5.2. Experimental Dataset
The source of the experimental dataset was composed of the data of the simulation experiment conducted by volunteers in the simulation laboratory. There were five volunteers involved in creating the dataset. Each volunteer was in good physical condition and had no pathological symptoms, such as a poor sleep history.
The ground truth of the dataset was a self-made dataset that used cameras to capture video data of volunteers conducting simulation experiments in a scheduling simulation laboratory. There were a total of 5 volunteers in the dataset, and all of them had been informed of the trial content and purpose in advance and were asked to sign the trial information form. Their information is detailed in the table below. Each volunteer collected 40 min of video data. The time distribution was 10 min between 9:00 a.m. and 10:00 p.m., 10 min between 15:00 p.m. and 16:00 p.m., and 20 min between 23:00 and 24:00 p.m. A total of 200 min of data was collected, including mild-to-no fatigue, moderate fatigue, and severe fatigue states. Each data sample was collected for 1 min, with a total of 200 samples of data. After screening, 192 samples of data were available, including 54 severe fatigue samples, 64 moderate fatigue samples, and 74 mild-to-no fatigue samples. We divided all data into 138 training data (each number was 36, 46, and 56) and 54 testing data (each number was 18, 18, and 18). The training data adopted the 5-fold cross-validation method, and 110 data in the training set were used for training, in turn, while the other 28 data were used for training verification, as shown in
Table 4 and
Table 5.
In the process of recording the video of the dispatchers’ simulation work, the subjects were asked to fill in the fatigue self-examination form (KSS) [
39,
40,
41] every 300 s and to measure their own fatigue levels during this time period from a subjective perspective. Therefore, 1–4 points indicated that the participant was awake; a total of 5–6 points indicated that the participant had mild fatigue; a total of 7–8 points indicated that the participant had moderate fatigue; and 9–10 points indicated that the participant had severe fatigue (sleepiness). In addition, the fatigue status of the participants in the video was further determined using expert scoring. Since the appearance of early intoxication and mild fatigue are similar, our algorithm does not distinguish between these behaviors and divides the degree of fatigue into the following categories: mild-to-no fatigue, moderate fatigue, and severe fatigue. These were validated with the mutual verification of the degree of fatigue according to the subjective and objective aspects. The sleepiness table is shown in
Table 6.
5.3. Experimental Procedure
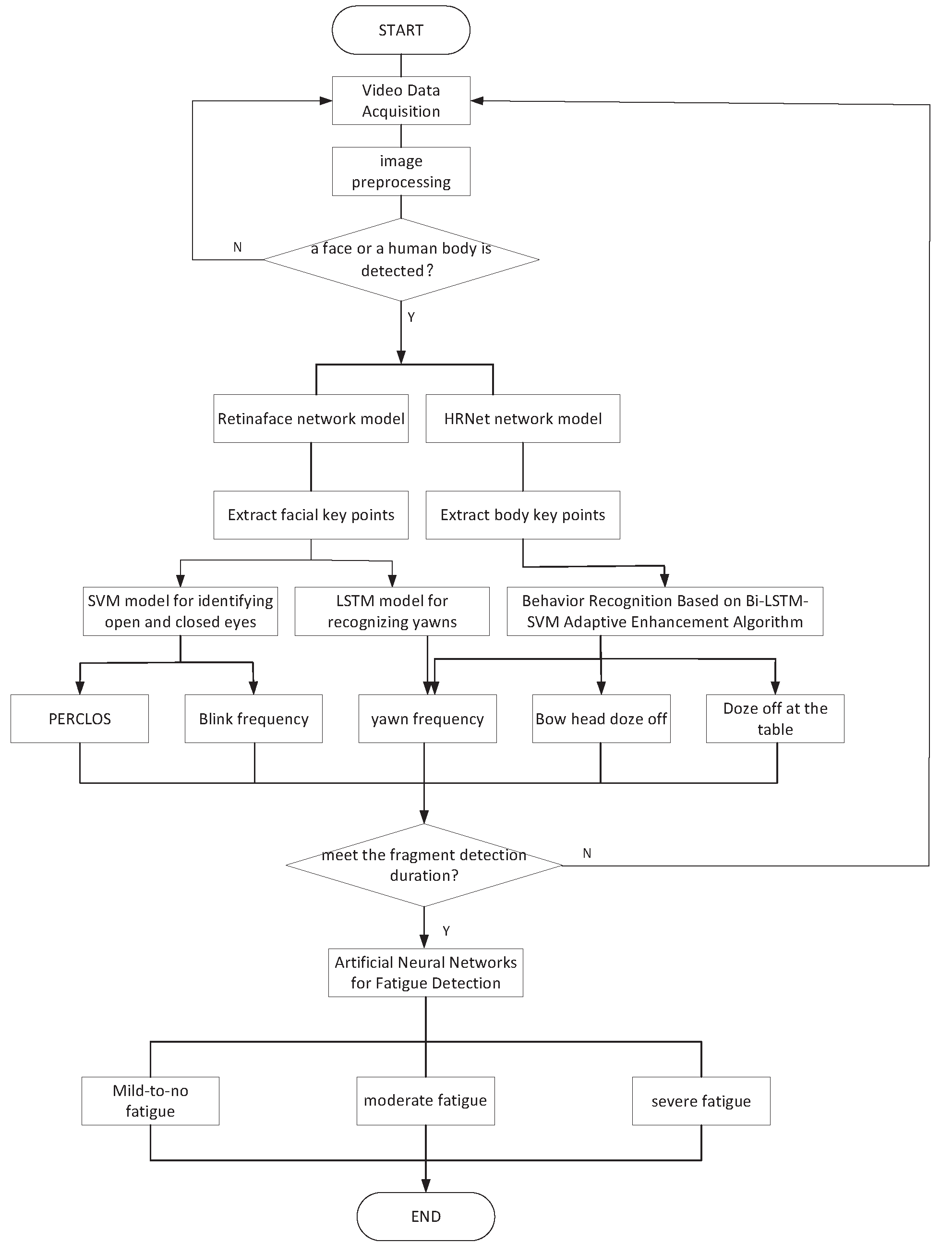
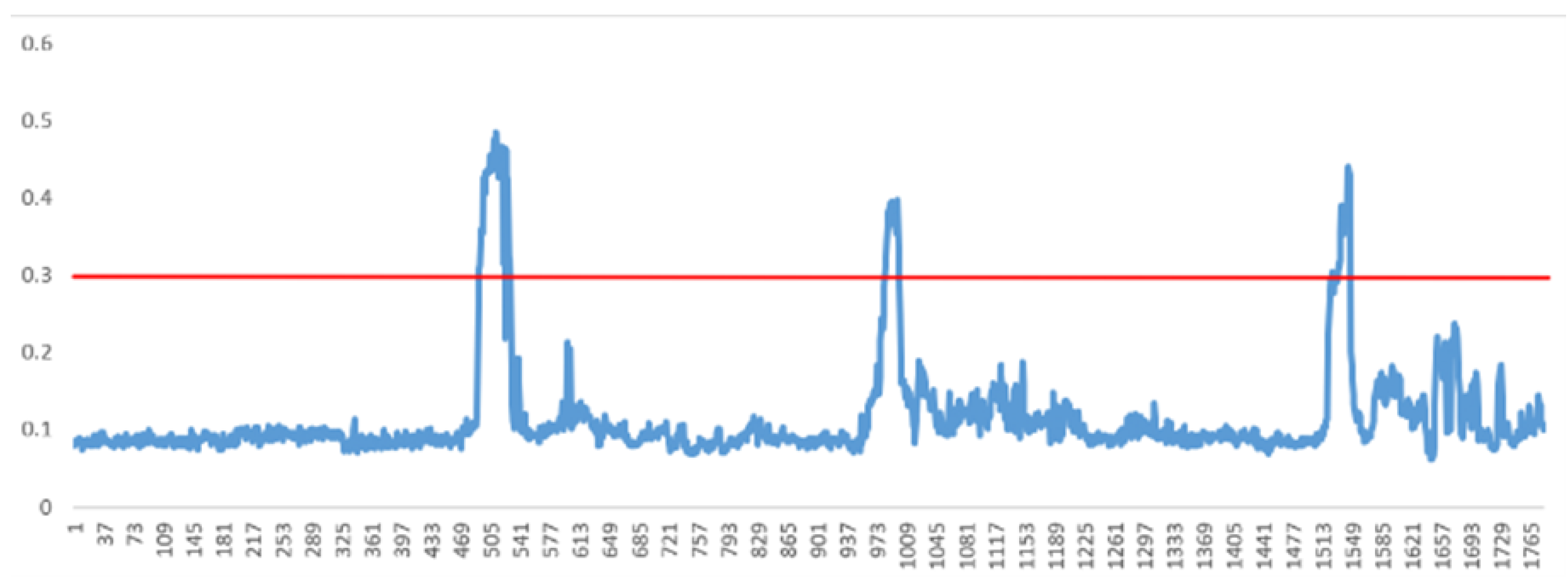
Normally, when the human body reaches a fatigued state, the blink frequency, the f-value of PERCLOS, and the number of yawns significantly increase. However, if the cycle of fatigue detection is too long, the fatigued state is difficult to identify within the time parameters; if the cycle is too short, the fatigue detection error rate increases. In order to ensure effective detection and efficiency, the fatigue detection period was set to 60 s, and the video sampling frame rate was 30 fps. Therefore, the most recent 1800 frames of data were used to calculate the values of various data and the dispatcher’s level of fatigue.
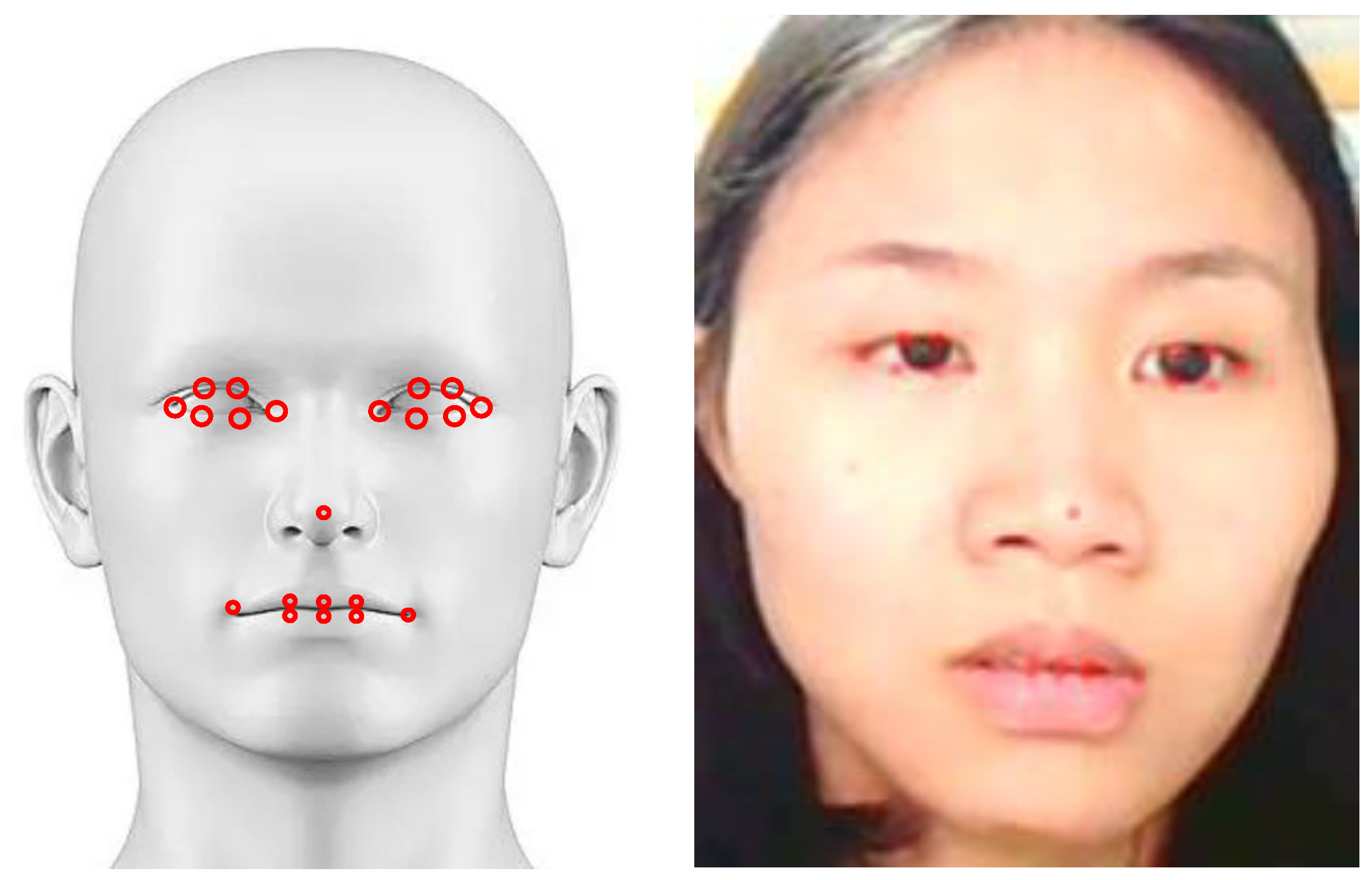
First, we input the collected video data into the RetinaFace model to locate the key points of the face and obtain the positioning data of human eyes (12 points), mouth (8 points), and nose tip (1 point), according to the facial key points of each frame of the image. The key point representing the tip of the nose was calculated to obtain the eye screenshot for the reference eye and extract the HOG feature, which was then input into the PSO-SVM classifier to distinguish the eye open or closed state and calculate the PERCLOS f-value of the latest 1800 frames.
Blinking is a process, and it takes about 0.1 s to blink one time. According to a video frame rate of 30 fps, the sampling time of one frame is about 0.033 s. Without any occlusion, at least two images could capture a single blink, so at least two consecutive pictures with eyes closed were counted as one blink.
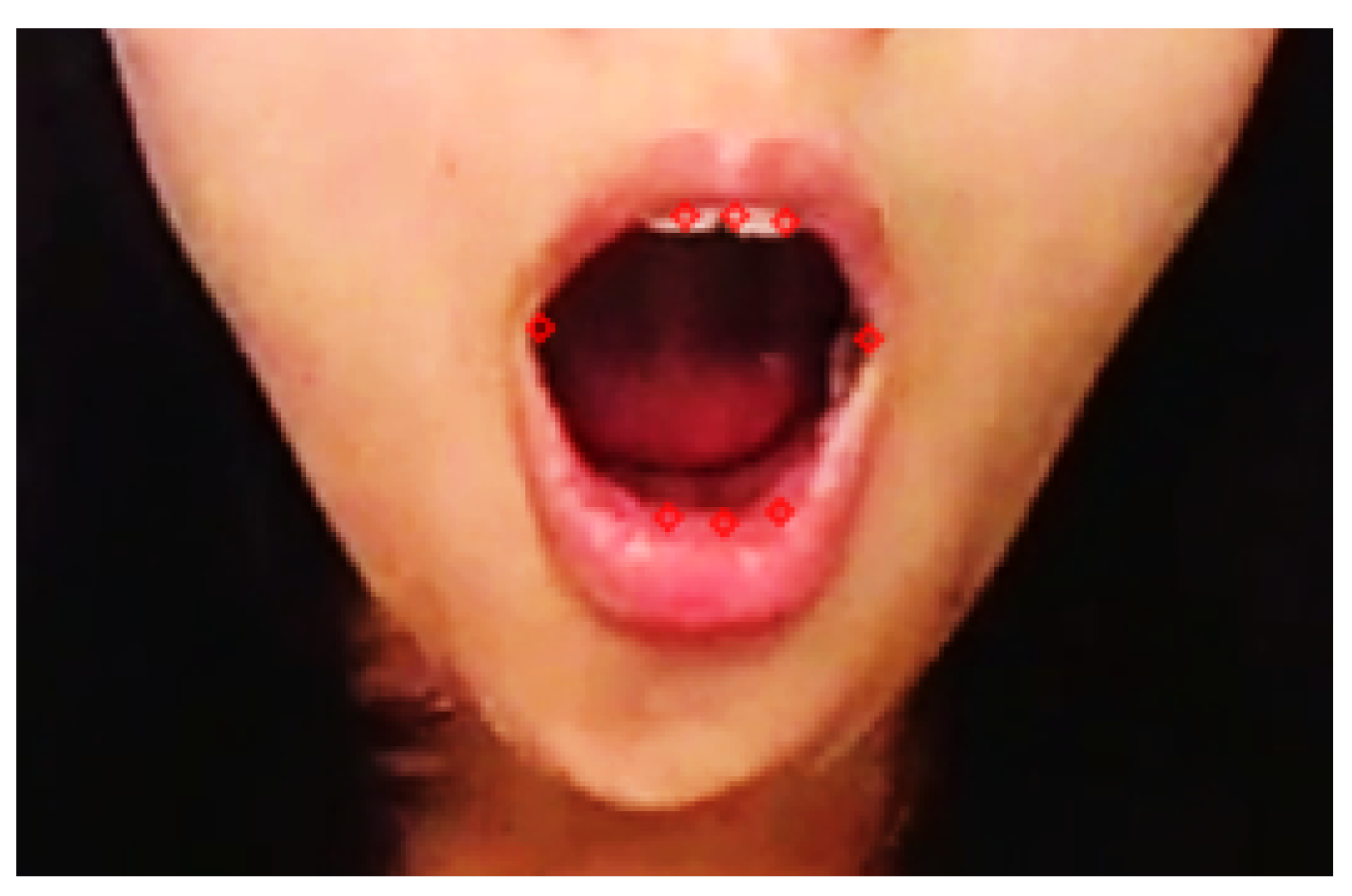
According to the position data of the eight key points of the mouth, the mouth aspect ratio (MAR) of each frame image was calculated, and a fixed threshold was used to determine the occurrence of yawning; then, the number of yawning actions in the most recent 1800 frames was also calculated. When collecting facial key points for calculation, the video data were added to the Bi-LSTM-SVM adaptive enhancement model at the same time, and the frequency of yawning, the number of sleep states (indicated by lying on the table), etc., were calculated.
The hyper-parameters that affected the classification results of the artificial neural network fatigue state classification model included the following: the number of network layers, the number of neurons in each layer, and the number of iterations. At first, we used an empirical equation to calculate the parameters and determined that the model had the following: a total of 5 input neurons; a total of 150 iterations; and two hidden layers, one with 20 neurons and the other with 30 neurons. However, this would have caused overfitting. As a result, we adopted four methods to reduce and avoid overfitting.
- (1)
Appropriately reducing model complexity
By reducing the number of neurons in the two-layer network to 10 and 15, we can reduce the amount of neuron computation and avoid overfitting.
- (2)
Using an optimizer and an appropriate learning rate
We used the Adam optimizer and selected an appropriate learning rate; we set 0.05 here.
- (3)
Early stopping
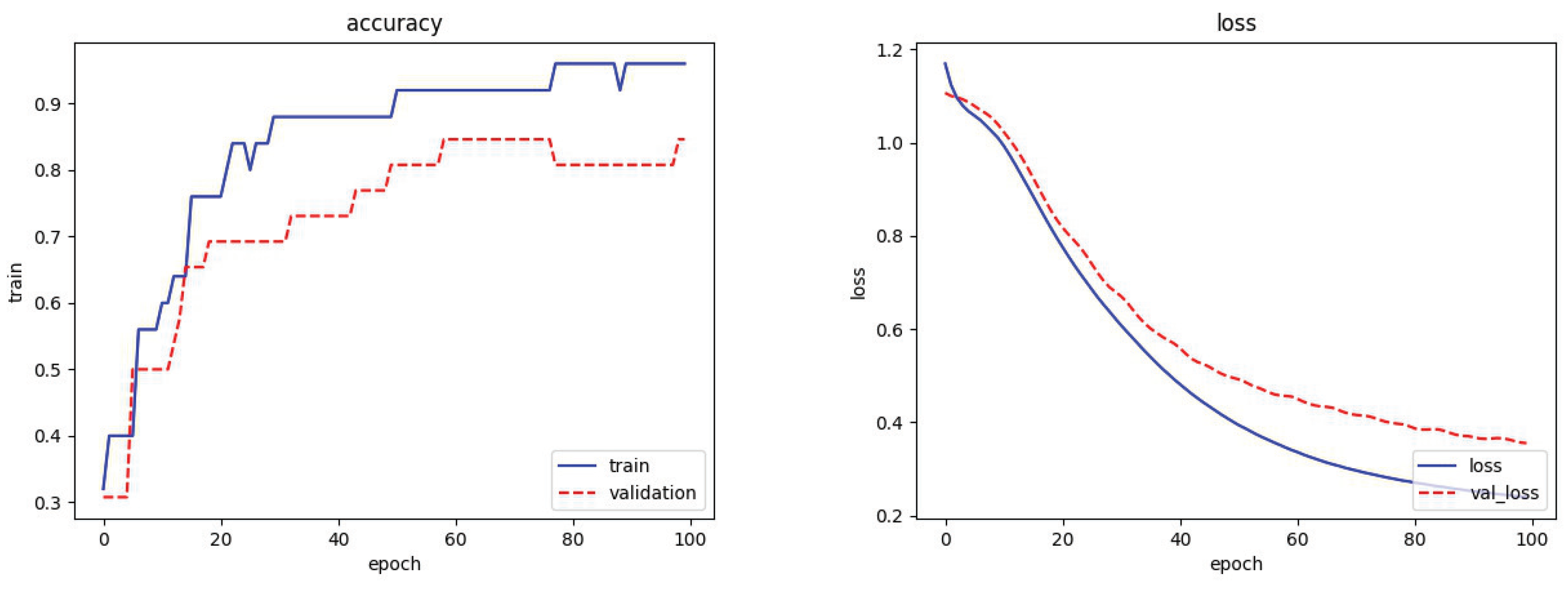
We divided the original training dataset into a training set and a validation set and only trained using the training set. We calculated the error of the model on the validation set in each cycle. When the error of the model on the validation set was worse than the previous training result, we stopped training. After training, the training epoch was stable at epoch 100. Therefore, 100 was chosen as the number of training epochs.
- (4)
The batch size cannot be set too large
When training the neural network, we set a smaller batch size, 10.
After the above debugging processes, the network effect was good, and the overfitting phenomenon was avoided. The training results are shown in
Figure 11.
The data and classification are shown in
Table 7.
5.4. Analysis of Results
In order to provide a clearer description of the effectiveness of our proposed algorithm, we conducted ablation and comparison experiments on fatigue detection, facial detection, and posture recognition. The results are as follows.
- (1)
Fatigue detection ablation test
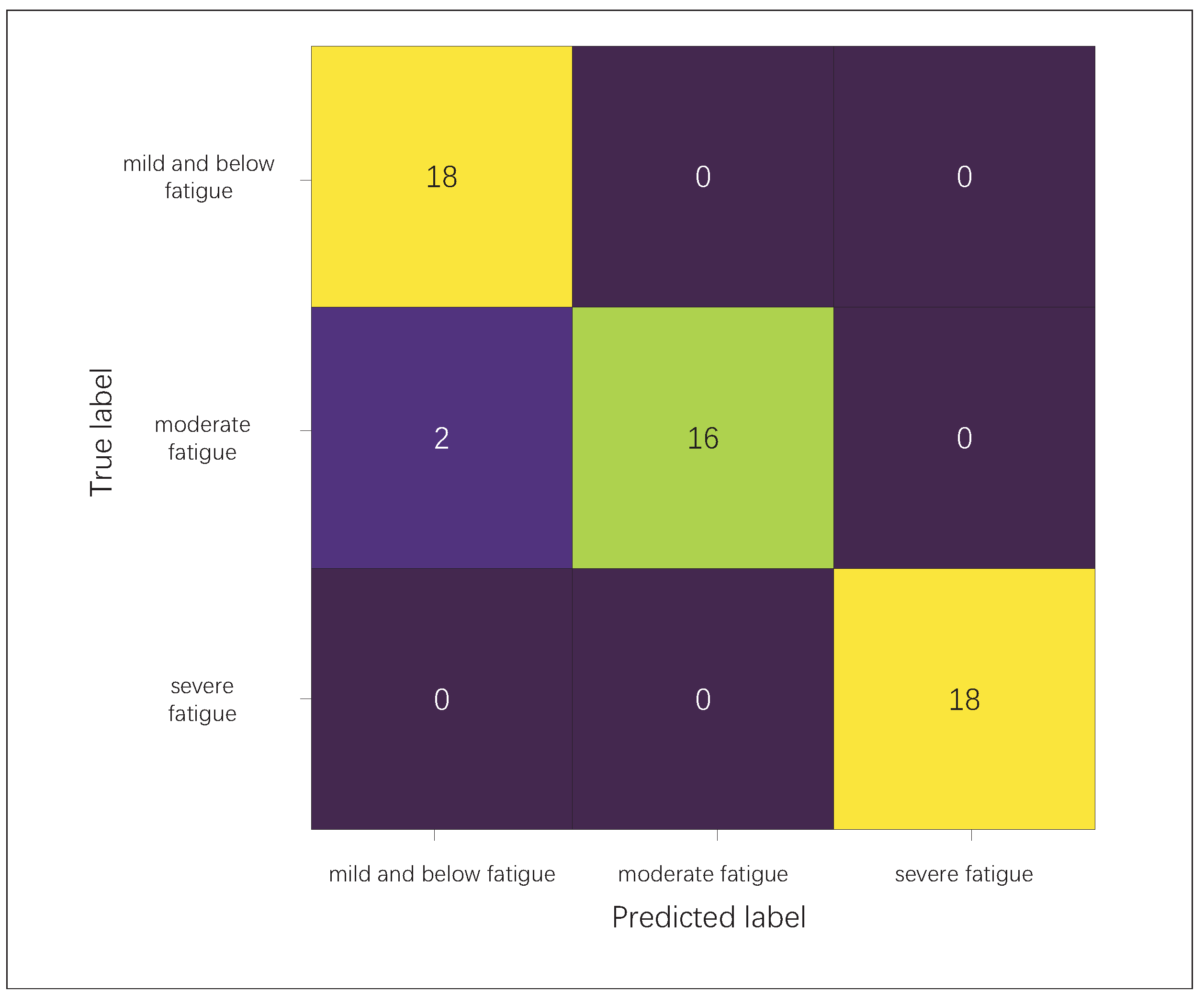
Table 8 shows the prediction results of each fatigue state, and the confusion matrix of the network model is shown in
Figure 12.
In order to verify the effectiveness of multi-feature selection in this study, the accuracy of fatigue classification under three different features was selected for comparative analysis: the PERCLOS method, which is calculated by only using eye key points; only facial features (eye key points, mouth key points, etc.); and the algorithm in this paper (facial features and behavioral features). The results are shown in
Table 9.
- (2)
Multi-feature fusion fatigue detection method comparison
A comparison with the algorithms used in previous studies is shown in
Table 10. In this study, the fatigue detection algorithm using multi-feature fusion had better accuracy than the other models, with a 3.71% higher rate than the next ranked model. The results are shown in
Table 10.
In this comparison of the three methods, all were multi-feature fusion methods for fatigue detection. In reference [
12], PERCLOS, eye closure duration, and mouth opening times are used as fatigue detection characteristics, and the fusion algorithm of the fatigue decision-making level is a BP neural network. Due to the relatively small number of features, the accuracy was the lowest among the three. In reference [
16], five features, such as the head, the eyes, and the mouth, are used for fusion, but the fusion method is weighted with empirical values. The overall effect was better than that of the other three features. Our algorithm had the best effect, because it uses five features and also considers body posture characteristics, as shown in
Table 11.
We provide a different model of behavioral and facial fusion features for fatigue state prediction. As shown in
Table 8, the overall fatigue prediction effect of the model is satisfactory, and the evaluation indexes of each fatigued state are above 96%. The model made an error in the classification of mild-to-no fatigue and moderate fatigue and classified moderate fatigue as mild-to-no fatigue. The reason is that in two records, the subjects did not display behavior changes, such as yawning or eye fatigue, making their overall characteristics relatively similar. In future research, we will focus on optimizing the scoring mechanism based on the degree of subjective sleepiness and improve the distinctive characteristics of eye fatigue.
- (3)
Facial key point model ablation test
In order to verify the efficiency of the research method proposed in this paper, the facial key point model was assessed with a testing set composed of a public and a hand-crafted dataset, and the normalized mean error (NME) was used for evaluation, as NME is a commonly used evaluation index for facial key point detection:
where
x represents the true position of the key point,
y represents the value predicted by the network, and
d represents the Euclidean distance between the two outer corners. The smaller NME is, the better the prediction results of the model are.
In order to verify the validity of the classification model proposed in this paper, the model was evaluated as a classification model, and the accuracy, recall, precision, and F1-score values are introduced for model classification. The accuracy rate is the proportion of accurately predicted samples out of all predicted samples; the recall rate reflects the probability of predicting a positive sample among the actually positive samples; and the precision rate is the accuracy of the model evaluation and prediction of positive samples. The F1-score considers both the precision and the recall values of the classification model. The equations for these calculations are the following:
True positive (TP): The sample is positive, and the prediction result is positive.
False positive (FP): The sample is negative, but the prediction result is positive.
True negative (TN): The sample is negative, and the prediction result is negative.
False negative (FN): The sample is positive, but the prediction result is negative.
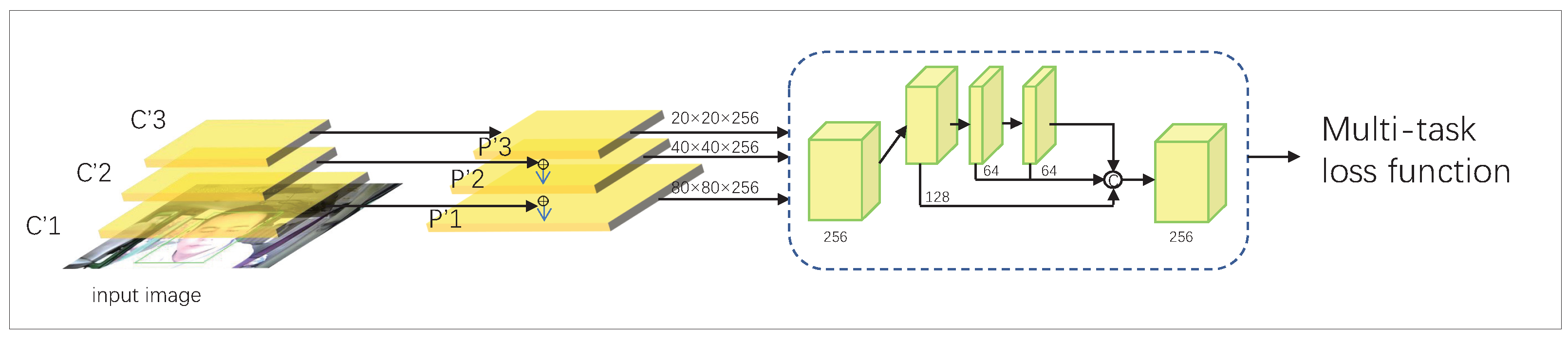
In this paper, the commonly used public dataset 300 W was used for the quality assessment of facial key point detection. The environment for this experiment used a camera (1280 × 720), a GPU NVIDIA Geforce GTX 1080Ti, and a graphics memory of 11 GB. The training set of this dataset had a total of 3148 images, and the testing set contained 689 images. In this paper, 12 key points of the eyes, 1 key point of the tip of the nose, and 8 key points of the mouth were used.
We conducted a comparative experiment. We compared the prediction accuracy (NME) of models with Gabor, without Gabor, and with LBPs. As the result show, the model with Gabor showed better performance. The Gabor filter can extract rich texture features in face images, making face feature classification and recognition more accurate, as shown in
Table 12.
- (4)
Facial key point model comparison
The NME results of RetinaFace-based facial key point recognition on the 300 W dataset are shown in
Table 13, and the prediction speeds of the single-frame pictures are shown in
Table 14.
As shown in
Table 13, RetinaFace-based facial key point recognition performed well with the comparison algorithm on the 300 W dataset, and it demonstrated good prediction accuracy on the common subset, challenge subset, and full subset. As shown in
Table 14, the volume of the model was very small, at only 1.84 M, and the prediction cost time was only 0.1 s, which meets the efficiency requirements of effective and efficient dispatcher fatigue detection.
- (5)
Behavioral classification model ablation test
To verify the effectiveness of our proposed algorithm for behavioral features, we conducted comparative experiments. We compared the accuracy of behavioral posture using different methods, including LSTM, Bi-LSTM, Bi-LSTM-SVM, and enhanced adaptive algorithms. As the results show, our algorithm improved the accuracy of posture detection. The results are shown in
Table 15.
- (6)
Behavioral classification model comparison
In order to verify the superiority of model classification, comparison and verification based on other neural networks were conducted on the same dataset. In this study, the fatigue detection algorithm based on multi-feature fusion had a higher accuracy than other models, as shown in
Table 16.
5.5. Discussion
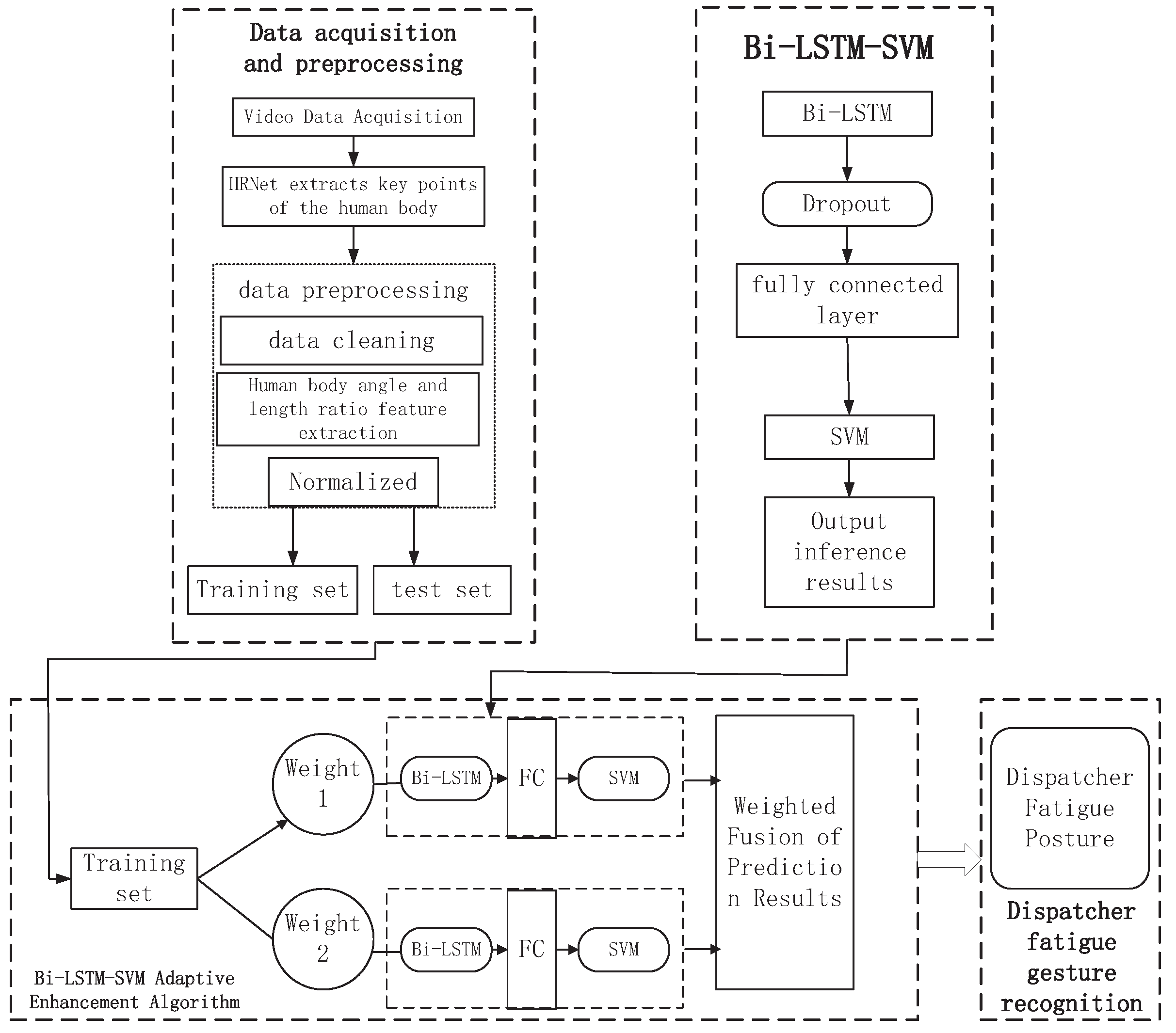
In this study, we show a method for railway train dispatcher fatigue detection using the multi-feature fusion of facial cues and body postures in a deep learning model. Considering the unfavorable factors, such as facial occlusion and angle changes, that have limited single-feature fatigue state detection methods, we developed our model based on the fusion of body postures and facial features for better accuracy.
First and foremost, this study’s method detects the fatigue status not only by using facial features but also by using human postures when the face is blocked. The result of model prediction accuracy was 96.3%, and recall was 96.3%, which indicates the effectiveness of the model. Second, we used an optimized RetinaFace model to identify eye key points, obtaining NME of 3.58 and prediction cost of 100 ms, ensuring its prediction accuracy and speed. Third, we adopted the optimized Bi-LSTM to recognize human posture to identify human fatigue posture, and the prediction accuracy was 0.96.
The comparison of the findings and those of other studies confirms that this study presents an objective fatigue detection method that uses non-contact methods to detect dispatchers’ fatigue status. At present, the features used in multi-feature fatigue detection include eye closure duration, mouth movements during yawning, and vocal tonality. The most prominent difference in our study is the use of behavioral actions as fatigue features. Compared with previous research methods that are based on facial multiple features, the prediction accuracy has been improved by 5.56% and 3.71%, respectively.
Our study focuses on the accuracy of fatigue state detection during the daily working time of dispatchers; the fatigue state is a gradual process, and the fatigue state is not an instantaneous state. Therefore, the real-time requirement for the detection of the fatigue of dispatchers is not strong. In our experimental environment, we ran it three times, and it took an average of 311 ms, which meets the research needs in dispatcher fatigue detection. In order to improve the real-time performance of the algorithm, we will continue to optimize the face key point recognition algorithm, human key point extraction algorithm, and feature extraction algorithm. For example, we will continue optimizing the feature extraction method for human posture, which can reduce the computational complexity of the algorithm and improve real-time performance.
The generalizability of the results is limited by fatigue detection methods. This study can add a more accurate technical method for identifying fatigue, such as EEG detection, and then identify fatigue using multiple feature fusion methods. Due to the fixed-focus camera used for the method in this study, if the face is far from the camera, it may not be possible to capture the face, and relying solely on posture recognition is not sufficient to fully detect fatigue. Therefore, it is more suitable for work positions where the relative camera distance remains unchanged.
This is an important issue for future research. Fatigue detection can be conducted on dispatchers to detect their fatigue status in advance, providing human fatigue data support for railway regulations and operation management and further ensuring railway operation safety.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}