


Visual Extraction of Refined Operation Mode of New Power System Based on IPSO-Kmeans

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- Taking key sections of the power grid as the entry point, extended calculations are carried out from different angles, such as transient stability margin, section quota, and limit transmission capacity, etc. Among them, [11] identified the strongly correlated sections based on the transient stability margin, improved the section monitoring accuracy of dispatching operators, and laid the foundation for the rationalization of the operation mode. The limit transmission capacity is an important index to evaluate the safe operation status of the transmission section. Ref. [12] analyzed the conditions affecting the section limit rules and proposed a method based on the branch power flow and the number of start-up units as the judgment rules to realize the automatic matching of section quotas and power generation plans and tap the transmission potential of the power grid. Ref. [13] proposed a search method for key transmission interface; the missing sections are searched to complement the initial sections, and then the key transmission interface is determined, reducing the possibility of missed selection. Furthermore, [14] proposed an FCM clustering algorithm based on fuzzy theory to solve the clustering problem of transmission lines in power system. Refs. [15,16] studied the calculation method of the real-time limit transmission capacity of the key section to solve the demand of power grid online analysis. However, this research method generally faces the problem that the selection of the initial section depends on the experience of experts or dispatchers, and in the new power system, the traditional safe operation area division method also has shortcomings, such as a single safety margin index, missed or wrongly selected lines, and so on;
- (2)
- The operating mode can be extracted based on machine learning algorithms, such as traditional clustering algorithms, hierarchical clustering algorithms, and long-term short-term memory networks. For instance, [5] proposes a power system flexibility evaluation method for typical operating scenarios, which clusters and combines the operating scenarios of new energy and loads to obtain typical operating scenarios and, and the authors propose flexibility evaluation indicators to evaluate the system. Ref. [17] clustered and preprocessed the historical scheduling based on the K-means algorithm then constructed a deep learning model of unit combination based on long short-term memory network and proposed a data-driven intelligent decision-making method for unit combination with self-learning ability. Ref. [18] proposed a hierarchical clustering technique to select typical scenes and consider the temporal and spatial correlation between scenes. Ref. [6] proposes an analysis method for the power system operation mode and its morphological change based on power system timing operation simulation data, analyzing the power system operation mode from qualitative and quantitative perspectives. Ref. [19] constructed a feature quantity library representing the operating section of the system and used the decision tree model to screen the feature quantities. Finally, the similarity clustering of the historical operation sections is carried out by the data-driven method. Ref. [20] proposed a meta-heuristic algorithm to classify the way. Variability and uncertainty in power generation operations are taken into account. At the same time, the total power generation cost is minimized, and the convergence time is shortened.
- (1)
- A variable standardization preprocessing method based on the maximum absolute value (MaxAbs) is proposed. It takes account of the characteristics of the power data of the characterization variable and uses the maximum value of the apparent power as the reference value to realize the unification of the dimension and scale of the data value;
- (2)
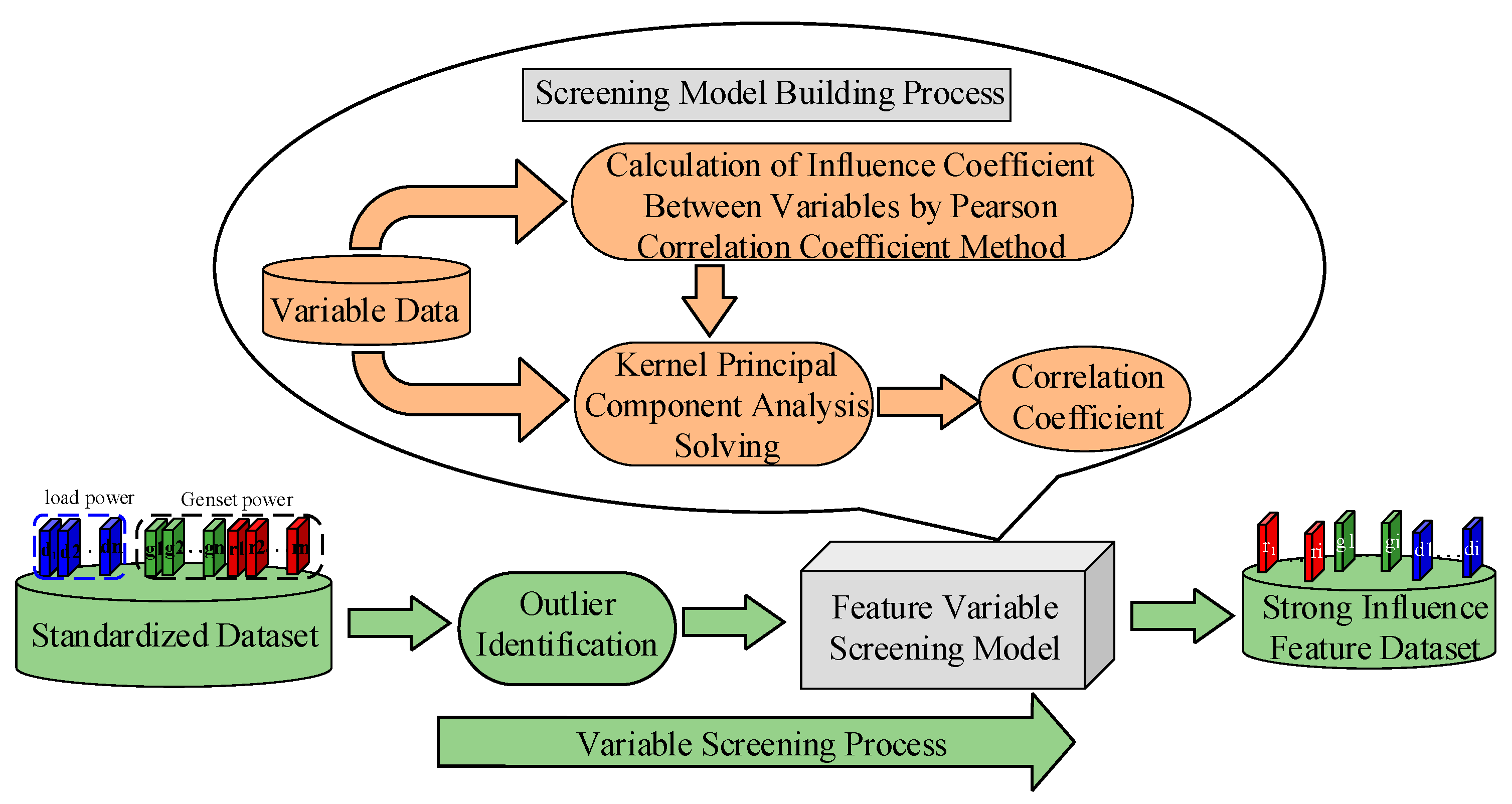
- A feature variable screening model based on pearson kernel principal component analysis (P_KPCA) was constructed to improve the accuracy of the extraction results of the operation mode by calculating the correlation between sample points and selecting strongly correlated feature variables;
- (3)
- An operation mode extraction algorithm was designed based on improved particle swarm optimization traditional clustering (IPSO-Kmeans). Taking the clustering elbow index as the premise, the operation scenarios with similar power output methods are clustered into one group so as to realize the extraction of the refined operation mode of the new power system.
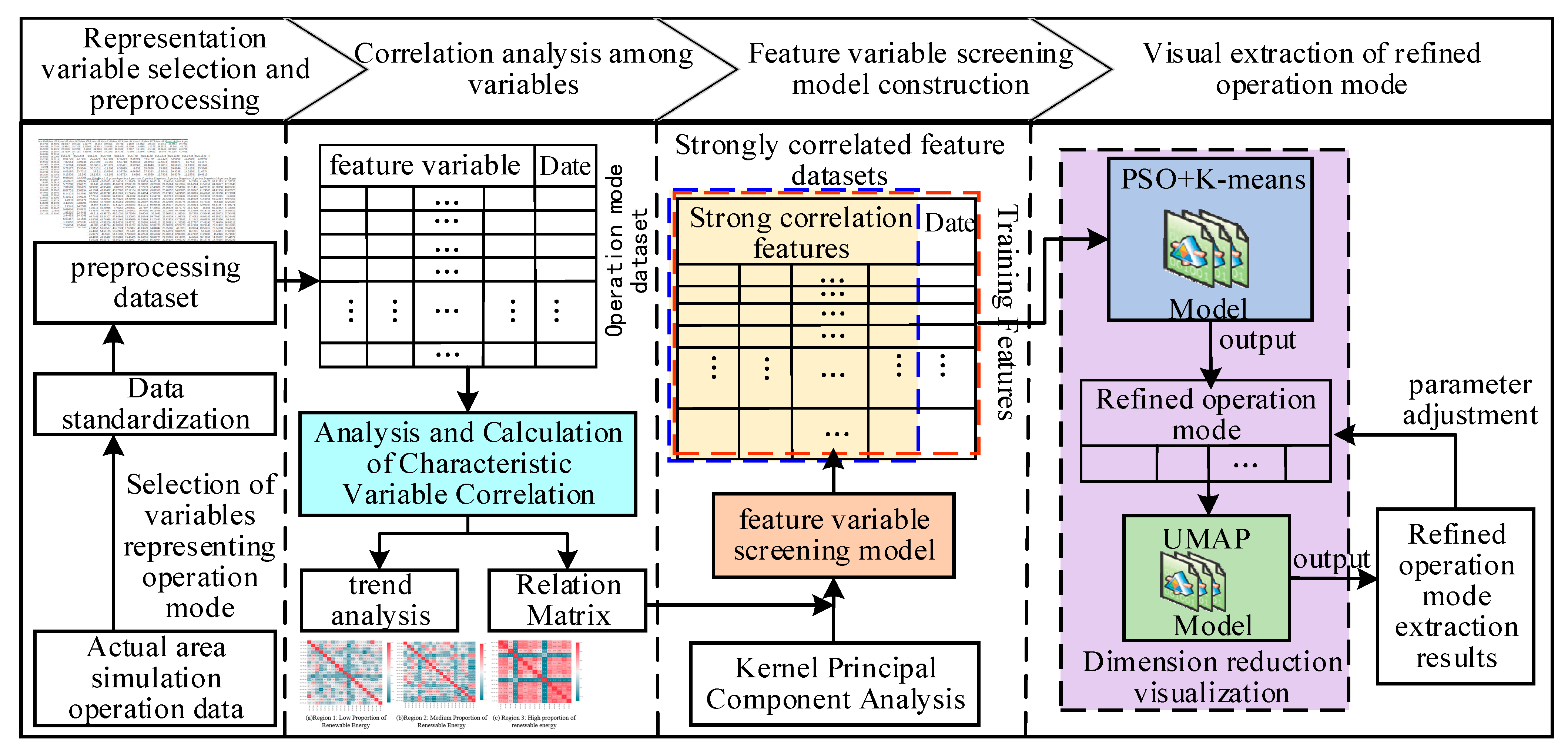
2. Visual Extraction Process of Refined Operation Mode
3. Operation Mode Representation Variable Selection and Preprocessing Method
3.1. Selection of Operating Mode Characterization Variables
- (1)
- Generator set
- (2)
- Load side
- (3)
- Line flow
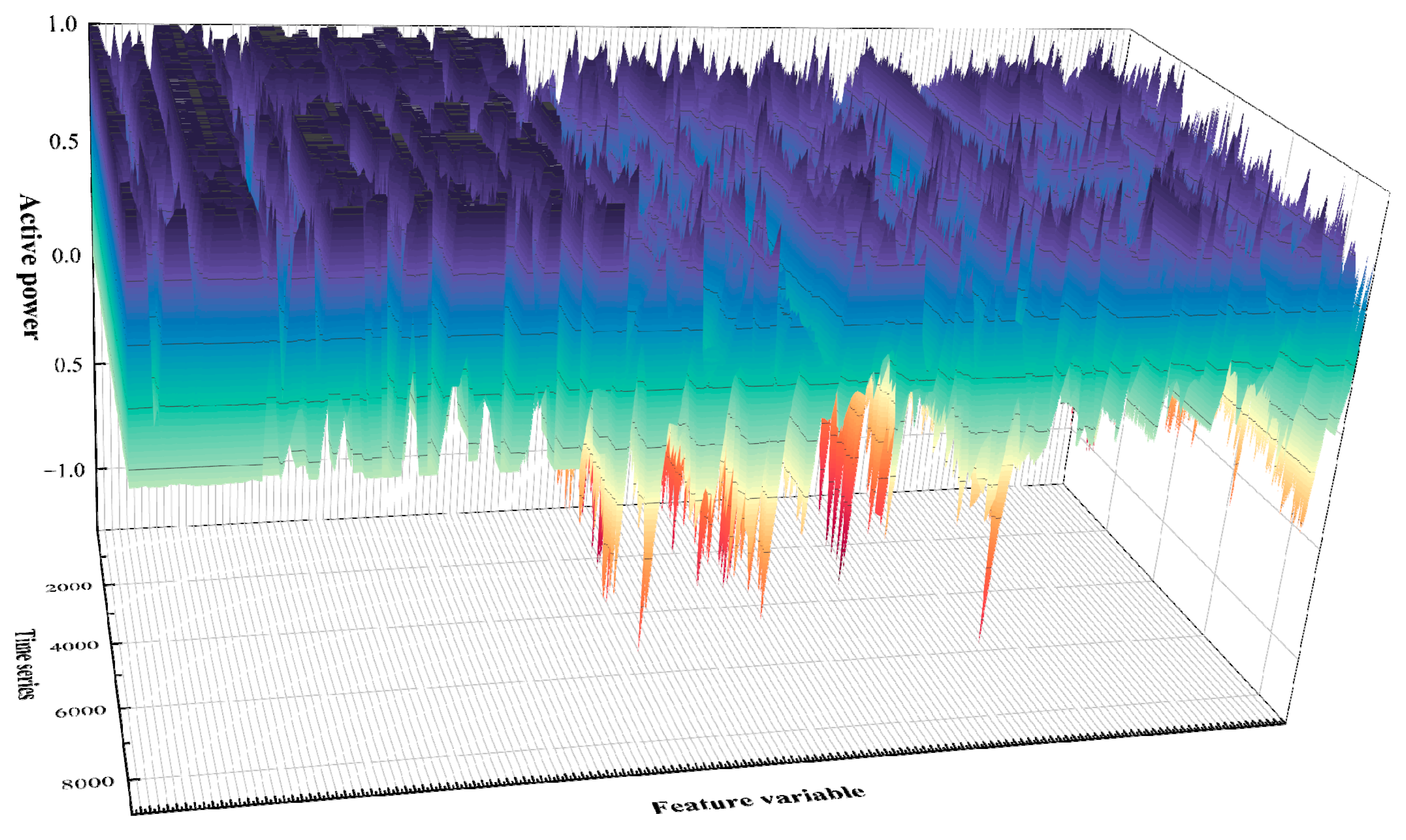
3.2. Variable Data Standardization Based on MaxAbs
4. A Screening Model for Operating Mode Characteristic Variables Based on Kernel Principal Component Correlation
5. Refined Operation Mode Extraction Based on IPSO-Kmeans
5.1. Refined Operation Mode Extraction
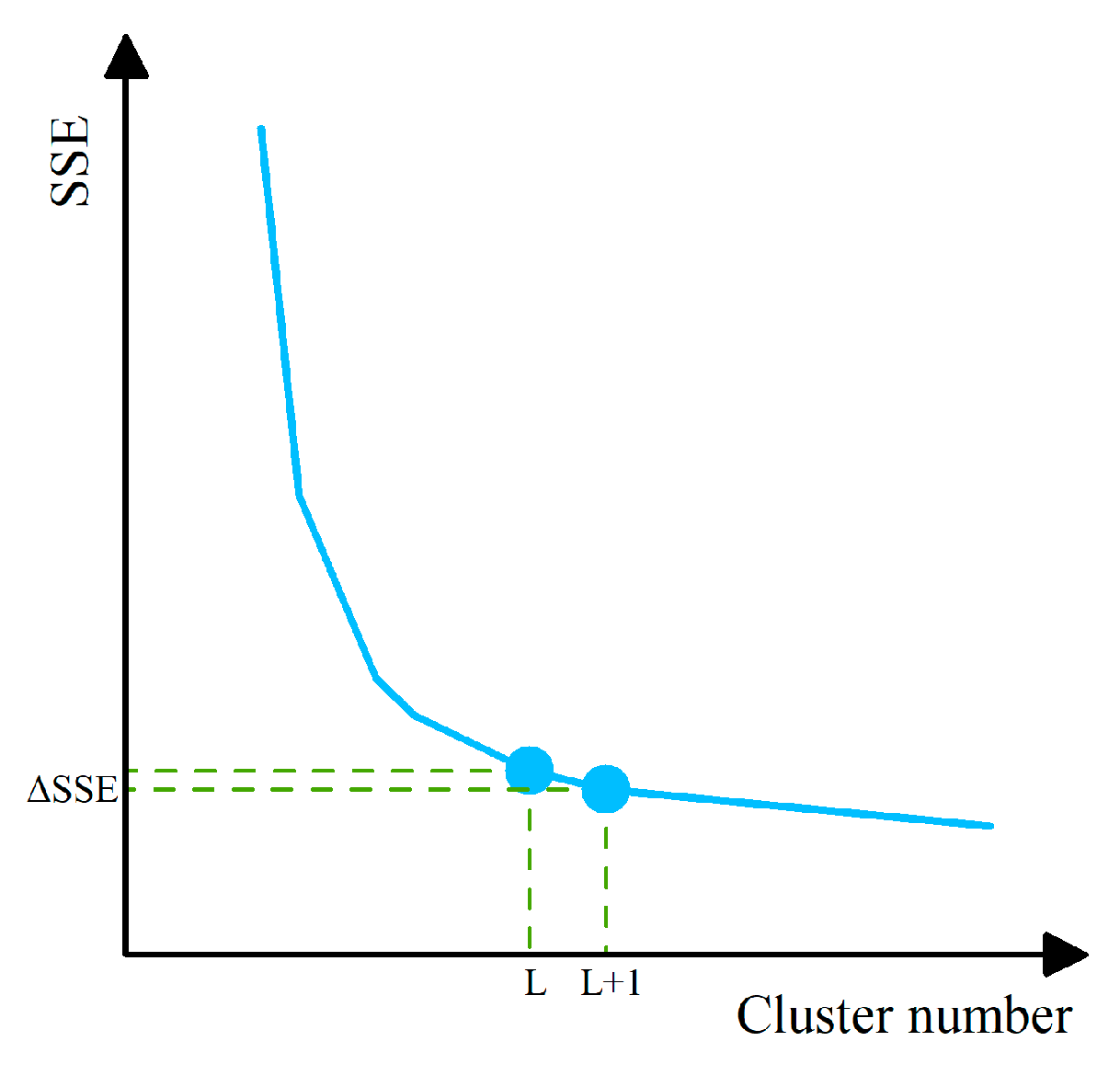
- (1)
- Determination of the number of clusters
- (2)
- Clustering Performance Improvement
- (3)
- Cluster Center Iterative Optimization
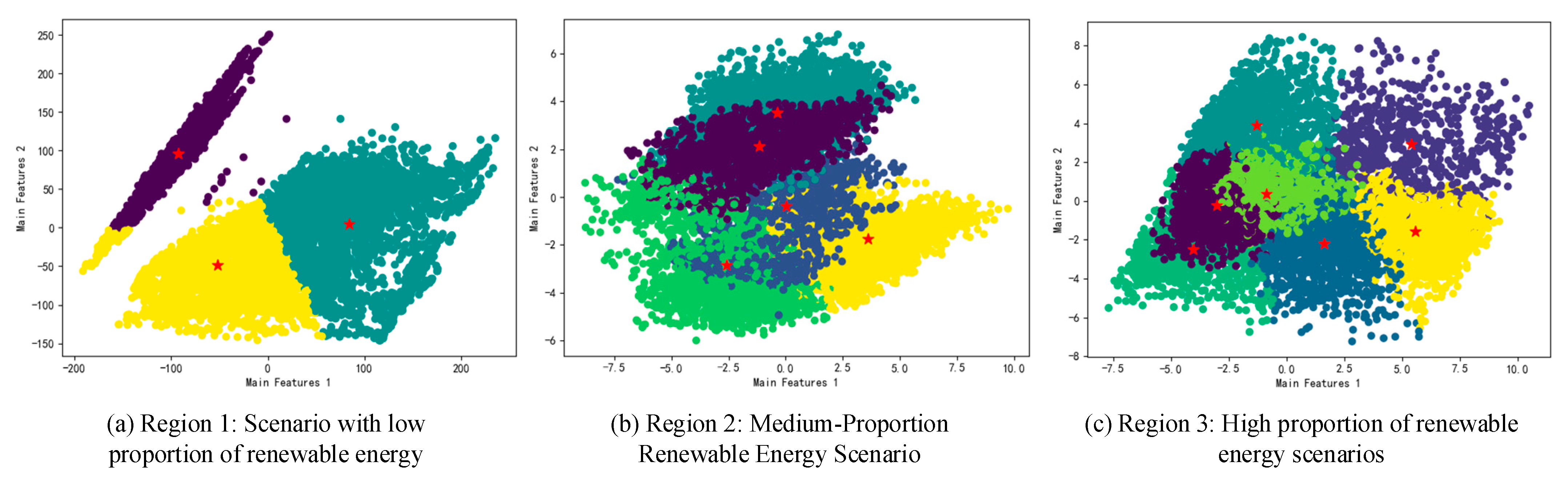
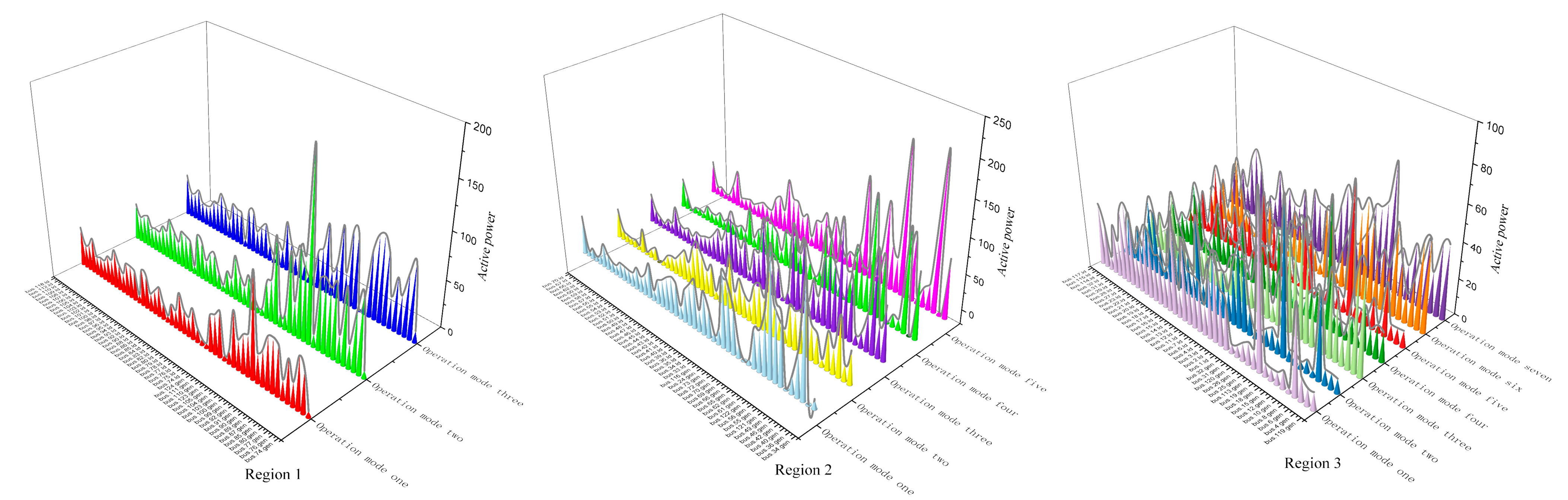
5.2. Visualization of Extraction Results
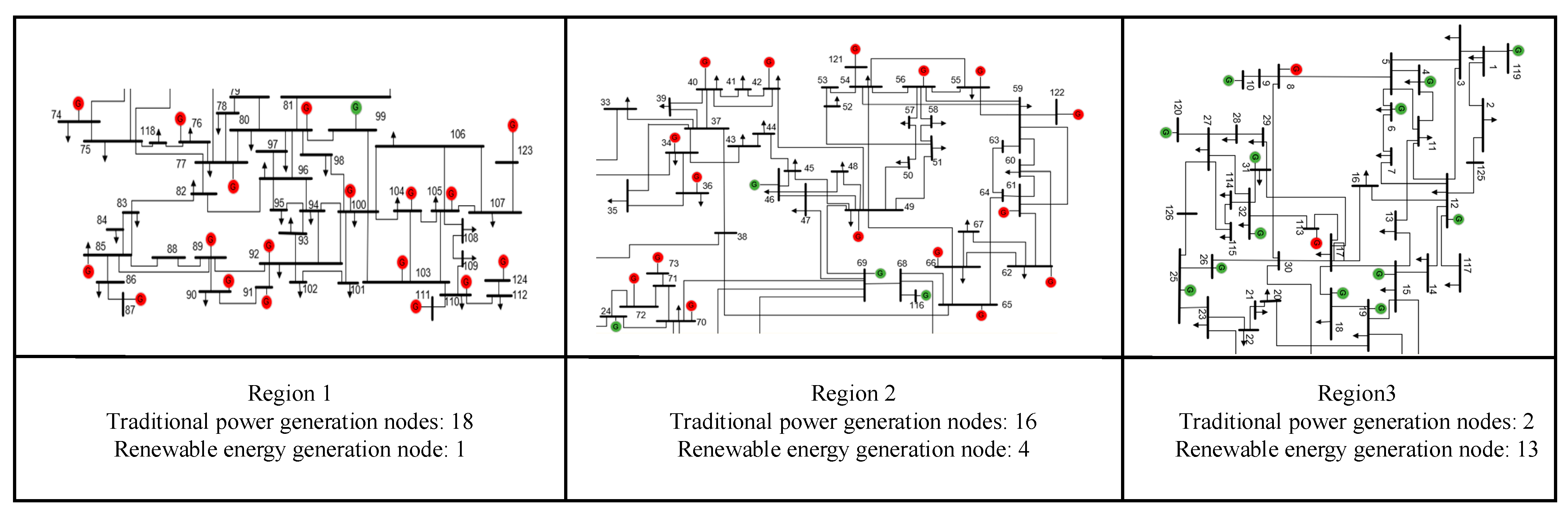
6. Case Analysis
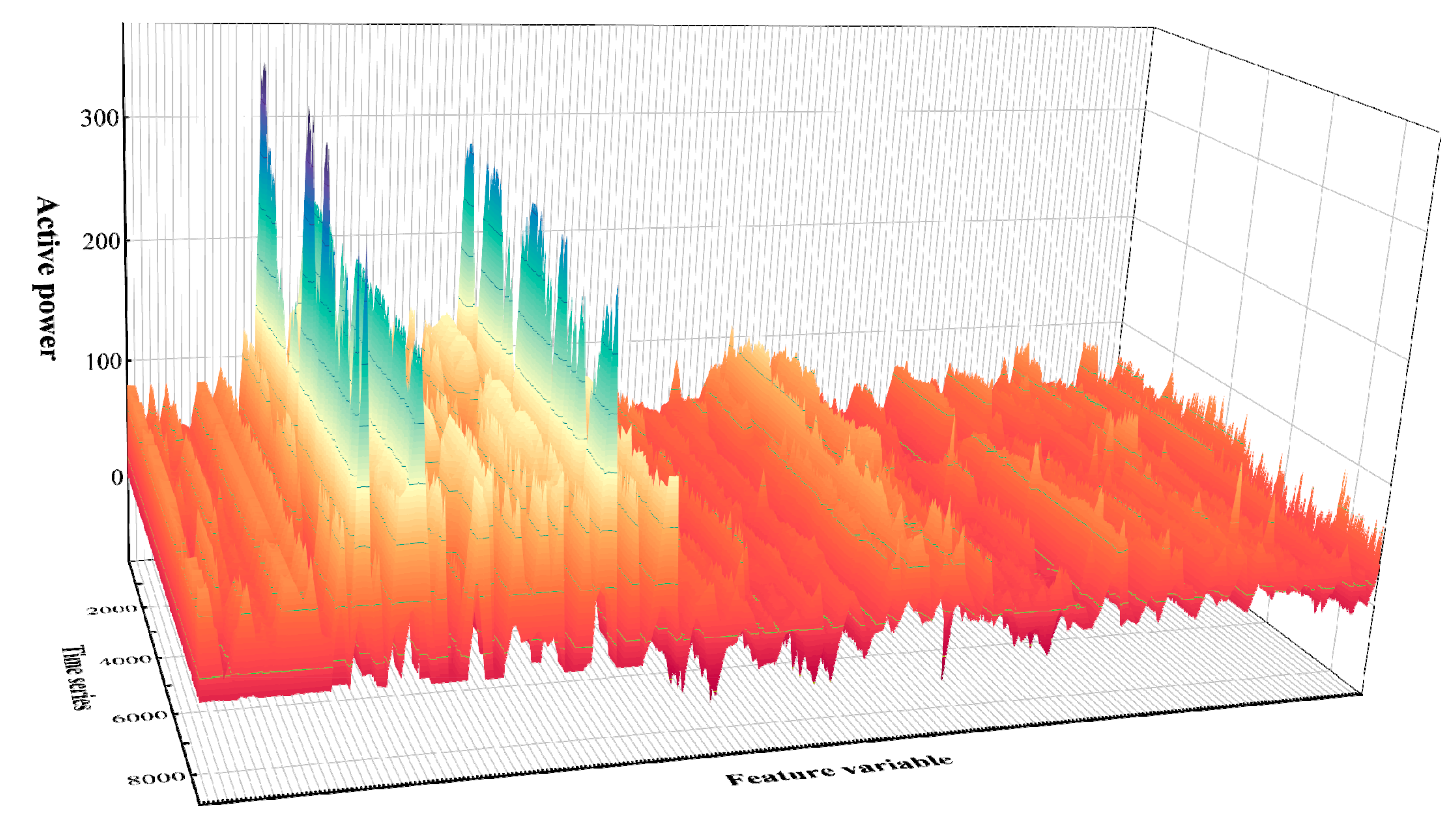
6.1. Standardization of Operating Mode Representation Variables
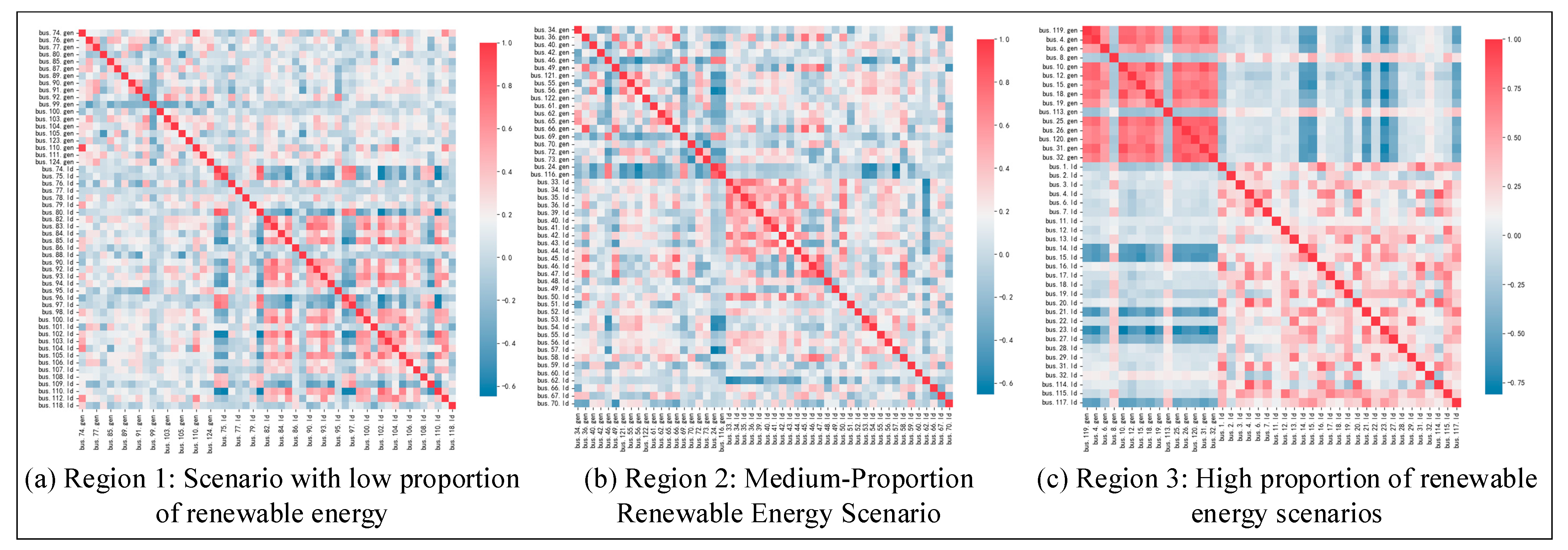
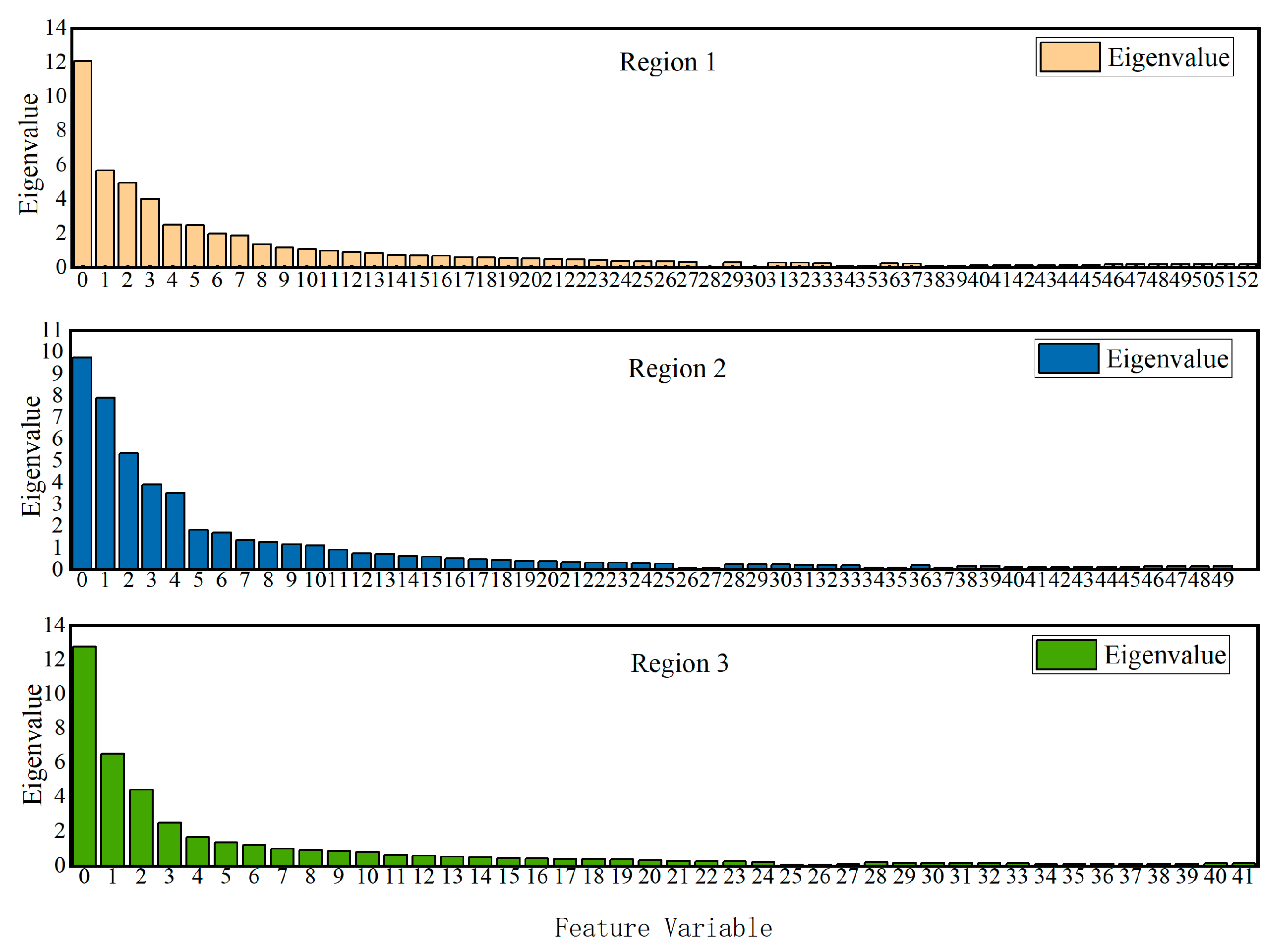
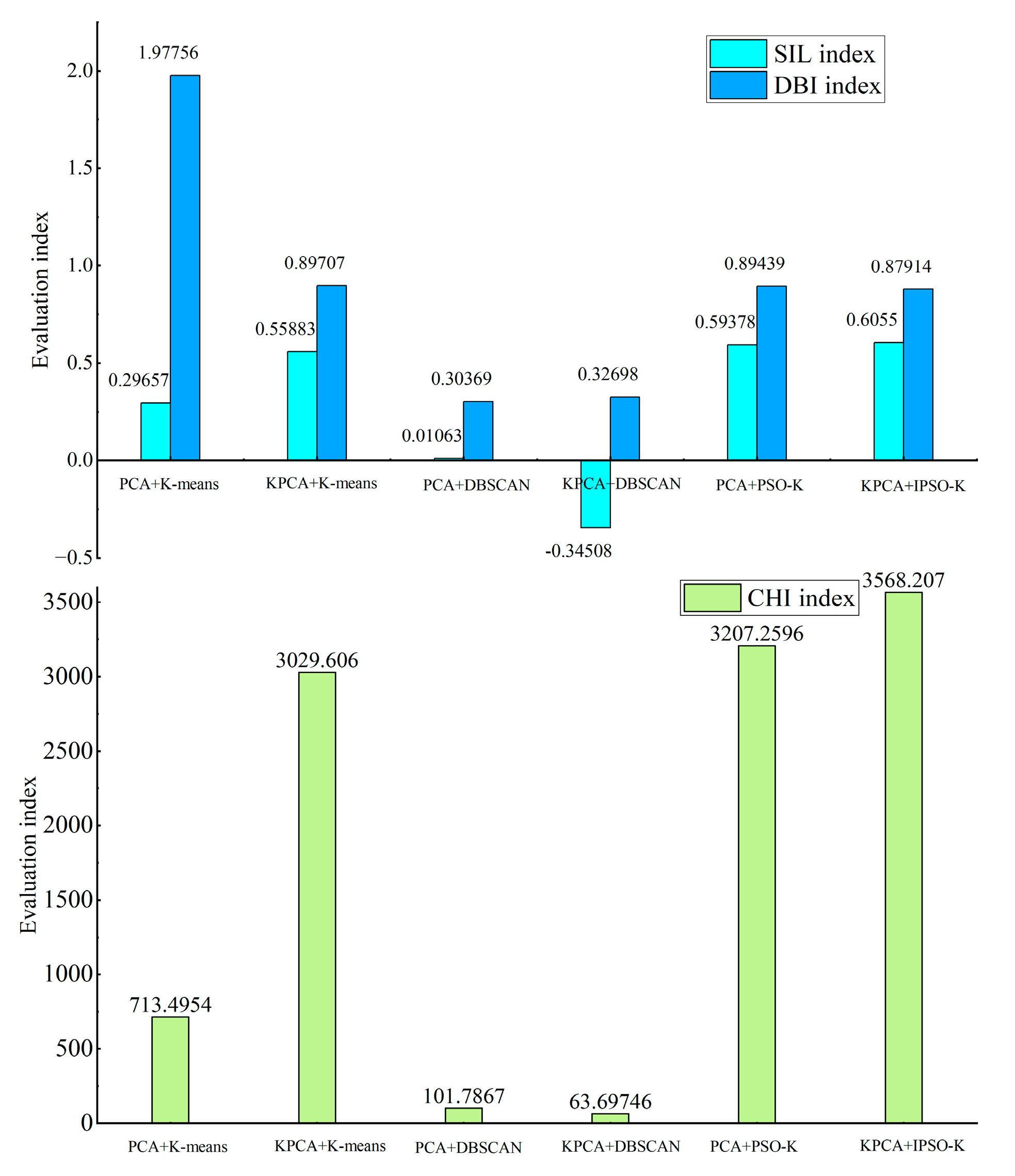
6.2. Strong Correlation Feature Variable Screening
6.3. Visual Extraction of Refined Operation Mode
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mallapaty, S. How China could be carbon neutral by mid-century. Nature 2020, 586, 482–483. [Google Scholar] [CrossRef] [PubMed]
- Kou, L.; Li, Y.; Zhang, F.; Gong, X.; Hu, Y.; Yuan, Q.; Ke, W. Review on monitoring, operation and maintenance of smart offshore wind farms. Sensors 2022, 22, 2822. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.; Zhang, N.; Du, E.; Miao, M.; Peng, F.; Kang, C. Probabilistic duck curve in high PV penetration power system: Concept, modeling, and empirical analysis in China. Appl. Energy 2019, 242, 205–215. [Google Scholar] [CrossRef]
- Yan, M.; Zhang, N.; Ai, X.; Shahidehpour, M.; Kang, C.; Wen, J. Robust two-stage regional-district scheduling of multi-carrier energy systems with a large penetration of wind power. IEEE Trans. Sustain. Energy 2018, 10, 1227–1239. [Google Scholar] [CrossRef]
- Mohandes, B.; El Moursi, M.S.; Hatziargyriou, N.; El Khatib, S. A review of power system flexibility with high penetration of renewables. IEEE Trans. Power Syst. 2019, 34, 3140–3155. [Google Scholar] [CrossRef]
- Hou, Q.; Du, E.; Zhang, N.; Kang, C. Impact of high renewable penetration on the power system operation mode: A data-driven approach. IEEE Trans. Power Syst. 2019, 35, 731–741. [Google Scholar] [CrossRef]
- Impram, S.; Nese, S.V.; Oral, B. Challenges of renewable energy penetration on power system flexibility: A survey. Energy Strategy Rev. 2020, 31, 100539. [Google Scholar] [CrossRef]
- Sinsel, S.R.; Riemke, R.L.; Hoffmann, V.H. Challenges and solution technologies for the integration of variable renewable energy sources—A review. Renew. Energy 2020, 145, 2271–2285. [Google Scholar] [CrossRef]
- D’Ettorre, F.; De Rosa, M.; Conti, P.; Testi, D.; Finn, D. Mapping the energy flexibility potential of single buildings equipped with optimally-controlled heat pump, gas boilers and thermal storage. Sustain. Cities Soc. 2019, 50, 101689. [Google Scholar] [CrossRef]
- Tang, A.; Lu, Z.; Yang, H.; Zou, X.; Huang, Y.; Zheng, X. Digital/analog simulation platform for distributed power flow controller based on ADPSS and dSPACE. CSEE J. Power Energy Syst. 2020, 7, 181–189. [Google Scholar]
- An, J.; Yu, J.; Li, Z.; Zhou, Y.; Mu, G. A data-driven method for transient stability margin prediction based on security region. J. Mod. Power Syst. Clean Energy 2020, 8, 1060–1069. [Google Scholar] [CrossRef]
- Nan, L.; Liu, T.; He, C. Identification of transmission sections based on power grid partitioning. Int. Trans. Electr. Energy Syst. 2019, 29, e2793. [Google Scholar] [CrossRef]
- Liu, X.; Min, Y.; Chen, L.; Zhang, X.; Feng, C.; Hu, W. A pragmatic method to determine transient stability constrained with interface real power flow limits via power system scenario similarity. CSEE J. Power Energy Syst. 2019, 6, 131–141. [Google Scholar]
- Yu, K.; Liu, Z.; Zhao, G.; Li, J.; Zeng, X.; Wang, Z. A novel protection method for a wind farm collector line based on FCM clustering analysis. Int. J. Electr. Power Energy Syst. 2021, 129, 106863. [Google Scholar] [CrossRef]
- Qiu, G.; Liu, J.; Liu, Y.; Liu, T.; Mu, G. Ensemble learning for power systems TTC prediction with wind farms. IEEE Access 2019, 7, 16572–16583. [Google Scholar] [CrossRef]
- Qiu, G.; Liu, Y.; Zhao, J.; Liu, J.; Wang, L.; Liu, T.; Gao, H. Analytic Deep learning-based surrogate model for operational planning with dynamic TTC constraints. IEEE Trans. Power Syst. 2020, 36, 3507–3519. [Google Scholar] [CrossRef]
- Yang, N.; Ye, D.; Lin, J.; Huang, Y.; Dong, B.T.; Hu, W.B.; Liu, S.K. Research on Data-driven Intelligent Security-constrained Unit Commitment Dispatching Method with Self-learning Ability. Proc. CSEE 2019, 39, 2934–2946. [Google Scholar]
- Liu, Y.; Sioshansi, R.; Conejo, A.J. Hierarchical clustering to find representative operating periods for capacity-expansion modeling. IEEE Trans. Power Syst. 2017, 33, 3029–3039. [Google Scholar] [CrossRef]
- Li, Y.; Bai, X.; Meng, J.; Zheng, L. Multi-level refined power system operation mode analysis: A data-driven approach. IET Gener. Transm. Distrib. 2022, 16, 2654–2680. [Google Scholar] [CrossRef]
- Farhat, M.; Kamel, S.; Atallah, A.M.; Abdelaziz, A.Y.; Tostado-Véliz, M. Developing a strategy based on weighted mean of vectors (INFO) optimizer for optimal power flow considering uncertainty of renewable energy generation. Neural Comput. Appl. 2023, 1–27. [Google Scholar] [CrossRef]
- Ulucak, R.; Khan, S.U.D. Determinants of the ecological footprint: Role of renewable energy, natural resources, and urbanization. Sustain. Cities Soc. 2020, 54, 101996. [Google Scholar]
- Tang, Y.; Huang, Y.; Wang, H.; Wang, C.; Guo, Q.; Yao, W. Framework for artificial intelligence analysis in large-scale power grids based on digital simulation. CSEE J. Power Energy Syst. 2018, 4, 459–468. [Google Scholar] [CrossRef]
- Su, B.; Ding, X.; Liu, C.; Wu, Y. Heteroscedastic Max–Min distance analysis for dimensionality reduction. IEEE Trans. Image Process. 2018, 27, 4052–4065. [Google Scholar] [CrossRef] [PubMed]
- Ayesha, S.; Hanif, M.K.; Talib, R. Overview and comparative study of dimensionality reduction techniques for high dimensional data. Inf. Fusion 2020, 59, 44–58. [Google Scholar] [CrossRef]
- El Khediri, S.; Fakhet, W.; Moulahi, T.; Khan, R.; Thaljaoui, A.; Kachouri, A. Improved node localization using K-means clustering for Wireless Sensor Networks. Comput. Sci. Rev. 2020, 37, 100284. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E.; Abualigah, L.; Abuhaija, B.; Heming, J. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Inf. Sci. 2023, 622, 178–210. [Google Scholar] [CrossRef]
- Anowar, F.; Sadaoui, S.; Selim, B. Conceptual and empirical comparison of dimensionality reduction algorithms (PCA, KPCA, LDA, MDS, SVD, LLE, ISOMAP, LE, ICA, t-SNE). Comput. Sci. Rev. 2021, 40, 100378. [Google Scholar] [CrossRef]
- Cai, L.; Wang, H.; Jiang, F.; Zhang, Y.; Peng, Y. A new clustering mining algorithm for multi-source imbalanced location data. Inf. Sci. 2022, 584, 50–64. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Shan, Q.; Zhang, Z.; Qu, Z. Visual Extraction of Refined Operation Mode of New Power System Based on IPSO-Kmeans. Electronics 2023, 12, 2326. https://doi.org/10.3390/electronics12102326
Guo X, Shan Q, Zhang Z, Qu Z. Visual Extraction of Refined Operation Mode of New Power System Based on IPSO-Kmeans. Electronics. 2023; 12(10):2326. https://doi.org/10.3390/electronics12102326
Chicago/Turabian StyleGuo, Xiaoli, Qingyu Shan, Zhenming Zhang, and Zhaoyang Qu. 2023. "Visual Extraction of Refined Operation Mode of New Power System Based on IPSO-Kmeans" Electronics 12, no. 10: 2326. https://doi.org/10.3390/electronics12102326