018, Xi'an, China, 25–28 October 2018; Springer: Cham, Switzerland, 2018; pp. 507–520. [Google Scholar]
- Lin, K.; Liu, D. Category-based dynamic recommendations adaptive to user interest drifts. In Proceedings of the 2014 Sixth International Conference on Wireless Communications and Signal Processing (WCSP), Hefei, China, 23–25 October 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Wangwatcharakul, C.; Wongthanavasu, S. Dynamic collaborative filtering based on user preference drift and topic evolution. IEEE Access 2020, 8, 86433–86447. [Google Scholar] [CrossRef]
- Koren, Y. Collaborative filtering with temporal dynamics. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 447–456. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, K.; Yu, H.; Sun, J.; Lim, E.P. Latent factor transition for dynamic collaborative filtering. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 24–26 April; 2014; pp. 452–460. [Google Scholar] [CrossRef]
- Tong, C.; Qi, J.; Lian, Y.; Niu, J.; Rodrigues, J.J. TimeTrustSVD: A collaborative filtering model integrating time, trust and rating information. Future Gener. Comput. Syst. 2019, 93, 933–941. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Number of users, number of items | |
| Number of latent factors | |
| Preference matrix at current time t | |
| Preference matrix at time t − 1 | |
| Time t user i item j preference prediction matrix | |
| Entire period | |
| User latent matrix at time t | |
| User latent matrix at time t − 1 | |
| Item latent matrix at time t | |
| Time weights | |
| Normalization parameters |
| University Cafeteria | Instacart | |
|---|---|---|
| # of users | 37,289 | 206,209 |
| # of items | 97 | 49,688 |
| # of orders | 725,438 | 3,421,083 |
| Contextual Dimensions | 4 | 3 |
| Contextual Conditions | 16 | 13 |
| Sparsity | 99.89% | 99.99% |
| Dataset | University Cafeteria | Instacart | |||
|---|---|---|---|---|---|
| Method | N = 10 | N = 20 | N = 10 | N = 20 | |
| RS | UserKNN | 0.043732 | 0.040358 | 0.023672 | 0.035216 |
| SVD++ | 0.008599 | 0.011044 | 0.047396 | 0.050524 | |
| PMF | 0.062262 | 0.068834 | 0.050791 | 0.052613 | |
| FM | 0.017369 | 0.019594 | 0.019762 | 0.028647 | |
| CARS | CAMF | 0.065836 | 0.075625 | 0.018642 | 0.022677 |
| ItemSplitting | 0.068498 | 0.066235 | 0.041653 | 0.040589 | |
| CSLIM | 0.012835 | 0.019662 | 0.038452 | 0.037446 | |
| DRS | TimeSVD | 0.057290 | 0.061211 | 0.029648 | 0.029273 |
| TMF | 0.064522 | 0.066507 | 0.052473 | 0.052981 | |
| BTMF | 0.077652 | 0.080917 | 0.064520 | 0.069118 | |
| TimeTrustSVD | 0.063861 | 0.064185 | 0.034913 | 0.035499 | |
| Proposed method | 0.114865 | 0.107562 | 0.085116 | 0.080427 | |
| Dataset | University Cafeteria | Instacart | |||
|---|---|---|---|---|---|
| Method | N = 10 | N = 20 | N = 10 | N = 20 | |
| RS | UserKNN | 0.136482 | 0.138623 | 0.020044 | 0.022758 |
| SVD++ | 0.082366 | 0.080475 | 0.095427 | 0.075211 | |
| PMF | 0.107694 | 0.108462 | 0.172436 | 0.153776 | |
| FM | 0.088219 | 0.090325 | 0.053641 | 0.058962 | |
| CARS | CAMF | 0.084963 | 0.087581 | 0.071628 | 0.070493 |
| ItemSplitting | 0.130531 | 0.035816 | 0.162285 | 0.158174 | |
| CSLIM | 0.035816 | 0.043746 | 0.049264 | 0.050723 | |
| DRS | TimeSVD | 0.084190 | 0.086997 | 0.082358 | 0.085279 |
| TMF | 0.127522 | 0.132490 | 0.164015 | 0.170294 | |
| BTMF | 0.178620 | 0.171236 | 0.170293 | 0.169470 | |
| TimeTrustSVD | 0.107223 | 0.114918 | 0.147526 | 0.150711 | |
| Proposed method | 0.223674 | 0.202638 | 0.197563 | 0.188249 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, S.-Y.; Kim, Y.-K. Deep Learning-Based Context-Aware Recommender System Considering Change in Preference. Electronics 2023, 12, 2337. https://doi.org/10.3390/electronics12102337
Jeong S-Y, Kim Y-K. Deep Learning-Based Context-Aware Recommender System Considering Change in Preference. Electronics. 2023; 12(10):2337. https://doi.org/10.3390/electronics12102337
Chicago/Turabian StyleJeong, Soo-Yeon, and Young-Kuk Kim. 2023. "Deep Learning-Based Context-Aware Recommender System Considering Change in Preference" Electronics 12, no. 10: 2337. https://doi.org/10.3390/electronics12102337